從 NanoBanana 出發,搭建自己的素材生產Agent
第 1 章:1 分鐘生成第一份圖片素材
在開始討論設計、風格或提示詞之前,我們先用最少的步驟生成第一張圖片。
1.1 認識 NanoBanana
在開始討論設計風格、提示詞工程之前,我們先解決一件更重要的事:確認你真的可以生成一張圖片。
當前主流的大模型已經具備圖像生成與編輯能力,這類模型通常被稱為生成式模型。
為了把流程儘量簡化,本教程選擇了一個已經具備穩定圖像生成與編輯能力的模型作為示例——NanoBanana。它是 Google 推出的圖像生成模型,正式名稱為 Gemini 3.1 Flash Image Preview ,支持通過自然語言直接生成圖片,也支持在已有圖片基礎上進行修改。

在能力層面,它和你可能聽說過的其他模型(如 GPT-4o、Claude、Qwen、Midjourney 等)並沒有本質區別:輸入描述,模型負責生成結果。



你可以把它理解為一支“畫筆”。我們在這一章只關心一件事: 👉 這支畫筆能不能在你手裡畫出第一筆。
在實際使用中,NanoBanana 可以通過 Google AI Studio 等官方平臺直接使用,也可以通過 API 的方式集成到開發流程中。本教程採用 API 調用方式。現在還推出了NanoBanana 2模型,你可以使用最新的大模型進行嘗試。
1.2 “Hello World” 級別的生成
在開始之前,你只需要完成下面三步:
- 在 Trae 中新建一個文件夾
- 新建一個 Python 文件
- 將下面的程式碼完整粘貼進去
Trae 會自動完成所需的環境部署與依賴安裝,不需要額外配置。
程式碼中會用到 NanoBanana 的 API Key。這裡不展開申請流程——只要你能獲取並填入對應參數即可。這一階段不追求理解每一行程式碼,只要它能成功運行。
# /// script
# dependencies = [
# "gradio>=4.0.0",
# "pillow>=10.0.0",
# "requests>=2.31.0",
# ]
# ///
import gradio as gr
import requests
import base64
from PIL import Image
import io
import os
import time
import re
from typing import Optional, Dict, Any, List
# 配置 API 資訊
NANOBANANA_API_URL: str = "YOUR API URL"
NANOBANANA_API_KEY: str = "YOUR API KEY"
OUTPUT_DIR: str = "outputs"
# 確保輸出目錄存在
os.makedirs(OUTPUT_DIR, exist_ok=True)
def image_to_base64_data_uri(image: Image.Image) -> str:
"""
將 PIL 圖像轉換為 OpenAI API 兼容的 data URI 格式。
"""
buffer = io.BytesIO()
# 統一轉為 PNG 以保證兼容性
image.save(buffer, format="PNG")
encoded = base64.b64encode(buffer.getvalue()).decode('utf-8')
return f"data:image/png;base64,{encoded}"
def base64_to_image(base64_str: str) -> Optional[Image.Image]:
"""
將純 base64 字符串轉換為 PIL Image。
"""
try:
image_bytes = base64.b64decode(base64_str)
return Image.open(io.BytesIO(image_bytes))
except Exception as e:
print(f"Base64 解碼失敗: {e}")
return None
def extract_base64_from_response(content: Any) -> Optional[str]:
"""
核心解析邏輯:從 API 返回的 content 中提取圖片 Base64 資料。
兼容 Markdown 格式和結構化列表格式。
"""
if not content:
return None
base64_data = None
# 1. 嘗試結構化提取 (List)
# 對應返回格式: [{"type": "image_url", "image_url": {"url": "data:..."}}]
if isinstance(content, list):
for part in reversed(content): # 倒序查找,通常最新的圖片在最後
if isinstance(part, dict):
# 檢查 image_url 或 output_image 字段
img_field = part.get("image_url") or part.get("image") or part.get("output_image")
if isinstance(img_field, dict):
url = img_field.get("url", "")
if url.startswith("data:image/") and "," in url:
return url.split(",", 1)[1].strip()
# 如果列表中沒有結構化圖片,嘗試把列表裡的文本拼起來找 Markdown
text_parts = [
str(p.get("text", ""))
for p in content
if isinstance(p, dict) and p.get("type") in ["text", "input_text"]
]
content_str = "".join(text_parts)
else:
content_str = str(content)
# 2. 嘗試 Markdown 正則提取 (String)
# 對應返回格式: "Here is your image: "
pattern = re.compile(r"!\[.*?\]\((data:image/[^;]+;base64,[^)]+)\)", re.IGNORECASE)
match = pattern.search(content_str)
if match:
data_url = match.group(1)
if "," in data_url:
return data_url.split(",", 1)[1].strip()
return None
def synthesize(prompt: str, input_image: Optional[Image.Image]) -> Optional[Image.Image]:
"""
調用 Nanobanana API 進行生成。
"""
if not prompt or not prompt.strip():
gr.Warning("請輸入提示詞")
return None
print(f">>> 開始任務: {prompt[:50]}...")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {NANOBANANA_API_KEY}"
}
# 構造符合 OpenAI Vision / Chat 標準的 payload
messages = []
if input_image is not None:
# 圖生圖/多模態輸入模式
print(">>> 檢測到輸入圖片,使用多模態模式")
img_base64 = image_to_base64_data_uri(input_image)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": img_base64}}
]
})
else:
# 純文生圖模式
messages.append({
"role": "user",
"content": prompt
})
payload = {
"messages": messages,
# 使用第一段程式碼中驗證可用的模型
"model": "gemini-2.5-flash-image",
# 可選參數,視 API 支持情況而定
"stream": False
}
try:
# 增加超時時間,圖片生成通常較慢
response = requests.post(NANOBANANA_API_URL, headers=headers, json=payload, timeout=120)
# 檢查 HTTP 狀態
if response.status_code != 200:
error_msg = f"API 請求失敗: {response.status_code} - {response.text}"
print(error_msg)
gr.Error(error_msg)
return None
result = response.json()
# Debug: 打印返回結果的前一部分,方便調試
print(f"API 原始響應 (截取): {str(result)[:200]}...")
# 提取 Content
content = None
if "choices" in result and len(result["choices"]) > 0:
content = result["choices"][0].get("message", {}).get("content")
if not content:
gr.Warning("API 返回結果中沒有 content 字段")
return None
# 使用之前驗證過的邏輯提取 Base64
base64_str = extract_base64_from_response(content)
if base64_str:
output_image = base64_to_image(base64_str)
if output_image:
return output_image
# 如果沒提取到圖片,可能是模型拒絕了或只返回了文本
text_content = str(content) if not isinstance(content, list) else " ".join([str(x) for x in content])
gr.Info(f"未生成圖片,模型返回文本: {text_content[:100]}...")
return None
except requests.exceptions.Timeout:
gr.Error("請求超時,請稍後重試")
return None
except Exception as e:
import traceback
traceback.print_exc()
gr.Error(f"發生未知錯誤: {str(e)}")
return None
# Gradio 界面配置
with gr.Blocks(title="Nanobanana Image Generator") as app:
gr.Markdown("# 🍌 Nanobanana Text/Image to Image")
gr.Markdown("基於 Gemini-2.5-Flash-Image 模型,支持文生圖與圖生圖。")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(
label="提示詞 (Prompt)",
placeholder="例如: A cyberpunk cat holding a neon sign...",
lines=3
)
image_input = gr.Image(
label="參考圖 (可選,用於圖生圖)",
type="pil",
height=300
)
submit_btn = gr.Button("開始生成", variant="primary")
with gr.Column():
image_output = gr.Image(label="生成結果", format="png")
submit_btn.click(
fn=synthesize,
inputs=[prompt_input, image_input],
outputs=image_output
)
if __name__ == "__main__":
app.launch(share=True)當 Trae 提示運行成功後,點擊它提供的本地鏈接(通常是 http://127.0.0.1:7860)。
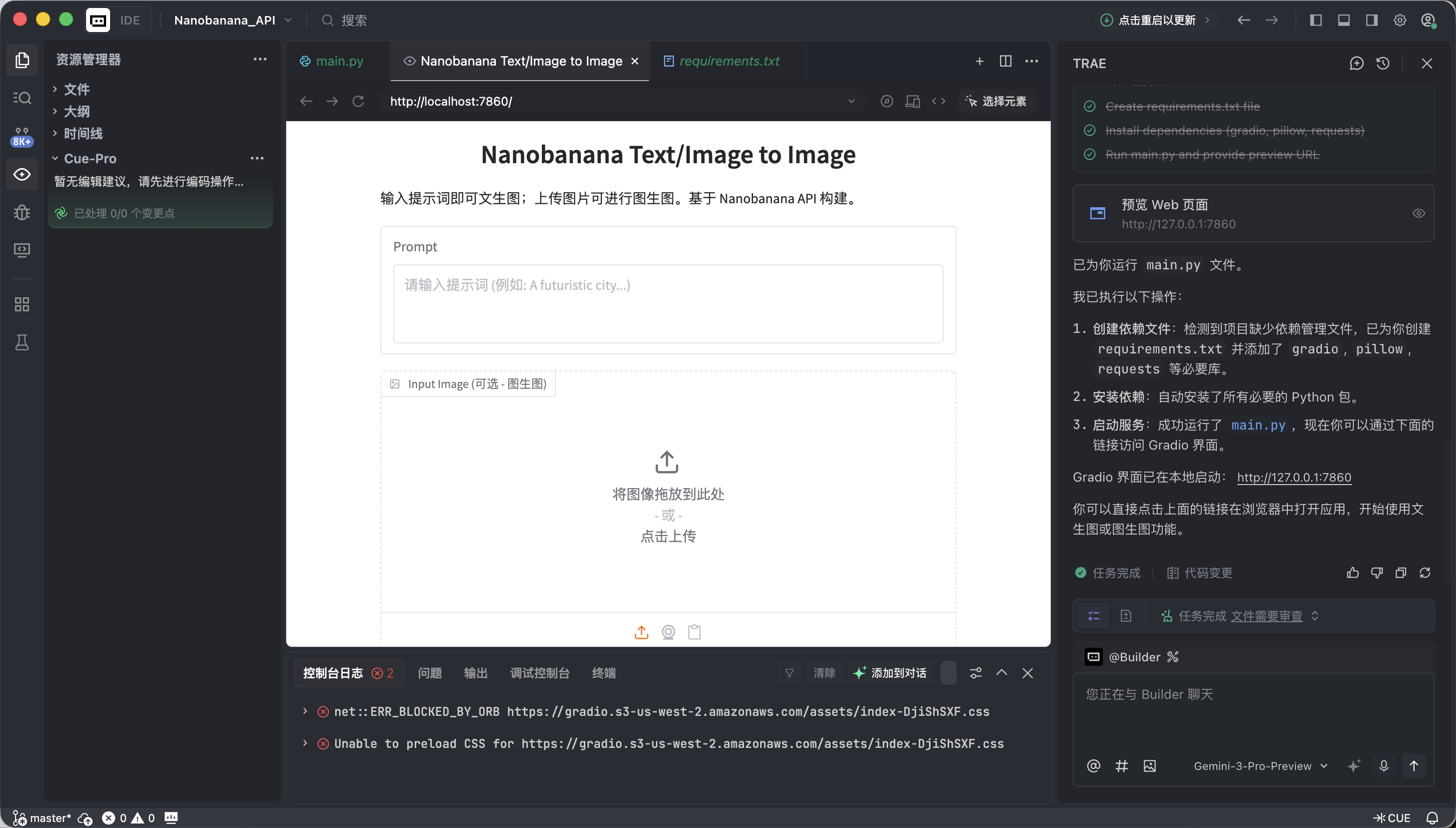
如果一切正常,你會看到一個已經可以工作的 AI 繪圖界面。
這個界面看起來很簡單,但它已經具備了商業級繪圖工具中最核心的兩項能力,即文生圖和圖生圖。
- 左側: 指令區 ( Input Zone) —— 你在這裡發號施令。
- Prompt (提示詞框): 輸入你的創意描述(推薦使用英文)。
- Input Image (參考圖框):
- 文生圖模式: 保持此處 為空 。
- 圖生圖模式: 將本地圖片拖入此處,AI 會以它為基礎進行創作。
- Submit 按鈕: 點擊即可發送指令,開始生成。
- 右側:展示區 ( Output Zone) —— 見證奇蹟的地方,生成結果將在此顯示。
現在我們可以嘗試生成你的第一張圖片了!
本示例使用的 prompt 如下:
A red apple
這是一個刻意簡化的示例,不包含任何風格或參數描述。
實際流程
運行程式碼後,流程可以概括為三步:
- 將文字描述發送給模型
- 模型生成對應圖片
- 圖片被保存為本地文件
幾秒鐘後,你會在本地看到生成結果。而模型生成具有隨機性,所以相同的prompt會有不同的生成結果,你可以多次生成,選擇你心儀的圖片。
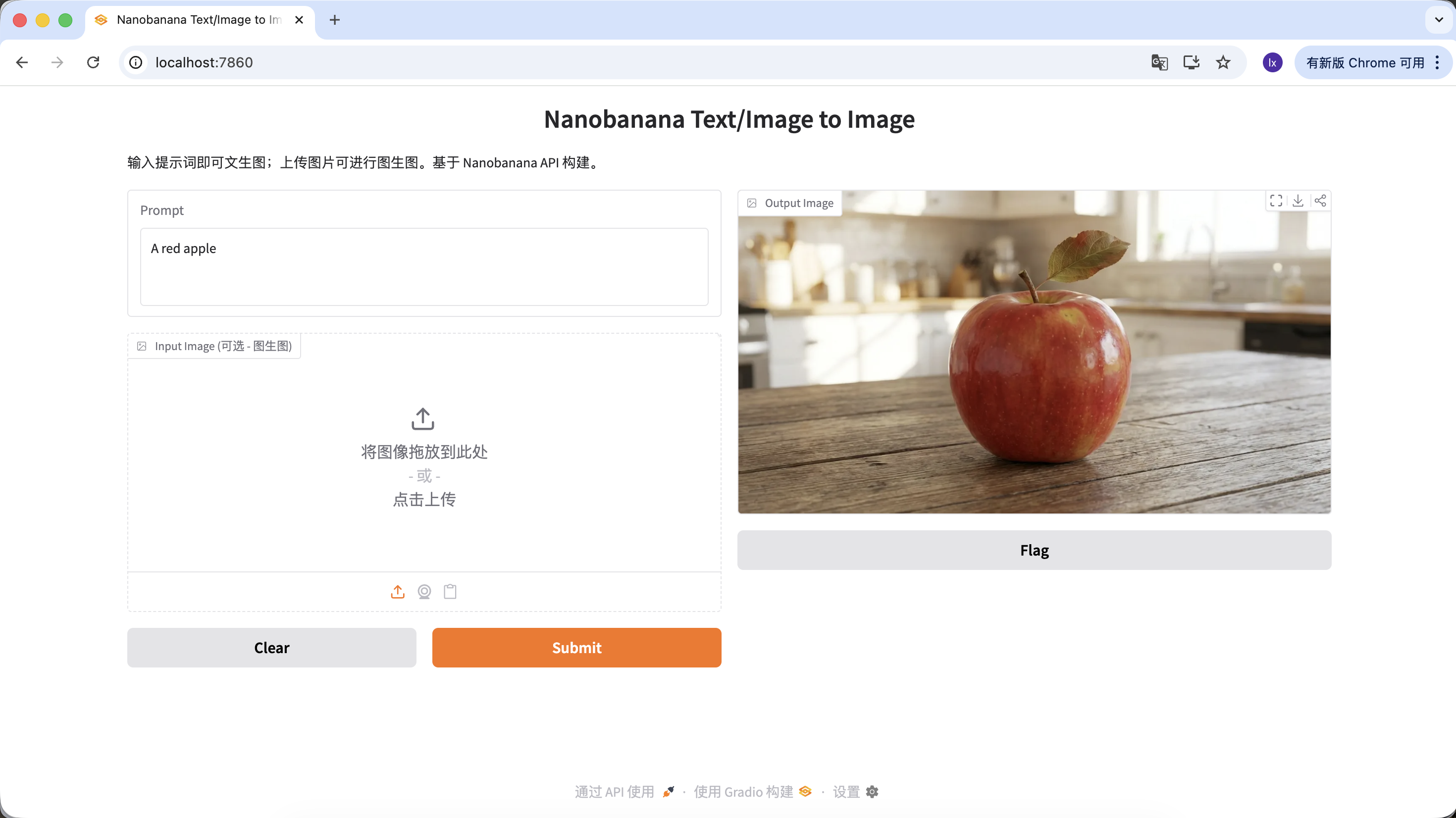
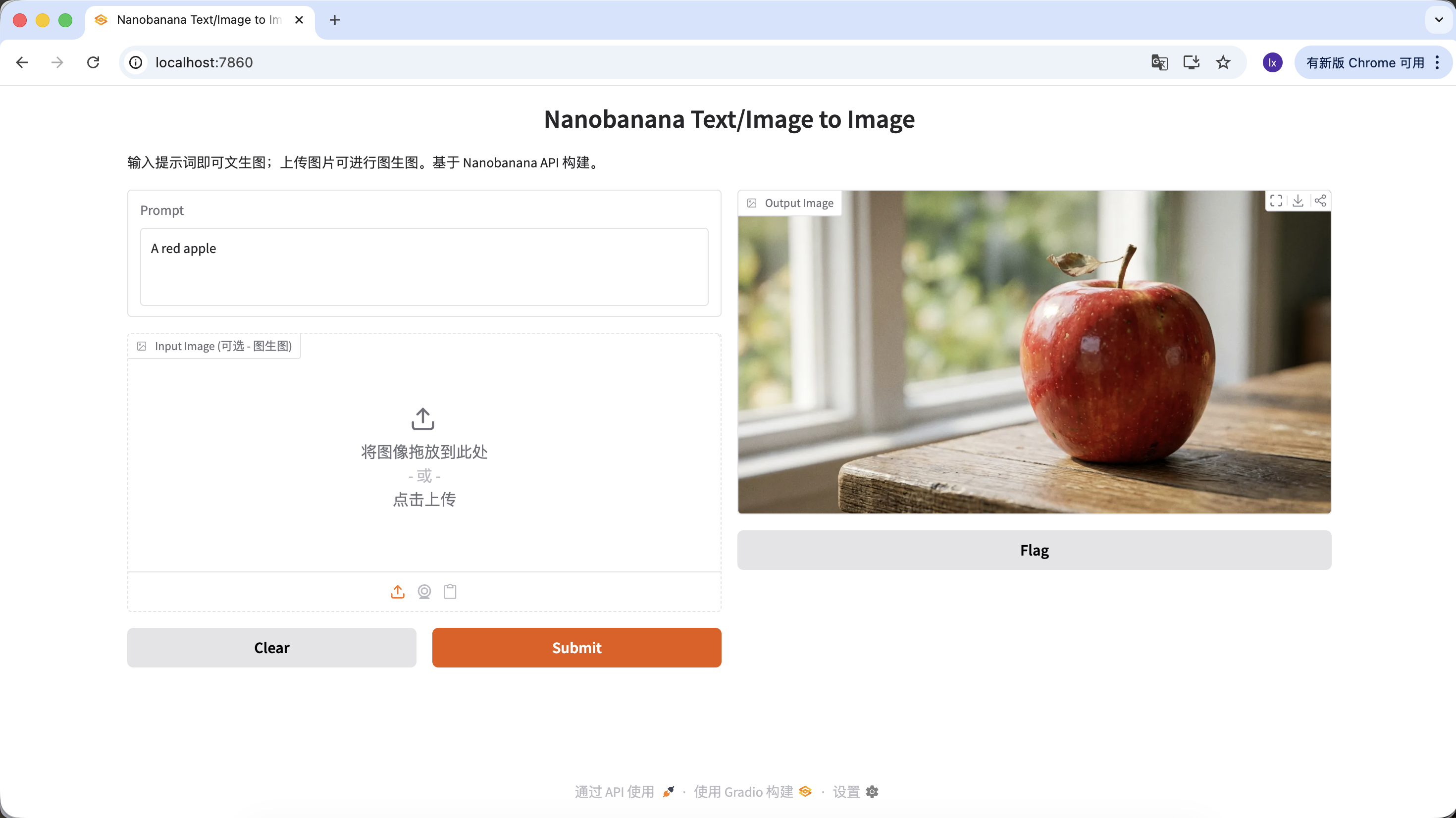
也可以豐富你的提示詞,給予它更多的描述和限定。例如以下提示詞,得到的圖片就會更加特殊一些。
"A hyper-realistic close-up of a fresh red apple with water droplets on its skin, sitting on a dark rustic wooden table. Cinematic dramatic lighting, rim light, shallow depth of field, bokeh background, 8k resolution, macro photography."
(一個超寫實的帶水珠的新鮮紅蘋果特寫,放在深色粗糙木桌上。電影級戲劇光效,輪廓光,淺景深,背景虛化,8k分辨率,微距攝影。)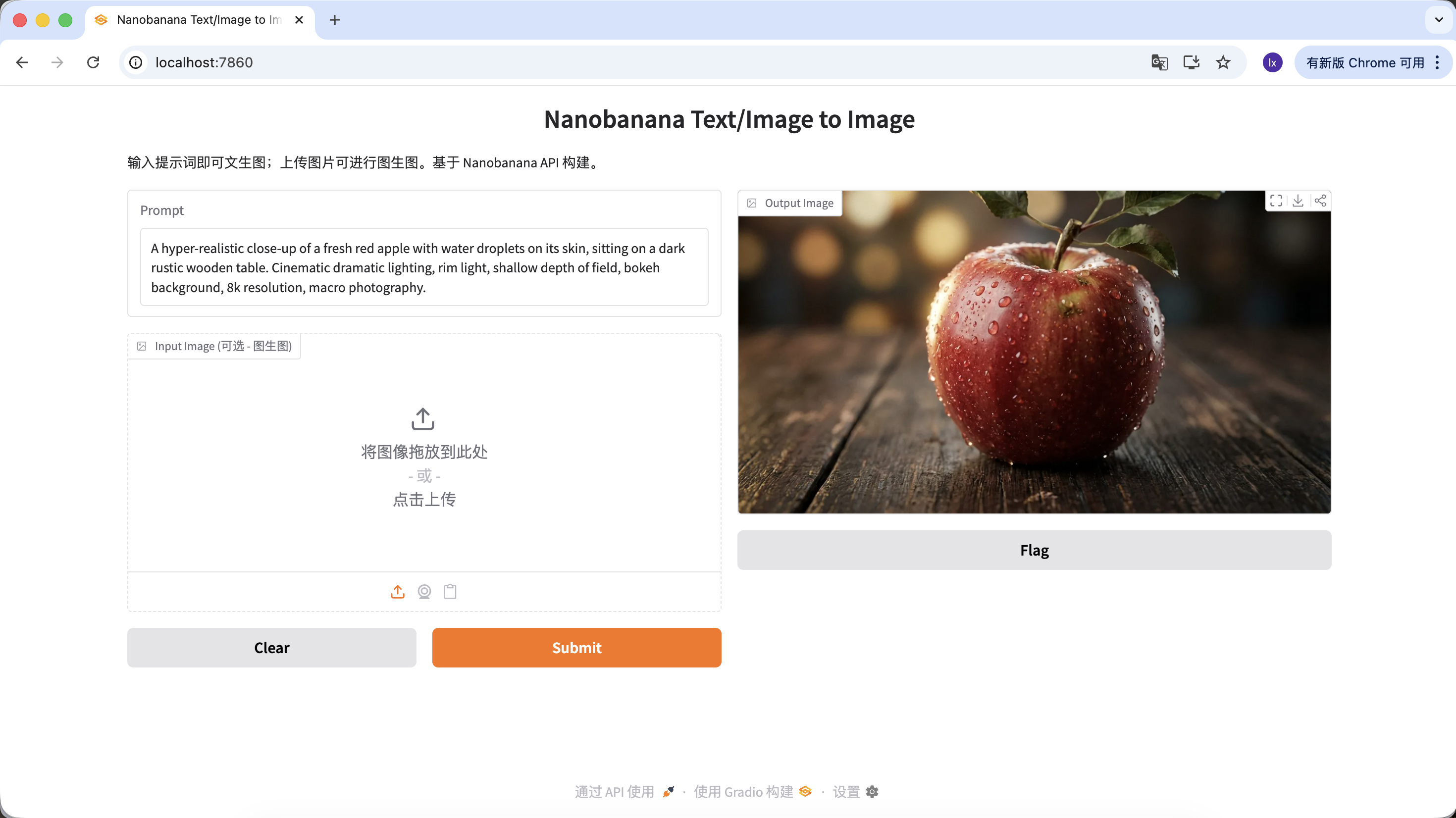
在Output Image區域點擊下載圖片即可保存到本地。
1.3 生圖模型常見的素材生成場景
在實際工作中,大模型生成圖片更多用於 高效產出設計素材 ,而不是創作單張藝術作品。
當你觀察一些設計類營銷賬號的高贊案例時會發現,它們的產出大多集中在兩類場景:
- 文生圖(從 0 到 1)
- 有圖參考生圖(從 1 到 N)
一、文生圖:快速獲取設計物料
這一類場景關注效率。當需要填補設計中的空白(如空狀態、頭像、配圖)時,AI 本質上充當的是一個 即時生成的圖庫 。
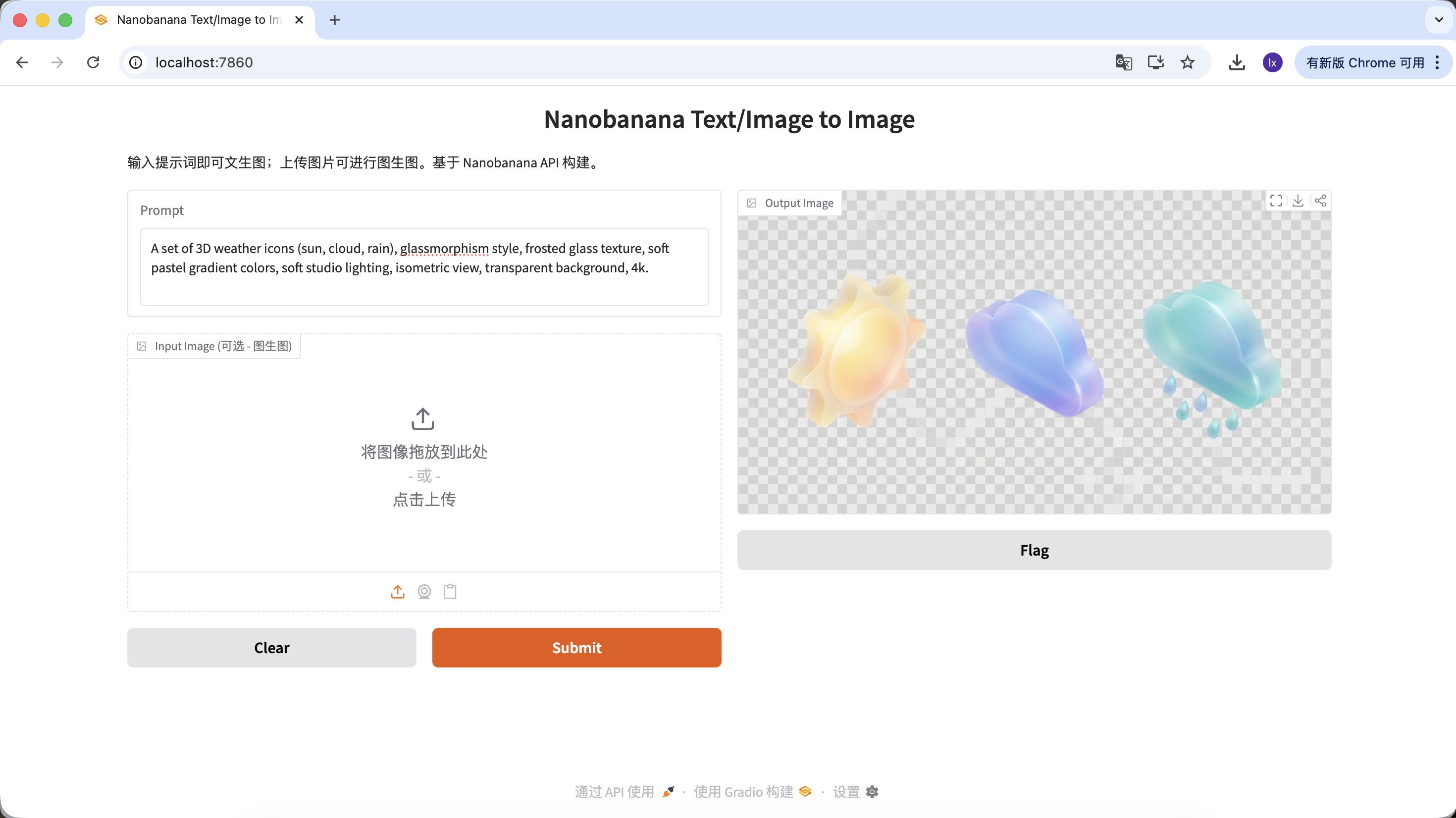
生成 UI 設計物料
- 流行趨勢:Dribbble 上常見的毛玻璃、黏土風 3D 圖標
- 常見表現:通透材質、邊緣發光、糖果配色的功能或天氣圖標
示例 Prompt:
A set of 3D weather icons (sun, cloud, rain), glassmorphism style, frosted glass texture, soft pastel gradient colors, soft studio lighting, isometric view, transparent background, 4k.
(一套 3D 天氣圖標,毛玻璃風格,磨砂質感,柔和漸變色,影棚光,等軸視圖)
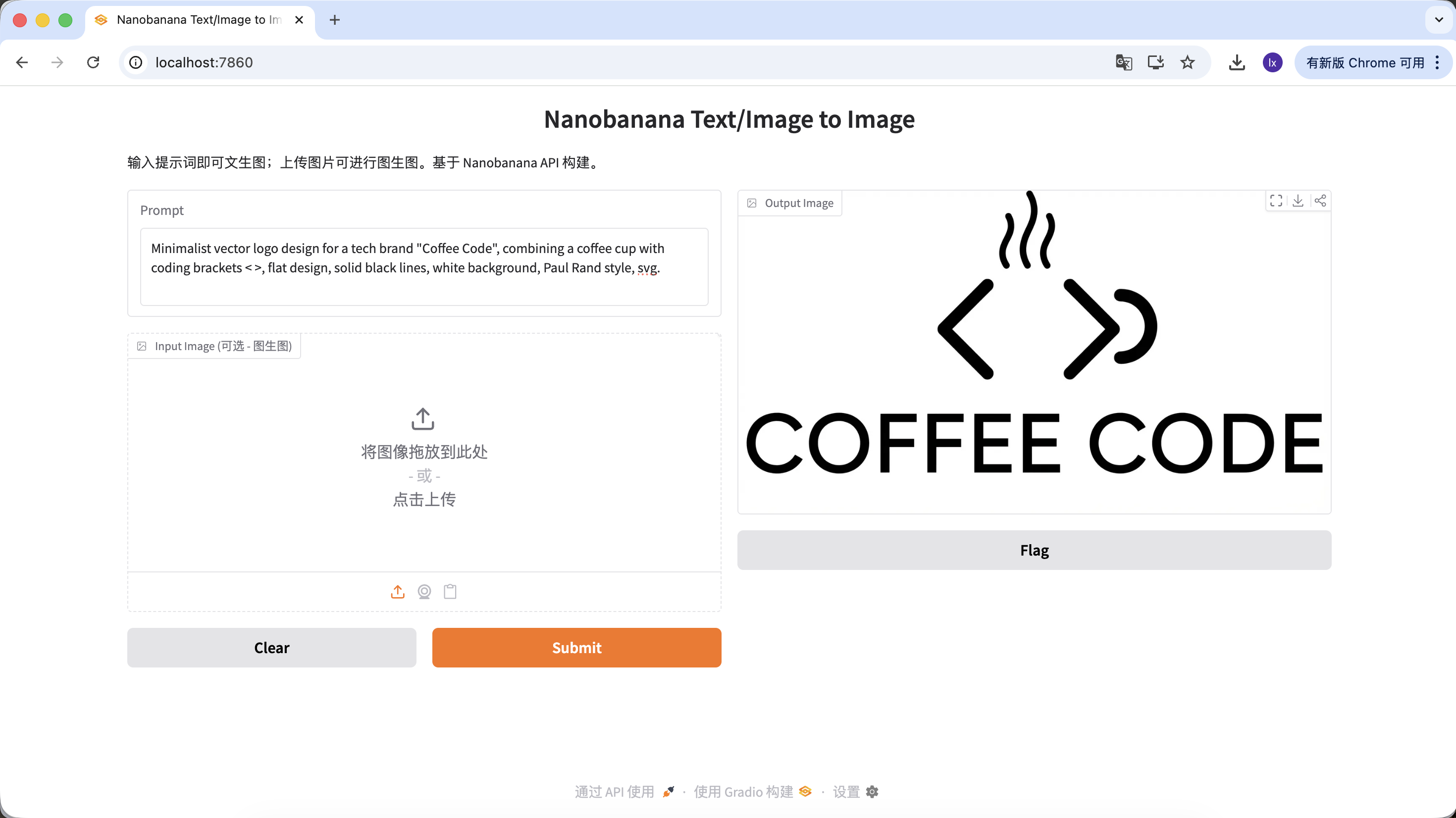
生成 Logo
- 流行趨勢:極簡線條、幾何組合的科技感 Logo
- 常見表現:黑白配色、負空間設計、品牌感明確
示例 Prompt:
Minimalist vector logo design for a tech brand "Coffee Code", combining a coffee cup with coding brackets < >, flat design, solid black lines, white background, Paul Rand style, svg.
(極簡矢量 Logo,結合咖啡杯與程式碼符號,扁平設計,純黑線條)
生成官網用戶圖片
- 流行趨勢:SaaS 官網常用 3D 虛擬頭像,用於規避真人版權
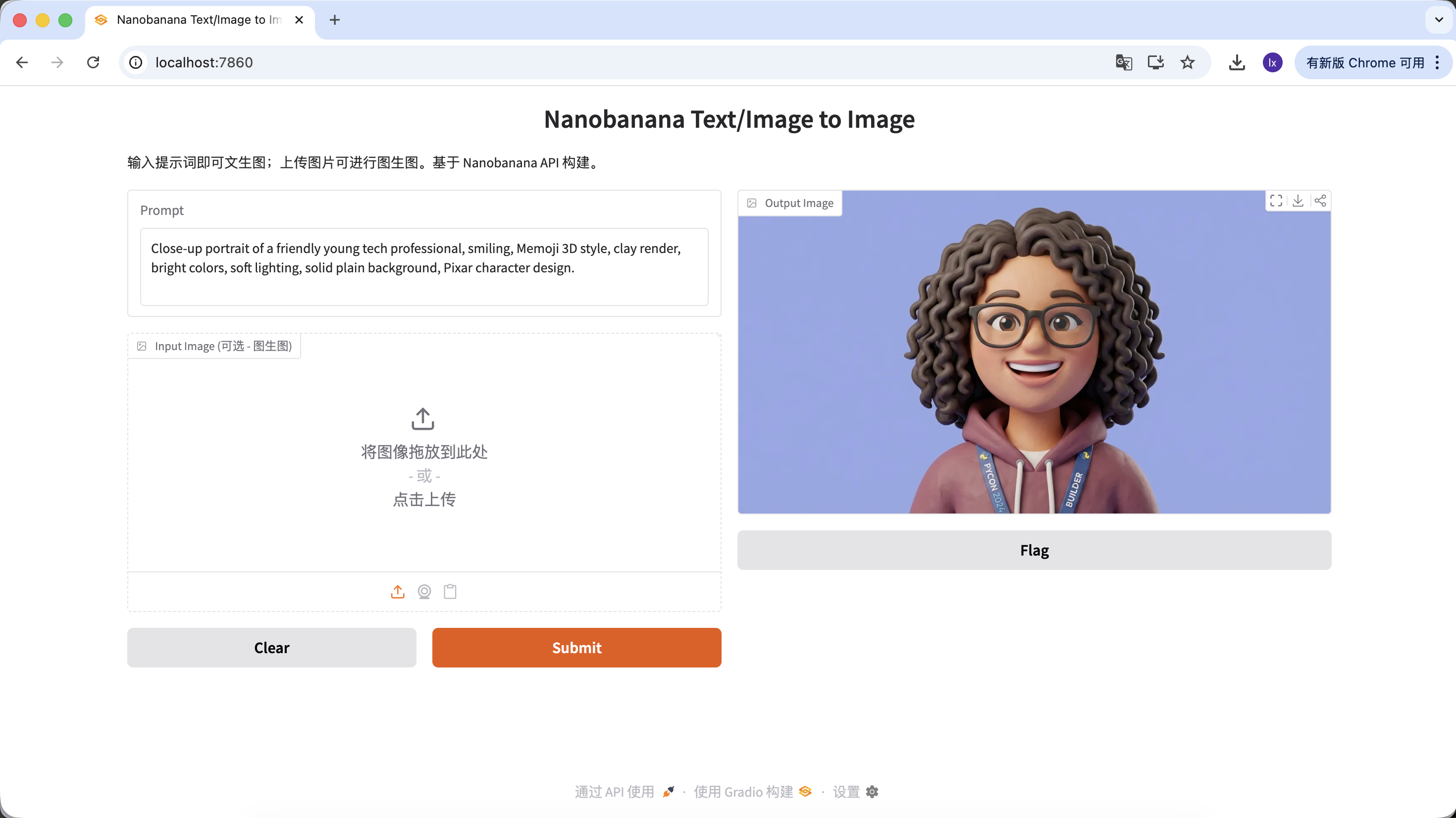
- 常見表現:友好表情、卡通比例、偏 Pixar 或 Memoji 風格
示例 Prompt:
Close-up portrait of a friendly young tech professional, smiling, Memoji 3D style, clay render, bright colors, soft lighting, solid plain background, Pixar character design.
(友好的年輕科技從業者,3D Memoji 風格,黏土渲染)
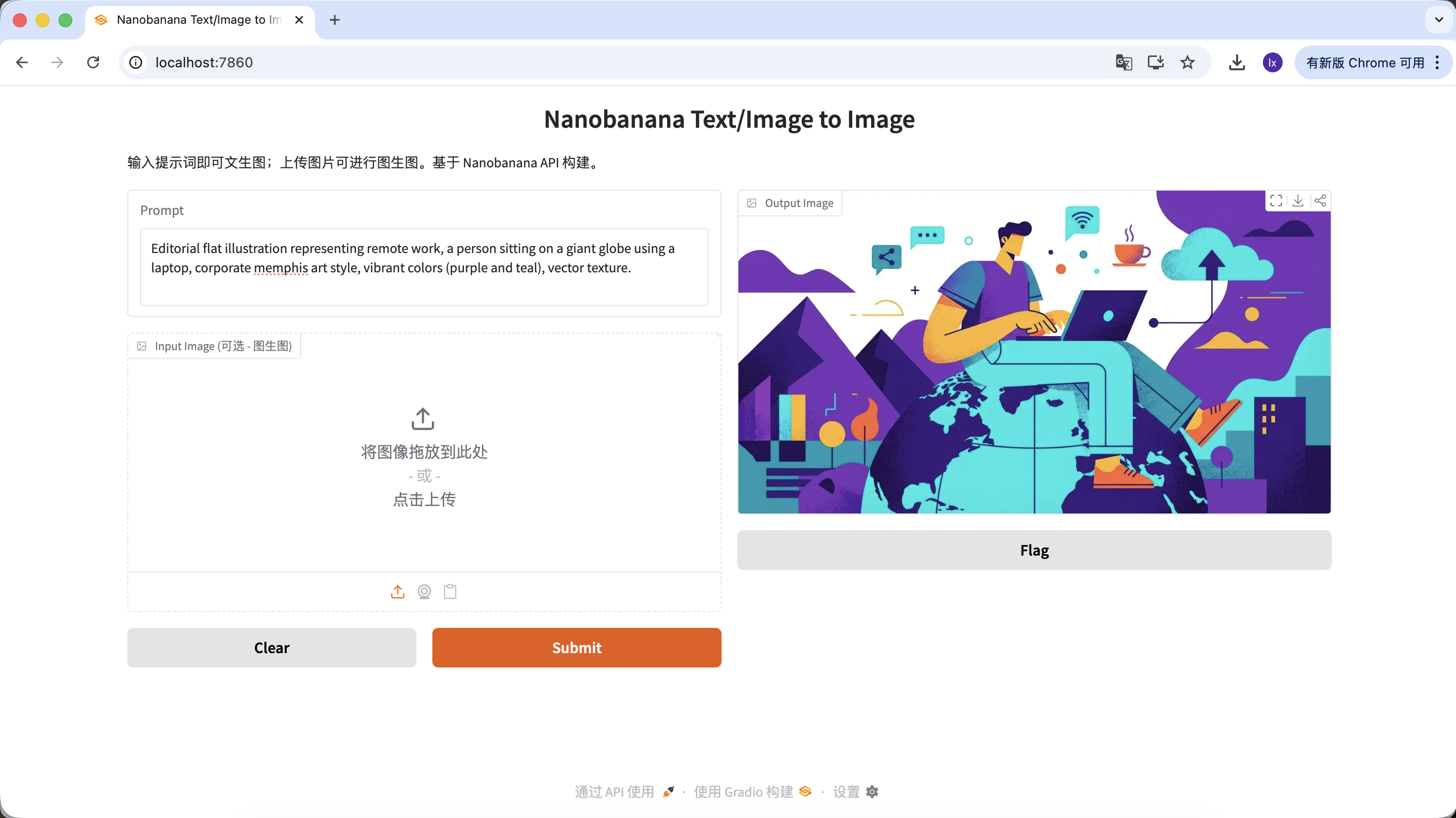
生成文章配圖
- 流行趨勢:科技公司博客中常見的抽象扁平插畫
- 常見表現:紫藍配色、誇張人物比例、漂浮 UI 元素
示例 Prompt:
Editorial flat illustration representing remote work, a person sitting on a giant globe using a laptop, corporate memphis art style, vibrant colors (purple and teal), vector texture.
(遠程辦公主題扁平插畫,企業孟菲斯風格)
二、有圖參考生圖:保持視覺一致性
這一類場景更關注 擴展性 。當你已經有一張滿意的主視覺,需要生成一整套風格一致的素材時使用。
主視覺相似的一套按鈕或交互素材圖
在遊戲開發中,UI 的一致性非常關鍵。假設你已經有了主界面的 “PLAY” 按鈕,現在需要擴展出一整套風格統一的功能按鈕(如暫停、設置、主頁)。僅靠手繪很難保證每個按鈕在光澤、透視和色值上的完全一致。
基本操作流程:
- 保存已有的藍色 “PLAY” 按鈕圖片

- 將其拖入界面的 Input** Image** 區域,作為後續生成的參考母版
- 保持 prompt 中的風格描述不變,僅修改主體內容
在這一流程下,只要替換主體描述,就可以得到不同功能但風格一致的按鈕。
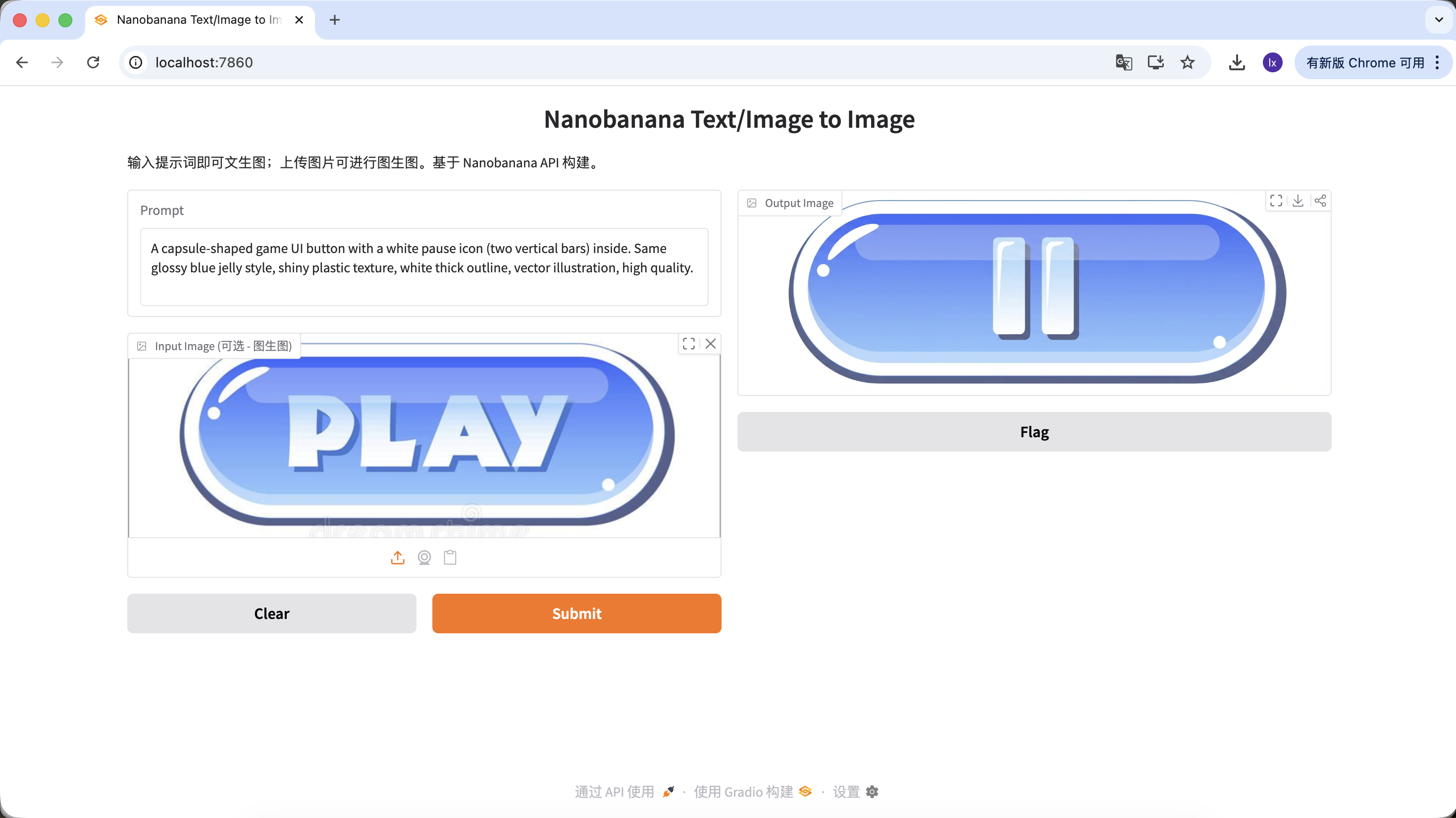
示例 Prompt:
變體 A:暫停按鈕(圖標類)
A capsule-shaped game UI button with a white pause icon (two vertical bars) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(膠囊形遊戲 UI 按鈕,白色暫停圖標,藍色果凍質感)
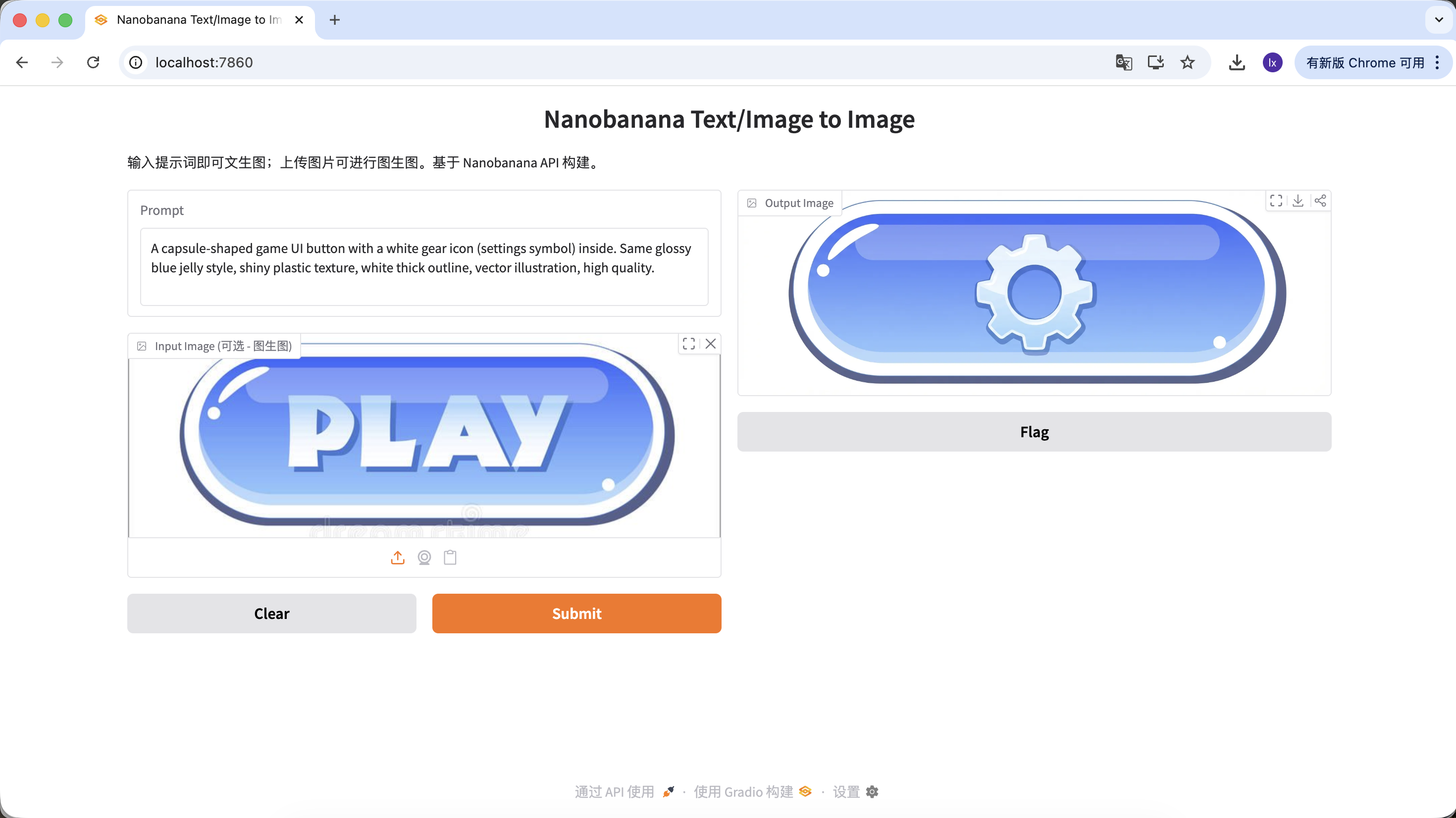
變體 B:設置按鈕(複雜圖標)
A capsule-shaped game UI button with a white gear icon (settings symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(膠囊形遊戲 UI 按鈕,白色齒輪圖標,藍色果凍質感)
變體 C:重玩按鈕(形狀變化)
如果需要調整按鈕外形,可以在 prompt 中直接描述形狀,模型會在保留材質特徵的同時嘗試改變結構。
A round game UI button with a white circular arrow icon (replay symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(圓形遊戲 UI 按鈕,循環箭頭圖標,藍色果凍質感)

通過這一組操作,你不僅可以替換按鈕功能和圖標,甚至改變按鈕形狀,但所有生成結果在材質、配色和光影上仍保持高度一致。這正是大模型在設計素材裂變場景中的核心價值。
第 2 章:更聽話的圖像生成助手 —— 以 Lovart 為例
在第一部分,我們通過程式碼直接調用 NanoBanana,體驗了“輸入即生成”的基礎流程。這種方式在需求簡單時沒有問題。但當生成任務開始包含更多約束,例如:
- 需要多張風格一致的圖片
- 需要在已有結果上反覆調整
- 需要根據用戶輸入動態修改生成方向
單次調用的方式就會逐漸變得不夠用。
這時,就需要引入 AI Agent( 智能體 ) 。本節以 Lovart 為例,展示當圖像生成模型具備“思考層”後,整體工作流會發生怎樣的變化。注意!這裡不是打廣告,只是幫助大家快速get到AI Agent的便捷性~
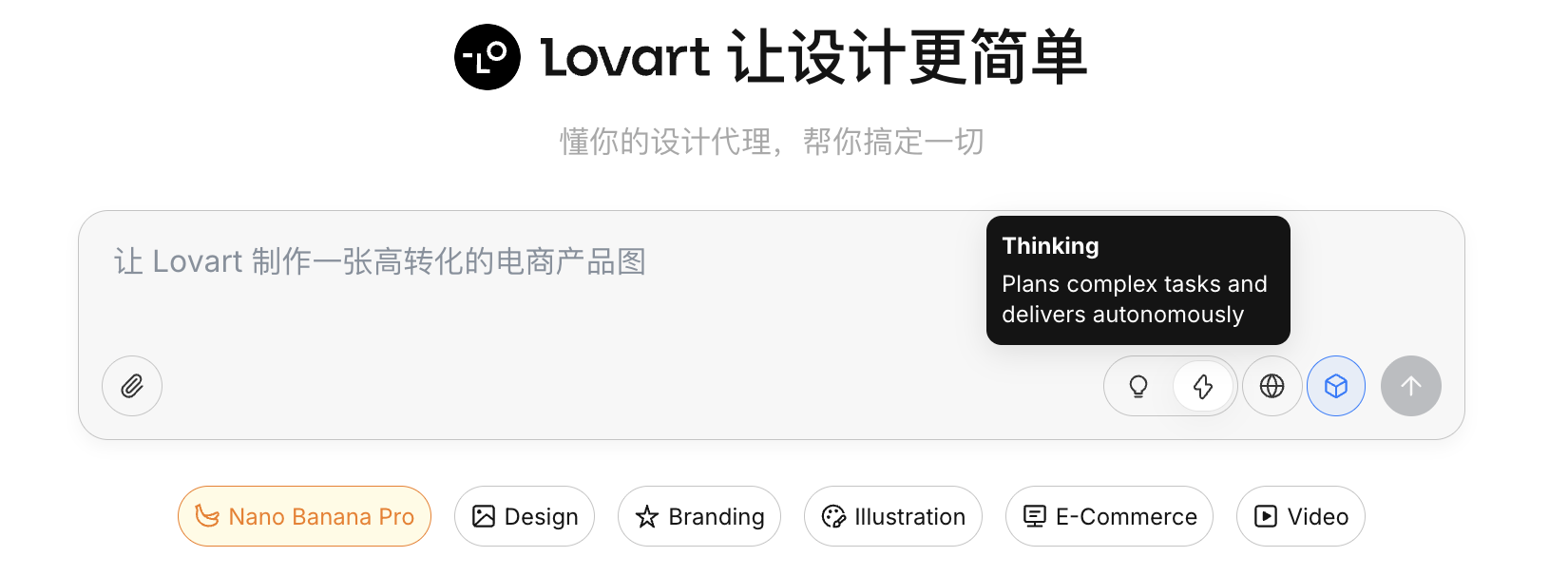
2.0 初識 Lovart:你的 AI 設計代理
Lovart 是一個基於 Agent 的設計工具 Web。相比普通生圖工具,它在生成之前多了一層“思考與規劃”。
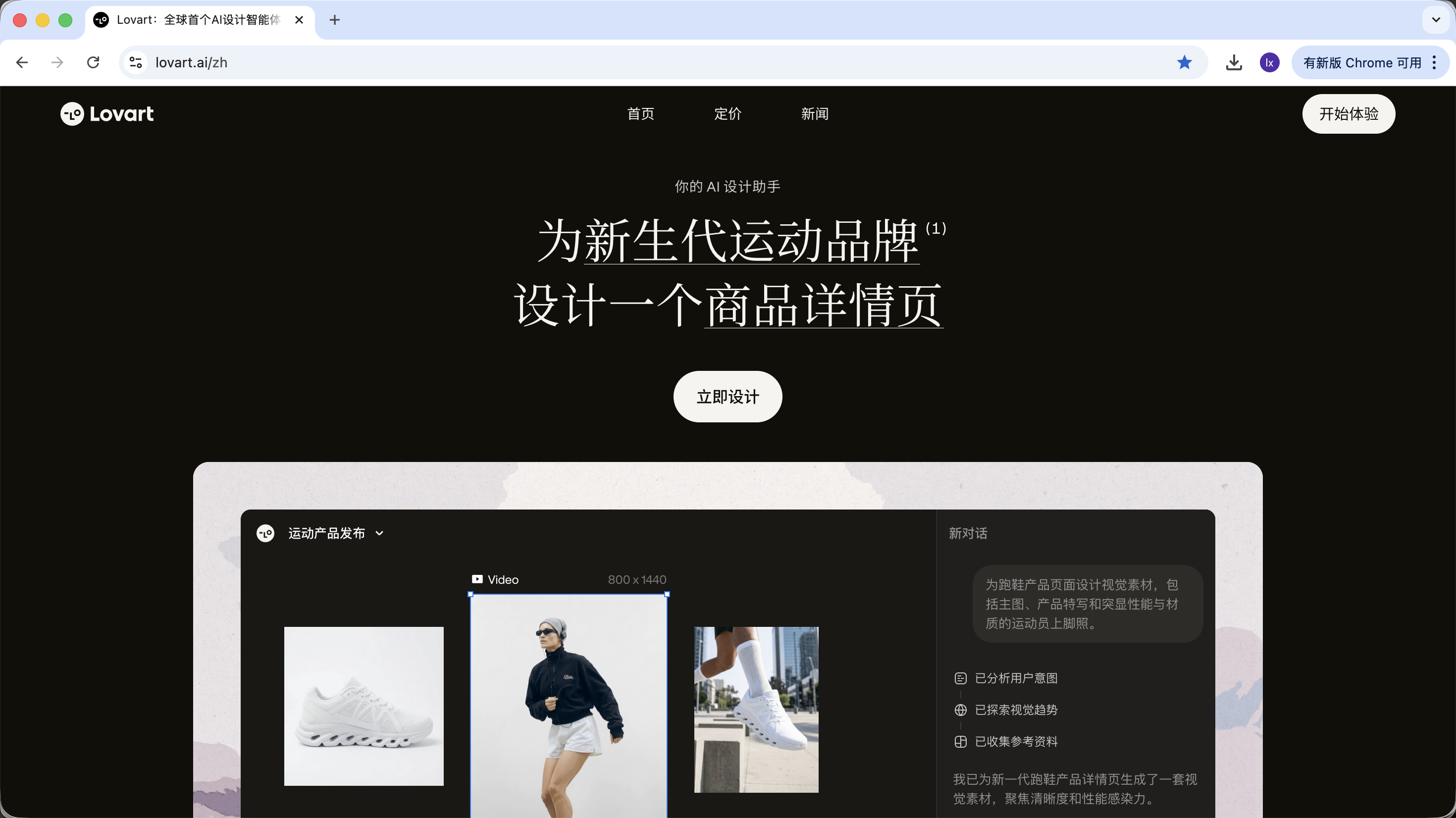
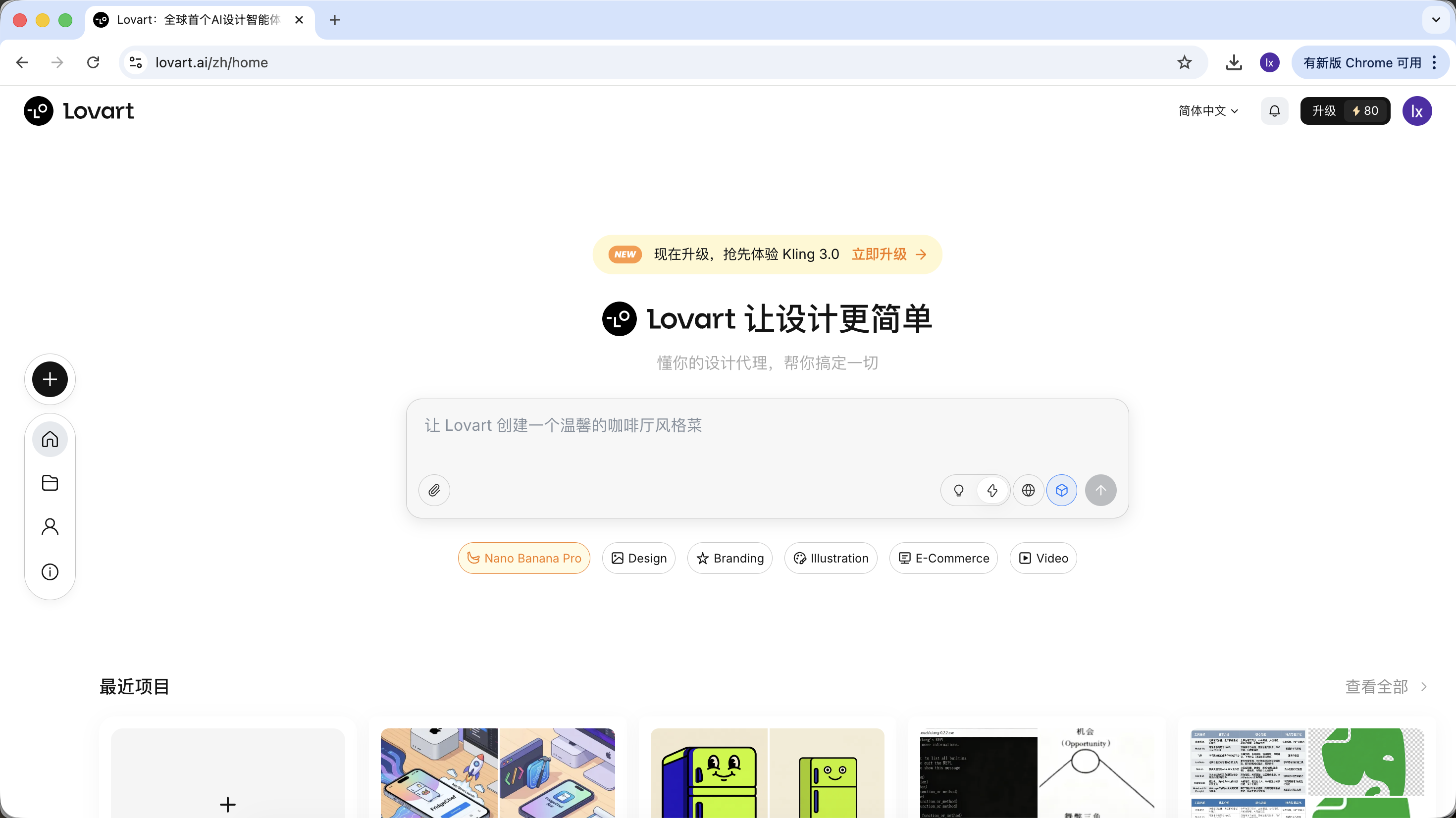
進入 Lovart 後,主要需要了解以下幾個控制項:
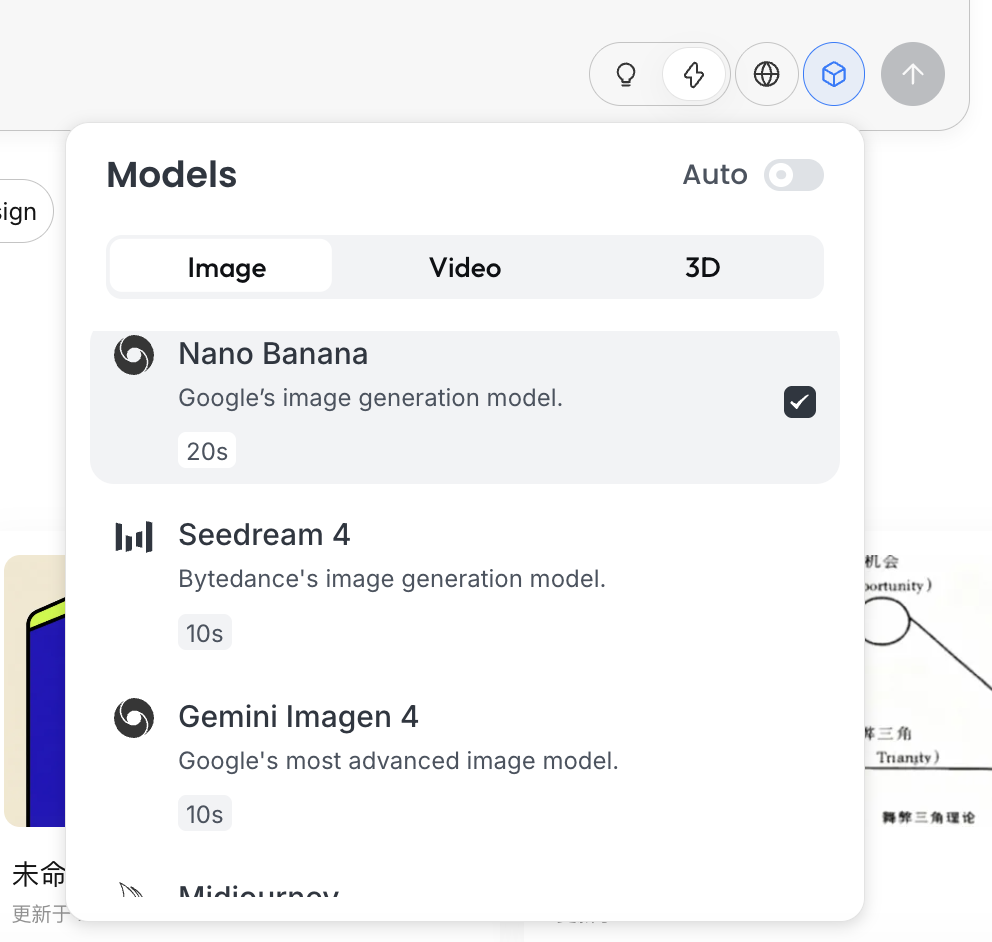
模型選擇
點擊輸入框下方的立方體圖標,可以查看當前可用的生成模型(如 GPT Image、Flux 等)。
為了與前文示例保持一致,本節仍然使用 NanoBanana 作為底層生成模型。
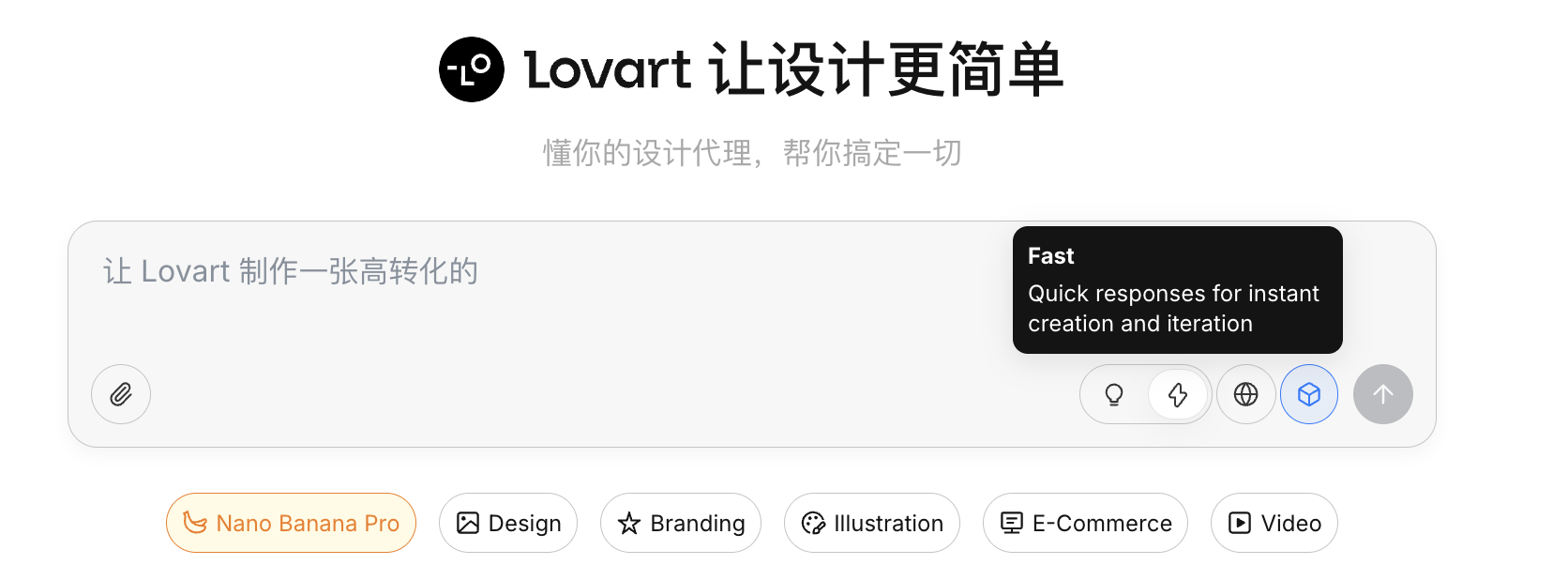
思考模式
這是 Lovart 的核心開關:
- Fast Mode(⚡) :接近原生 API,響應快,適合單張、明確指令的生成
- Thinking Mode(💡) :Agent 模式,AI 會先拆解需求、改寫 prompt,再執行生成
聯網能力
開啟地球圖標後,Agent 可以在生成過程中檢索網路資訊(例如設計趨勢、配色風格),作為輔助輸入。
2.1 為什麼原生 API 還不夠?
即使已經可以通過 Python 生成質量不錯的圖片,原生 API 在複雜任務中仍然存在限制。關鍵原因在於:原生 API 本質上是指令式的。當你要求它生成一個具體對象時,它可以直接執行;但當輸入變成“策劃一套完整的遊戲素材”時,它並不會主動將目標拆解為多個可執行步驟。
Lovart 的核心差異在於 Agent 機制。在用戶輸入與圖像生成模型之間,它加入了一層用於理解和規劃的邏輯:先識別用戶意圖,再拆解任務、重寫 prompt,最後才執行生成。
2.2 實戰演示:5 分鐘打造一套 IP 表情包
以 “製作一套程序員鴨子 IP 表情包” 為例,看看 Agent 是如何參與整個流程的。
環節一:策劃(Agent 的思考能力)
原生 API 的問題: 你需要自己思考角色設定、情緒狀態,併為每一張圖單獨編寫 prompt。
Lovart 的做法:
- 點亮 💡 Thinking Mode
- 輸入一句指令:
設計一套程序員鴨子的 IP 表情包,風格要扁平化、可愛
AI 不會立即畫圖,而是先去網路上搜索相關的程序員鴨子的設計圖。輸出一份拆解後的方案,自動生成 Debug、Coffee Break、Panic 等場景,並對應生成多條視覺描述。
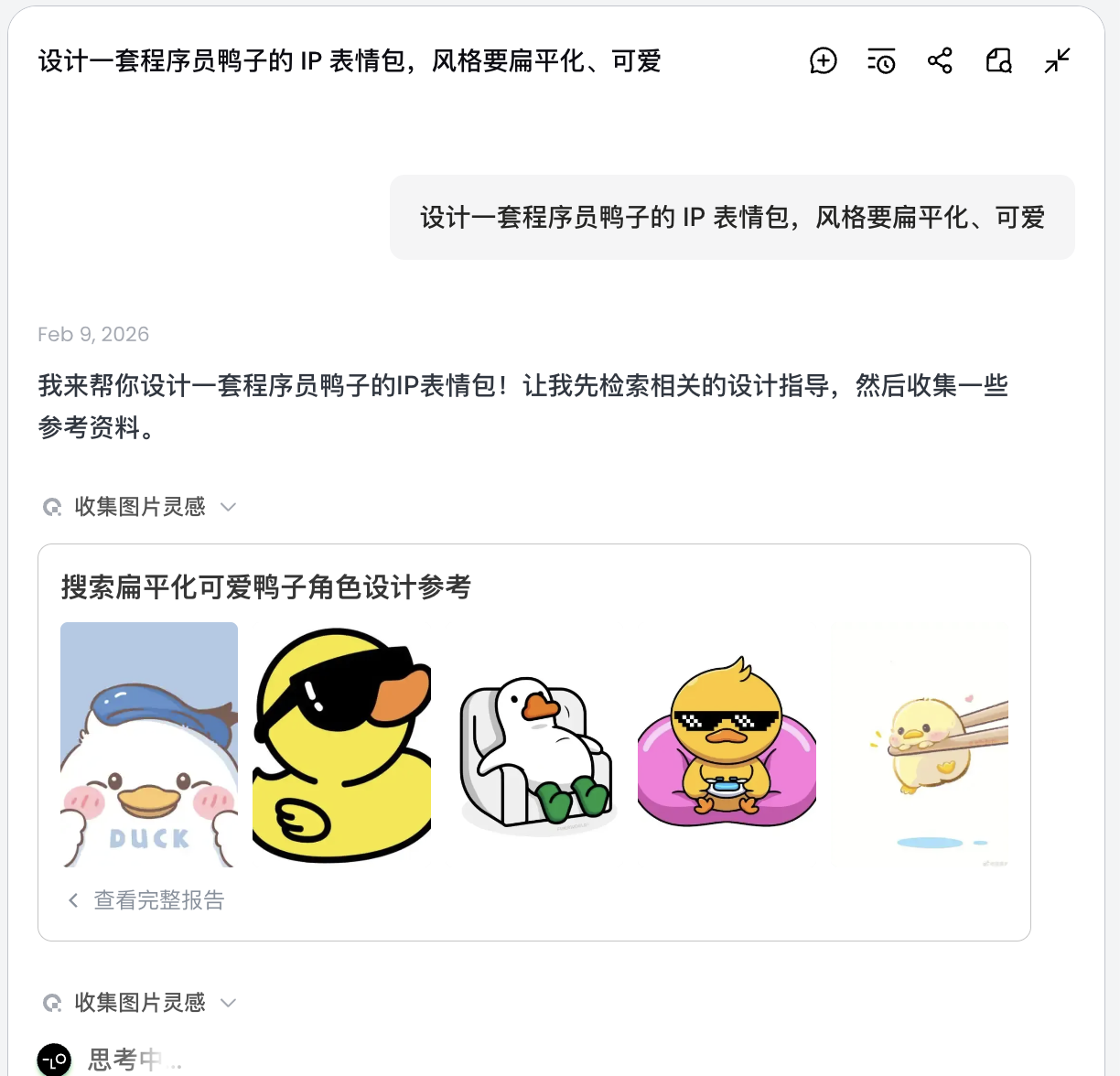

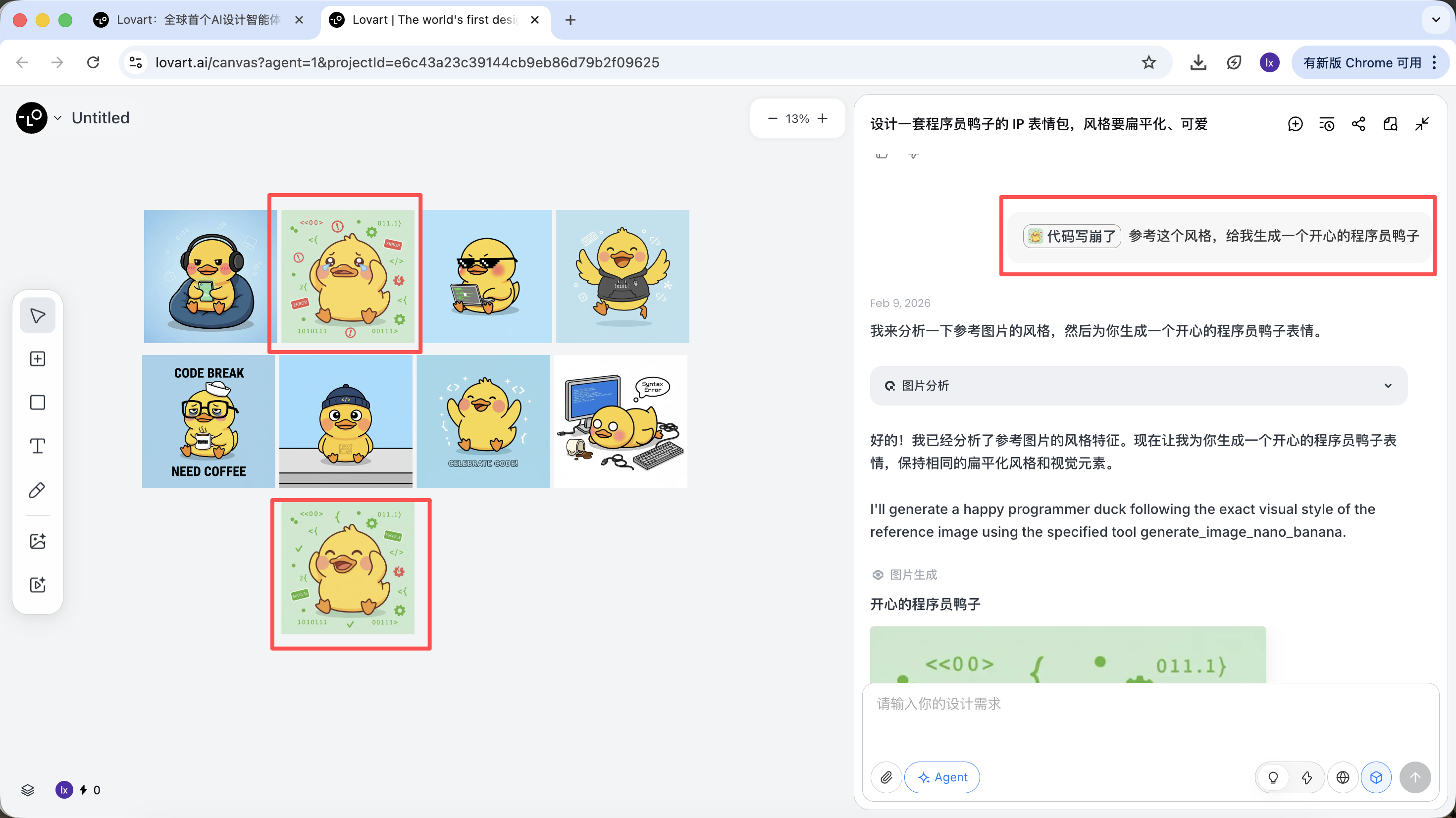
這一步,AI 從“執行者”轉變為“策劃者”。在AI幫你分析完需求後,可以在Lovart的畫布區看到多種風格和內容的程序員鴨子圖片。可以開始篩選你喜歡的風格。
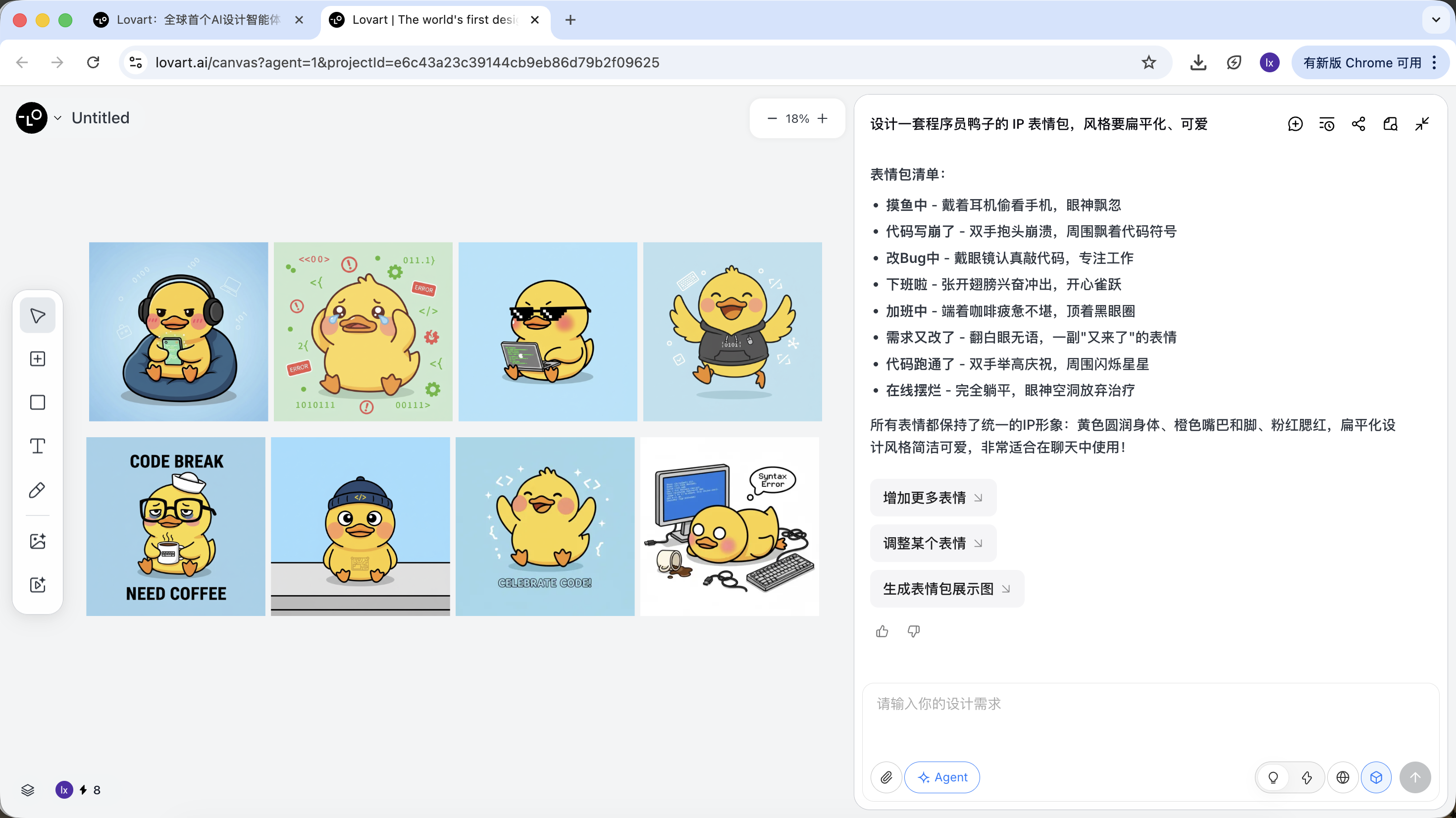
環節二:一致性(基於參考的視覺錨定)
Lovart 中的圖片不僅是結果,也參與後續生成。
完整參考圖
- 從草圖中選出一張最滿意的“標準鴨子”,在畫布區點擊對應圖片
- 該圖將會自動出現在對話區,作為 Reference
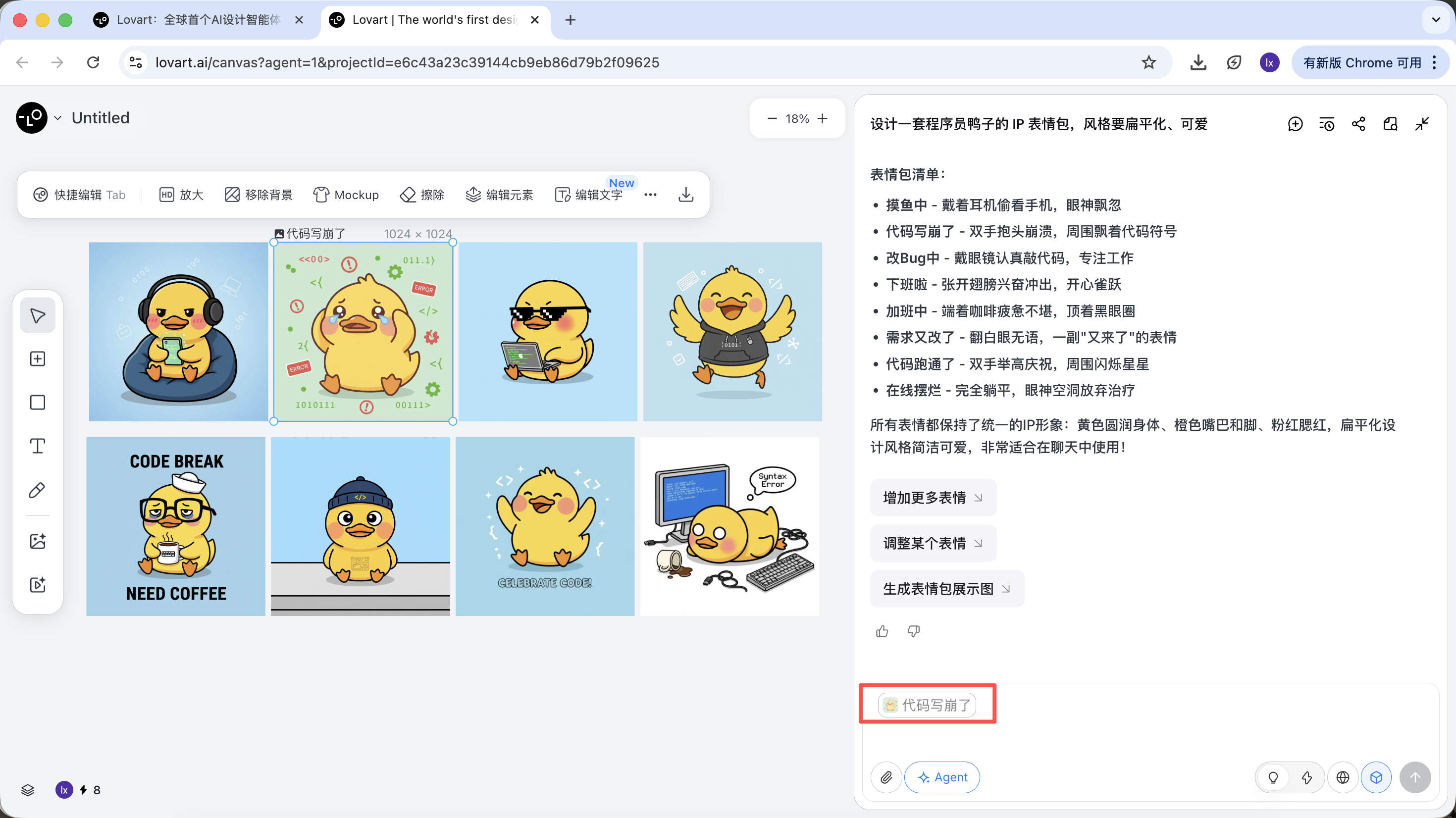
- 輸入新的動作(如開心)並生成
生成結果會繼承母版的配色、比例和細節。
局部參考 / 多圖整合
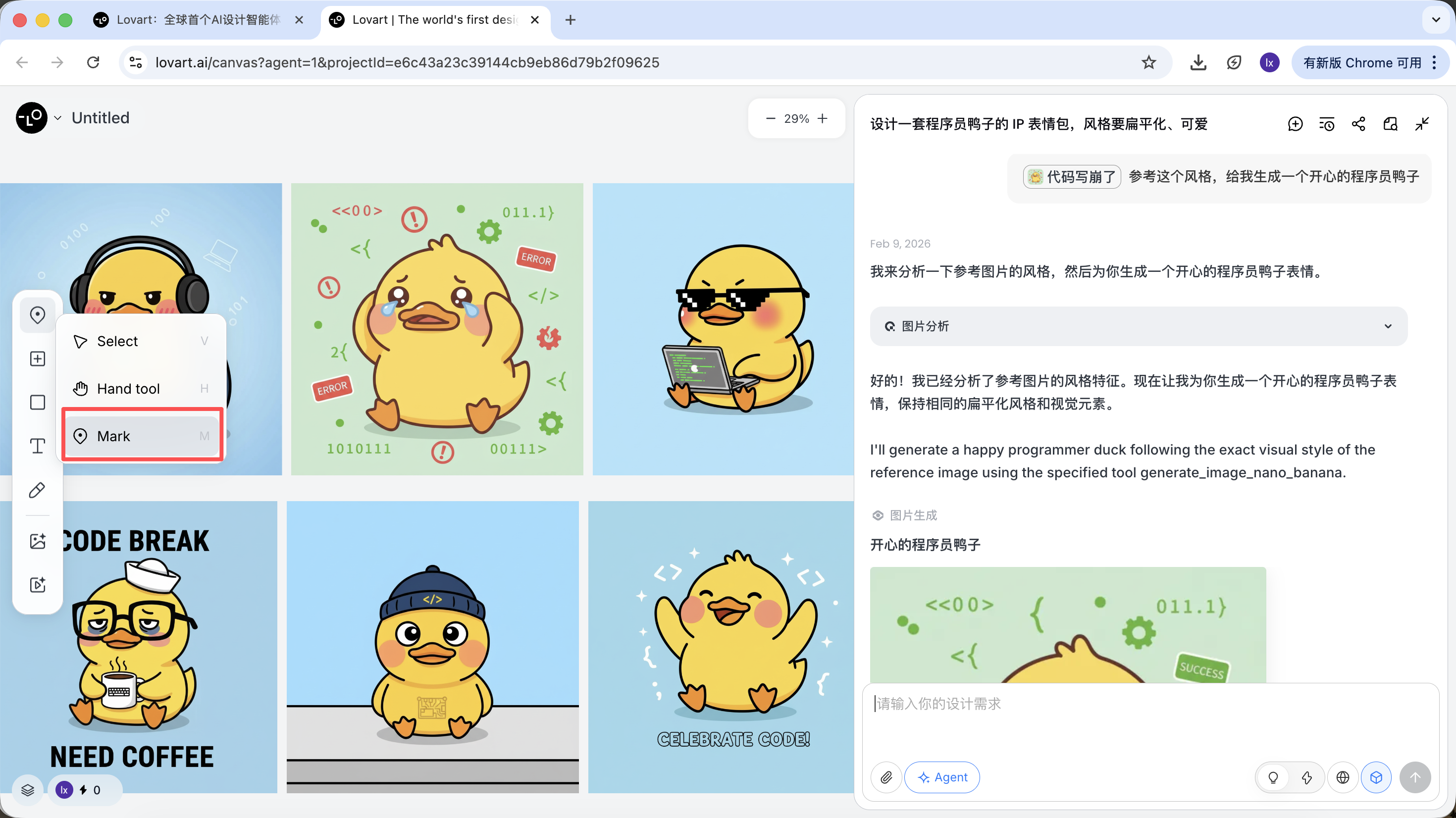
除了整張圖片作為參考,Lovart 還支持:
- 只選取圖片的局部區域 (例如只參考帽子或表情)
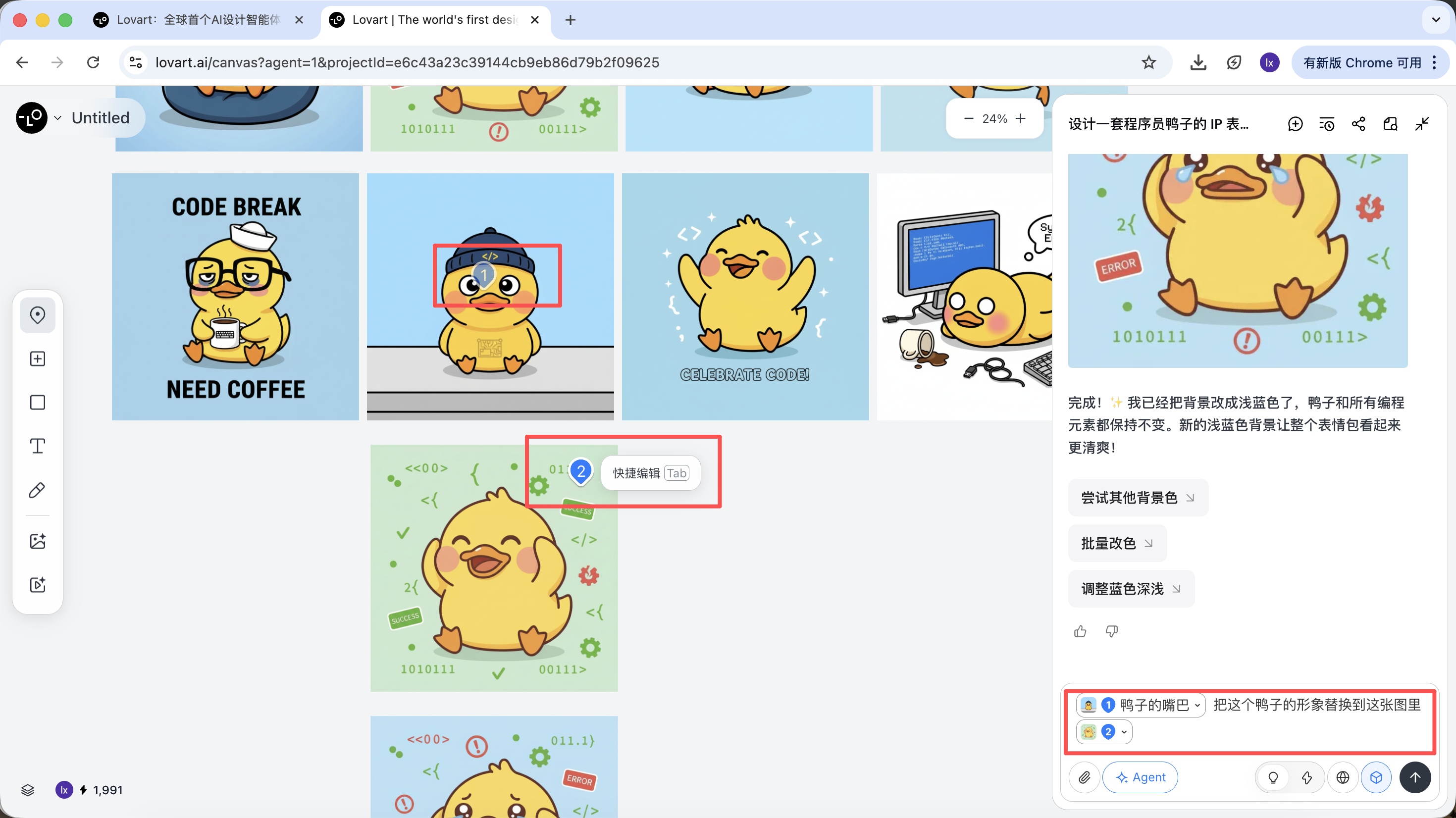
點擊畫布區左側tab欄,選擇「Mark」鍵,在目標圖像的局部區域標記即可,這部分內容會自動同步到對話框。比如在這裡我們可以選擇修改背景的顏色。
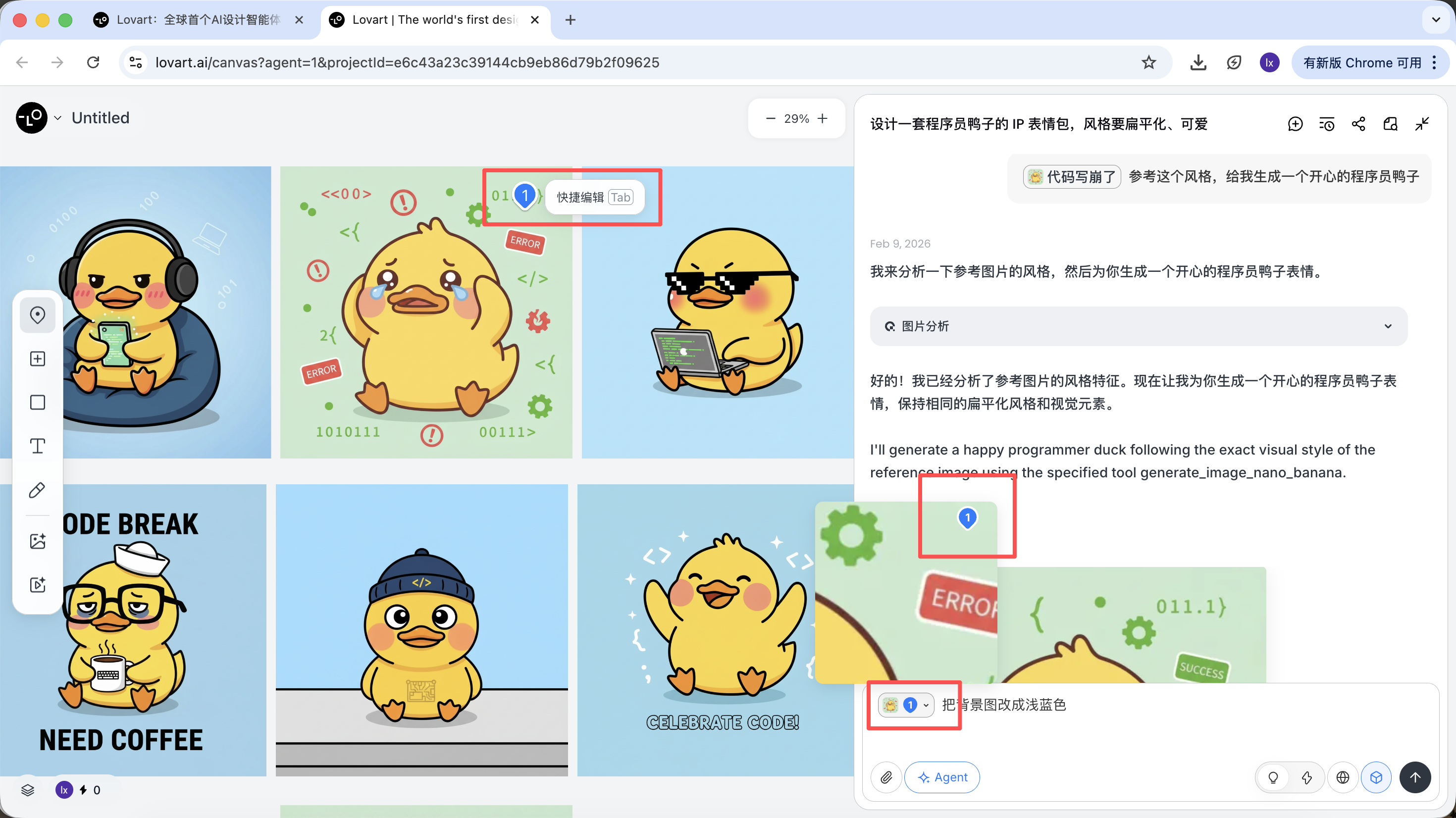
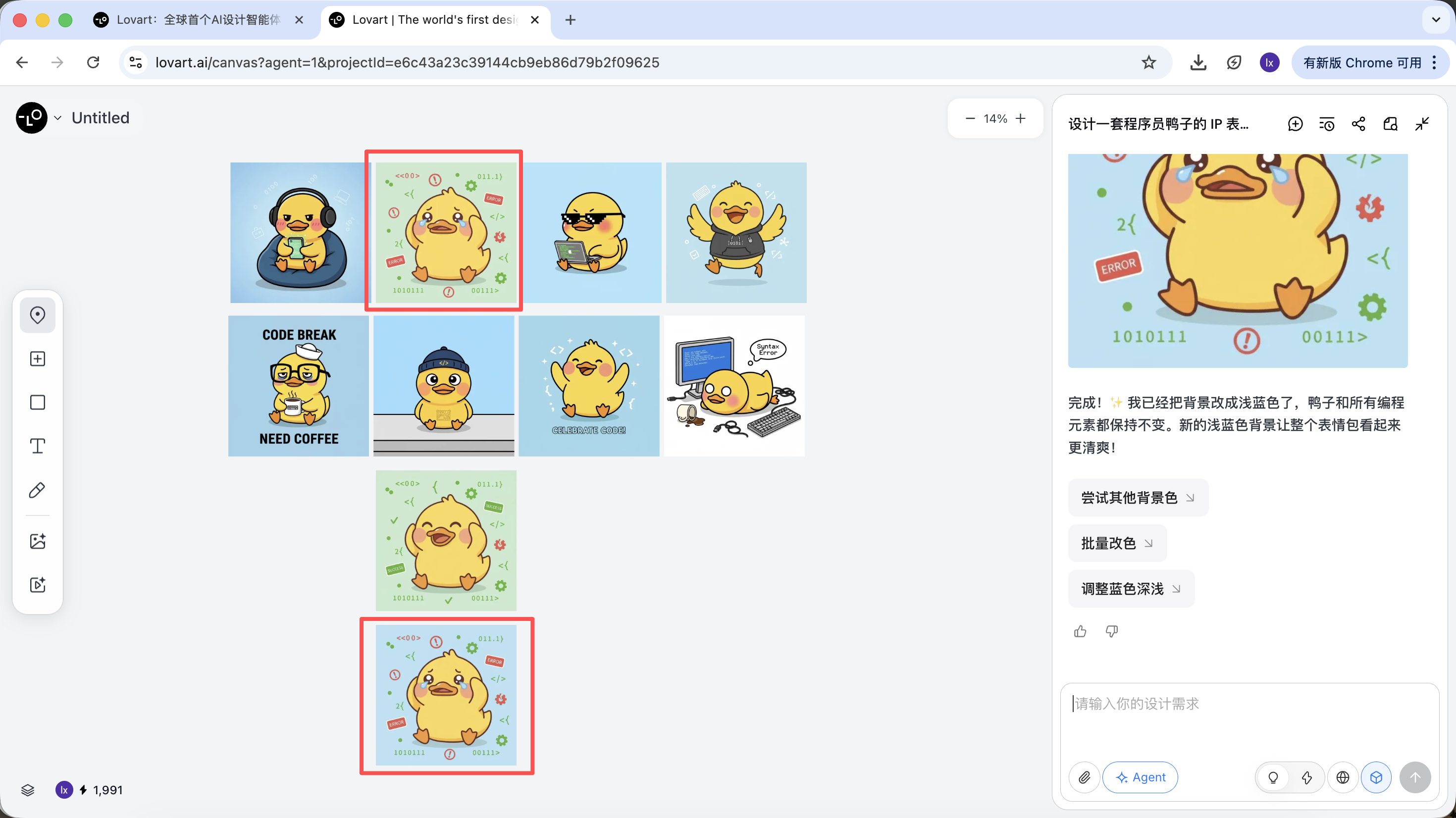
能看到新生成的圖片只改變了背景的顏色,這也跟我們輸入的要求一致。
- 從多張圖片中分別引用子元素 ,再組合生成新結果
例如:你可以保留 A 圖的角色主體,同時只替換帽子為 B 圖中的樣式,Agent 會在後臺自動整合這些視覺約束。
以程序員鴨子為例,我們可以選擇保留第一個圖中的鴨子形象,並將其替換到第二張圖中作為主體元素。
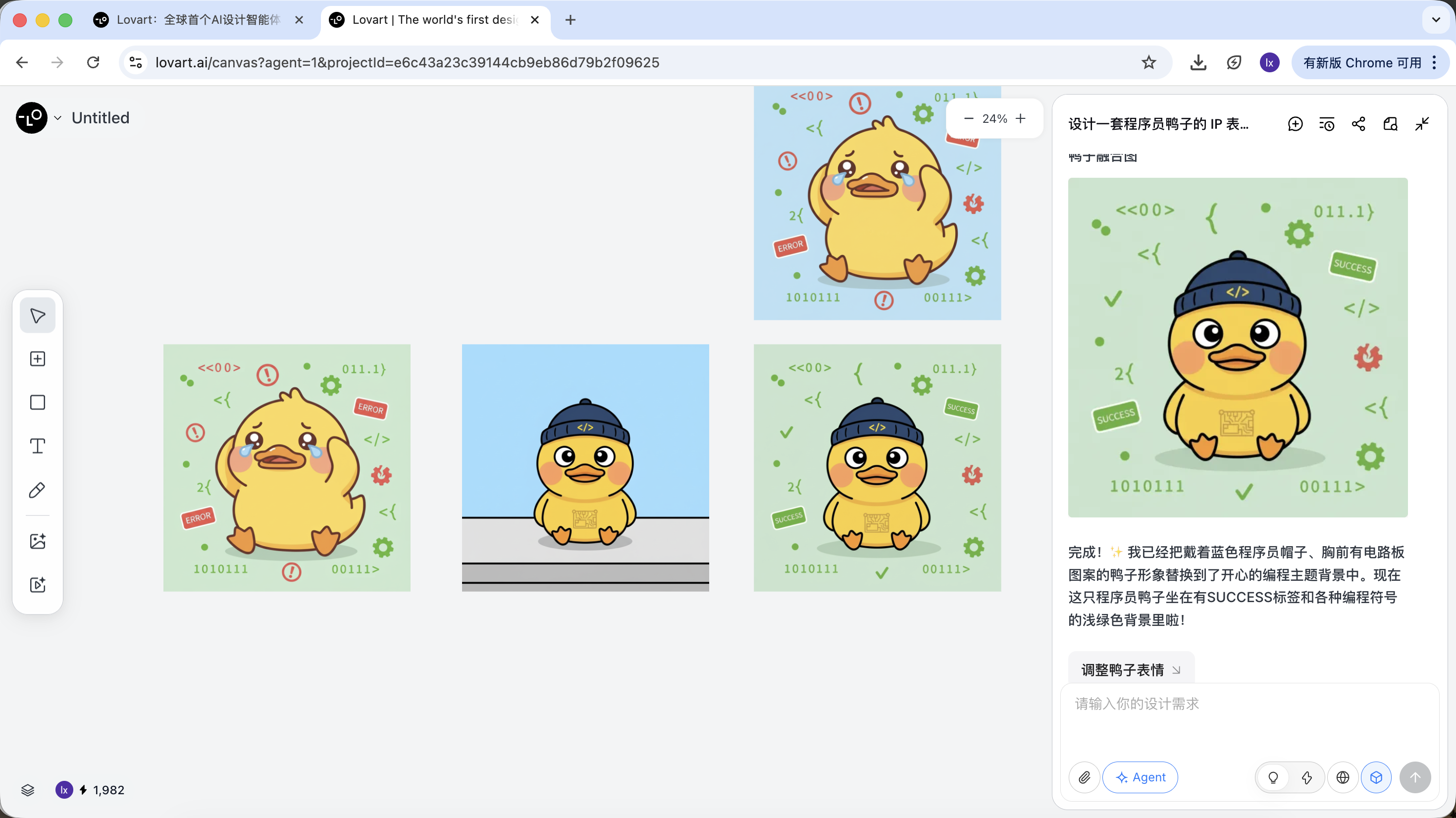
最後的效果也非常顯著。你也可以試著其他的組合!
環節三:落地(Agent 的工具調用)
生成完成後,可以直接執行:放大、移除背景、擦除等操作
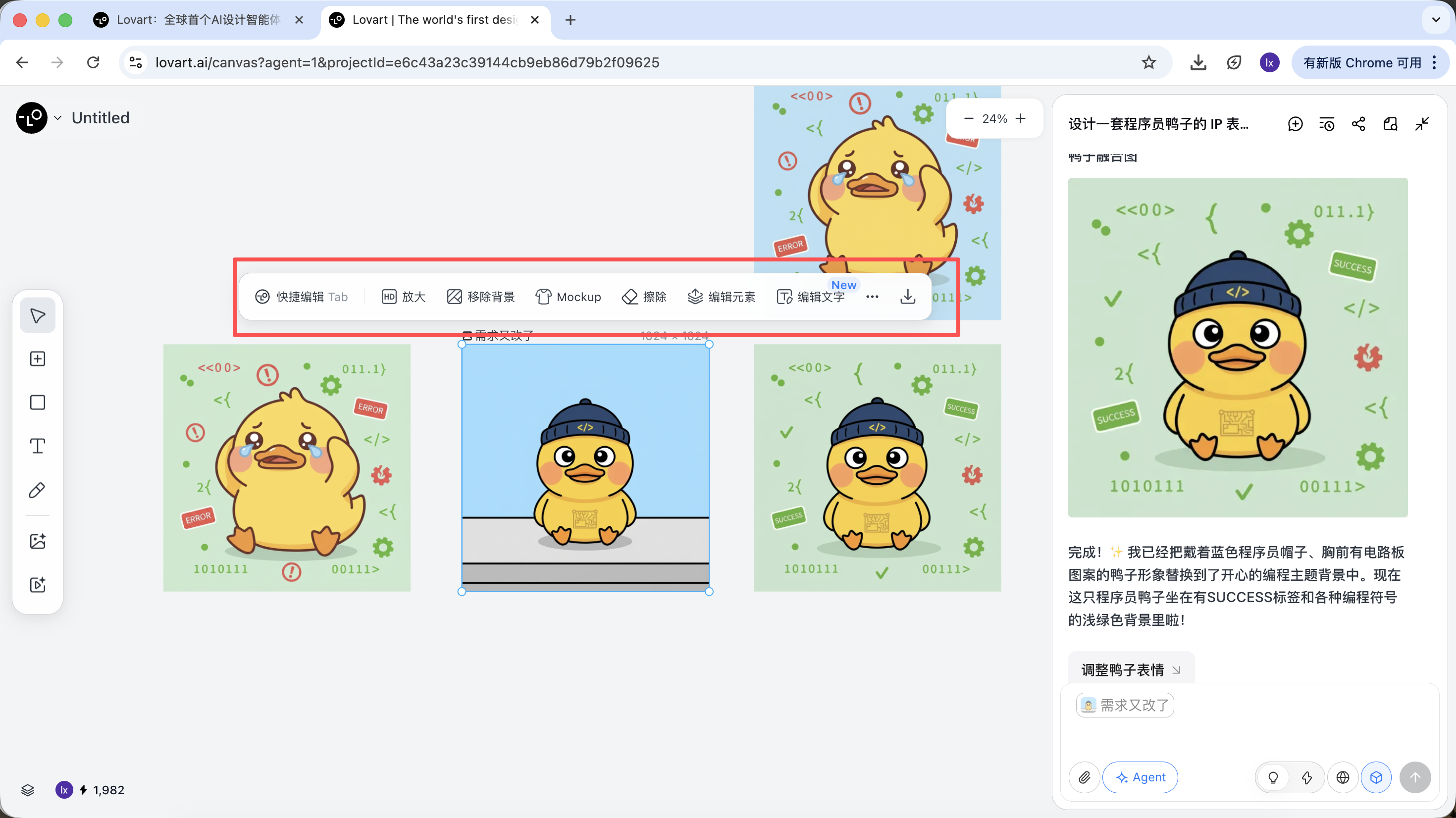
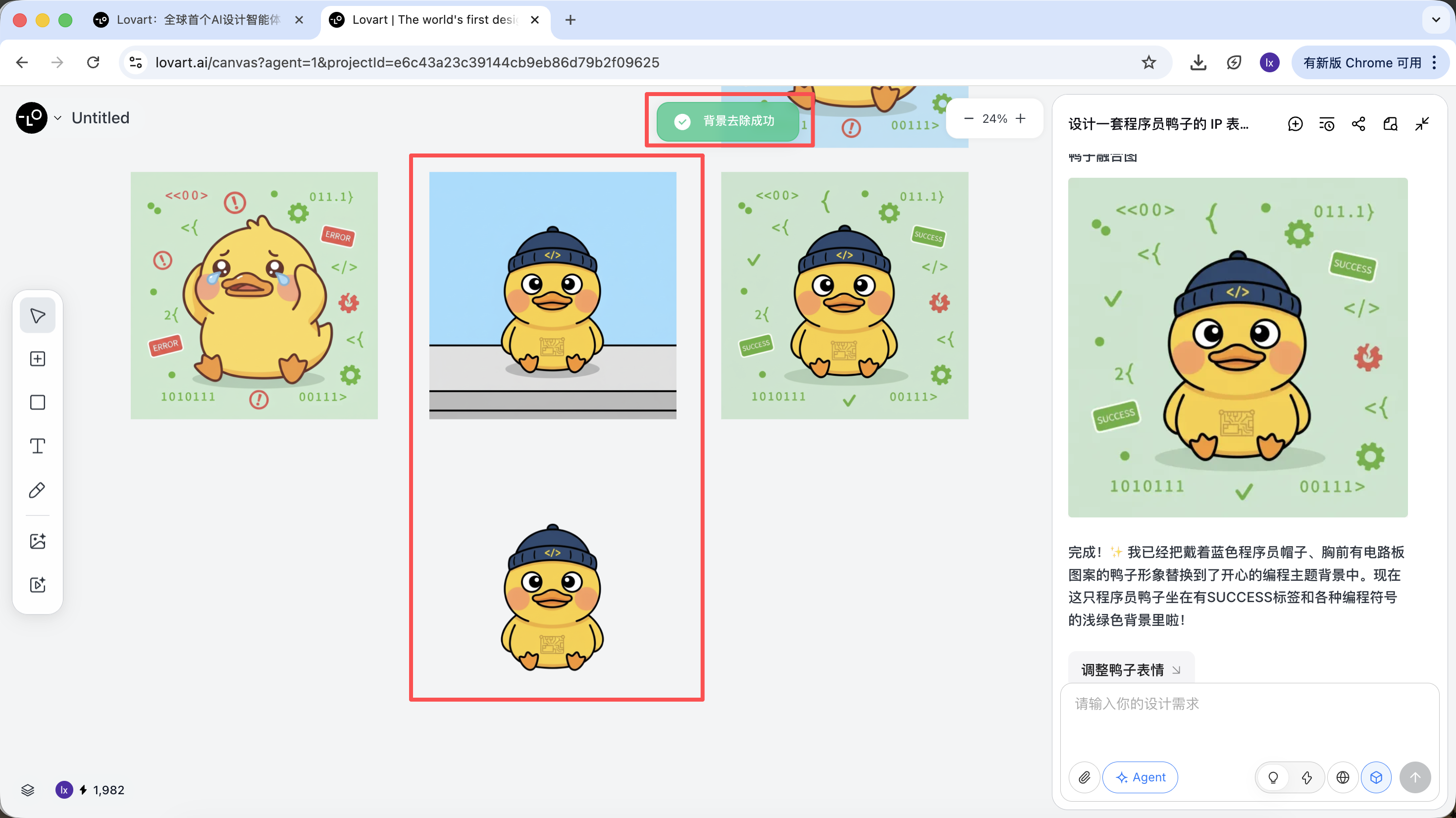
這些並不是簡單濾鏡,而是 Agent 自動調度不同工具完成的結果。
而在確定完基調風格後,可以很快速的生成一系列的表情包圖像。
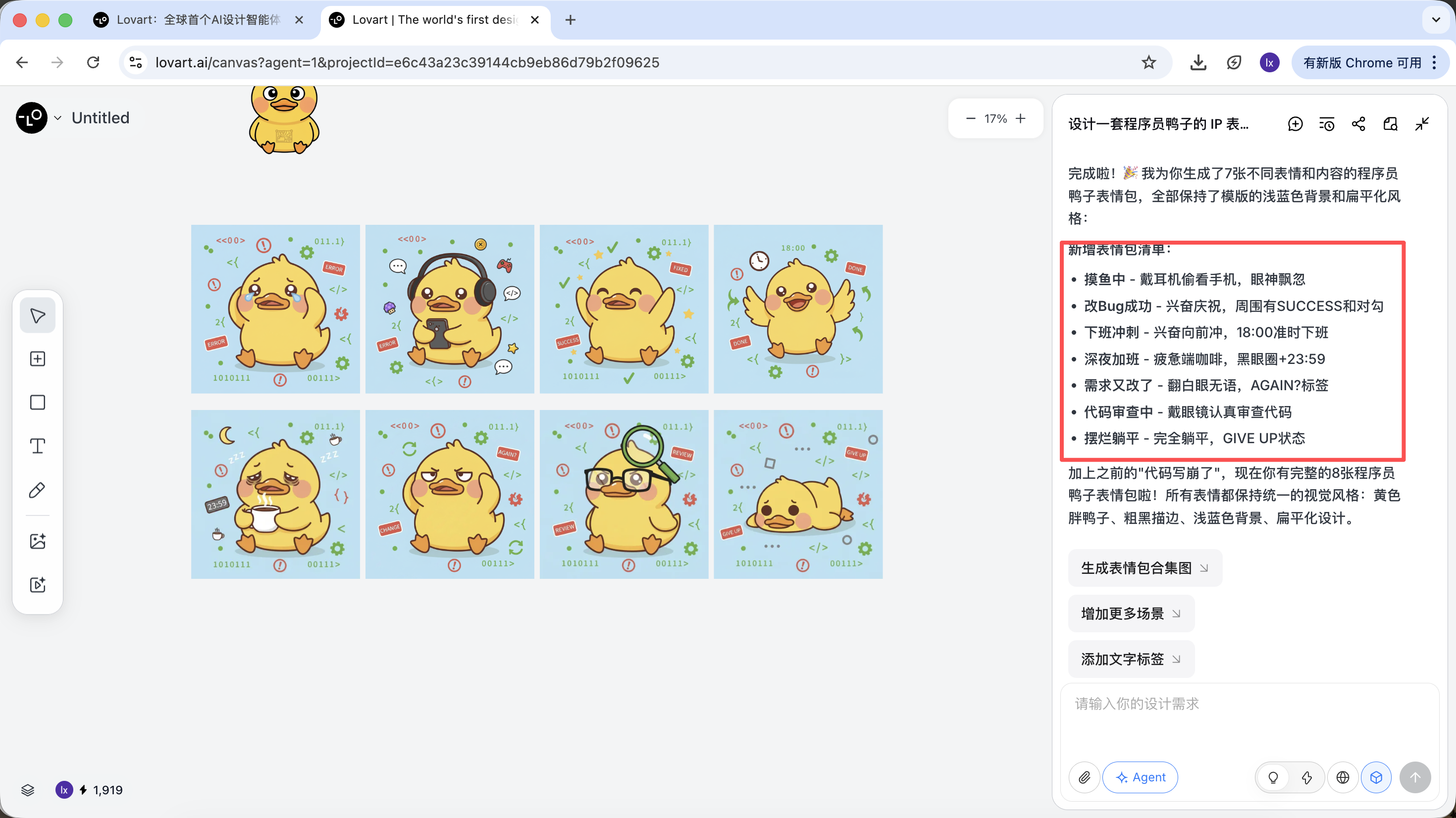
最終我們得到的是可直接交付的生產級素材,而不僅是一張展示圖。
2.3 使用與收費方式說明
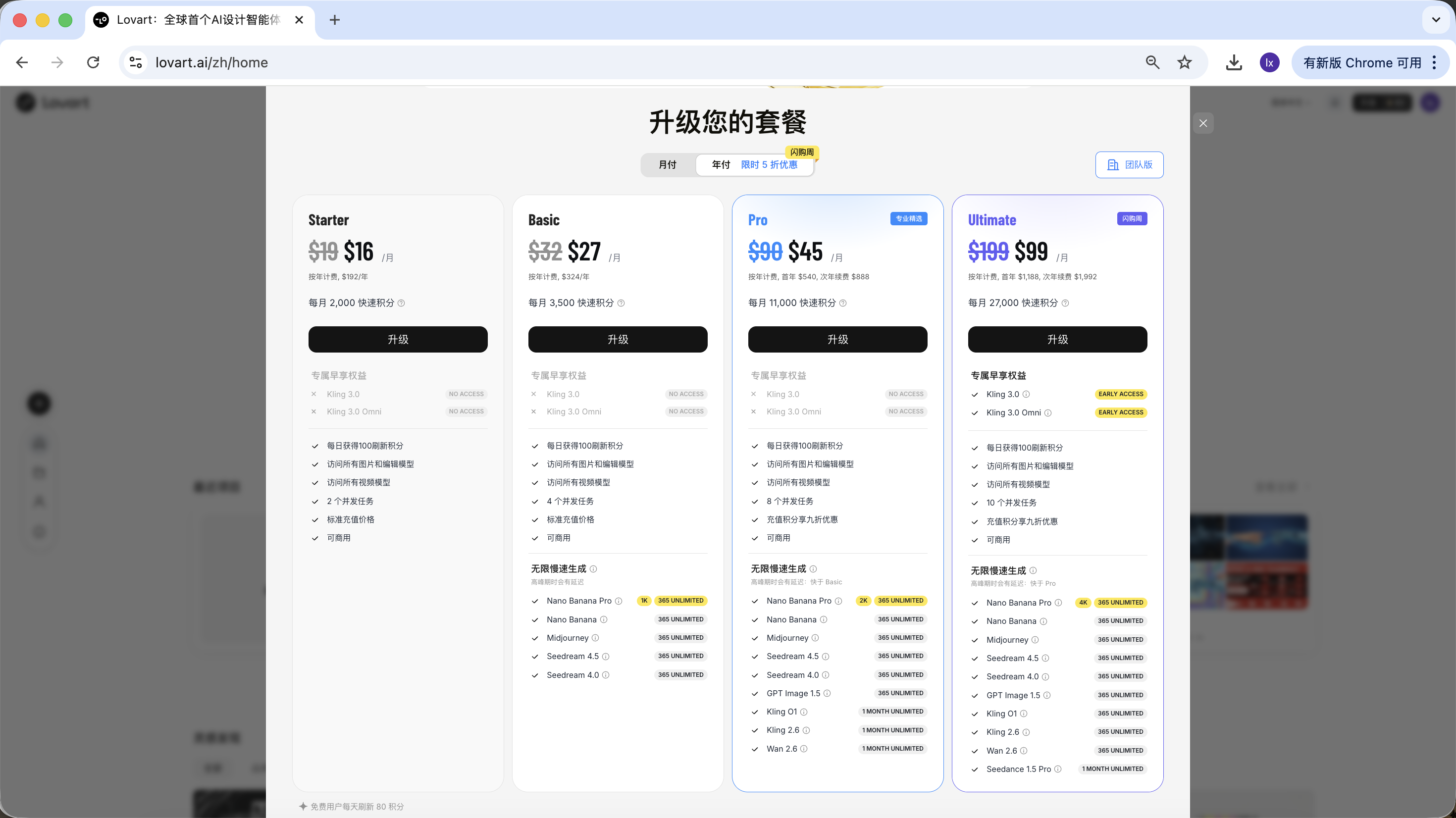
Lovart 採用訂閱制收費模式,不同套餐對應不同的使用額度與功能權限,具體以官網展示為準。
本教程不對任何套餐做推薦或比較;如果在實際使用中有需求,可以根據個人情況選擇付費升級。 目前支持通過支付寶等方式完成支付。
小結
Lovart 並不是替代底層模型,而是通過 Agent 機制,讓圖像生成從“單次執行”升級為“連續工作流”。
當任務開始涉及策劃、一致性和交付時,這類工具的優勢會變得非常明顯。
第 3 章:自己動手做一個智能繪圖助手
除了直接使用 Lovart,我們也可以自己實現一個簡化版的繪圖助手。
本章以“文章自動配圖”為例,從實際問題出發,逐步搭建一個帶有思考能力的 Agent。
3.1 痛點引入:為什麼直接發文章給畫圖模型沒用?
直接將一篇較長的文章輸入給 NanoBanana 並要求配圖,通常很難得到理想結果。原因並不在於模型“畫得不行”,而在於 它並不擅長理解長文本 。
圖像生成模型更適合處理簡短、明確的視覺描述,而當輸入變成一段包含結構、重點和上下文關係的文章時,模型無法判斷哪些內容才是畫面中真正需要表達的部分。這往往會導致生成結果偏離主題,或只能捕捉到零散細節,缺乏整體概括能力。
本質上,圖像模型只有“執行”的能力,卻缺少對文本進行分析和取捨的過程。
3.2 解決思路:用 Agent 把「理解」和「執行」拆開
要解決這個問題,關鍵並不是更復雜的提示詞,而是 在繪圖之前先把事情想清楚 。因此,我們在生成流程中引入一個獨立的「思考層」,並以此構建一個最簡單可用的 Agent。
這個 Agent 的核心目標只有一個:讓最終生成的圖片,儘可能貼近用戶真正的表達意圖。
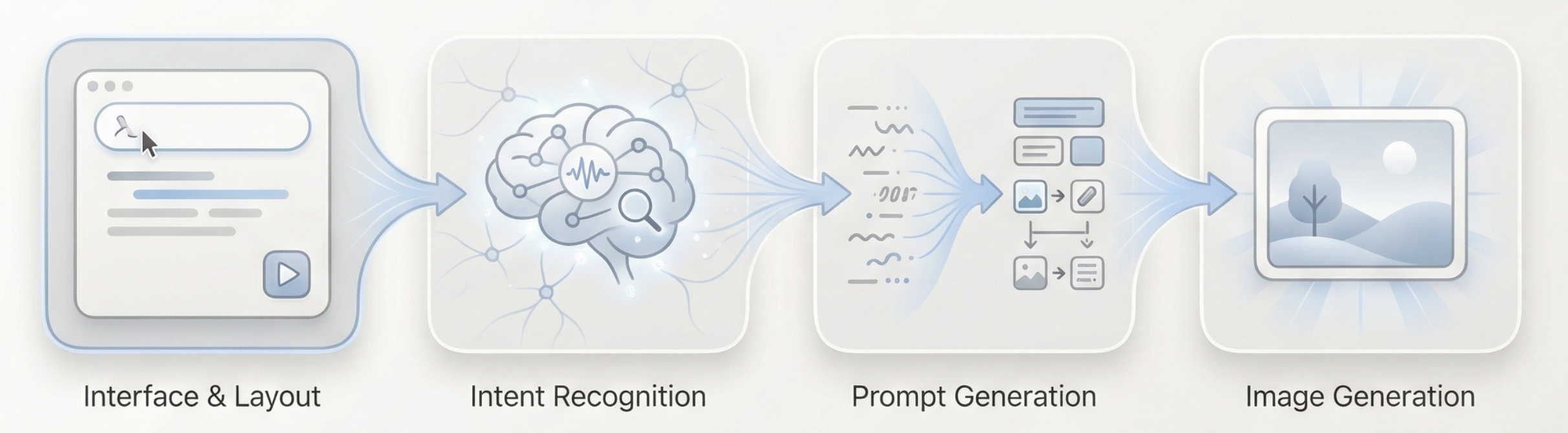
整體流程可以概括為:長文本輸入 → 語言模型理解與判斷 → 生成合適的視覺提示詞 → 圖像模型執行生成 → 輸出圖片
那我們構建的 Agent 怎樣才能明白用戶的意圖呢?
這裡選擇做一個簡化的 “思考層” ,我們設置了三種不同的意圖:無效輸入、直接生圖、需要理解的長文本。
在這個 Agent 中,各個角色的分工可以概括為四點:
- 語言模型作為決策核心 它負責理解文章內容、判斷用戶輸入的意圖,並將任務分發到合適的生成路徑中,決定接下來“該怎麼做”以及如何生成生圖提示詞。
- 圖像模型作為執行者 圖像模型不參與理解與判斷,只接收已經整理好的視覺指令,專注完成圖像渲染。
- 用戶作為可介入的引導者 除了直接輸入文本,用戶還可以在過程中手動調整生成的提示詞,或加入參考圖來輔助生成,從而對最終結果進行引導和微調。
- Gradio 與後端 API 作為整體承載層 它們負責將界面、模型調用和結果展示串聯起來,保證整個 Agent 能夠以一個完整 Web 應用的形式穩定運行。
3.3 實戰準備 :獲取API
看起來是不是很有趣呢!要跑通上述流程,我們只需要準備兩類 API。
手:NanoBanana API(圖像生成)
直接沿用第 1 章中已經配置好的 API Key 和 API URL,無需額外設置。
腦:SiliconFlow API(文本思考)
我們需要一個大語言模型來承擔“思考層”的職責。本教程使用 SiliconFlow 提供的模型服務:https://cloud.siliconflow.cn
SiliconFlow 提供了兼容 OpenAI API 規範的接口,可以非常方便地在項目中通過標準網路請求進行調用。在這裡我們選擇的是免費的Qwen2.5-7B-Instruct模型,調用需要的內容都已經寫入下面的Prompt。在開始之前,你只需要在官網註冊賬號並創建一個 API Key。
該 Key 將用於後續的模型調用。
3.4 搭建Agent :
本次實驗主要使用Trae來幫我們編寫程式碼,本教程選用的是Gemini-3-Pro-Preview模型。總思路是,新建項目後將下述完整 Prompt 複製到對話框並輸入,逐步替換 API KEY 後運行程式碼,完成測試即可。
環節1️⃣:Gradio Blocks 基礎框架與界面佈局
在這個環節,我們的主要目標是先給整個Agent搭建出一個“外觀”,實現前端的頁面設計。複製以下Prompt在Trae對話框中實現後,你將會得到一個本地的URL(通常是 http://127.0.0.1:7860 )即可查看界面,並且檢驗實現效果。
板塊 1:Gradio Blocks 基礎框架與界面佈局
1、任務目標
·基於 Gradio 4.0.0+ 的 Blocks 佈局,實現「LLM+Nanobanana 文生圖」項目的基礎界面,嚴格遵循固定左右分欄佈局,初始化所有 UI 組件並設置正確的初始狀態。
2、技術棧要求
·必須使用 Gradio 4.0.0+ 的 Blocks 模式開發,禁止使用 Interface 模式;
·依賴:gradio>=4.0.0,pillow>=10.0.0(僅導入,暫不實現圖片處理邏輯);
·程式碼需是完整可運行的 Python 文件,包含所有必要的導入語句。
3、界面佈局規則(核心約束,融合實戰細節)
·整體佈局:
頁面標題:LLM 驅動的文生圖全流程工具;
固定左右分欄:左側佔 60% 寬度,右側佔 40% 寬度,使用 gr.Row 和 gr.Column 實現比例控制。
·左側 60%(提示詞生成流程區)組件清單:
input_text:gr.Textbox,標籤「輸入文本(教程段落 / 繪圖指令)」,lines=6,佔位符「請輸入需要配圖的教程文本或直接繪圖指令...」;
identify_intent_btn:gr.Button,value="識別意圖",初始狀態正常可點擊;
intent_status:gr.Textbox,標籤「意圖類型 / 處理狀態」,lines=2,interactive=False,初始值「未識別意圖」;
system_prompt:gr.Textbox,標籤「System Prompt(僅文章配圖意圖可編輯)」,lines=4,interactive=False,佔位符「LLM 生成提示詞的約束規則...」;
confirm_prompt_btn:gr.Button,value="確認生成生圖提示詞",interactive=False(初始禁用防誤觸);
generation_prompt:gr.Textbox,標籤「生圖提示詞(可編輯)」,lines=3,interactive=True,初始值為空,佔位符「生成的英文生圖提示詞將顯示在此,支持手動修改...」。
·右側 40%(Nanobanana 生圖功能區)組件清單:
ref_image:gr.Image,標籤「參考圖(可選,圖生圖)」,type=filepath,height=300,允許上傳;
generate_btn:gr.Button,value="生成圖片",interactive=False(初始禁用,無提示詞不可點擊);
result_image:gr.Image,標籤「生成結果」,type=pil,height=300,初始為空,interactive=False。
4、交互邏輯要求
·所有組件的 interactive 初始狀態嚴格按上述配置,後續通過函數動態更新;
·按鈕禁用狀態需直觀(置灰),避免用戶誤操作。
5、輸出要求
·生成完整的 Python 程式碼,僅實現界面佈局和組件初始化,不包含任何業務邏輯;
·程式碼註釋清晰,組件命名與實戰版一致(input_text/identify_intent_btn 等);
·程式碼可直接運行,界面結構與描述完全一致。在瀏覽器打開http://127.0.0.1:7860後可看到Trae已經按照我們的要求生成了以下的網頁,跟我們的要求大致相當,可以進行到下一步的生成中了。
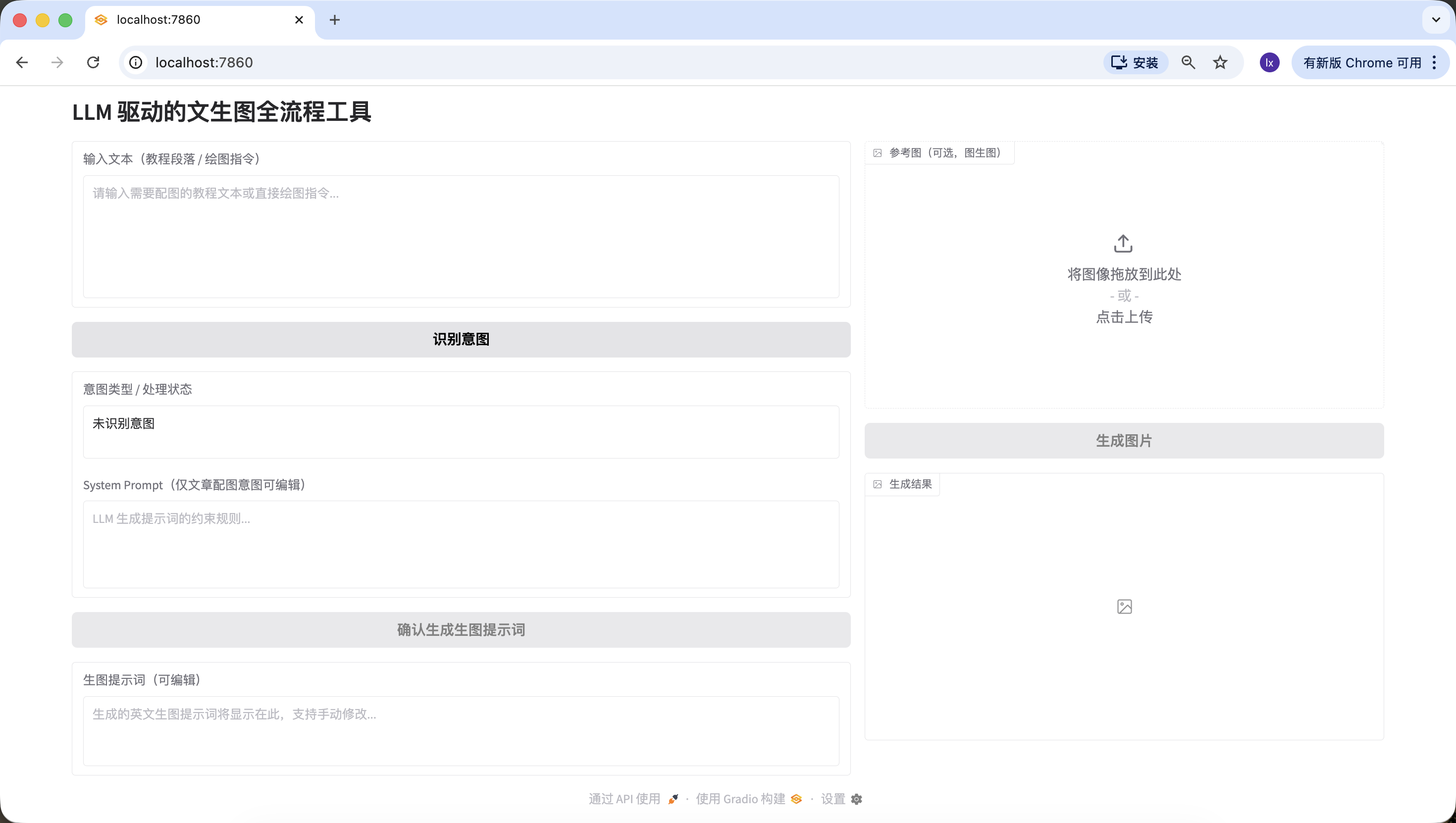
環節2️⃣:LLM 意圖識別模塊(Siliconflow API)
在日常使用VLM畫圖的時候,可能有以下三種常見輸入情況:
- 無意義內容,比如“你好”、“你今天吃飯了嗎”等,無法畫出對應的圖片。
- 文章/長文本,字數較多,比如200字左右的一篇有結構的文章,需要先理解文章的結構與內容,再考慮如何生成能完整概括這段文字的圖片。
- 直接繪圖指令,比如“幫我畫一隻在洗澡的狗”等,要求已經闡述的非常具體,可以直接生成圖片。
跟前面一樣,複製以下Prompt在Trae對話框中實現,並且補充在前面步驟中獲得的API。
板塊 2:LLM 意圖識別模塊(Siliconflow API)
1、任務目標
在已實現的 Gradio 界面基礎上,為「識別意圖」按鈕添加點擊邏輯,調用 Siliconflow API 完成意圖識別,並聯動組件狀態。
2、技術棧要求
基於 Gradio 4.0.0+ Blocks;
依賴:requests>=2.31.0,openai;
輸出完整可運行 Python 文件,包含板塊 1 界面 + 本模塊邏輯。
3、核心業務規則(絕對不可偏離)
·意圖分類規則(僅 3 類,嚴格返回數字 + 描述)
1 = 無意義內容:僅閒聊、寒暄、無關對話,沒有任何繪圖或配圖需求(如 “你好”“今天吃了嗎”);
2 = 文章 / 長文本配圖需求:用戶輸入一段完整文章、教程、段落、說明性文字,內容偏敘事 / 說明 / 講解,隱含需要為這段內容生成配圖的意圖,不需要用戶明確說 “為這段文字配圖”;
3 = 直接繪圖指令:用戶輸入簡短、明確的畫圖命令,沒有長文本背景,直接要求畫某個內容(如 “畫一隻 Apple 風格的貓”)。
·LLM 調用約束(融合實戰版模板)
接口地址:https://api.siliconflow.cn/v1/chat/completions;
模型:Qwen/Qwen2.5-7B-Instruct;
temperature=0.1;
統一定義程式碼:
python
運行
LLM_BASE_URL = "https://api.siliconflow.cn/v1"
LLM_API_KEY = "" # 用戶自行替換
LLM_MODEL = "Qwen/Qwen2.5-7B-Instruct"# 實戰驗證的意圖識別模板(固化到程式碼中)
INTENT_PROMPT_TEMPLATE = """你需要識別用戶輸入文本的意圖,僅返回以下 3 類結果中的一種(格式:數字 + 中文描述):
1 = 無意義內容;2 = 文章 / 長文本配圖需求;3 = 直接繪圖指令。
用戶輸入:{user_input}
識別結果:
僅提取返回結果中的數字和描述,禁止額外內容。"""
4、組件聯動規則
·結果為 1:intent_status 顯示「1 = 無意義內容:無繪圖需求」,system_prompt 保持禁用,confirm_prompt_btn 禁用;
·結果為 2:intent_status 顯示「2 = 文章 / 長文本配圖需求:為輸入內容生成配圖」,啟用 system_prompt 並填充默認規則,激活 confirm_prompt_btn;
·結果為 3:intent_status 顯示「3 = 直接繪圖指令:根據指令生成圖片」,system_prompt 禁用且填充默認規則,激活 confirm_prompt_btn。
5、異常處理
API 異常、解析異常均給出友好提示,不崩潰,組件恢復初始狀態。
6、輸出要求
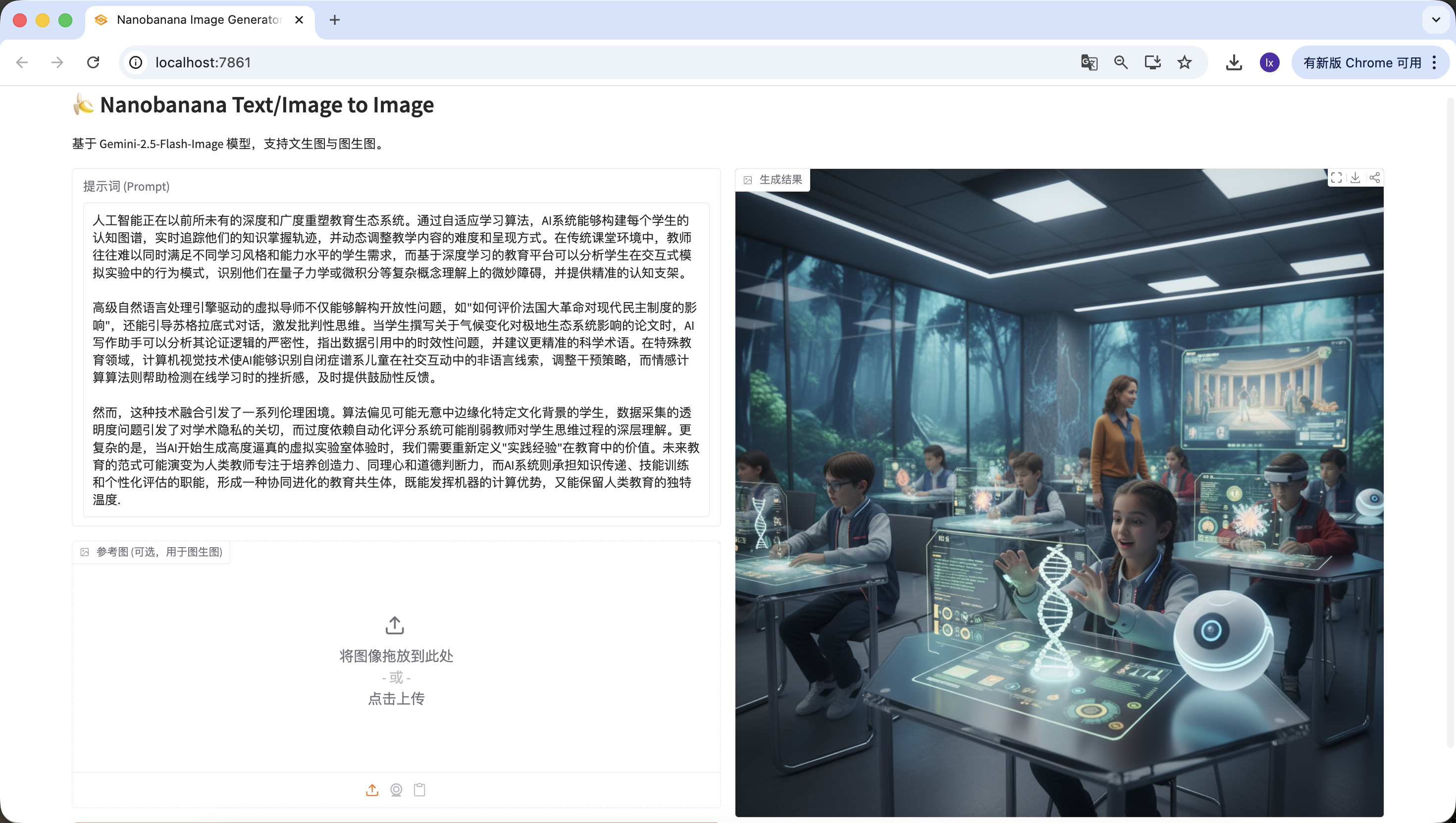
生成完整可運行程式碼,替換 LLM_API_KEY 即可使用,邏輯清晰註釋完整,意圖識別模板嚴格使用實戰版。刷新之前的http://127.0.0.1:7860網址,開始測試是否能正確檢測三種情況。
- 無意義內容,可以嘗試輸入“你好”、“謝謝”等,發現能夠正常識別。
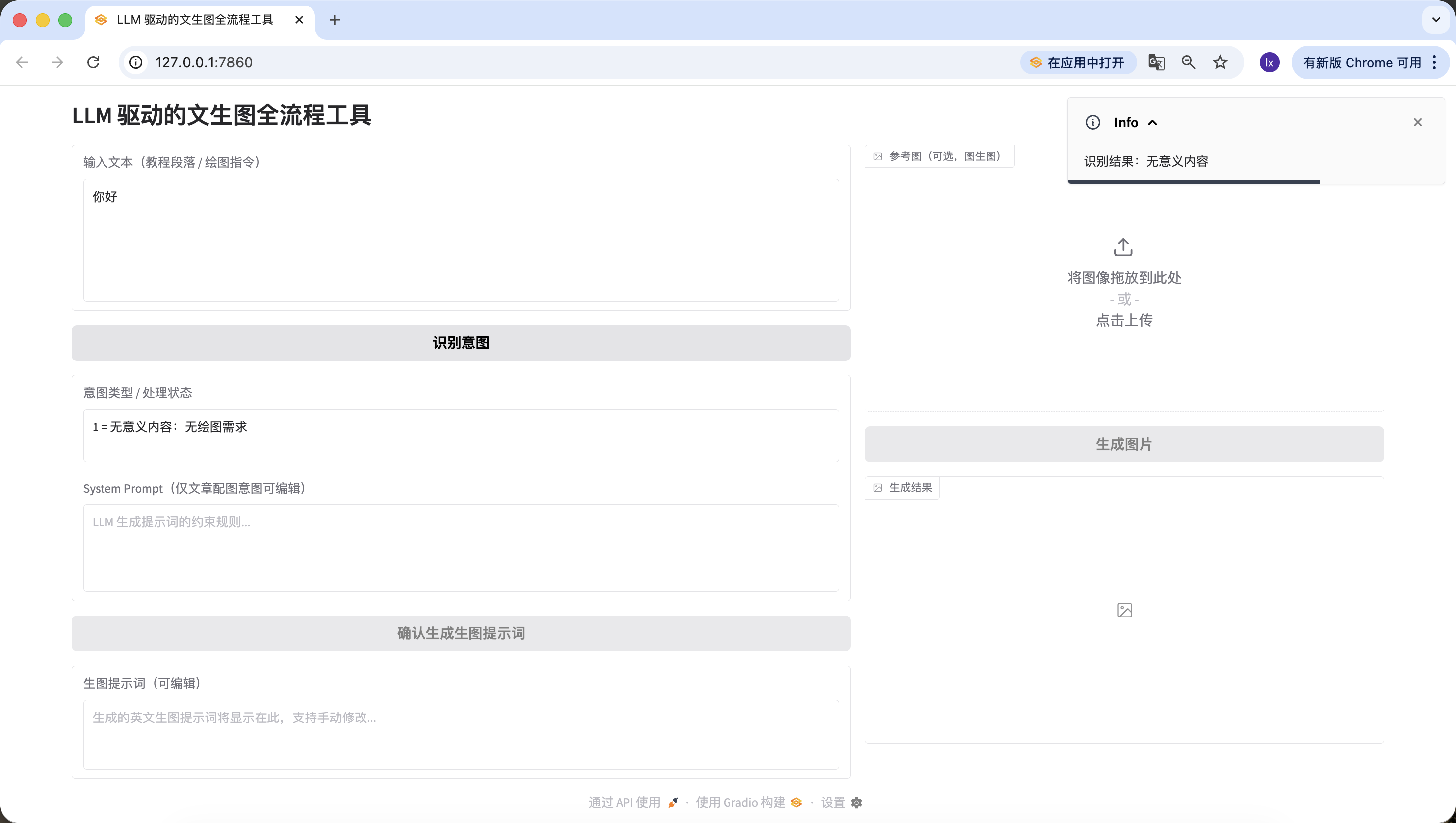
- 文章/長文本,在這裡我們選用了一段豆包生成的描述人工智能的文字。你也可以嘗試使用自己的論文段落進行測試。
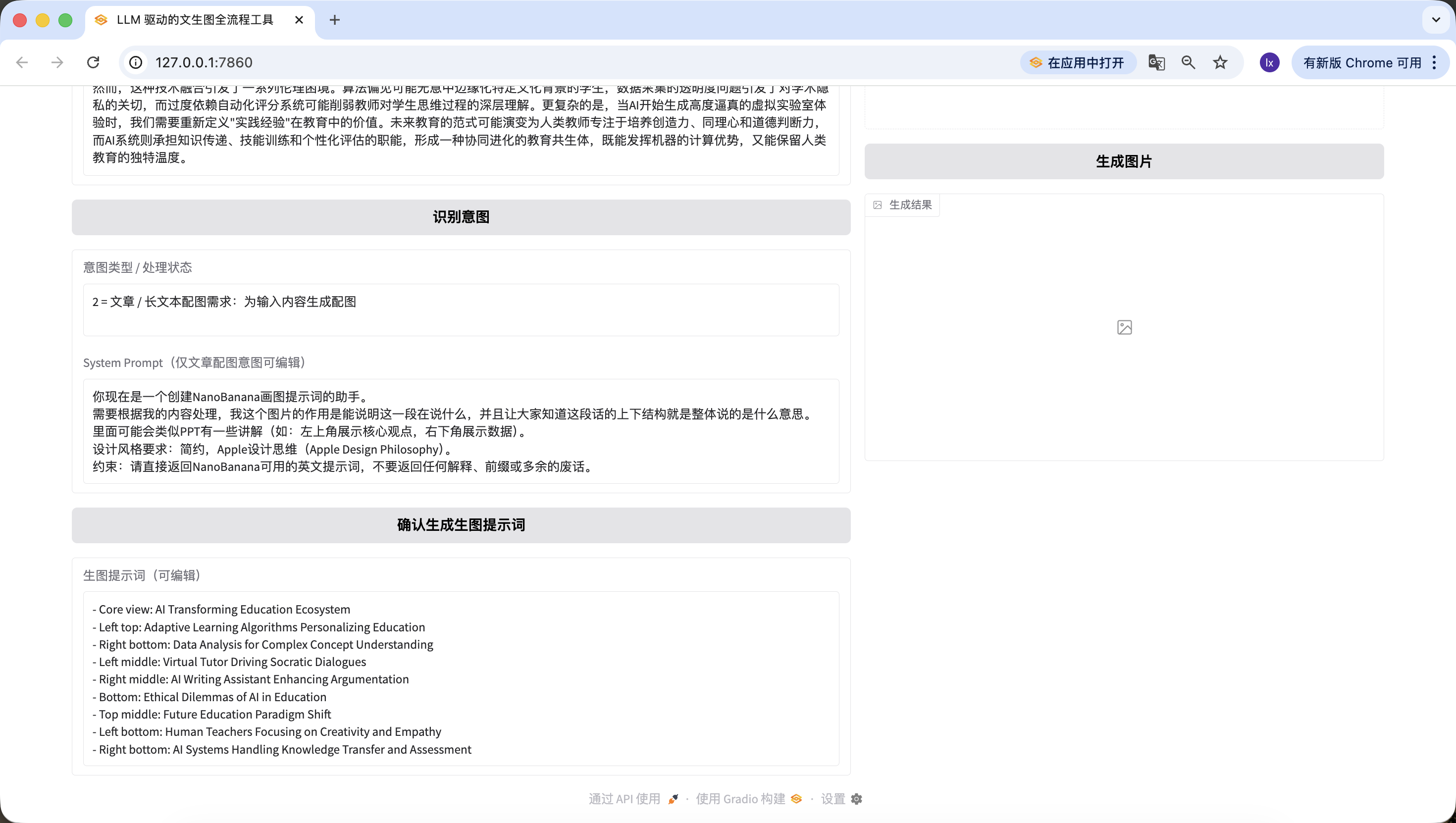
人工智能正在以前所未有的深度和廣度重塑教育生態系統。通過自適應學習算法,AI系統能夠構建每個學生的認知圖譜,實時追蹤他們的知識掌握軌跡,並動態調整教學內容的難度和呈現方式。在傳統課堂環境中,教師往往難以同時滿足不同學習風格和能力水平的學生需求,而基於深度學習的教育平臺可以分析學生在交互式模擬實驗中的行為模式,識別他們在量子力學或微積分等複雜概念理解上的微妙障礙,並提供精準的認知支架。
高級自然語言處理引擎驅動的虛擬導師不僅能夠解構開放性問題,如"如何評價法國大革命對現代民主制度的影響",還能引導蘇格拉底式對話,激發批判性思維。當學生撰寫關於氣候變化對極地生態系統影響的論文時,AI寫作助手可以分析其論證邏輯的嚴密性,指出資料引用中的時效性問題,並建議更精準的科學術語。在特殊教育領域,計算機視覺技術使AI能夠識別自閉症譜系兒童在社交互動中的非語言線索,調整干預策略,而情感計算算法則幫助檢測在線學習時的挫折感,及時提供鼓勵性反饋。
然而,這種技術融合引發了一系列倫理困境。算法偏見可能無意中邊緣化特定文化背景的學生,資料採集的透明度問題引發了對學術隱私的關切,而過度依賴自動化評分系統可能削弱教師對學生思維過程的深層理解。更復雜的是,當AI開始生成高度逼真的虛擬實驗室體驗時,我們需要重新定義"實踐經驗"在教育中的價值。未來教育的範式可能演變為人類教師專注於培養創造力、同理心和道德判斷力,而AI系統則承擔知識傳遞、技能訓練和個性化評估的職能,形成一種協同進化的教育共生體,既能發揮機器的計算優勢,又能保留人類教育的獨特溫度.同樣檢測成功~
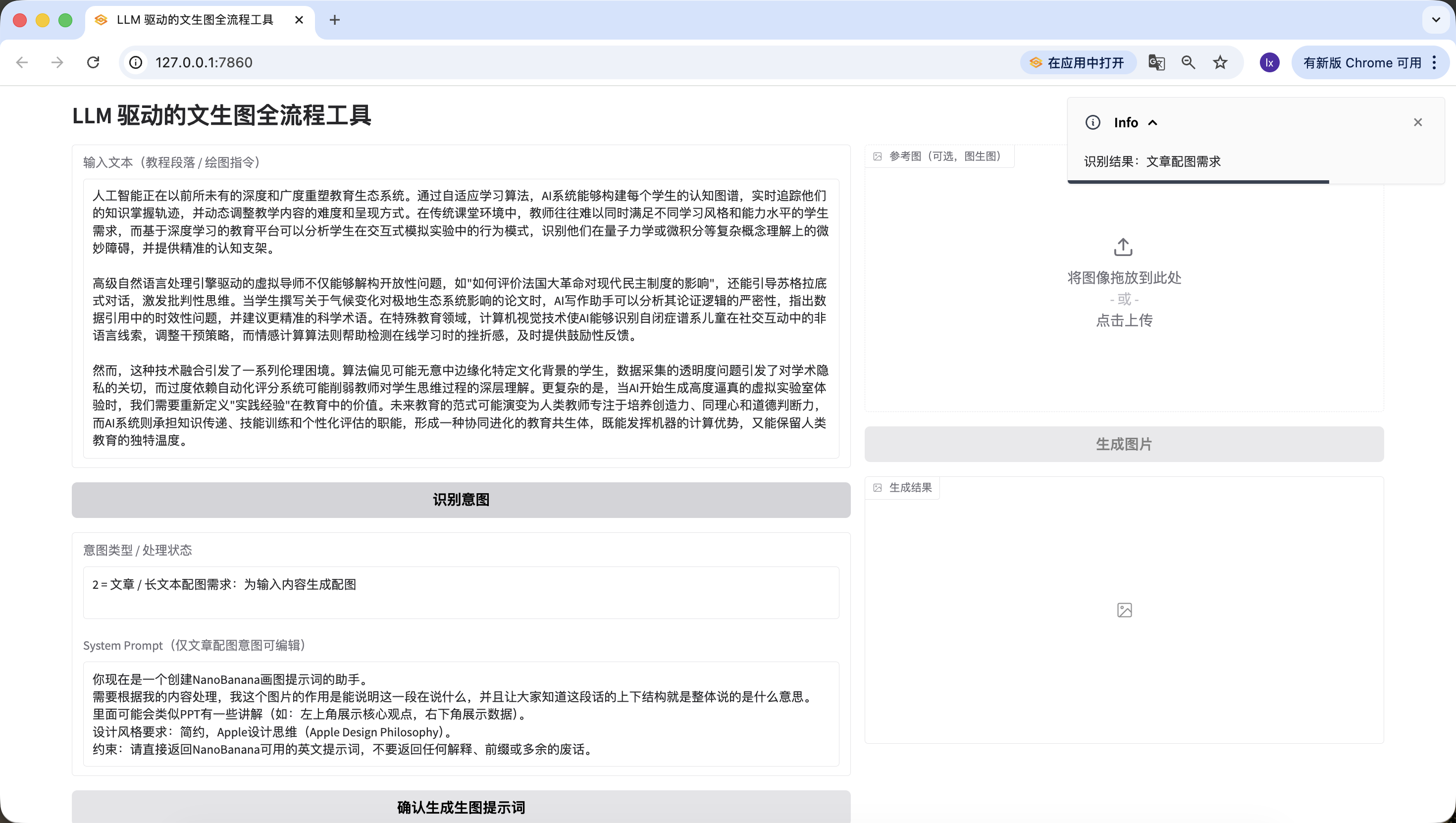
- 直接繪圖指令,這裡輸入的是“我要畫一隻貓”,同樣檢測準確。
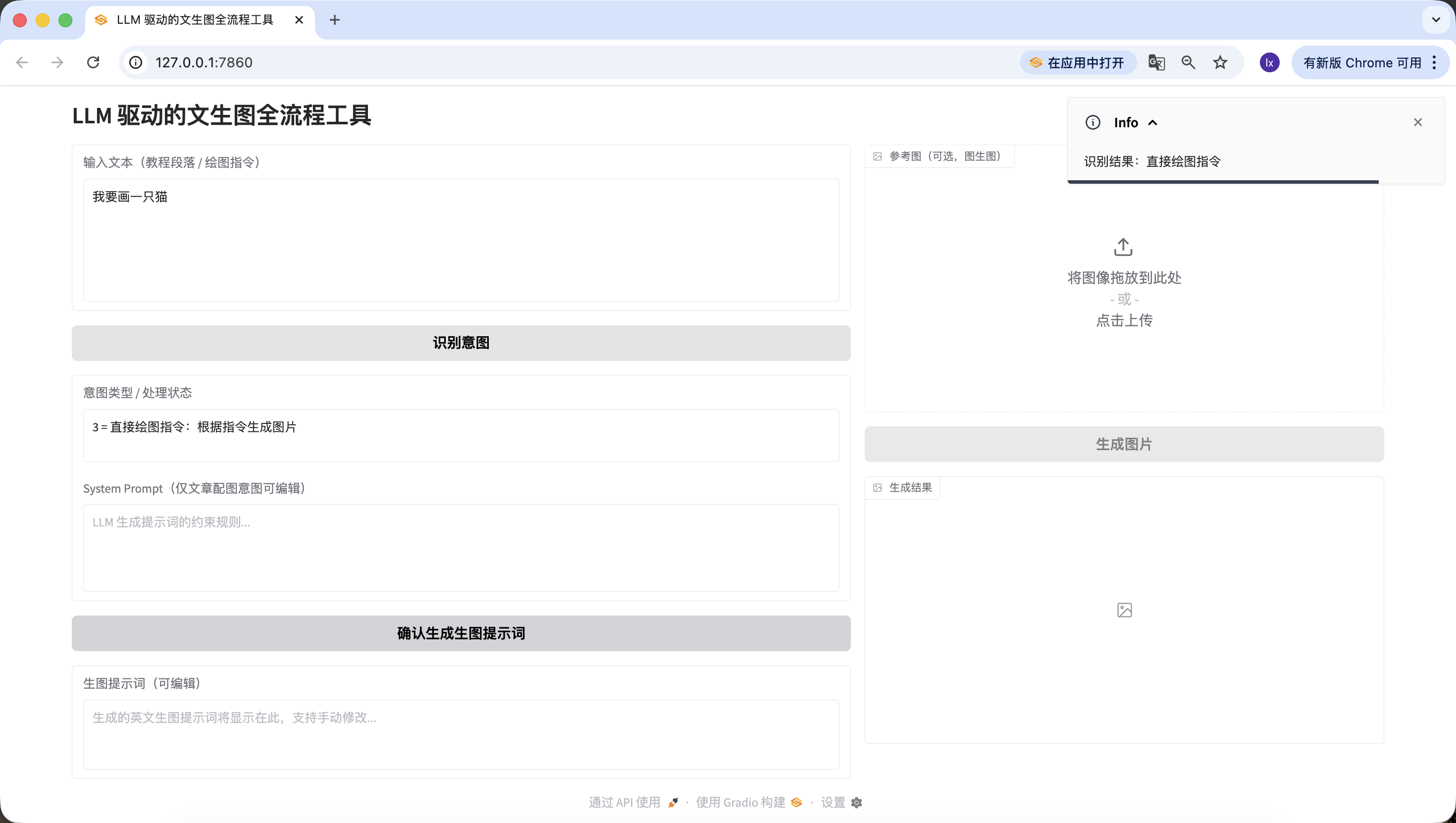
到這裡我們就已經順利實現了第二個環節——意圖識別。
環節3️⃣:生圖提示詞生成模塊(LLM 二次調用)
意圖識別後,對於文章或長文本,還有很重要的一步就是生成畫圖的提示詞,而這正是本Agent的重點。
板塊 3:生圖提示詞生成模塊(LLM 二次調用)
1、任務目標
在意圖識別基礎上,實現「確認生成生圖提示詞」按鈕邏輯,調用 LLM 將文本優化為適合繪圖的英文視覺提示詞,填充到編輯框並聯動「生成圖片」按鈕。
2、技術棧要求
同板塊 2,輸出完整程式碼 = 板塊 1 + 板塊 2 + 本模塊;
共用板塊 2 定義的 LLM_BASE_URL、LLM_API_KEY、LLM_MODEL,不新增密鑰。
3、核心業務規則(融合實戰版 Prompt 組裝邏輯)
·提示詞生成輸入規則(必須嚴格遵循)
生圖提示詞生成不再是簡單字符串拼接,而是構建標準 Chat 消息列表,程式碼結構如下:
python
運行
messages=[# System角色:網頁上用戶最終確認/編輯後的system_prompt內容{"role": "system", "content": final_system_prompt},# User角色:承載待處理資料,明確任務目標{"role": "user", "content": f"請為以下內容生成視覺提示詞:\n\n{user_input}"}]
意圖為 2 時:System 內容取用戶編輯後的 system_prompt 最終版本;
意圖為 3 時:System 內容取禁用狀態下填充的默認規則
user_input 為用戶最初輸入到 input_text 框的原始文本。
·實戰驗證的 System Prompt 預設(固化到程式碼中)
python
運行
SYSTEM_PROMPT_DEFAULT = """你現在是一個創建NanoBanana畫圖提示詞的助手。
需要根據我的內容處理,我這個圖片的作用是能說明這一段在說什麼,並且讓大家知道這段話的上下結構就是整體說的是什麼意思。
裡面可能會類似PPT有一些講解(如:左上角展示核心觀點,右下角展示資料)。
設計風格要求:簡約,Apple設計思維(Apple Design Philosophy)。
約束:請直接返回NanoBanana可用的英文提示詞,不要返回任何解釋、前綴或多餘的廢話。"""
·LLM 調用約束
與板塊 2 共用同一套 LLM_BASE_URL、LLM_API_KEY、LLM_MODEL;
temperature=0.7(保證提示詞的創意性與適配性);
max_tokens=200(限制輸出長度,匹配提示詞約束);
嚴格使用上述標準 Chat 消息列表結構,禁止字符串拼接。
·示例輸入輸出(核心參考)
輸入示例 1(文章配圖意圖):原始文本:「AI 如何改變教育:隨著人工智能技術的發展,教師的角色從知識傳授者轉變為引導者,AI 助手可輔助學生完成個性化學習,課堂上人機協作成為常態。」最終 System Prompt:SYSTEM_PROMPT_DEFAULT(未修改)輸出預期:"Minimalist illustration, Apple Design Philosophy, 1024x1024. Top left shows 'AI + Education' core concept, bottom right shows data of teacher-student-AI collaboration, soft color palette, clean lines, no redundant elements."
輸入示例 2(直接繪圖指令):原始文本:「畫一隻 Apple 風格的貓,坐在 MacBook 旁邊」最終 System Prompt:SYSTEM_PROMPT_DEFAULT(禁用狀態)輸出預期:"Minimalist cat, Apple style, 1024x1024, sitting next to a silver MacBook, clean white background, soft shadows, geometric shapes, no extra details."
·提示詞輸出強制約束
純英文,無中文;
必須包含 Apple Design Philosophy/Apple style + 1024x1024;
長度 50–200 字符,程式碼內校驗;
無額外解釋、前綴或廢話,僅返回提示詞本身。
4、組件聯動規則
生成成功:將提示詞填入 generation_prompt 框,激活 generate_btn,intent_status 追加「提示詞生成成功,可修改後生成圖片」;
生成失敗:提示具體原因(如 API 調用失敗、長度不達標),generate_btn 保持禁用,generation_prompt 框為空;
用戶手動修改 / 清空 generation_prompt 框:
清空時自動禁用 generate_btn;
非空時保持 generate_btn 激活。
5、異常處理
API 調用失敗:友好提示「提示詞生成失敗:{具體錯誤資訊}」,不崩潰;
提示詞校驗失敗:明確提示原因(如 “未包含 Apple style”“長度僅 40 字符”),允許重試;
響應解析失敗:提示「無法解析 LLM 返回結果,請重試」。
6、輸出要求
完整可運行程式碼,替換 LLM_API_KEY 即可使用;
程式碼結構清晰、註釋完善,界面美觀簡潔;
嚴格實現標準 Chat 消息列表結構,參數與示例邏輯一致;
包含提示詞長度、內容校驗邏輯,錯誤提示友好。同樣複製第二個環節的文本進行檢測。
值得注意的是,我們在這裡預設的生成生圖提示詞的System Prompt為:
你現在是一個創建NanoBanana畫圖提示詞的助手。 需要根據我的內容處理,我這個圖片的作用是能說明這一段在說什麼,並且讓大家知道這段話的上下結構就是整體說的是什麼意思。 裡面可能會類似PPT有一些講解(如:左上角展示核心觀點,右下角展示資料)。 設計風格要求:簡約,Apple設計思維(Apple Design Philosophy)。 約束:請直接返回NanoBanana可用的英文提示詞,不要返回任何解釋、前綴或多餘的廢話。
如果你想換成其他的預設模版,可以在前面的prompt裡修改,或者直接在Trae裡通過對話修改。
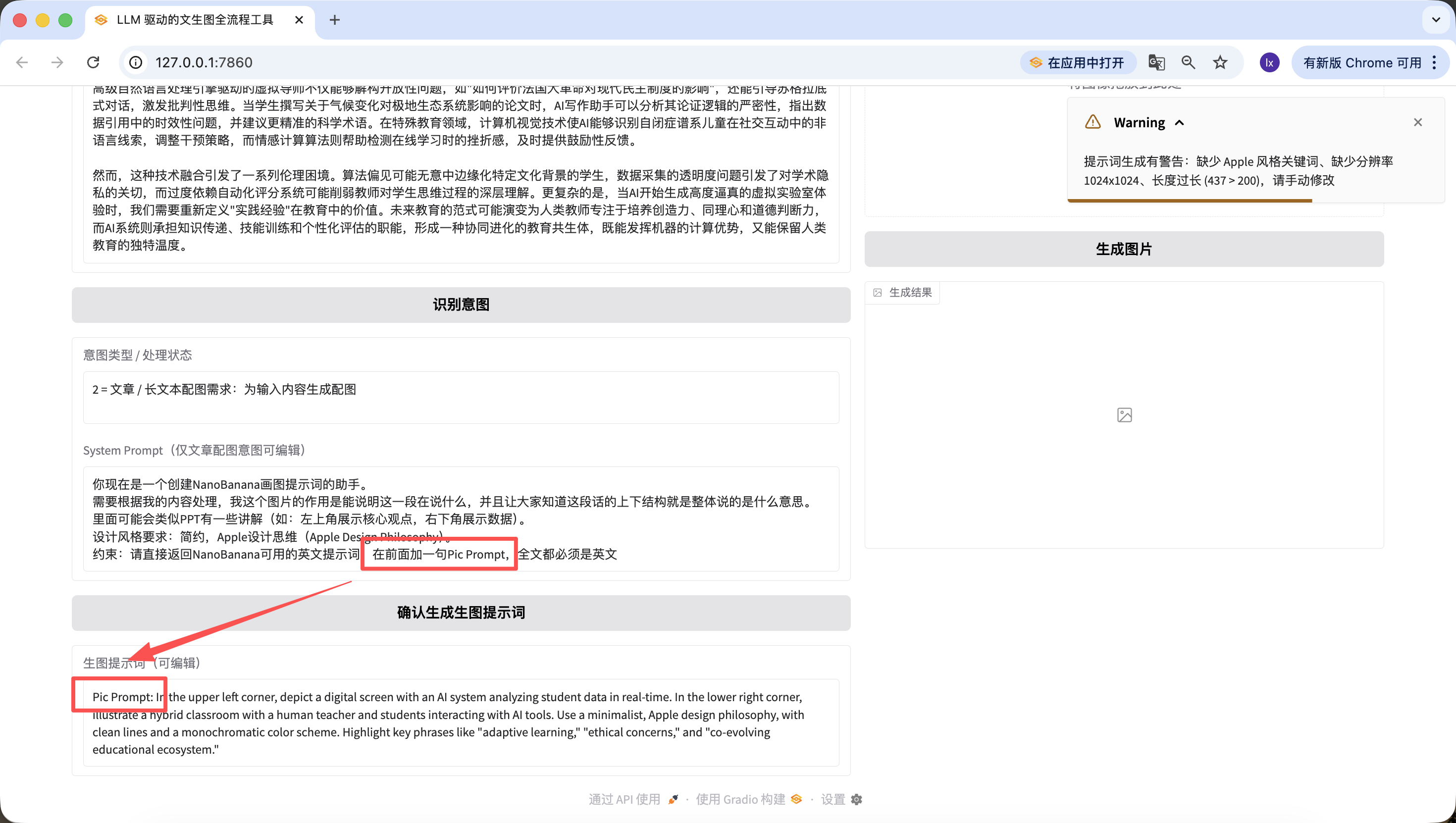
除了修改底層程式碼,我們在網頁上也可以快速編輯。舉個例子,我在這裡加了一句,“在前面加一句Pic Prompt”,可以看到生成的新的提示詞前面也包含了~這樣設計是為了方便快速修改生成提示詞的System Prompt,幫助我們快速切換風格。
環節4️⃣:Nanobanana 文生圖 / 圖生圖模塊
終於來到了最後一步,不接入生圖模型,就不是一個完整的Agent!
板塊 4:Nanobanana 文生圖 / 圖生圖模塊(最終版)
1、任務目標
實現「生成圖片」按鈕邏輯,調用真實 Nanobanana API,支持文生圖 / 圖生圖,解析 Base64 並展示圖片。
2、技術棧要求
基於 Gradio 4.0.0+ Blocks;
依賴:requests, pillow, base64, io, re;
完整程式碼 = 板塊 1+2+3 + 本模塊。
3、核心 API 配置(實戰驗證固化)
固化程式碼配置:
python
運行
# 固化到程式碼中的API配置
NANOBANANA_API_URL = "https://api.zyai.online/v1/chat/completions"
NANOBANANA_MODEL = "gemini-2.5-flash-image"
NANOBANANA_API_KEY = "" # 用戶自行替換
鑑權方式:Header Authorization: Bearer {NANOBANANA_API_KEY}。
4、圖片預處理要求(必須實現)實現函數 image_to_base64_data_uri (ref_image_path),核心邏輯:
將 PIL 圖片轉為 PNG 格式;
自動縮放到 1024x1024 分辨率;
透明通道轉為白色背景;
編碼為 Base64,返回格式:data:image/png;base64,...。
5、請求構建規則(嚴格按實戰版分支邏輯)
·核心函數定義實現函數 generate_image (prompt, ref_image_path):
入參:prompt(generation_prompt 框內容)、ref_image_path(ref_image 上傳的文件路徑);
返回:PIL Image(展示到 result_image)或錯誤提示。
·邏輯分支 1:純文生圖(ref_image_path 為空)
python
運行
messages = [{"role": "user", "content": prompt}]
·邏輯分支 2:圖生圖(ref_image_path 有值)
python
運行
# 先調用圖片預處理函數
image_base64 = image_to_base64_data_uri(ref_image_path)
messages = [{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url", "image_url": {"url": image_base64}}]}]
6、響應解析要求(必須兼容兩種格式)從 choices [0].message.content 中提取圖片 Base64,支持:
結構化 JSON 返回的 image_url 字段;
Markdown 格式
;
統一提取 Base64 編碼,解碼後轉換為 PIL Image 返回。
7、組件聯動與異常處理
生成成功:將 PIL Image 展示到 result_image,intent_status 提示「圖片生成成功」;
生成 / 解析 / 上傳失敗:在 intent_status 顯示清晰文字提示(如 “Base64 解析失敗”“API 調用超時”),不崩潰。
8、輸出要求
完整可運行程式碼,替換 LLM_API_KEY 和 NANOBANANA_API_KEY 即可直接運行,全流程可用,分支邏輯嚴格匹配實戰版。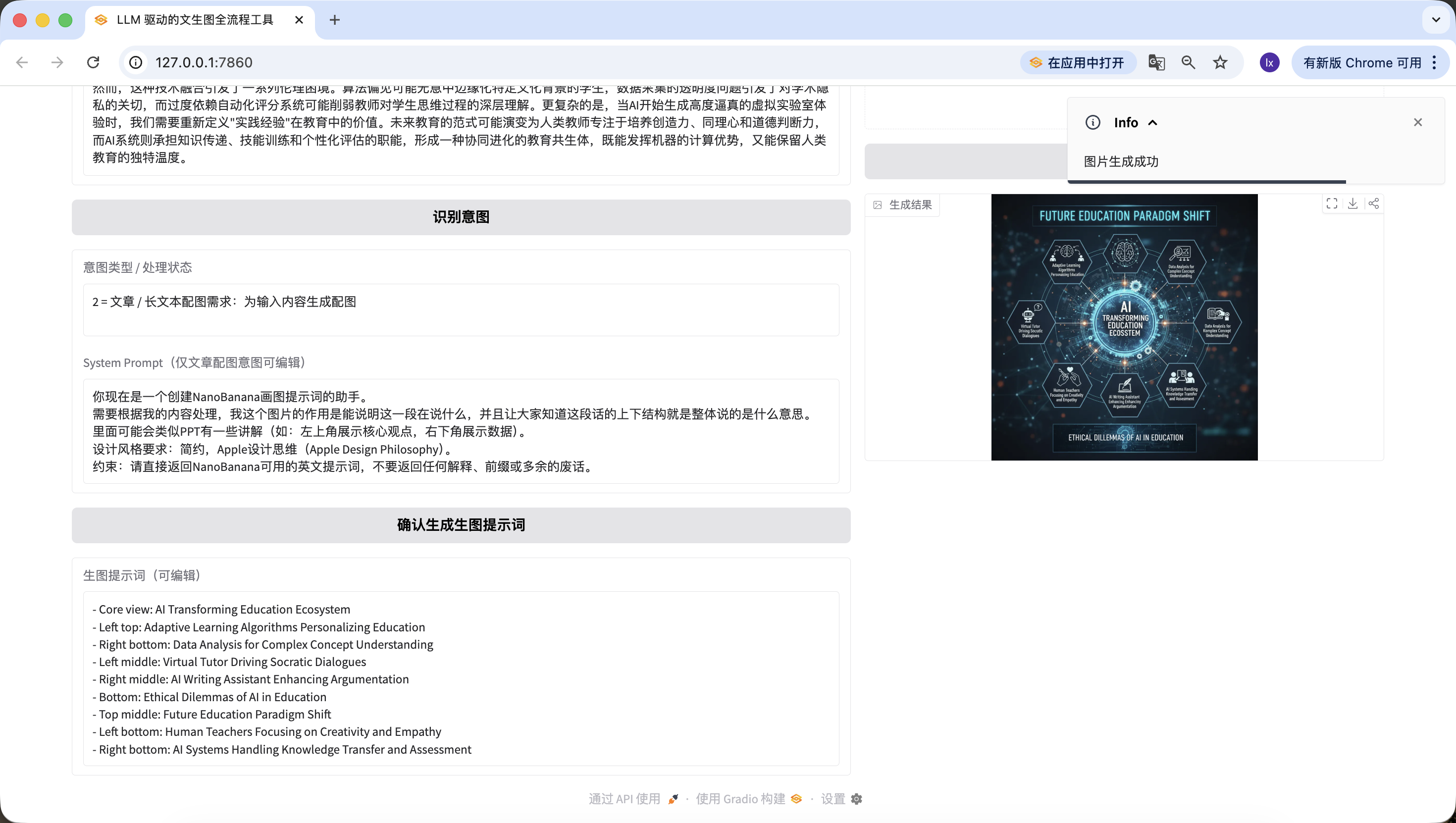
太令人激動啦!我們終於順利地生成出了這個Agent的第一張圖,仔細看看生成的圖片,跟我們的文本和提示詞是匹配的。到這裡你已經基本上實現你自己的Agent啦!

我們還添加了圖生圖功能,上傳你喜歡的圖片,AI會自動借鑑風格。
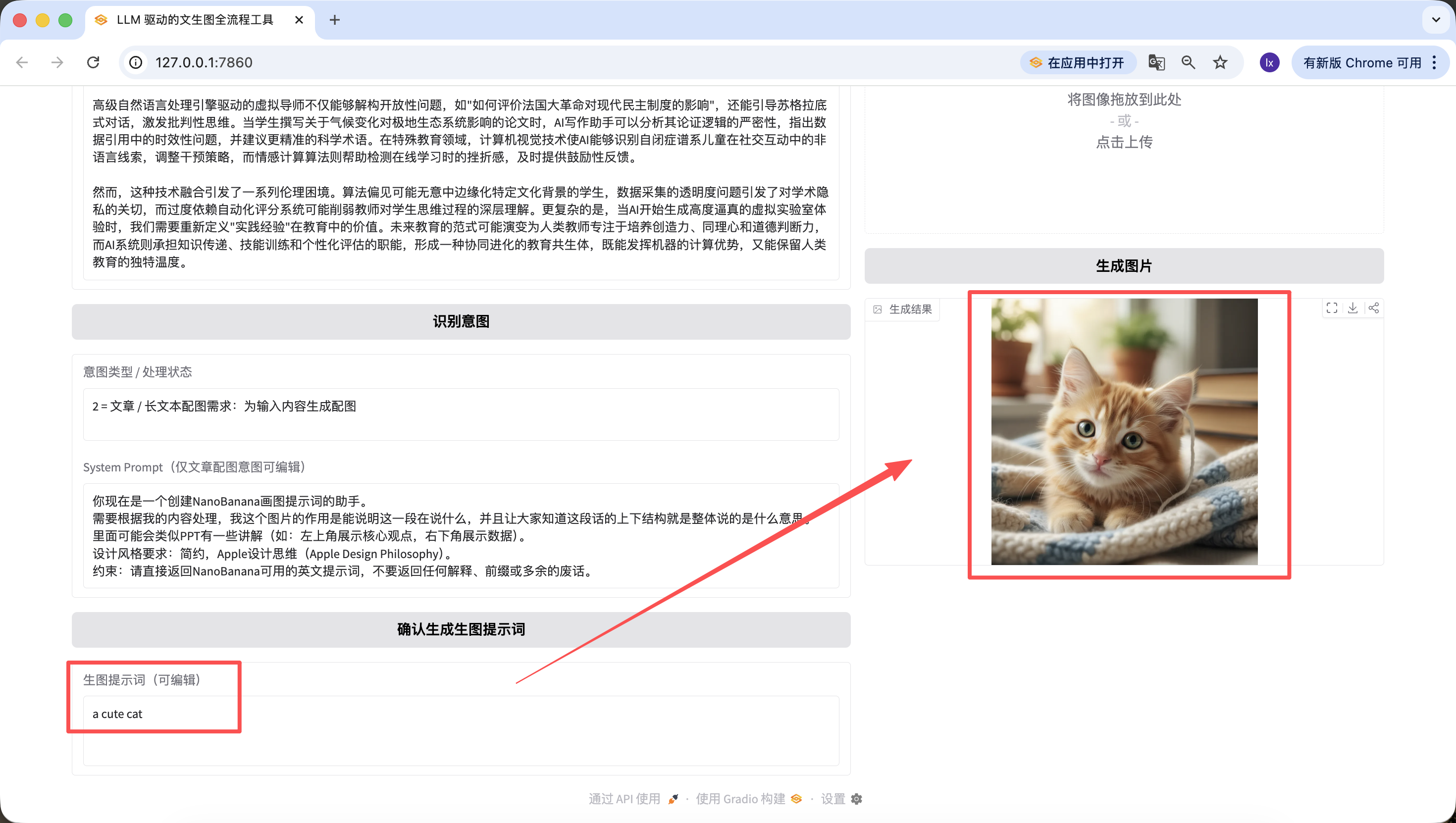
值得一提的是,前面步驟生成的提示詞也是可以在網頁上編輯的,並且我們是以最終點擊按鈕時的提示詞為準~哪怕我在這裡換成“a cute cat”,最終生成的圖片也只會是可愛的小貓。
第 4 章:總結

嗚呼!終於寫完了。 說實話,連我自己寫完最後一行的時候都忍不住長舒一口氣,更別說一路跟著做到這裡的你了。能把這一整套流程完整跑下來,本身就已經很厲害了,這說明你真的把手放到鍵盤上,把事情一步步做完了。Bravo 🎉 🥳 👏
在寫這套內容的過程中,我一直在想,我們到底要留下些什麼?答案其實並不是模型名字、參數或者某種固定套路,而是讓你慢慢建立起一種感覺:哪些事情可以放心交給 AI 去理解和規劃,哪些地方只需要你來決定方向。一旦這層分工成立,很多原本看起來複雜的生成流程,都會開始變得順起來。
回頭看,這條路其實並不複雜。想清楚你要解決的問題,把長文本交給語言模型去拆解,再把整理好的視覺意圖交給繪圖模型去呈現,最後把這一整套流程封裝成一個屬於你自己的小助手。到這裡,你已經不只是“在用模型”,而是在搭建一套可以長期陪你工作的系統,而這,才是這套教程最想帶給你的東西。
但是你已經做的很棒啦!相信學到這裡的你對Vibe Coding已經有初步的掌握了,給自己放個小假休息一下吧!