NanoBanana로 시작하기: 나만의 에셋 제작 Agent 만들기
제1장: 1분 만에 첫 번째 이미지 에셋 생성하기
디자인, 스타일, 프롬프트 엔지니어링에 대해 논의하기 전에, 먼저 가장 적은 단계로 첫 번째 이미지를 생성해 보겠습니다.
1.1 NanoBanana 알아보기
디자인 스타일과 프롬프트 엔지니어링을 논의하기 전에, 먼저 더 중요한 한 가지를 해결하겠습니다: 실제로 이미지를 생성할 수 있다는 것을 확인하는 것입니다.
현재 주류 대형 모델은 이미 이미지 생성 및 편집 능력을 갖추고 있으며, 이러한 모델은 보통 생성형 모델 이라고 불립니다.
과정을 최대한 단순화하기 위해, 이 튜토리얼은 안정적인 이미지 생성 및 편집 능력을 갖춘 모델을 예시로 선택했습니다 — NanoBanana. 이는 Google이 출시한 이미지 생성 모델로, 공식 명칭은 Gemini 3.1 Flash Image Preview 이며, 자연어로 직접 이미지를 생성할 수 있고, 기존 이미지를 기반으로 수정하는 것도 지원합니다.

기능 측면에서, 여러분이 들어본 다른 모델(예: GPT-4o, Claude, Qwen, Midjourney 등)과 본질적인 차이는 없습니다: 설명을 입력하면, 모델이 결과를 생성합니다.



이를 하나의 "붓"으로 이해할 수 있습니다. 이 장에서 우리는 단 한 가지에만 관심이 있습니다: 👉 이 붓이 여러분의 손에서 첫 번째 획을 그릴 수 있는지.
실제 사용에서 NanoBanana은 Google AI Studio 등 공식 플랫폼을 통해 직접 사용할 수도 있고, API 방식으로 개발 프로세스에 통합할 수도 있습니다. 이 튜토리얼은 API 호출 방식을 사용합니다. 현재 NanoBanana 2 모델도 출시되었으니, 최신 대형 모델로 시도해 볼 수 있습니다.
1.2 "Hello World" 수준의 생성
시작하기 전에 다음 세 단계만 완료하면 됩니다:
- Trae에서 새 폴더 만들기
- 새 Python 파일 만들기
- 아래 코드를 완전히 복사하여 붙여넣기
Trae가 필요한 환경 배포와 의존성 설치를 자동으로 완료하므로, 추가 설정이 필요하지 않습니다.
코드에는 NanoBanana의 API Key가 필요합니다. 여기서는 신청 과정을 자세히 설명하지 않습니다 — 해당 파라미터를 얻어 입력하기만 하면 됩니다. 이 단계에서는 모든 코드 라인을 이해하는 것을 추구하지 않고, 성공적으로 실행되기만 하면 됩니다.
# /// script
# dependencies = [
# "gradio>=4.0.0",
# "pillow>=10.0.0",
# "requests>=2.31.0",
# ]
# ///
import gradio as gr
import requests
import base64
from PIL import Image
import io
import os
import time
import re
from typing import Optional, Dict, Any, List
# API 정보 구성
NANOBANANA_API_URL: str = "YOUR API URL"
NANOBANANA_API_KEY: str = "YOUR API KEY"
OUTPUT_DIR: str = "outputs"
# 출력 디렉토리가 존재하는지 확인
os.makedirs(OUTPUT_DIR, exist_ok=True)
def image_to_base64_data_uri(image: Image.Image) -> str:
"""
PIL 이미지를 OpenAI API 호환 data URI 형식으로 변환합니다.
"""
buffer = io.BytesIO()
# 호환성을 위해 통일하여 PNG로 변환
image.save(buffer, format="PNG")
encoded = base64.b64encode(buffer.getvalue()).decode('utf-8')
return f"data:image/png;base64,{encoded}"
def base64_to_image(base64_str: str) -> Optional[Image.Image]:
"""
순수 base64 문자열을 PIL Image로 변환합니다.
"""
try:
image_bytes = base64.b64decode(base64_str)
return Image.open(io.BytesIO(image_bytes))
except Exception as e:
print(f"Base64 디코딩 실패: {e}")
return None
def extract_base64_from_response(content: Any) -> Optional[str]:
"""
핵심 파싱 로직: API가 반환한 content에서 이미지 Base64 데이터를 추출합니다.
Markdown 형식과 구조화된 리스트 형식을 모두 호환합니다.
"""
if not content:
return None
base64_data = None
# 1. 구조화된 추출 시도 (List)
# 해당 반환 형식: [{"type": "image_url", "image_url": {"url": "data:..."}}]
if isinstance(content, list):
for part in reversed(content): # 역순으로 검색, 일반적으로 최신 이미지가 마지막에 있음
if isinstance(part, dict):
# image_url 또는 output_image 필드 확인
img_field = part.get("image_url") or part.get("image") or part.get("output_image")
if isinstance(img_field, dict):
url = img_field.get("url", "")
if url.startswith("data:image/") and "," in url:
return url.split(",", 1)[1].strip()
# 리스트에 구조화된 이미지가 없으면, 리스트 내 텍스트를 연결하여 Markdown 검색
text_parts = [
str(p.get("text", ""))
for p in content
if isinstance(p, dict) and p.get("type") in ["text", "input_text"]
]
content_str = "".join(text_parts)
else:
content_str = str(content)
# 2. Markdown 정규식 추출 시도 (String)
# 해당 반환 형식: "Here is your image: "
pattern = re.compile(r"!\[.*?\]\((data:image/[^;]+;base64,[^)]+)\)", re.IGNORECASE)
match = pattern.search(content_str)
if match:
data_url = match.group(1)
if "," in data_url:
return data_url.split(",", 1)[1].strip()
return None
def synthesize(prompt: str, input_image: Optional[Image.Image]) -> Optional[Image.Image]:
"""
Nanobanana API를 호출하여 생성합니다.
"""
if not prompt or not prompt.strip():
gr.Warning("프롬프트를 입력해 주세요")
return None
print(f">>> 작업 시작: {prompt[:50]}...")
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {NANOBANANA_API_KEY}"
}
# OpenAI Vision / Chat 표준에 맞는 payload 구성
messages = []
if input_image is not None:
# 이미지에서 이미지/멀티모달 입력 모드
print(">>> 입력 이미지가 감지되어 멀티모달 모드를 사용합니다")
img_base64 = image_to_base64_data_uri(input_image)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": img_base64}}
]
})
else:
# 순수 텍스트에서 이미지 생성 모드
messages.append({
"role": "user",
"content": prompt
})
payload = {
"messages": messages,
# 첫 번째 코드에서 검증된 사용 가능한 모델 사용
"model": "gemini-2.5-flash-image",
# 선택적 파라미터, API 지원 여부에 따라 다름
"stream": False
}
try:
# 타임아웃 시간 증가, 이미지 생성은 보통 더 느림
response = requests.post(NANOBANANA_API_URL, headers=headers, json=payload, timeout=120)
# HTTP 상태 확인
if response.status_code != 200:
error_msg = f"API 요청 실패: {response.status_code} - {response.text}"
print(error_msg)
gr.Error(error_msg)
return None
result = response.json()
# Debug: 반환 결과의 앞부분 출력, 디버깅에 편리
print(f"API 원본 응답 (잘림): {str(result)[:200]}...")
# Content 추출
content = None
if "choices" in result and len(result["choices"]) > 0:
content = result["choices"][0].get("message", {}).get("content")
if not content:
gr.Warning("API 반환 결과에 content 필드가 없습니다")
return None
# 이전에 검증된 로직을 사용하여 Base64 추출
base64_str = extract_base64_from_response(content)
if base64_str:
output_image = base64_to_image(base64_str)
if output_image:
return output_image
# 이미지를 추출하지 못한 경우, 모델이 거부했거나 텍스트만 반환했을 수 있음
text_content = str(content) if not isinstance(content, list) else " ".join([str(x) for x in content])
gr.Info(f"이미지가 생성되지 않았습니다, 모델이 텍스트를 반환함: {text_content[:100]}...")
return None
except requests.exceptions.Timeout:
gr.Error("요청 시간이 초과되었습니다, 나중에 다시 시도해 주세요")
return None
except Exception as e:
import traceback
traceback.print_exc()
gr.Error(f"알 수 없는 오류가 발생했습니다: {str(e)}")
return None
# Gradio 인터페이스 구성
with gr.Blocks(title="Nanobanana Image Generator") as app:
gr.Markdown("# 🍌 Nanobanana Text/Image to Image")
gr.Markdown("Gemini-2.5-Flash-Image 모델 기반, 텍스트에서 이미지 및 이미지에서 이미지를 지원합니다.")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(
label="프롬프트 (Prompt)",
placeholder="예: A cyberpunk cat holding a neon sign...",
lines=3
)
image_input = gr.Image(
label="참고 이미지 (선택사항, 이미지에서 이미지 생성용)",
type="pil",
height=300
)
submit_btn = gr.Button("생성 시작", variant="primary")
with gr.Column():
image_output = gr.Image(label="생성 결과", format="png")
submit_btn.click(
fn=synthesize,
inputs=[prompt_input, image_input],
outputs=image_output
)
if __name__ == "__main__":
app.launch(share=True)Trae가 실행 성공을 알리면, 제공된 로컬 링크(보통 http://127.0.0.1:7860)를 클릭합니다.
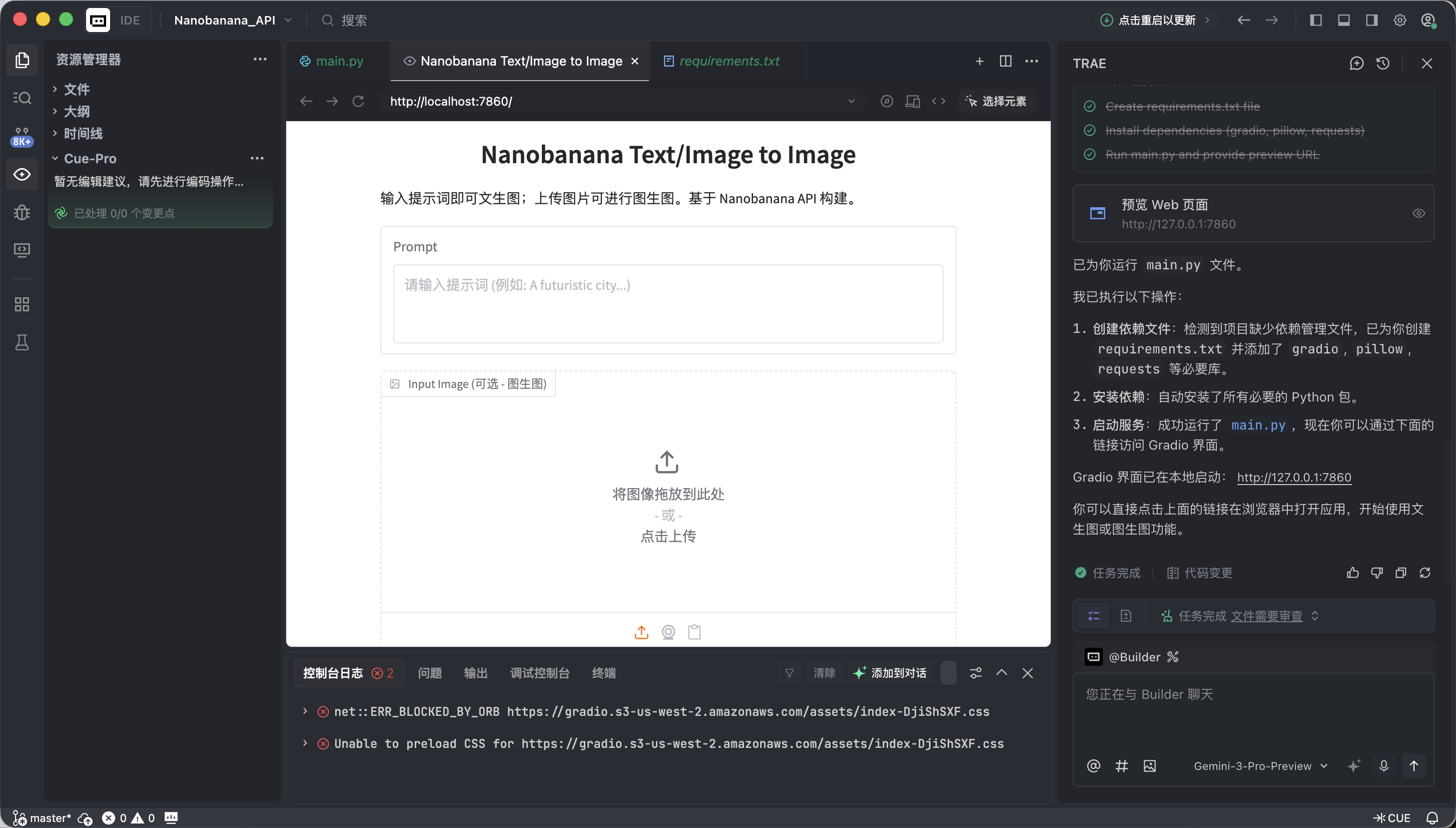
모든 것이 정상이라면, 이미 작동하는 AI 이미지 생성 인터페이스를 볼 수 있습니다.
이 인터페이스는 간단해 보이지만, 상업용 이미지 생성 도구에서 가장 핵심적인 두 가지 능력인 텍스트에서 이미지 생성과 이미지에서 이미지 생성을 이미 갖추고 있습니다.
- 왼쪽: 명령 영역 (Input Zone) — 여기서 지시를 내립니다.
- Prompt (프롬프트 입력란): 창의적인 설명을 입력합니다 (영어 사용 권장).
- Input Image (참고 이미지 입력란):
- 텍스트에서 이미지 모드: 여기를 비워두세요.
- 이미지에서 이미지 모드: 로컬 이미지를 여기로 드래그하면, AI가 이를 기반으로 창작합니다.
- Submit 버튼: 클릭하면 지시가 전송되고 생성이 시작됩니다.
- 오른쪽: 결과 표시 영역 (Output Zone) — 기적이 일어나는 곳, 생성 결과가 여기에 표시됩니다.
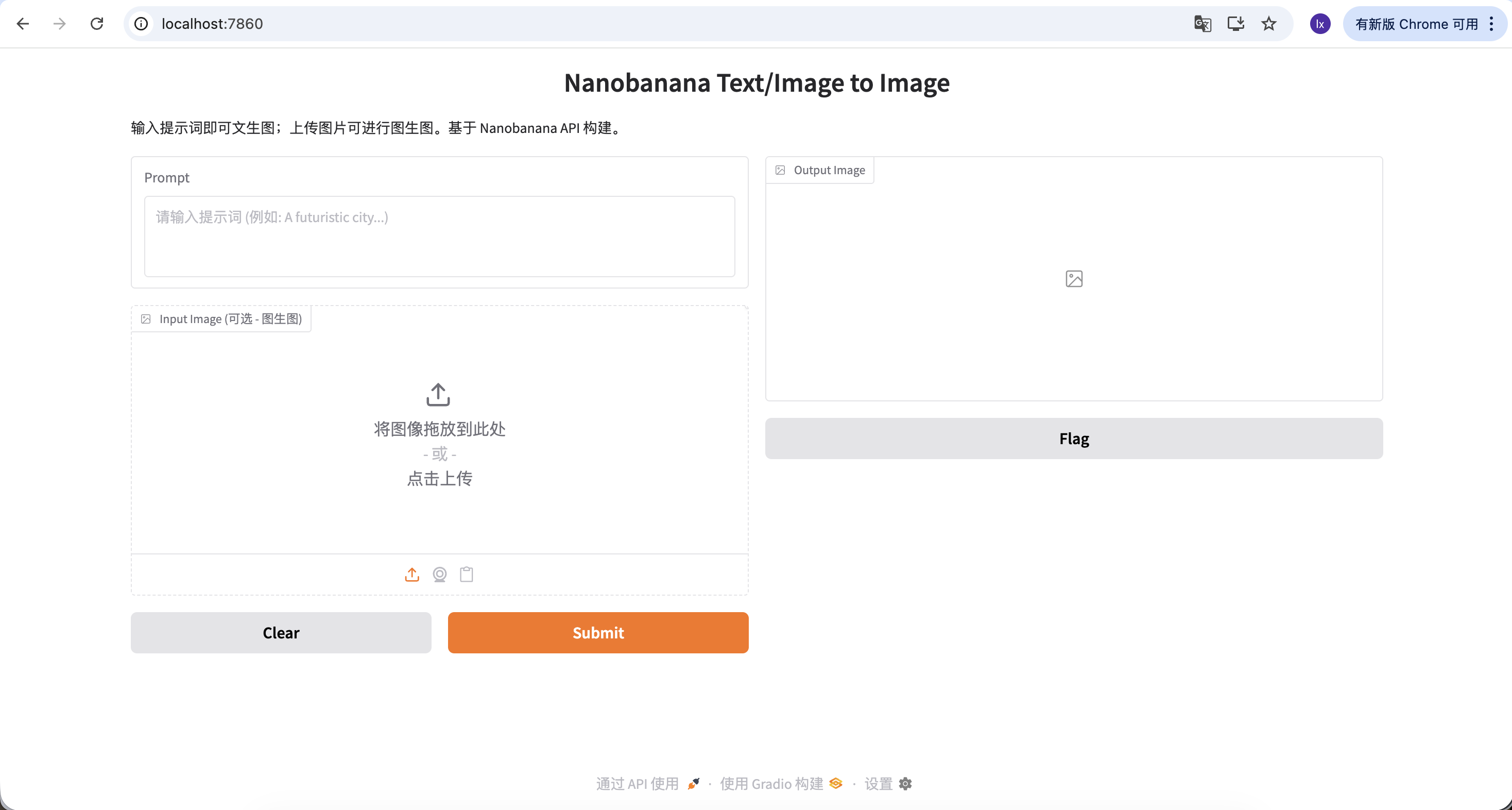
이제 첫 번째 이미지를 생성해 볼 수 있습니다!
이 예시에서 사용한 프롬프트는 다음과 같습니다:
A red apple
이는 의도적으로 단순화된 예시로, 스타일이나 파라미터 설명이 포함되어 있지 않습니다.
실제 프로세스
코드를 실행한 후, 프로세스는 세 단계로 요약할 수 있습니다:
- 텍스트 설명을 모델에 전송
- 모델이 해당 이미지를 생성
- 이미지가 로컬 파일로 저장
몇 초 후, 로컬에서 생성 결과를 볼 수 있습니다. 모델 생성에는 무작위성이 있으므로, 동일한 프롬프트라도 다른 결과가 생성됩니다. 여러 번 생성하여 마음에 드는 이미지를 선택할 수 있습니다.
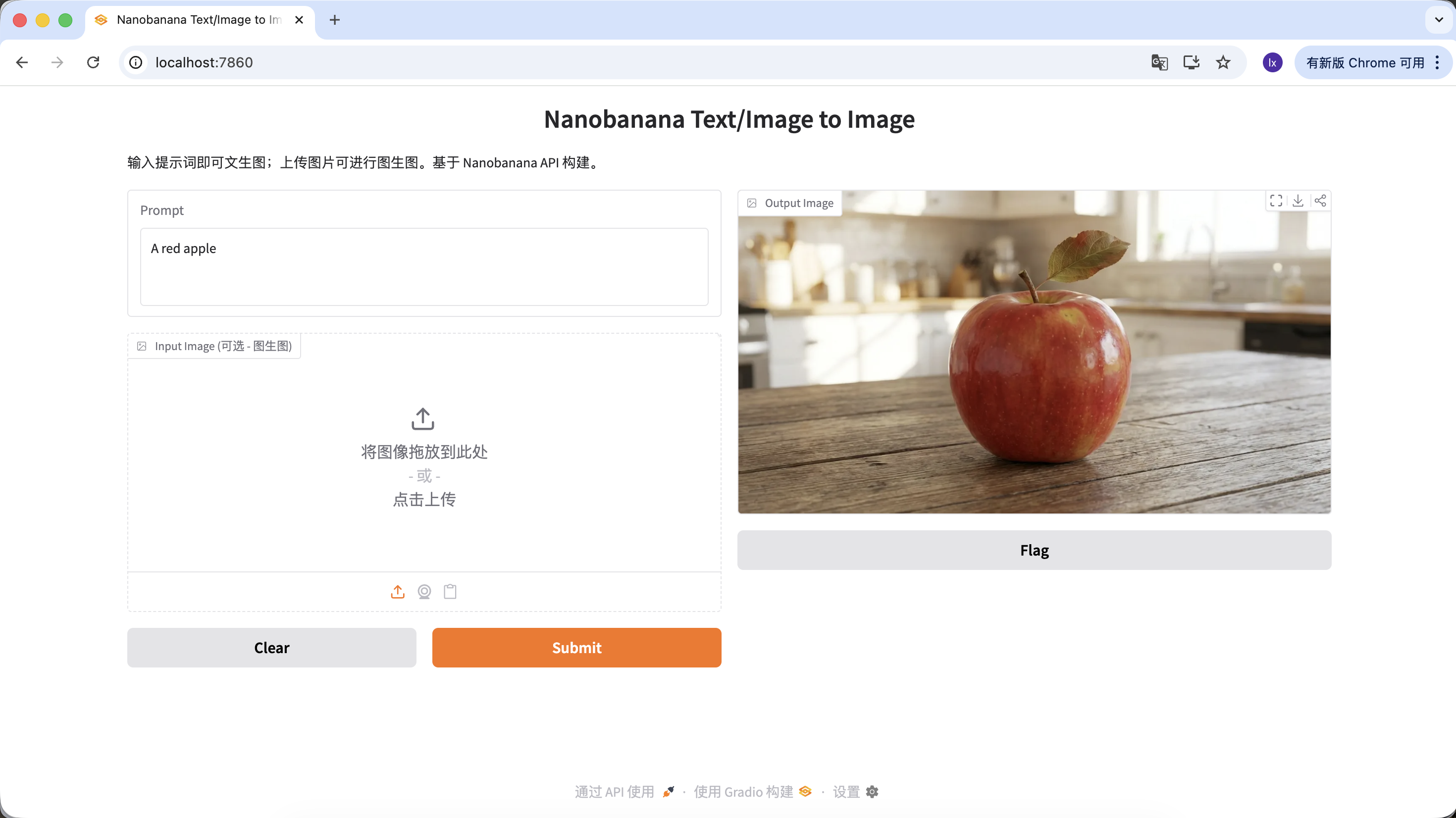
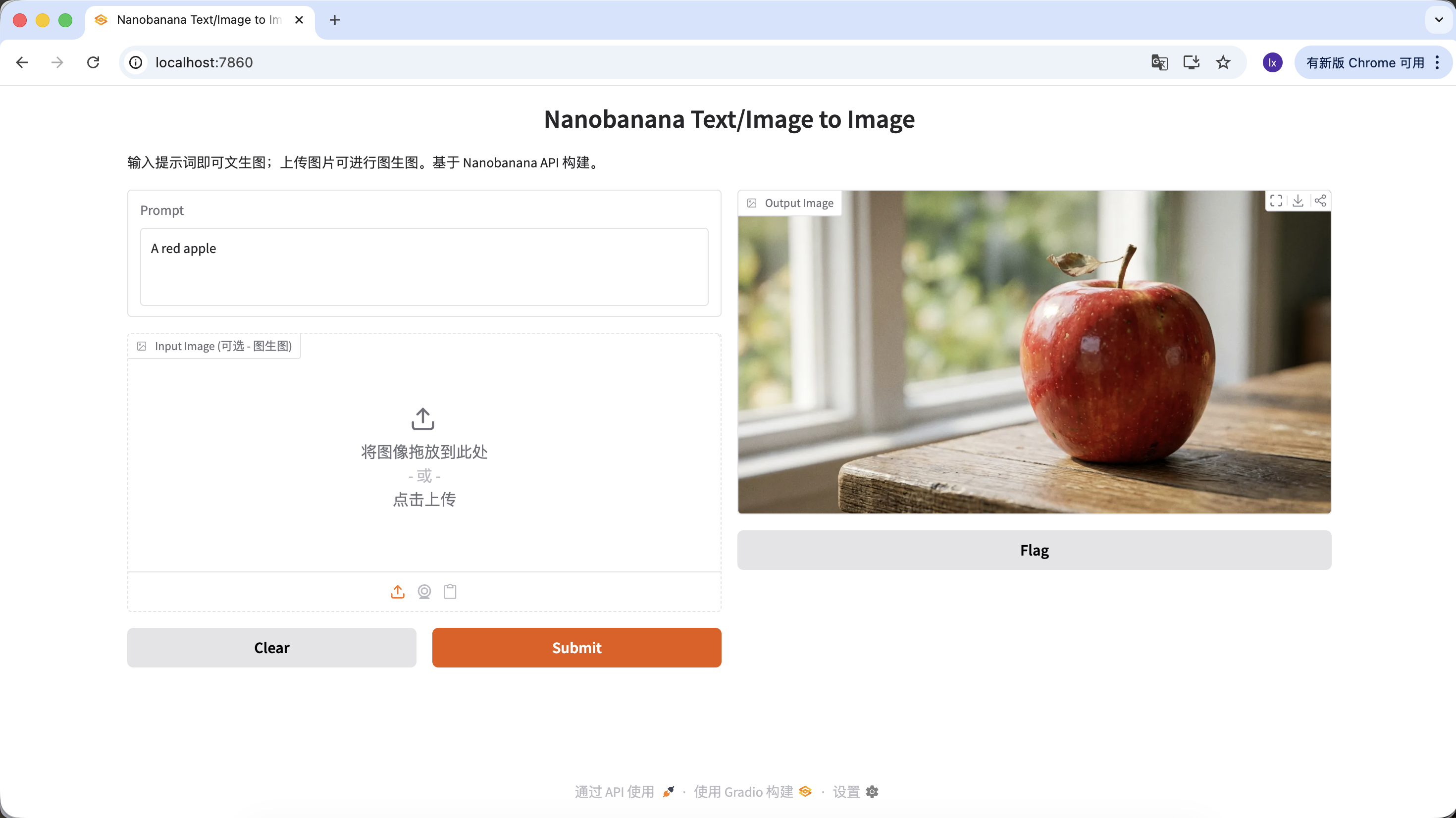
프롬프트를 풍부하게 하여 더 많은 설명과 제한을 추가할 수도 있습니다. 예를 들어 다음 프롬프트를 사용하면 더 특별한 이미지를 얻을 수 있습니다.
"A hyper-realistic close-up of a fresh red apple with water droplets on its skin, sitting on a dark rustic wooden table. Cinematic dramatic lighting, rim light, shallow depth of field, bokeh background, 8k resolution, macro photography."
(초현실적인 물방울이 있는 신선한 붉은 사과 클로즈업, 어두운 거친 나무 테이블 위에 놓여 있음. 영화 드라마틱 조명, 림 라이트, 얕은 피사계 심도, 보케 배경, 8k 해상도, 매크로 촬영.)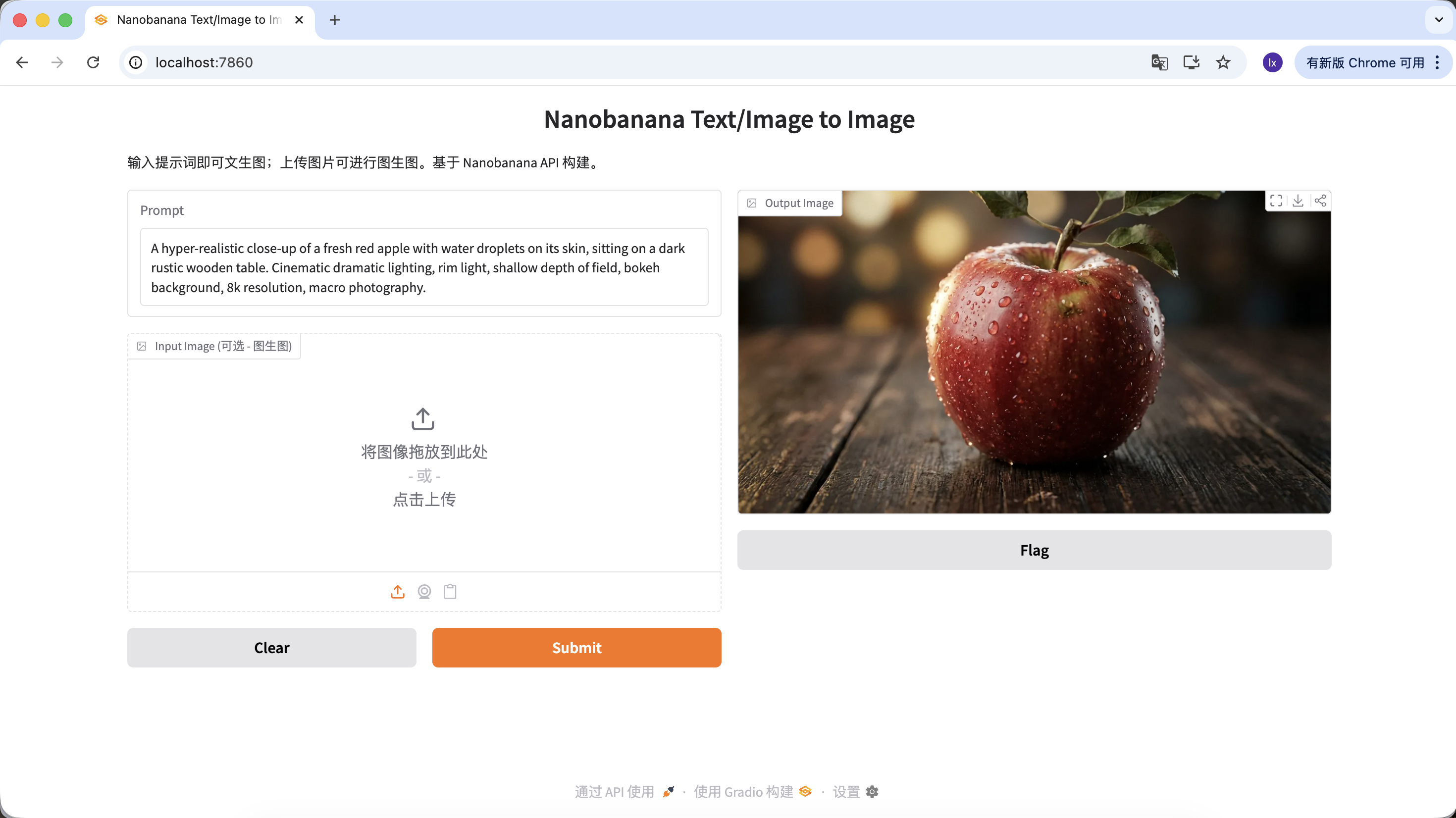
Output Image 영역에서 다운로드를 클릭하면 로컬에 저장할 수 있습니다.
1.3 이미지 생성 모델의 일반적인 에셋 생성 시나리오
실제 업무에서 대형 모델로 이미지를 생성하는 것은 단일 예술 작품을 창작하는 것보다 효율적인 디자인 에셋 생산 에 더 많이 사용됩니다.
디자인 관련 마케팅 계정의 인기 사례를 관찰해 보면, 그 산출물은 주로 두 가지 시나리오에 집중되어 있습니다:
- 텍스트에서 이미지 (0에서 1로)
- 참고 이미지로 이미지 생성 (1에서 N으로)
하나: 텍스트에서 이미지 — 빠른 디자인 자산 확보
이러한 유형의 시나리오는 효율성에 초점을 맞춥니다. 디자인의 빈 공간(예: 빈 상태, 아바타, 일러스트)을 채워야 할 때, AI는 본질적으로 즉시 생성되는 이미지 라이브러리 역할을 합니다.
UI 디자인 에셋 생성
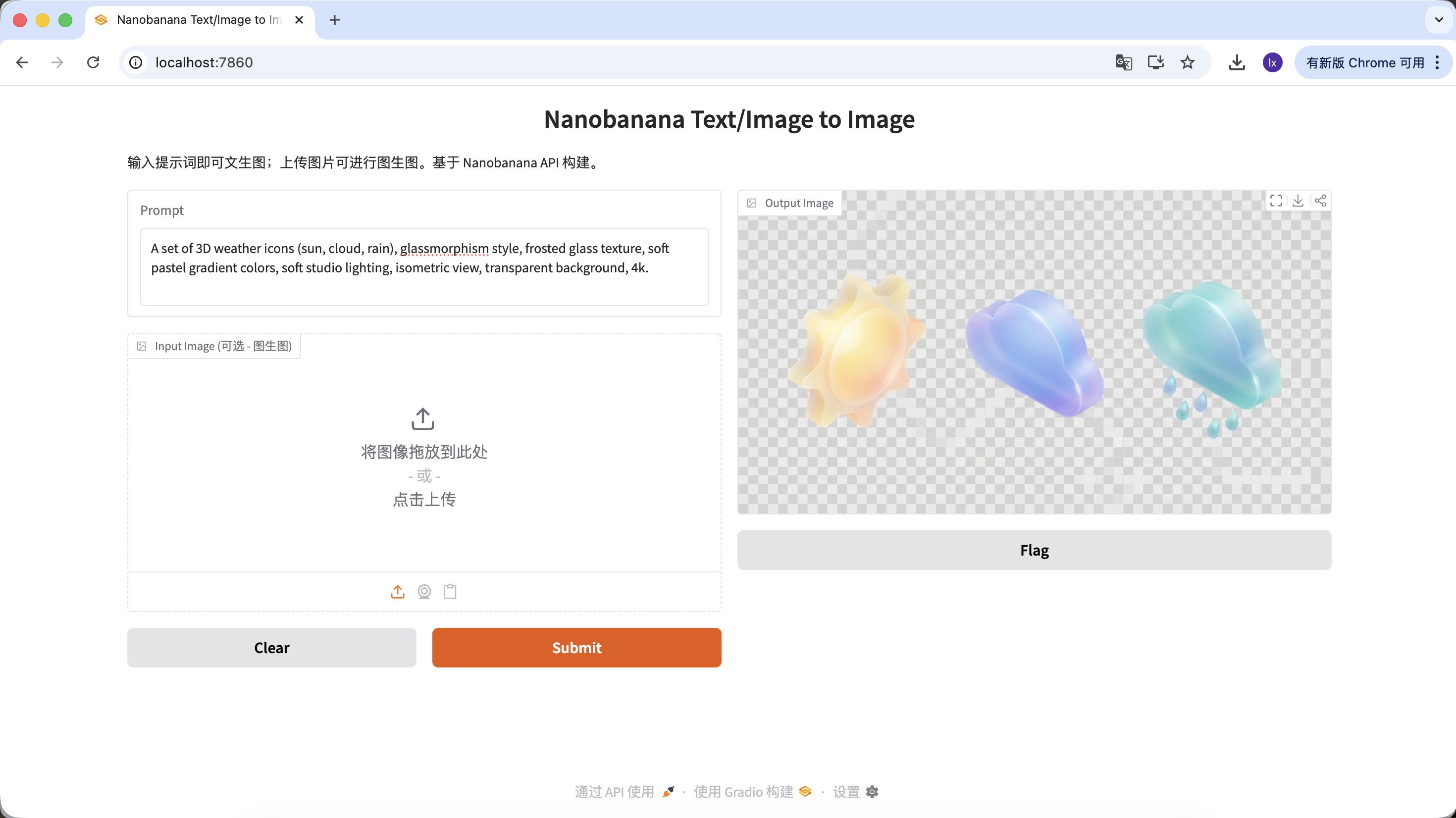
- 유행 트렌드: Dribbble에서 흔히 볼 수 있는 글래스모피즘, 클레이 스타일 3D 아이콘
- 일반적인 특징: 투명한 소재, 가장자리 발광, 캔디 색상의 기능 또는 날씨 아이콘
예시 프롬프트:
A set of 3D weather icons (sun, cloud, rain), glassmorphism style, frosted glass texture, soft pastel gradient colors, soft studio lighting, isometric view, transparent background, 4k.
(3D 날씨 아이콘 세트, 글래스모피즘 스타일, 서리 유리 질감, 부드러운 파스텔 그라데이션 색상, 스튜디오 조명, 등축 투시)
로고 생성
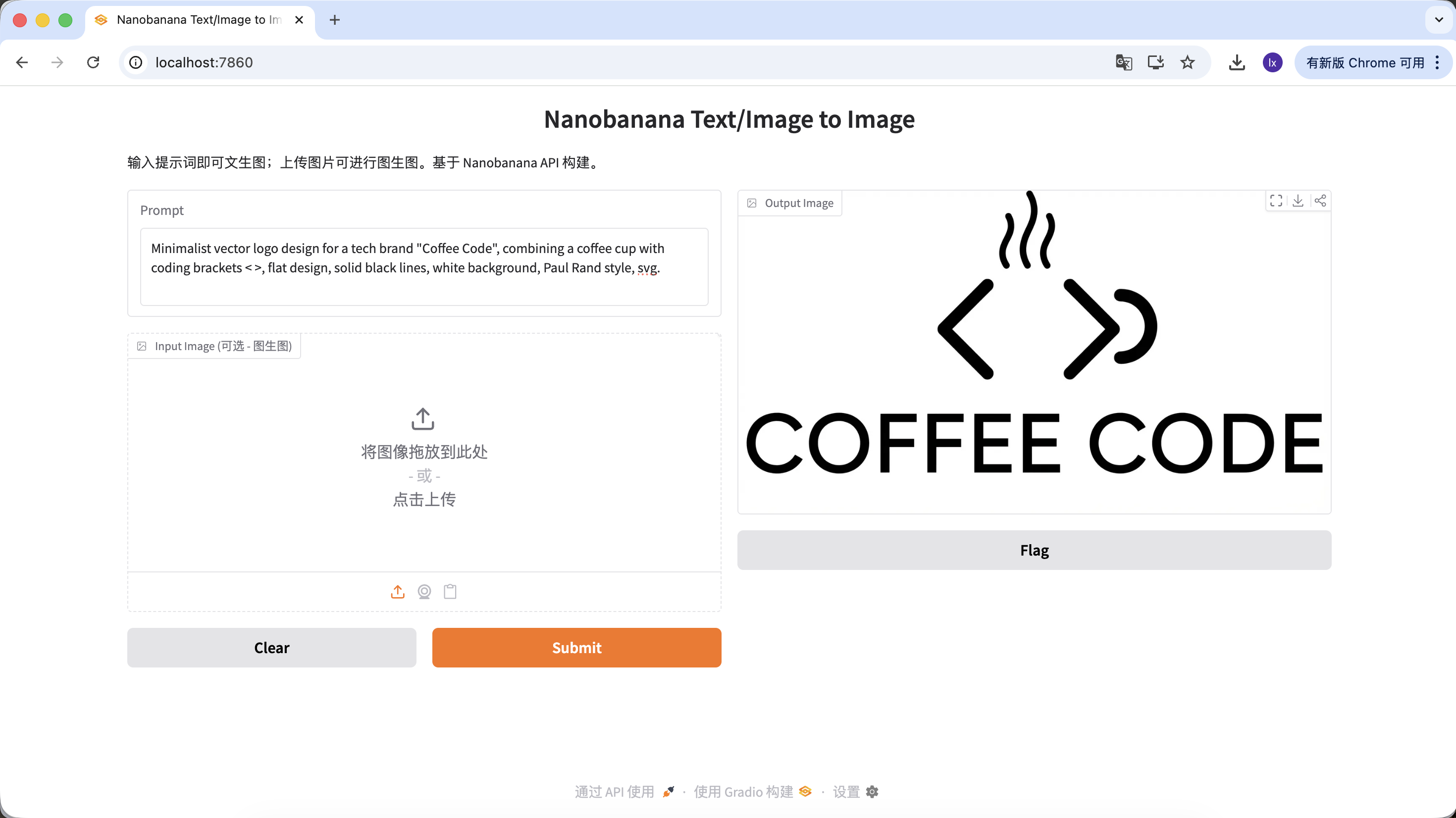
- 유행 트렌드: 미니멀 라인, 기하학적 조합의 테크놀로지 로고
- 일반적인 특징: 흑백 색상, 네거티브 스페이스 디자인, 명확한 브랜드 느낌
예시 프롬프트:
Minimalist vector logo design for a tech brand "Coffee Code", combining a coffee cup with coding brackets < >, flat design, solid black lines, white background, Paul Rand style, svg.
(미니멀 벡터 로고, 커피잔과 코드 기호 결합, 플랫 디자인, 순흑 라인)
공식 웹사이트 사용자 이미지 생성
- 유행 트렌드: SaaS 공식 웹사이트에서 자주 사용하는 3D 가상 아바타, 실제 인물 초상권 문제 회피
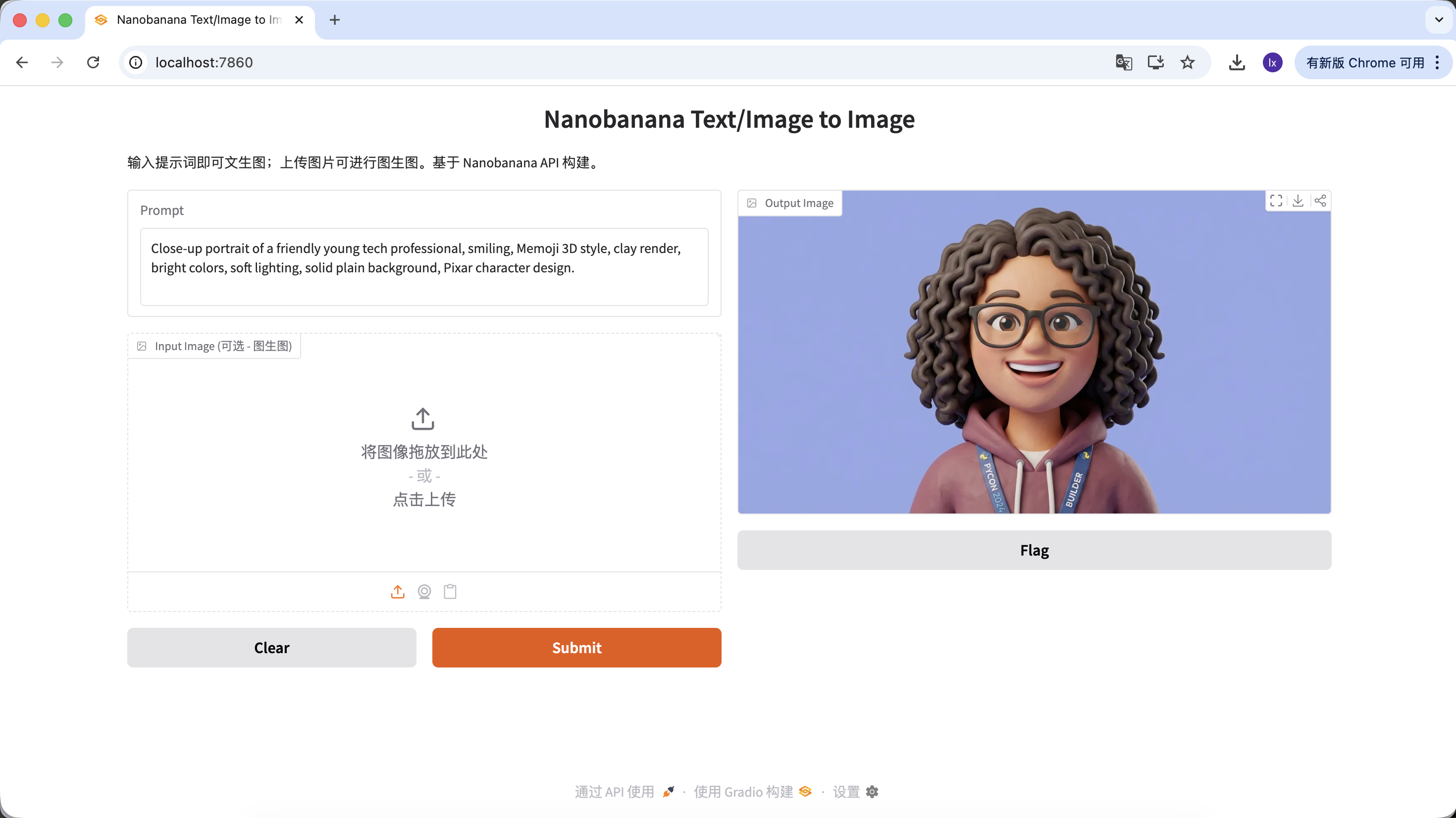
- 일반적인 특징: 친근한 표정, 카툰 비율, Pixar 또는 Memoji 스타일
예시 프롬프트:
Close-up portrait of a friendly young tech professional, smiling, Memoji 3D style, clay render, bright colors, soft lighting, solid plain background, Pixar character design.
(친근한 젊은 기술 전문가, 3D Memoji 스타일, 클레이 렌더)
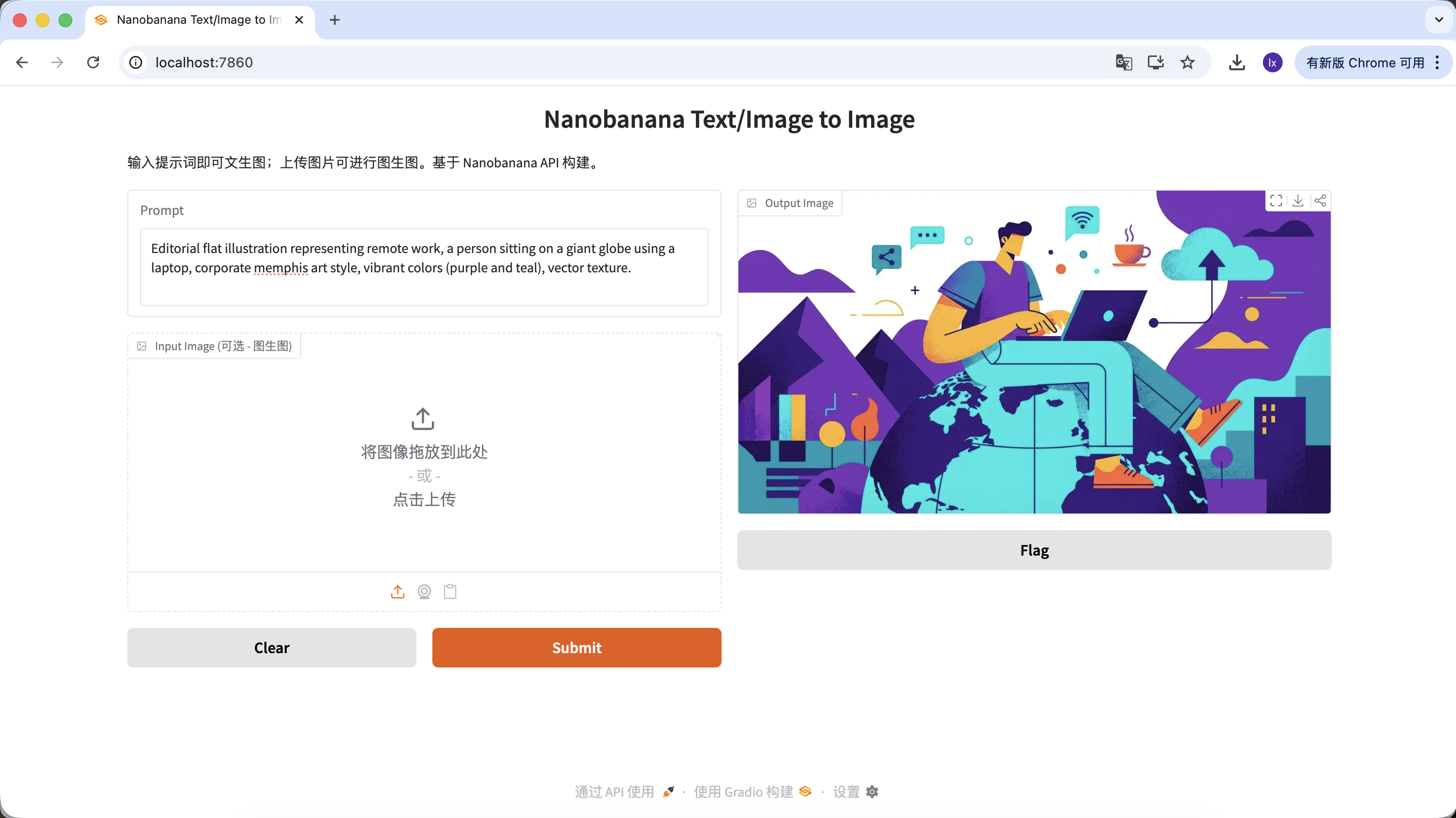
기사 일러스트 생성
- 유행 트렌드: 기술 기업 블로그에서 흔히 볼 수 있는 추상 플랫 일러스트
- 일반적인 특징: 보라-파랑 색상, 과장된 인물 비율, 떠다니는 UI 요소
예시 프롬프트:
Editorial flat illustration representing remote work, a person sitting on a giant globe using a laptop, corporate memphis art style, vibrant colors (purple and teal), vector texture.
(원격 근무 주제 플랫 일러스트, 기업 멤피스 스타일)
둘: 참고 이미지로 이미지 생성 — 시각적 일관성 유지
이러한 유형의 시나리오는 확장성 에 더 초점을 맞춥니다. 만족스러운 메인 비주얼이 있고, 스타일이 일관된 에셋 세트를 생성해야 할 때 사용합니다.
메인 비주얼과 유사한 버튼 또는 인터랙티브 에셋 이미지 세트
게임 개발에서 UI의 일관성은 매우 중요합니다. 메인 화면의 "PLAY" 버튼이 이미 있다고 가정해 보겠습니다. 이제 스타일이 통일된 기능 버튼 세트(예: 일시 정지, 설정, 홈)를 확장해야 합니다. 수작업만으로는 각 버튼의 광택, 투시, 색상 값을 완전히 일치시키기 어렵습니다.
기본 작업 흐름:
- 기존의 파란색 "PLAY" 버튼 이미지 저장

- 이를 인터페이스의 Input Image 영역으로 드래그하여 후속 생성의 참고 마스터로 사용
- 프롬프트의 스타일 설명은 그대로 유지하고, 주요 내용만 수정
이 흐름에서 주요 설명만 교체하면 다른 기능이지만 스타일이 일관된 버튼을 얻을 수 있습니다.
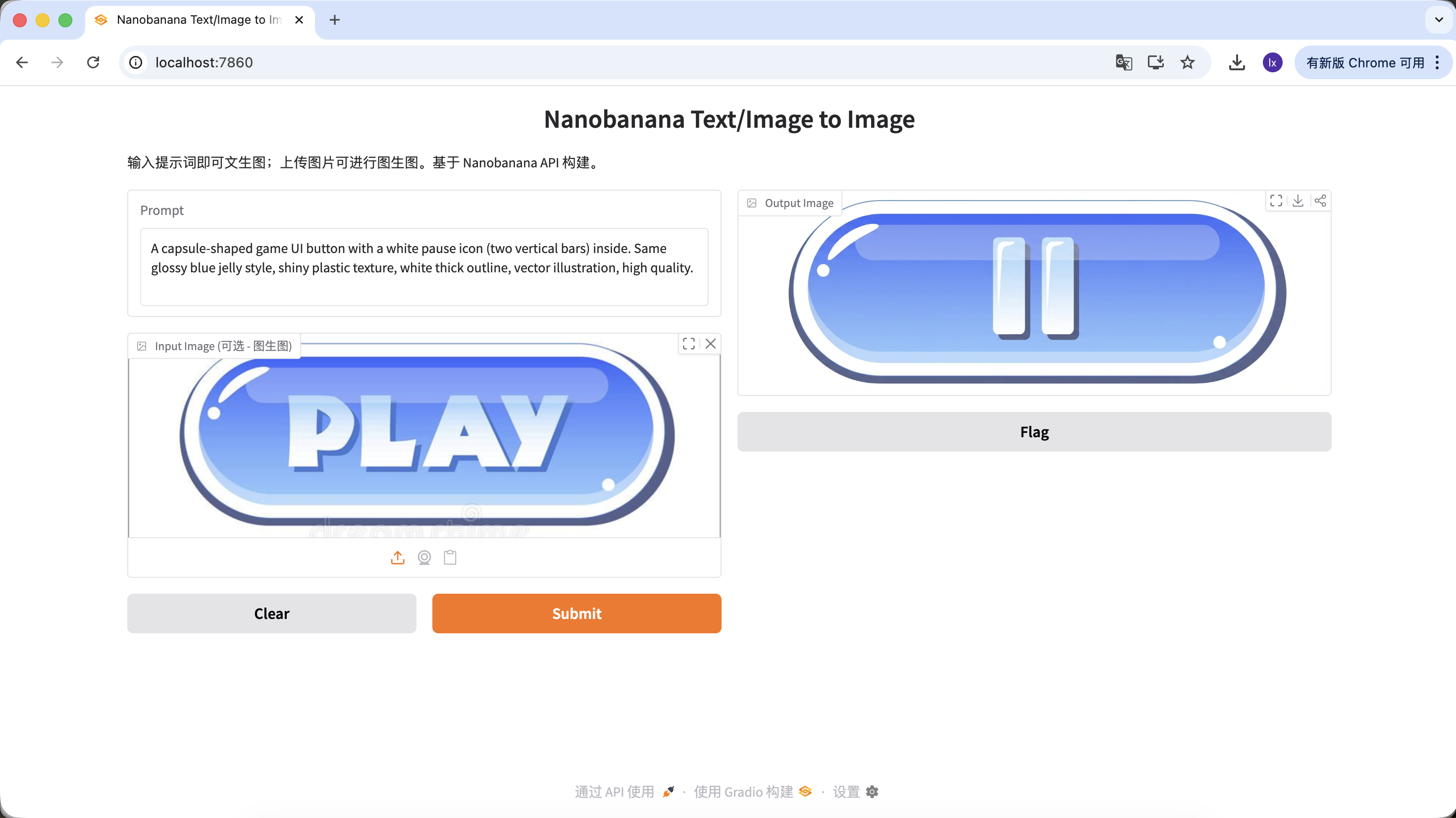
예시 프롬프트:
변형 A: 일시 정지 버튼 (아이콘 유형)
A capsule-shaped game UI button with a white pause icon (two vertical bars) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(캡슐형 게임 UI 버튼, 흰색 일시 정지 아이콘, 파란색 젤리 질감)
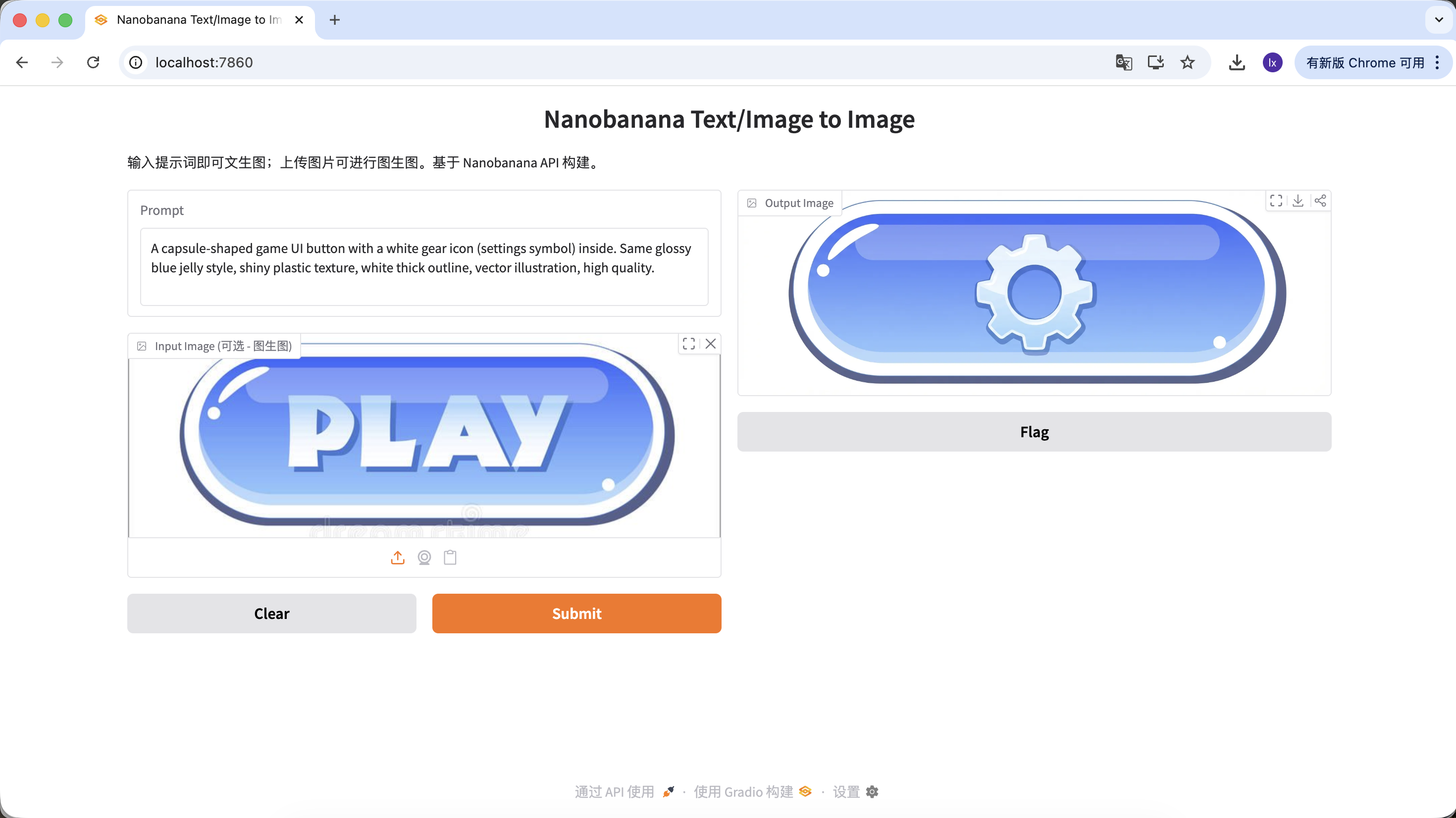
변형 B: 설정 버튼 (복잡한 아이콘)
A capsule-shaped game UI button with a white gear icon (settings symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(캡슐형 게임 UI 버튼, 흰색 톱니바퀴 아이콘, 파란색 젤리 질감)
변형 C: 다시하기 버튼 (모양 변화)
버튼의 외형을 조정해야 한다면, 프롬프트에서 모양을 직접 설명하면 됩니다. 모델은 소재 특징을 유지하면서 구조를 변경하려고 시도합니다.
A round game UI button with a white circular arrow icon (replay symbol) inside. Same glossy blue jelly style, shiny plastic texture, white thick outline, vector illustration, high quality.
(원형 게임 UI 버튼, 순환 화살표 아이콘, 파란색 젤리 질감)

이 작업을 통해 버튼 기능과 아이콘을 교체할 수 있을 뿐만 아니라, 버튼 모양까지 변경할 수 있습니다. 그러나 모든 생성 결과는 소재, 색상, 조명 측면에서 여전히 높은 일관성을 유지합니다. 이것이 바로 대형 모델이 디자인 에셋 파생 시나리오에서 가지는 핵심 가치입니다.
제2장: 더 잘 따르는 이미지 생성 어시스턴트 — Lovart를 예시로
첫 번째 부분에서 우리는 코드를 통해 NanoBanana를 직접 호출하고, "입력 즉시 생성"이라는 기본 흐름을 경험했습니다. 이 방식은 요구 사항이 간단할 때는 문제가 없습니다. 하지만 생성 작업에 더 많은 제약이 포함되기 시작하면, 예를 들어:
- 여러 장의 스타일이 일관된 이미지가 필요한 경우
- 기존 결과를 바탕으로 반복적으로 조정해야 하는 경우
- 사용자 입력에 따라 생성 방향을 동적으로 수정해야 하는 경우
단일 호출 방식으로는 점점 부족해집니다.
이때 AI Agent(지능형 에이전트) 를 도입해야 합니다. 이 섹션에서는 Lovart 를 예시로, 이미지 생성 모델에 "사고 계층"이 추가되면 전체 작업 흐름이 어떻게 변화하는지 보여줍니다. 참고! 이것은 광고가 아니라, AI Agent의 편리함을 빠르게 이해할 수 있도록 돕기 위한 것입니다~
2.0 Lovart 처음 만나기: 당신의 AI 디자인 에이전트
Lovart는 Agent 기반의 디자인 도구 웹 서비스입니다. 일반 이미지 생성 도구와 비교하여, 생성 전에 "사고와 계획"이라는 계층이 하나 더 있습니다.
Lovart에 들어간 후, 주로 다음 제어 항목을 이해해야 합니다:
모델 선택
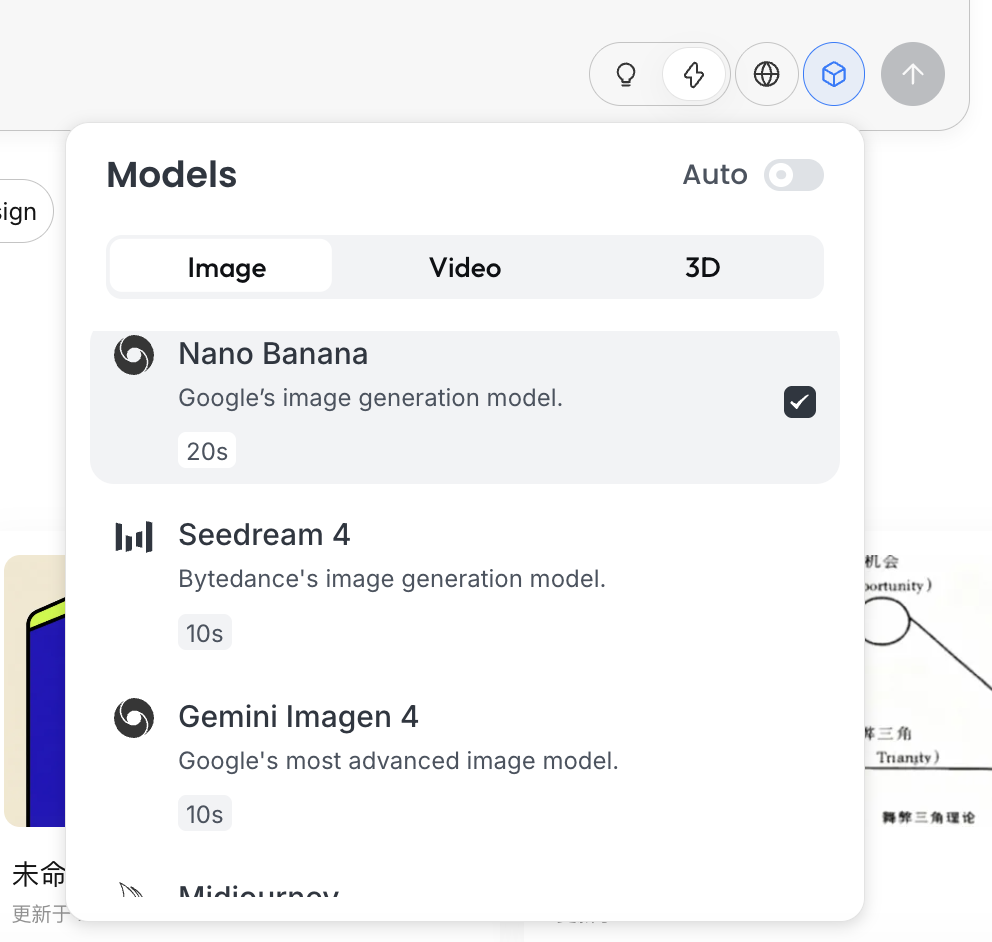
입력 상자 아래의 큐브 아이콘을 클릭하면, 현재 사용 가능한 생성 모델(예: GPT Image, Flux 등)을 볼 수 있습니다.
앞선 예시와 일관성을 유지하기 위해, 이 섹션에서는 여전히 NanoBanana를 기본 생성 모델로 사용합니다.
사고 모드
이것은 Lovart의 핵심 스위치입니다:
- Fast Mode (⚡): 원시 API에 가까움, 빠른 응답, 단일 이미지 및 명확한 지시 생성에 적합
- Thinking Mode (💡): Agent 모드, AI가 먼저 요구 사항을 분해하고 프롬프트를 재작성한 후 생성을 실행
인터넷 연결 기능
지구본 아이콘을 켜면, Agent가 생성 과정에서 웹 정보(예: 디자인 트렌드, 색상 스타일)를 검색하여 보조 입력으로 사용할 수 있습니다.
2.1 왜 원시 API만으로는 부족한가?
Python으로 품질이 괜찮은 이미지를 생성할 수 있음에도 불구하고, 원시 API는 복잡한 작업에서 여전히 제한이 있습니다. 핵심적인 이유는: 원시 API는 본질적으로 지시형(imperative)입니다. 구체적인 객체를 생성하라고 요청하면 직접 실행할 수 있지만, 입력이 "완전한 게임 에셋 세트를 기획하기"가 되면, 목표를 여러 실행 가능한 단계로 자발적으로 분해하지 않습니다.
Lovart의 핵심적인 차이는 Agent 메커니즘에 있습니다. 사용자 입력과 이미지 생성 모델 사이에 이해와 계획을 위한 논리 계층을 추가합니다: 먼저 사용자 의도를 식별하고, 작업을 분해하며, 프롬프트를 재작성한 후 마지막에 생성을 실행합니다.
2.2 실전 데모: 5분 만에 IP 이모티콘 세트 만들기
"프로그래머 오리 IP 이모티콘 세트 만들기" 를 예시로, Agent가 전체 프로세스에 어떻게 참여하는지 살펴보겠습니다.
단계 1: 기획 (Agent의 사고 능력)
원시 API의 문제: 캐릭터 설정, 감정 상태를 직접 생각해야 하며, 각 이미지마다 개별적으로 프롬프트를 작성해야 합니다.
Lovart의 방식:
- 💡 Thinking Mode 활성화
- 하나의 지시 입력:
프로그래머 오리의 IP 이모티콘 세트를 디자인해 줘, 스타일은 플랫하고 귀여운 것으로
AI는 즉시 그림을 그리지 않고, 먼저 인터넷에서 관련 프로그래머 오리 디자인 이미지를 검색합니다. 분해된 방안을 출력하고, Debug, Coffee Break, Panic 등의 시나리오를 자동으로 생성하며, 각각에 대응하는 여러 시각적 설명을 생성합니다.
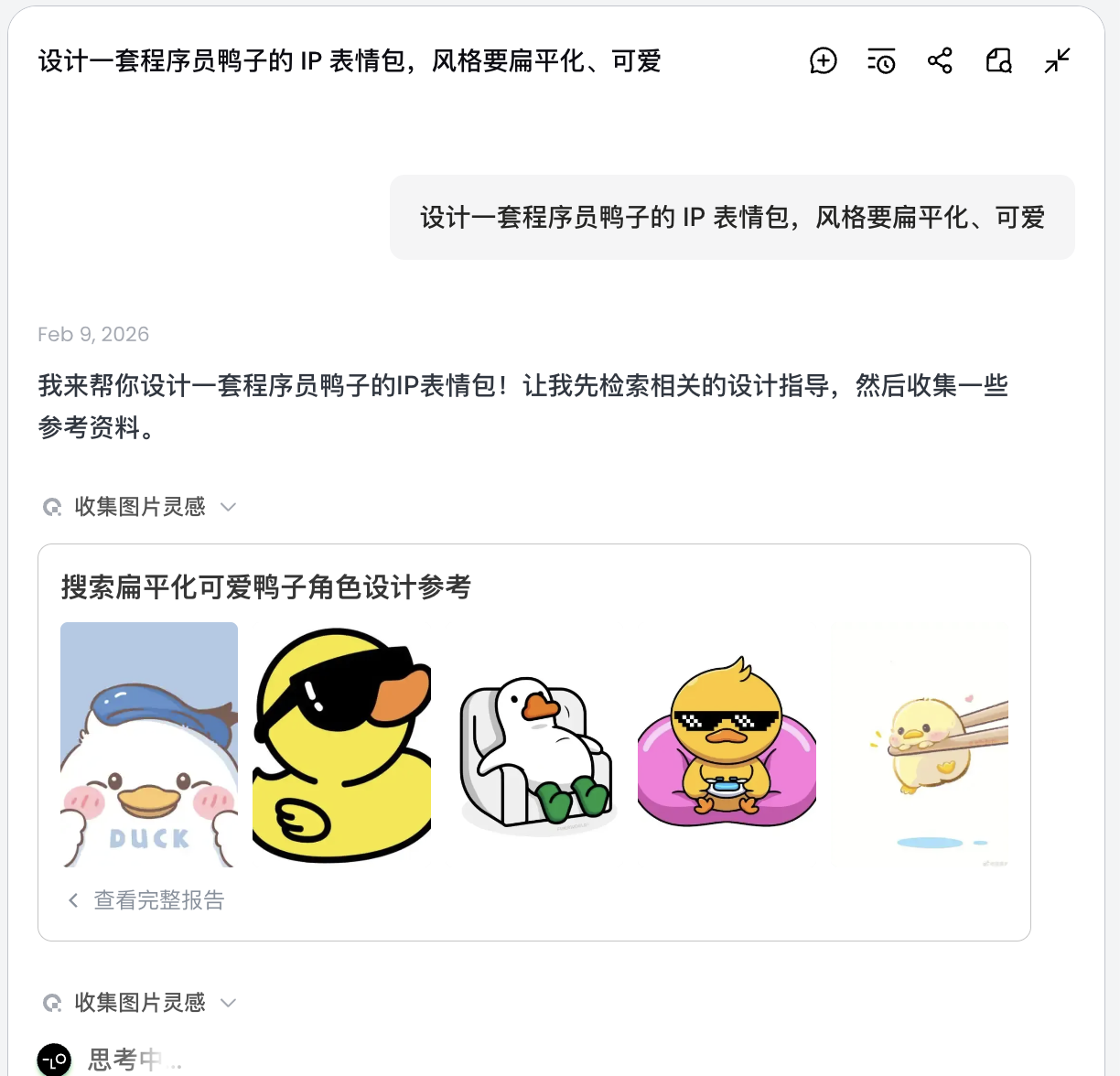

이 단계에서 AI는 "실행자"에서 "기획자"로 전환됩니다. AI가 요구 사항을 분석한 후, Lovart의 캔버스 영역에서 다양한 스타일과 내용의 프로그래머 오리 이미지를 볼 수 있습니다. 마음에 드는 스타일을 선택하기 시작할 수 있습니다.
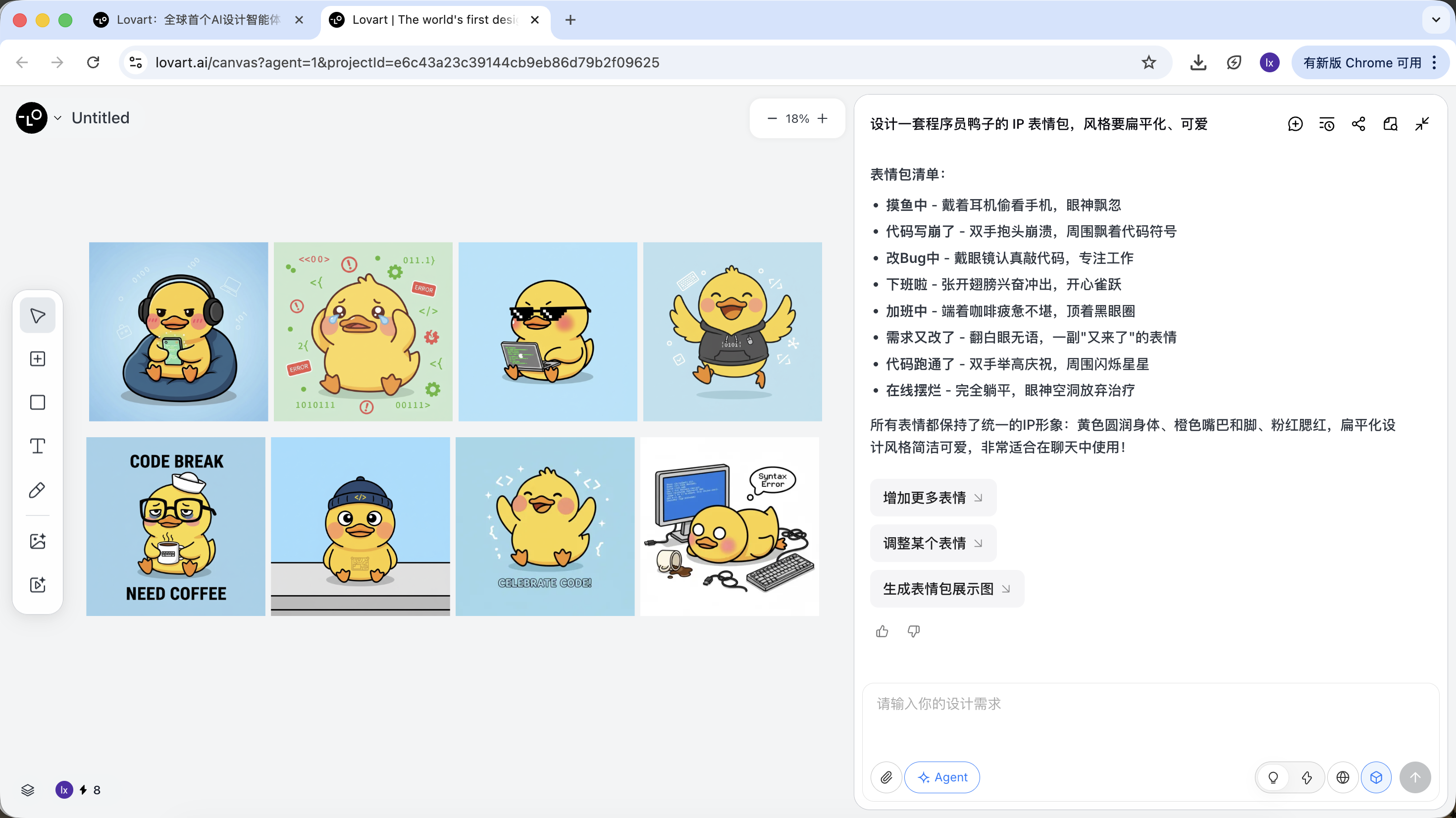
단계 2: 일관성 (참고 기반 시각적 앵커링)
Lovart에서 이미지는 결과일 뿐만 아니라 후속 생성에도 참여합니다.
완전한 참고 이미지
- 스케치에서 가장 만족스러운 "표준 오리"를 하나 선택하고, 캔버스 영역에서 해당 이미지를 클릭
- 해당 이미지가 자동으로 대화 영역에 나타나 Reference로 사용됨
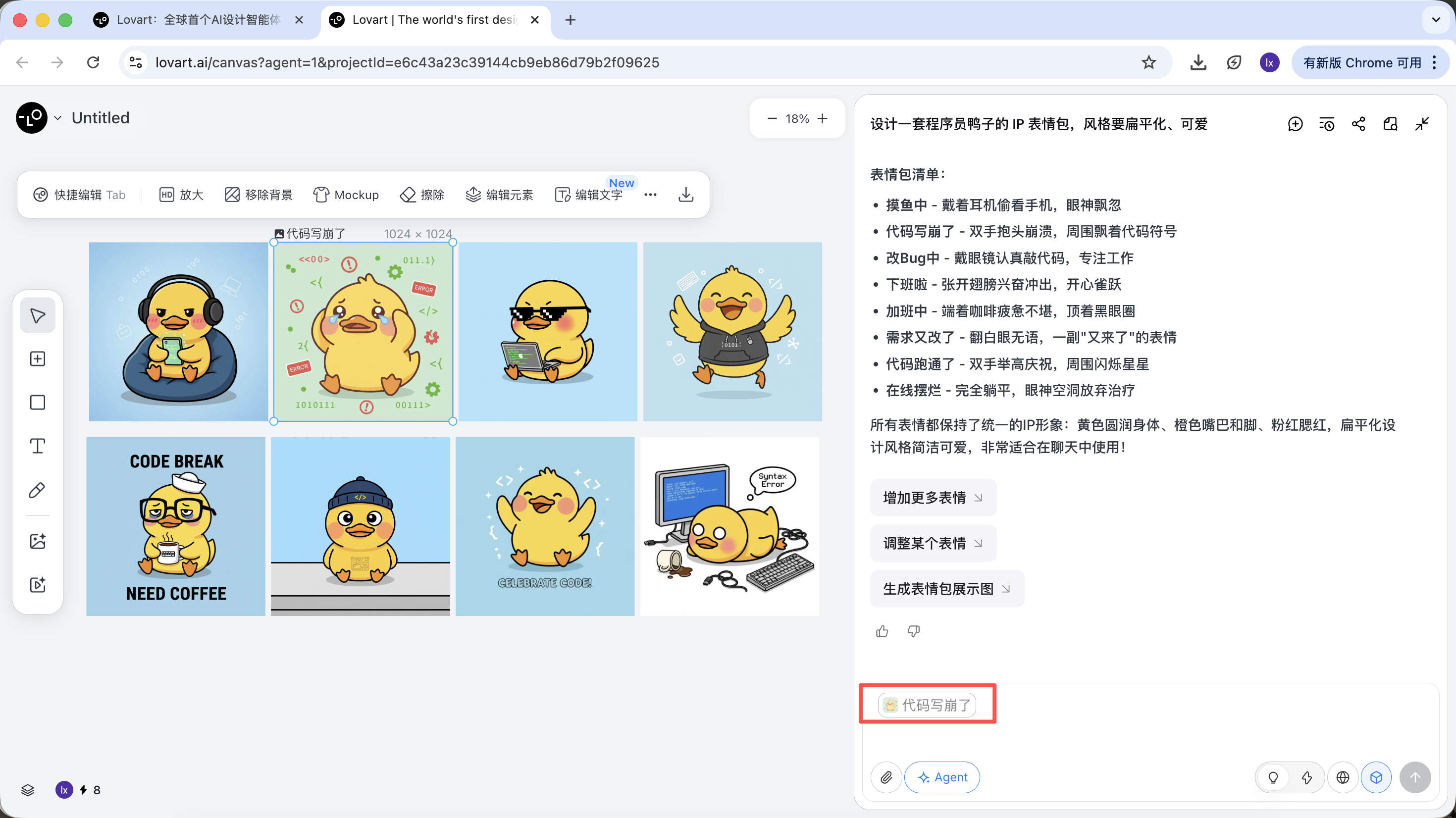
- 새로운 동작(예: 행복)을 입력하고 생성
생성 결과는 마스터 이미지의 색상, 비율, 디테일을 물려받습니다.
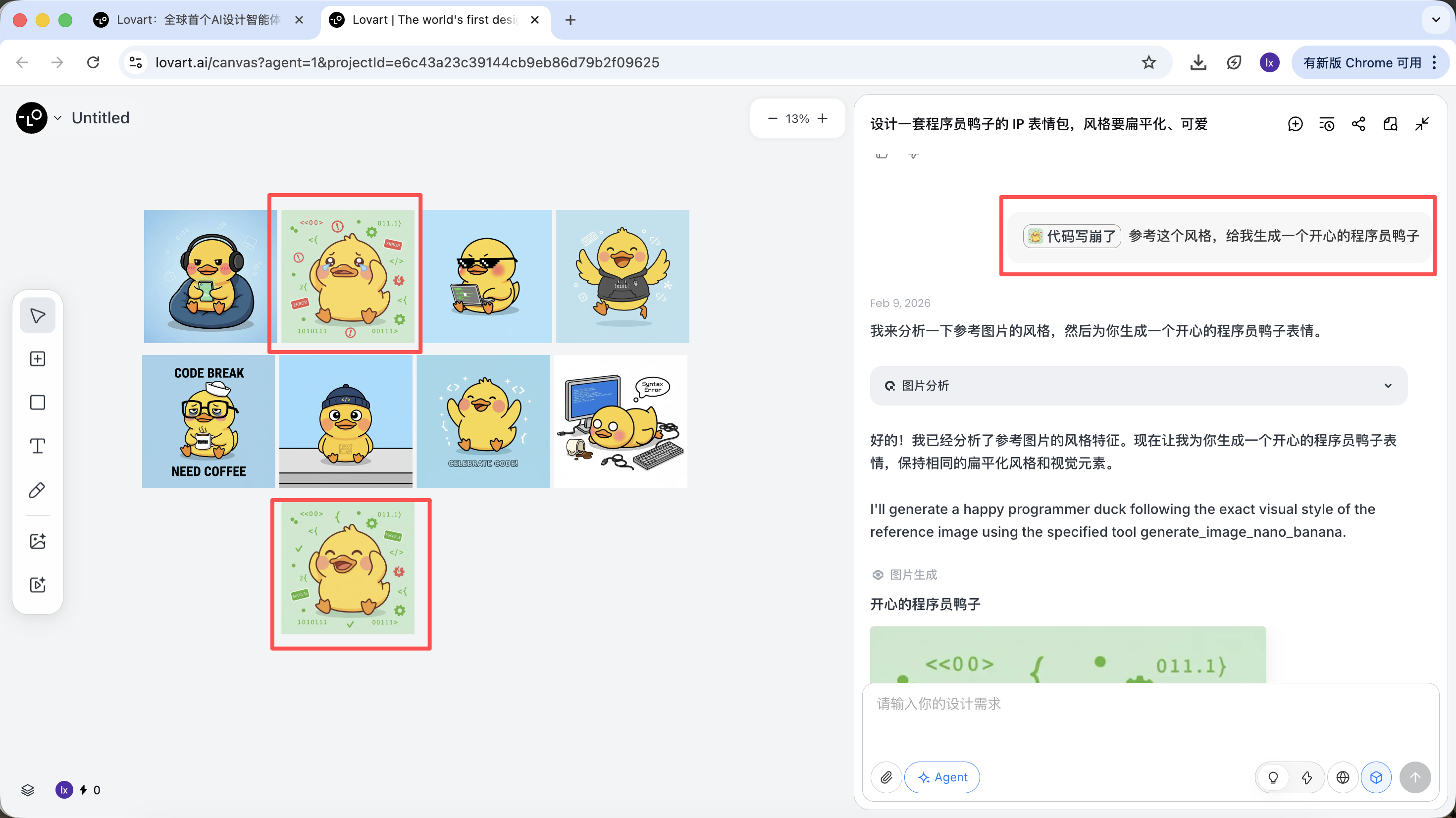
부분 참고 / 다중 이미지 통합
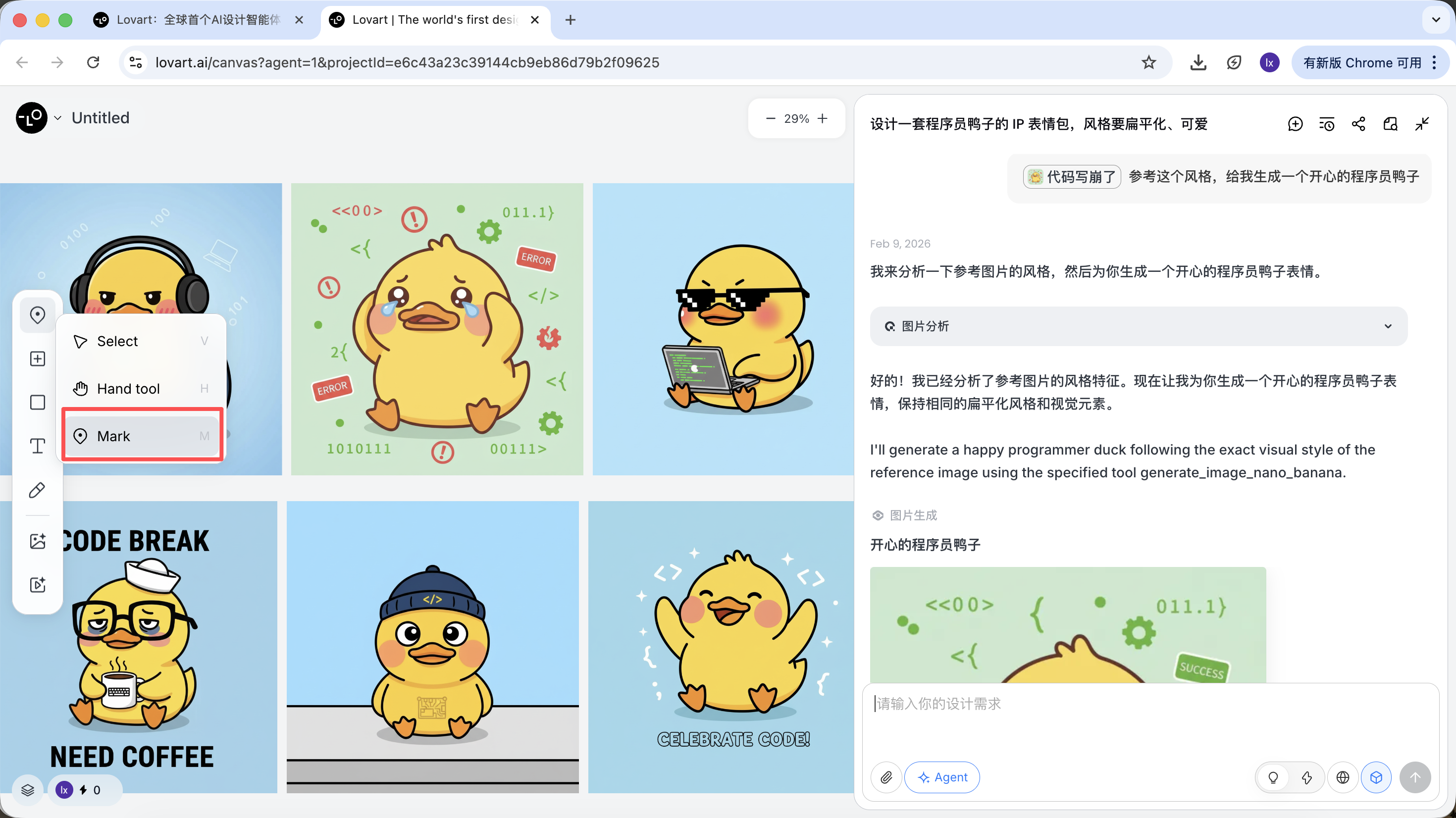
전체 이미지를 참고로 사용하는 것 외에도, Lovart는 다음을 지원합니다:
- 이미지의 특정 영역만 선택 (예: 모자나 표정만 참고)
캔버스 영역 왼쪽 탭 바를 클릭하고, "Mark" 키를 선택한 후 대상 이미지의 특정 영역을 마크하면 됩니다. 이 부분의 내용은 자동으로 대화 상자에 동기화됩니다. 예를 들어 여기서 배경 색상 수정을 선택할 수 있습니다.
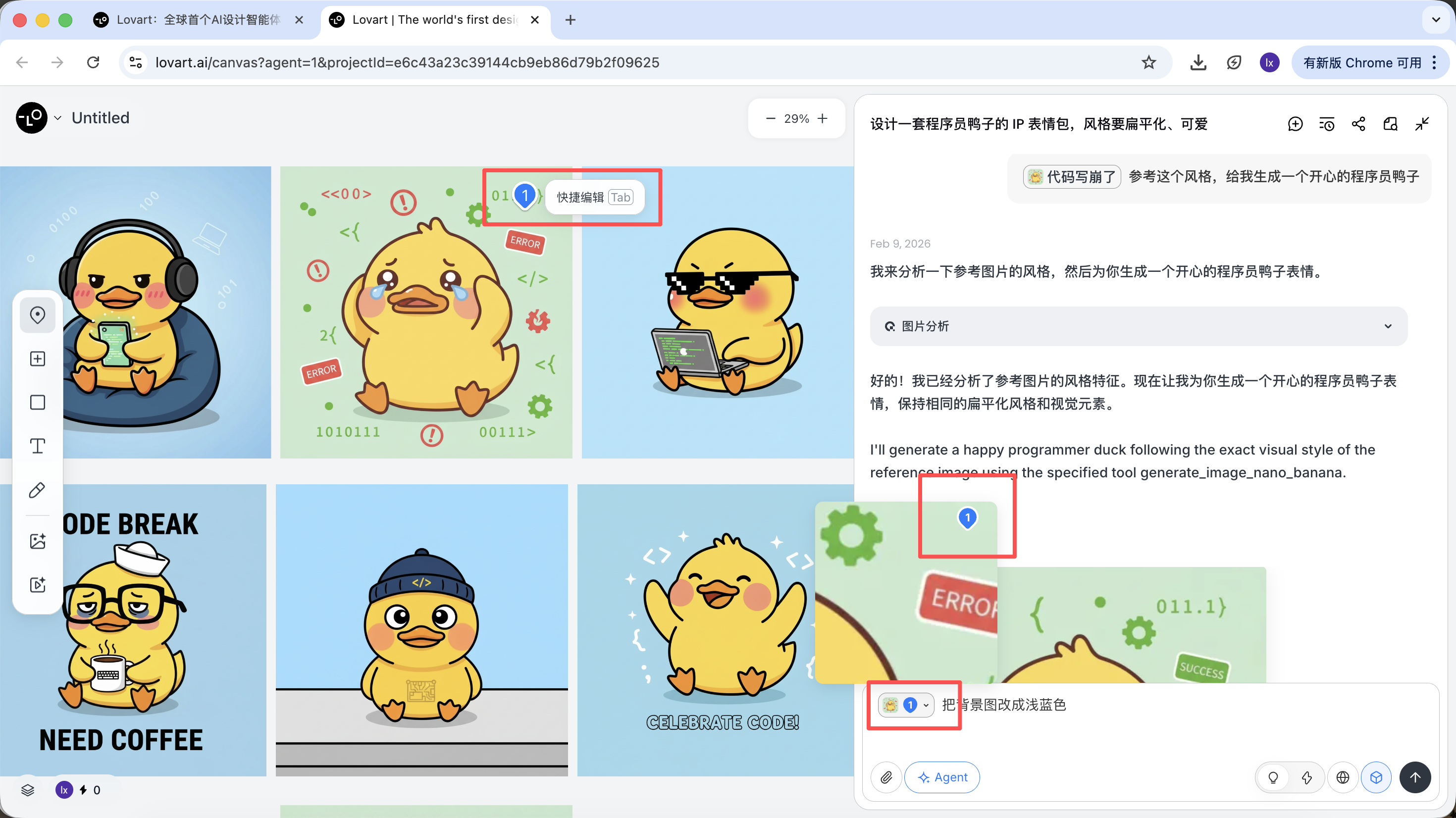
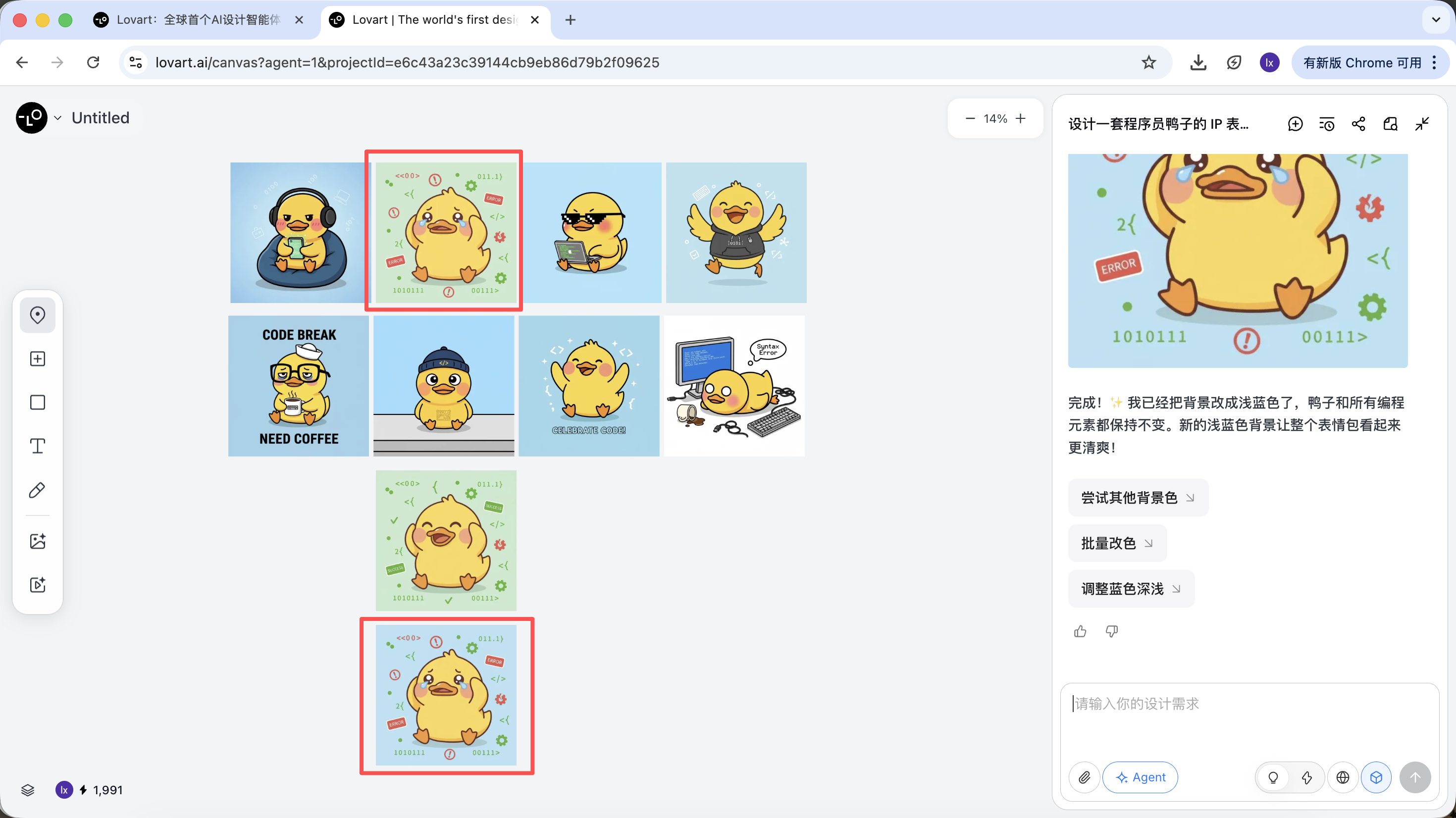
새로 생성된 이미지가 배경 색상만 변경된 것을 볼 수 있으며, 이는 우리가 입력한 요구 사항과도 일치합니다.
- 여러 이미지에서 각각 하위 요소를 인용 한 다음 결합하여 새로운 결과 생성
예를 들어: A 이미지의 캐릭터 주체를 유지하면서, 모자만 B 이미지의 스타일로 교체할 수 있습니다. Agent가 배경에서 이러한 시각적 제약을 자동으로 통합합니다.
프로그래머 오리를 예로 들면, 첫 번째 이미지의 오리 형상을 유지하고 이를 두 번째 이미지의 주요 요소로 교체하도록 선택할 수 있습니다.
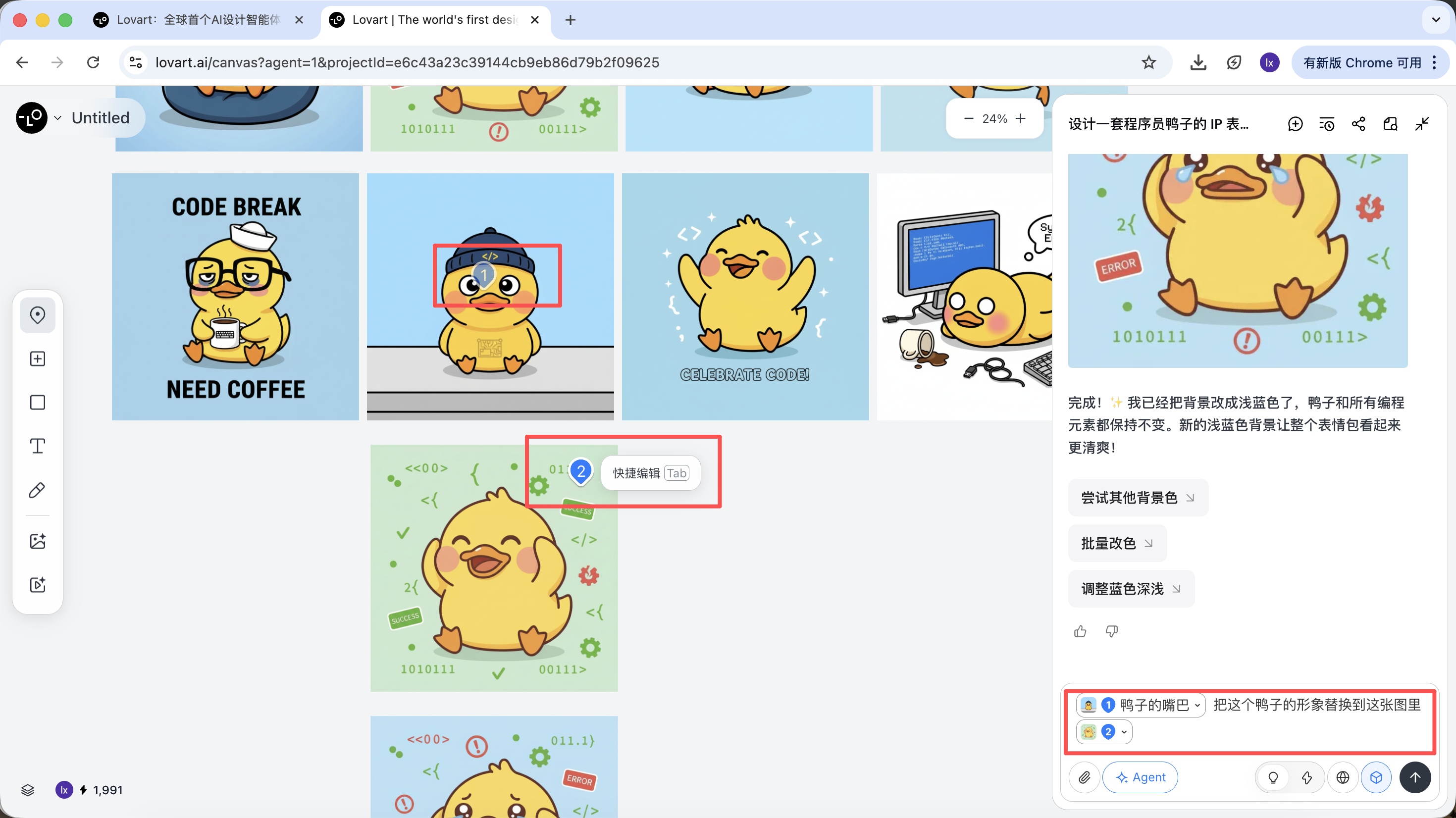
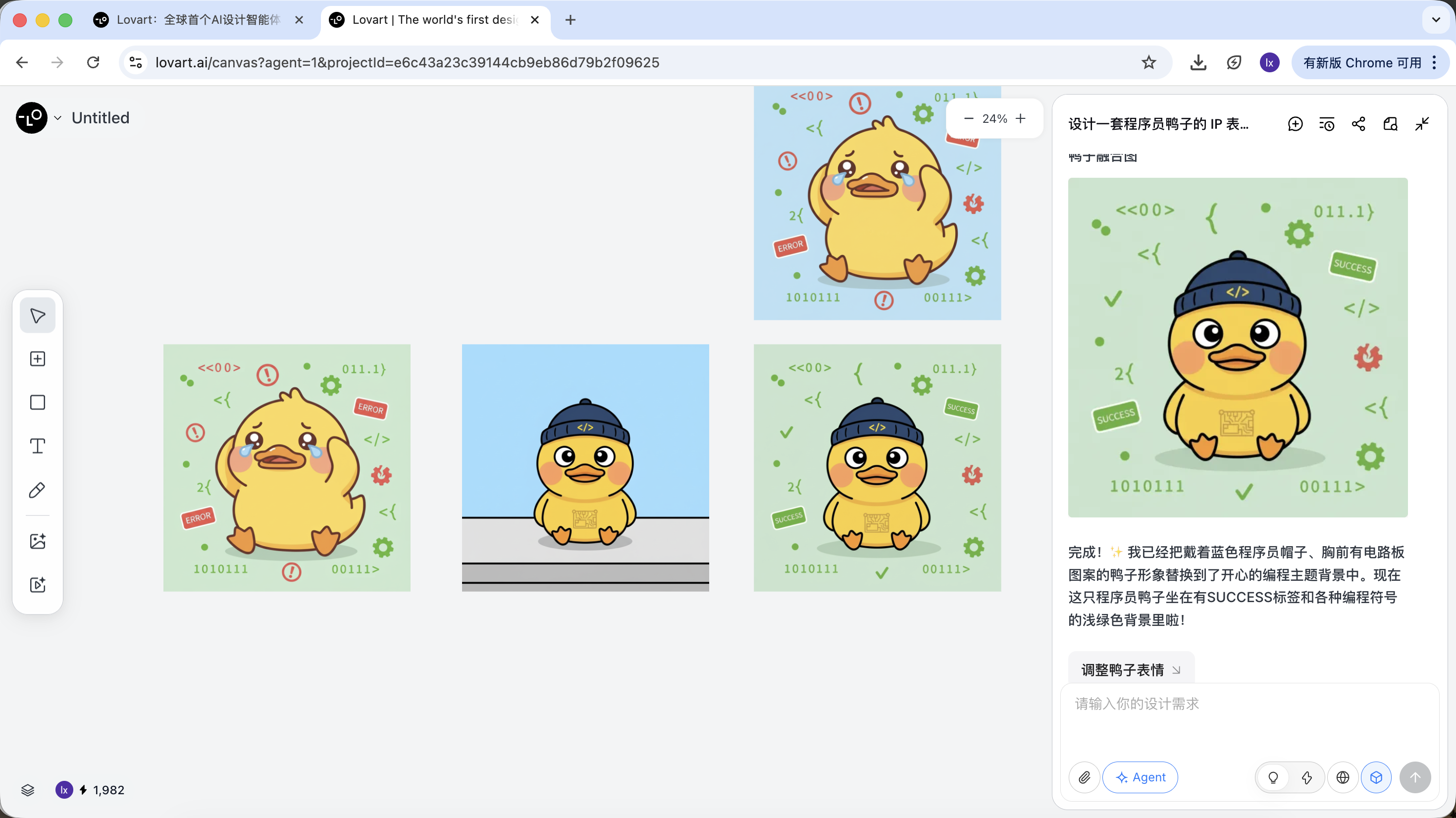
최종 효과도 매우 뚜렷합니다. 다른 조합도 시도해 보세요!
단계 3: 완성 (Agent의 도구 호출)
생성이 완료되면, 확대, 배경 제거, 지우기 등의 작업을 직접 실행할 수 있습니다.
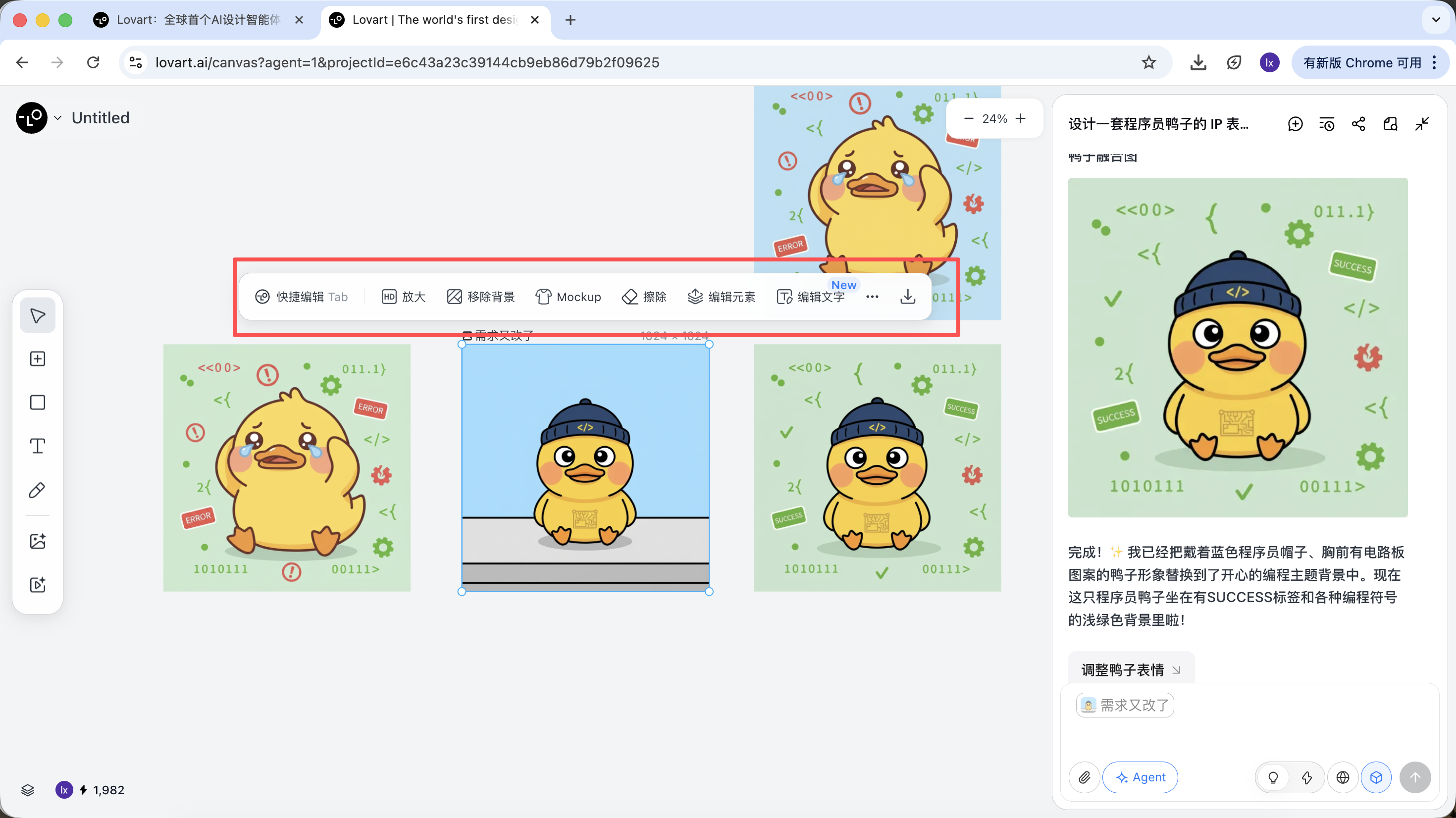
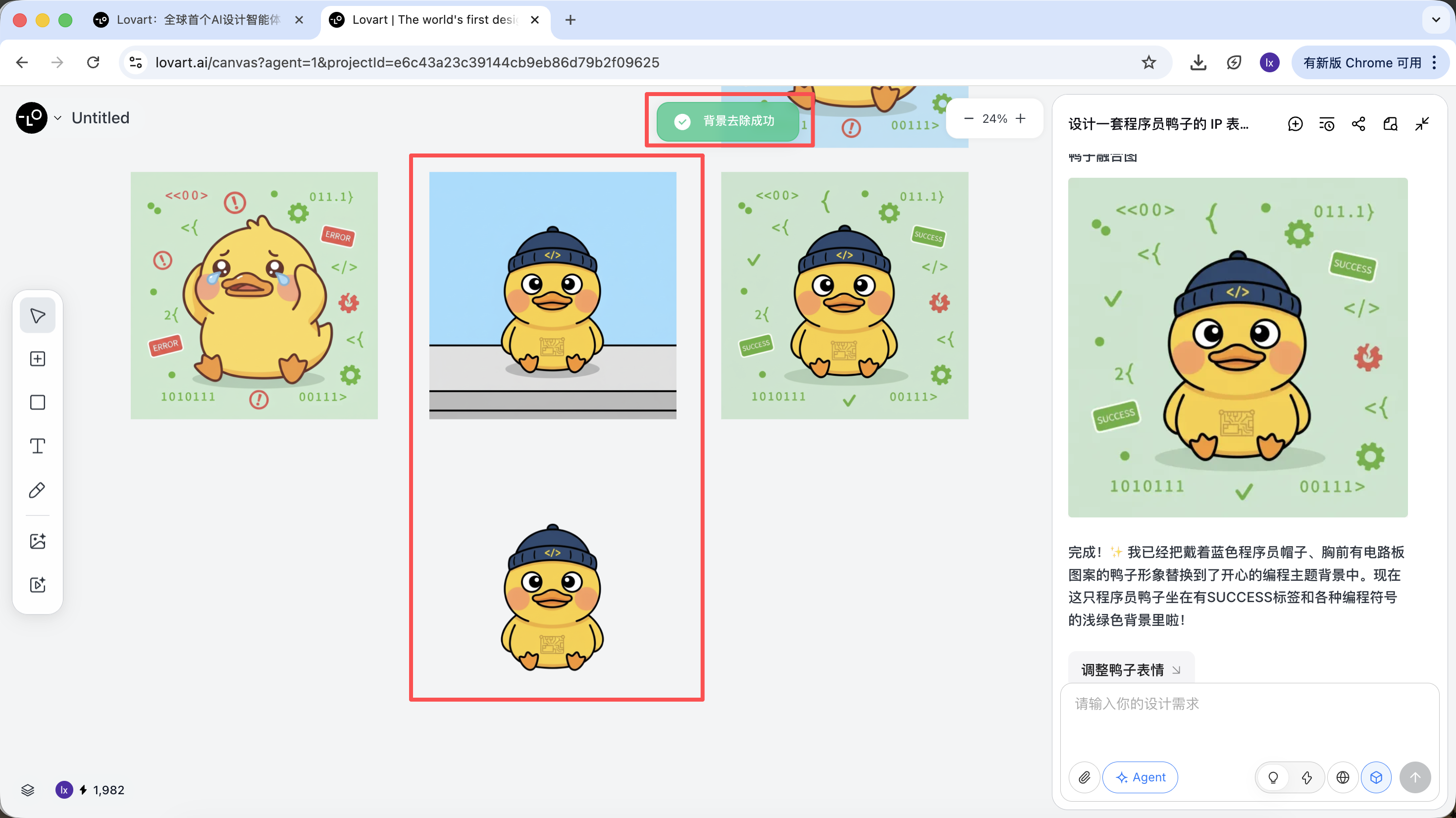
이것들은 단순한 필터가 아니라 Agent가 다른 도구를 자동으로 호출하여 완성한 결과입니다.
기조 스타일이 확정된 후, 일련의 이모티콘 이미지를 매우 빠르게 생성할 수 있습니다.
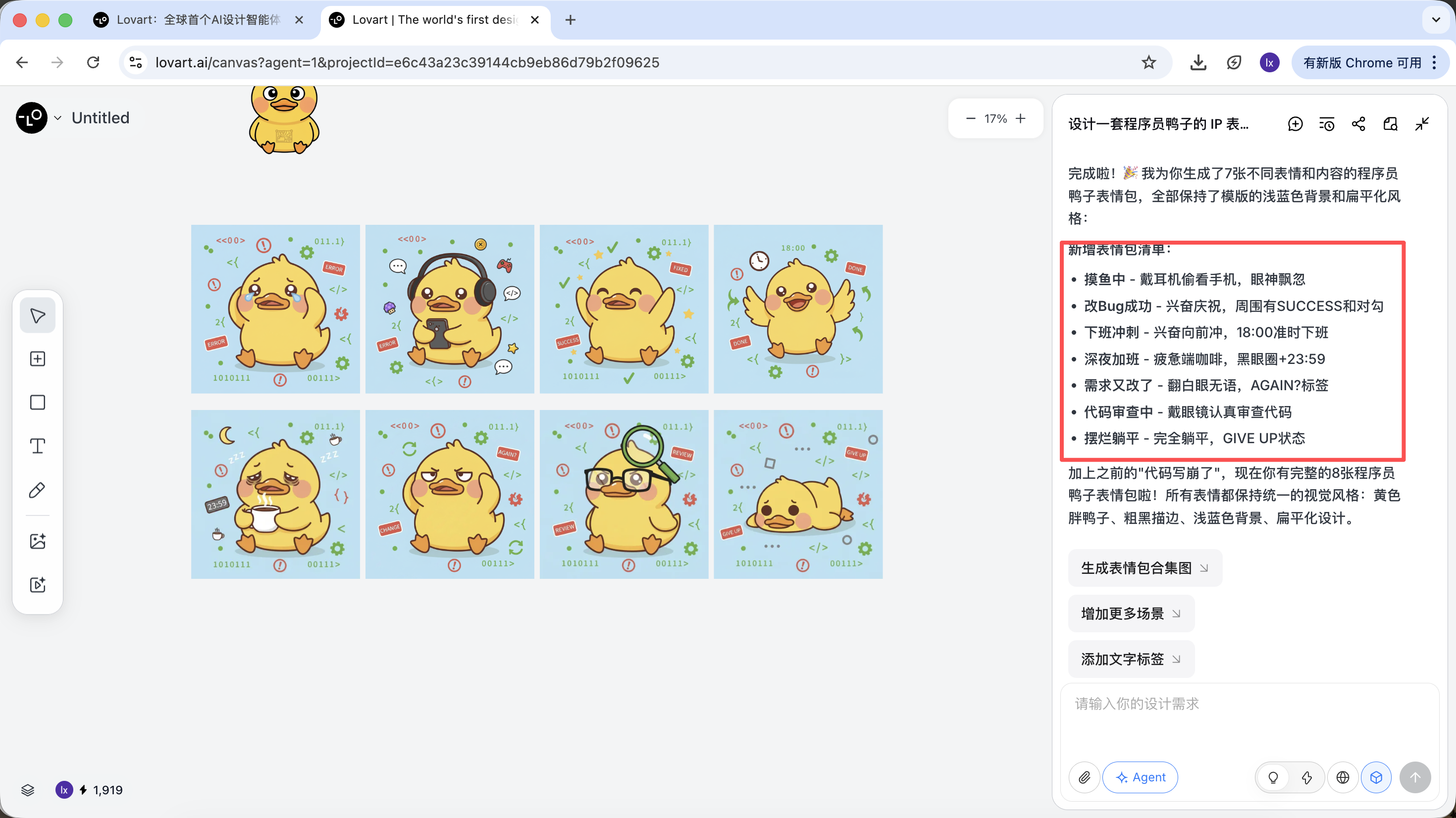
최종적으로 우리가 얻은 것은 직접 납품할 수 있는 생산 등급의 에셋이며, 단순한 시연용 이미지가 아닙니다.
2.3 사용 및 요금 안내
Lovart는 구독제 요금 모델을 채택하고 있으며, 다양한 플랜에 따라 사용 한도와 기능 권한이 다릅니다. 구체적인 내용은 공식 웹사이트에 게시된 것을 기준으로 합니다.
이 튜토리얼은 어떤 플랜도 추천하거나 비교하지 않습니다. 실제 사용에 필요가 있다면 개인 상황에 따라 유료 업그레이드를 선택할 수 있습니다. 현재 알리페이 등의 방식으로 결제를 완료할 수 있습니다.
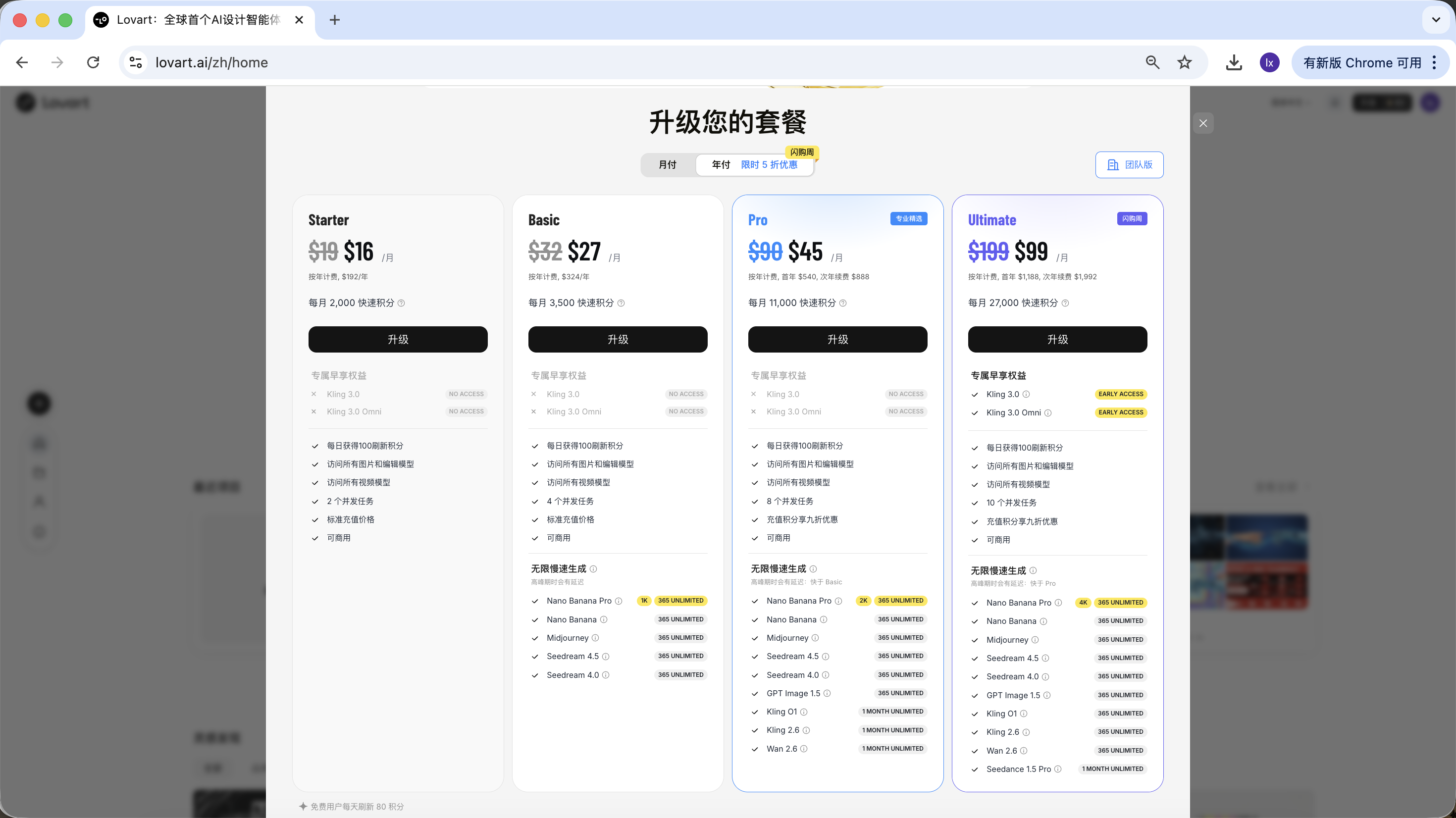
요약
Lovart는 기본 모델을 대체하는 것이 아니라, Agent 메커니즘을 통해 이미지 생성을 "단일 실행"에서 "연속 작업 흐름"으로 업그레이드합니다.
작업이 기획, 일관성, 납품과 관련되기 시작하면, 이러한 유형의 도구의 장점이 매우 분명해집니다.
제3장: 직접 스마트 이미지 생성 어시스턴트 만들기
Lovart를 직접 사용하는 것 외에도, 우리는 간소화된 버전의 이미지 생성 어시스턴트를 직접 구현할 수도 있습니다.
이 장에서는 "기사 자동 일러스트"를 예시로, 실제 문제에서 출발하여 사고 능력을 갖춘 Agent를 점진적으로 구축합니다.
3.1 문제 소개: 왜 기사를 이미지 생성 모델에 직접 전달하면 안 되는가?
긴 기사를 NanoBanana에 입력하고 일러스트 생성을 요청하면, 일반적으로 만족스러운 결과를 얻기 어렵습니다. 그 이유는 모델이 "그림을 못 그려서"가 아니라, 긴 텍스트를 이해하는 데 능숙하지 않기 때문 입니다.
이미지 생성 모델은 간결하고 명확한 시각적 설명을 처리하는 데 더 적합합니다. 입력이 구조, 핵심, 문맥 관계를 포함하는 기사가 되면, 모델은 어떤 내용이 화면에 실제로 표현되어야 하는지 판단할 수 없습니다. 이는 종종 생성 결과가 주제에서 벗어나거나, 산발적인 디테일만 포착하고 전체적인 개괄 능력이 부족하게 만듭니다.
본질적으로 이미지 모델은 "실행" 능력만 있을 뿐, 텍스트를 분석하고 선택하는 과정이 부족합니다.
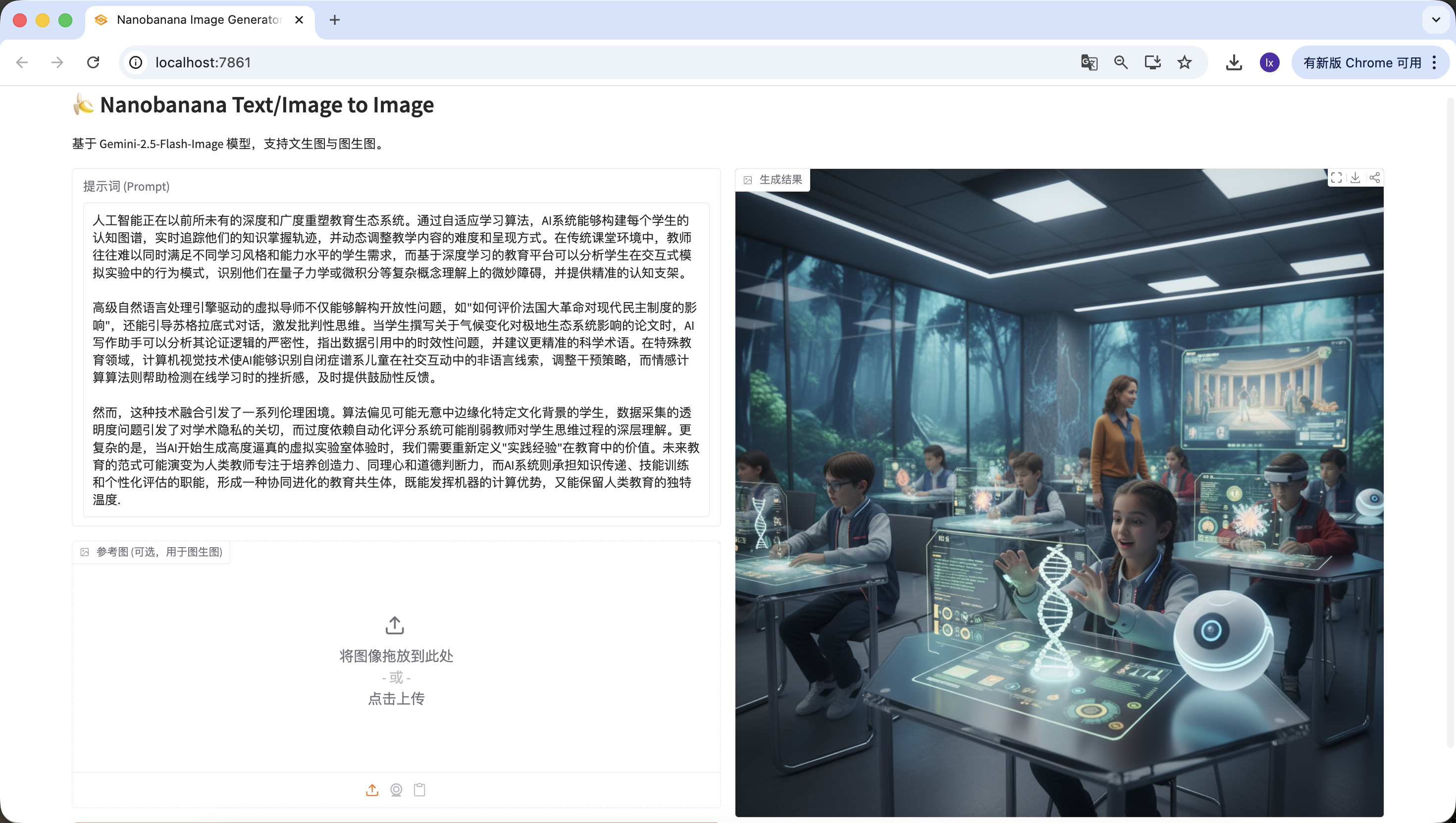
3.2 해결 방안: Agent로 "이해"와 "실행" 분리하기
이 문제를 해결하기 위한 핵심은 더 복잡한 프롬프트가 아니라, 이미지 생성 전에 먼저 생각을 정리하는 것 입니다. 따라서 생성 흐름에 독립적인 "사고 계층"을 도입하고, 이를 바탕으로 가장 간단하게 사용할 수 있는 Agent를 구축합니다.
이 Agent의 핵심 목표는 단 하나입니다: 최종 생성된 이미지가 사용자의 실제 표현 의도에 최대한 가깝게 만드는 것.
전체 흐름은 다음과 같이 요약할 수 있습니다: 긴 텍스트 입력 → 언어 모델 이해 및 판단 → 적절한 시각적 프롬프트 생성 → 이미지 모델 생성 실행 → 이미지 출력
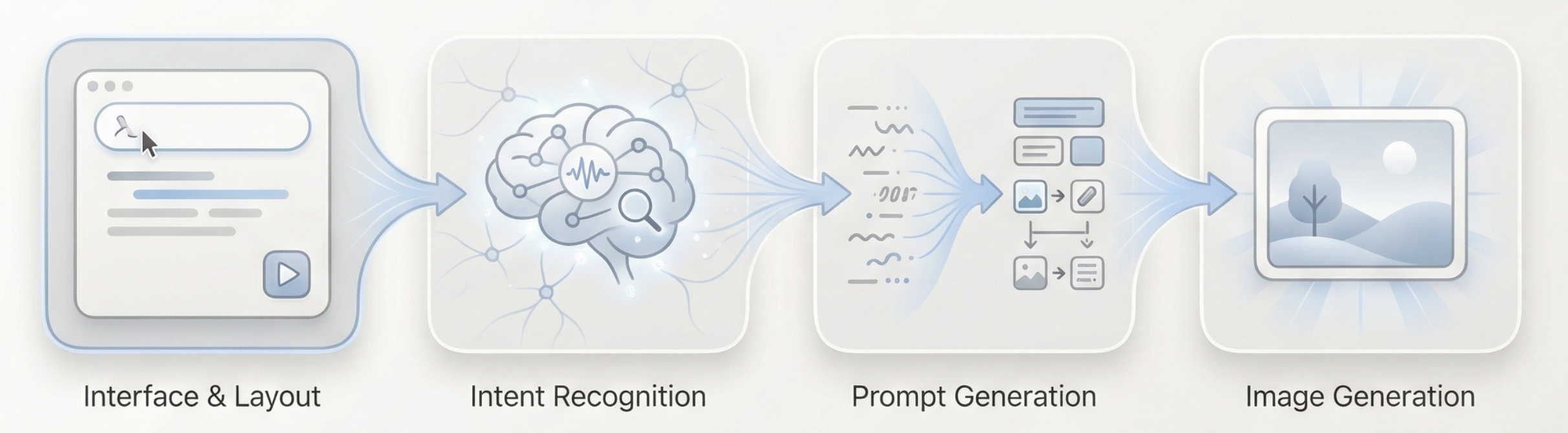
그렇다면 우리가 구축한 Agent는 어떻게 사용자의 의도를 이해할 수 있을까요?
여기서는 간소화된 "사고 계층" 을 선택했습니다. 세 가지 다른 의도를 설정했습니다: 무효 입력, 직접 이미지 생성, 이해가 필요한 긴 텍스트.
이 Agent에서 각 역할의 분담은 네 가지로 요약할 수 있습니다:
- 언어 모델이 의사 결정의 핵심 역할 기사 내용을 이해하고, 사용자 입력의 의도를 판단하며, 작업을 적절한 생성 경로에 배분하여, 다음에 "어떻게 해야 하는지"와 이미지 생성 프롬프트를 어떻게 생성할지 결정합니다.
- 이미지 모델이 실행자 역할 이미지 모델은 이해와 판단에 참여하지 않고, 이미 정리된 시각적 지시만 받아 이미지 렌더링에 집중합니다.
- 사용자가 개입 가능한 안내자 역할 텍스트를 직접 입력하는 것 외에도, 사용자는 과정에서 생성된 프롬프트를 수동으로 조정하거나, 참고 이미지를 추가하여 생성을 보조할 수 있어, 최종 결과를 안내하고 미세 조정할 수 있습니다.
- Gradio와 백엔드 API가 전체 지원 계층 역할 인터페이스, 모델 호출, 결과 표시를 연결하여, 전체 Agent가 완전한 웹 애플리케이션 형태로 안정적으로 실행되도록 보장합니다.
3.3 실전 준비: API 얻기
정말 흥미롭지 않나요! 위의 흐름을 실행하려면 두 가지 유형의 API만 준비하면 됩니다.
손: NanoBanana API (이미지 생성)
제1장에서 이미 구성한 API Key와 API URL을 그대로 사용하며, 추가 설정이 필요하지 않습니다.
뇌: SiliconFlow API (텍스트 사고)
우리는 대형 언어 모델이 "사고 계층"의 역할을 담당하도록 해야 합니다. 이 튜토리얼은 SiliconFlow에서 제공하는 모델 서비스를 사용합니다: https://cloud.siliconflow.cn
SiliconFlow는 OpenAI API 규격과 호환되는 인터페이스를 제공하여, 프로젝트에서 표준 네트워크 요청을 통해 매우 편리하게 호출할 수 있습니다. 여기서 선택한 것은 무료 Qwen2.5-7B-Instruct 모델이며, 호출에 필요한 내용은 아래의 프롬프트에 모두 작성되어 있습니다. 시작하기 전에 공식 웹사이트에서 계정을 등록하고 API Key를 생성하기만 하면 됩니다.
이 Key는 후속 모델 호출에 사용됩니다.
3.4 Agent 구축:
이번 실험은 주로 Trae를 사용하여 코드를 작성하며, 이 튜토리얼에서 선택한 모델은 Gemini-3-Pro-Preview입니다. 전체적인 아이디어는, 새 프로젝트를 만든 후 아래의 완전한 프롬프트를 대화 상자에 복사하여 입력하고, API KEY를 점진적으로 교체한 후 코드를 실행하여 테스트를 완료하는 것입니다.
단계 1️⃣: Gradio Blocks 기본 프레임워크 및 인터페이스 레이아웃
이 단계에서 우리의 주요 목표는 전체 Agent의 "외관"을 먼저 구축하는 것입니다, 즉 프론트엔드 페이지 디자인을 구현합니다. 아래의 프롬프트를 Trae 대화 상자에 복사하여 구현한 후, 로컬 URL(보통 http://127.0.0.1:7860)을 얻게 되며, 이를 통해 인터페이스를 확인하고 구현 효과를 검증할 수 있습니다.
모듈 1: Gradio Blocks 기본 프레임워크 및 인터페이스 레이아웃
1, 작업 목표
- Gradio 4.0.0+의 Blocks 레이아웃을 기반으로 "LLM+Nanobanana 텍스트에서 이미지" 프로젝트의 기본 인터페이스를 구현하고, 고정 좌우 분할 레이아웃을 엄격히 따르며, 모든 UI 컴포넌트를 초기화하고 올바른 초기 상태를 설정합니다.
2, 기술 스택 요구 사항
- Gradio 4.0.0+의 Blocks 모드를 사용하여 개발해야 하며, Interface 모드는 사용할 수 없습니다;
- 의존성: gradio>=4.0.0, pillow>=10.0.0 (가져오기만 하고, 이미지 처리 로직은 일시적으로 구현하지 않음);
- 코드는 완전히 실행 가능한 Python 파일이어야 하며, 모든 필수 import 문을 포함해야 합니다.
3, 인터페이스 레이아웃 규칙 (핵심 제약, 실전 디테일 융합)
- 전체 레이아웃:
페이지 제목: LLM 기반 텍스트에서 이미지 전체 프로세스 도구;
고정 좌우 분할: 왼쪽이 60% 너비, 오른쪽이 40% 너비, gr.Row와 gr.Column을 사용하여 비율 제어를 구현합니다.
- 왼쪽 60% (프롬프트 생성 흐름 영역) 컴포넌트 목록:
input_text: gr.Textbox, 레이블 "텍스트 입력 (튜토리얼 단락 / 이미지 생성 지시)", lines=6, 플레이스홀더 "일러스트가 필요한 튜토리얼 텍스트 또는 직접 이미지 생성 지시를 입력하세요...";
identify_intent_btn: gr.Button, value="의도 식별", 초기 상태는 정상적으로 클릭 가능;
intent_status: gr.Textbox, 레이블 "의도 유형 / 처리 상태", lines=2, interactive=False, 초기값 "의도 미식별";
system_prompt: gr.Textbox, 레이블 "System Prompt (기사 일러스트 의도만 편집 가능)", lines=4, interactive=False, 플레이스홀더 "LLM이 프롬프트를 생성하는 제약 규칙...";
confirm_prompt_btn: gr.Button, value="이미지 생성 프롬프트 생성 확인", interactive=False (초기 비활성화, 오작동 방지);
generation_prompt: gr.Textbox, 레이블 "이미지 생성 프롬프트 (편집 가능)", lines=3, interactive=True, 초기값 비어 있음, 플레이스홀더 "생성된 영문 이미지 생성 프롬프트가 여기에 표시되며, 수동 수정을 지원합니다...".
- 오른쪽 40% (Nanobanana 이미지 생성 기능 영역) 컴포넌트 목록:
ref_image: gr.Image, 레이블 "참고 이미지 (선택사항, 이미지에서 이미지)", type=filepath, height=300, 업로드 허용;
generate_btn: gr.Button, value="이미지 생성", interactive=False (초기 비활성화, 프롬프트가 없으면 클릭 불가);
result_image: gr.Image, 레이블 "생성 결과", type=pil, height=300, 초기값 비어 있음, interactive=False.
4, 인터랙션 로직 요구 사항
- 모든 컴포넌트의 interactive 초기 상태는 위 구성을 엄격히 따르며, 이후 함수를 통해 동적으로 업데이트됩니다;
- 버튼 비활성화 상태는 직관적이어야 함 (회색으로 표시), 사용자의 오작동을 방지합니다.
5, 출력 요구 사항
- 완전한 Python 코드를 생성하며, 인터페이스 레이아웃과 컴포넌트 초기화만 구현하고 비즈니스 로직은 포함하지 않습니다;
- 코드 주석이 명확하고, 컴포넌트 명명이 실전 버전과 일치 (input_text/identify_intent_btn 등);
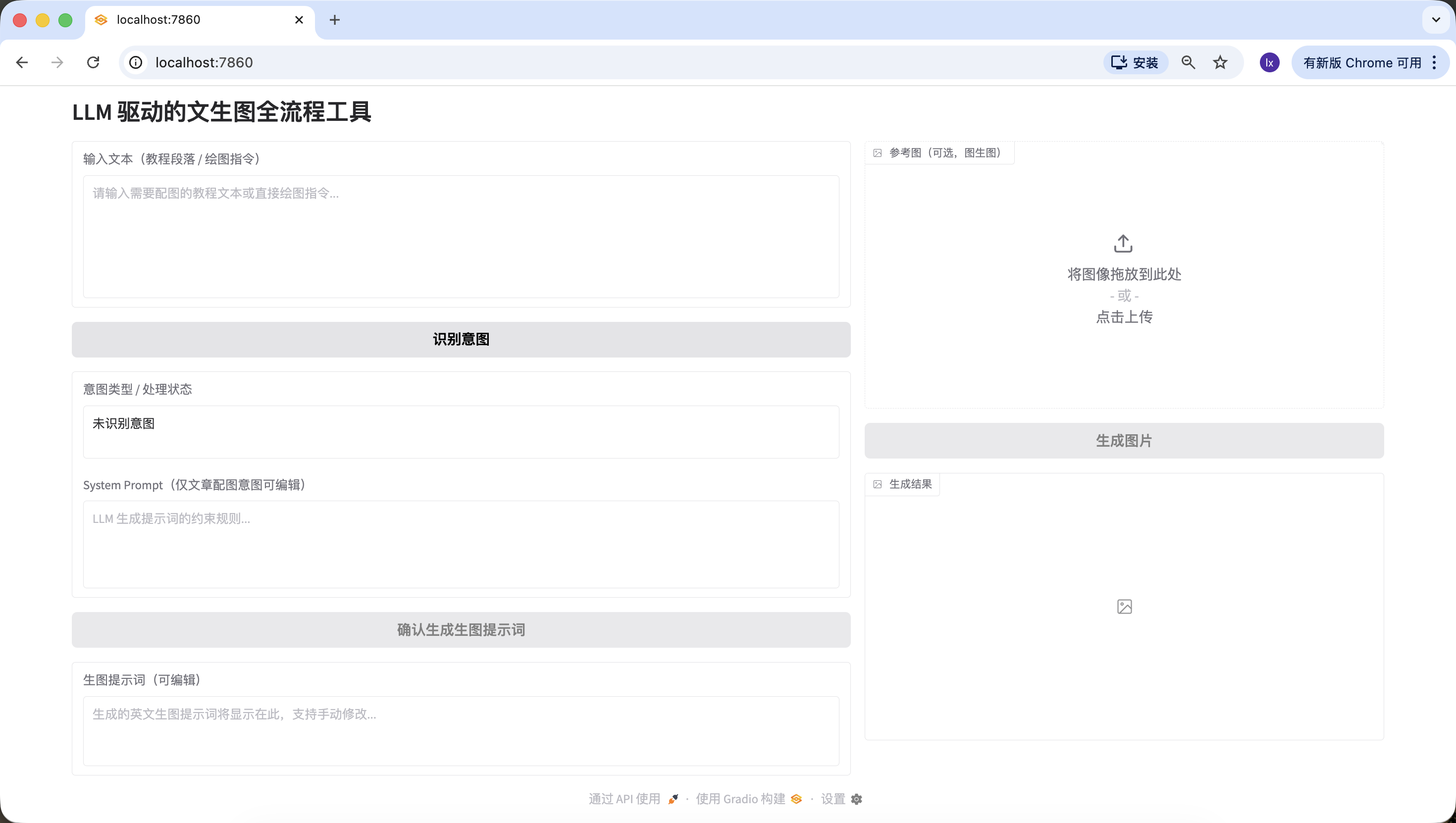
- 코드를 직접 실행할 수 있으며, 인터페이스 구조가 설명과 완전히 일치합니다.브라우저에서 http://127.0.0.1:7860을 열면 Trae가 우리의 요구 사항에 따라 다음 웹 페이지를 생성한 것을 볼 수 있으며, 우리의 요구 사항과 대략 일치하므로 다음 생성 단계로 진행할 수 있습니다.
단계 2️⃣: LLM 의도 식별 모듈 (Siliconflow API)
일상적으로 VLM으로 그림을 그릴 때, 다음과 같은 세 가지 일반적인 입력 상황이 있을 수 있습니다:
- 무의미한 내용, 예를 들어 "안녕", "오늘 밥 먹었어?" 등, 해당 이미지를 그릴 수 없습니다.
- 기사/긴 텍스트, 단어 수가 많고, 예를 들어 200자 정도의 구조화된 기사로, 먼저 기사의 구조와 내용을 이해한 다음 이 텍스트를 완전히 개괄할 수 있는 이미지를 어떻게 생성할지 고려해야 합니다.
- 직접 이미지 생성 지시, 예를 들어 "목욕하는 강아지를 그려줘" 등, 요구 사항이 이미 매우 구체적으로 설명되어 있어 직접 이미지를 생성할 수 있습니다.
이전과 마찬가지로 아래의 프롬프트를 Trae 대화 상자에 복사하여 구현하고, 이전 단계에서 얻은 API를 추가합니다.
모듈 2: LLM 의도 식별 모듈 (Siliconflow API)
1, 작업 목표
이미 구현된 Gradio 인터페이스를 기반으로, "의도 식별" 버튼에 클릭 로직을 추가하고, Siliconflow API를 호출하여 의도 식별을 완료하며, 컴포넌트 상태를 연동합니다.
2, 기술 스택 요구 사항
Gradio 4.0.0+ Blocks 기반;
의존성: requests>=2.31.0, openai;
완전히 실행 가능한 Python 파일 출력, 모듈 1 인터페이스 + 이 모듈 로직 포함.
3, 핵심 비즈니스 규칙 (절대 이탈 불가)
- 의도 분류 규칙 (단 3가지, 엄격하게 숫자 + 설명 반환)
1 = 무의미한 내용: 단순 잡담, 인사, 관련 없는 대화, 그리기나 일러스트에 대한 어떠한 요구도 없음 (예: "안녕", "밥 먹었어?");
2 = 기사 / 긴 텍스트 일러스트 요구: 사용자가 완전한 기사, 튜토리얼, 단락, 설명 텍스트를 입력하며, 내용이 서술/설명/해설에 편중되어 있고, 이 내용에 대한 일러스트를 생성해야 한다는 의도가 내포되어 있음, 사용자가 명시적으로 "이 텍스트에 일러스트를 달아주세요"라고 말할 필요는 없음;
3 = 직접 이미지 생성 지시: 사용자가 짧고 명확한 그리기 명령을 입력하며, 긴 텍스트 배경이 없고, 직접 특정 내용을 그리라고 요구함 (예: "Apple 스타일의 고양이를 그려줘").
- LLM 호출 제약 (실전 버전 템플릿 융합)
인터페이스 주소: https://api.siliconflow.cn/v1/chat/completions;
모델: Qwen/Qwen2.5-7B-Instruct;
temperature=0.1;
통일 정의 코드:
python
실행
LLM_BASE_URL = "https://api.siliconflow.cn/v1"
LLM_API_KEY = "" # 사용자가 직접 교체
LLM_MODEL = "Qwen/Qwen2.5-7B-Instruct"# 실전 검증된 의도 식별 템플릿 (코드에 고정)
INTENT_PROMPT_TEMPLATE = """사용자가 입력한 텍스트의 의도를 식별해야 합니다, 다음 3가지 결과 중 하나만 반환하세요 (형식: 숫자 + 한국어 설명):
1 = 무의미한 내용; 2 = 기사 / 긴 텍스트 일러스트 요구; 3 = 직접 이미지 생성 지시.
사용자 입력: {user_input}
식별 결과:
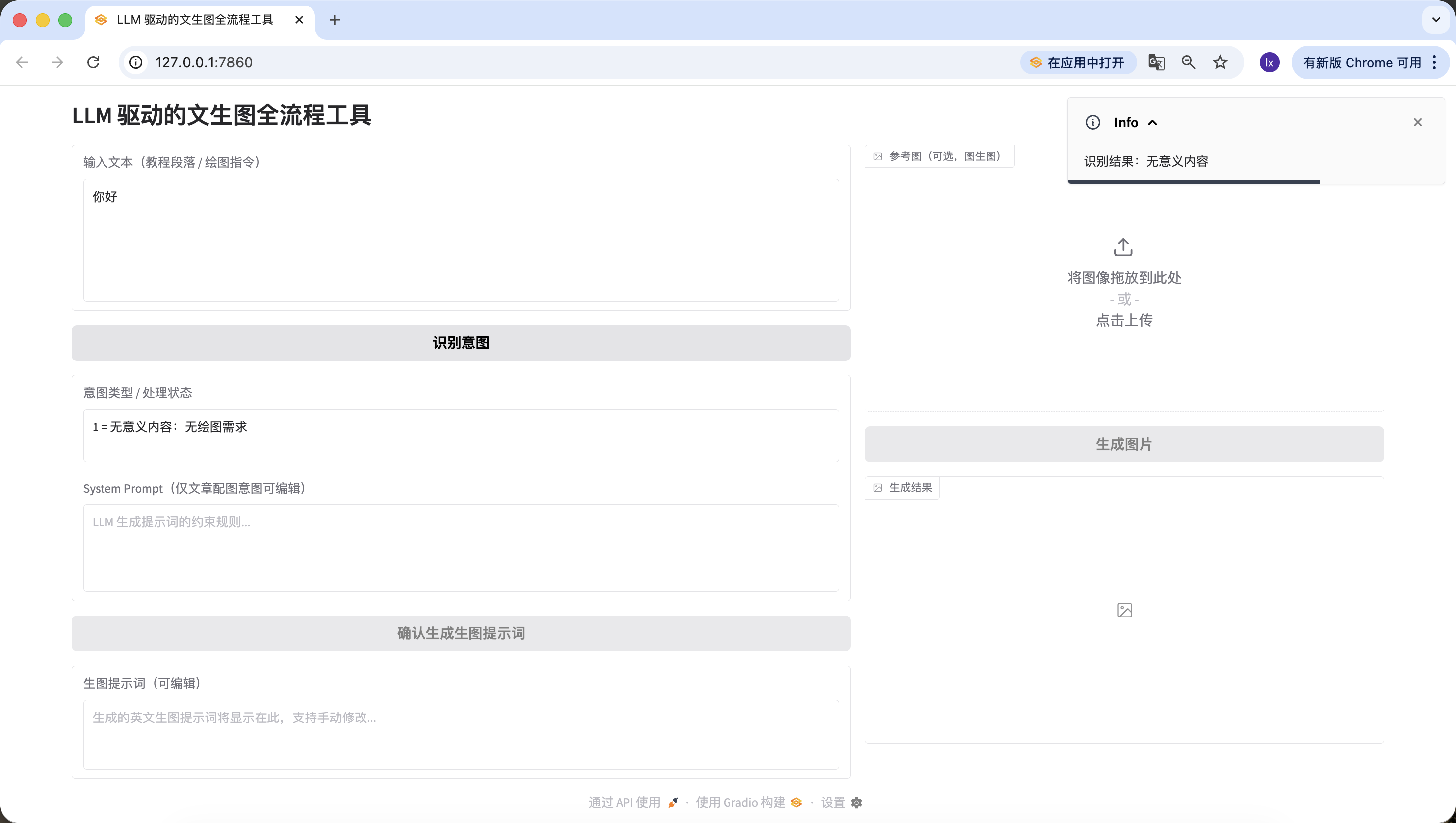
반환 결과에서 숫자와 설명만 추출, 추가 내용은 금지합니다."""이전의 http://127.0.0.1:7860 웹 주소를 새로고침하고, 세 가지 상황을 올바르게 감지할 수 있는지 테스트를 시작합니다.
- 무의미한 내용, "안녕", "고마워" 등을 입력해 보면, 정상적으로 식별되는 것을 확인할 수 있습니다.
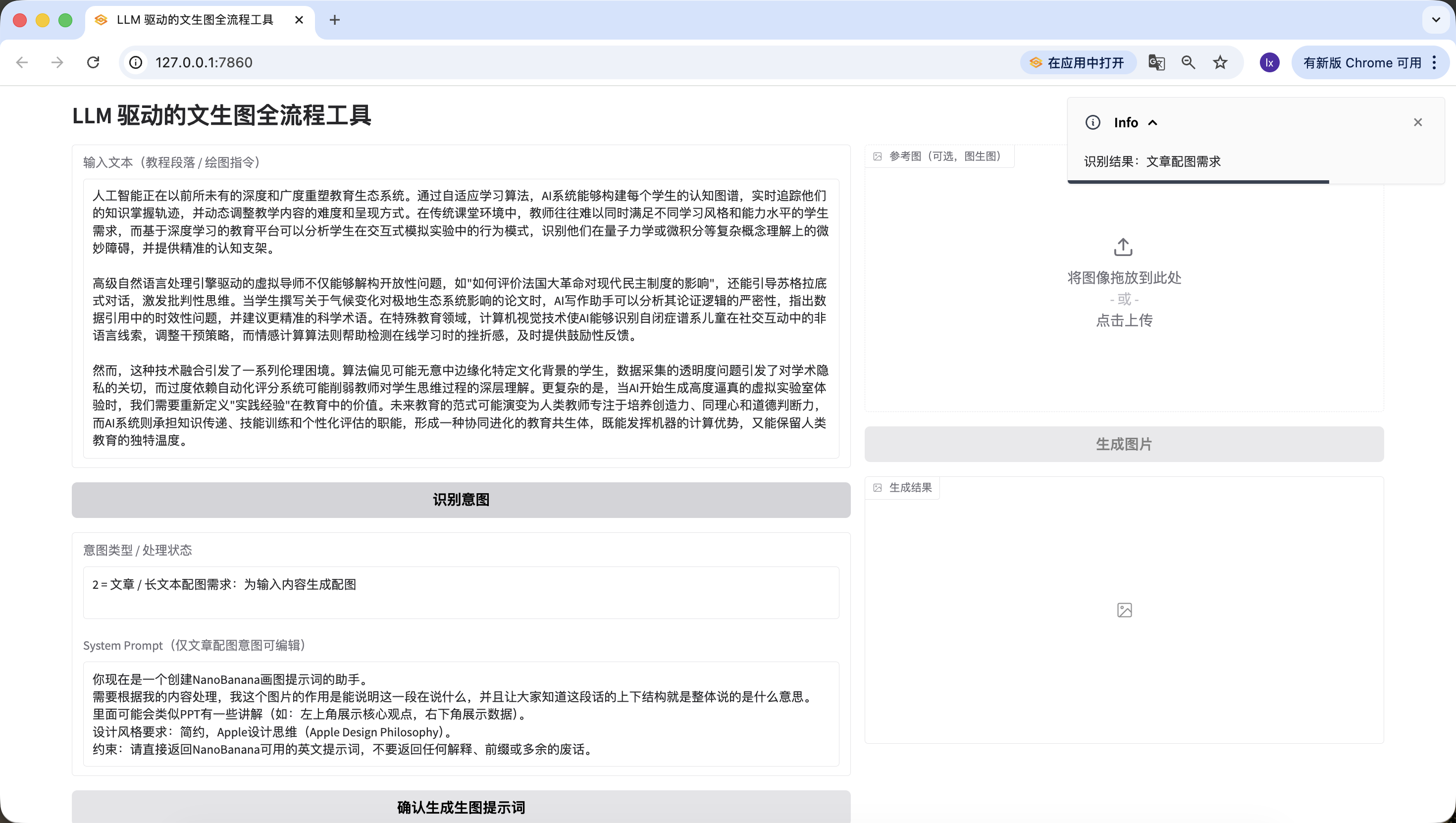
- 기사/긴 텍스트, 여기서는 Doubao가 생성한 인공지능에 대한 설명 텍스트를 사용했습니다. 자신의 논문 단락을 사용하여 테스트해 볼 수도 있습니다.
인공지능은 전례 없는 깊이와 폭으로 교육 생태계를 재편하고 있습니다. 적응형 학습 알고리즘을 통해, AI 시스템은 각 학생의 인지 지도를 구축하고, 그들의 지식 습득 궤적을 실시간으로 추적하며, 교육 콘텐츠의 난이도와 제공 방식을 동적으로 조정합니다. 전통적인 교실 환경에서 교사는 종종 다양한 학습 스타일과 능력 수준을 가진 학생들의 요구를 동시에 충족시키기 어렵지만, 딥러닝 기반의 교육 플랫폼은 학생들이 인터랙티브 시뮬레이션 실험에서 보이는 행동 패턴을 분석하고, 양자역학이나 미적분과 같은 복잡한 개념 이해에서의 미묘한 장애물을 식별하며, 정확한 인지 비계를 제공할 수 있습니다.
고급 자연어 처리 엔진 기반의 가상 튜터는 개방형 질문을 해체할 수 있을 뿐만 아니라, 소크라테스식 대화를 이끌어 비판적 사고를 자극합니다. 학생이 기후 변화가 극지 생태계에 미치는 영향에 대한 논문을 작성할 때, AI 작문 조수는 그 논증 논리의 엄밀성을 분석하고, 데이터 인용에서의 시의성 문제를 지적하며, 더 정확한 과학 용어를 제안할 수 있습니다. 특수 교육 분야에서 컴퓨터 비전 기술은 AI가 자폐 스펙트럼 아동이 사회적 상호작용에서 보이는 비언어적 단서를 식별할 수 있게 하여 개입 전략을 조정하고, 정서 컴퓨팅 알고리즘은 온라인 학습 시 좌절감을 감지하여 적시에 격려 피드백을 제공합니다.
그러나 이러한 기술 융합은 일련의 윤리적 딜레마를 야기합니다. 알고리즘 편향은 특정 문화적 배경을 가진 학생을 무의식적으로 소외시킬 수 있고, 데이터 수집의 투명성 문제는 학술적 개인정보에 대한 우려를 불러일으키며, 자동화된 평가 시스템에 대한 과도한 의존은 교사의 학생 사고 과정에 대한 깊은 이해를 약화시킬 수 있습니다. 더 복잡한 것은, AI가 고도로 사실적인 가상 실험실 경험을 생성하기 시작할 때, 우리는 교육에서 "실무 경험"의 가치를 재정의해야 한다는 것입니다. 미래 교육의 패러다임은 인간 교사가 창의성, 공감 능력, 도덕적 판단력을 배양하는 데 집중하고, AI 시스템이 지식 전달, 기술 훈련, 개인화된 평가의 기능을 담당하여, 기계의 계산적 장점을 발휘하면서도 인간 교육의 독특한 온기를 보존하는 협동 진화적 교육 공생체로 진화할 수 있습니다.마찬가지로 감지에 성공했습니다~
- 직접 이미지 생성 지시, 여기서는 "고양이를 그리고 싶어요"를 입력했으며, 마찬가지로 정확하게 감지되었습니다.
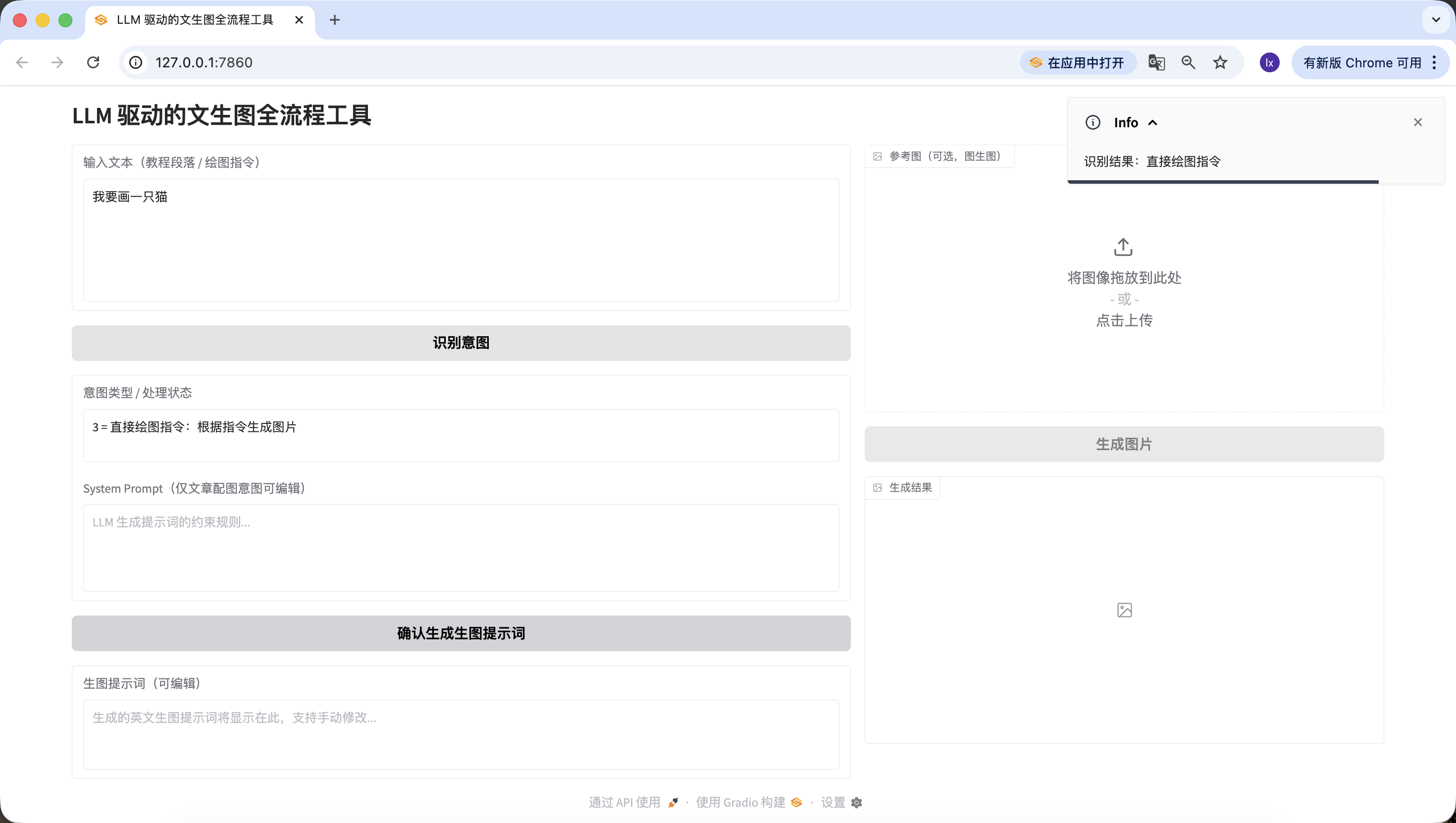
여기까지 우리는 두 번째 단계인 의도 식별을 순조롭게 구현했습니다.
단계 3️⃣: 이미지 생성 프롬프트 생성 모듈 (LLM 두 번째 호출)
의도 식별 후, 기사나 긴 텍스트의 경우 그림을 그리기 위한 프롬프트를 생성하는 것이 매우 중요한 단계이며, 이것이 바로 이 Agent의 핵심입니다.
모듈 3: 이미지 생성 프롬프트 생성 모듈 (LLM 두 번째 호출)
1, 작업 목표
의도 식별을 기반으로, "이미지 생성 프롬프트 생성 확인" 버튼 로직을 구현하고, LLM을 호출하여 텍스트를 이미지 생성에 적합한 영문 시각적 프롬프트로 최적화하며, 편집 상자에 채우고 "이미지 생성" 버튼과 연동합니다.
2, 기술 스택 요구 사항
모듈 2와 동일, 완전한 코드 출력 = 모듈 1 + 모듈 2 + 이 모듈;
모듈 2에서 정의한 LLM_BASE_URL, LLM_API_KEY, LLM_MODEL을 공유하며, 새로운 키를 추가하지 않습니다.
3, 핵심 비즈니스 규칙 (실전 버전 프롬프트 조립 로직 융합)
- 프롬프트 생성 입력 규칙 (엄격하게 준수해야 함)
이미지 생성 프롬프트 생성은 더 이상 단순한 문자열 연결이 아니라, 표준 Chat 메시지 리스트를 구성하는 것입니다. 코드 구조는 다음과 같습니다:
python
실행
messages=[# System 역할: 웹 페이지에서 사용자가 최종 확인/편집한 system_prompt 내용{"role": "system", "content": final_system_prompt},# User 역할: 처리할 데이터를 담당하며, 작업 목표를 명확히 함{"role": "user", "content": f"다음 내용에 대한 시각적 프롬프트를 생성해 주세요:\n\n{user_input}"}]
의도가 2일 때: System 내용은 사용자가 편집한 system_prompt의 최종 버전을 사용;
의도가 3일 때: System 내용은 비활성화 상태에서 채워진 기본 규칙을 사용
user_input은 사용자가 최초로 input_text 상자에 입력한 원본 텍스트입니다.
- 실전 검증된 System Prompt 사전 설정 (코드에 고정)
python
실행
SYSTEM_PROMPT_DEFAULT = """당신은 이제 NanoBanana 이미지 생성 프롬프트를 생성하는 어시스턴트입니다.
내 콘텐츠에 따라 처리해야 합니다. 이 이미지의 역할은 이 단락이 무엇을 말하고 있는지 설명하고, 모두가 이 텍스트의 위아래 구조, 즉 전체적으로 무엇을 의미하는지 알 수 있게 하는 것입니다.
PPT와 유사한 해설이 있을 수 있습니다 (예: 왼쪽 상단에 핵심 관점 표시, 오른쪽 하단에 데이터 표시).
디자인 스타일 요구 사항: 간결, Apple 디자인 철학 (Apple Design Philosophy).
제약 사항: NanoBanana에서 사용할 수 있는 영문 프롬프트만 직접 반환하고, 어떠한 설명, 접두사 또는 불필요한 말도 반환하지 마세요."""
- LLM 호출 제약
모듈 2와 동일한 LLM_BASE_URL, LLM_API_KEY, LLM_MODEL 공유;
temperature=0.7 (프롬프트의 창의성과 적합성 보장);
max_tokens=200 (출력 길이 제한, 프롬프트 제약에 부합);
위의 표준 Chat 메시지 리스트 구조를 엄격히 사용하며, 문자열 연결은 금지합니다.
- 예시 입력 및 출력 (핵심 참고)
입력 예시 1 (기사 일러스트 의도): 원본 텍스트: "AI가 교육을 어떻게 변화시키는가: 인공지능 기술의 발전에 따라, 교사의 역할이 지식 전달자에서 안내자로 변화하고, AI 어시스턴트가 학생의 개인화된 학습을 보조할 수 있으며, 교실에서의 인간-기계 협력이 일상이 되었습니다." 최종 System Prompt: SYSTEM_PROMPT_DEFAULT (수정하지 않음) 예상 출력: "Minimalist illustration, Apple Design Philosophy, 1024x1024. Top left shows 'AI + Education' core concept, bottom right shows data of teacher-student-AI collaboration, soft color palette, clean lines, no redundant elements."
입력 예시 2 (직접 이미지 생성 지시): 원본 텍스트: "Apple 스타일의 고양이를 그려줘, MacBook 옆에 앉아 있는" 최종 System Prompt: SYSTEM_PROMPT_DEFAULT (비활성화 상태) 예상 출력: "Minimalist cat, Apple style, 1024x1024, sitting next to a silver MacBook, clean white background, soft shadows, geometric shapes, no extra details."
- 프롬프트 출력 강제 제약
순수 영문, 중국어 없음;
반드시 Apple Design Philosophy/Apple style + 1024x1024 포함;
길이 50-200자, 코드 내 검증;
추가 설명, 접두사 또는 불필요한 말 없이 프롬프트 자체만 반환.
4, 컴포넌트 연동 규칙
생성 성공: 프롬프트를 generation_prompt 상자에 채우고, generate_btn을 활성화하며, intent_status에 "프롬프트 생성 성공, 수정 후 이미지 생성 가능"을 추가;
생성 실패: 구체적인 원인 표시 (예: API 호출 실패, 길이 미달), generate_btn은 비활성화 유지, generation_prompt 상자는 비어 있음;
사용자가 수동으로 generation_prompt 상자를 수정/비우기:
비우면 자동으로 generate_btn을 비활성화;
비어 있지 않으면 generate_btn을 활성화 상태로 유지.
5, 예외 처리
API 호출 실패: 친절한 안내 "프롬프트 생성 실패: {구체적인 오류 정보}", 충돌하지 않음;
프롬프트 검증 실패: 명확한 원인 안내 (예: "Apple style 미포함", "길이가 단 40자"), 재시도 허용;
응답 파싱 실패: 안내 "LLM 반환 결과를 파싱할 수 없습니다, 다시 시도해 주세요".
6, 출력 요구 사항
완전히 실행 가능한 코드, LLM_API_KEY만 교체하면 사용 가능;
코드 구조가 명확하고 주석이 완전하며, 인터페이스가 아름답고 간결함;
표준 Chat 메시지 리스트 구조를 엄격히 구현하고, 파라미터와 예시 로직이 일치함;
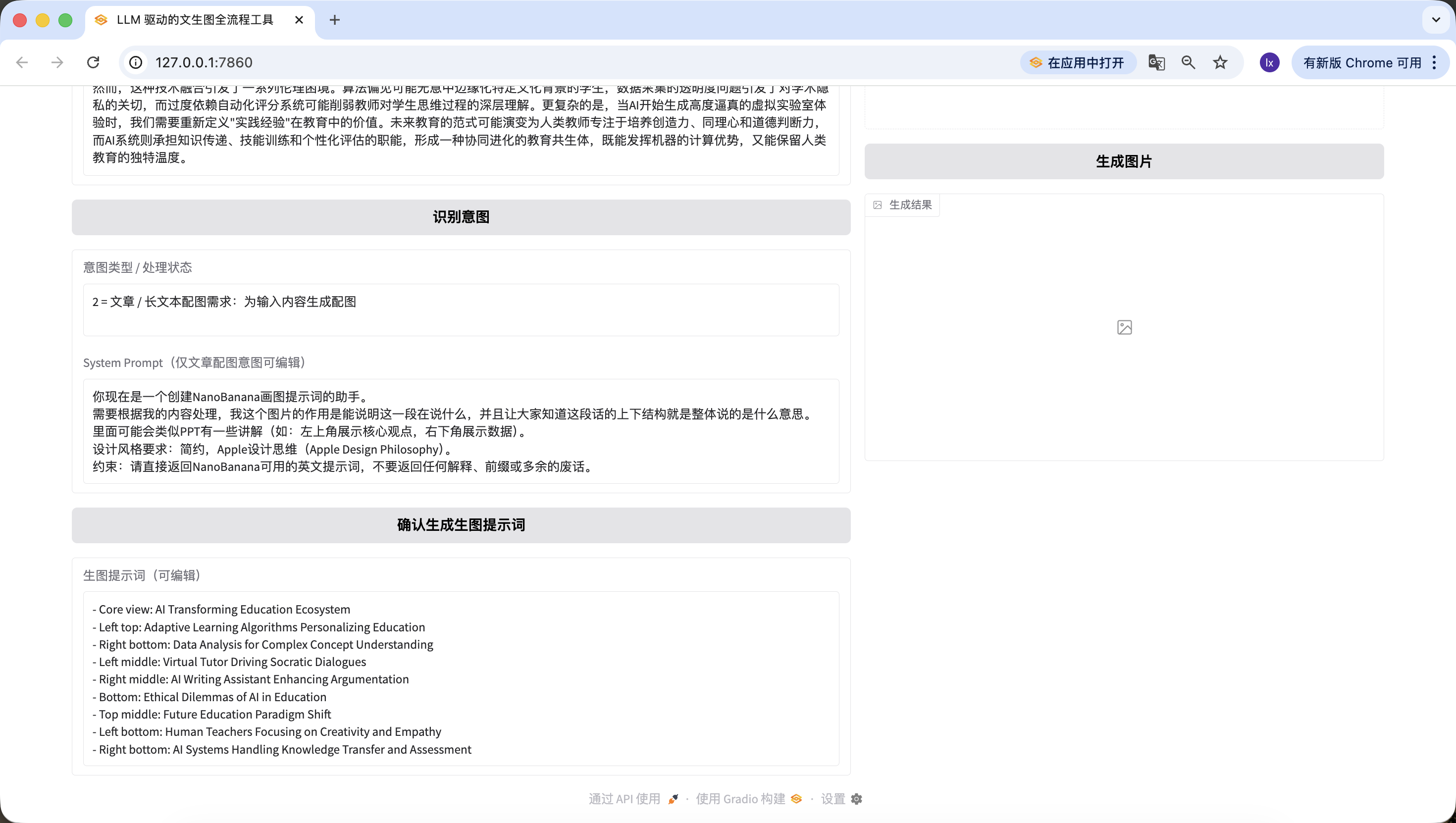
프롬프트 길이, 내용 검증 로직을 포함하며, 오류 안내가 친절함.마찬가지로 두 번째 단계의 텍스트를 복사하여 검증합니다.
주목할 점은, 여기서 우리가 사전 설정한 이미지 생성 프롬프트의 System Prompt는 다음과 같습니다:
당신은 이제 NanoBanana 이미지 생성 프롬프트를 생성하는 어시스턴트입니다. 내 콘텐츠에 따라 처리해야 합니다. 이 이미지의 역할은 이 단락이 무엇을 말하고 있는지 설명하고, 모두가 이 텍스트의 위아래 구조, 즉 전체적으로 무엇을 의미하는지 알 수 있게 하는 것입니다. PPT와 유사한 해설이 있을 수 있습니다 (예: 왼쪽 상단에 핵심 관점 표시, 오른쪽 하단에 데이터 표시). 디자인 스타일 요구 사항: 간결, Apple 디자인 철학 (Apple Design Philosophy). 제약 사항: NanoBanana에서 사용할 수 있는 영문 프롬프트만 직접 반환하고, 어떠한 설명, 접두사 또는 불필요한 말도 반환하지 마세요.
다른 사전 설정 템플릿으로 변경하고 싶다면, 앞의 프롬프트에서 수정하거나 Trae에서 대화를 통해 직접 수정할 수 있습니다.
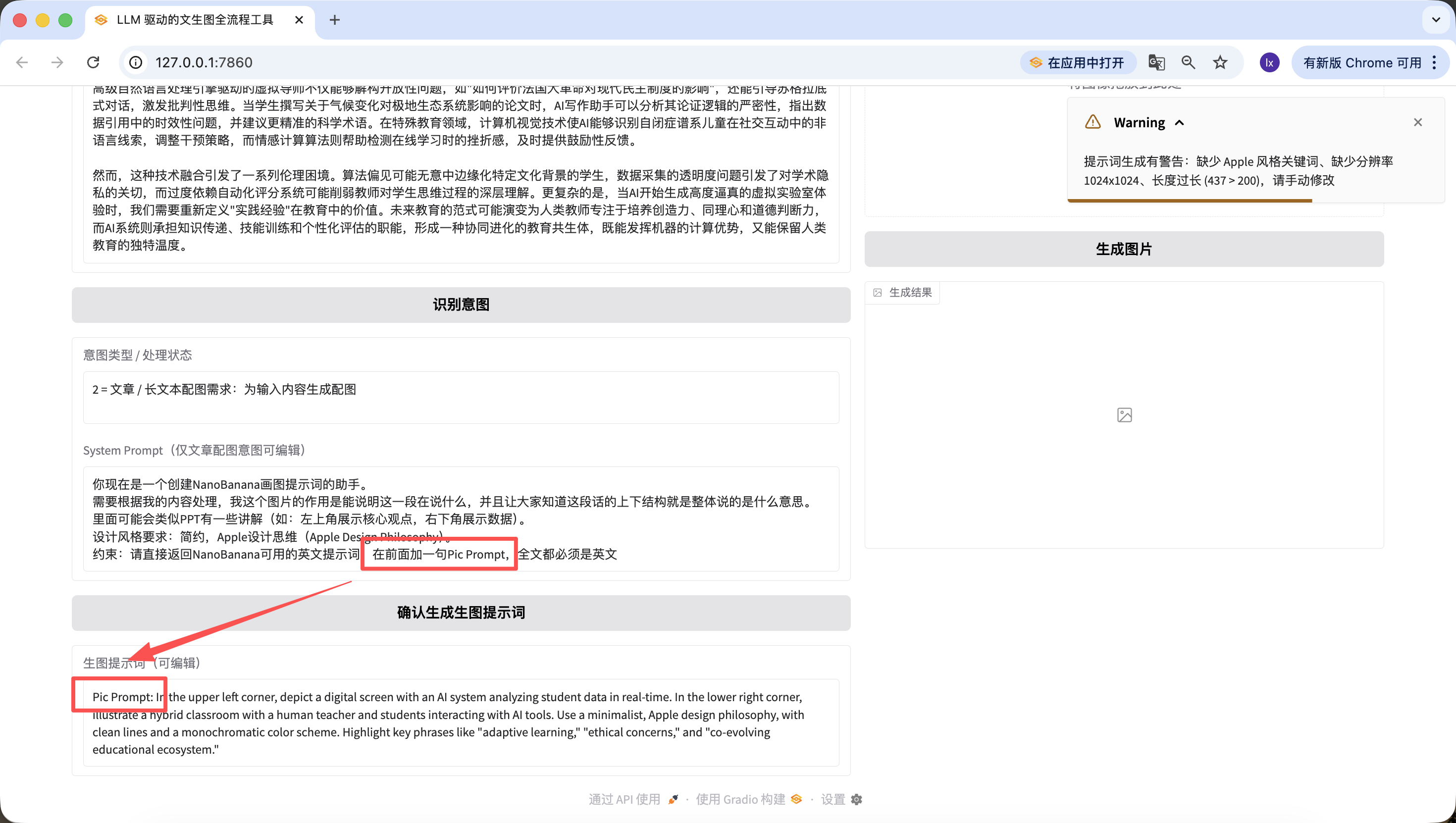
기본 코드를 수정하는 것 외에도, 웹 페이지에서도 빠르게 편집할 수 있습니다. 예를 들어, 여기에 "앞에 Pic Prompt라는 문장을 추가"라는 문장을 추가했는데, 생성된 새로운 프롬프트의 앞에도 포함되어 있는 것을 볼 수 있습니다~ 이렇게 설계한 것은 생성 프롬프트의 System Prompt를 빠르게 수정할 수 있도록 돕기 위한 것이며, 스타일을 빠르게 전환할 수 있게 합니다.
단계 4️⃣: Nanobanana 텍스트에서 이미지 / 이미지에서 이미지 모듈
드디어 마지막 단계입니다. 이미지 생성 모델을 연결하지 않으면, 완전한 Agent가 아닙니다!
모듈 4: Nanobanana 텍스트에서 이미지 / 이미지에서 이미지 모듈 (최종 버전)
1, 작업 목표
"이미지 생성" 버튼 로직을 구현하고, 실제 Nanobanana API를 호출하며, 텍스트에서 이미지 / 이미지에서 이미지를 지원하고, Base64를 파싱하여 이미지를 표시합니다.
2, 기술 스택 요구 사항
Gradio 4.0.0+ Blocks 기반;
의존성: requests, pillow, base64, io, re;
완전한 코드 = 모듈 1+2+3 + 이 모듈.
3, 핵심 API 구성 (실전 검증 고정)
고정 코드 구성:
python
실행
# 코드에 고정된 API 구성
NANOBANANA_API_URL = "https://api.zyai.online/v1/chat/completions"
NANOBANANA_MODEL = "gemini-2.5-flash-image"
NANOBANANA_API_KEY = "" # 사용자가 직접 교체
인증 방식: Header Authorization: Bearer {NANOBANANA_API_KEY}.
4, 이미지 전처리 요구 사항 (반드시 구현해야 함) 함수 image_to_base64_data_uri (ref_image_path) 구현, 핵심 로직:
PIL 이미지를 PNG 형식으로 변환;
1024x1024 해상도로 자동 크기 조정;
투명 채널을 흰색 배경으로 변환;
Base64로 인코딩, 반환 형식: data:image/png;base64,...
5, 요청 구성 규칙 (실전 버전 분기 로직에 엄격히 따름)
- 핵심 함수 정의 함수 generate_image (prompt, ref_image_path) 구현:
입력 파라미터: prompt (generation_prompt 상자 내용), ref_image_path (ref_image에 업로드한 파일 경로);
반환: PIL Image (result_image에 표시) 또는 오류 안내.
- 논리 분기 1: 순수 텍스트에서 이미지 (ref_image_path가 비어 있음)
python
실행
messages = [{"role": "user", "content": prompt}]
- 논리 분기 2: 이미지에서 이미지 (ref_image_path에 값이 있음)
python
실행
# 먼저 이미지 전처리 함수 호출
image_base64 = image_to_base64_data_uri(ref_image_path)
messages = [{"role": "user","content": [{"type": "text", "text": prompt},{"type": "image_url", "image_url": {"url": image_base64}}]}]
6, 응답 파싱 요구 사항 (두 가지 형식을 모두 호환해야 함) choices [0].message.content에서 이미지 Base64를 추출, 지원:
구조화된 JSON 반환의 image_url 필드;
Markdown 형식
;
통일하여 Base64 인코딩을 추출한 후 디코딩하여 PIL Image로 변환하여 반환.
7, 컴포넌트 연동 및 예외 처리
생성 성공: PIL Image를 result_image에 표시, intent_status에 "이미지 생성 성공" 안내;
생성 / 파싱 / 업로드 실패: intent_status에 명확한 텍스트 안내 표시 (예: "Base64 파싱 실패", "API 호출 시간 초과"), 충돌하지 않음.
8, 출력 요구 사항
완전히 실행 가능한 코드, LLM_API_KEY와 NANOBANANA_API_KEY만 교체하면 직접 실행 가능, 전체 프로세스 사용 가능, 분기 로직이 실전 버전과 엄격히 일치함.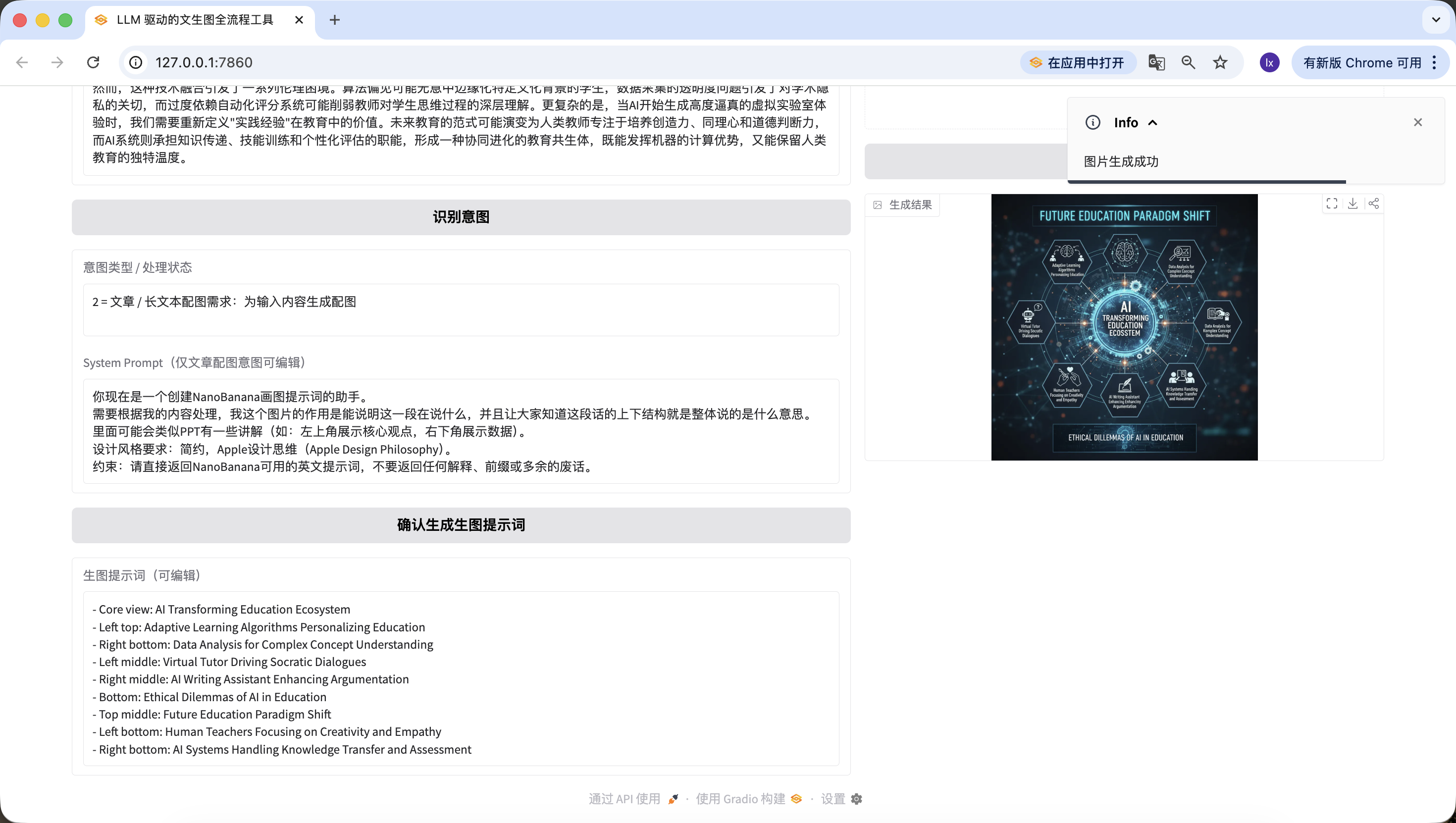
정말 신나네요! 우리는 드디어 이 Agent의 첫 번째 이미지를 성공적으로 생성했습니다. 생성된 이미지를 자세히 보면, 우리의 텍스트와 프롬프트와 일치합니다. 여기까지 여러분은 이미 자신만의 Agent를 기본적으로 구현했습니다!

우리는 이미지에서 이미지 기능도 추가하여, 좋아하는 이미지를 업로드하면 AI가 자동으로 스타일을 참고합니다.
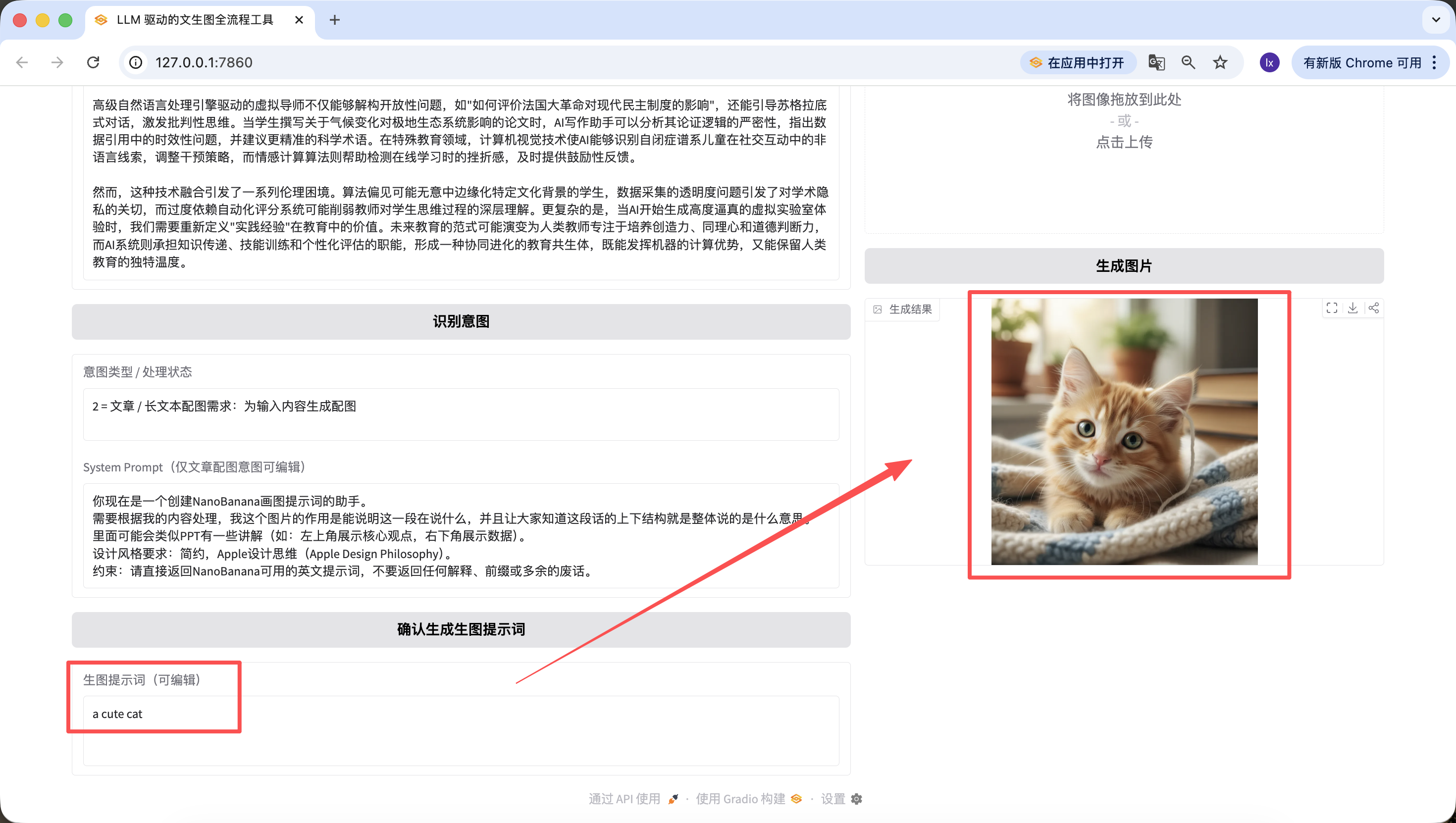
언급할 만한 점은, 이전 단계에서 생성된 프롬프트도 웹 페이지에서 편집할 수 있으며, 우리는 최종적으로 버튼을 클릭할 때의 프롬프트를 기준으로 합니다~ 여기서 "a cute cat"으로 바꾸더라도, 최종적으로 생성되는 이미지는 귀여운 고양이가 됩니다.
제4장: 요약

드디어 끝났네요! 솔직히 말하면, 저 자신도 마지막 줄을 쓰고 나서 긴 한숨을 쉬었는데, 여기까지 따라오신 여러분은 오죽하겠습니까. 이 전체 프로세스를 완전히 실행해 낸 것 자체가 이미 대단한 일입니다. 이는 여러분이 정말로 키보드에 손을 올리고, 일을 단계별로 완료했다는 것을 의미합니다. Bravo 🎉 🥳 👏
이 콘텐츠를 작성하는 동안, 저는 계속 생각했습니다: 우리는 결국 무엇을 남겨야 하는가? 답은 사실 모델 이름, 파라미터, 또는 어떤 고정된 방법이 아니라, 여러분이 점차 하나의 감각을 구축하도록 하는 것입니다: 어떤 일은 AI에게 이해하고 계획하도록 안심하고 맡길 수 있고, 어떤 부분은 여러분이 방향만 결정하면 된다는 것입니다. 이러한 분업이 성립되면, 원래 복잡해 보이던 많은 생성 프로세스들이 순조로워지기 시작할 것입니다.
돌이켜 보면, 이 길은 사실 복잡하지 않습니다. 해결하고자 하는 문제를 명확히 생각하고, 긴 텍스트를 언어 모델에 전달하여 분해시킨 다음, 정리된 시각적 의도를 이미지 생성 모델에 전달하여 표현하게 하고, 마지막으로 이 전체 프로세스를 나만의 작은 어시스턴트로 캡슐화합니다. 여기까지 왔을 때, 여러분은 더 이상 "모델을 사용하는" 것이 아니라, 장기적으로 함께 작업할 수 있는 시스템을 구축하고 있는 것입니다. 그리고 이것이 바로 이 튜토리얼이 여러분에게 전달하고자 하는 핵심입니다.
하지만 여러분은 이미 정말 훌륭하게 해냈어요! 여기까지 배운 여러분은 Vibe Coding에 대해 이미 초기 단계의 이해를 갖추었습니다. 잠시 휴식을 취하세요!