
Part B:CEM-MPC 与潜在 Actor-Critic
有了世界模型,智能体如何用它来选择动作?这一部分是 P03 和 P04 的直接前置,介绍三种规划机制:从最直觉的随机搜索,到 Dreamer 的想象训练,再到 TD-MPC 的混合方案。
MuZero 与反事实型范式
还有一类任务把反事实推理做到极致:反事实型范式,不预测像素,只在抽象的价值或奖励层面做出正确预测。MuZero(Nature, 2020)把世界模型分解为三个函数:
- 表示函数
:把过去观测 压缩为内部隐状态 - 动力学函数
:给定上一步隐状态和候选动作,预测即时奖励和新隐状态: - 预测函数
:从隐状态预测策略先验和价值:
三个函数端到端联合训练,总损失为:
各符号含义:
MuZero 维护三个预测头:
| 预测头 | 预测目标 | 作用 |
|---|---|---|
| reward head | 即时奖励 | 评估当前步的好坏 |
| value head | 未来累计价值 | 引导 MCTS 搜索方向 |
| policy prior | 动作概率分布 | 减少 MCTS 需要搜索的分支数 |
三个预测头通过展开的动力学函数在真实交互数据上联合训练。
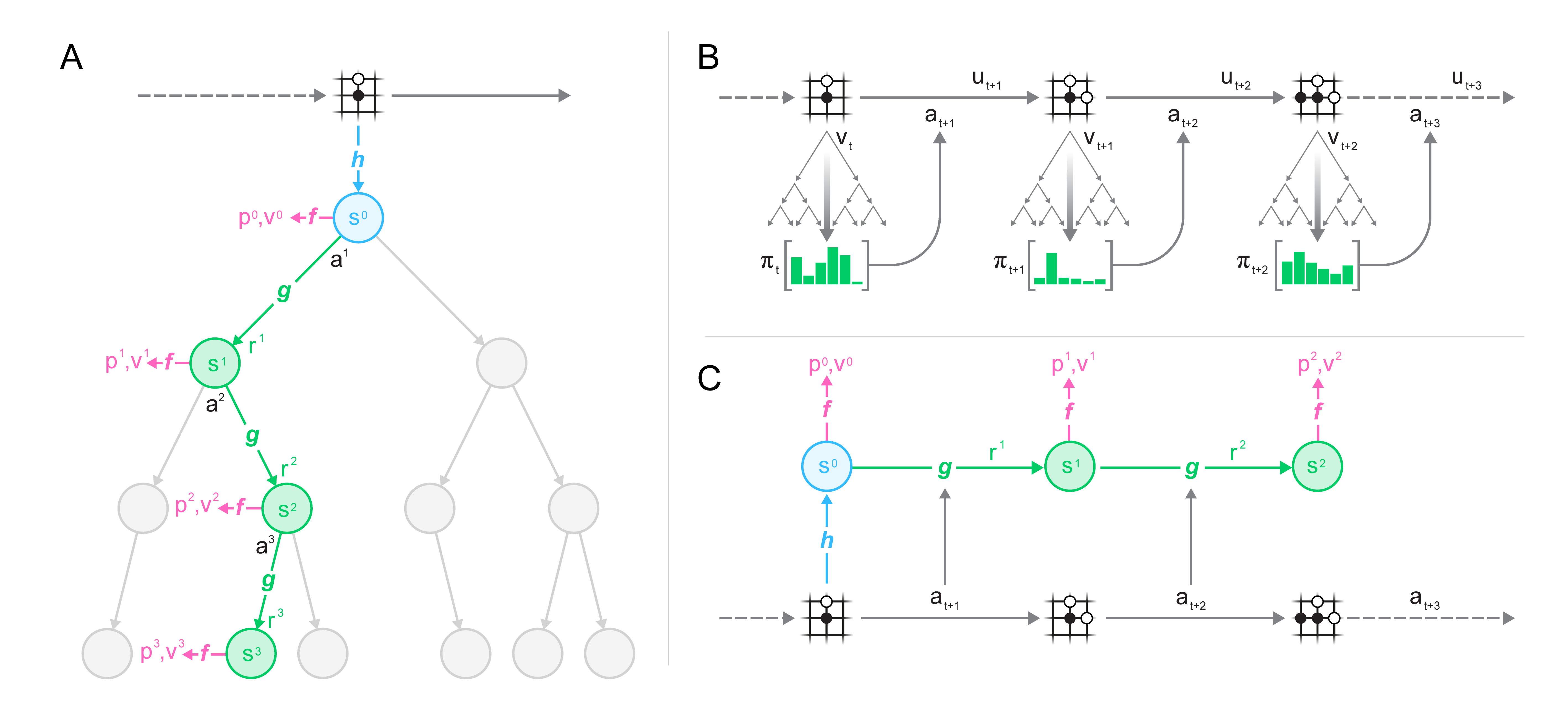
只要这三个预测头准确,潜在状态
📖 MCTS(Monte Carlo Tree Search,蒙特卡洛树搜索):从当前状态出发,反复进行四个步骤:①选择:沿树向下,选择 UCB 分数(Upper Confidence Bound,置信上界,
,其中 是该动作的平均价值, 是父节点总访问次数, 是该动作被访问次数, 是探索系数;UCB 平衡"选已知好的动作"和"探索访问少的动作")最高的节点;②扩展:在叶节点尝试一个新动作;③模拟/评估:用神经网络估计新节点的价值(MuZero 直接用 value head,无需 rollout);④反向传播:将价值估计沿路径向上更新。重复数百次后,访问次数最多的动作就是"经过充分搜索认为最优的动作"。MuZero 对 AlphaZero 的关键扩展:支持单智能体域(非双人博弈)和中间步骤奖励(Atari),价值目标用 步自举而非终局胜负。
机制一:CEM 射击法 MPC
📖 CEM(Cross-Entropy Method,交叉熵方法):一种基于采样的优化算法。核心思路:先从一个分布(如高斯)中采样大量候选解,计算每个候选解的目标值,保留最优的一小部分(精英样本),用这些精英样本重新拟合分布(更新均值和方差),反复迭代。每轮迭代后,采样分布逐渐收窄,向高质量区域集中。这里用它在动作序列空间中搜索最优动作,故称"射击法"(shooting method)。
📖 MPC(Model Predictive Control,模型预测控制):在每个时间步,用模型向前预测未来
步( 称为规划时域,planning horizon),选出最优的动作序列,只执行第一个动作,然后在下一步重新规划。即使模型不完美,频繁重规划可以及时纠正误差,不会让错误无限累积。
一句话描述:随机采样一批动作序列,在模型中"想象"执行,选出预期回报最高的序列,只执行第一步,然后重复。
算法步骤:
CEM-MPC 规划循环(每步执行一次)
输入:当前状态 s_t,世界模型 f,奖励模型 r,规划步数 H,精化轮数 K
1. 初始化动作分布:μ ← 0, σ ← 1
2. FOR k = 1 to K(精化轮):
a. 从 N(μ, σ²) 采样 N 条动作序列:{a^(i)_{t:t+H}}
b. FOR 每条序列 i:
展开想象轨迹:s^(i)_{t+1} = f(s_t, a^(i)_t), ..., s^(i)_{t+H}
计算累计奖励:R^(i) = Σ_{h=0}^{H-1} γ^h · r(s^(i)_{t+h}, a^(i)_{t+h})
# γ(gamma)是折扣因子,0 < γ < 1,使未来奖励的权重随步数指数衰减
# γ=0.99 表示 100 步后的奖励仍值当前的 0.99^100 ≈ 0.37 倍
c. 选出 Top-K 条序列(按 R^(i) 降序)
d. 用 Top-K 序列重新拟合:μ ← mean(Top-K), σ ← std(Top-K)
3. 执行 μ 的第一个动作:a_t ← μ[0]第一轮采样覆盖范围广但精度低,找到"高回报区域大概在哪里";后续几轮用精英序列重新拟合分布,让采样范围逐渐向高回报区域收缩。
局限:在高维连续动作空间(如机械臂同时控制 7 个关节)随机搜索效率极低。这是 TD-MPC 要解决的核心问题:用 Q 函数引导搜索,而不是盲目采样。
优点:简单、无梯度、易于实现,对世界模型的可微分性没有要求。
机制二:潜在空间中的 Actor-Critic(Dreamer 的做法)
📖 Actor-Critic 架构:由两个网络组成,Actor(策略网络
)负责"决策",Critic(价值网络 )负责"评估"。Critic 提供的基准(baseline)大幅降低了梯度估计的方差,使训练更稳定。
Dreamer 的核心洞察:与其在真实环境里收集大量数据训练策略,不如在世界模型的想象轨迹中训练,速度快、无风险、可微分。
训练流程:
- 想象展开:从当前潜在状态
出发,用 Actor 采样动作,RSSM 滚动预测 步 - Critic 估值:对每个想象状态计算
,用 -return 构造训练目标 - Actor 优化:Actor 通过反向传播(跨越整条想象轨迹)最大化 Critic 预测的累计价值
- 世界模型更新:用真实环境数据(重建损失 + KL)更新 RSSM 和编码器
λ-return 的直觉:纯蒙特卡洛需要等 episode 结束才能得到真实回报,方差高;纯 TD 只看一步,偏差大。λ-return 是两者的插值,用"前
为什么可微分很重要:Actor 的梯度直接从 RSSM 的可微分动力学中流过,比蒙特卡洛采样估计策略梯度精确得多。
模型漏洞(Model Exploitation)问题:Policy 可能找到模型里高奖励但真实世界不成立的动作,用高频抖动动作在世界模型里获得高分,但这个动作在真机上只会损坏电机。Dreamer 系列的解决思路是定期用真实环境数据更新世界模型,同时限制想象展开的步数,但这个问题并没有被根本解决。
CEM 在高维动作空间效率低,Actor-Critic 有模型漏洞风险;TD-MPC 的核心价值,正是把两者结合起来同时缓解这两个问题。