
Metrics Specific to STORM (Transformer Dynamics)
STORM (Transformer Dynamics) [See L03 Further Reading [1]]
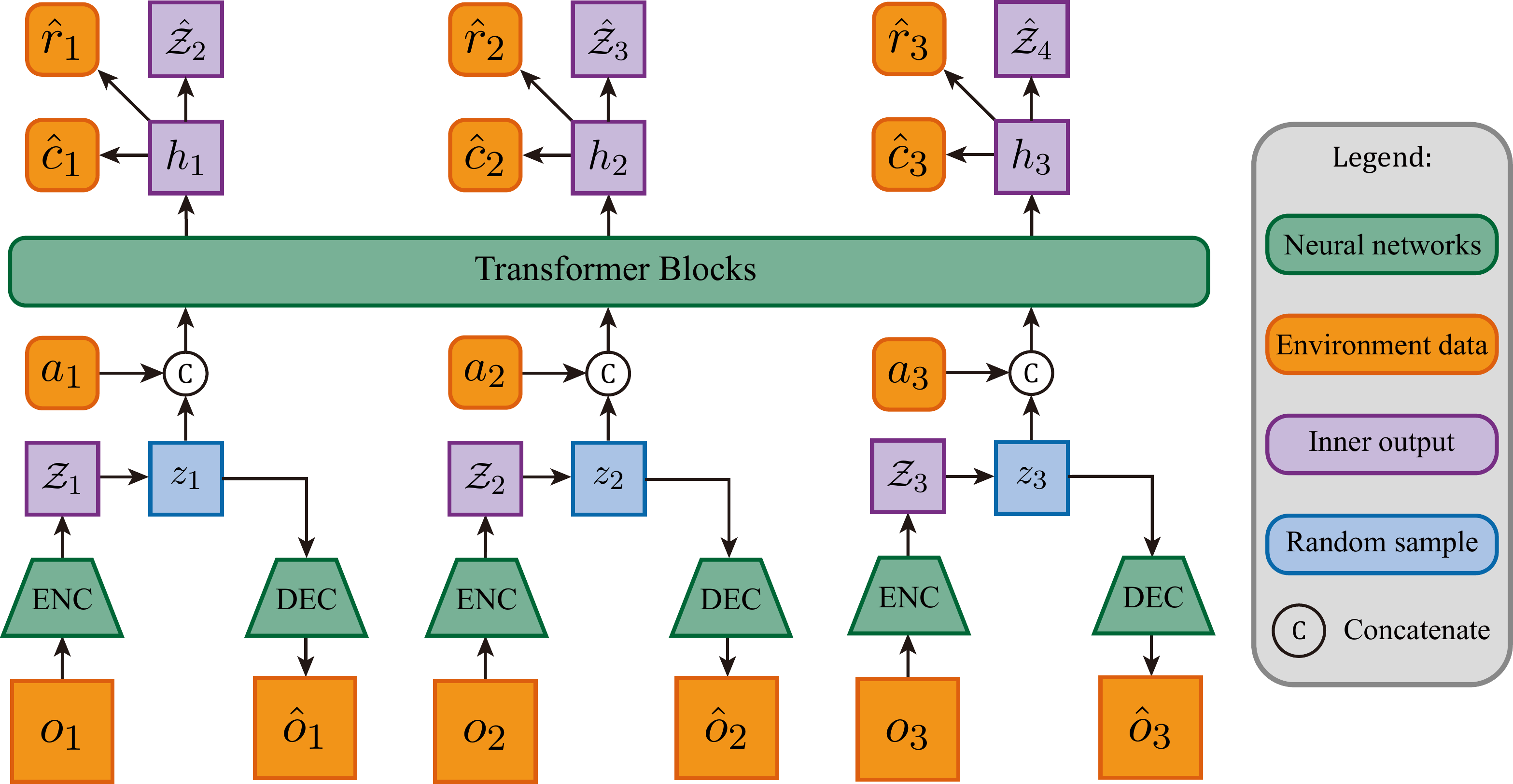
P05 asks you to replace the GRU in RSSM with a Transformer, implementing a STORM-style dynamics model.
The core idea of STORM is to replace the recurrent state in RSSM with Transformer self-attention sequence modeling: historical frames are encoded as a token sequence, actions are appended as additional tokens, and the Transformer processes the sequence with a causal mask (in self-attention, the causal mask sets the attention scores for all positions after the current one to
Evaluating STORM requires distinguishing two entirely different timescales: per-frame accuracy (whether each step's token prediction is correct) and sequential dynamics quality (whether the motion trajectory of the entire video segment is coherent). The two categories of problems are covered by different metrics.
Token Prediction Loss
This is STORM's training objective and the most direct online monitoring metric. During stable training, this loss should decrease monotonically. There are two types of anomalous behavior:
- The loss curve stalls at a plateau for more than 5k steps mid-training: usually caused by a learning rate that is too large, or a context window length exceeding the sequence length used during training, causing attention weights to break down.
- Loss is low on short sequences but high on long sequences: an early signal of excessive teacher forcing gap (see below).
Diagnostic rule: compute token prediction loss separately using a sliding window (e.g., window length 20 steps vs. 50 steps). If the gap between the two keeps widening, the model's predictive ability degrades significantly under longer contexts, and you should shorten the training sequence length or introduce relative positional encoding (a way of encoding position information in a Transformer: absolute positional encoding assigns a fixed encoding to each position, causing poor generalization to sequences longer than the training length; relative positional encoding encodes only the relative distance between two tokens, giving better extrapolation to sequences beyond the training length).
Long-Horizon PSNR
Peak Signal-to-Noise Ratio (PSNR) measures the pixel-level alignment between generated frames and ground-truth frames:
where MAX is the maximum pixel value (typically 255 or 1.0) and MSE is the mean squared error between the generated frame and the ground-truth frame. Higher values are better; the typical range is 20-40 dB, and values below 20 dB generally indicate generation quality that is visibly degraded to the human eye.
Why "long-horizon" matters: under teacher forcing training, the model always receives ground-truth historical frames as input during training, but must use its own previous predictions as input during inference. This distribution gap between training and inference accumulates with each step, causing PSNR to decrease systematically as the rollout step count grows rather than fluctuating randomly. Evaluating STORM should involve plotting PSNR as a function of rollout step count, not just reporting the single-step average.
Diagnostic rule: if PSNR drops sharply by more than 5 dB within the first 10 steps, the teacher forcing gap is the primary cause. Consider trying scheduled sampling (during training, randomly replace ground-truth frames with generated frames as historical input, gradually increasing the replacement ratio so the model adapts to the autoregressive mode used at inference time; see the RWM section in L03) or self-forcing training.
📖 Teacher Forcing (definition in the Transformer architecture section of L03): during training the model always receives ground-truth historical frames as input, but at inference time it must use its own predicted frames as input, producing a distribution gap between training and inference. This is the most common source of error accumulation in autoregressive world models.
FVD (Fréchet Video Distance)
FVD extends the idea of FID to video sequences: a pretrained I3D network (a 3D convolutional network trained on video action recognition) is used to extract spatiotemporal features from video clips, and the Fréchet distance between the feature distributions of real and generated videos is computed. Lower values are better.
The formula has the same form as FID; the difference is that the feature extractor is replaced with I3D, and the feature vectors encode the overall dynamics of a video clip rather than the visual quality of a single frame. FVD is more sensitive to motion patterns and the coherence of object trajectories, making it the standard metric for evaluating sequential quality in world models.
Division of labor: use PSNR for debugging (fast, pixel-level, suited for monitoring during training); use FVD for policy evaluation and paper reporting (captures sequential dynamics quality and correlates better with human perceptual judgment). Both are necessary: high PSNR but poor FVD means per-frame pixel alignment is acceptable but the overall motion trajectory is incoherent; good FVD but low PSNR means the model has learned reasonable dynamic patterns but per-frame generation is noisy.
Further Reading
- Zhang et al. (2023): STORM: Transformer dynamics world model, efficient training under 100k interactions
- Carreira & Zisserman (2017): I3D: the video feature extraction backbone used by FVD