
Part B: CEM-MPC and Latent Actor-Critic
Given a world model, how does an agent use it to select actions? This section is the direct prerequisite for P03 and P04. It introduces three planning mechanisms: from the most intuitive random search, to Dreamer's imagination-based training, to TD-MPC's hybrid approach.
MuZero and the Counterfactual Paradigm
There is a class of tasks that takes counterfactual reasoning to the extreme: the counterfactual paradigm, which forgoes pixel prediction entirely and instead makes accurate predictions only at the abstract level of values or rewards. MuZero (Nature, 2020) decomposes the world model into three functions:
- Representation function
: compresses past observations into an internal hidden state - Dynamics function
: given the previous hidden state and a candidate action, predicts the immediate reward and the next hidden state: - Prediction function
: predicts a policy prior and value from the hidden state:
The three functions are trained jointly end-to-end, with the total loss:
Symbol definitions:
MuZero maintains three prediction heads:
| Prediction head | Prediction target | Role |
|---|---|---|
| reward head | immediate reward | evaluates the quality of the current step |
| value head | future cumulative value | guides MCTS search direction |
| policy prior | action probability distribution | reduces the number of branches MCTS needs to explore |
All three heads are trained jointly through the unrolled dynamics function on real interaction data.
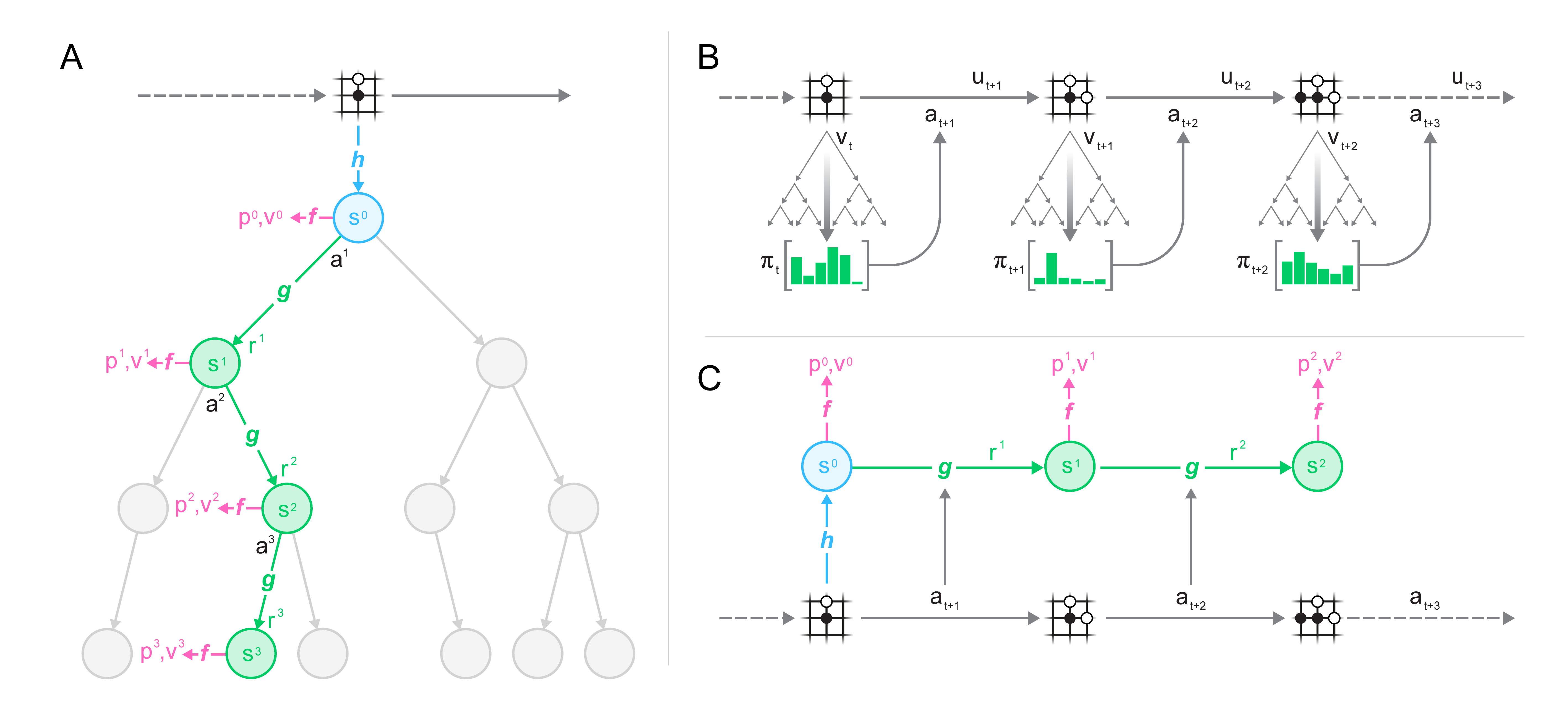
As long as these three prediction heads are accurate, the exact form of the latent state
📖 MCTS (Monte Carlo Tree Search): Starting from the current state, repeatedly perform four steps: (1) Select: traverse down the tree, selecting the node with the highest UCB score (Upper Confidence Bound,
, where is the average value of that action, is the total visit count of the parent node, is the visit count of that action, and is the exploration coefficient; UCB balances "choosing known good actions" with "exploring less-visited actions"); (2) Expand: try a new action at a leaf node; (3) Simulate/Evaluate: use the neural network to estimate the value of the new node (MuZero uses the value head directly, without rollout); (4) Backpropagate: update the value estimate upward along the path. After hundreds of repetitions, the most-visited action is the one "deemed optimal after sufficient search." MuZero's key extension over AlphaZero: support for single-agent domains (not just two-player games) and intermediate step rewards (Atari), with value targets constructed via -step bootstrapping rather than terminal win/loss.
Mechanism 1: CEM Shooting-Method MPC
📖 CEM (Cross-Entropy Method): A sampling-based optimization algorithm. The core idea: sample a large number of candidate solutions from a distribution (e.g., Gaussian), evaluate the objective value of each candidate, retain the best fraction (elite samples), refit the distribution using these elite samples (update the mean and variance), and repeat. With each iteration, the sampling distribution narrows and concentrates toward high-quality regions. Here it is used to search for optimal action sequences in the action sequence space, hence the name "shooting method."
📖 MPC (Model Predictive Control): At each time step, use the model to predict
steps into the future ( is called the planning horizon), select the optimal action sequence, execute only the first action, then re-plan at the next step. Even if the model is imperfect, frequent re-planning corrects errors promptly, preventing them from accumulating indefinitely.
In one sentence: randomly sample a batch of action sequences, "imagine" executing them in the model, select the sequence with the highest expected return, execute only the first step, and repeat.
Algorithm steps:
CEM-MPC Planning Loop (executed once per step)
Input: current state s_t, world model f, reward model r, planning steps H, refinement rounds K
1. Initialize action distribution: μ ← 0, σ ← 1
2. FOR k = 1 to K (refinement rounds):
a. Sample N action sequences from N(μ, σ²): {a^(i)_{t:t+H}}
b. FOR each sequence i:
Roll out imagined trajectory: s^(i)_{t+1} = f(s_t, a^(i)_t), ..., s^(i)_{t+H}
Compute cumulative reward: R^(i) = Σ_{h=0}^{H-1} γ^h · r(s^(i)_{t+h}, a^(i)_{t+h})
# γ (gamma) is the discount factor, 0 < γ < 1, causing future rewards to decay exponentially
# γ=0.99 means a reward 100 steps away is still worth 0.99^100 ≈ 0.37 of its face value
c. Select Top-K sequences (sorted by R^(i) descending)
d. Refit using Top-K sequences: μ ← mean(Top-K), σ ← std(Top-K)
3. Execute the first action from μ: a_t ← μ[0]The first round of sampling covers a broad range with low precision, identifying roughly "where the high-return regions are." Subsequent rounds refit the distribution using elite sequences, progressively narrowing the sampling range toward high-return regions.
Limitation: in high-dimensional continuous action spaces (e.g., a robotic arm controlling 7 joints simultaneously), random search is extremely inefficient. This is the core problem TD-MPC addresses: guiding the search with a Q-function rather than sampling blindly.
Advantages: simple, gradient-free, easy to implement, with no differentiability requirements on the world model.
Mechanism 2: Actor-Critic in Latent Space (Dreamer's Approach)
📖 Actor-Critic architecture: consists of two networks. The Actor (policy network
) handles "decision-making," and the Critic (value network ) handles "evaluation." The baseline provided by the Critic greatly reduces the variance of gradient estimates, making training more stable.
Dreamer's core insight: rather than collecting large amounts of data in the real environment to train a policy, train inside the imagined trajectories of the world model, which is faster, risk-free, and differentiable.
Training procedure:
- Imagination rollout: starting from the current latent state
, sample actions with the Actor and use RSSM to roll forward steps - Critic evaluation: compute
for each imagined state, constructing training targets with -return - Actor optimization: the Actor maximizes the cumulative value predicted by the Critic via backpropagation through the entire imagined trajectory
- World model update: update the RSSM and encoder using real environment data (reconstruction loss + KL)
Intuition behind
Why differentiability matters: the Actor's gradients flow directly through the differentiable dynamics of the RSSM, which is far more accurate than estimating policy gradients via Monte Carlo sampling.
Model exploitation problem: the policy may discover actions that yield high rewards inside the model but are invalid in the real world, such as high-frequency jitter actions that score highly in the world model but would only damage motors on a real robot. The Dreamer series addresses this by periodically updating the world model with real environment data and limiting the number of imagination rollout steps, but the problem has not been fundamentally solved.
CEM is inefficient in high-dimensional action spaces, and Actor-Critic carries model exploitation risk. TD-MPC's core value is combining both approaches to mitigate these two problems at the same time.