從資料庫到 Supabase
在上節課中,我們學會了 UI 設計程序 Mastergo 和 Figma 的基本用法,能夠使用 github 進行程式碼的獲取與版本管理,並通過 Zeabur 部署網站將自己的應用 / 網站傳達給更多人使用。
為了幫助大家更好地銜接知識,在開始本節課關於設計工具與部署的新內容前,讓我們一起通過幾道簡單的題目快速回顧一下上節課的核心知識點:
- 什麼是前端設計工具、Figma、MasterGo 的定義和使用方式。
- 將設計稿轉換為程式碼的基礎方法。
- 什麼是 Github,如何配置 SSH,如何構建自己的第一個倉庫。
- 部署是什麼意思,如何使用 Zeabur,如何將 Github 或本地程式碼部署至公共網路給大家訪問。
如果對以上任何一個問題還有印象模糊的地方,建議先回顧一下上節課的文檔和講義。歡迎隨時在微信學習群中提出疑問。
在本節課中,我們將學習如何讓一個 APP / 網站從能跑起來變為更接近真實線上產品:除了用資料庫管理程序運行中的各種資料變化外,還要具備完善的用戶體系(註冊、登錄、權限等)以及其他關鍵後端能力。我們會以 Supabase 這一後端服務平臺為主線,先用它實現“資料庫 + 用戶系統”這兩項基礎功能,再以 Supabase 提供的組件為參照,進一步理解現代雲服務後端服務通常包含的核心模塊,以及各模塊的具體職能與作用邏輯。
你將學到
- 什麼是資料、什麼是資料庫,常見資料庫與使用方法
- 什麼是 supabase,如何使用 supabase 進行基礎的資料庫操作
- 如何使用 supabase 為應用添加基礎用戶管理功能
- 學會 Supabse 進階功能:realtime、storage、edge function
- 學會為Supabase增加 google 與 github 登錄支持
- 一款支持用戶註冊 / 登錄,並能將資料存入在線資料庫的基礎應用
- 一套可複用的 Supabase 後端程式碼模板(資料庫 + 用戶管理等),供後續項目直接套用
1. 什麼是資料庫
1.1 什麼是資料
在數字世界裡,資料(Data)無處不在。簡單來說,資料是資訊的載體。你朋友的聯繫方式、一篇微信文章、一條短影片、遊戲裡的角色等級,這些都是資料。在我們的應用中,資料就是需要被記錄和管理的一切資訊,比如用戶的個人資料、訂單歷史、程序設置等。
一般而言,資料在程序中有不同的表現形式,最簡單的就是變量,我們可以用不同變量記錄簡單的數字:
# Python variable definition examples
# Integer variable: stores age information
age = 30
# Boolean variable: stores status (whether active)
is_active = True # True means active, False means inactive
# List variable: stores a set of score data
scores = [85, 92, 78, 90] # Contains 4 integer elements representing different scores
# Dictionary variable: stores multiple related information of a user
user_info = {
"age": 30, # Key "age" corresponds to the value of age
"height": 1.80, # Key "height" corresponds to the value of height (unit: meter)
"login_count": 156 # Key "login_count" corresponds to the value of login times
}而對於上述所說的個人資料、訂單歷史這類複雜的資料而言,我們可以用更復雜的表格進行資料的表示:
| user_id | name | |
|---|---|---|
| 1001 | Alice | alice@example.com |
| 1002 | Bob | bob@example.com |
| order_id | user_id | amount | status |
|---|---|---|---|
| 901 | 1001 | 29.99 | completed |
| 902 | 1002 | 15.50 | pending |
但對於結構複雜、具有層級關係或字段不固定的資料,我們可以用 JSON 格式進行描述 —— 它是互聯網通用的資料中間格式,幾乎所有程序都能讀取解析,跨系統傳資料很方便。例如,一個訂單可能包含多個商品,每個商品又有自己的名稱、數量和價格。用傳統的表格來表示會很笨拙:要麼得拆成 “訂單表”“商品表” 多張表,靠關聯字段才能體現 “訂單包含商品” 的關係;要麼在一張表用 “商品 1 名稱、商品 1 價格、商品 2 名稱……” 這類冗餘字段,遇到商品數量不固定時根本沒法適配;而 JSON 能直接用嵌套結構把 “訂單 - 商品 - 商品屬性” 的層級說清,既直觀又靈活。
{
"order_id": 901,
"user_id": 1001,
"amount": 29.99,
"status": "completed",
"items": [
{ "sku": "BG-001", "name": "牛肉漢堡", "quantity": 1, "price": 18.00 },
{ "sku": "SD-003", "name": "炸薯條", "quantity": 1, "price": 6.99 },
{ "sku": "DK-002", "name": "可樂", "quantity": 1, "price": 5.00 }
],
"shipping_address": {
"street": "科技園路123號",
"city": "深圳",
"zip_code": "518057"
}
}更進一步的,如果我們考慮一個被編碼成向量(Vector)的資料,向量資料通常是文本、圖片或音頻等非結構化資料經過 AI 模型(如 Embedding 模型)處理後得到的數值表示。它的表示形式可能是:
[0.123, -0.456, 0.789, ..., -0.234] (一個由幾百甚至上千個浮點數組成的數組)
總的來說,在現實世界中有太多不同形態、用途的資料值得我們詳細分析,每種資料可能都需要專門的資料庫用於存儲,具體可參考下圖——是不是感覺非常多?
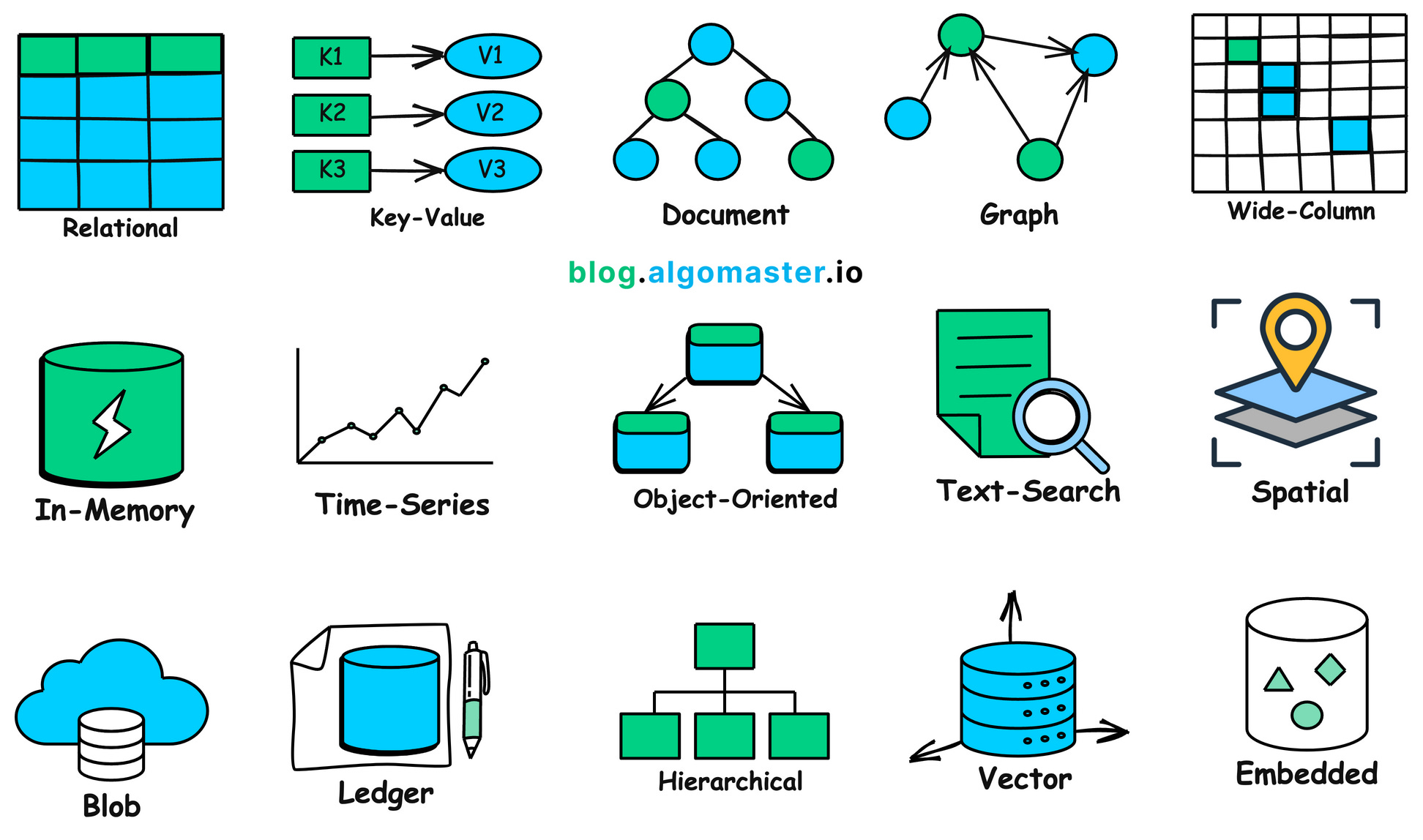
1.2 為什麼我們需要資料庫
我們已經瞭解到真實世界中的資料往往結構複雜,為了高效存儲與使用這些資料,我們需要一個專門的程序或容器來管理它們 —— 這便是資料庫(Database)的誕生初衷。資料庫本質上是一款特殊程序,核心作用就是對資料進行規範化組織、安全存儲、系統化管理,並支持高效查詢調用。
想象一下,若沒有資料庫,應用資料會陷入怎樣的困境?當用戶關閉瀏覽器或退出應用時,所有臨時加載的資訊都會直接丟失;我們既無法永久保存用戶的使用狀態(比如登錄資訊、個性化設置),也沒法在不同用戶之間共享關鍵資料(比如商品庫存、訂單記錄)。我們需要有一個裝置幫我們存儲所有的資料!
更靈活的是,資料庫的部署方式可按需選擇:既可以部署在本地服務器,滿足資料本地化管理的需求;也能部署到雲端,雲端資料庫支持彈性擴容(Scale),可隨資料量與訪問量增長擴展能力、承載海量資料與高併發,即便用戶量大幅提升,也能保障用戶的正常使用體驗。
歸納而言,資料庫憑藉高效的持久化存儲、精細化管理與快速查詢能力,主要解決了以下核心問題:
- 資料的持久化存儲 : 如果沒有資料庫,資料將僅存在於應用的內存中,一旦應用關閉,資料就會丟失。資料庫解決了這個問題,它將資料持久地存儲在硬盤等存儲介質上,確保了資料的長期保存,降低了丟失風險。
- 便捷的資料查詢與分析 : 資料庫提供了強大的查詢語言(如 SQL),讓用戶可以輕鬆、高效地對海量資料進行復雜的查詢、篩選和分析,從而幫助企業做出更明智的決策。 如果沒有資料庫,從大量無序文件中查找特定資訊將是一項極其耗時且困難的任務。
- 支持高性能與高併發訪問 : 資料庫通過索引優化、查詢緩存、連接池以及分佈式架構等技術,能夠在毫秒級時間內響應查詢請求,並支撐成千上萬用戶的併發訪問。這對於現代互聯網應用(如電商平臺秒殺活動、社交網路實時動態)至關重要,確保了系統的響應速度和用戶體驗。如果沒有資料庫的高性能支撐,面對海量用戶請求時系統將會出現嚴重延遲甚至崩潰。
- 保證資料的完整性和一致性 : 資料庫通過一系列機制(如約束、觸發器)來確保資料的準確性和一致性。 這意味著資料庫中的資料必須符合預設的規則,例如,用戶的年齡必須是數字,訂單號必須是唯一的,從而有效防止了非法或無效資料的產生。
- 確保資料的安全性 : 資料庫提供了強大的安全機制,包括用戶身份驗證、訪問控制和資料加密等,以保護資料免受未經授權的訪問、修改或破壞。為了應對硬體故障、人為失誤或惡意攻擊等意外情況,資料庫還提供了資料備份和恢復功能。 通過定期備份,可以在資料丟失或損壞時及時恢復,保障了業務的連續性。
1.3 關係型資料庫與非關係型資料庫
前面我們已經瞭解了資料庫的核心價值、部署方式與彈性優勢,而在實際選擇時,首先要面對的就是資料庫的兩大核心類別:關係型資料庫與非關係型資料庫(NOSQL),我們可以用簡單的兩段話簡單理解他們的區別:
關係型資料庫就像結構嚴謹的Excel表格,所有資料必須預先定義好格式(定義好 Schema 的內容, 比如要有姓名和年齡,且姓名必須是文字,年齡必須是數字),並通過關聯字段(用來連接不同表格的標識,如身份證號)將不同表格連接起來。它的好處是資料精確可靠,特別適合銀行轉賬、庫存管理等不能出錯的場景,但缺點是調整結構比較麻煩,海量資料下性能會受限。
非關係型資料庫則像靈活的文件夾,可以存放格式各異的文檔、圖片或鍵值對(類似字典的"詞-解釋"結構),不需要提前規定好每份資料的結構。它更容易應對快速變化的需求和超大規模資料(比如社交媒體的海量帖子),擴展(增加服務器提升性能)起來也更方便,但犧牲了部分關聯查詢能力(跨不同資料表整理資訊的能力)和一致性保障(確保資料時刻準確不矛盾),適合對容錯性要求較高的互聯網應用。
那麼,實際應用中該如何選擇資料庫?從場景劃分總結來看,關係型資料庫常見於金融交易、庫存管理、訂單處理、賬務系統等需要強一致性、複雜事務處理以及頻繁讀寫均衡訪問的場景;而非關係型資料庫更適配社交媒體內容存儲、實時日誌分析、物聯網海量資料寫入、推薦系統特徵讀多寫多等高併發、讀寫模式不均衡且結構靈活的需求。
但對於企業而言,在初級階段並不需要花大量時間思考什麼需要使用什麼資料庫。當前的資料庫已是非常成熟的產品服務,最直接的方式是諮詢不同雲服務廠商(指提供服務器、存儲、資料庫、軟體、算力等 IT 資源與技術服務的服務商)。我們可直接對接雲服務官方銷售,根據自身產品業務需求匹配適配的資料庫方案;而構建企業級應用的便捷路徑,便是優先與專業廠商合作。(需注意:企業級服務價格通常較高,建議先多方調研對比,也可選擇購買服務器自行部署開源資料庫程序作為替代方案。)
我們也可參考某家雲廠商的資料庫選型推薦,根據場景可進行不同資料庫類型的選擇,你可以對比不同雲廠商的資料庫規格選出最合適的進行使用。
| 資料庫類型 | 資料庫名稱 | 價格 | 適用場景 |
|---|---|---|---|
| 關係型資料庫 | RDS MySQL版 | 低 | 基礎版:學習以及小型網站高可用版:一定業務壓力的中型資料庫場景集群版:業務不允許中斷,訪問壓力較大 |
| RDS SQL server版 | 高 | 基礎版:測試以及小型商業化網站高可用版:企業級商業化網站集群版:企業業務不允許中斷,訪問壓力較大 | |
| RDS PostgreSQL版 | 最低 | 基礎版:學習以及小型網站高可用版:一定業務壓力的中型資料庫場景集群版:業務不允許中斷,訪問壓力較大的場景,其性能較一般MySQL高 | |
| RDS PPAS版 | 高 | 通用型:兼容Oracle業務,但業務壓力Udacity,虛擬化可以滿足其需求獨享型:面對需要獨享物理機的業務,一般為高併發Oracle類業務 | |
| DRDS | 中 | 入門版本:4 Core 8 G,價格親民,適合中小型在線業務企業版:16 Core 32 G,複雜 SQL 響應好,適合超高併發在線業務至尊版:32 Core 64 G,複雜 SQL 執行響應最好,提供超大規格選擇 | |
| NoSQL資料庫 | Redis | 中 | 雙機熱備Redis:一般作為持久化資料庫提高業務可用性集群版本的Redis:一般作為緩存層,加速應用訪問,解決一般資料庫無法負載的讀取壓力 |
| MongoDB版 | 中 | 單節點實例單節點:適用於開發、測試及其他非企業核心資料存儲的場景副本集實例:適用於某些業務場景下對資料庫有更高讀取性能需求,如閱讀類網站、訂單查詢系統等讀多寫少場景或有臨時活動等突發業務需求分片集群實例:基於多個副本集(每個副本集沿用三副本模式)組成的分片集群實例,提供更高的讀取性能需求,為實時在線業務提供高速讀取性能 |
光說不易理解,我們通過一個具體的“博客文章”場景,來看看同樣的資料在關係資料庫 (SQL) 和不同類型的非關係資料庫 (NoSQL) 中是如何存儲的。
假設我們有一個博客平臺,需要存儲以下資訊:
- 用戶(Users):用戶 ID、用戶名、郵箱
- 文章(Posts):文章 ID、標題、內容、作者 ID
- 評論(Comments):評論 ID、評論內容、評論者 ID、所屬文章 ID
- 標籤(Tags):標籤 ID、標籤名
- 文章與標籤的關係:單篇文章關聯的多個標籤、單個標籤對應的多篇文章
關係資料庫 (SQL) 示例
在SQL資料庫中,我們會將不同類型的資料分別存儲在不同的表中,並通過“外鍵”將它們關聯起來。這種結構清晰、規範,減少了資料冗餘。
以 “內容平臺的文章管理” 為例,我們不會把 “用戶、文章、評論、標籤” 混存,而是拆成 5 張功能單一的表,每張表都有明確的 “職責邊界” 和嚴格的結構定義(Schema):
users表 (存儲用戶資訊)
| user_id (主鍵) | username | |
|---|---|---|
| 101 | Alice | alice@example.com |
| 102 | Bob | bob@example.com |
posts表 (存儲文章資訊)
| post_id (主鍵) | title | content | author_id (外鍵) |
|---|---|---|---|
| 1 | 初識SQL | 這是關於SQL資料庫的一篇文章... | 101 |
| 2 | NoSQL入門 | NoSQL提供了靈活的資料模型... | 102 |
comments表 (存儲評論資訊)
| comment_id (主鍵) | body | commenter_id (外鍵) | post_id (外鍵) |
|---|---|---|---|
| 1001 | 寫得很棒! | 102 | 1 |
| 1002 | 學習了。 | 101 | 2 |
| 1003 | 有沒有更多例子? | 101 | 1 |
tags表 (存儲標籤)
| tag_id (主鍵) | tag_name |
|---|---|
| 51 | 資料庫 |
| 52 | 技術 |
| 53 | 入門 |
post_tags表 (存儲文章與標籤的多對多關係,體現聯表特點)
| post_id (外鍵) | tag_id (外鍵) |
|---|---|
| 1 | 51 |
| 1 | 52 |
| 2 | 51 |
| 2 | 52 |
| 2 | 53 |
若需查詢 “Alice 發表的《初識 SQL》(post_id=1)的完整資訊(含文章內容、作者、評論、標籤)”,需執行多表連接(JOIN)查詢,通過外鍵關聯 5 張表並聚合資料,SQL 語句如下:
SELECT
p.title,
p.content,
u.username AS author,
c.body AS comment,
t.tag_name AS tag
FROM
posts p
JOIN
users u ON p.author_id = u.user_id
LEFT JOIN
comments c ON p.post_id = c.post_id
LEFT JOIN
post_tags pt ON p.post_id = pt.post_id
LEFT JOIN
tags t ON pt.tag_id = t.tag_id
WHERE
p.post_id = 1;這個查詢會跨越5個表,將所有相關資料聚合在一起返回。這是關係資料庫的核心優勢:通過規範化和連接操作,可以靈活地進行各種複雜的查詢,同時保證了資料的一致性和最小冗餘。
非關係資料庫 (NoSQL) 示例
NoSQL 資料庫(如 MongoDB、Redis)的設計思路與 SQL 相反,它不強調資料的拆分與規範,通常會將業務上相關聯的所有資料打包聚合在一起,以減少查詢時的連接操作,從而提高讀取性能。
在 NoSQL 資料庫中,文檔資料庫(Document Database) 是最常用的類型之一,MongoDB 就是典型代表。它以 “文檔” 作為基本存儲單元,這裡的 “文檔” 並非我們日常理解的 “文章”,而是一種類似 JSON 的資料結構(MongoDB 中實際使用 BSON 格式,支持更多資料類型):無需預先定義統一的 Schema(資料結構),每個文檔的字段可以靈活增減,字段類型也能自由調整,完美適配資料格式多變的場景。
在文檔資料庫中,通常會將一篇文章及其所有相關資訊(如評論、標籤)存儲在一個文檔中(文檔格式類似 JSON,可靈活定義字段,無需預先制定 Schema),核心邏輯是 “將‘一個業務場景下的完整資訊’存放在一個文檔中”,避免查詢時的多資料源拼接。
posts 集合中的一個文檔示例:
{
"_id": 1,
"title": "初識SQL",
"content": "這是關於SQL資料庫的一篇文章...",
"author": {
"user_id": 101,
"username": "Alice",
"email": "alice@example.com"
},
"tags": [
"資料庫",
"技術"
],
"comments": [
{
"comment_id": 1001,
"body": "寫得很棒!",
"commenter": {
"user_id": 102,
"username": "Bob"
}
},
{
"comment_id": 1003,
"body": "有沒有更多例子?",
"commenter": {
"user_id": 101,
"username": "Alice"
}
}
]
}這種設計的優勢非常直觀:當你需要獲取 “第一篇文章的完整資訊(含作者、評論、標籤)” 時,只需通過 _id:1 查詢這一個文檔,資料庫一次讀取就能返回所有資料,無需像 SQL 那樣執行 3-4 次表連接操作,讀取效率大幅提升。
但它也存在明顯的 trade-off(取捨):由於資料是 “聚合存儲”,會不可避免地產生資料冗餘—— 比如作者 “Alice” 的 username 被嵌入到她寫的每一篇文章文檔中,如果某天 “Alice” 將用戶名改為 “Alice_New”,理論上需要遍歷所有包含她資訊的文章文檔,逐一更新 author.username 字段,不僅操作繁瑣,還可能因網路或服務器問題導致部分文檔更新失敗,出現 “同一用戶在不同文章中用戶名不一致” 的情況。
不過在實際業務中,這種冗餘往往是 “可接受的”:對於博客、資訊、電商商品詳情等 “ 讀多寫少 ” 的場景(用戶查看內容的次數遠多於作者修改用戶名的次數),用少量的冗餘換取 “極致的讀取性能” 是更優的選擇;而如果是 “寫多讀少”(如頻繁修改用戶資訊)的場景,則需要結合業務需求權衡是否使用文檔資料庫。
以上是對不同資料庫的簡單介紹,如果你對更多具體的資料庫類型感興趣,你可以參考如下資料嘗試不同類型的資料庫。
Examples of SQL databases: Db2、MySQL、PostgreSQL、YugabyteDB、CockroachDB、Oracle Database、Azure SQL Database
Examples of NoSQL databases: Redis、CouchDB、MongoDB、Cassandra、Elasticsearch、BigTable、Neo4j、HBase
2. Supabase
在前面我們已經介紹了幾類常見的資料庫,以及它們各自適合的使用場景。不過在真實項目裡,資料庫通常只是後端體系中的一個基礎模塊:除了存儲和查詢資料,你還需要解決用戶註冊登錄、權限校驗、文件上傳與存儲、對外 **API** 接口、甚至定時任務、實時通知等一整套問題。僅僅選好資料庫,並不能讓你的應用“立刻就能上線運行”,中間還隔著一大圈繁瑣的後端工程工作。
所以,我們需要考慮一個更大的背景: 後端服務 。一個完整的應用,通常都由“前端 + 後端”組成:前端負責頁面展示和用戶交互,後端則負責資料存儲、用戶登錄、業務邏輯處理等。過去,開發者往往需要自己搭建服務器、配置資料庫、設計並實現 API,還要手動處理權限管理、安全策略、擴展性和監控運維等事務,整個過程既重複又耗時。為了解決這些重複勞動,業界出現了 BaaS(Backend as a Service,後端即服務) :把資料庫、用戶認證、文件存儲、實時能力等常見後端功能打包成一個雲端平臺,開發者通過 SDK / API 就能直接調用這些能力,而無需從零搭建和運維基礎設施。
在這個背景下,Supabase 就可以看作是新一代的 BaaS 代表:它以 PostgreSQL 作為核心資料庫,在其之上集成了 Auth、Storage、Realtime、Edge Functions、Vector 等一整套後端能力,為開發者提供一個“以 Postgres 為中心的一站式後端平臺”。接下來,我們就從這個角度出發,從“只選資料庫”升級到“選擇完整的後端開發平臺”,具體看看 Supabase 能幫我們省掉哪些工作,又是如何讓一個項目從原型到可用產品的距離大幅縮短的。
2.1 分步指南
在清晰把握 Supabase 的整體定位後,接下來我們將沿著 Supabase 控制檯的操作路徑,逐項拆解它具體提供哪些核心能力,以及每項能力對應的核心職責。我們會詳細介紹 supabase 涉及的每個選項,幫助你快速入門 supabase 的基本操作。

訪問 Supabase 官網並登錄後,在控制檯首頁點擊 New project 進入創建流程;
輸入需要配置的主要內容 Project Name、資料庫密碼,地址只需要選擇為與程序目標用戶最接近的區域即可。
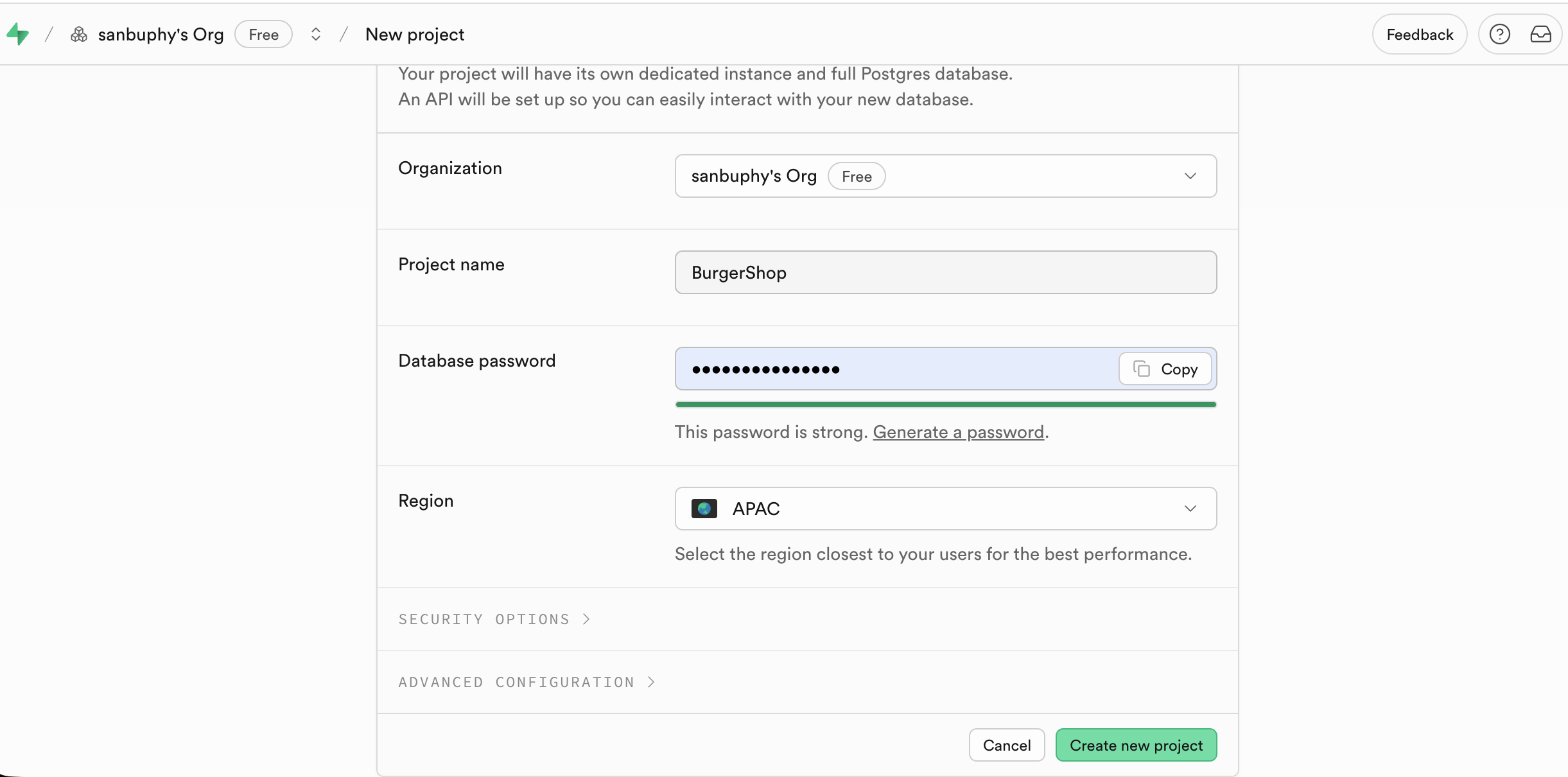
創建成功後,控制檯左側側邊欄將顯示所有核心功能模塊(Table Editor、SQL Editor、Database、Authentication 等),後續操作將圍繞這些模塊展開。
表編輯器
Table Editor 可以當成是 Supabase 的可視化資料表編輯器,它能讓你像操作 Excel 一樣直接查看和修改資料庫裡的資料,無需編寫 SQL 語句,只需要用鼠標交互即可修改資料內容。
其中值得關注的是 Schema,Schema 可理解為資料庫內的 “資源容器”,用於對錶、視圖、函數、索引等資源進行分組管理,主要作用有二:一是避免命名衝突(不同 Schema 下可存在同名table),二是實現權限隔離(如僅允許特定用戶訪問某 Schema 下的表);
點擊編輯器頂部的 Schema 下拉框可切換不同容器,日常開發中一般只需關注兩類:
public:默認的公共資源容器,開發者新建的業務表(如 “文章表”“評論表”)均存儲於此;auth:用戶認證專屬容器,其中的users表自動存儲所有註冊用戶資訊(如用戶 ID、郵箱、登錄時間),不建議手動修改此 Schema 下的默認表,避免影響認證功能;

SQL 編輯器
SQL Editor 作為 Supabase 的 SQL 語句執行器,可讓你用程式碼的方式直接操作資料庫。你可以讓大模型直接生成 SQL 語句,在右側輸入後點擊 RUN 即可用語句創建或修改 table,也可以直接在 Results 中直接看到篩選出的 table 資料。
你可以在運行 RUN 之後,在 Table Editor 的 public schema 裡找到新建後的資料表;並且運行後的語句會保存在左側的 PRIVATE 欄中,甚至可以點擊下方的愛心標誌對這一條查詢或創建語句進行收藏。
資料庫管理中心
Database 是 Supabase 的資料庫管理中心,支持可視化地查看和管理所有資料表,並通過表的相互連線理解不同表間的關聯關係(即外鍵約束,表示資料間的引用關係)。
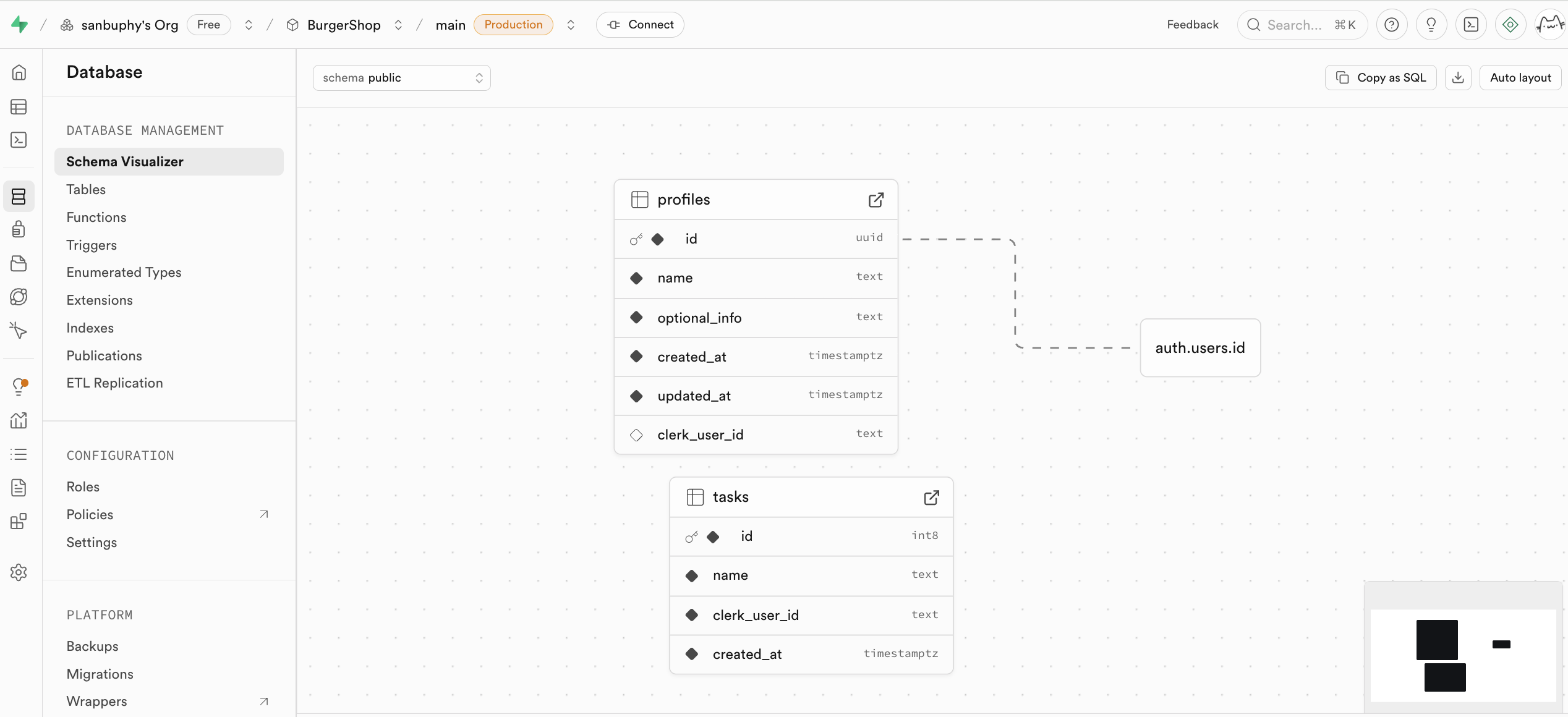
如果你想要手動新建 table,可以在 tables 中直接新建表格,我們會在之後的教程中詳細講解。
身份認證
Authentication 負責管理用戶的註冊、登錄和權限。默認的用戶管理系統資料都在此處存儲,它提供了開箱即用的用戶註冊、登錄、密碼重置、郵箱驗證等功能,並支持第三方 OAuth 登錄(如微信、GitHub、Google 等)。所有用戶資料會自動同步到資料庫的 auth.users 表中。
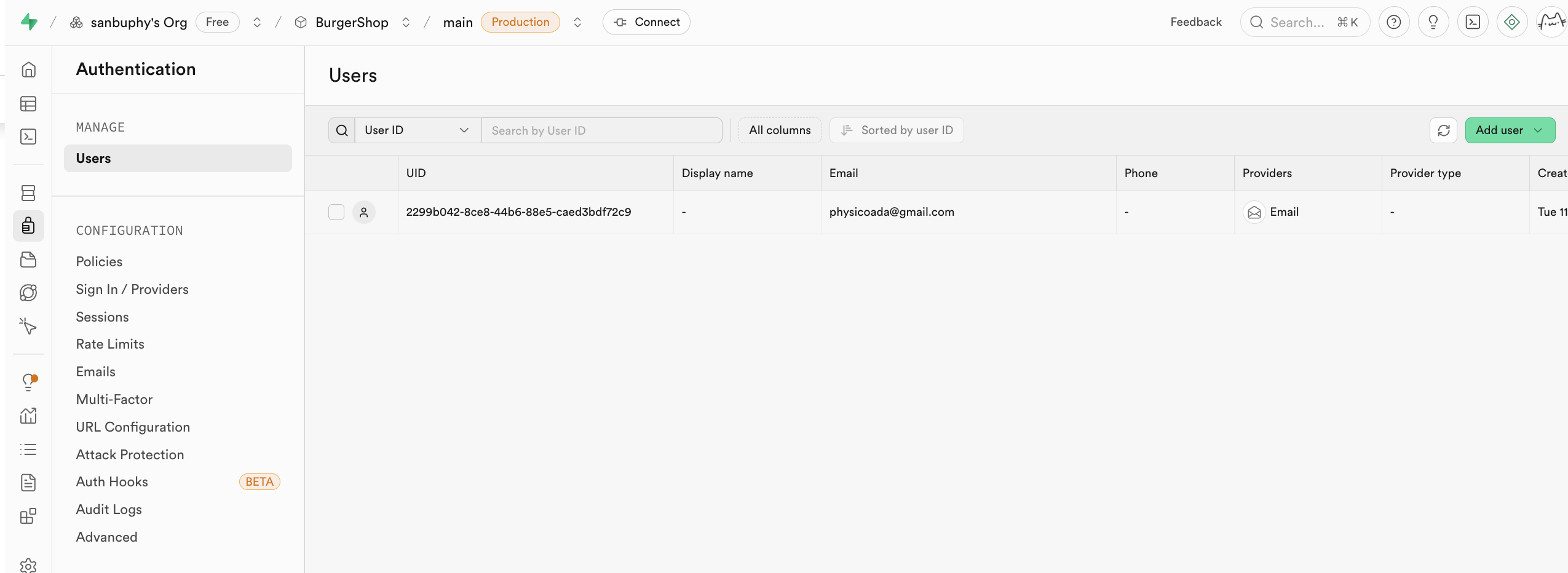
你可以在 Provider 選項中找到不同 supabase 支持的用戶資訊登錄入口,默認使用 Email;如果你想使用 Github 或者 Google 賬戶進行登錄,還需要更多屬性配置,我們會在下面的課程中進行詳細講解。
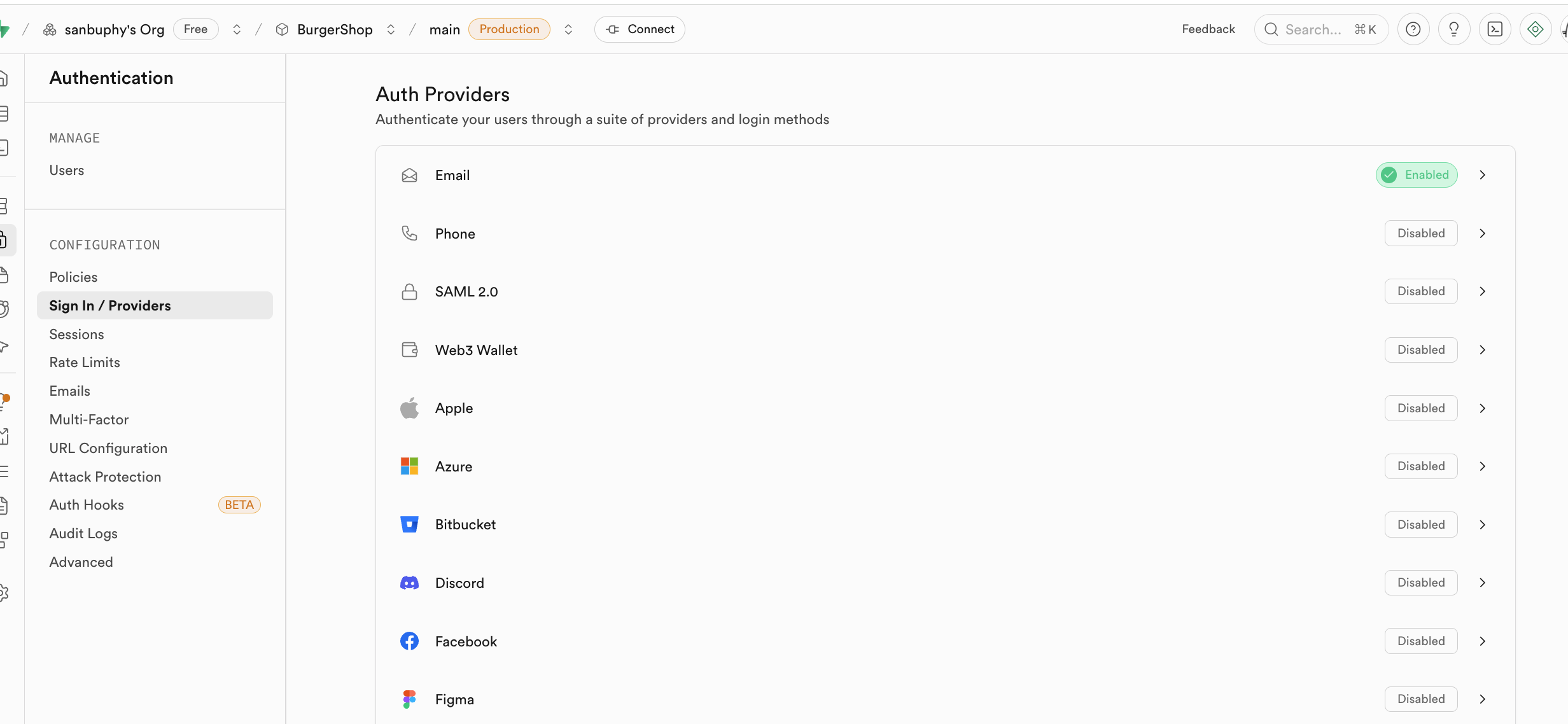
在 Sign In / Providers 裡還包含了對註冊郵箱行為的控制,如果你不想每次郵箱註冊都必須讓用戶接受邀請後才能成為用戶,你可以取消 Confirm email 的強制要求。
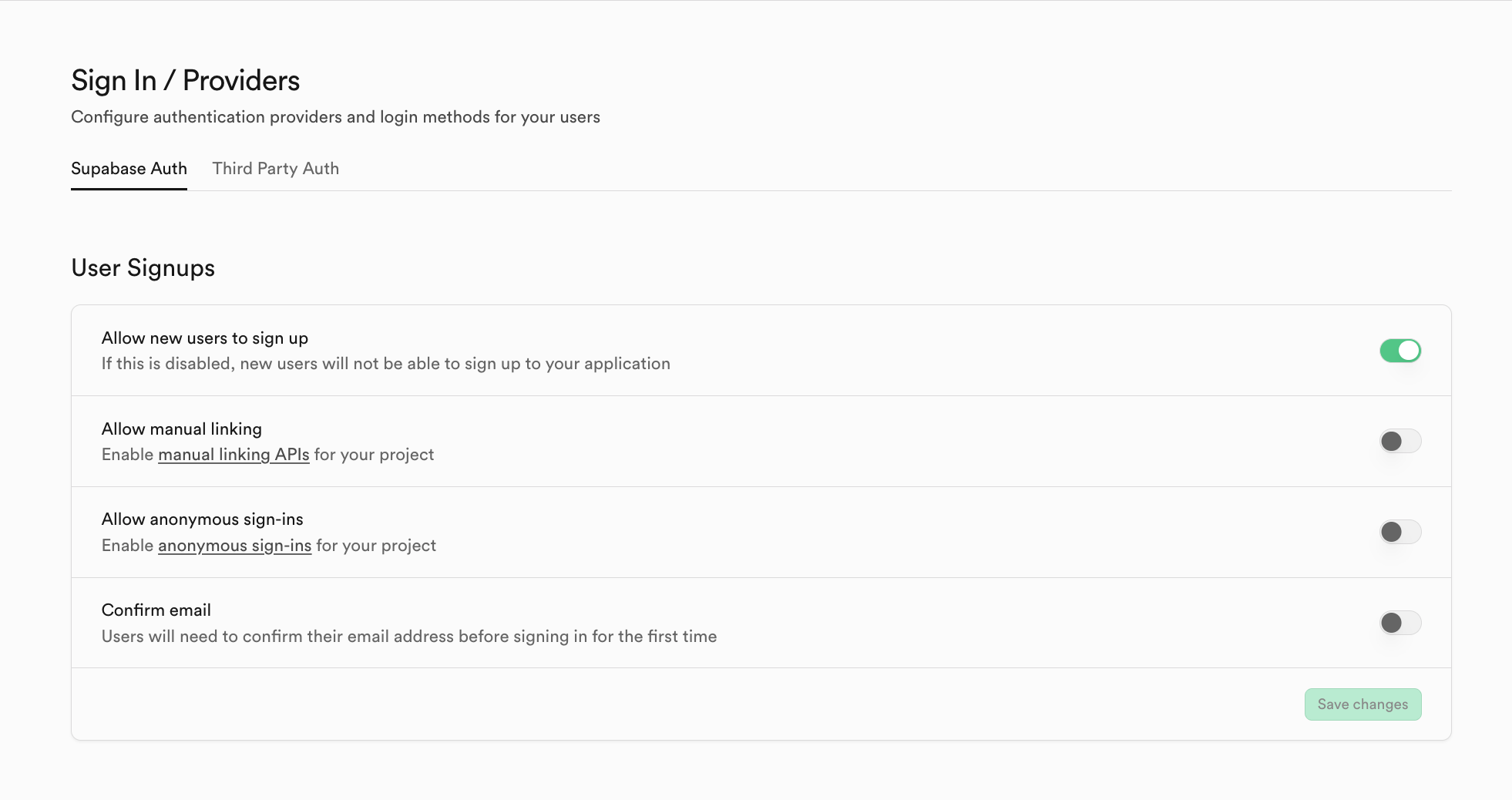
如果你想切換非 Supabase 的其他 auth 系統服務商,你可以點擊 Third Party Auth,比如此處就使用 Clerk 作為第三方的系統服務商。
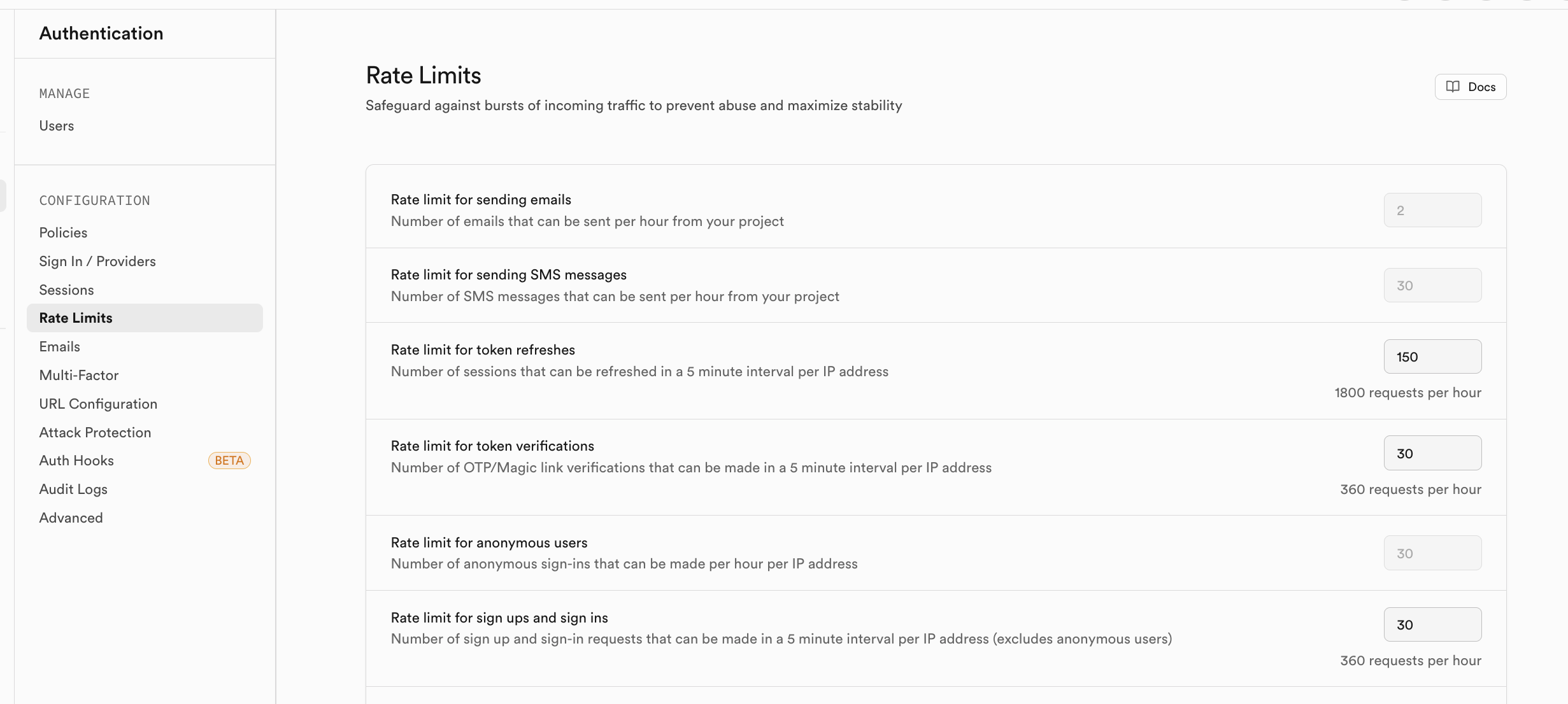
如果你擔心註冊用戶在短期內訪問量過大,你可以在 Rate Limits 中啟用對應的流量限制策略:
存儲
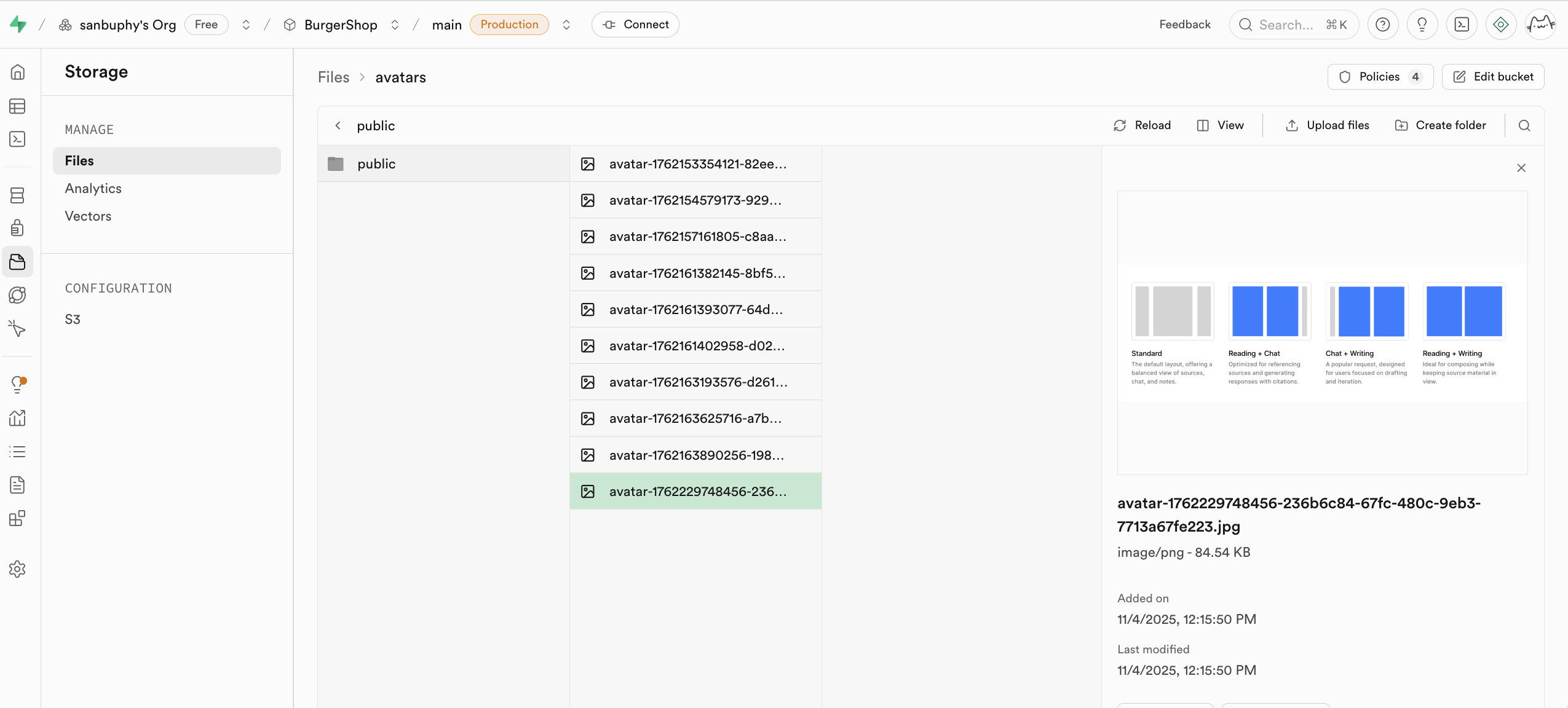
Storage 是 Supabase 的存儲系統,兼容 amazon cloud 的 s3 概念,可用於存儲任意類型的文件(如圖片、影片、文檔、音頻等),並提供訪問權限管理(公開或私有)和下載鏈接獲取(永久鏈接或臨時鏈接),你能夠很方便在應用中對用戶涉及到的文件內容進行上傳與下載管理,並與 Supabase 的認證系統無縫集成,實現精細化的訪問控制。
我們將會在本節課的進階 project 中講解 storage 的具體用法。
如果你想使用 S3 的相關協議進行操作,可以直接使用對應的配置:
Amazon Cloud(亞馬遜雲服務,簡稱 AWS)是亞馬遜提供的雲計算平臺(就像一個大型的網路機房,你可以按需租用計算和存儲資源)。S3(Simple Storage Service)是 AWS 裡專門用來存儲文件的服務(類似一個無限大的網盤,可以存圖片、影片、備份等各種文件),它是目前最流行的對象存儲服務,已經成為了事實上的行業標準。
**為什麼要做成 S3 兼容 **API** ** ? :S3 已經存在近 20 年,市面上有大量現成的工具、SDK 和文檔,兼容 S3 意味著你可以直接用這些資源,不用從頭開始製作各類相關工具,能夠快速滿足業務上線的需求。
邊緣函數
如果你不想部署後端,但是想使用資料庫和函數操作,你可以使用 Edge Functions 構建無需自建服務器的後端核心能力,它是 Supabase 提供的全球分佈式服務端函數。簡單來說,它讓你無需購買和管理自己的後端服務器,就能直接編寫並部署在雲端的後端程式碼。這些函數部署在全球網路的邊緣節點上,會自動在離你的用戶最近的位置運行,從而大幅降低網路延遲,提供極致的響應速度。你可以在 Supabase 的儀表盤中直接創建、編輯和部署,整個開發流程非常便捷。
Edge Functions 的一個核心用途是充當安全的中間層,保護你的敏感資訊和鑑權密鑰。在前端程式碼中直接調用第三方服務(如 OpenAI、Stripe)會暴露你的 API Key,帶來極大的安全風險。通過 Edge Functions,你的前端應用只與你的 supabase 函數通信,所有秘密只在 supabase 中保管。
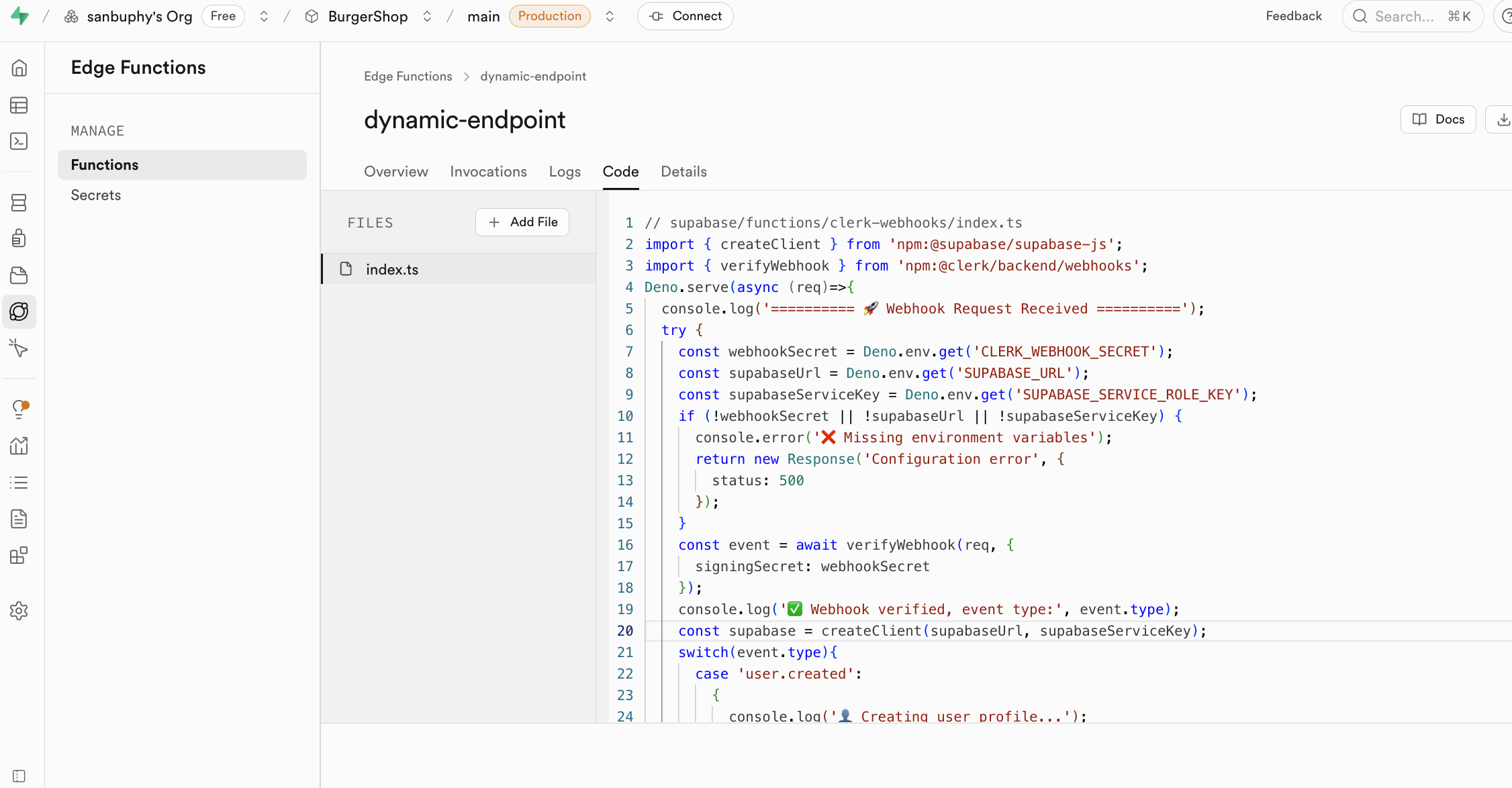
Edge Functions 的函數使用 secrets 中暴露的密鑰作為環境變量,通過 Deno.env.get 加載,從而實現第三方服務的調用。這樣一來,敏感密鑰就永遠不會暴露在客戶端(你的瀏覽器),徹底杜絕了被盜用的風險。
請求 Supabase Edge Function 時,需在請求頭攜帶對應的 Supabase 密鑰,下面是一個極簡示例:
// 核心配置(替換為你的實際資訊)
const projectId = "你的 Supabase 項目ID";
const functionName = "目標 Edge Function 名稱";
const supabaseKey = "Supabase anon_key";
// 調用函數
async function callEdgeFunction() {
const url = `https://${projectId}.supabase.co/functions/v1/${functionName}`;
try {
const response = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${supabaseKey}` // 關鍵:攜帶密鑰完成認證
},
body: JSON.stringify({ order_id: "123", action: "refund" }) // 自定義請求資料
});
const result = await response.json();
console.log("調用成功:", result);
} catch (error) {
console.error("調用失敗:", error.message);
}
}
// 執行調用
callEdgeFunction();此外,Edge Functions 與 Supabase 的用戶認證系統無縫集成。當已登錄的用戶調用一個函數時,其身份資訊會傳遞給函數。這使得你可以在函數內部輕鬆識別當前用戶,並根據其身份執行權限控制。更重要的是,函數在操作資料庫時會自動遵循你設置好的行級安全策略(Row Level Security),確保用戶只能訪問和修改他們有權操作的資料,讓構建安全的多用戶應用變得簡單。
Edge Functions 的應用場景非常廣泛,能夠處理各種後端任務。它們非常適合用來監聽來自第三方服務的 Webhook 事件(例如支付成功、程式碼提交等),並自動執行相應的資料處理邏輯。你也可以用它來發送郵件通知、生成 PDF 報告、創建自定義的 API 接口來封裝複雜的業務邏輯,或者執行任何你希望在服務端完成的計算任務,極大地擴展了你應用的能力。
具體到一個常見的例子:身份認證工具 Clerk 。Clerk 僅用於處理用戶登錄、註冊、資訊更新等認證相關操作,並不直接管理你的業務資料庫。如果你想要將這些認證動態同步到業務資料庫中,則需要通過觸發 Webhook 事件請求 Edge Functions 實現。Edge Functions 能夠監聽 Clerk 發出的 Webhook 信號,自動執行資料同步邏輯,讓 Supabase 資料庫中的用戶資訊與 Clerk 登錄狀態實時對齊,全程無需你部署獨立後端。
實時資料同步引擎
Realtime 是 Supabase 的實時資料同步引擎,它允許你的應用即時接收資料庫的變化通知,而無需反覆輪詢 API。當資料庫中的資料發生 INSERT、UPDATE 或 DELETE 操作時,Realtime 會通過 WebSocket 將這些變化實時推送給所有已連接的客戶端。這對於構建需要實時交互的應用至關重要。
Realtime 主要包含三大核心功能,覆蓋了絕大多數實時場景:
- Postgres Changes: 直接監聽資料庫表的變化。你可以精確地訂閱特定表、特定事件(增、刪、改),甚至可以根據篩選條件來接收通知,並與行級安全策略(Row Level Security)完美集成,確保用戶只能收到他們有權限查看的資料變更。
- Broadcast: 允許客戶端之間通過頻道(Channel)發送低延遲的臨時消息。這非常適合實現聊天室、實時光標追蹤、在線遊戲狀態同步等功能。
- Presence: 用於追蹤和同步在線用戶狀態。你可以用它來輕鬆實現“誰在線上”、“當前有X人正在查看”等功能,非常適合協作類應用。
我們會在後續的項目制學習中詳細介紹該部分的內容。
項目設置
Project Settings 是 Supabase 項目的高級配置部分,你可在此實現計算資源的深度調度,以及各類功能底層參數的精細化配置。
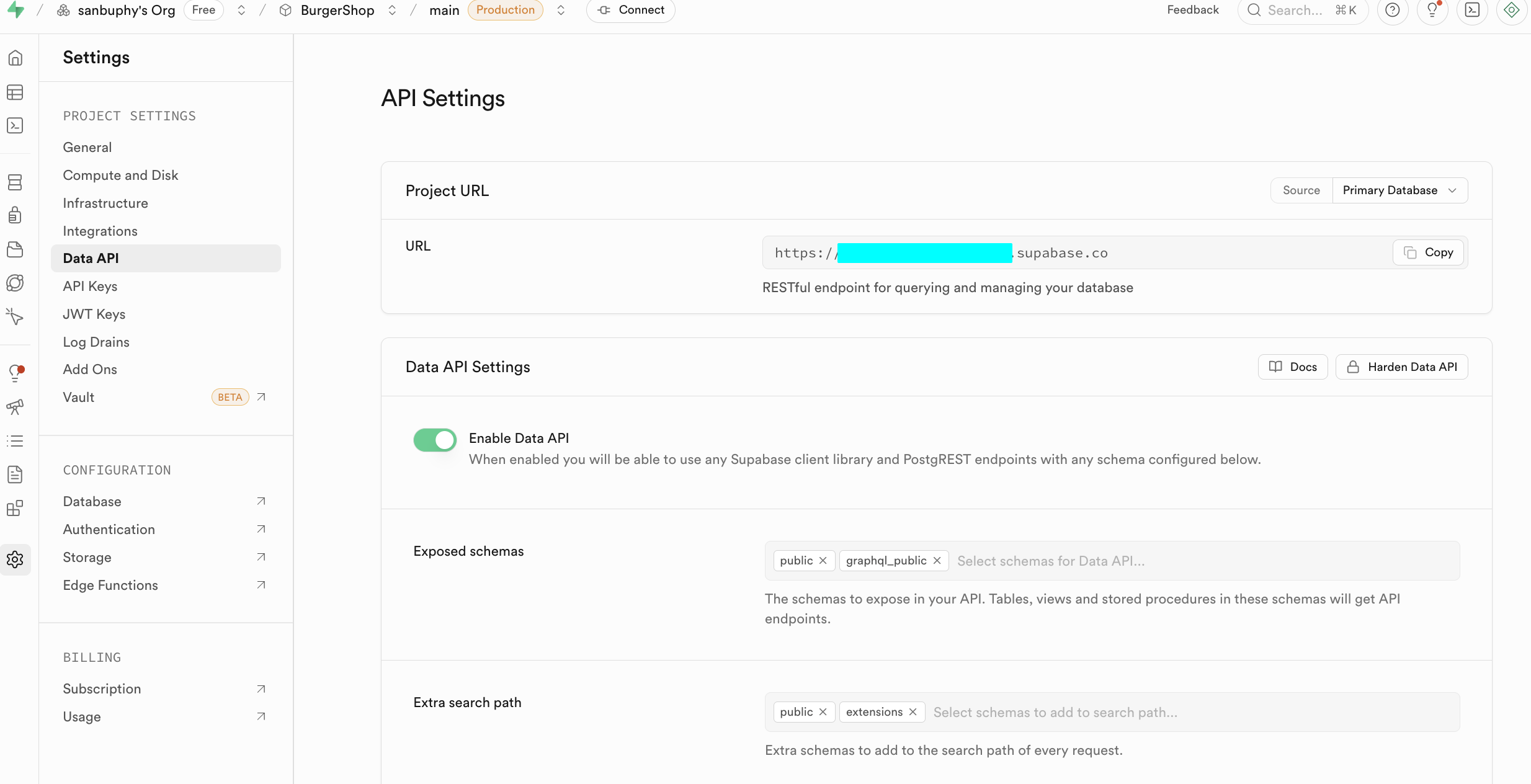
在入門階段,我們只需聚焦以下兩個核心板塊,一個是 Data API,我們在此可獲取關鍵的 “Supabase URL”, 它是形如 https://xxx.supabase.co 的 RESTful 端點,是所有資料查詢、新增、修改、刪除操作的 “入口地址”。前端或服務端需通過該 URL 初始化 Supabase 客戶端,建立與資料庫的連接。
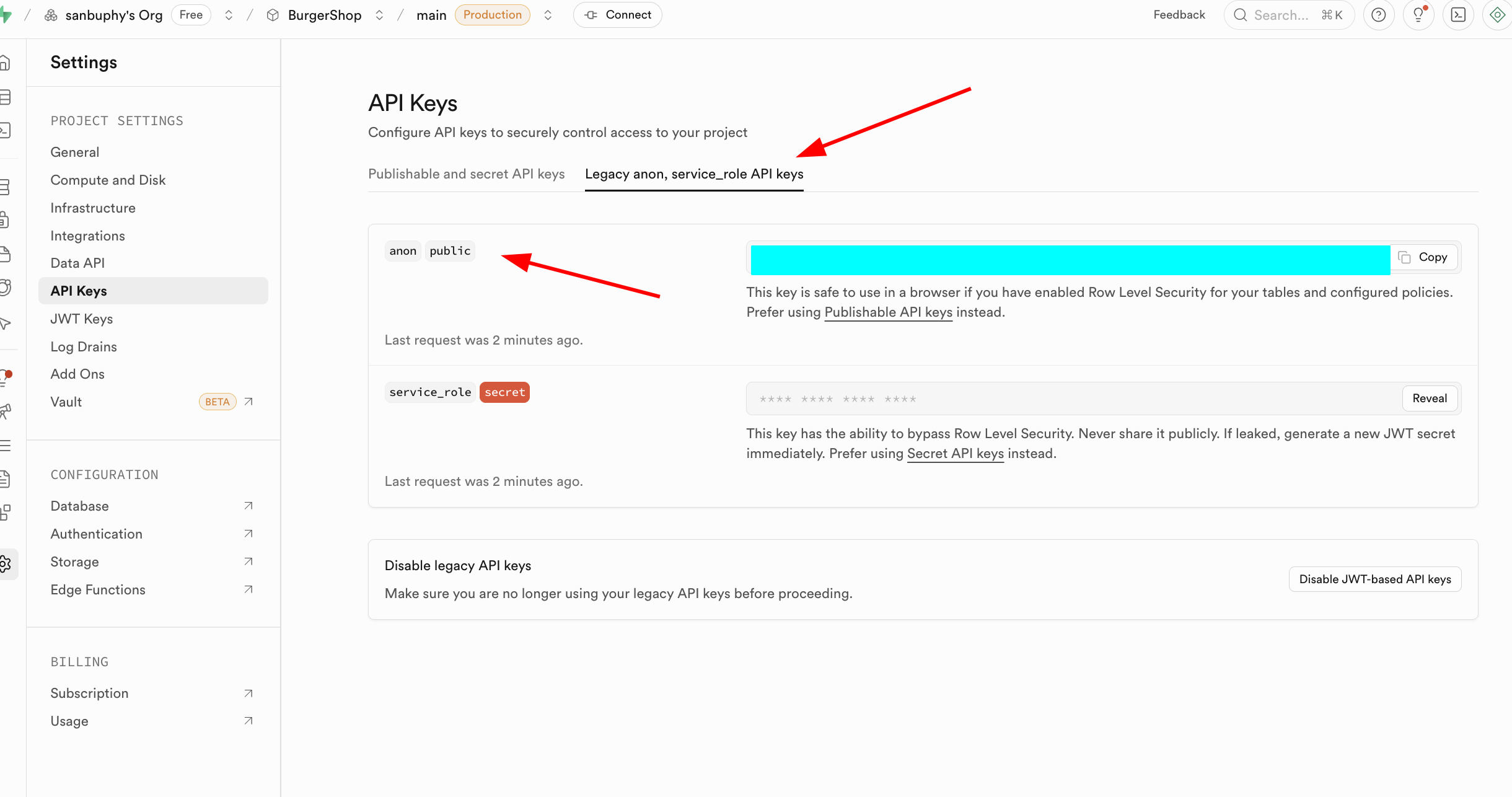
另一個重點是 API Keys,選擇 “Legacy anon, service_role API keys” 標籤頁,其中的 anon public 密鑰 是前端場景的重要身份憑證,它的權限被 RLS 嚴格限制,僅能訪問用戶被授權的資料。而 service_role 密鑰屬於 “服務端高權限密鑰”,具備繞過行級安全的能力,可執行批量資料操作、系統級配置等敏感操作。絕對禁止公開分享,若洩露需立即生成新密鑰並更新服務端配置。
其餘配置項在當前階段無需深究,待後續有進階使用需求時再逐一探索即可。
2.1 創建你的第一個 SQL 資料表
以上是 Supabase 的界面介紹,接下來我們將深入 Supabase 的核心資料庫的操作環節。
在 Supabase 中創建資料表,主要有以下兩種常用方式,你可以根據需求選擇:
- (推薦)藉助大語言模型生成適配 Supabase 的 SQL 語句,直接在 SQL Editor( 前文介紹的 SQL 語句執行器)中粘貼執行,高效快捷,我們會在下個部分環節重點說明這個操作過程。
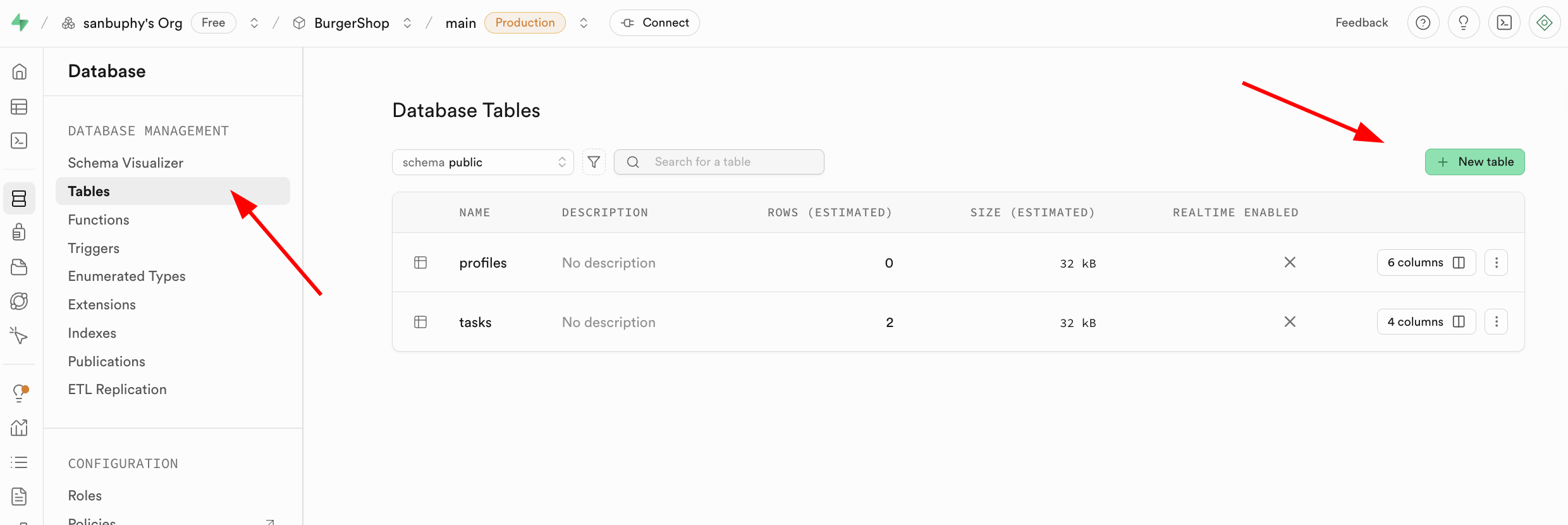
- 通過可視化操作創建:在左側側邊欄找到 Database 模塊,點擊進入後選中側邊欄的 Tables,在右側點擊 New table 按鈕,即可通過圖形化界面創建資料表。
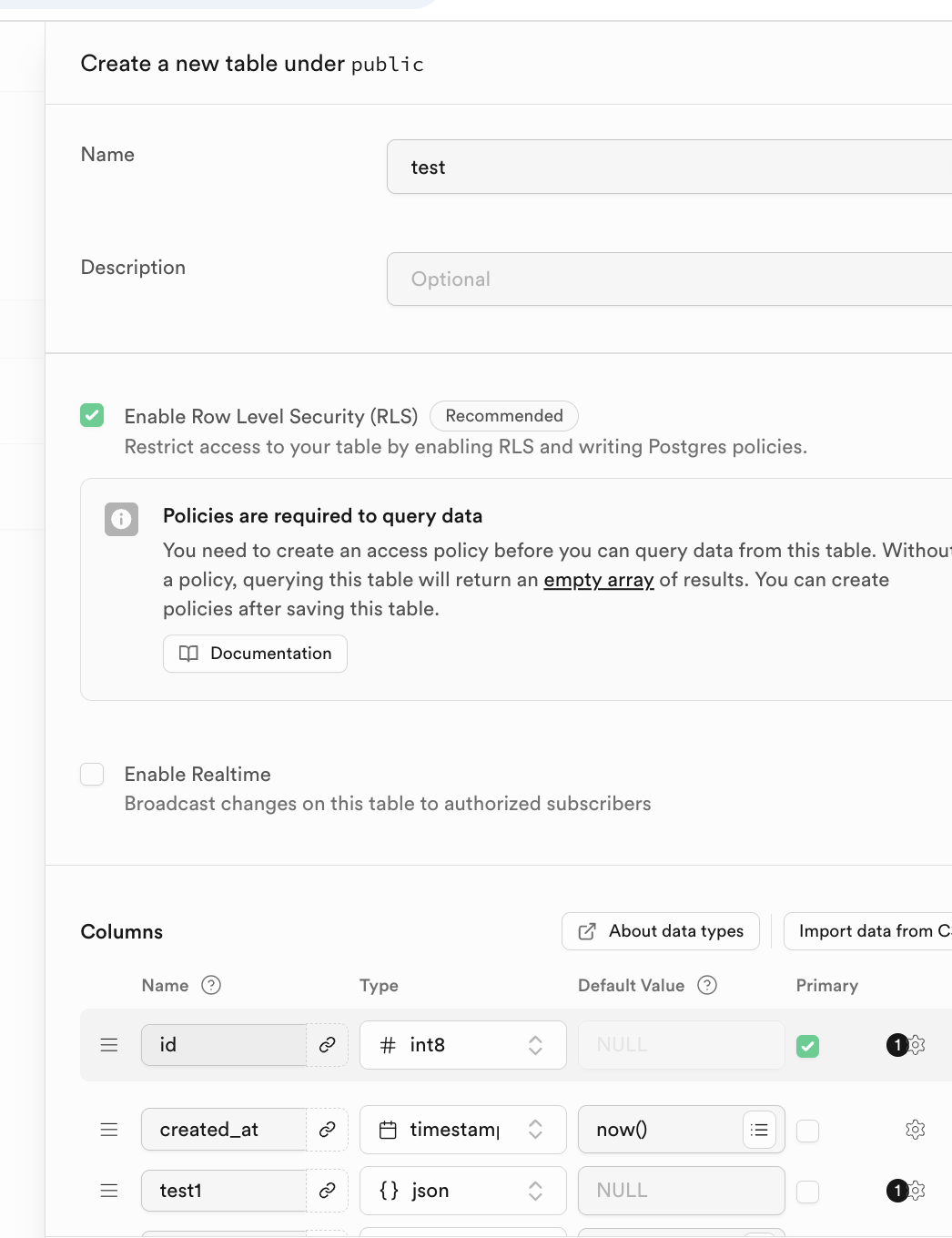
值得注意的是,對應資料表的名稱以及存儲的資料類型可在下方的 Columns 中指定。
對於關係資料庫,其中很重要的特點是表與表之間的關聯,你可以在下方找到 Foreign keys ,點擊創建相應的關聯關係:
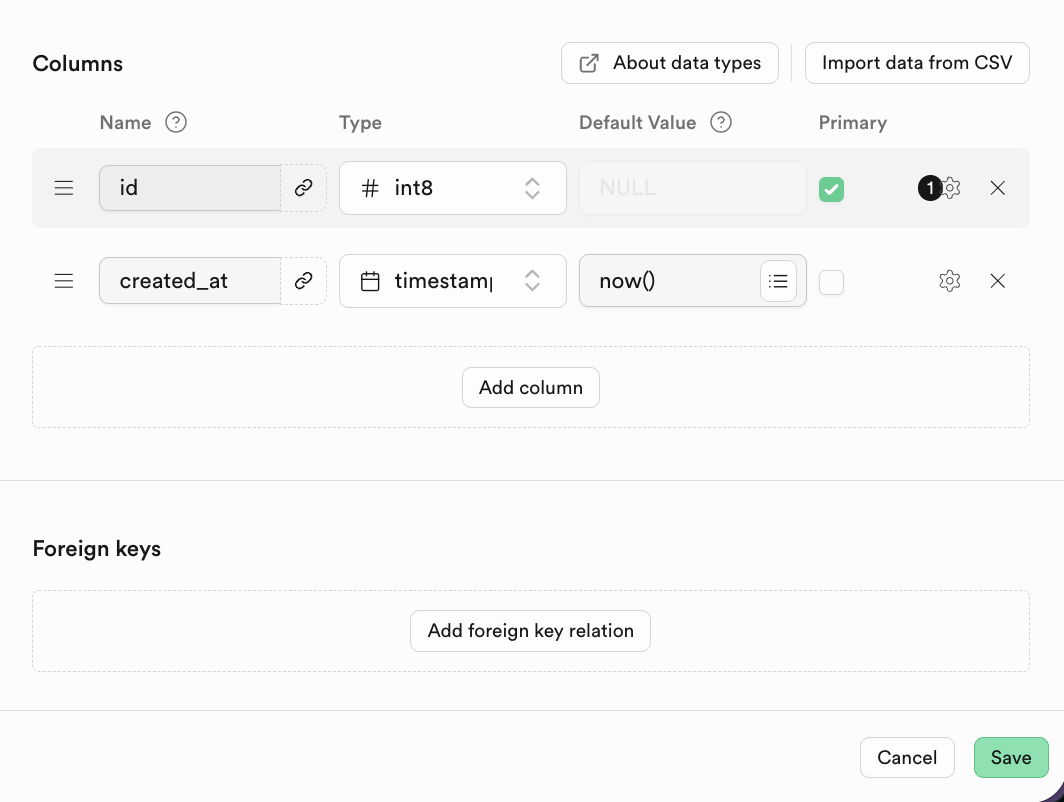
其中 Foreign keys 表達了表與表之間的關聯關係:一個或一組字段,它在當前表(子表)中的值,會引用另一張表(父表)中主鍵的值。
例如,在創建 學生表的時候,我們可以這樣定義外鍵:(所屬班級編號 這一列是一個外鍵。這個外鍵引用了 班級表 裡的 班級編號 這一列。)
CREATE TABLE 學生表 (
學生學號 INT PRIMARY KEY,
學生姓名 VARCHAR(50),
所屬班級編號 INT,
FOREIGN KEY (所屬班級編號) REFERENCES 班級表(班級編號)
);更具體舉例而言,我們可以可視化觀察對應的表的結構:
班級表: 這張表裡記錄了所有班級的資訊,每個班級都有一個獨一無二的班級編號。班級編號就是這張表的主鍵 (Primary Key),是每個班級的唯一身份證。
| 班級編號 | 班級名稱 |
|---|---|
| 101 | 一年級一班 |
| 102 | 一年級二班 |
學生表: 這張表記錄了所有學生的資訊。每個學生都屬於一個特定的班級,對嗎?那麼我們怎麼知道哪個學生在哪個班級呢?
我們可以在學生表裡增加一列,叫做 所屬班級編號。
| 學生學號 | 學生姓名 | 所屬班級編號 |
|---|---|---|
| 2024001 | 張三 | 101 |
| 2024002 | 李四 | 102 |
| 2024003 | 王五 | 101 |
在該例子中,學生表中的 所屬班級編號 列就是外鍵 (Foreign Key)。
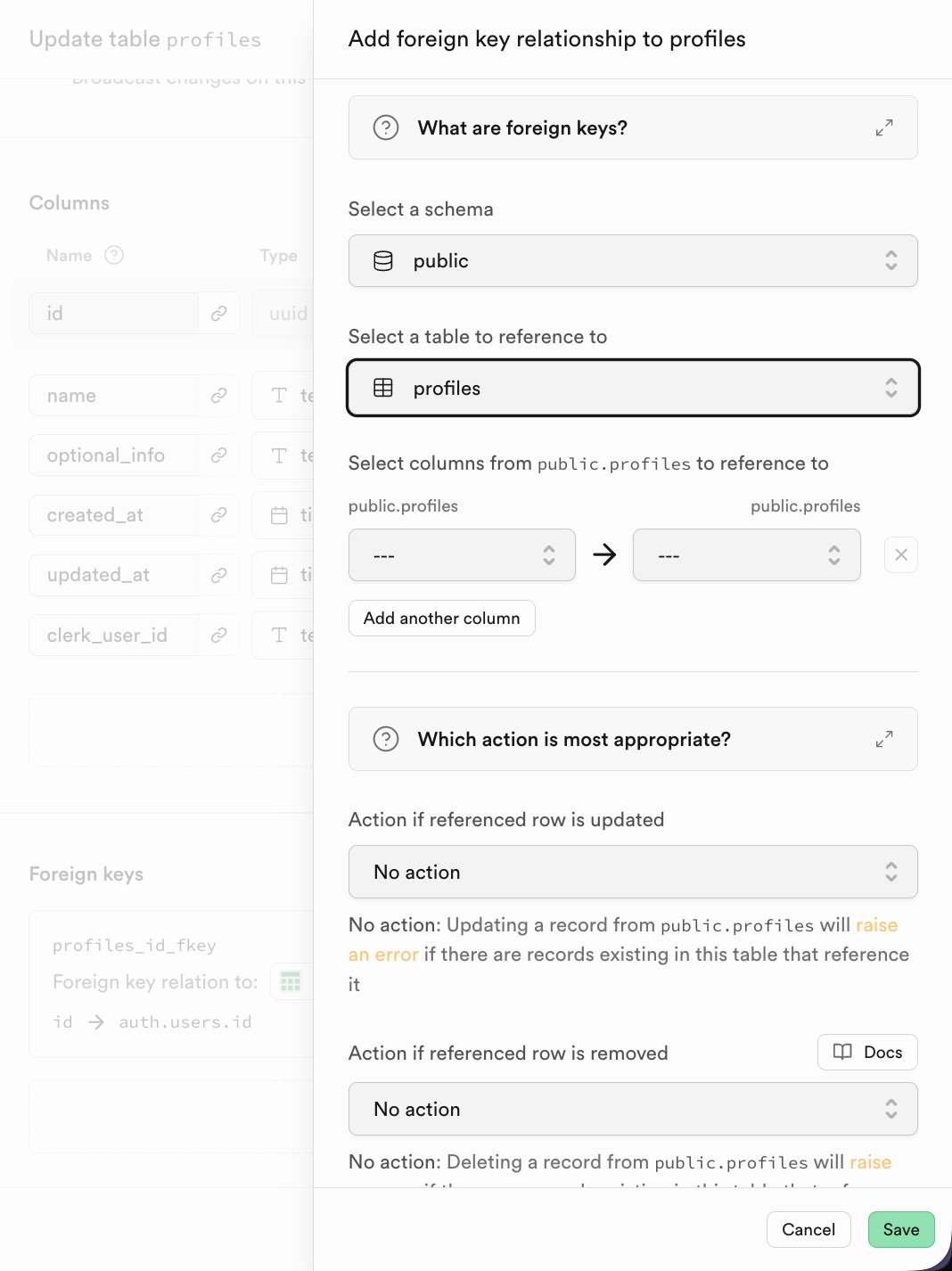
在 Supabse 中,點擊添加 Foreign Key 後,你可直接選擇進行關聯表對應列的選取
2.3 SQL Editor 簡介與資料庫基本操作
接下來我們將分步執行一系列 SQL 腳本,熟悉常見的 SQL 中的增刪查改操作。你可以將每個步驟的程式碼複製到 SQL Editor 中,執行並觀察結果。
你可以在該目錄下獲得所有的測試 SQL 文件:
https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos/tree/main/apps/sql-examples
2.3.1 CREATE - 創建表結構
CREATE TABLE 語句用於為新表定義模式(Schema),包括其列(Columns)、對應的資料類型(Data Types)以及任何約束(Constraints),簡單理解是創建了一個資料表。
-- Step 1: Create the 'orders' table
-- This file is fully independent and creates a sample table for later steps.
CREATE TABLE IF NOT EXISTS orders (
id serial PRIMARY KEY,
user_id int NOT NULL, -- User ID
status text NOT NULL, -- Order status (e.g. paid, pending)
amount numeric(10, 2) NOT NULL, -- Order total amount
details jsonb, -- Item and extra details as JSON
placed_at timestamptz DEFAULT now(), -- Order creation time
is_paid boolean DEFAULT false -- Paid flag
);
-- Expected Output:
-- Orders table created if it did not exist.
-- No data inserted. (Querying returns zero rows for now.)
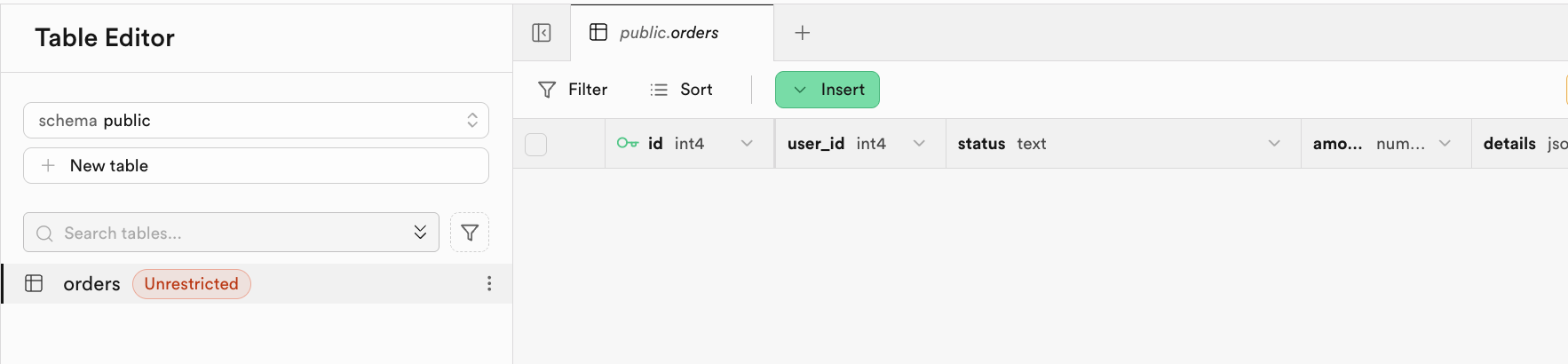
-- If table already exists, no error occurs.成功執行後,系統將提示腳本已完成。你可以在 Table Editor 中看到對應的表被創建完成:
2.3.2 INSERT - 填充初始資料
表結構創建完畢後,下一步是使用 INSERT INTO 語句向表中添加資料行。
-- Step 2: Insert initial rows into the orders table
-- Provides realistic, varied data for demo/testing. All values are self-contained.
INSERT INTO orders (user_id, status, amount, details, placed_at, is_paid) VALUES
(2001, 'pending', 23.50, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '2 days', false),
(2002, 'paid', 50.00, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":2,"price":5.00}]}', now() - interval '1 day', true),
(2003, 'cancelled', 15.00, '{"items":[{"sku":"FRY001","name":"French Fries","qty":3,"price":5.00}], "reason":"Not available"}', now() - interval '45 days', false),
(2004, 'paid', 22.98, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":2,"price":9.99}], "promo":"SUMMER22"}', now() - interval '10 days', true),
(2005, 'pending', 18.75, '{"items":[{"sku":"SAL001","name":"Salad","qty":1,"price":6.75},{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00}]}', now() - interval '7 hours', false),
(2006, 'paid', 8.00, '{"items":[{"sku":"DRK002","name":"Cola","qty":2,"price":4.00}]}', now() - interval '3 hours', true),
(2007, 'refunded', 14.50, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99},{"sku":"FRY001","name":"French Fries","qty":1,"price":4.51}], "refund_reason":"Late delivery"}', now() - interval '15 days', false),
(2008, 'paid', 26.99, '{"items":[{"sku":"BGR002","name":"Chicken Burger","qty":2,"price":10.00},{"sku":"DRK001","name":"Lemonade","qty":1,"price":6.99}]}', now() - interval '12 days', true),
(2009, 'pending', 9.99, '{"items":[{"sku":"BGR003","name":"Veggie Burger","qty":1,"price":9.99}]}', now() - interval '30 minutes', false),
(2010, 'paid', 19.89, '{"items":[{"sku":"BGR001","name":"Beef Burger","qty":1,"price":12.00},{"sku":"DRK002","name":"Cola","qty":2,"price":3.95}]}', now() - interval '5 days', true),
(2011, 'cancelled', 0.00, '{"items":[], "reason":"User cancelled"}', now() - interval '2 days', false);
-- Expected Output:
-- After running this script, SELECT * FROM orders will show about 11 rows with varied user_id, status, amount, details (JSON), placed_at, and is_paid fields.
-- For example:
-- | id | user_id | status | amount | is_paid | placed_at |
-- |----|---------|-----------|--------|---------|---------------------|
-- | 1 | 2001 | pending | 23.50 | false | 2025-10-28 13:40:00Z|
-- | 2 | 2002 | paid | 50.00 | true | ... |
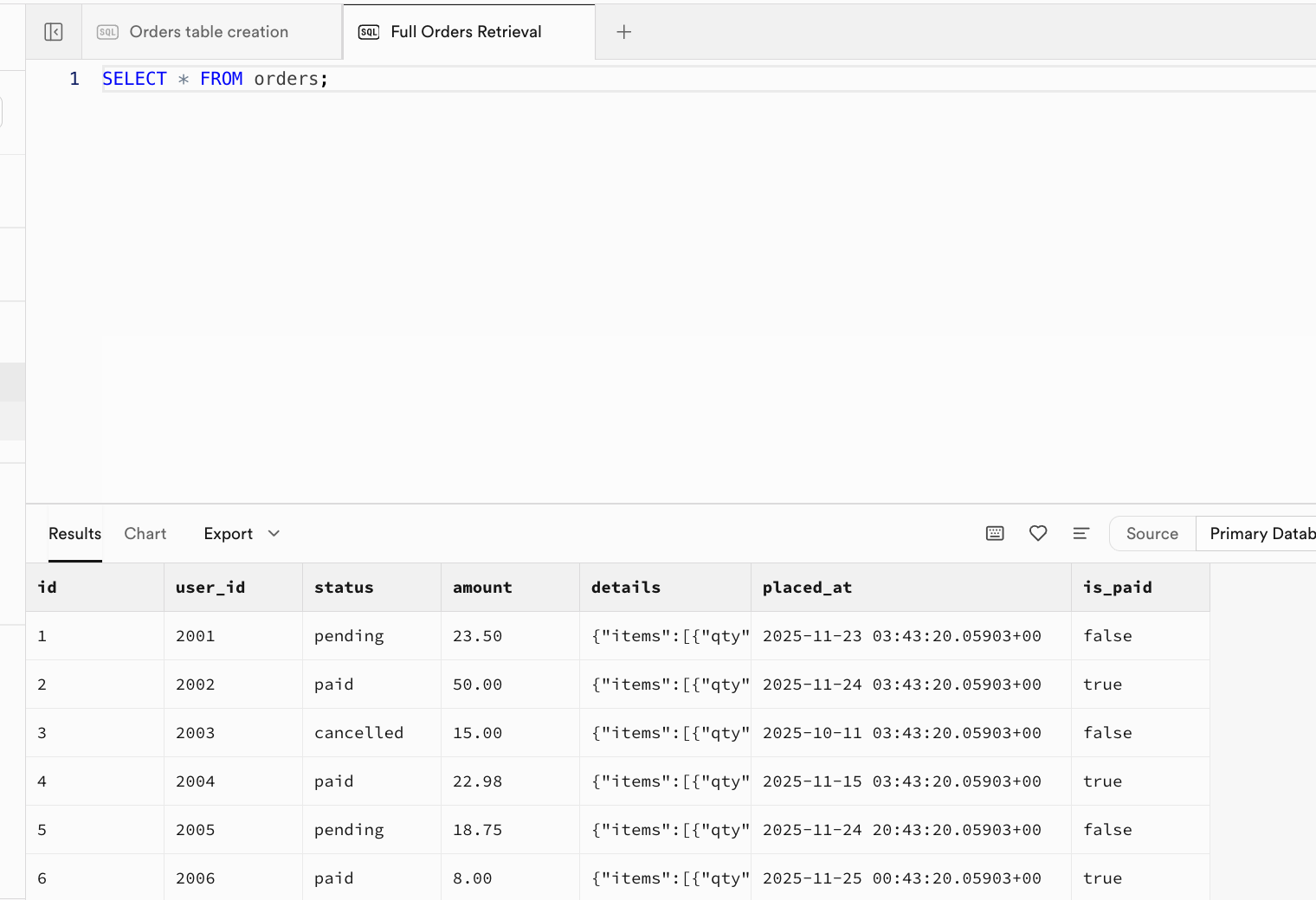
-- |... | ... | ... | ... | ... | ... |執行成功後,此時表中已經插入了原始資料,你可以進入到 Table Editor 界面刷新後看到結果,也可以直接在 SQL Editor 界面中新建窗口,執行查詢語句 SELECT * FROM orders;查看結果:
2.3.3 SELECT - 讀取與查詢資料
SELECT 語句用於從表中檢索資料。通過使用不同的子句,可以實現對資料的精確篩選、排序和格式化,我們可參考以下語句一步步執行查看結果:
-- Step 3: SELECT query examples for the orders table
-- Example 1: Select all fields for all orders
SELECT * FROM orders;
-- Expected Output: Returns all rows and fields. Columns: id, user_id, status, amount, details, placed_at, is_paid.
-- Example 2: Select only pending orders
SELECT id, user_id, amount FROM orders WHERE status = 'pending';
-- Expected Output: All rows with status 'pending'; columns: id, user_id, amount.
-- Example 3: Select specific fields and filter by payment status
SELECT id, status, is_paid, amount FROM orders WHERE is_paid = true;
-- Expected Output: All rows where is_paid is true; columns: id, status, is_paid, amount.
-- Example 4: Extract all item names from the details (JSON) for each order
SELECT id, details -> 'items' AS item_list FROM orders;
-- Expected Output: Each row shows id and an array from JSON with item details.- 示例 1: 返回
orders表中的所有行和列,與第二步的輸出類似。 - 示例 2: 僅返回狀態為 'pending' 的訂單,且只包含指定的列:
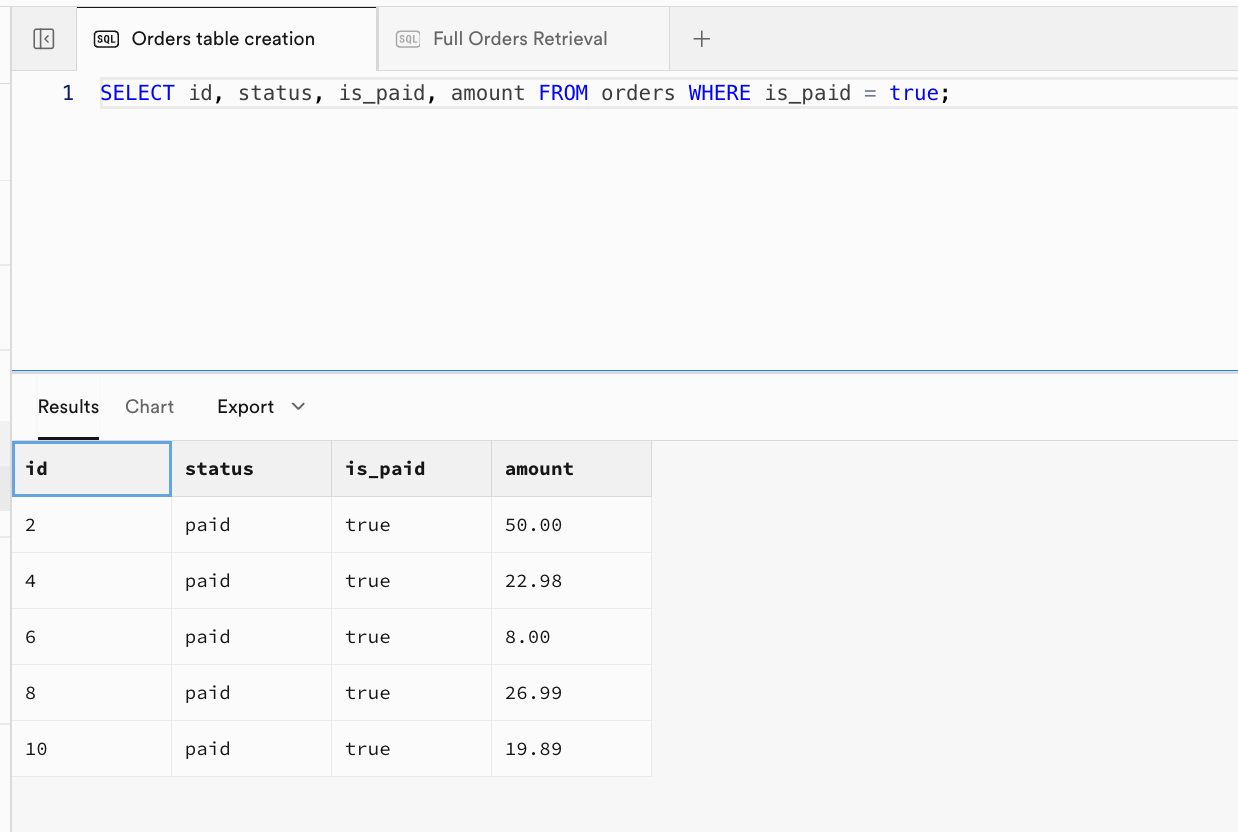
- 示例 3: 僅返回已支付的訂單,並顯示指定的列:
| id | status | is_paid | amount |
|---|---|---|---|
| 2 | paid | true | 50.00 |
| 4 | paid | true | 22.98 |
| 6 | paid | true | 8.00 |
| 8 | paid | true | 26.99 |
| 10 | paid | true | 19.89 |
- 示例 4: 返回每個訂單的
id和從details字段中提取的items數組:
| id | item_list |
|---|---|
| 1 | [{"qty":1,"sku":"BGR001","name":"Beef Burger","price":12}] |
| 2 | [{"qty":2,"sku":"BGR002","name":"Chicken Burger","price":10},{"qty":2,"sku":"DRK001","name":"Lemonade","price":5}] |
| 3 | [{"qty":3,"sku":"FRY001","name":"French Fries","price":5}] |
| ... | ... |
2.3.4 INSERT - 插入單條記錄
在 2.3.2 中,我們演示的是開頭時刻初始化批量插入資料,現在我們查看如何新增插入單條資料。
-- Step 4: INSERT a new order (single row)
-- Example: Add a new paid order for user 2012 with one Chicken Burger
INSERT INTO orders (user_id, status, amount, details, is_paid)
VALUES (
2012, 'paid', 9.99,
'{"items":[{"sku":"BGR002","name":"AIID Burger","qty":100,"price":1000}]}',
true
);
-- Expected Output:
-- Before (table fragment):
-- | id | user_id | status | amount | is_paid |
-- | ...| ... | ... | ... | ... |
--
-- After (last row):
-- | id | user_id | status | amount | is_paid |
-- | xx | 2012 | paid | 9.99 | true |
-- (where xx = next serial value)此時再用 SELECT * FROM orders; 對資料進行查詢,我們可以看到 orders 表成功從 11 個資料變成了 12 個資料。
2.3.5 UPDATE - 修改現有資料
在實際工作中,我們需要對資料表進行頻繁資料更新,我們能夠用 UPDATE 語句修改表中已存在的記錄。
-- Step 5: UPDATE example
-- Example: Mark order with id=1 as paid and update its status
UPDATE orders SET status = 'paid', is_paid = true WHERE id = 1;
-- Expected Output:
-- Before (row with id=1):
-- | id | status | is_paid |
-- | 1 | pending | false |
-- After (row with id=1):
-- | id | status | is_paid |
-- | 1 | paid | true |
-- All other rows remain unchanged.2.3.6 DELETE - 刪除資料
DELETE 語句可用於從表中移除記錄,並結合條件對指定部分的資料進行修改。
-- Step 6: DELETE example
-- Example: Delete orders older than 2 days to clean up old data
DELETE FROM orders WHERE placed_at < now() - interval '2 days';
-- Expected Output:
-- Before (filtered for affected rows):
-- | id | status | placed_at |
-- | 3 | shipped | 2025-10-13 ... | <-- will be deleted
--
-- After:
-- No such rows remain. SELECT * FROM orders WHERE placed_at < now()-interval '2 days' yields zero rows.
-- Other rows in orders table are unaffected.執行前,你可先執行 SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days'; 進行資料表篩選結果的查看。當運行 DELETE 命令後,再次執行相同的 SELECT 查詢 SELECT id, status, placed_at FROM orders WHERE placed_at < now() - interval '2 days';,將返回一個空的結果,表明這些行已被成功刪除。
2.4 行級安全
在學習了資料庫的基本操作後,我們需要進一步深入一個保障資料安全的核心概念 ——RLS(行級安全,Row Level Security)。
不妨先思考一個實際場景中的關鍵問題:如何實現資料的 “隔離訪問”?比如,只允許用戶 A 查看自己的資料,而無法看到用戶 B 的資訊;再比如,即便某角色擁有資料庫的訪問權限,如何避免其誤操作或洩露其他用戶的敏感資料?
RLS 正是為解決這類資料安全與隔離需求而生。它允許開發者為資料庫表定義精細化的安全策略,根據用戶的身份資訊(如用戶 ID、角色權限等),精確控制哪些用戶能訪問、修改表中的哪些行資料。 舉個典型示例:對於訂單表(orders),我們可以定義這樣一條 RLS 策略 ——“僅當 orders 表中某條記錄的 user_id 列,與當前登錄用戶的 ID 完全一致時,該用戶才能查詢到這條訂單資料”,從而實現 “用戶只能看自己的訂單” 的核心需求。
當你為某張表啟用 RLS後,該表的所有資料操作請求(包括 SELECT 查詢、INSERT 新增、UPDATE 修改、DELETE 刪除)都會觸發 RLS 校驗:必須通過至少一條安全策略的檢查,操作才能執行。若不存在允許該操作的策略,或請求未滿足任何策略的條件,資料庫會直接拒絕此次操作,從底層阻斷非授權訪問。
在 Supabase 中,RLS 與用戶認證系統深度綁定,使用起來更為便捷。Supabase 提供了一個專用函數 auth.uid(),它能直接返回 “當前發起請求的已登錄用戶” 的唯一 ID(格式為 UUID)。藉助這個函數,我們可以輕鬆編寫策略,實現 “資料行與用戶身份” 的精準關聯(比如前文提到的 “訂單 user_id 匹配當前用戶 ID”)。
啟用 RLS 策略的方式很靈活,你可以在 Supabase 資料庫管理界面中的 “RLS” 按鈕,直接配置並啟用策略:
主動配置難免顯得麻煩,通常,我們在資料表語句創建、初始化的時候就會自動考慮植入對應的 RLS 策略。我們只需在 SQL Editor 中執行類似如下語句,即可自動開啟對應資料表的行級安全策略。

3. 第一個 SQL 應用
掌握了資料庫基礎操作與RLS核心邏輯,我們終於進入本次教程的實踐環節。漫長的學習鋪墊是為了讓後續“從0到1搭建應用”的過程更清晰。接下來,我們將以“漢堡店訂單管理”為場景,手把手演示Supabase的常見操作:從應用與Supabase的關聯配置,到資料庫與登錄功能的集成,逐步學習不同操作邏輯。
3.1 克隆並運行 Supabase 示例項目
要開展實操,首先需要獲取配套的演示程式碼倉庫。你可以讓 Trae 或 Claude Code 協助 git clone 以下倉庫:https://github.com/THU-SIGS-AIID/Project5-Supabase-Demos
若已配置 SSH 密鑰,建議使用 SSH 地址進行 clone(git@github.com:THU-SIGS-AIID/Project5-Supabase-Demos.git)以提升安全性;若 SSH 或 HTTPS 連接遇到網路問題,可以直接點擊倉庫頁面的 “Download ZIP”,獲取壓縮包後解壓即可看到完整程式碼。
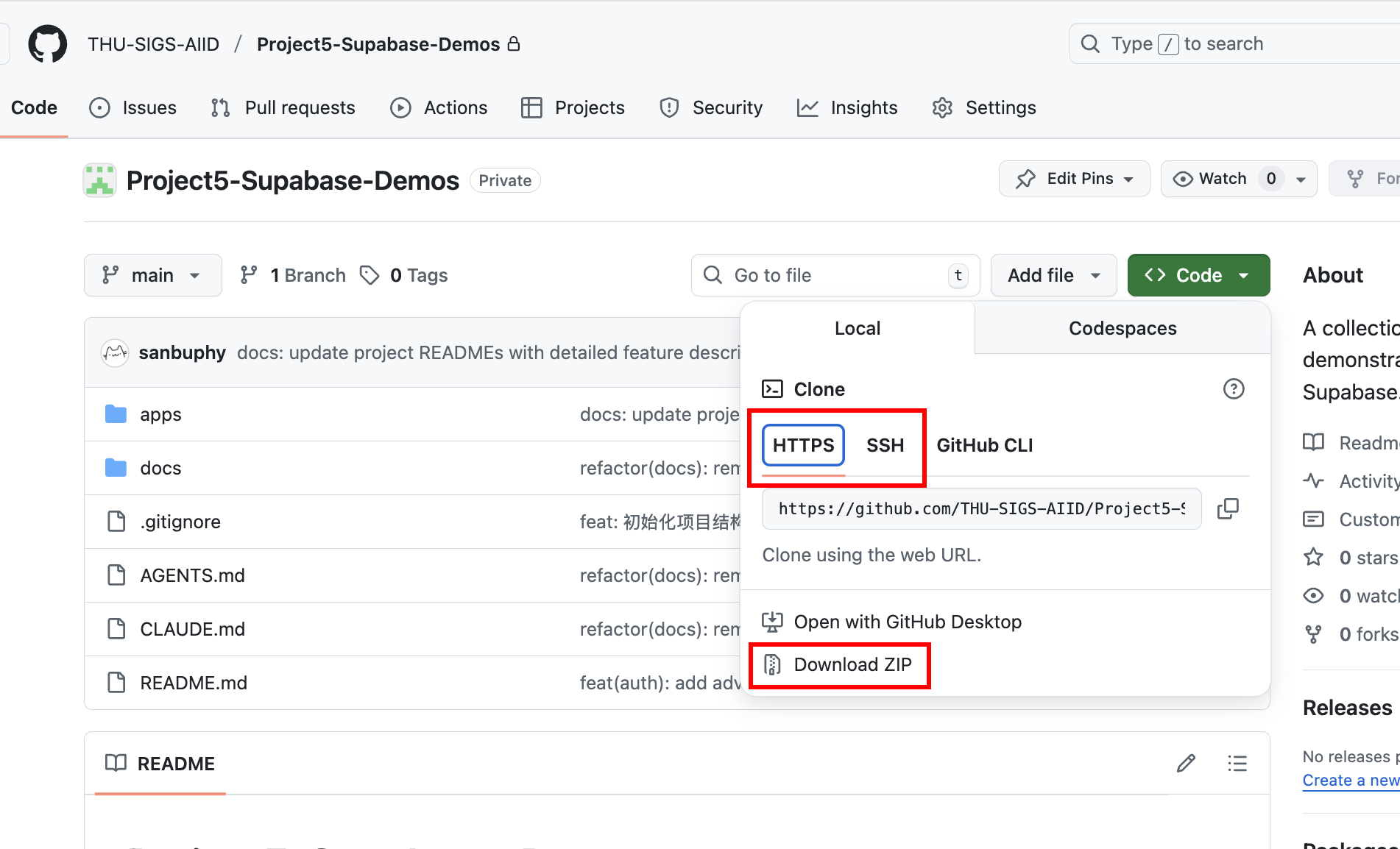
Clone 後,你同樣可以讓 Trae 或者是 Claude Code 幫你啟動項目,例如直接在 Agent 界面中說明: 幫我直接啟動這個項目裡面的 project 1 ,或者複製對應想啟動 project 的絕對路徑,粘貼給大模型讓大模型直接啟動。
3.2 項目1 - 漢堡店菜單增刪改查
接下來進入實操環節 —— 以 project-burger-shop-menu-crud-1 為例,我們將學習如何通過 SQL 腳本一鍵初始化 Supabase 資料庫,並完成本地項目與 Supabase 資料庫的關聯配置,讓前端能正常讀寫菜單資料。
使用腳本創建資料庫
首先,我們需要在 Supabase 中創建需要的資料表的相關內容。進入 Project1 項目目錄看到名為 scripts的文件夾,其中包含 1 個 init.sql資料庫腳本文件,它能幫我們自動完成所有資料庫相關資源的創建(包括表結構、初始資料等),之後我們會經常用到該文件進行資料庫中表的初始化。
......
-- ============================================================================
-- 2. Create Menu Items Table
-- ============================================================================
create table if not exists public.menu_items (
id uuid primary key default gen_random_uuid(),
name text not null,
description text,
category text check (category in ('burger','side','drink')) default 'burger',
price_cents int not null check (price_cents > 0),
available boolean default true,
emoji text,
created_at timestamptz not null default now(),
updated_at timestamptz not null default now()
);
-- Comments for documentation
comment on table public.menu_items is 'Burger shop menu items for CRUD demo';
comment on column public.menu_items.id is 'Unique identifier for each menu item';
comment on column public.menu_items.name is 'Display name of the menu item';
comment on column public.menu_items.description is 'Detailed description of the menu item';
comment on column public.menu_items.category is 'Category: burger, side, or drink';
comment on column public.menu_items.price_cents is 'Price in cents (integer) to avoid floating point issues';
comment on column public.menu_items.available is 'Whether the item is currently available for order';
comment on column public.menu_items.emoji is 'Optional emoji representation of the menu item';
comment on column public.menu_items.created_at is 'Timestamp when the item was created';
comment on column public.menu_items.updated_at is 'Timestamp when the item was last updated';
......在 SQL Editor 中執行初始化 sql 腳本後,即可在 Table Editor 中看見已創建的資料表。其中資料庫初始化程式碼具體執行邏輯如下:
- 創建 menu_items 表 :
- 這個表用於存儲漢堡店菜單中的所有項目。它包含了如 name (商品名), description (描述), price_cents (以美分為單位的價格,避免浮點數精度問題), category (分類) 和 available (是否可售) 等字段。這基本涵蓋了一個菜單項所需的所有資訊。
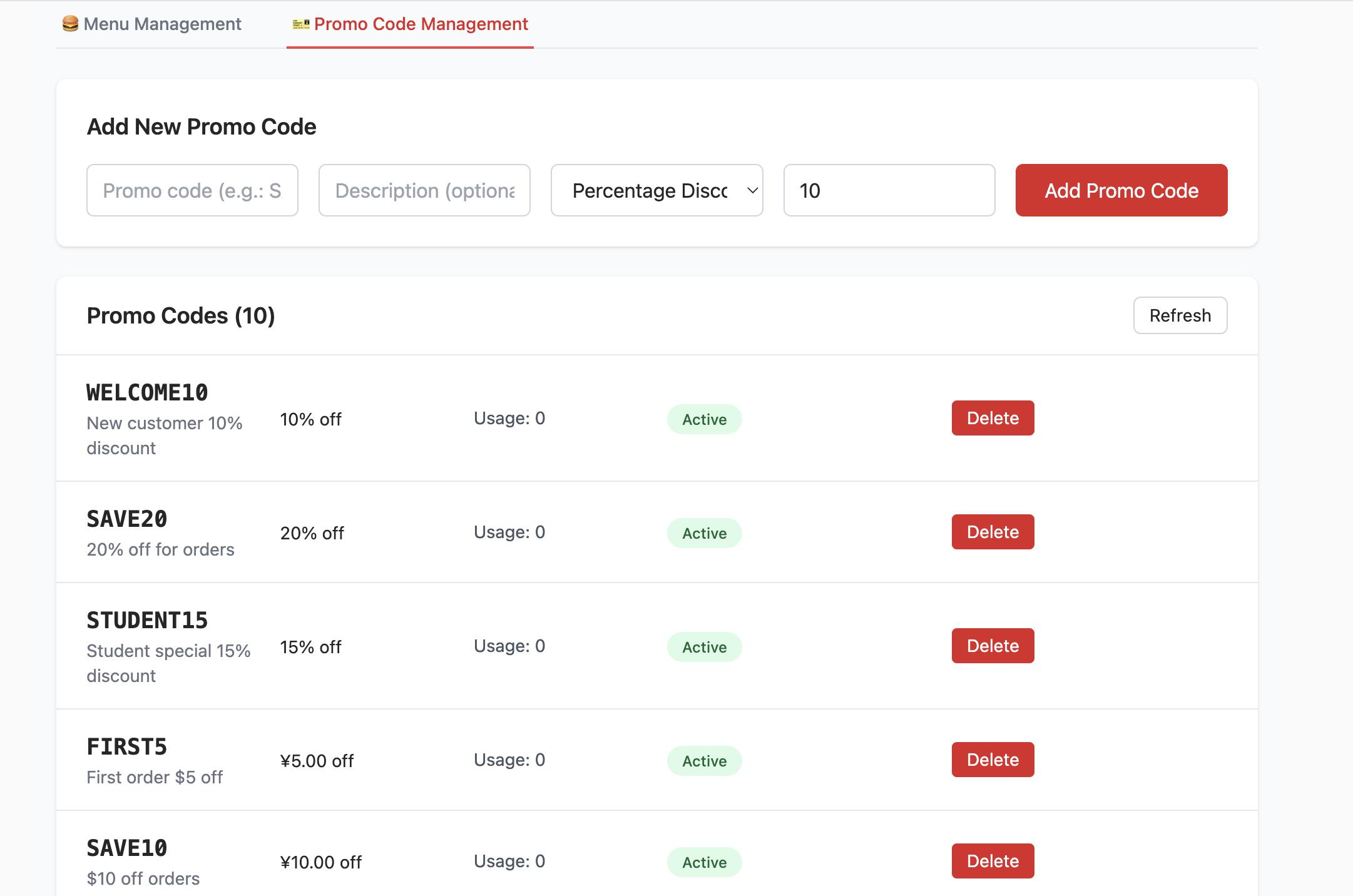
- 創建 promo_codes 表 :
- 此表用於管理促銷活動,例如折扣碼。它定義了 code (折扣碼), discount_type (折扣類型,如百分比或固定金額), discount_value (折扣數值) 等字段。
- 禁用行級安全 (Row Level Security - RLS) :
- 為了方便開發和測試,腳本中明確地禁用了 RLS。但結合我們之前學習的 RLS 核心邏輯:RLS 是 Supabase 保障資料安全的關鍵功能,能通過精細化策略控制 “誰能訪問 / 修改哪些資料”(比如只允許管理員編輯促銷碼,普通用戶只能查看菜單)。因此在生產環境中,必須開啟 RLS 並配置合理策略,從底層阻斷非授權訪問(如防止用戶惡意修改他人創建的菜單,或洩露促銷碼規則)。
- 插入種子資料 (Seed Data) :
- 為了讓前端項目啟動後就能看到真實的菜單與促銷資料(無需手動錄入測試資料),
init.sql腳本還會向menu_items和promo_codes表中插入 “種子資料”(即示例資料)。例如,你可以看到各種漢堡、小食、飲料以及多種多樣的折扣碼。
設置與資料庫的連接
資料庫準備完成,我們需要將這個前端項目與 Supabase 進行連接,從而正常讀取資料庫內的資料。我們需要將 Supabase 項目的 URL 和 anon key 寫到指定配置中,本項目提供了兩種靈活的配置方式:
- 通過環境變量配置
在項目根目錄創建一個 .env 文件,並填入你的 Supabase 憑證:
NEXT_PUBLIC_SUPABASE_URL=https://your-project.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=your-anon-key- 在項目頁面中直接設置
為了方便快速演示和切換不同的 Supabase 項目,首頁頁面右上角提供了一個 設置 按鈕。你可以點擊它,在彈出的模態框中直接輸入或粘貼 Supabase URL 和 anon key。
點擊 “Save” 後,這些資訊會用於動態創建 Supabase 客戶端實例,類似下列程式碼所示:
import { createClient, type SupabaseClient } from '@supabase/supabase-js';
// Optional client factory for demos: returns null when env is not set.
export function maybeCreateBrowserClient(): SupabaseClient | null {
const url = process.env.NEXT_PUBLIC_SUPABASE_URL;
const anon = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY;
if (!url || !anon) return null;
return createClient(url, anon);
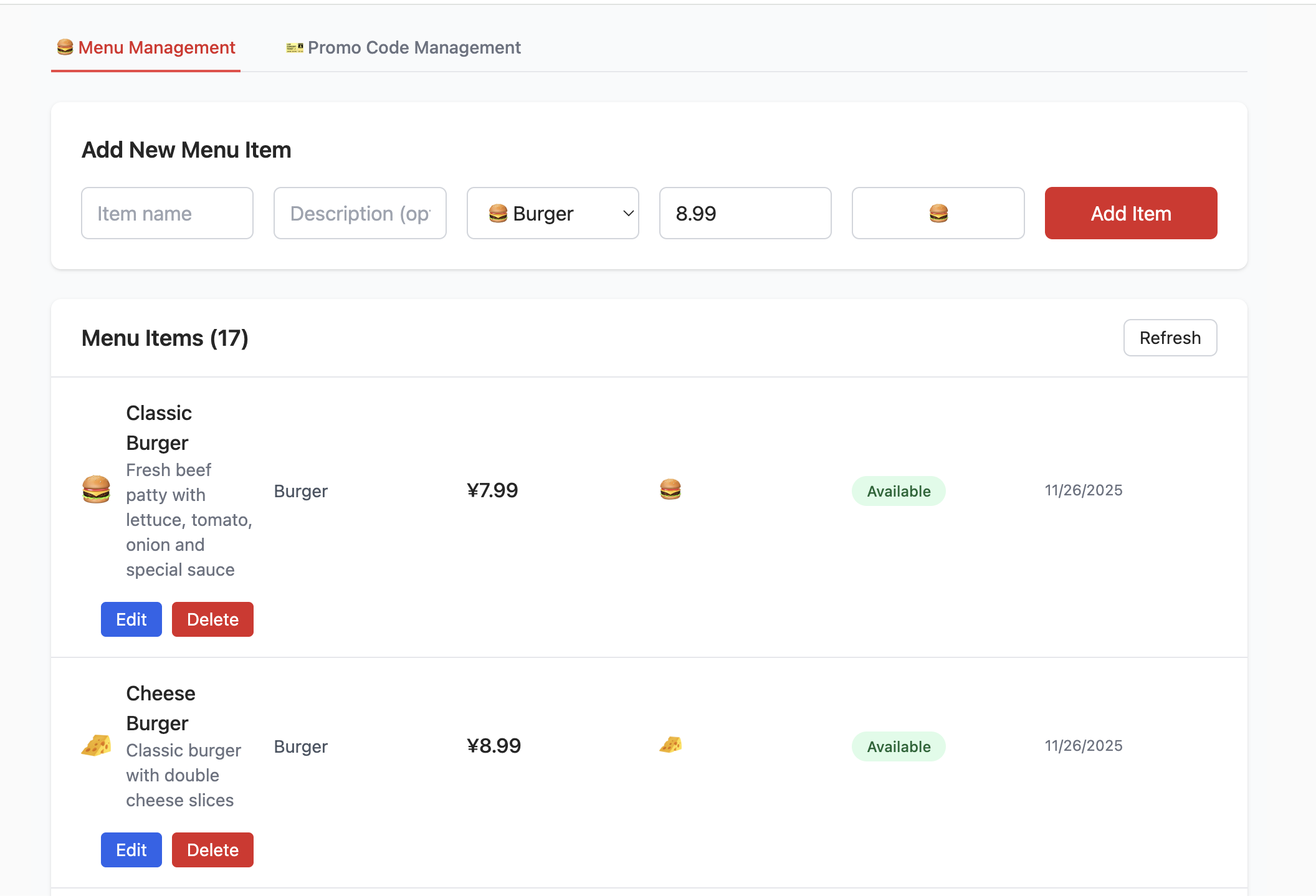
}創建完資料庫,填寫完對應的 Supabase Link 相關配置後,即可看到如下界面,你可以嘗試對商品進行增刪查改,並觀察 Supabase 中對應部分資料表的變化。
📚 作業
- 嘗試增加和刪除已有項目,在 Table Editor 中查看修改操作對資料表內容變動的影響。
3.4 項目2 - 漢堡店認證用戶
Project1 實現了 “菜單 CRUD + 資料庫連接” ,Project2 將引入更貼近真實業務的核心能力,用戶認證(Auth)與行級安全(RLS)權限管理。
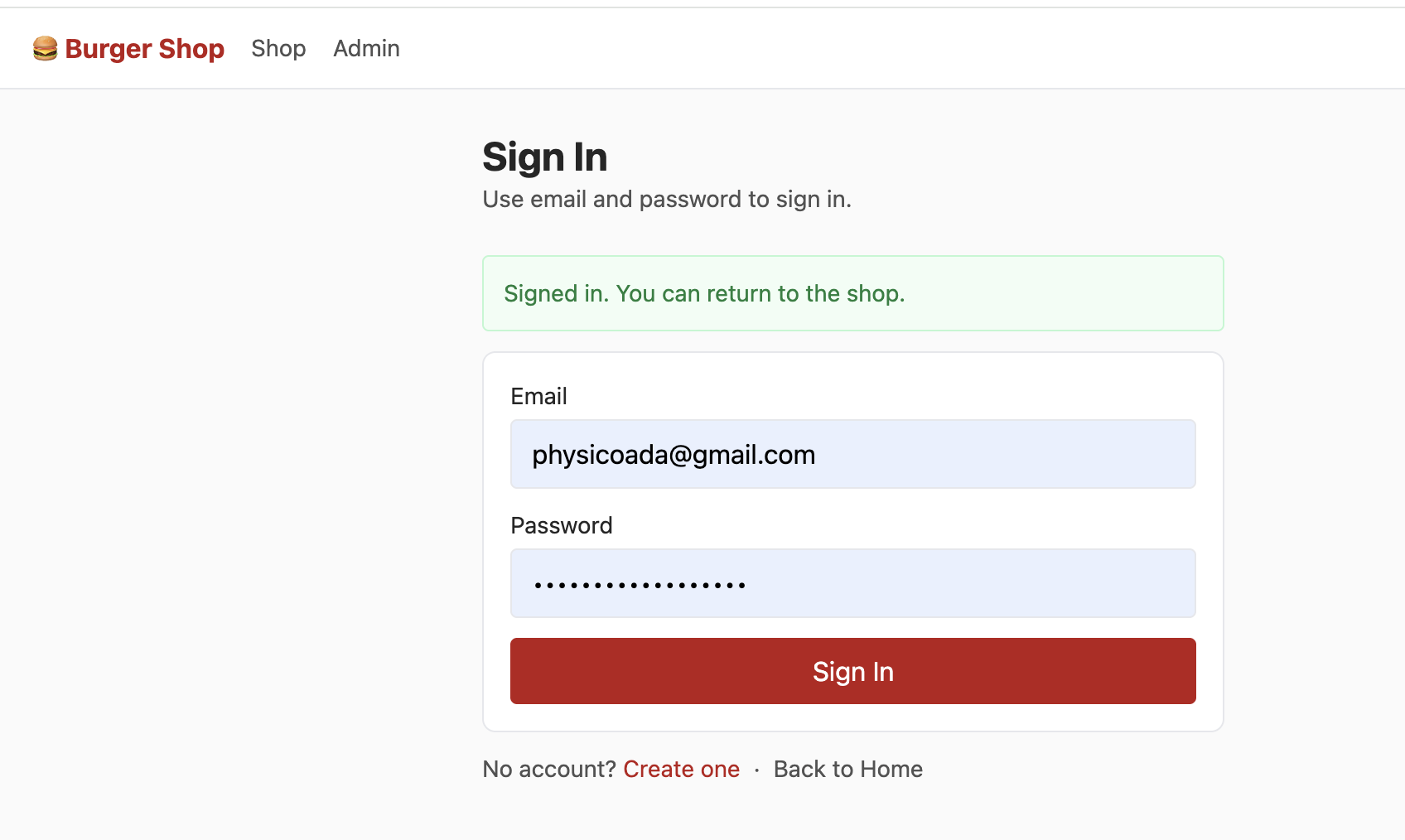
Project2 包含獨立的登錄頁,支持用戶通過「郵箱 + 密碼」的方式登錄。其核心邏輯是調用 Supabase Auth 提供的原生方法,快速實現認證流程,無需手動開發複雜的登錄校驗邏輯:
const { error: err } = await supabaseClient.auth.signUp({
email,
password,
options: {
data: {
full_name: fullName || null,
birthday: birthday || null,
avatar_url: avatarUrl || null
}
}
});
登錄成功後,Supabase 會自動為用戶創建一個會話(session),並在後續所有資料庫請求中自動攜帶認證資訊;通過 RLS 的作用,每個用戶根據對應的認證資訊只能看到自己的賬戶資訊(已購買項目、錢包剩餘額度),無法看到其他用戶的賬戶資訊,這就實現了不同用戶登錄後的資料隔離,每個人只能看到自己的內容。
和 Project 1 一樣,你需要先使用 init.sql 進行資料表的初始化(注:如果發現初始化出錯,請先在 Table Editor 中刪除已經創建的資料表,或者是直接刪除這個 Supabase Project, 重新新建一個 Project)
成功使用郵箱註冊賬戶、在郵箱確認註冊賬戶後,登錄後進入 Shop 界面即可看到如下內容:
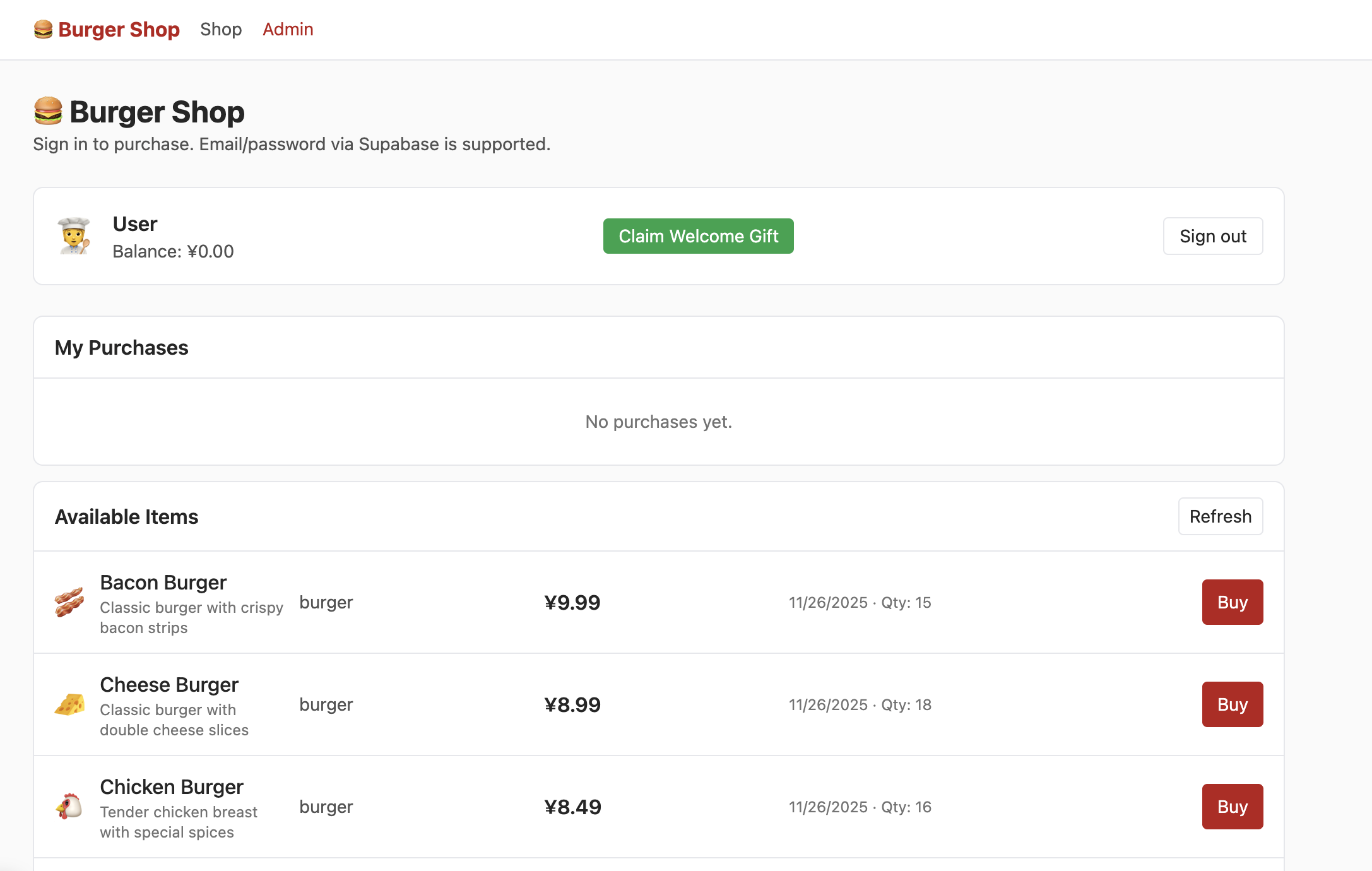
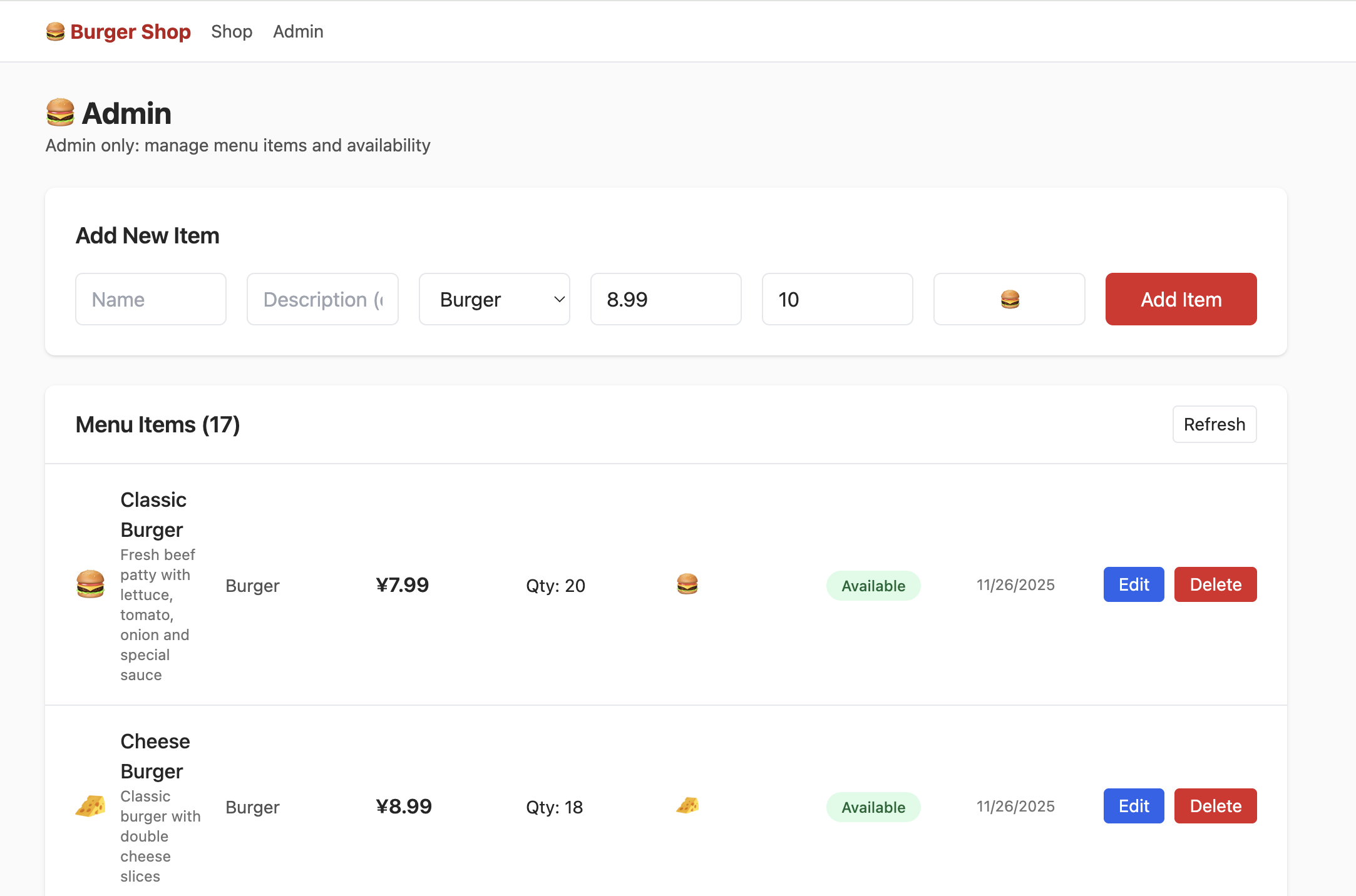
但此時點擊 admin,你並不能看到如下界面,你需要嘗試在資料表中找到控制用戶權限的部分,將權限修改為 admin,從而能夠在 Admin 界面正常看到如下內容:
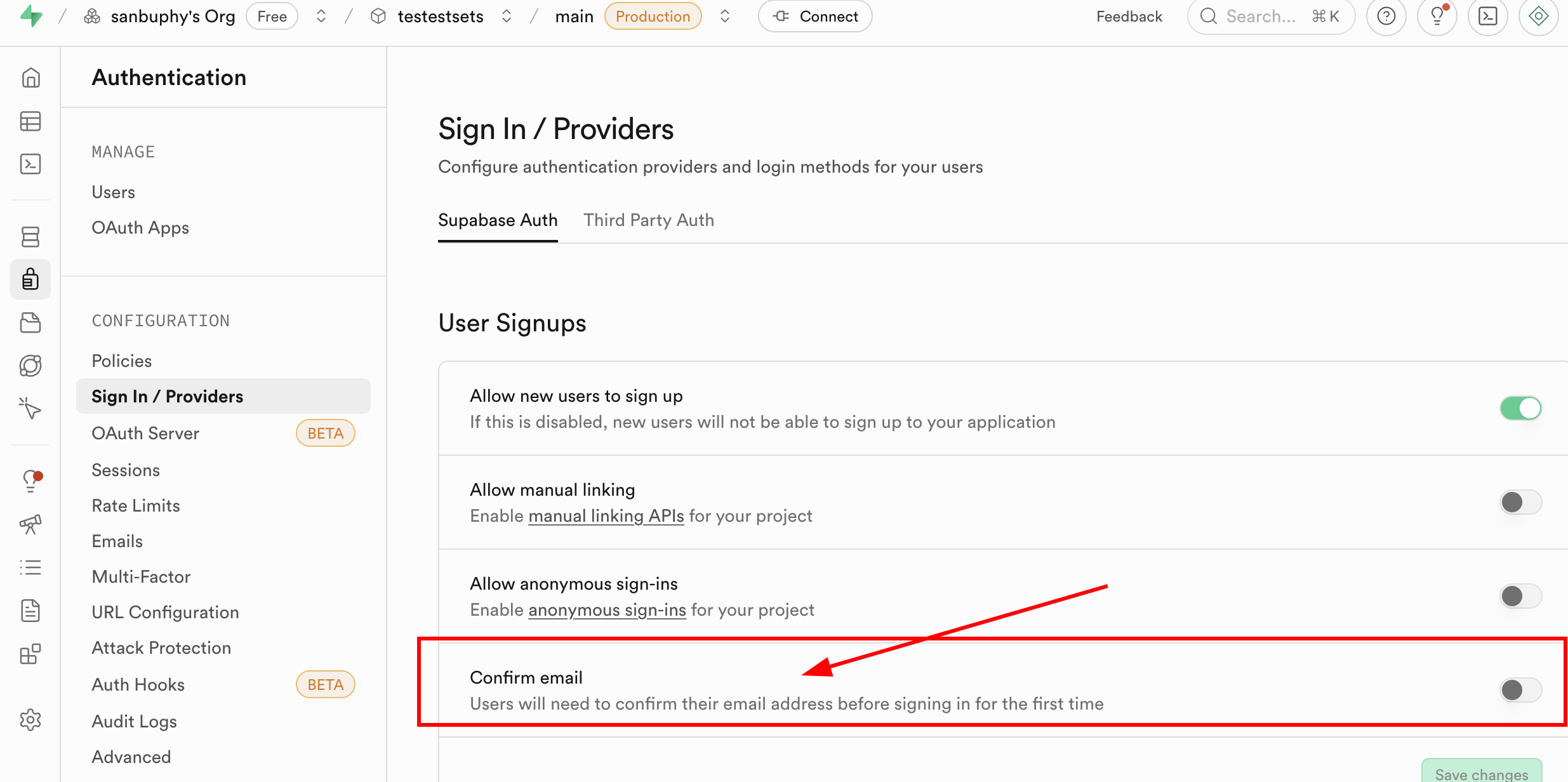
值得提示的是,目前每次註冊新的郵箱,你都需要在郵箱中進行註冊確認才可登錄;但這一步並非是必須的,你可以在 Supabase 的 Authentication 欄目中找到 Sign In / Providers,點擊Confirm email 取消郵箱的強制確認。
📚 作業
- 請先領取新手禮包,完成商品購買操作。
- 嘗試找到用戶權限的設定資料表位置,將權限修改為
admin,併成功在訂單管理界面修改商品數量 - 嘗試在資料表內定位到錢包金額相關表,通過修改使剩餘錢包金額增加。
4. 構建你的第一個 Supabase 應用
經過前面的系統學習,你已掌握 Supabase 的核心能力(資料庫操作、用戶認證、RLS 安全策略),現在是時候親自動手,搭建屬於你的第一個包含資料庫、支持用戶登錄系統的應用了!
4.1 為任意應用接入 Supabase 資料庫的標準化流程
我們可以使用標準化流程將任意應用接入 Supabase 資料庫:
- 首先進行需求梳理與資訊同步,明確目標並告知AI
- 你需要向AI清晰描述當前應用的核心功能、待新增的資料庫需求。示例:“我現有一個本地React Todo應用,資料僅存在瀏覽器本地存儲,需新增‘資料雲端同步’功能並接入Supabase資料庫。請幫我梳理:這個應用涉及哪些資料操作(如新增待辦、修改狀態、刪除待辦)?需要創建哪些資料表來存儲這些資料?”
- 補充關鍵約束條件(可選):比如字段格式要求(時間戳用
timestamptz、金額用整數存分)、資料權限規則(僅自己可見待辦),讓AI的分析更貼合實際需求。 - 對 AI 返回的結果進行審核,若AI思路存在遺漏(如未考慮“待辦截止時間”字段),補充提示修正:“你漏考慮截止時間了,幫我加上。”
- 讓AI基於你確認後的表結構,生成適配Supabase的
init.sql腳本:“基於上述所說思路和表的結構,返回給我在 Supabase 中可以進行初始化的 init.sql 腳本”,之後你需要在 SQL Editor 中執行腳本;若執行報錯,將錯誤資訊反饋給AI,讓其修正腳本。 - 在 Supabase 運行 init.sql 腳本後,讓 AI 基於腳本重構當前程式碼,使得能夠和 Supabase 進行正常的資料交互:“請你根據我的 sql 腳本以及上面討論的設定,重構項目的程式碼讓它支持能夠和 Supabase 對應的資料庫進行通信並處理資料”。
- 重構完畢,此時只需要配置好 Supabase 地址和 key 的參數(正式項目通常只用環境變量配置),隨後進行檢查,若沒問題則順利實現將應用接入 Supabase 資料庫。
- 運行項目,測試所有資料庫交互功能,到Supabase Table Editor 實時查看資料是否同步;
- 若出現問題(如資料無法插入、僅能看到部分資料),將問題現象反饋給AI,讓其定位原因並修正程式碼。
此外,若目標是開發用戶登錄頁面,可直接讓 AI 協助集成登錄頁面 :“現在你需要幫我給這個應用加入 Supabase 的用戶登錄系統,使用郵箱可以註冊和登錄”。另外,你還需要向 AI 明確頁面的跳轉邏輯與路徑(如登錄成功後跳轉至系統首頁、跳轉首頁的地址是什麼、登錄失敗時留在當前頁並顯示錯誤提示)。集成完成後,你需要嘗試註冊登錄後能在 Supabase 的 Authentication 項目中看到新增的用戶資料,並在登錄後能正常進入到原先未登錄無法進入的應用界面即可。
當然,你還可以直接讓 AI 參考某個 project 的實現直接遷移對應的 Supabase 功能,比如某個 Project 用到了資料庫以及 Edge fuction 的高級功能,你可以按照如下方式直接讓 AI 遷移對應的相似功能:“請你參考該項目 {此處複製粘貼參考項目的絕對地址} 當中的 Supabase 相關功能實現邏輯,給當前項目加上類似的實現邏輯(如用戶登錄、資料庫管理、函數請求等等)”。
4.2 案例研究:構建一個在線貪吃蛇遊戲
根據上面所提到的 SOP ,讓我們通過一個具體的實際案例 Project5-Supabase-Demos/apps_snakegame來實踐:為一個已有的“貪吃蛇”遊戲項目增加分數排行榜單,包含用戶登錄與資料庫基礎功能。
4.2.1 分析項目,識別資料需求
首先,和在之前提到的標準化流程類似,我們可以先把需求澄清給 AI ,讓 AI 基於我們項目和需求給出對應的修改方案,之後我們會基於這個修改方案。
你可以使用如下的提示詞來指導 AI:
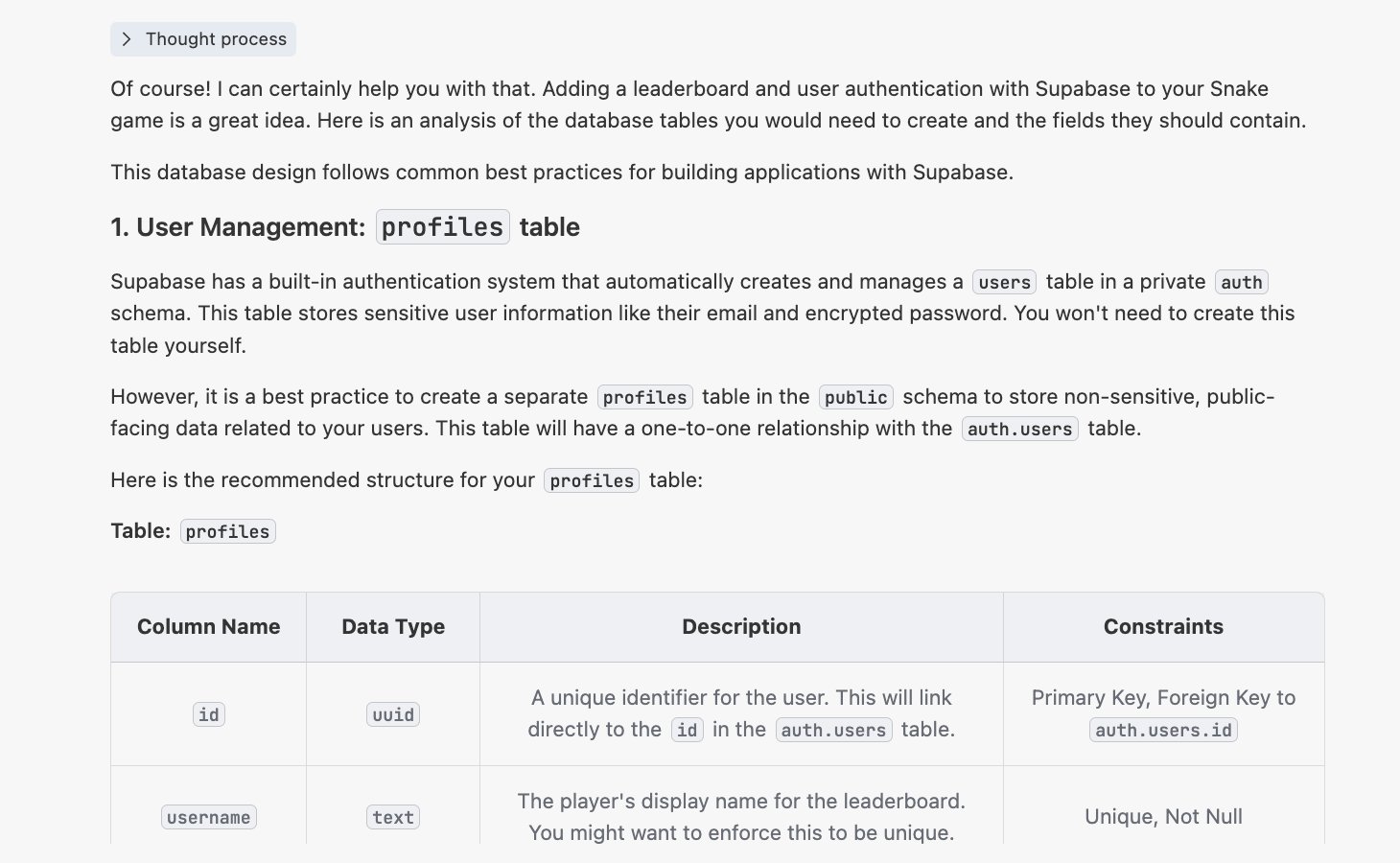
“我有一個貪吃蛇遊戲,目錄在 {此處粘貼貪吃蛇遊戲的絕對路徑}。現在我想結合 supabase 給它增加一個在線排行榜功能,並且支持用戶登錄系統,排行榜可以根據用戶名和郵箱顯示排名。
請幫我分析一下,為了實現這個功能,我需要建立哪些資料表?每個表應該包含哪些字段?”
此時你會得到類似如下返回:
4.2.2 生成 init.sql 腳本
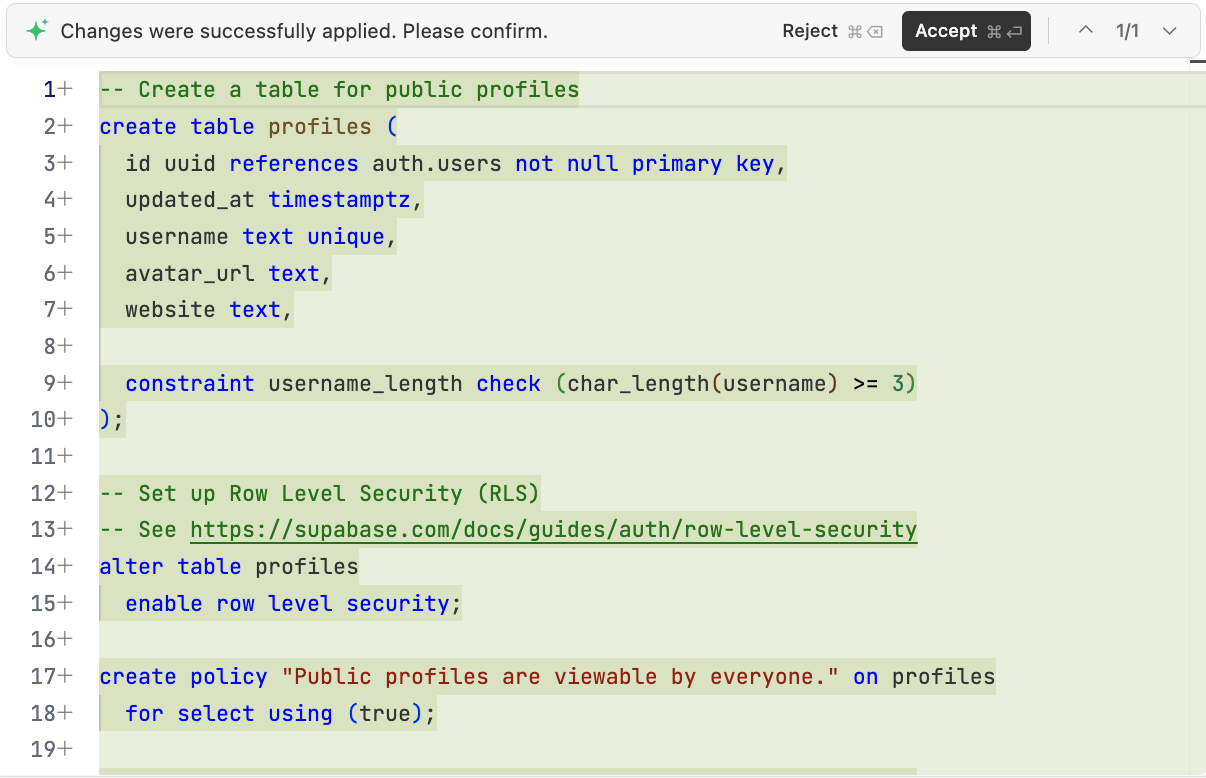
確定需要的部分,我們可以讓 AI 生成需要在 Supabase 執行的資料庫初始化腳本:“請你基於上面的分析,幫我在項目中生成 scripts/init.sql 腳本用於在 Supabase 中初始化所需資料庫”。
4.2.3 改造項目程式碼
接下來我們只需要讓 AI 基於前面的內容重構當前的貪吃蛇程式碼:“接下來請你基於前面思考的內容以及 sql 表,使用 Supabase 幫我實現排行榜功能,排行榜是單獨的一頁,需要可以根據郵箱和用戶名區分不同用戶的總分,你還需要支持基於郵箱的用戶登錄系統,註冊登錄才能玩這個遊戲。”
如果當前 AI 對話輪次太多,你想重開一個新的會話進行項目重構,你可以把上面提到的 init.sql作為上下文中的內容,讓 AI 基於 sql 文件進行項目重構。
若是發現 AI 實現的用戶登錄系統不夠正常,你可以直接將我們之前寫好的 Project5-Supabase-Demos/apps/project-burger-shop-auth-users-2 的地址一同放入提示詞,讓 AI 基於項目直接實現用戶登錄系統。並檢查是否已經正確設定了連接到 Supabase 的必要條件,防止因為 Supabase 配置錯誤而報錯。
在程式碼修改過程中,若出現實際效果與預期不符的情況(如排行榜資料不顯示、登錄驗證失效等),只需完整記錄具體現象並反饋給 AI,即可逐步接近正確結果。改造成功的標準為:用戶能順利完成註冊與登錄操作,且登錄後可正常查看對應的遊戲排行榜單。
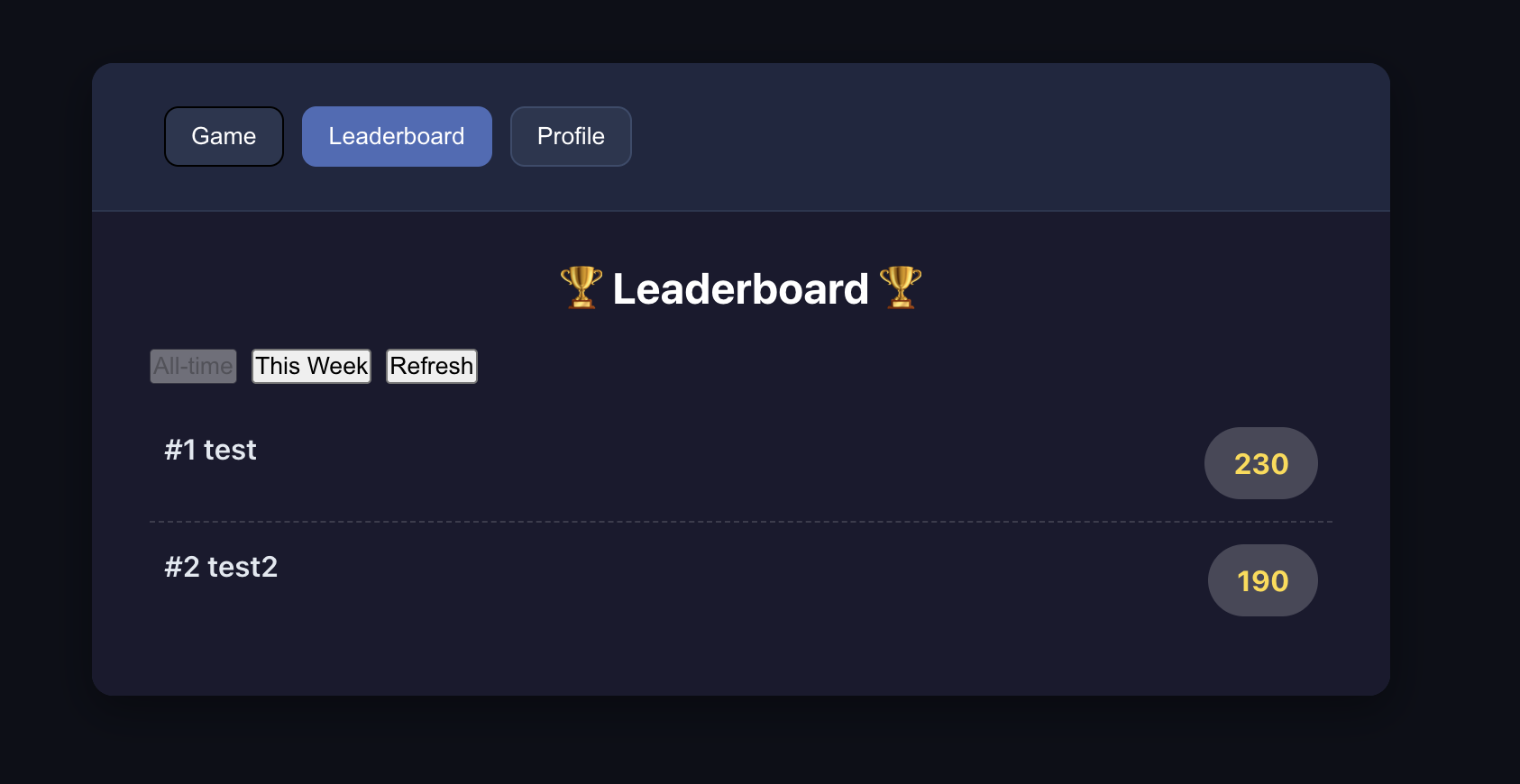
📚 課程作業
- 將用戶管理系統集成到貪吃蛇遊戲演示版中
- 將用戶管理系統集成到你的應用程序中(如果之前已開發過一個應用程序)
5. 成為 Supabase 大師
以上是 Supabase 的基本操作,接下來的旅程中我們將會接觸 Supbase 的進階原理和功能,你將理解為什麼我們會選擇 Supabase 作為教學案例,以及如何使用 Supbase 實現更高級的操作,協助你實現更復雜的交互功能,並且在學習這些功能後,即便面對 Supabase 之外的其他同類工具,你也能觸類旁通,從更本質的層面理解後端服務的核心原理。當然,你並不需要在短時間內學會全部,也許只需要學會第三方登錄支持已經足夠,你可以先瀏覽下列內容,直到項目遇到對應的需求時再倒回來深入學習。
5.1 為什麼我們選擇 Supabase
在開始進階之前,我們再次思考這個問題:眾多後端技術方案中,為何我們最終選擇 Supabase 作為技術底座?
初創團隊在技術選型時普遍面臨一個矛盾:既想完全掌控後端系統,又必須快速上線產品——而自建後端通常意味著要投入數月時間搭建資料庫與實時同步、用戶認證、API服務、文件存儲、定時任務、監控告警等核心組件,除非團隊成員已在對應領域積累了豐富的實戰經驗。在資金不足、市場窗口短暫的雙重壓力下,一旦陷入基礎設施泥潭,極易導致迭代滯後、錯失早期增長空間。
Supabase 將這些後端能力打包為開箱即用的服務(PostgreSQL資料庫、實時訂閱、身份認證、對象存儲、邊緣函數、自動生成API等),讓初創團隊得以將稀缺資源聚焦於核心功能開發,避免因底層建設拖慢上線速度——這已成為當前創投環境下務實的生存策略。當然,我們也可以使用別的一棧式後端產品進行開發,例如 PocketBase(輕量極簡)和 Appwrite(跨平臺適配)等方案,但綜合功能完整性、SQL 生態成熟度及 Github 社區關注度,Supabase 更適合支撐業務的長期穩定運行。
在同類產品中,Supabase 的開源策略更具優勢。 以市場佔有率較高的 Firebase 為例:其閉源特性易導致平臺綁定,遷移成本極高。Supabase 採用完全開源模式,支持私有化部署,規避了供應商鎖定風險,可根據需求切換至其其他競品。
總而言之,技術選型需匹配業務規模與目標。 對於個人項目或極小範圍測試,PocketBase 等超輕量方案已足夠;若企業需對接複雜身份系統,或要滿足上市公司合規審計要求,WorkOS 這類企業級全身份治理方案更為適用。但對於驗證 MVP、承載早期用戶的核心業務場景,Supabase 的完整功能完全夠用,它不僅能獨立支撐至少萬級用戶規模,更可靈活集成 Stripe(支付)、Resend(郵件)、Cloudflare(CDN)等第三方服務;即便未來業務擴展至企業級需求,Supabase 的開源架構也能與企業系統並行部署,不同功能選擇最適配的平臺進行使用。這種漸進式靈活性,使初創團隊無需過早投入重型基礎設施,又能保留 future-proof 的演進空間。
5.2 Google 和 GitHub 登錄支持
在前面的教程中,我們講解了如何直接使用郵箱進行註冊和登錄,但在實際操作中我們通常想要簡化註冊流程,例如使用第三方登錄 Google 和 GitHub 進行系統的快速註冊與登錄,我們將會在這節教程中展開每個細節;同時,一個完整的認證系統也必須提供安全可靠的密碼重置功能,我們也會將密碼重置功能集成在本節教程的項目中。
本項目 Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6)完整地演示瞭如何實現這些高級功能。

5.2.1 OAuth 流程:第三方登錄是如何工作的?
第三方登錄的核心是 OAuth 2.0 開放授權協議,它的本質是 “授權代理”:允許用戶授權我們的應用(漢堡店項目)訪問其在第三方平臺(如 Google)的公開資訊(如郵箱、頭像),但無需將第三方平臺的密碼暴露給我們的應用,從根本上規避了密碼洩露風險。
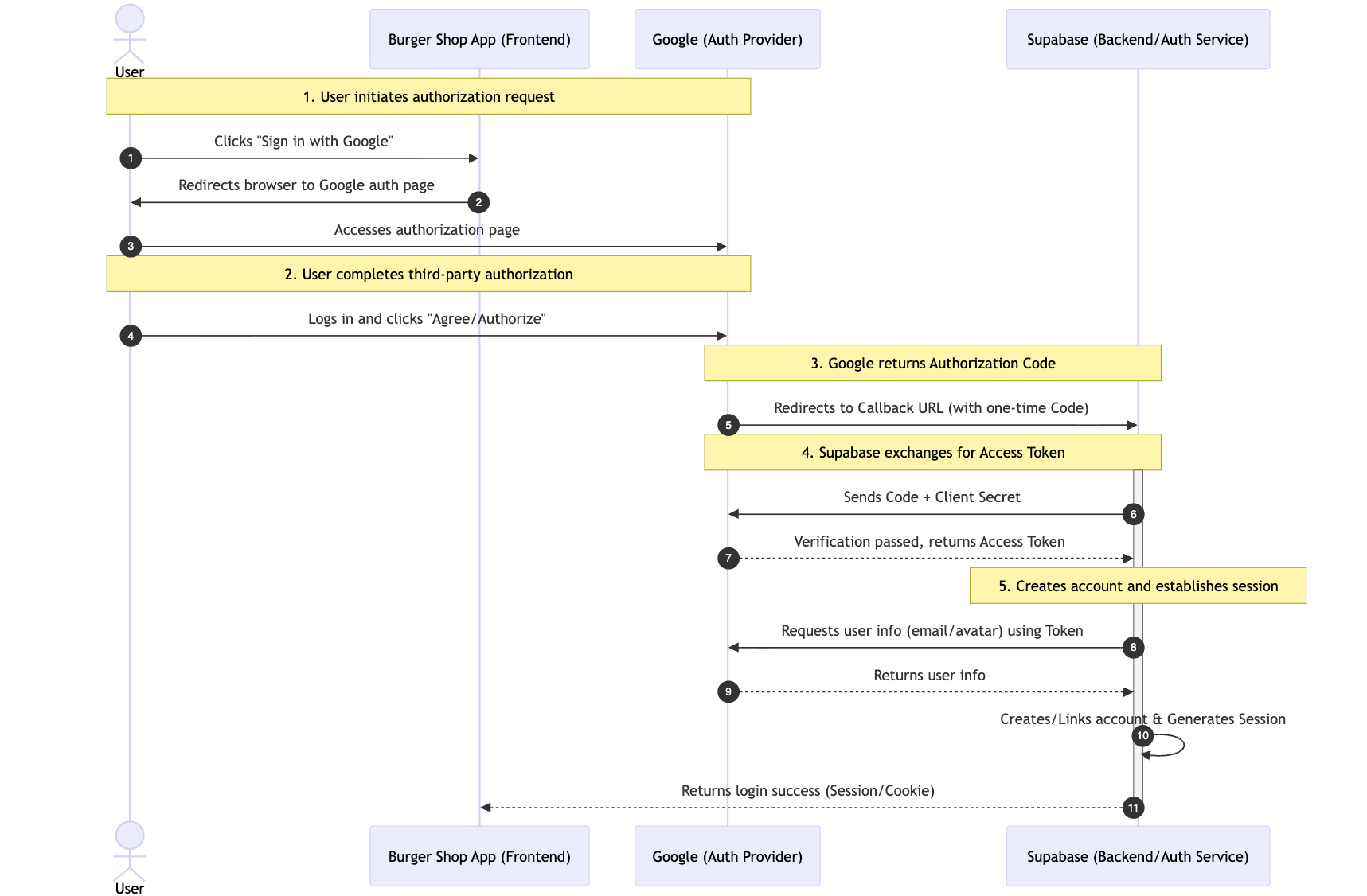
完整流程可拆解為 5 個關鍵步驟,以 Google 登錄為例:
- 用戶發起授權請求:用戶點擊頁面上的 “Sign in with Google” 按鈕,我們的應用會自動將用戶重定向到 Google 官方的授權頁面(確保授權過程的安全性,避免釣魚風險)。
- 用戶完成第三方授權:用戶在 Google 頁面登錄自己的賬戶(驗證用戶身份),並同意我們的應用請求的權限(如 “獲取郵箱地址”)。
- Google 返回一次性授權碼:授權通過後,Google 會將用戶重定向回我們提前約定的 “回調 URL(Callback URL)”,並在 URL 參數中附帶一個一次性、短期有效的授權碼(而非直接返回用戶資訊,進一步提升安全性)。
- Supabase 交換訪問令牌(Access Token):我們的後端(由 Supabase 託管,無需自建)會拿著這個授權碼,向 Google 官方接口發起請求,換取可用於獲取用戶資訊的 Access Token(授權碼僅用於換 Token,避免 Token 直接在前端傳輸)。
- 創建賬戶並建立會話:Supabase 使用 Access Token 從 Google 拉取用戶的公開資訊(如郵箱、頭像),並在我們的項目中為該用戶自動創建賬戶(若首次登錄)或直接關聯現有賬戶,最終生成一個有效的用戶會話(Session),完成登錄。
5.2.2 配置 Google Cloud 獲取 Client ID 和 Secret
無論是何種第三方登錄方式,我們通常都需要獲取 Client ID 與 Secret 進行配置;對於 Google 的第三方登錄,你首先需要在 Google Cloud Platform 中創建一個 OAuth 2.0 客戶端 ID 進行對應參數的獲取。
- 進入 Google Cloud Console :
- 訪問 Google Cloud Console。
- 創建一個新項目或選擇一個現有項目。
- 配置 OAuth 同意屏幕 (OAuth consent screen) :
- 在左側導航欄中,找到 “APIs & Services” -> “OAuth consent screen”。
- 選擇 “External” 用戶類型,然後點擊 “Create”。
- 填寫應用名稱、用戶支持電子郵件等必填資訊。
- 在 “Authorized domains” 部分,添加你的 Supabase 項目域名,格式為
*.supabase.co。 - 保存並繼續。在 “Scopes” 和 “Test users” 步驟中,你可以暫時跳過,直接保存。
- 創建憑據 (Create Credentials) :
- 進入 “APIs & Services” -> “Credentials”。
- 點擊 “+ CREATE CREDENTIALS”,選擇 “OAuth client ID”。
- 在 “Application type” 中選擇 “Web application”。
- 為它取一個名字,例如 “Supabase Auth”。
- 在 “Authorized redirect URIs” 部分,點擊 “ADD URI”,並填入你的 Supabase 項目的回調 URL。你可以在 Supabase Dashboard 的 “Authentication” -> “Providers” -> “Google” 中找到這個 URL,它的格式通常是
https://<你的項目ID>.supabase.co/auth/v1/callback。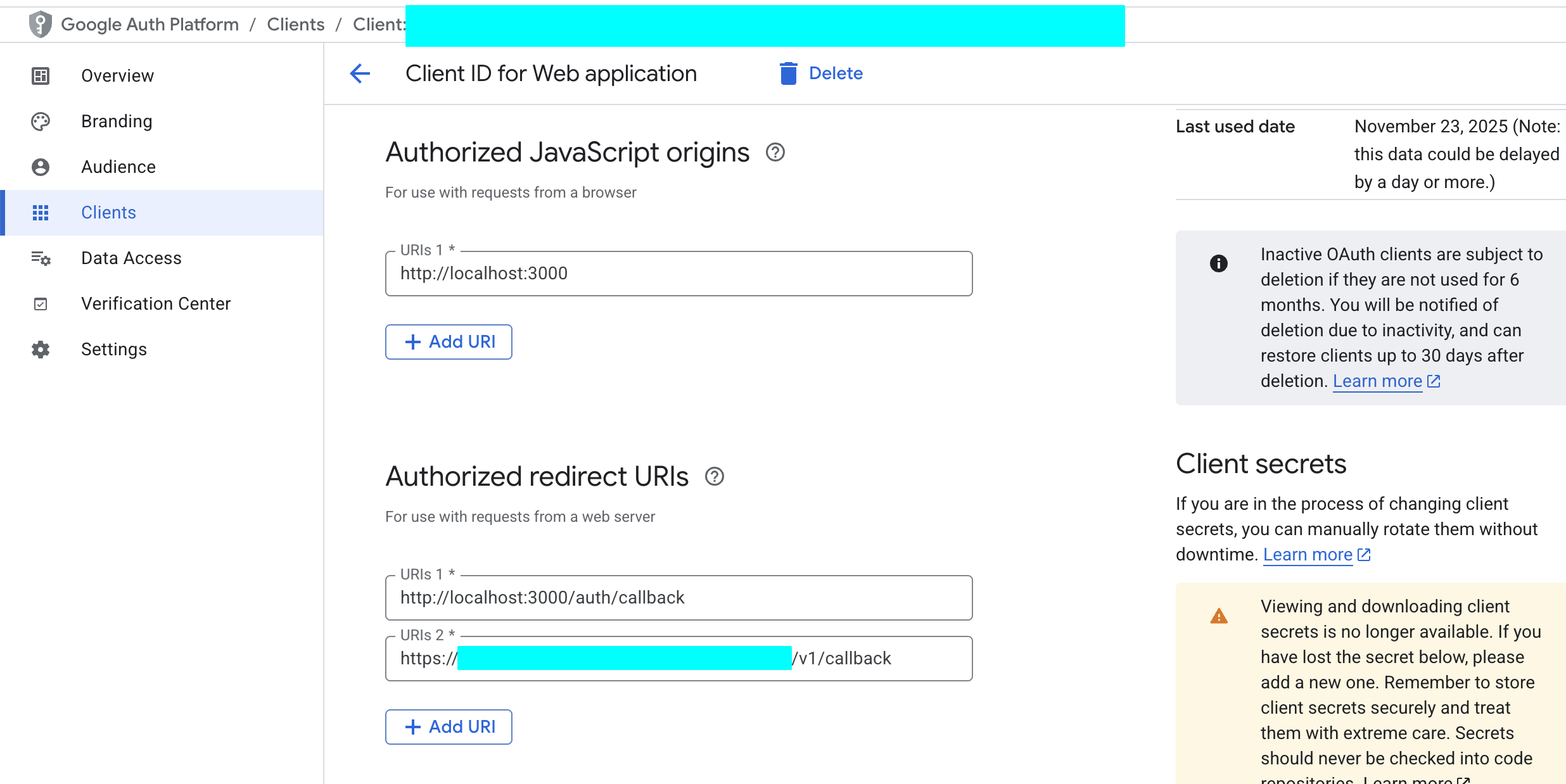
- 點擊 “CREATE”。
- 獲取 Client ID 和 Client Secret :
- 創建成功後,一個彈窗會顯示你的 Client ID 和 Client Secret 。請務必立即複製並妥善保存 它們。
5.2.3 配置 GitHub 獲取 Client ID 和 Secret
同樣地,你也需要在 GitHub 上註冊一個 OAuth 應用。
**進入 **GitHub** ** Developer Settings :
- 登錄你的 GitHub 賬戶。
- 點擊右上角的頭像,進入 “Settings”。
- 在左側導航欄的底部,找到 “Developer settings”。
註冊新應用 (Register a new application) :
選擇 “OAuth Apps”,然後點擊 “New OAuth App”。
填寫應用名稱,例如 “My Burger Shop”。
Homepage URL : 填寫你應用的線上地址,或者本地開發地址
http://localhost:3000。**Authorization **callback** ** URL : 填入你的 Supabase 項目的回調 URL。同樣,你可以在 Supabase Dashboard 的 “Authentication” -> “Providers” -> “GitHub” 中找到它,格式為
https://<你的項目ID>.supabase.co/auth/v1/callback。點擊 “Register application”。
獲取 Client ID 和 Client Secret :
註冊成功後,頁面會顯示你的 Client ID 。
點擊 “Generate a new client secret” 來生成你的 Client Secret 。同樣,請立即複製並保存 它。
5.2.4 在 Supabase 中配置 Provider
現在,將我們獲取到的憑證配置到 Supabase 中。
- 進入 Supabase Dashboard :
- 選擇你的項目,進入 “Authentication” -> “Providers”。
- 啟用並配置 Google :
- 找到 “Google” 並啟用它。
- 將你從 Google Cloud 獲取的 Client ID 和 Client Secret 粘貼到對應的輸入框中。
- 點擊 “Save”。
- **啟用並配置 ** GitHub :
- 找到 “GitHub” 並啟用它。
- 將你從 GitHub 獲取的 Client ID 和 Client Secret 粘貼到對應的輸入框中。
- 點擊 “Save”。

至此,你已經能夠使用第三方賬戶在構建的網站中進行登錄,你可以直接讓 AI 基於 Project5-Supabase-Demos/apps/project-burger-shop-auth-advanced-supabase-6項目作為參考,在你的項目的基礎上支持用戶登錄系統,以最小成本集成包含 github 與 google 鑑權的用戶登錄界面。
5.2.6 密碼重置實現
作為一個成熟的用戶登錄組件,密碼重置也是極其重要的一環,本項目 project-burger-shop-auth-advanced-supabase-6也包含了該功能的完整實現,你可以直接讓 AI 基於本項目的密碼重置功能復刻完整的密碼重置組件。其主要分為以下幾步:
- 發起請求 :用戶在忘記密碼頁面輸入郵箱,前端調用
supabase.auth.resetPasswordForEmail()函數,並指定一個重定向 redirectTo URL(例如 /auth/reset )。 - 發送郵件 :Supabase 會向該郵箱發送一封包含唯一重置鏈接的郵件。
- 訪問鏈接 :用戶點擊郵件中的鏈接,被重定向到應用內指定的重置頁面。
- 更新密碼 :在重置頁面,用戶輸入新密碼。前端調用
supabase.auth.updateUser(),將新密碼提交給 Supabase。Supabase 會自動驗證鏈接的有效性並完成密碼更新。
最後,如果你覺得當前的密碼重置郵件過於簡陋,你可以 在 Supabase Dashboard 的 Authentication -> Email Templates 中自定義“Reset Password”郵件模板。
除了 Reset password 功能外,你還能看到許多其他與用戶管理相關的高級功能設定(例如 Invite user 等),你可根據對應功能各自的開發文檔,結合 Vibe coding 工具自行添加對應功能。
5.3 實時功能
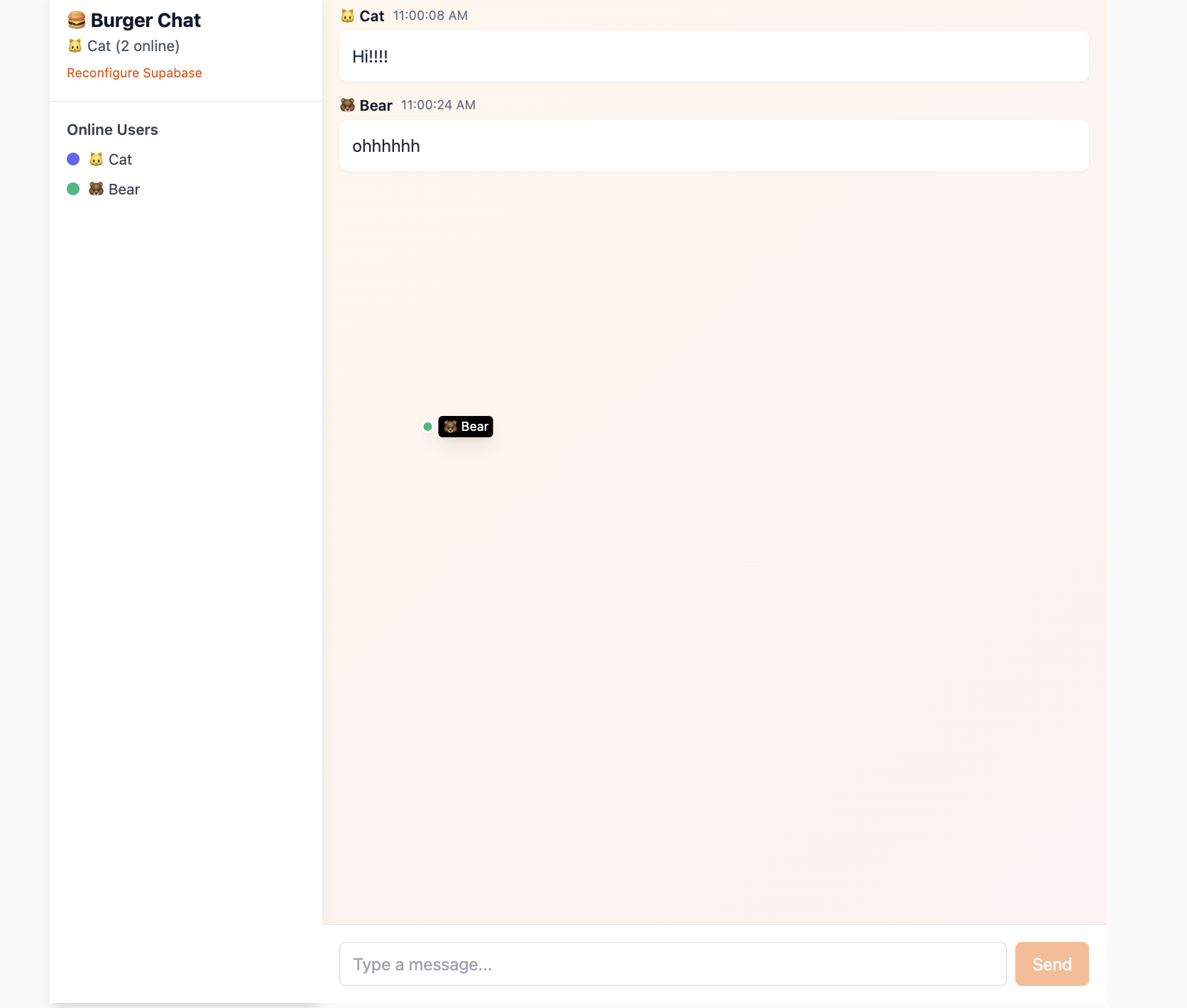
Supabase 的實時功能是其最強大的特性之一,為構建協作文檔、實時儀表盤、遊戲大廳或客服系統提供了極大的便利。
本項目 Project5-Supabase-Demos/apps/project-burger-shop-realtime-orders-3 通過構建一個 多人實時聊天室、光標位置共享 功能,展示了 Supabase Realtime 涉及到的三大核心能力:資料庫變更監聽 (Postgres Changes)、廣播 (Broadcast) 和 在線狀態 (Presence)。
如果你覺得相關程式碼部分有一定難度,可以直接讓 AI 參考該部分文檔內容,對你的程序進行修改。
5.3.1 資料庫實時變動 Postgres Changes
最常見的 Realtime 功能是對資料庫的變更進行實時監聽 Postgres Changes 。它允許客戶端訂閱資料庫中特定表、特定行甚至特定列的 INSERT 、 UPDATE 或 DELETE 事件。一旦資料庫發生變動(無論是通過 API 調用、Supabase Dashboard 操作,還是 SQL 腳本執行),Supabase 都會利用 PostgreSQL 的底層複製機制,立即通過 WebSocket 將變更的資料推送到所有訂閱了該頻道的前端客戶端,而無需前端通過輪詢(Polling)去反覆查詢。
一般而言,該功能可以在 Table Editor 中找到 Enable Realtime 點擊後啟動, 但更方便的是通過 SQL 腳本初始化執行,例如:
-- Enable realtime replication
ALTER TABLE public.chat_messages REPLICA IDENTITY FULL;
DO $$
BEGIN
IF NOT EXISTS (
SELECT 1 FROM pg_publication_tables
WHERE pubname = 'supabase_realtime'
AND schemaname = 'public'
AND tablename = 'chat_messages'
) THEN
ALTER PUBLICATION supabase_realtime ADD TABLE public.chat_messages;
END IF;
END $$;該語句將 chat_messages 表添加到了 Supabase 預設的 supabase_realtime 中,而一旦一個表被加入到這個特殊的 publication 中,Supabase 的實時服務器就會開始監聽它的所有資料變更。
基於上面的特殊資料表,我們能夠使用監聽程式碼對錶內資料變動進行實時監聽。我們需要實現的是當一個用戶發送消息時,其他所有在線用戶都能立刻在屏幕上看到這條消息。通過訂閱 chat_messages 表的 INSERT 事件能夠實現這一點。
const sub = supabase
.channel('chat_messages_channel')
.on('postgres_changes', {
event: 'INSERT',
schema: 'public',
table: 'chat_messages'
}, (payload: any) => {
console.log('New message received:', payload.new);
const newMessage = payload.new as Message;
// ... //
.subscribe((status: string) => {
console.log('Chat subscription status:', status);
});.channel('chat_messages_channel'): 創建一個隔離的通信頻道。.on('postgres_changes', ...): 這是核心的訂閱方法。我們告訴 Supabase 我們只關心chat_messages表的INSERT事件。payload.new: 當有新消息被插入資料庫時,Supabase 會將這條新資料的完整內容通過payload.new推送給所有訂閱的客戶端。.subscribe(): 啟動訂閱。
5.3.2 資訊廣播同步 Broadcast & Presence
對於那些不需要存入資料庫的、更“即時”的交互,比如光標移動、在線狀態等,Supabase 提供了 Broadcast 和 Presence 功能。
- Presence: 用於跟蹤頻道內所有客戶端的 共享狀態 。適合用來實現“誰在線”的功能。
- Broadcast: 用於向頻道內的所有其他客戶端發送低延遲的 臨時消息 。
Presence 的核心思想是: 讓每個客戶端聲明自己的在線狀態,並由 Supabase 的服務器負責將這些狀態可靠地同步給頻道內的所有其他客戶端。實現 Presence 分為以下幾個關鍵步驟:
- 創建一個支持 Presence 的頻道
首先,我們創建了一個頻道 lobby_presence 來專門處理這些交互,並在配置中指定一個唯一的 key 來標識當前用戶。這個 key 通常是用戶的 ID。
const ch = supabase.channel
('lobby_presence', {
config: {
presence: { key: anonymousUser.id },
}
});- 訂閱頻道宣告“我在線”的資訊
一旦頻道創建成功,我們需要訂閱它。在訂閱成功的回調( status === 'SUBSCRIBED' )中,我們調用 channel.track() 方法。這個方法會將當前用戶的資訊(例如用戶ID、名稱、頭像顏色等)廣播給頻道內的所有其他客戶端,宣告自己的“在線”狀態。
const me = {
id: anonymousUser.id,
name: anonymousUser.name,
color: anonymousUser.color
};
ch.subscribe(async (status) => {
if (status === 'SUBSCRIBED') {
await ch.track(me);
}
});- 同步完整的在線列表
當一個新用戶加入頻道時,他們需要獲取當前所有已經在線的用戶列表。這通過監聽 presence 的 sync 事件來實現。 sync 事件會在你首次加入頻道時觸發,為你提供一個完整的“快照”。
channel.presenceState() 方法會返回一個對象,包含了當前頻道內所有在線用戶的狀態資訊。我們將其處理後更新到應用的 state 中,從而渲染出完整的在線用戶列表。
ch.on('presence', { event: 'sync' }, ()
=> {
const state = ch.presenceState();
const flat = {};
Object.values(state).forEach((arr) => {
arr.forEach((u) => { flat[u.id] =
{ ...u }; });
});
setOnline(flat);
});- 監聽單個用戶的加入與離開
除了 sync 事件,我們還可以監聽 join 和 leave 事件,以便在有新用戶進入或離開時做出即時響應,例如顯示一個 "User has joined" 的通知。
ch.on('presence', { event: 'join' }, ({
key, newPresences }) => {
console.log('User joined:', key,
newPresences);
});
ch.on('presence', { event: 'leave' }, ({
key, leftPresences }) => {
console.log('User left:', key,
leftPresences);
});通過以上步驟,我們便構建了一個功能完備的在線狀態系統。Supabase 自動處理了用戶意外斷開連接(如關閉瀏覽器或斷網)的情況,並在適當的時候觸發 leave 事件,確保了在線列表的準確性。
當 Presence 讓我們知道了“誰在場”之後, Broadcast 能夠讓他們之間能夠進行“對話”,但對話的內容是短暫存儲的。一個典型的例子就是實時光標追蹤。如果每次鼠標移動都去讀寫資料庫,會造成巨大的性能浪費和延遲。 Broadcast 完美地解決了這個問題,它允許消息在各個客戶端之間直接通過 WebSocket 傳遞,完全繞過資料庫。
Broadcast 的工作模式主要依賴兩個核心方法: channel.send() 用於發送,channel.on() 用於接收。】
- 發送端:廣播我的光標位置
我們為 mousemove 事件添加了一個監聽器。當鼠標移動時,我們構造一個包含用戶 ID、座標和顏色的 payload,然後通過 channel.send() 將其廣播出去,並指定事件名稱為 'cursor'。
const handleMouseMove = (e) => {
const payload = {
id: anonymousUser.id,
x: e.clientX,
y: e.clientY,
name: anonymousUser.name,
color: anonymousUser.color
};
channelRef.current?.send({
type: 'broadcast',
event: 'cursor',
payload
});
};
document.addEventListener('mousemove', handleMouseMove);- 接收端:監聽並渲染他人的光標
在同一個頻道內,所有客戶端都使用 channel.on() 來監聽 broadcast 類型的、且 event 為 'cursor' 的消息。一旦收到匹配的消息,回調函數就會被觸發。我們從 payload 中解析出發送方的資料,並用它來更新本地的 online 狀態,從而在屏幕上實時渲染出其他用戶光標的位置。
ch.on('broadcast', { event: 'cursor' }, ({ payload }) => {
setOnline((prev) => ({
...prev,
[payload.id]: {
...(prev[payload.id] || {}),
x: payload.x,
y: payload.y
}
}));
});通過這種方式, Presence 和 Broadcast 協同工作;Presence 維護在線用戶列表,而 Broadcast 則負責在這些用戶之間傳遞像光標位置這樣的臨時狀態,最終以較低的成本實現了豐富的實時互動功能。
5.4 存儲
除了用戶資訊、訂單這類可規整定義的結構化資料,一個完整的應用通常還需要處理大量非結構化文件 —— 例如用戶頭像、商品展示圖、用戶上傳的訂單文檔等。這類文件的特點是體積差異大、數量可能極多(比如電商平臺的商品圖可能達數萬甚至數十萬張),若直接存儲在應用自身的業務服務器中,會顯著增加服務器的存儲負載,還可能拖慢資料讀寫速度,影響應用整體性能。
實際開發中,這類非結構化文件會統一交由 “對象存儲服務” 管理,OSS、Amazon S3 均屬於這類服務,它們是專門為海量文件存儲設計的 “專業存儲工具”,能高效應對文件的存儲、備份與快速讀取需求。而我們在應用中獲取這些文件時,並不會直接從對象存儲服務的 “底層倉庫” 調取,而是通過 URL 地址實現:每個存儲在對象存儲中的文件,都會被分配一個唯一的 URL(類似 “https://xxx.oss.com/avatar/user123.jpg” 的地址,可簡單理解為這個“網站”只有一張圖片),這個 URL 就像文件的 “專屬訪問地址”,前端頁面只需通過該地址,就能直接下載或加載頭像、商品圖,無需依賴應用業務服務器中轉,既提升了文件加載速度,也減輕了業務服務器的壓力。
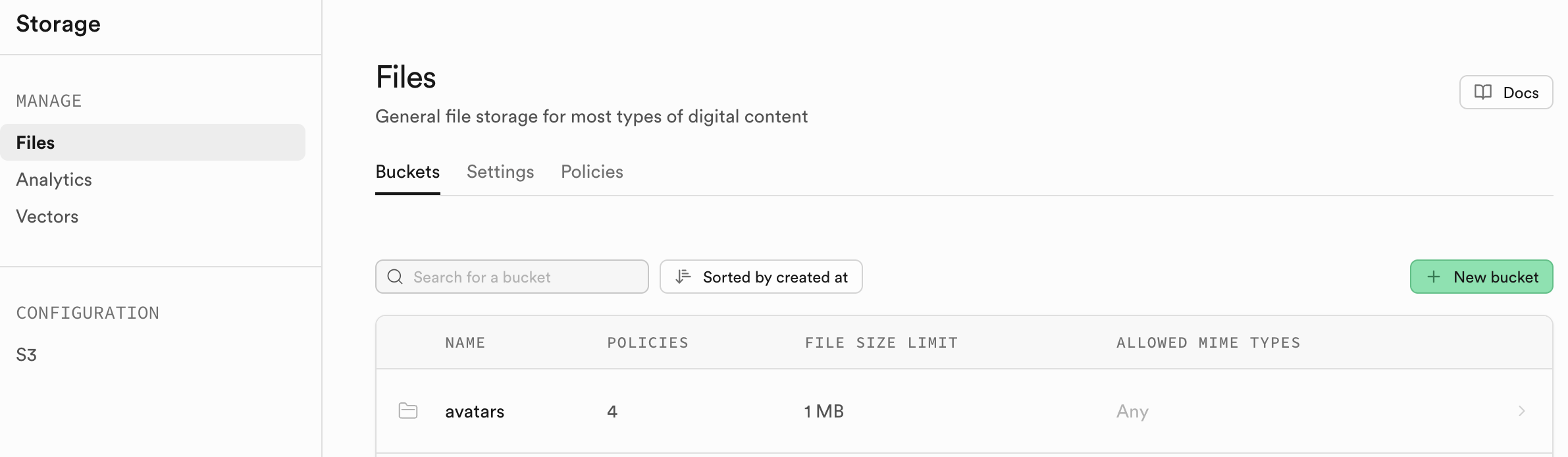
本項目 project-burger-shop-storage-uploads-4 便通過一個用戶頭像上傳功能,深入演示瞭如何利用 Supabase Storage 構建現代化的文件上傳系統,讓開發者直觀理解非結構化文件從上傳到通過 URL 訪問的完整流程。此外,本項目使用 Uppy 庫來提供一個優秀的文件上傳界面,並結合 Tus 插件實現了可續傳上傳,通過將 Uppy 的上傳端點指向 Supabase 的標準 API (<supabaseUrl>/storage/v1/upload/resumable) 進行工作,你可以參考類似的方式實現上傳功能組件。
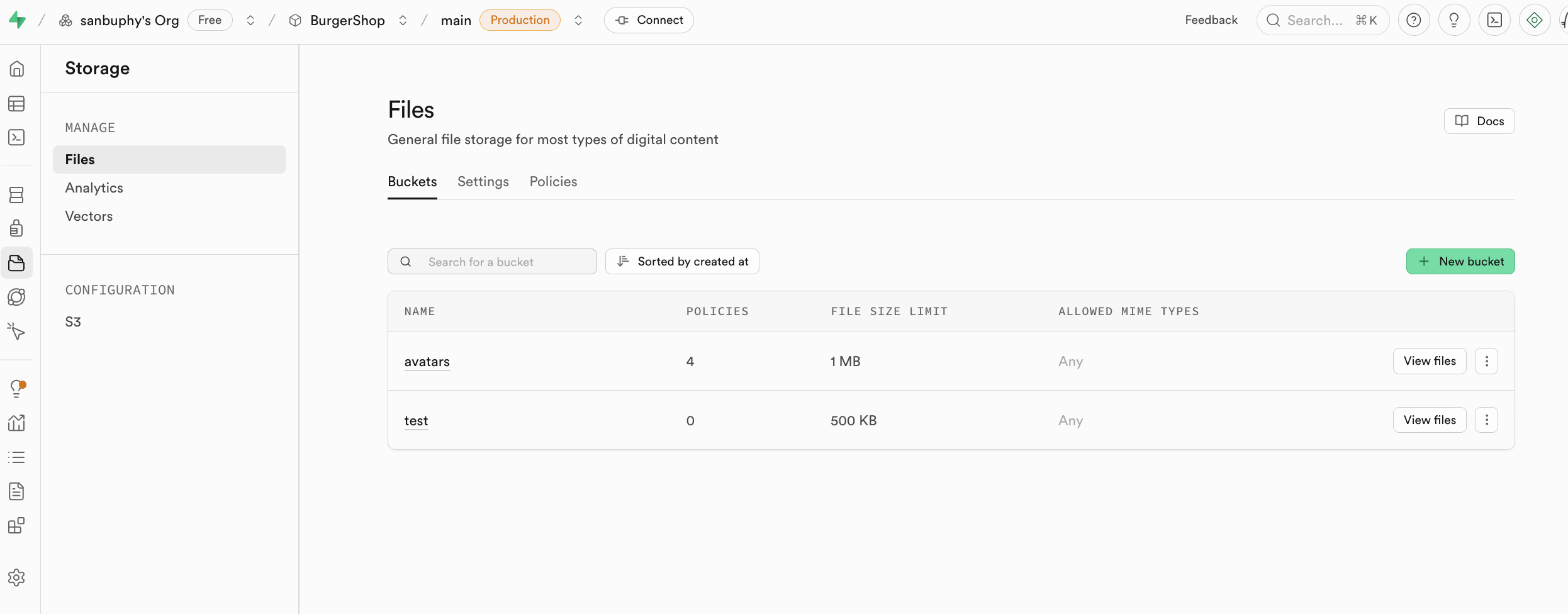
5.4.1. 存儲桶
Supabase Storage 的組成單元是存儲桶 Bucket。你可以把它想象成電腦操作系統中的文件夾。每個 Bucket 都可以有自己獨立的安全策略和配置。
Storage 內的所有文件都可以通過一個公開的 URL 直接訪問,但並不意味著任何人都可以隨意上傳或修改,具體的訪問權限將由更精細的策略來控制。和資料庫一樣,Storage 的訪問權限也是通過行級安全策略來管理的。SQL 策略寫在 storage.objects 和 storage.buckets 這兩張特殊表上,可以精確定義誰能讀取 (SELECT)、上傳 (INSERT)、更新 (UPDATE) 或刪除 (DELETE) 文件。
例如,我們可以創建一條策略,只允許用戶上傳到以自己 user_id 命名的文件夾下,並且只能上傳圖片類型的文件:
CREATE POLICY "Allow authenticated
uploads to avatars bucket"
ON storage.objects FOR INSERT
TO authenticated
WITH CHECK (
bucket_id = 'avatars' AND
auth.uid() = (storage.foldername(name))
[1]::uuid AND
(storage.extension(name) IN ('png',
'jpg', 'jpeg'))
);
CREATE POLICY "Allow public read access
to avatars"
ON storage.objects FOR SELECT
USING ( bucket_id = 'avatars' );5.4.2 獲取可訪問文件 URL
本項目需要你手動創建一個名為 avatars 的公共桶,所有文件將上傳至該公共桶下進行存儲。文件上傳成功後,我們只得到了它在 Storage 中的存儲路徑 ,例如 public/avatar1.png 。這只是存儲在資料庫中的一個字符串,要讓瀏覽器能夠渲染這張圖片,我們需要將其轉換為一個可訪問的 HTTP URL。
Supabase 提供了兩種截然不同的策略來獲取這個 URL,它們在安全性、持久性和成本控制上有著本質的區別。
1. 公開 URL (Public URL) - 永久鏈接
這是最直接的方式。如果你的文件存放在一個Public Bucket 中,你可以獲取一個固定、永久的公開鏈接。
const { data } = supabase.storage
.from('avatars')
.getPublicUrl('public/avatar1.png');
const publicUrl = data.publicUrl;這類鏈接具有兩大核心特點:一是簡單直接,其 URL 結構固定,在實際操作中易於拼接和管理,降低了技術使用門檻;二是利於緩存,作為永久鏈接,它能被 CDN(內容分發網路)和瀏覽器有效緩存,從而大幅提升資源的訪問速度,優化用戶體驗。基於這些特點,它適用於真正意義上的公共資源場景,例如網站 Logo、產品目錄圖片、博客文章配圖等,能很好地滿足這類資源的訪問和管理需求。
不過在生產環境中,這類鏈接存在明顯的被盜刷流量(Hotlinking)風險。由於鏈接是永久公開的,外部人員可以輕易將你的圖片鏈接嵌入到他們自己的高流量網站中,導致流量被非法佔用。這一行為會讓你的 Supabase 項目產生大量不必要的流量費用,而這些消耗的流量並未服務於你自身的應用,屬於典型的成本浪費,是生產環境中需要高度警惕和防範的問題;因此,我們需要轉向臨時簽名 URL 實現對外資源的暴露。
2. 簽名 URL (Signed URL) - 臨時授權鏈接
為了解決公開 URL 的安全和成本問題,Supabase 提供了生成臨時簽名 URL 的方式。這是絕大多數線上應用推薦的最佳實踐,比如文生圖應用給用戶生成限時查看的圖片鏈接、電商平臺僅讓下單用戶獲取臨時發票下載地址、付費內容平臺為訂閱用戶提供短期有效的課程播放鏈接,既防文件盜用又能避免流量盜刷,適配性極強。
const { data, error } = await supabase.storage
.from('avatars')
.createSignedUrl('private/user-invoice.pdf', 3600); // 鏈接有效期為 3600 秒 (1小時)
const signedUrl = data?.signedUrl;臨時簽名 URL(Signed URL)有三大核心優勢:安全可控是指鏈接帶安全標記、有有效期,過期就用不了;權限綁定很簡單 —— 只有能看這文件的人,才能生成這個鏈接,就算文件藏在私有存儲裡(Private Bucket),他用這個鏈接也能正常打開;杜絕盜刷是因為鏈接是臨時的,複製到別處很快就失效,不會被惡意刷流量。靠這些優勢,像用戶頭像、私人照片、付費內容、訂單發票這些需要管權限的文件,都能用它。
從安全保障和成本控制的角度,建議養成優先使用臨時簽名 URL 的習慣。只有當某個資源明確需要永久公開、無限制訪問(比如應用的公開 Logo、公共活動宣傳圖等)時,才考慮使用 Public URL。這樣既能滿足特定業務需求,又能最大程度規避不必要的風險和成本消耗。
5.5 邊緣函數
Edge Function 是 Serverless(無服務器架構)生態中極具核心價值的形態之一,它為 “無自建後端” 場景提供了輕量、高效的函數運行支持。
什麼是 Serverless? Serverless(無服務器架構)並不意味著真的沒有服務器,而是指開發者無需關心服務器的購買、運維、配置和擴容 。你只需要編寫業務程式碼(函數),雲服務商會在特定事件觸發時自動為你分配資源運行程式碼,並按實際運行時間計費。
當你的應用需要執行一些不能或不應在客戶端(瀏覽器)上完成的邏輯時——例如與需要私密密鑰的第三方 API 交互、執行計算密集型任務、或強制執行複雜的業務規則——Edge Functions 就派上了用場。Supabase Edge Functions 基於 Deno 和 TypeScript,它們被部署在全球的邊緣節點上,物理距離上靠近你的用戶,從而提供極低的函數執行延遲。
目前主流雲廠商都推出了各自的 Edge Function 服務,常見的包括:
- AWS Lambda@Edge:基於 AWS Lambda 延伸的邊緣函數服務,可與 CloudFront CDN 聯動,支持 Node.js、Python 等語言;
- Cloudflare Workers:Cloudflare 推出的邊緣函數,部署在其全球 275+ 邊緣節點,支持 JavaScript/TypeScript,以 “毫秒級延遲” 為核心優勢;
- Vercel Edge Functions:適配 Vercel 前端項目的邊緣函數,與 Next.js 深度集成,支持 TypeScript,主打 “前端與邊緣邏輯無縫銜接”;
回到 Supabase ,當你的應用需要執行 “不能在客戶端(瀏覽器)完成” 的邏輯時,比如用私密密鑰調用第三方 API(如 LLM 接口)、處理計算密集型任務(如圖片壓縮)、或強制執行權限校驗(如文件訪問規則)時,Supabase Edge Functions 就能發揮作用。它基於 Deno runtime 和 TypeScript 構建,部署在全球邊緣節點上,能以 “靠近用戶的物理距離” 實現極低的執行延遲,是編寫自定義、可信服務器端邏輯的核心工具。
本項目 Project5-Supabase-Demos/apps/project-burger-shop-edge-function-5通過一個與大語言模型(LLM)實時流式對話的功能,展示了 Edge Functions 的最簡應用流程。
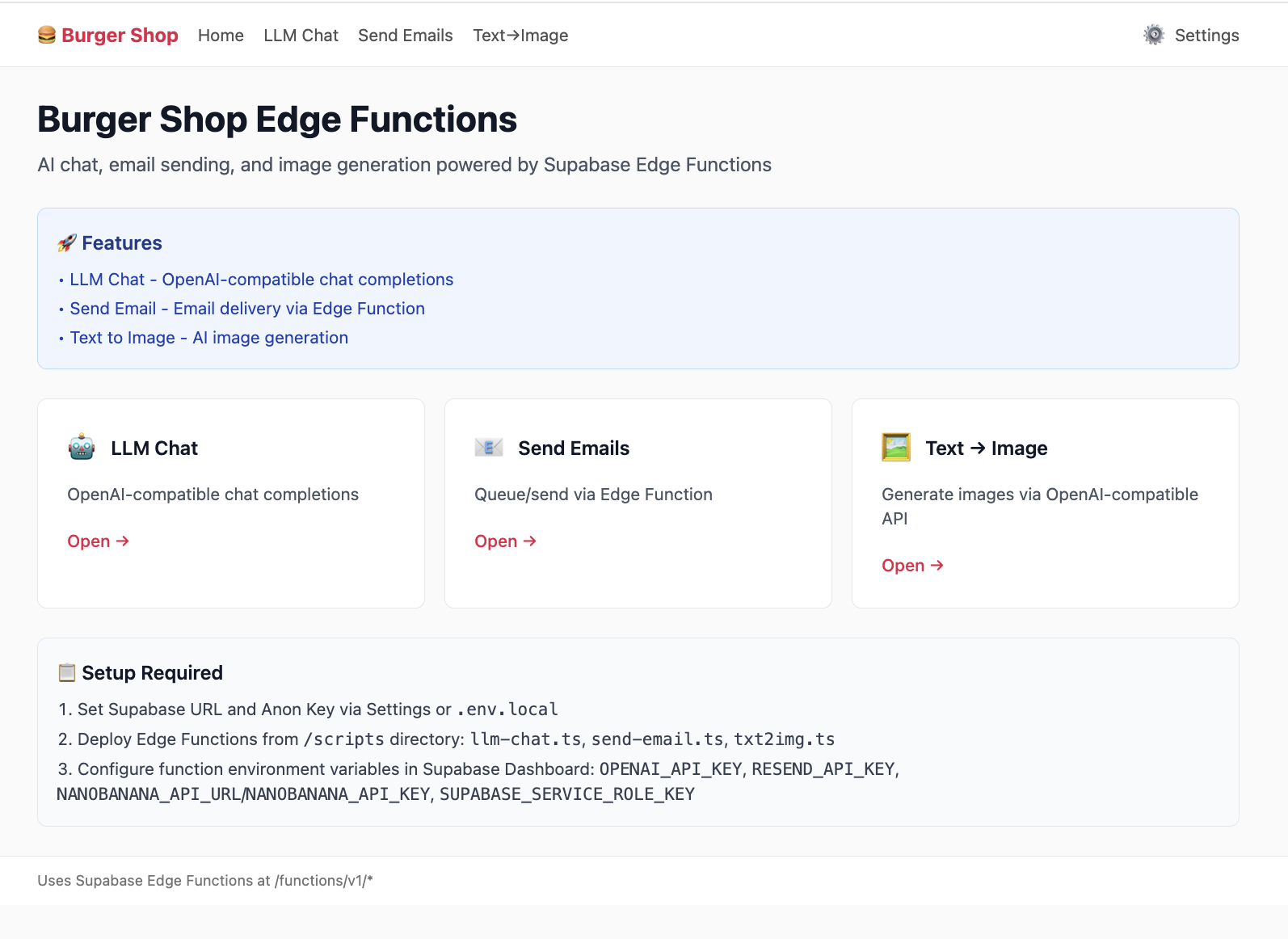
5.5.1 LLM Chat 案例解析
假設你想在應用中集成一個類似 ChatGPT 的聊天機器人。你需要在服務器端調用 OpenAI 的 API,但這需要一個私密的 API Key。 這個 Key 絕對不能暴露在前端程式碼中 ,否則任何人都可以通過查看網頁源碼盜用你的 Key,產生高昂的費用。這正是 Edge Function 的用武之地。我們將創建一個名為 llm-chat 的函數,它充當了前端和 OpenAI API 之間的一個 安全代理 。
參考 project-burger-shop-edge-function-5/scripts/llm-chat.ts的程式碼,我們來看看它是如何工作的:
// scripts/llm-chat.ts
import "jsr:@supabase/functions-js/edge-runtime.d.ts";
import { OpenAI } from "npm:openai";
const OPENAI_API_KEY = Deno.env.get("OPENAI_API_KEY");
Deno.serve(async (req) => {
try {
const openai = new OpenAI({ apiKey: OPENAI_API_KEY });
const { prompt } = await req.json();
const stream = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: prompt }],
stream: true,
});
return new Response(stream.toReadableStream(), {
headers: { "Content-Type": "text/event-stream" },
});
} catch (err) {
}
});在該案例中,對於密鑰安全,OPENAI_API_KEY 作為環境變量被安全存儲於 Supabase 的服務器。本地前端程式碼完全無法接觸到該密鑰,從而有效保障了密鑰的安全性。
5.5.2 創建並部署函數
Supabase 提供了非常友好的界面,讓你無需接觸命令行即可完成部署。
- 進入 Edge Functions 面板 :
- 登錄你的 Supabase 項目 Dashboard。
- 在左側導航欄中,點擊像程式碼一樣的圖標,進入 “Edge Functions”。
- 創建新函數 :
- 點擊 “Create a new function” 按鈕。
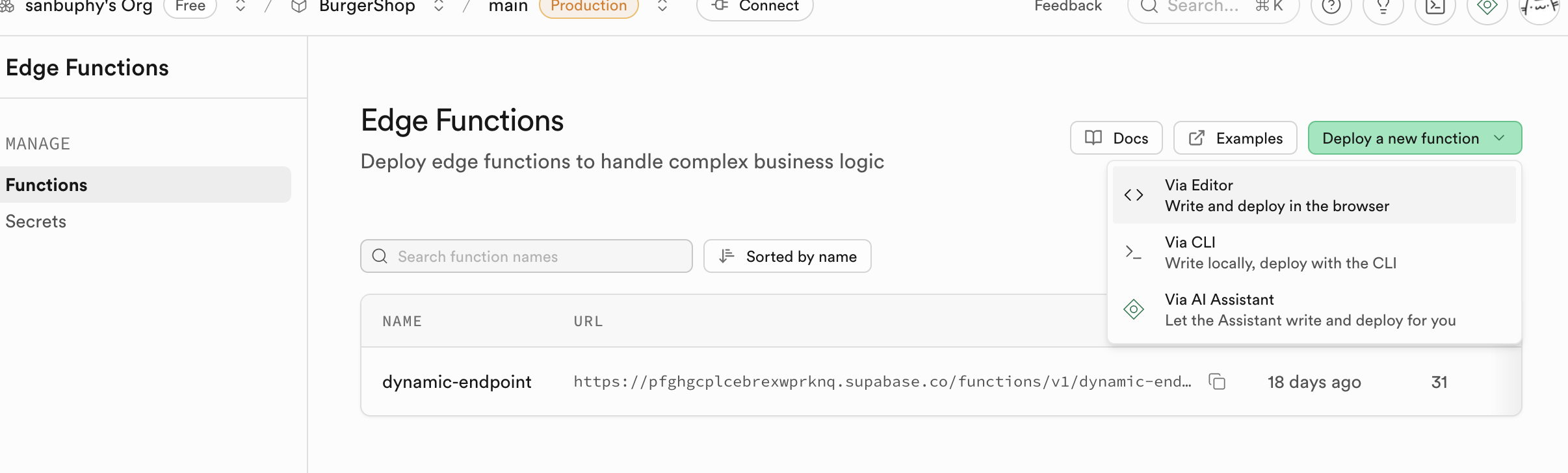
- 為函數命名,例如
llm-chat。 - 粘貼程式碼 :
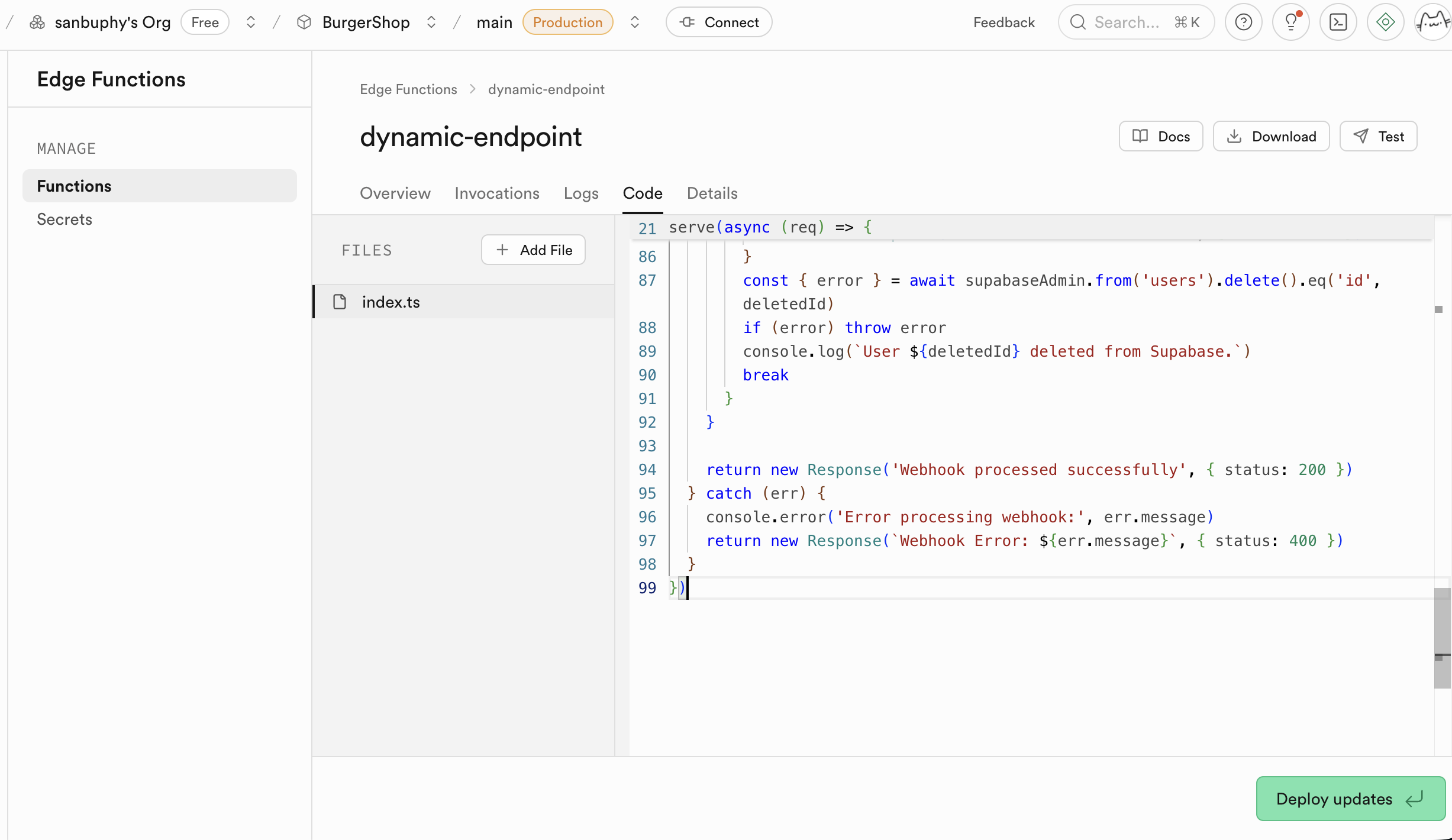
- 在彈出的在線編輯器中, 刪除所有默認的佔位程式碼 。
- 打開你本地的
llm-chat.ts文件, 複製其全部內容 。 - 將複製的程式碼粘貼到 Supabase 的在線編輯器中。
- 配置**環境變量** ** (Secrets)** :
- 在側邊欄找到 Secrets。
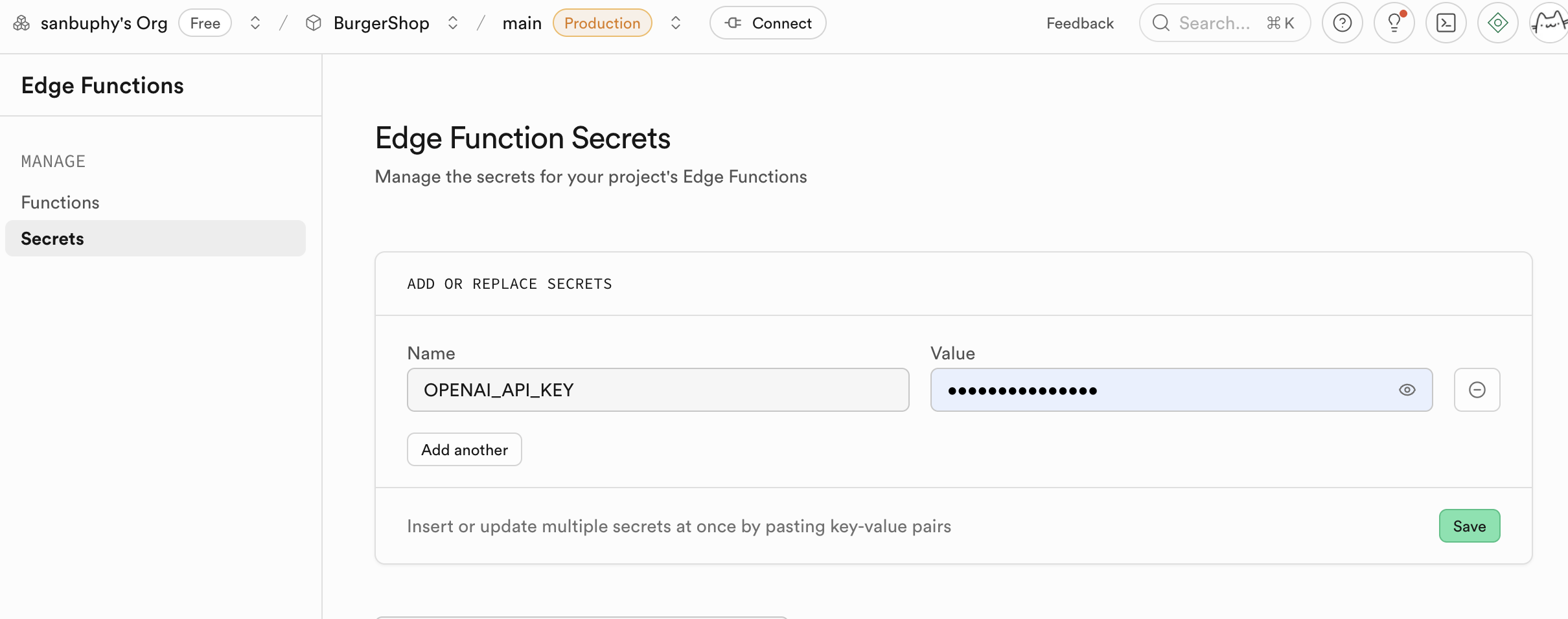
- Name: 輸入
OPENAI_API_KEY。 - Value: 粘貼你自己的 OpenAI API Key。
- 點擊 “Save”。在這裡設置的 Secret 會被加密存儲,並安全地注入到你的函數運行時環境中。
- 在側邊欄找到 Secrets。
若有函數需要更新,記得在 Edge Function 部分執行 Deploy updates。Supabase 會在雲端為你構建並部署這個函數。幾分鐘後,你的函數就可以在線訪問。
除了作為語言模型的安全代理,Edge Functions 的應用場景遠不止於此。實際上,任何需要服務器端邏輯處理的任務,無論是簡單的 API 調用、資料驗證,還是更復雜的計算,都可以通過 Edge Function 實現。它為你提供了一個輕量級、可擴展的後端,而無需管理任何服務器基礎設施。
如果你想探索更多可能性,可以參考項目中的其他示例。例如:
- 圖片生成 ( txt2img.ts ) : 這個函數展示瞭如何利用 Edge Function 調用第三方的文生圖(Text-to-Image)API(如 Stability AI, Midjourney 等)來動態生成圖片。這是一種典型的計算密集型或需要安全調用外部服務的場景。與 llm-chat 案例一樣,API 密鑰被安全地存儲在 Supabase 後端,前端只負責發送文本描述,然後接收並展示生成的圖片,整個過程安全、高效。
- 發送郵件 ( send-email.ts ) : 在應用中發送歡迎郵件、交易通知或密碼重置郵件是常見需求。 send-email.ts 示例演示瞭如何通過 Edge Function 集成郵件服務(如 Resend, SendGrid)。你無需在客戶端程式碼中暴露敏感的郵件服務 API Key,只需創建一個函數,讓前端通過調用這個函數來觸發郵件發送。
5.6 Clerk 登錄
Clerk 是一款專注於身份認證與用戶管理的專業開發工具,核心能力覆蓋用戶註冊、登錄、賬號安全MFA、權限控制、會話管理等全鏈路身份認證相關需求,能幫助開發者快速搭建安全、靈活且符合現代應用標準的用戶體系,無需從零開發複雜的身份邏輯。
本部分將介紹如何從零開始配置 Clerk 服務,並將其與 Supabase 進行整合。你可以在項目 project-burger-shop-auth-advanced-clerk-7 中體驗全流程。
5.6.1 創建 Clerk 應用與獲取密鑰
在使用本項目之前,你需要擁有一個 Clerk 賬號並創建一個應用。
- 註冊與創建:
- 訪問 dashboard.clerk.com 並註冊賬號。
- 點擊 "Create application" 。
- 輸入應用名稱(例如 "Burger Shop")。
- 在 "How will your users sign in?" 中,默認勾選 Email , Google , GitHub 。
- 點擊 Create application 。
- 獲取 API Keys:
創建成功後,你會被引導至 API Keys 頁面。
找到 Publishable key (以
pk_開頭) 和 Secret key (以sk_開頭)。
將它們複製到你的
.env.local文件中(參考本項目.env.example):bashNEXT_PUBLIC_CLERK_PUBLISHABLE_KEY=pk_test_... CLERK_SECRET_KEY=sk_test_...
5.6.2 配置 Supabase 和 Clerk 的原生集成
在進一步使用前,我們需要集成 Supabase 與 Clerk 的關聯關係,方便之後登錄的鑑權跳轉以及控制對特定資料庫的訪問權限。Supabase 與 Clerk 提供官方原生集成能力,通過該集成可快速實現兩者的身份認證打通,無需手動配置複雜的適配邏輯,大幅簡化用戶登錄、權限校驗等功能的開發流程:
- 在 Clerk 中激活對 Supab ase 的官方集成
- 登錄 Clerk Dashboard。
- 在左側菜單導航至 Integrations (集成)。
- 在列表中找到並點擊 Supabase。
- 開啟 Enable Supabase 開關(或點擊 Activate integration)。
- 關鍵步驟:激活成功後,頁面會顯示你的 Clerk Domain(格式通常為
https://<your-id>.clerk.accounts.dev或你的自定義域名)。請複製這個 Domain 地址,下一步會用到。
- 在 Supabase 中添加 Clerk 提供商
- 登錄 Supabase Dashboard 並進入你的項目。
- 在左側菜單導航至 Authentication > Sign In / Up (或者直接點擊 Providers)。
- 點擊 Add provider 按鈕,從下拉列表中選擇 Clerk。
- 在彈出的 Clerk Domain 輸入框中,粘貼你剛才從 Clerk 複製的 Domain 地址。
- 點擊 Save 保存配置。
5.6.3 通過 Webhook 同步用戶資料至 Supabase
僅僅是集成只滿足了鑑定權限的需求,但這並不會將 Clerk 中已經註冊的用戶資訊同步到 Supabase,為了方便管理,我們還需要在 Supabase 的 public.users 表中保留一份用戶備份,以便進行關聯查詢或資料分析。我們可以通過 Clerk Webhooks 實現這一功能,完整過程如下:
- Clerk 發送通知 : 當用戶在 Clerk 註冊或更新資料時,Clerk 會向我們配置的 Webhook URL 發送一個 POST 請求。
- Supabase 接收並寫入 : Edge Function 接收請求,驗證簽名(確保安全),然後將用戶資料更新到 Supabase 的資料庫表中。
在開始之前,我們需要配置同步資訊所需的資料表:
-- File: init.sql
-- 1. Create `users` table for synced Clerk users
-- This table will store user data pushed from Clerk Webhooks.
CREATE TABLE public.users (
id TEXT NOT NULL PRIMARY KEY, -- Corresponds to Clerk User ID
email TEXT,
first_name TEXT,
last_name TEXT,
image_url TEXT,
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW()
);
-- 2. Enable Row Level Security (RLS) on the table
-- This is an important security measure to ensure users cannot access any data by default.
ALTER TABLE public.users ENABLE ROW LEVEL SECURITY;
-- 3. Create RLS policies
-- Policy 1: Allow authenticated users to read their own user info.
-- `auth.jwt()->>'sub'` extracts the user ID from the JWT provided by Clerk.
CREATE POLICY "Authenticated users can view their own user record"
ON public.users FOR SELECT
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );
-- Policy 2: Allow users to update their own info.
CREATE POLICY "Authenticated users can update their own user record"
ON public.users FOR UPDATE
TO authenticated
USING ( (SELECT auth.jwt()->>'sub') = id );以及在 Supabase 中啟用對應的 Edge function:
// File path: supabase/functions/clerk-webhooks/index.ts
import { serve } from 'https://deno.land/std@0.177.0/http/server.ts'
import { Webhook } from 'npm:svix'
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2'
// Get Clerk Webhook signing secret from environment variables
const CLERK_WEBHOOK_SECRET = Deno.env.get('CLERK_WEBHOOK_SECRET')
if (!CLERK_WEBHOOK_SECRET) {
throw new Error('CLERK_WEBHOOK_SECRET is not set in environment variables')
}
const supabaseAdmin = createClient(
Deno.env.get('SUPABASE_URL')!,
Deno.env.get('SUPABASE_SERVICE_ROLE_KEY')!
)
serve(async (req) => {
try {
// 1. Get Svix signature info from request headers
const headers = Object.fromEntries(req.headers)
const svix_id = headers['svix-id']
const svix_timestamp = headers['svix-timestamp']
const svix_signature = headers['svix-signature']
if (!svix_id || !svix_timestamp || !svix_signature) {
return new Response('Missing Svix headers', { status: 400 })
}
const payload = await req.json()
const body = JSON.stringify(payload)
// 2. Verify Webhook signature validity using the secret
const wh = new Webhook(CLERK_WEBHOOK_SECRET)
const evt = wh.verify(body, {
'svix-id': svix_id,
'svix-timestamp': svix_timestamp,
'svix-signature': svix_signature,
})
const { id } = evt.data
const eventType = evt.type
console.log(`Received webhook event: ${eventType} for user: ${id}`)
// 3. Execute database operations based on event type
switch (eventType) {
case 'user.created': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin.from('users').insert({
id,
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
})
if (error) throw error
console.log(`User ${id} created in Supabase.`)
break
}
case 'user.updated': {
const { id, first_name, last_name, image_url, email_addresses } = evt.data
const { error } = await supabaseAdmin
.from('users')
.update({
first_name,
last_name,
image_url,
email: email_addresses[0]?.email_address,
updated_at: new Date().toISOString(), // Update timestamp
})
.eq('id', id)
if (error) throw error
console.log(`User ${id} updated in Supabase.`)
break
}
case 'user.deleted': {
// For delete events, ID might be at the top level
const deletedId = id
if (!deletedId) {
return new Response('Deleted user ID not found', { status: 400 })
}
const { error } = await supabaseAdmin.from('users').delete().eq('id', deletedId)
if (error) throw error
console.log(`User ${deletedId} deleted from Supabase.`)
break
}
}
return new Response('Webhook processed successfully', { status: 200 })
} catch (err) {
console.error('Error processing webhook:', err.message)
return new Response(`Webhook Error: ${err.message}`, { status: 400 })
}
})初始化 Supabase 資料表與函數結束後,你還需要在 Clerk 中啟用 Webhooks 支持:
- 在 Clerk Dashboard -> Webhooks 中添加 Endpoint,填入Supabase Edge Function 的 URL。
- 勾選
user.created,user.updated,user.deleted等事件。
一旦設置成功,你能夠在 Message Attempts 中看到不同請求資訊,點擊後可看到詳細的請求返回參數結果;如果 webhook 在請求 Edge function 時出現問題,你可以快速在返回值中找到詳細原因結果。推薦你同時對照 Clerk 和 Supabase 的請求日誌資訊,用於分析各個函數設定是否正確。
5.6.4 Clerk 中的第三方登錄支持
在深入瞭解如何對 Clerk 支持第三方登錄前,我們先明確兩個核心概念:開發環境與生產環境,這是軟體從 “開發測試” 到 “上線可用” 的兩個關鍵階段,二者的定位、用途和安全要求截然不同:
- 開發環境:開發者本地或測試服務器使用的環境,僅用於功能開發、調試和內部驗證(如本地 localhost:3000 服務),不對外開放
- 生產環境:應用正式上線後,面向真實用戶的公開環境(如部署在 Vercel、阿里雲等平臺的 https://my-app.com)
而 Clerk 對社交登錄區分這兩種環境,本質是平衡 “開發效率” 與 “生產安全”:開發階段需減少冗餘配置以快速驗證功能,生產階段需通過專屬憑證保障資料安全,同時符合 Google、GitHub 等第三方 OAuth 平臺的規則(線上應用必須綁定專屬域名與憑證,不允許使用共享資源)。下面具體說明兩種環境下 Clerk 社交登錄的差異配置:
- 開發環境快速驗證
開發環境中,Clerk 已預置共享 OAuth 憑證和默認重定向 URI,無需前往 GitHub/Google 申請專屬憑證,操作步驟如下:
登錄 Clerk Dashboard ,在左側導航欄進入 SSO connections (SSO 連接)頁面。
點擊 Add connection (添加連接),選擇 For all users (對所有用戶生效)。
在 Choose provider (選擇提供商)下拉菜單中,按需選擇 GitHub 或 Google 。
直接點擊 Add connection (添加連接),Clerk 會自動用共享憑證完成綁定。
配置後,本地啟動應用(如
localhost:3000)並點擊“Sign in with GitHub/Google”,Clerk 會自動代理登錄請求,快速驗證功能是否正常。
- 生產環境自定義憑證配置
(注:如果發現有環節和預期不一致,建議閱讀官方文檔進行最新方式的嘗試)
應用部署上線(如 Vercel、阿里雲)並切換到 Clerk Production Instance 後,共享憑證失效,需為 GitHub/Google 配置自定義 OAuth 憑證(建議同時打開 Clerk Dashboard 和第三方平臺頁面,方便同步操作):
- 前置通用操作(Clerk 控制檯):
- 進入 Clerk SSO connections 頁面,點擊 Add connection → 選擇 For all users 。
- 選擇目標平臺(GitHub/Google),確保開啟 Enable for sign-up and sign-in (允許註冊登錄)和 Use custom credentials (使用自定義憑證)。
- 複製頁面中的 Authorization Callback URL (GitHub)或 Authorized Redirect URI (Google),保存到安全位置,不要關閉當前頁面/彈窗。
- 2.1 GitHub 平臺配置:
- 登錄 GitHub,進入 Developer Settings (路徑:頭像 → Settings → Developer settings → OAuth Apps)。
- 點擊 New OAuth app ,填寫資訊:
Application name(應用名稱)、Homepage URL(生產域名,如https://my-app.com)、Authorization Callback URL(粘貼從 Clerk 複製的地址)。 - 點擊 Register application ,再點擊 Generate a new client secret ,保存生成的 Client ID 和 Client Secret (Secret 僅顯示一次)。
- 回到 Clerk 彈窗,粘貼 Client ID 和 Client Secret,點擊 Add connection 完成配置(若關閉彈窗,可在 SSO connections 找到 GitHub 連接,在“Use custom credentials”模塊補填)。
- 2.2 Google 平臺配置:
- 登錄 Google Cloud Console ,選擇已有項目或新建項目(如“My App Production”)。
- 點擊左上角菜單 → APIs & Services → Credentials ,點擊 Create Credentials → OAuth client ID (首次配置需先完成 OAuth consent screen 設置,選擇“External”並填寫應用資訊)。
- 選擇 Application type 為 Web application ,配置:
Authorized JavaScript origins:添加生產域名(如https://my-app.com、https://www.my-app.com),本地驗證可補充http://localhost:端口號。Authorized Redirect URIs:粘貼從 Clerk 複製的地址。
- 點擊 Create ,保存彈窗中的 Client ID 和 Client Secret ,回到 Clerk 彈窗粘貼並點擊 Add connection 。
- 關鍵注意事項:
- 禁止 WebView 登錄:Google OAuth 不支持應用內瀏覽器登錄,需參考 Google 官方文檔 調整。
- 切換髮布狀態:默認“Testing”狀態僅支持 100 個測試用戶,需在 OAuth consent screen 將“Publishing status”改為 In production (需通過 Google 審核)。
- 阻止子郵箱:Clerk 默認攔截含
+/=/#的 Google 郵箱(如user+alias@example.com),可在 Google 連接詳情頁開啟/關閉 Block email subaddresses (建議開啟提升安全性)。 - 支持 Google One Tap:配置完成後,可集成 Clerk
<GoogleOneTap />組件實現“一鍵登錄”,參考 Clerk 組件文檔。
- 測試第三方登錄連接
配置完成後,通過 Clerk 內置 Account Portal 驗證功能:
- 進入 Clerk Dashboard,左側導航欄進入 Account Portal 頁面。
- 在“Sign-in”模塊右側,點擊“訪問登錄頁面”按鈕,跳轉至對應環境登錄頁:
- 開發環境:
https://你的域名.accounts.dev/sign-in(如https://my-app.accounts.dev/sign-in)。 - 生產環境:
https://accounts.你的域名.com/sign-in(如https://accounts.my-app.com/sign-in)。
- 開發環境:
- 點擊“Sign in with GitHub/Google”,用對應平臺賬號登錄,若能成功跳轉並返回應用,說明連接配置正常。
6. 從 Supabase 到更多後端開發組件(進階)
在上文中,我們主要是站在 Supabase 的視角,去看“一個以 Postgres 為核心的一站式後端平臺”能幫我們解決哪些問題:認證、資料庫、文件存儲、實時通信、邊緣函數等,都被集成在同一個控制檯裡,開箱即用、體驗統一,非常適合快速起步和中小型項目。
但從更長期、更工程化的角度來看, Supabase 提供的每一塊能力(Auth / Storage / Edge Functions / Realtime / Database),在業界幾乎都有對應的專業替代方案 ——既包括同類 BaaS 平臺,也包括更“單點突破”的雲服務和開源組件。作為上進的個人開發者和初創團隊來說,瞭解這些替代選項有幾個好處:
- 判斷當前項目是否“全用 Supabase 就夠了”,還是某一塊需要更專業/更便宜/更易合規的專用服務;
- 當項目規模變大或需求變複雜時,是否可以把某個模塊從 Supabase 替換出去(例如改用專門的 Auth 平臺或對象存儲),而不是一開始就被平臺徹底鎖死;
- 拓寬技術選型視野,即使暫時不更換,也能大致知道“如果不用 Supabase 的 X 功能,我還有哪些常見選擇”。
本節將分別介紹 Supabase 所覆蓋的幾大能力在市場上的主流替代方案,例如:認證(Auth)、文件存儲(Storage)、邊緣函數(Edge Functions)、實時通信(Realtime)、資料庫託管等。簡單對比它們在功能特性、免費額度/定價、易用性以及社區流行度等方面的差異, 讓你對後端組件工具庫有更全面的理解。
同類 Baas 平臺
在開始之前,我們可以瀏覽同類的 Baas 平臺,若覺得 Supabase 不夠好用,你可以根據需求選擇不同替代品進行嘗試。
| 平臺/服務 | 類型 | 免費額度/定價 | 特點 / 適用場景 |
|---|---|---|---|
| Firebase(Google) | 全託管 BaaS(Auth + Firestore + Storage + Functions + Hosting) | Spark:免費輕量額度;Blaze:按量計費(Firestore/Storage/Functions 分別算) | 行業最成熟、文檔好、上手快、實時能力強。適用於中小型產品、移動/前端主導團隊。缺點:計費複雜、鎖定性強、查詢限制多(尤其 Firestore)。 |
| Supabase | 開源 BaaS(Postgres + Auth + Storage + Edge Functions + Realtime) | 免費:500MB DB、1GB Storage、無服務器函數少量調用;Pro:按實例計費 | 最像 Firebase 的 SQL 版;界面優秀、體驗現代、可自託管。適用於需要強 SQL、BI、事務能力的應用。缺點:高併發或複雜函數成本較高。 |
| Appwrite Cloud | 開源一站式 BaaS(DB + Auth + Storage + Functions + Realtime) | 免費:包含基本 DB/Storage/FaaS;付費按資源級別計費 | 體驗現代化、API 統一、可自託管;適合開發者友好的應用快速迭代。缺點:生態還不如 Firebase/Supabase 成熟;性能在大型應用中需要測試。 |
| Nhost | Postgres + GraphQL + Auth + Storage + Functions | 免費:1GB DB、1GB Storage、少量函數調用 | 類似“Supabase + Hasura”;天然 GraphQL;適合前端團隊與 React/Next.js 項目。缺點:生態小、成本隨用量升高。 |
| AWS Amplify | AWS 一站式後端(Cognito + AppSync + DynamoDB + Storage + Functions + Hosting) | 免費:Hosting 額度 + Cognito 10k MAU + 部分函數額度 | 大而全,適合已有 AWS 基礎的團隊;企業級可靠性。缺點:最難上手,服務碎片化;初創團隊維護成本高。 |
| Xata(近兩年快速增長) | 多模型資料庫 + Auth + Edge Functions | 免費:250k 記錄、15GB 帶寬 | 雖然更偏「DB + API」,但提供 Auth、文件、邏輯,可作為輕量全棧後端。UI/開發體驗極佳。缺點:功能不如 Firebase/Supabase 全面。 |
| Convex(開發者體驗極強) | 託管資料庫 + Auth + Functions(前端優先) | 免費開發版;付費按請求量計費 | 極簡上手;無需 schema;前端寫函數即可用後端。適合 MVP/快速驗證。缺點:高度綁定平臺,遷移成本高;不算完全傳統 BaaS。 |
認證 (Auth)
| 工具/平臺 | 功能特點 | 免費額度/定價 | 適用場景與優缺點 |
|---|---|---|---|
| Firebase Authentication | Google 提供的 BaaS 身份驗證服務,支持郵箱/密碼、手機、社交登錄、匿名等常見方式。Spark 免費方案支持最高50k 月活躍用戶。 | Spark(免費)50k MAU;Blaze 按量計費 | 集成 Google 生態,文檔豐富,上手簡單;功能全面(MFA、阻塞函數等),適合快速開發。但與 Firebase 平臺綁定,擴展到其他服務需額外配置。 |
| Auth0 (Okta) | 全託管身份認證平臺,支持社交登錄、企業 SSO、多因子認證、規則擴展等強大功能。 | 免費方案25k MAU,付費按 MAU 計費 | 企業級功能齊全(RBAC、審計日誌等),適合中大型應用;界面友好。缺點是 MAU 上升時成本高,免費版功能有限(如不含 MFA/RBAC)。社區知名度高,用戶眾多。 |
| AWS Cognito | 亞馬遜雲原生身份服務,支持社交及 SAML 聯合登錄。直接登錄用戶池提供每月10k MAU 免費,超過部分按 0.0055 美元/MAU 收費。 | 免費10k MAU/月,超出按量付費 | 與 AWS 生態深度集成(可無縫配合 API Gateway、Lambda 等),入門門檻略高,文檔較複雜;免費額度有限,適合已有 AWS 使用習慣的團隊。 |
| Logto | 開源身份認證平臺,自託管版免費,雲服務計劃免費50k MAU。支持多語言、多租戶、OAuth/OIDC 等。 | 社區版免費;Logto Cloud 免費50k MAU | 近期流行的 Auth0 開源替代方案,GitHub 已有 10k+ Stars。易擴展,自託管降低成本;缺點是生態和文檔相對較新,社區規模略遜於 Firebase/Auth0。 |
| Keycloak | 知名開源 IAM/SSO 解決方案,支持用戶名密碼、LDAP、SAML、OAuth2 等。 | 完全免費,需自託管 | 功能強大、可擴展(支持細粒度權限控制),企業級功能豐富;但部署和維護複雜度高,對小團隊而言學習曲線較陡。缺點是對容器化和集群運維要求較高。 |
文件存儲 (Storage)
| 平臺/服務 | 類型 | 免費額度/定價 | 特點/適用場景 |
|---|---|---|---|
| Amazon S3 | 雲對象存儲(AWS) | AWS 免費套餐提供 5GB 存儲、20k GET/PUT 請求/月,超出按使用量付費 | 行業標準的對象存儲,可靠性高、全球多區域部署。功能全面,與 AWS 生態整合良好;定價較複雜,新用戶需瞭解計費規則。 |
| Google Cloud Storage(Firebase Storage) | 雲對象存儲(Google) | Firebase Spark 方案提供免費額度(1GB 存儲 + 流量限制),Blaze 付費 | 與 Firebase/Google Cloud 緊密集成,易於管理;支持 CDN 加速、細粒度安全規則。 |
| 騰訊雲 COS / 阿里雲 OSS | 雲對象存儲(國內) | 按量付費(各有新用戶贈送額度,如OSS有首年40GB免費等) | 面向國內市場,高性能、大規模對象存儲;與中國雲生態整合,文檔較完善。阿里OSS 功能全面、全球加速;七牛KODO 專注多媒體處理,成本較低,適合個人和小團隊。 |
| MinIO | 開源 S3 兼容存儲 | 開源免費(自建) | 輕量級、高性能、與 S3 API 兼容,適合在私有云或本地搭建對象存儲。文檔和社區活躍;需自己維護基礎設施。 |
| Cloudinary / Imgix 等 | 媒體存儲+CDN | 基本免費方案(如 Cloudinary 免費 25GB/月帶寬) | 針對圖片/影片優化的雲存儲+CDN 服務,提供實時轉碼、壓縮等高級功能。適合媒體項目,但功能較專一,作為通用文件存儲使用成本偏高。 |
邊緣函數 (Edge Functions)
| 平臺/服務 | 特點 | 免費額度/定價 | 適用場景與優缺點 |
|---|---|---|---|
| Cloudflare Workers | 全球分佈式 JavaScript/Wasmtime 環境 | 免費計劃:每天 100k 請求;標準計劃$5/月含1,000萬請求 | 運行在 Cloudflare 邊緣節點,延遲極低;適合全局分發的邏輯、靜態資源渲染等。免費配額較少(相當於每月約300萬請求),上手簡單。缺點是運行時(JS/Wasmtime)限制與調試工具有限。 |
| Vercel Edge Functions | 隨 Next.js/前端框架無縫集成,支持 JS/TS/Go | Hobby 免費:每月 100萬 函數調用,100萬 邊緣請求 | 深度集成前端框架,自動部署;適合現代 Web 應用。免費額度充足,默認運行時 10s,可提升至 60s。缺點是免費版團隊協作功能受限;依賴 Vercel 平臺。 |
| Netlify Edge / Functions | Node.js 雲函數+邊緣路由(NFT) | 免費:300 代幣/月(約相當於每月 1M 請求);按信用點計費 | 支持 Node.js 函數、邊緣處理路由等。免費額度用於構建、函數和帶寬,適合前端全棧部署。優點是簡便易用,集成 Git 部署;缺點是免費額度使用需算計(10k 請求 = 3 點)。 |
| AWS Lambda@Edge / CloudFront Functions | AWS 無服務器邊緣計算 | AWS Lambda(1M 免費請求/月+400k GB-s)+ CloudFront $0.085/每10萬調用起 | 與 CloudFront 集成,可在邊緣執行程式碼。適合需要 AWS 生態(如在節點層面做權限或 A/B 測試)。優點是靈活強大;缺點是配置複雜,延遲略高於 Cloudflare/Vercel。 |
實時通信 (Realtime)
| 平臺/服務 | 功能特點 | 免費額度/定價 | 適用場景與優缺點 |
|---|---|---|---|
| Firebase Realtime Database / Firestore | Google BaaS 實時資料庫;支持資料變更推送 | Spark 免費:實時資料庫1GB 存儲 & 限額;Blaze 按量付費 | 強集成 Firebase 生態,實時監聽簡單。優點是免費起步快;缺點是資料庫類型(JSON/NoSQL),複雜查詢能力弱。 |
| Ably | 實時消息與 pub/sub 平臺,支持 WebSocket、MQTT 等 | 免費包:每月 6,000,000 條消息 | 功能全面的實時消息服務,高併發支持;免費額度可達600萬消息/月。社區與文檔較好,適合全球分佈。 |
| Pusher Channels | 事件推送服務,支持頻道/事件機制 | Sandbox 免費:每日 200k 消息,100 併發連接 | 易用的 WebSocket 服務,文檔齊全,適合快速實現聊天和通知功能。免費版限制消息量和連接數;付費後擴展性好。 |
| 自建 WebSocket/Socket.IO | 自己搭建服務器(Node.js、Elixir 或 Go 等) | 自行託管成本(如服務器費用) | 靈活度最高,可根據需求定製協議和拓撲。適合對成本控制嚴格且技術成熟的團隊。缺點是需自行處理可用性、擴展和跨域等問題。 |
資料庫
| 平臺/工具 | 資料庫類型 | 免費額度/定價 | 主要特點 |
|---|---|---|---|
| Neon (Serverless PostgreSQL) | 關係型(PostgreSQL) | 免費計劃:0.5GB 存儲,主分支永久在線,20h 分支計算/月 | 雲原生無服務器 Postgres,支持自動伸縮和分支(fork 測試)。免費額度對小項目夠用,適合現代開發流程。分支功能強大,但免費額度較小。 |
| Aiven PostgreSQL | 關係型(PostgreSQL/MySQL) | 免費計劃:1GB 存儲,1 vCPU,1GB 內存 | 託管級資料庫服務,支持跨雲多區域遷移。提供有 MySQL、Redis 等可選。免費額度適合開發和小型項目;商業版支持高可用集群和監控。 |
| CockroachDB Cloud | 分佈式 SQL(兼容 PostgreSQL) | 免費計劃:10GB 存儲 | 類似 Google Spanner 的分佈式 SQL 資料庫,自動分片擴展。免費10GB 空間較慷慨;適合需要橫向擴展和高一致性的應用。商業版 SLA 高。 |
| TiDB Cloud | 分佈式關係型(MySQL 兼容) | 免費計劃:每節點5GB,總計最多25GB | 開源 TiDB 的雲版,兼容 MySQL 協議,分佈式架構。免費額度充足,適合熟悉 MySQL 的團隊,性能優秀;缺點是運維相對複雜(針對大型場景)。 |
| MongoDB Atlas | 文檔型(NoSQL MongoDB) | 免費 M0 集群:0.5GB 存儲 | 雲端 MongoDB,靈活的文檔模型,支持豐富查詢和索引。免費 0.5GB 資料庫適合測試和小型應用;可按需橫向擴展。學習曲線略高於關係型資料庫。 |
| SQLPub | 多資料庫(MySQL、PostgreSQL、Redis 等) | 免費計劃:36,000 請求/小時,30 併發連接,500MB 存儲 | 一站式資料庫平臺,支持多種資料庫類型。免費版適合學習和小項目;優點是支持多種 DB,缺點是存儲額度較小。 |
以上替代方案各有側重:開源更靈活可控(Keycloak、MinIO、Socket.IO、Neon、CockroachDB 等),雲託管服務更易上手(Firebase、Auth0、Cloudflare、Vercel、Netlify、AWS、Aiven、MongoDB Atlas 等)。選擇時可根據項目需求、團隊技術棧、預算和社區生態等權衡。個人項目可優先選用免費配額充足、易集成的服務(如 Firebase 系列、七牛存儲、Cloudflare Workers、Neon、CockroachDB 等),而對企業級或特定安全需求,則可考慮功能更豐富但收費較高的方案(Auth0、Alibaba/Tencent 雲、AWS、TiDB/Aiven 等)。你可以在實際應用中不斷嘗試,直到選擇出最適合的後端開發工具組件。
總結
在今天的課程中,我們系統學習了資料庫的基礎概念、Supabase 的核心定義及其操作細節。後續在實踐過程中,你可根據項目的實際應用場景與需求,隨時回頭翻閱這份文檔作為參考。
請時刻記住一個重要原則: 先完成,再完美! 無需追求一步到位,我們完全可以通過持續迭代優化,逐步靠近更優的成果。祝你在後續的項目實踐中一切順利!
📚 課後作業
- 開發一個包含用戶管理系統和資料庫的應用程序。最好包含更多的Supabase 功能 (Realtime / cloud storage / Edge function).