
STORM(Transformer 动力学)的专属指标
STORM(Transformer 动力学)[见 L03 延伸阅读 [1]]
P05 要求你把 RSSM 的 GRU 替换为 Transformer,实现 STORM 式的动力学模型。
STORM 的本质是把 RSSM 的循环状态替换为 Transformer 的自注意力序列建模:历史帧编码为 token 序列,动作作为额外 token 拼入,Transformer 以因果掩码(causal mask,在自注意力计算中,将当前位置之后的所有位置的注意力分数遮盖为
评估 STORM 时需要区分两个完全不同的时间尺度:逐帧精度(每一步的 token 预测是否准确)和序列动态质量(整段视频的运动轨迹是否合理)。两类问题用不同的指标覆盖。
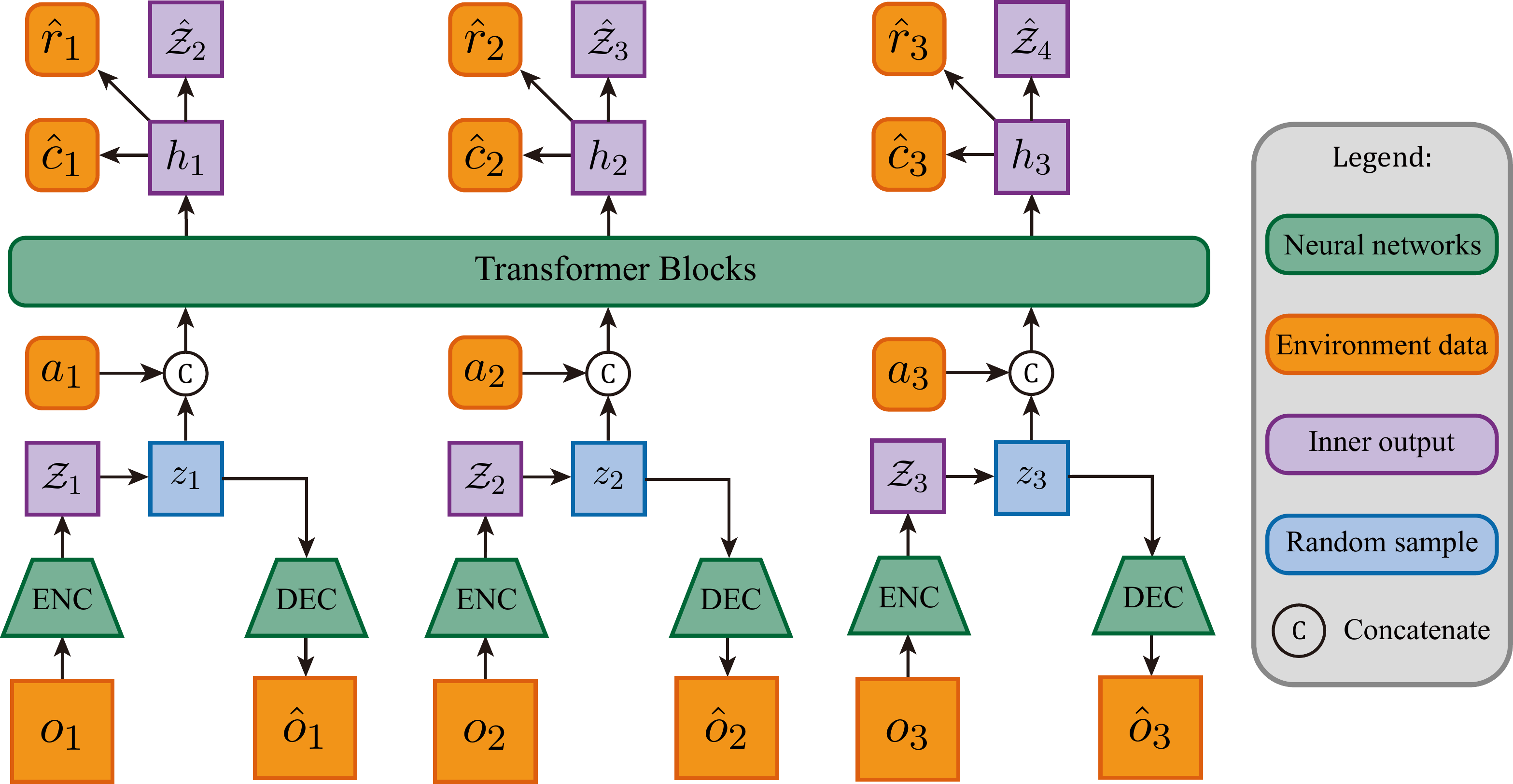
Token 预测损失
这是 STORM 的训练目标,也是最直接的在线监控指标。训练稳定时,该损失应单调下降。异常表现有两种:
- 损失曲线在中途平台期停滞超过 5k 步:通常是学习率过大,或上下文窗口长度超过训练时的序列长度,导致注意力权重失效。
- 损失在短序列上低、长序列上高:teacher forcing 差距过大的早期信号。
诊断规则:用滑动窗口(如窗口长度 20 步 vs 50 步)分别计算 token 预测损失,若两者差距持续扩大,说明模型在较长上下文下预测能力显著下降,需要缩短训练时的序列长度或引入相对位置编码(relative positional encoding,Transformer 中编码序列位置信息的方式:绝对位置编码给每个位置分配固定编码,导致模型对训练长度之外的序列泛化差;相对位置编码只编码两个 token 之间的相对距离,对超出训练长度的序列具有更好的外推能力)。
长时域 PSNR
**峰值信噪比(PSNR)**衡量生成帧与真实帧的像素级对齐程度:
其中 MAX 是像素最大值(通常为 255 或 1.0),MSE 是生成帧与真实帧的均方误差。数值越高越好,典型范围 20-40 dB;低于 20 dB 通常意味着生成质量已经对人眼可见。
为何要强调"长时域":在 teacher forcing 训练模式下,模型在训练时始终以真实历史帧作为输入,在推理时却要以自己上一步的预测输出作为输入。这个训练与推理的分布差距随步数积累,PSNR 会随展开步数增加而系统性下降,而非随机波动。对 STORM 的评估,应该画出 PSNR 随展开步数的曲线,而非只报告单步平均值。
诊断规则:若 PSNR 在前 10 步内急剧下降超过 5 dB,teacher forcing 差距是主因,可尝试 scheduled sampling(计划采样,训练时随机以生成帧替换真实帧作为历史输入,逐步增加替换比例,使模型逐渐适应推理时的自回归模式,详见 L03 RWM 一节)或 self-forcing 训练。
📖 Teacher Forcing(定义见 L03 Transformer 架构一节):训练时始终以真实历史帧作为输入,推理时却要以自身预测帧作为输入,产生训练与推理之间的分布差距,是自回归世界模型最常见的误差累积来源。
FVD(Fréchet Video Distance)
FVD 将 FID 的思路扩展到视频序列:用预训练的 I3D 网络(一种在视频动作识别任务上训练的 3D 卷积网络)提取视频片段的时空特征,计算真实视频与生成视频特征分布之间的 Fréchet 距离。数值越低越好。
与 FID 的公式形式相同,区别在于特征提取器换成了 I3D,特征向量编码的是视频片段的整体动态而非单帧的视觉质量。FVD 对运动模式、物体轨迹的连贯性更敏感,是评估世界模型序列质量的标准指标。
分工建议:用 PSNR 做调试(快速、像素级,适合训练过程监控);用 FVD 做策略评估和论文报告(捕捉序列动态质量,与人类感知判断更相关)。两者缺一不可:PSNR 高但 FVD 差,说明逐帧像素对齐还可以,但运动轨迹整体不连贯;FVD 好但 PSNR 低,说明模型学到了合理的动态模式,但逐帧生成有噪声。
延伸阅读
- Zhang et al. (2023): STORM:Transformer 动力学世界模型,100k 交互下的高效训练
- Carreira & Zisserman (2017): I3D:FVD 使用的视频特征提取骨干网络