第10章:搜索的艺术:在推理空间中巡航
MCTS 不知道围棋的规律。它知道的是:哪条路值得继续走下去。
一、2016年3月的第37手
2016年3月9日,首尔四季酒店。AlphaGo对阵李世石的第二局,进行到第37手。
AlphaGo在右上角下了一步五路肩冲。
解说室沉默了12秒。职业九段棋手看着棋盘,不敢相信自己的眼睛。这不是人类会下的棋——它违反了围棋的常规定式,看起来像是业余选手的失误。
但37手之后的棋局证明,这是制胜的关键。后来这一手被称为”上帝之手”。
AlphaGo是如何找到这步棋的?
不是通过”理解”围棋的美学,不是通过记忆棋谱,而是通过搜索——在数百万种可能的棋局中,找到那条通向胜利的路径。
这揭示了一个深刻的同构性:推理过程可以被视为在状态空间中的路径搜索。
每个状态是一个推理步骤(或棋局)
每个动作是一个逻辑推断(或落子)
目标是找到证明(或获胜)
从这个角度看,定理证明、数学推理、游戏对弈,本质上都是搜索问题。
二、搜索空间的诅咒
但搜索空间是指数级的。
围棋的状态空间约为
国际象棋的状态空间”只有”
暴力搜索不可行。我们需要聪明的搜索。
经典的搜索算法有两类:
深度优先搜索(DFS):沿着一条路走到底,走不通再回溯。优点是空间复杂度低,O(深度);缺点是可能陷入无限深的分支,找不到最优解。
广度优先搜索(BFS):逐层扩展,先探索所有深度为1的节点,再探索深度为2的节点。优点是保证找到最短路径;缺点是空间复杂度指数级,O(分支因子^深度)。
这两者都不够好。DFS太盲目,BFS太昂贵。
我们需要一种方法,既能探索未知区域,又能利用已知的好路径。
这就是蒙特卡洛树搜索(MCTS)。
三、MCTS:随机采样的智慧
MCTS的核心思想出奇地简单:用随机模拟来估计每个动作的价值,然后优先探索价值高的动作。
它有四个步骤,循环执行:
1. 选择(Selection):从根节点开始,用UCB公式选择最有潜力的子节点,直到到达叶节点。
2. 扩展(Expansion):如果叶节点不是终止状态,添加一个新的子节点。
3. 模拟(Simulation):从新节点开始,随机走到游戏结束,得到一个结果(胜/负/平)。
4. 回传(Backpropagation):把结果沿着路径向上传播,更新所有经过节点的统计信息。
重复这个循环N次(比如10000次),然后选择访问次数最多的动作。
为什么这样有效?
因为MCTS自动平衡了探索与利用:好的分支会被反复访问,统计信息越来越准确;差的分支访问次数少,不会浪费太多时间;未探索的分支有”探索奖励”,不会被完全忽略。
四、UCB公式:探索与利用的数学
MCTS的核心是UCB(Upper Confidence Bound)公式,用于选择下一个要探索的节点:
其中: -
第一项:
第二项:
当父节点被访问很多次(
这个公式有理论保证:Kocsis和Szepesvári在2006年证明,使用UCB的MCTS会以对数速度收敛到最优策略。
五、自己动手:用MCTS玩井字棋
让我们用一个简单的例子体验MCTS。
游戏:井字棋(3×3),X先手。
初始状态:空棋盘
. . .
. . .
. . .
步骤1:第一次模拟
从根节点(空棋盘)开始,随机选一个动作,比如X下在中心:
. . .
. X .
. . .
然后O随机下,X随机下,直到游戏结束。假设X赢了。
回传:根节点的统计变为(胜=1, 访问=1)。
步骤2:第二次模拟
再次从根节点开始。这次可能选择不同的第一步,比如X下在角落:
X . .
. . .
. . .
随机走到结束,假设平局。
回传:根节点的统计变为(胜=1, 访问=2)。
步骤3:重复1000次
经过1000次模拟,根节点的9个子节点(对应9个可能的第一步)有不同的统计:
| 位置 | 访问次数 | 胜率 |
|---|---|---|
| 中心 | 342 | 0.68 |
| 角落 | 278 | 0.65 |
| 边缘 | 156 | 0.52 |
| … | … | … |
选择访问次数最多的”中心”作为最佳第一步。
观察: - 中心位置被访问最多,因为它的胜率高,UCB分数高 - 边缘位置被访问较少,因为早期模拟显示胜率低 - 即使是差的位置也被访问了一些次数,保证不会遗漏
问题:如果只模拟100次,决策会改变吗?模拟次数和决策质量的关系是什么?
六、从搜索到直觉:ADS的熵正则化
MCTS很强大,但有一个问题:太慢。
每一步决策都需要运行数千次模拟。AlphaGo每步棋需要约0.1秒,对人类来说很快,但对实时系统(如自动驾驶)来说太慢了。
更深层的问题是:搜索的时间复杂度是
[Zixi Li, 2026a]的ADS工作提出了一个激进的想法:不是学习MCTS的搜索轨迹,而是用熵正则化重塑LLM的推理空间,将扩散的搜索树坍缩为低熵流形。
这不是传统的知识蒸馏,而是拓扑重塑:
核心机制:动态对数障碍
当模型的输出熵
效果: - 高熵分支(不确定的推理路径)在优化中变得不可达 - 搜索被强制沿着低熵(高置信度)路径前进 - 这不是剪枝,而是改变了可达状态的几何结构
与MCTS的对比: - MCTS是显式搜索:构建树,模拟,回传——每次都重新计算 - ADS是隐式剪枝:用熵障碍排斥高不确定性状态——推理空间被预先压缩
关键洞察:搜索不需要”固化为权重”,而是通过动态约束实时重塑。每一步推理,熵障碍都在调整可达状态的边界。
AlphaGo Zero用神经网络学习MCTS的策略分布。ADS则用熵正则化直接约束LLM的输出空间——不需要教师模型,不需要蒸馏,只需要一个对数障碍函数。
七、伪代码:MCTS与ADS
算法1:MCTS主循环
import math
import random
class MCTSNode:
def __init__(self, state, parent=None):
self.state = state
self.parent = parent
self.children = {} # action -> MCTSNode
self.visits = 0
self.value = 0.0
def is_fully_expanded(self, actions):
return all(a in self.children for a in actions)
def ucb_select(node, actions, c=math.sqrt(2)):
# 选择 UCB 分数最高的子节点
best, best_score = None, -float("inf")
for a, child in node.children.items():
exploit = child.value / child.visits
explore = c * math.sqrt(math.log(node.visits) / child.visits)
score = exploit + explore
if score > best_score:
best_score, best = score, child
return best
def mcts(root_state, get_actions, transition, rollout, N=1000):
# get_actions(s) -> list of actions
# transition(s, a) -> next_state
# rollout(s) -> reward
root = MCTSNode(root_state)
for _ in range(N):
node = root
# 选择
actions = get_actions(node.state)
while node.is_fully_expanded(actions) and node.children:
node = ucb_select(node, actions)
actions = get_actions(node.state)
# 扩展
unexplored = [a for a in actions if a not in node.children]
if unexplored:
a = random.choice(unexplored)
s_new = transition(node.state, a)
child = MCTSNode(s_new, parent=node)
node.children[a] = child
node = child
# 模拟
reward = rollout(node.state)
# 回传
while node is not None:
node.visits += 1
node.value += reward
node = node.parent
# 返回访问次数最多的动作
return max(root.children, key=lambda a: root.children[a].visits)算法2:UCB选择(已内嵌于 ucb_select 函数,见上)
算法3:ADS熵正则化
import torch
import torch.nn.functional as F
def ads_entropy_regularization(model, input_ids, tokenizer, max_steps=20, threshold=0.5):
# model: 语言模型(支持 logits 输出)
# input_ids: 初始 token 序列
# 返回: 生成的 token id 列表
generated = list(input_ids)
vocab_size = model.config.vocab_size
for t in range(max_steps):
with torch.no_grad():
logits = model(torch.tensor([generated])).logits[0, -1] # (vocab_size,)
p_t = F.softmax(logits, dim=-1)
H_t = -(p_t * torch.log(p_t + 1e-10)).sum().item() # 当前熵
H_max = math.log(vocab_size) # 最大熵(均匀分布)
# 动态对数势垒:熵越接近最大值,α_t 越大,惩罚越强
alpha_t = -math.log(1 - H_t / H_max + 1e-10)
# 熵足够低时停止(模型已收敛到低熵 token)
if H_t < threshold:
break
next_token = p_t.argmax().item() # 贪心解码
generated.append(next_token)
# α_t → ∞ 当 H_t → H_max:高熵状态被势垒排斥,搜索坍缩到低熵流形
return generated八、可视化:搜索树的不对称生长
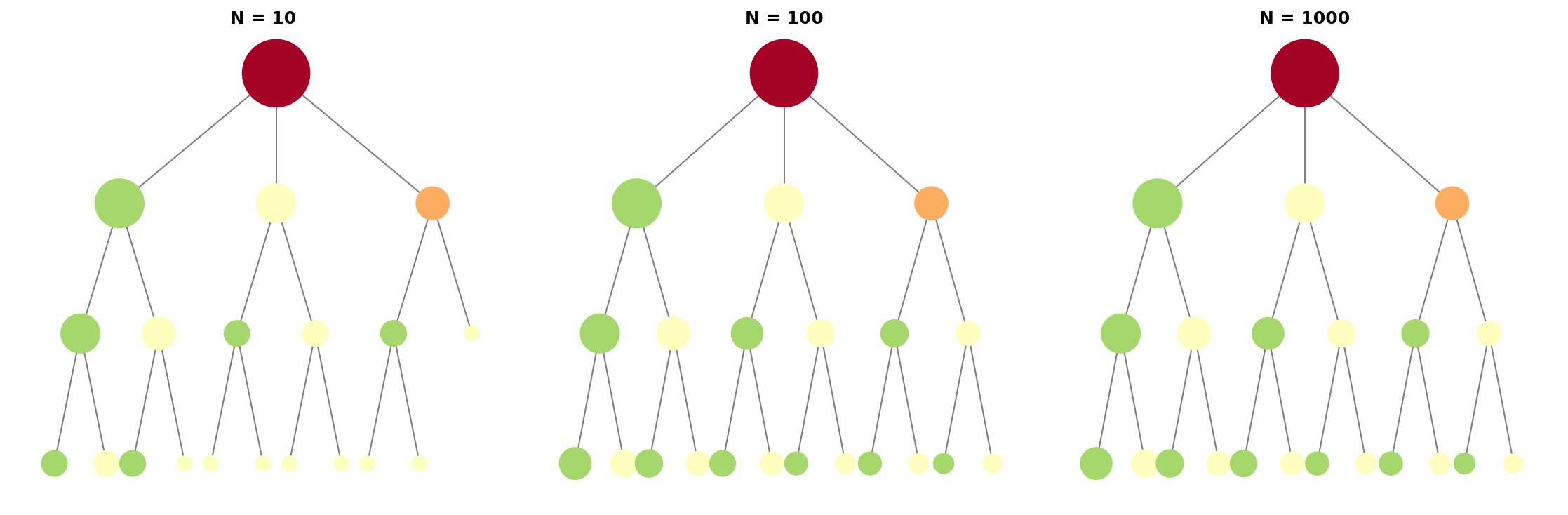
图10.1展示了MCTS搜索树在不同模拟次数下的形态演化。三个子图从左到右分别对应N=10、100、1000次模拟:
左图(N=10):树几乎对称,每个分支的访问次数相近(节点大小相似)。此时探索不足,UCB尚未区分出好坏路径。
中图(N=100):开始出现不对称性。好的分支(绿色节点,胜率高)被优先探索,节点明显变大。差的分支(红色节点)访问次数减少。
右图(N=1000):高度不对称。最优路径被反复访问(最大的绿色节点),次优路径适度探索,差路径几乎被放弃(小红色节点)。
关键观察:节点大小正比于访问次数,颜色表示平均胜率(绿=高,红=低)。这种不对称生长正是UCB算法的核心——用有限的模拟预算集中探索最有希望的路径。
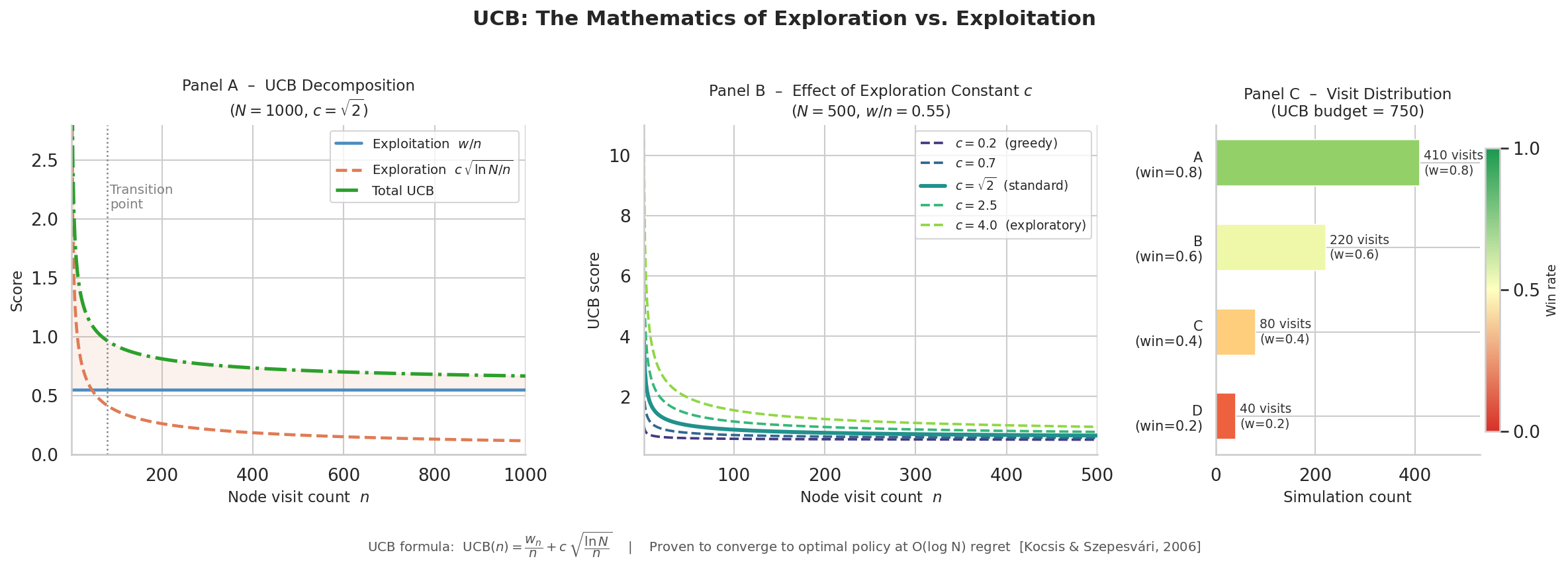
图10.2展示了UCB公式中探索项和利用项随节点访问次数的变化:
蓝色曲线(利用项):平均胜率随访问次数收敛到真实值(~0.7)。早期波动大,后期稳定。
红色曲线(探索项):
随访问次数衰减。访问越多,探索奖励越小。 绿色虚线(总UCB):两项之和。早期探索项主导(红色高),后期利用项主导(蓝色稳定)。
转换点在n≈30:此时探索项和利用项贡献相当。之前是”大胆尝试”,之后是”精准利用”。这个平衡点由常数
九、大语言模型的搜索:从思维链到强化学习
2022年之后,搜索问题有了一个新维度:语言模型本身就是一个状态空间。每一个推理步骤不再是棋盘上的落子,而是一段文字——数学推导、逻辑分析、代码行。
这产生了一个深刻的问题:如何让LLM在语言推理空间中做有效的搜索?
MCTS的答案是:构建树,模拟,回传。但对于语言模型,"模拟一次"就意味着运行整个前向传播,计算代价极高。而且语言推理空间是连续的,分支因子无限大——你不能穷举"下一句话"的所有可能。
两条不同的技术路线,给出了两种截然不同的答案。
9.1 GPT-o1:过程打分模型与策略蒸馏
2024年9月,OpenAI发布了o1系列模型。其核心创新不在于模型架构,而在于搜索策略。
o1的技术路线可以概括为三层架构:
第一层:过程奖励模型(Process Reward Model, PRM)
传统强化学习的奖励是在终点给出的——答案对了+1,答案错了-1。但在推理任务中,这太稀疏了:一道需要20步推导的数学题,只有第20步才能判断对错。
PRM的想法是:对每一个中间步骤打分。给定推理链中的第
这相当于把稀疏终端奖励转化为稠密过程奖励,让搜索可以在每一步获得反馈。
第二层:策略模型在树搜索中的引导
有了PRM之后,o1用策略模型(一个经过微调的语言模型)在推理步骤空间中执行类MCTS搜索:
- 选择:用策略模型生成
个候选推理步骤 - 评估:PRM对每个候选步骤打分
- 扩展:选择分数最高的步骤继续展开
- 回传:将最终结果反向更新PRM和策略模型
这是第一次将树搜索与语言模型推理系统性地结合起来。思维链(CoT)不再是单条线性推导,而是一棵在推理空间中生长的搜索树。
第三层:知识蒸馏压缩搜索
搜索很好,但很慢。o1在推理时实际运行的是一个经过蒸馏的策略模型——它在训练时见过大量树搜索生成的高质量推理轨迹,学会了"在内部"模拟搜索过程,而不需要在推理时显式建树。
这类似于人类棋手:新手需要计算所有变化,高手看一眼就知道最优着法——因为高手已经将搜索"内化"为直觉。
这是思维链的历史性时刻:CoT不再只是一个提升准确率的技巧,而是成为了语言模型在推理空间中进行系统性搜索的基础设施。
9.2 DeepSeek-R1:干掉PRM,组内竞争强化学习
2025年初,DeepSeek发布了R1模型,技术路线与o1形成鲜明对比:完全不使用PRM。
o1的路线有一个根本性的瓶颈:PRM是怎么训练的?
要训练PRM,你需要人工对每一个中间推理步骤标注"对/错"。这是极其昂贵的数据工程——一道题需要20步推导,每步都要标注,数据成本是终端标注的20倍。
而且更深的问题是:谁来判断中间步骤对不对? 有些推理路径看起来"走错了",最终却给出正确答案;有些路径看起来"走对了",却在最后一步失败。中间步骤的正确性依赖于结局,但PRM需要在不知道结局的情况下打分。这是一个本质性的困难。
DeepSeek-R1的解决方案是组内相对策略优化(Group Relative Policy Optimization, GRPO):
核心思想:不需要绝对打分,只需要相对排名
对于同一个问题,让模型生成
只在终点判断对错:
然后计算组内相对优势——哪些轨迹比这一组的平均水平更好?
用这个相对优势更新策略:
这个设计的深刻之处:
- 无需PRM:奖励信号只来自终端的对/错判断,彻底消除了中间步骤标注的需求
- 组内竞争:同组轨迹之间形成竞争关系——"比平均水平更好的"获得正向梯度,"比平均水平更差的"获得负向梯度
- 涌现搜索:模型在训练中自发学会了"自我验证"——生成多条推理路径,在内部对比,保留更好的那条
这是强化学习的一次深刻创新:把明确的过程监督(PRM)替换为隐式的组内竞争压力。
9.3 两条路线的哲学对比
| 维度 | GPT-o1 路线 | DeepSeek-R1 路线 |
|---|---|---|
| 过程监督 | 显式PRM,逐步打分 | 无PRM,仅终端奖励 |
| 搜索方式 | 显式树搜索 + 蒸馏 | GRPO组内竞争 |
| 数据需求 | 高(过程标注) | 低(仅答案标注) |
| 计算成本 | 训练低,推理高 | 训练高,推理低 |
| 涌现能力 | 通过蒸馏传递 | 通过竞争自发涌现 |
从MCTS的视角看,两条路线对应两种不同的搜索策略:
o1的路线更像有监督的树搜索:PRM是手工设计的启发函数,策略模型是通过人类数据引导的先验。它高度依赖人类知识,但在有数据的领域表现强大。
DeepSeek-R1的路线更像无监督的随机搜索 + 选择压力:GRPO相当于让
这是一个深刻的张力:越精确的过程监督,越依赖人类知识;越少依赖人类知识,越需要自发的竞争涌现。
思维链把这个张力暴露在语言模型的时代里。在围棋时代,这个张力的答案是AlphaGo Zero——完全抛弃人类棋谱,依赖自我对弈的竞争选择。在语言推理时代,这个张力还没有最终答案。
十、搜索的哲学:计算即推理
MCTS揭示了一个深刻的事实:推理不需要”理解”,只需要有效的搜索。
AlphaGo不知道围棋的美学,不理解”厚势”、“实地”这些概念。它只知道:在这个状态下,哪个动作的模拟胜率最高。
但这足够了。通过数百万次模拟,MCTS找到了人类几千年都没发现的棋路。
这引发了一个哲学问题:如果搜索足够强大,我们还需要”理解”吗?
一种观点认为:理解是搜索的捷径。人类棋手通过理解棋理,可以快速剪枝,不需要搜索所有可能。但如果计算资源无限,搜索可以替代理解。
另一种观点认为:理解是泛化的基础。MCTS在围棋上很强,但换一个游戏就要重新训练。人类理解了”策略”、“权衡”这些抽象概念,可以快速迁移到新游戏。
ADS的熵正则化提供了第三种视角:搜索可以通过动态约束实时重塑。不需要将搜索”固化为权重”,而是用熵障碍在每一步推理时排斥高不确定性状态。
这类似于物理学中的势场:不是预先计算所有路径,而是在每个位置感受到势能梯度,自然地沿着低势能方向前进。
搜索很强大,但很昂贵。下一章,我们将直面推理的经济学:如何用更少的计算,做出同样好的推理?
悬而未决
熵正则化的泛化边界在哪里? ADS在算术任务上有效,但在需要多层抽象的任务上,小模型会出现”confident hallucination”。熵障碍与模型容量的关系是什么?
拓扑重塑能否推广到其他推理任务? 对数障碍在LLM推理中有效,但在符号推理、定理证明等离散搜索空间中呢?
探索-利用的最优平衡是什么? UCB公式中的常数c如何选择?不同问题是否需要不同的c?
MCTS能否推广到连续动作空间? 围棋、井字棋的动作是离散的。如何将MCTS应用到机器人控制、连续优化等连续动作问题?
搜索与推理的边界在哪里? 定理证明可以视为搜索,但数学家的”洞察”能被搜索捕获吗?
PRM的中间步骤标注存在本质困难吗? 如果某条”看起来错误”的推理路径最终得到正确答案,这步是对还是错?这个标注困难是否意味着PRM永远无法提供真正可靠的过程监督?
GRPO的组内竞争压力从哪里来? 如果所有
条轨迹都答对了(或都答错了), ,梯度消失,模型无法学习。这说明GRPO需要任务难度的精确校准——既不能太难(全错),也不能太简单(全对)。这个校准是可解决的工程问题,还是根本性的限制?
延伸阅读
Kocsis & Szepesvári (2006). Bandit based Monte-Carlo Planning — MCTS原始论文,提出UCT算法
→ [ECML 2006]Silver et al. (2016). Mastering the game of Go with deep neural networks and tree search — AlphaGo论文,MCTS+神经网络的里程碑
Silver et al. (2017). Mastering the game of Go without human knowledge — AlphaGo Zero,完全自我对弈学习
[Zixi Li, 2026a] — ADS自适应双搜索,熵正则化框架,拓扑重塑推理空间
→ [DOI: 10.13140/RG.2.2.17091.16164]Lightman et al. (2023). Let's Verify Step by Step — OpenAI过程奖励模型(PRM)的系统性研究,证明过程监督优于结果监督
→ [arXiv:2305.20050]DeepSeek-AI (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning — GRPO方法,组内竞争强化学习,无需PRM实现强推理能力
→ [arXiv:2501.12948]Shao et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models — GRPO算法的首次提出,在数学推理任务上的验证
→ [arXiv:2402.03300]Wei et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models — 思维链论文,将CoT确立为LLM推理的基础设施
→ [arXiv:2201.11903]Browne et al. (2012). A Survey of Monte Carlo Tree Search Methods — MCTS方法综述
[Dam et al., 2020] — MCTS中的凸正则化,指数收敛率证明
→ [arXiv:2007.00391][Dam et al., 2019] — Power-UCT,幂平均算子改进节点价值估计
→ [arXiv:1911.00384]