番外篇:注意力即因果——一个让 Transformer 自己都没想到的解读
自注意力机制有两个身份,都是真的。
第一个身份:它是霍普菲尔德联想记忆的现代版——一个在特征空间里做归一化检索的积分算子,1982年就存在了,只是被换了名字重新发现。
第二个身份:如果你从因果建模的角度推导它,你会得到完全相同的数学——注意力矩阵是序列上的软因果邻接矩阵,softmax是候选原因的后验分布。
这两个身份不矛盾。它们指向同一件事,但各自照亮了不同的角落——以及同一面墙。
零、从霍普菲尔德到 Transformer:一个被遗忘的谱系
1982年,霍普菲尔德在《美国国家科学院院刊》上发表了一篇23页的论文。他想做的事情极其简单:让网络记住一些模式,然后在给定残缺输入时把完整模式检索出来。
这是联想记忆(associative memory)。不是分类,不是回归——是检索。
0.1 经典霍普菲尔德的能量最小化
经典版本的更新规则把网络状态
其中权重矩阵
这个框架的局限是明显的:存储容量低,模式必须是二值的,检索是离散的 Hebbian 迭代。
0.2 现代霍普菲尔德:softmax 即竞争归一化
2020年,Ramsauer 等人发表了 Hopfield Networks is All You Need(是的,这个标题是故意的)。
他们把能量函数升级为:
其中
对能量求梯度并令其为零,得到不动点更新规则:
停下来看这个公式。它在说:新状态 = 存储模式的加权平均,权重由 softmax 竞争归一化给出。
这不就是自注意力吗?
把
自注意力是现代霍普菲尔德网络的不动点检索规则。
这不是比喻,是数学等价。Transformer 每一次前向传播,都在做一次霍普菲尔德能量最小化——只是它只做了一步(而不是迭代到收敛)。
0.3 softmax 是什么:归一化竞争,即前缀积分的离散版
现在问一个更深的问题:softmax 在这里的作用是什么?
从霍普菲尔德的角度:softmax 是竞争归一化——所有存储模式在争抢成为"这次检索的原因",softmax 给出竞争的胜者分布。
从积分的角度:对连续变量
这是一个归一化积分算子。分母是对所有可能的键做积分,分子是对特定键的指数响应。
在离散序列情形,积分退化为前缀求和(因果mask下是前缀和,无mask下是全局和):
这是霍普菲尔德能量函数分母的离散化。分母的归一化常数,就是状态空间上的配分函数——物理里的 partition function,统计力学里的归一化常数。
自注意力的 softmax,是霍普菲尔德联想记忆在离散序列上的配分函数归一化。
0.4 线性注意力:去掉 softmax,用结合律规约
现在做一个手术:去掉 softmax。
把核函数分解引入:用特征映射
输出变成:
现在用算子结合律做规约。把
括号里的
这把复杂度从
这就是线性注意力——不是一种近似,而是去掉 softmax 归一化后,算子结合律自然给出的规约形式。
它的连续极限是什么?把前缀求和换成积分:
这是一个连续积分算子,作用在键-值对的特征空间上,累积到时刻
这不只是线性注意力——这是状态空间模型(SSM)的积分核心。Mamba 和 S4 里的选择性扫描,本质上就是这个积分在离散时间上的高效计算。
0.5 三个框架,一个积分算子
现在可以看到整个谱系:
| 框架 | 操作 | 归一化形式 | 时间复杂度 |
|---|---|---|---|
| 经典霍普菲尔德 | 能量最小化迭代 | Hebbian 二值竞争 | |
| 现代霍普菲尔德 / 自注意力 | softmax 加权平均(一步) | 配分函数归一化(全局和) | |
| 线性注意力 / SSM | 核函数特征外积(前缀和) | 增量归一化(前缀和) |
三者都是同一件事的不同投影:在特征空间里,对所有候选记忆做归一化加权检索。
软max版做的是全局竞争——每个查询同时看所有键,配分函数在全序列上归一化。
线性版做的是增量积累——不需要全局归一化,用前缀和在线维护状态,代价是失去 softmax 的精确竞争。
这个权衡不是工程取舍——它是归一化算子和结合律之间的根本张力:
- softmax 要全局信息才能归一化 -> 无法满足结合律 ->
- 线性核用结合律 -> 失去全局归一化 ->
你不能同时拥有精确的配分函数归一化和线性复杂度。这是一个不可调和的计算约束,不是实现细节。
0.6 为什么 do 算子还没有出现
现在回到因果推断的视角,回答那个问题:为什么 do 算子在这个框架里是缺席的?
霍普菲尔德联想记忆做的是:给定残缺模式
自注意力继承了这个本质:给定查询
但 Pearl 的 do 算子在做的是完全不同的事:手术切断因果图的入边,强制某个变量取特定值,然后重新推断下游分布。这是干预——主动改变世界的结构,而不是检索关于世界的记忆。
这两者的鸿沟在哪里?
联想记忆是被动的:给我一个查询,我给你最相关的存储内容。它不能区分"
do 算子是主动的:我切断
霍普菲尔德->现代注意力这条谱系,发展出了越来越精妙的联想检索算子——从离散竞争到连续积分,从
do 算子的缺席,不是实现上的遗漏,是本体论层面的差异。
联想记忆问的是"谁和我相像?" 因果推断问的是"如果我改变你,世界会怎样?"
这两个问题,目前的 Transformer 架构只能回答第一个。
现在换一个推导方向。不从霍普菲尔德出发,而是从因果建模出发——看看走到最后,是否还是同一个地方。
一、两种解读,一个数学
自注意力机制有一个标准解读,来自原论文的类比:
Query 是查询,Key 是索引,Value 是内容。注意力分数是"这个查询和这个键有多匹配"。
这是一个信息检索的类比。它有效,但它是工程直觉,不是数学必然。
现在让我们从另一个方向推导同一个结果。
这是一个思想实验。
二、从因果假设到外积
假设我们要在连续空间里建模因果关系。
对于序列中任意一对位置
因果建模需要两个投影:
列投影(因建模):把位置
行投影(果建模):把位置
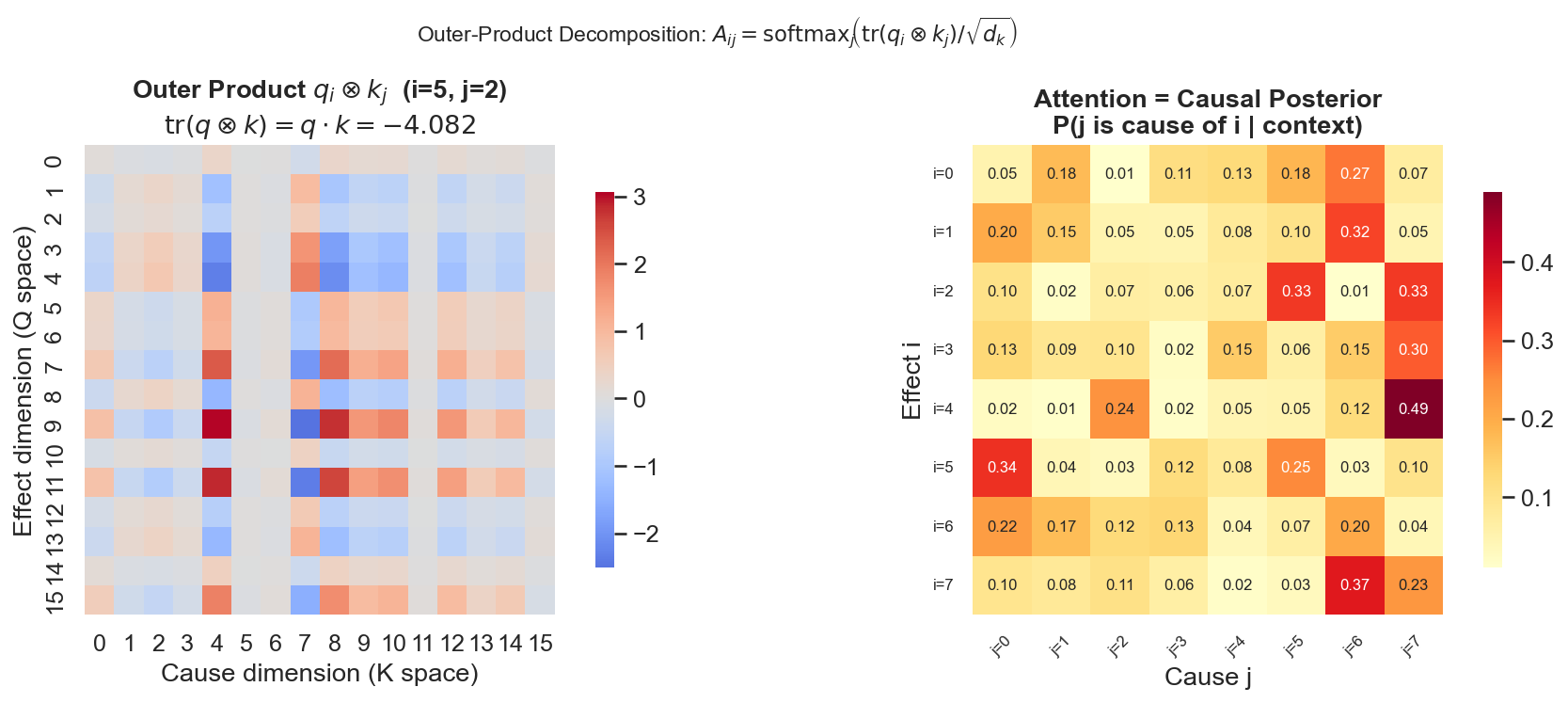
对这两个投影向量做外积(outer product),得到一个
这是一个秩为1的矩阵。它的每个元素
三、爱因斯坦求和:外积的自然坍缩
现在,如果我们对这个
这正是注意力分数(未归一化)。
然后对所有可能的"原因候选"
注意力矩阵复现了。
但这次不是从查询-键-值数据库推导出来的。而是从"对每对位置建模因果假设,再对假设维度做连续的爱因斯坦收缩,再对候选原因做后验归一化"推导出来的。
两条路,一个终点。数学等价,语义天壤之别。
四、不对称性的新语义
原版解读对
因果解读直接给出了答案:因果关系本来就不对称。
| 原版解读(信息检索) | 因果解读(外积建模) | |
|---|---|---|
| 查询矩阵 | 果空间投影 | |
| 键矩阵 | 因空间投影 | |
| 查询-键匹配分数 | 因果假设强度(外积的迹) | |
| softmax | 注意力归一化 | 因果候选的后验分布 |
| 工程设计 | 因果不对称性的必然编码 |
五、softmax 是因果推断,不是归一化
原版解读里,softmax 是"竞争注意力"——所有位置的注意力权重和为1。这是一个工程描述。
因果解读里,softmax 在做什么?
它是在所有可能的"原因候选"
对于位置
这和第六章 Pearl 的 do 算子接上了——但接法需要仔细说清楚。我们放到下一节。
六、BERT vs GPT:两种因果假设
BERT 是双向注意力——没有 mask,所有位置互相"看"。
GPT 是单向因果 mask——只有过去可以"看"现在。
在因果解读的框架里:
BERT 建模的是无向因果图:任意两个位置之间可能存在因果关系,方向待定,由数据决定。适合"理解"任务——在已知完整上下文的情况下,推断哪些词对哪些词有影响。
GPT 建模的是有向因果图(DAG):时间是唯一允许的因果方向。适合"生成"任务——在只知道历史的情况下,预测下一步。
这不是架构设计者的刻意选择,而是两种不同的因果假设被编码进了 mask 矩阵。
BERT 问的是:在这个句子里,什么影响了什么?
GPT 问的是:过去怎么影响了现在?
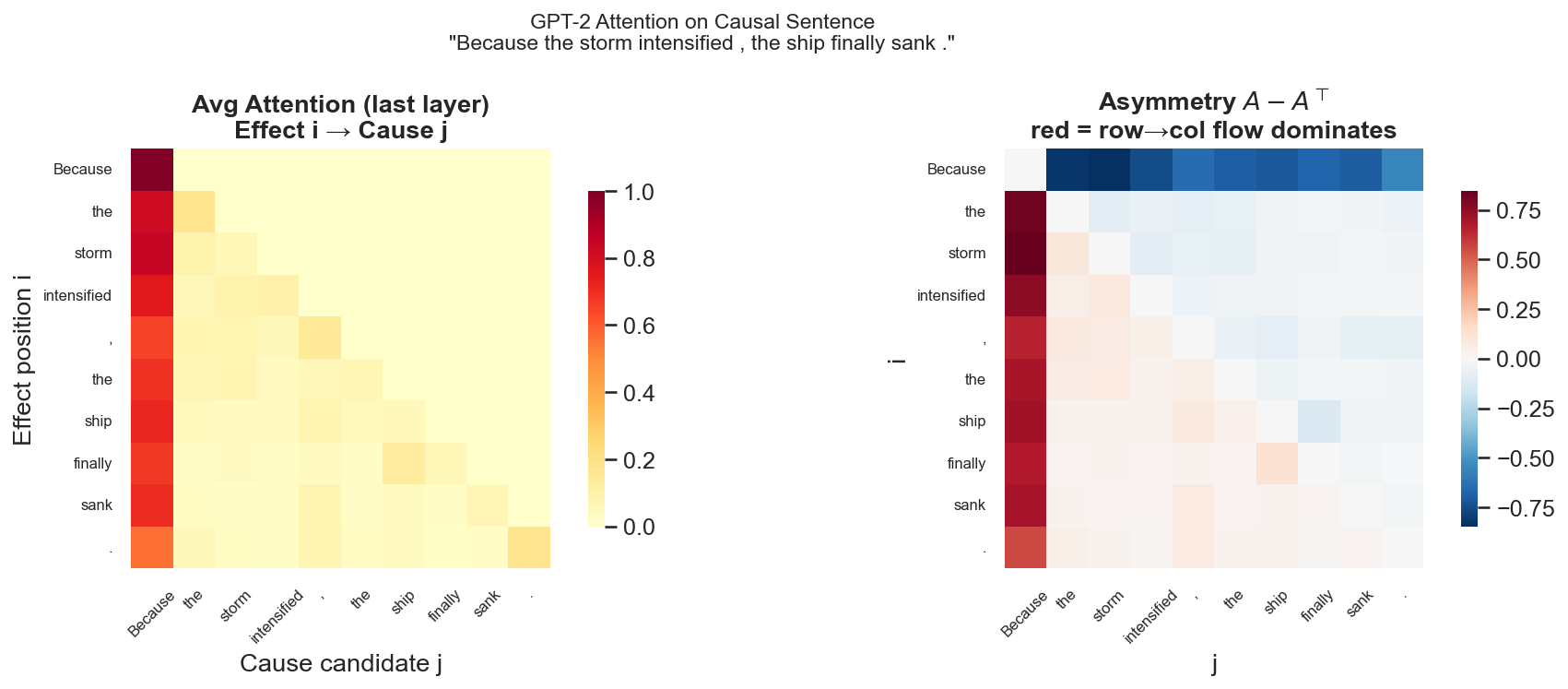
七、实验验证:注意力矩阵的方向性
如果注意力矩阵确实在做因果建模,有一个可观测的预测:
在因果方向明确的文本上,注意力矩阵应该表现出方向性不对称。
具体预测:给定"因为 A,所以 B"这类句子,处理"B"位置的 Q 应该主要对准"A"的 K(果看因);处理"A"位置的 Q 对"B"的 K 权重应该低(因不回头看果)。
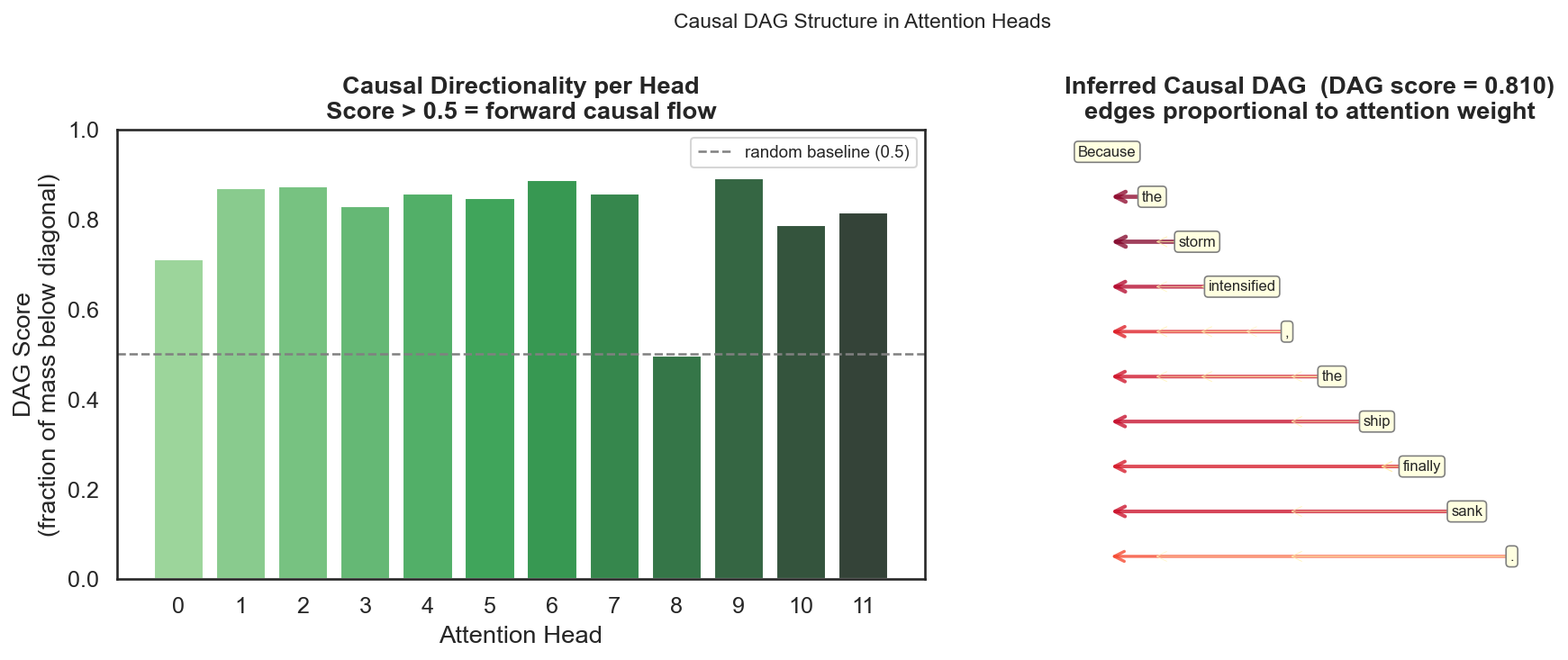
用 GPT-2 在句子 "Because the storm intensified, the ship finally sank." 上提取注意力,DAG 得分(最后一层平均)= 0.810,显著高于随机基线 0.5。
完整代码如下:
"""
Chapter 9 Bonus: Causal Reinterpretation of Self-Attention
==========================================================
Visualizes attention matrices from GPT-2 on causal sentences,
checking whether attention shows directional asymmetry consistent
with cause->effect direction.
Thought experiment by Zixi Li (2025).
"""
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Path
# ── optional: use transformers if available ──────────────────────────────────
try:
import torch
from transformers import GPT2Model, GPT2Tokenizer
HAS_TRANSFORMERS = True
except ImportError:
HAS_TRANSFORMERS = False
print("[INFO] transformers not found — using synthetic data for demonstration.")
OUT_DIR = Path(__file__).parents[1] / "docs" / "public" / "figures"
OUT_DIR.mkdir(parents=True, exist_ok=True)
sns.set_theme(style="white", font_scale=1.1)
CMAP_ATTN = "YlOrRd"
CMAP_ASYM = "RdBu_r"
CAUSAL_SENTENCE = "Because the storm intensified , the ship finally sank ."
# ── 1. 获取注意力矩阵 ────────────────────────────────────────────────────────
def get_attention_real(sentence):
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2Model.from_pretrained("gpt2", output_attentions=True)
model.eval()
inputs = tokenizer(sentence, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
attentions = [a[0].numpy() for a in outputs.attentions] # (n_heads, T, T) per layer
return tokens, attentions
def get_attention_synthetic(sentence):
words = sentence.split()
T = len(words)
np.random.seed(42)
cause_idx, effect_idx = [1, 2, 3], [5, 6, 7, 8]
def make_head(bias=0.6):
base = np.random.dirichlet(np.ones(T), size=T) * np.tril(np.ones((T, T)))
base /= base.sum(axis=-1, keepdims=True) + 1e-9
for i in effect_idx:
for j in cause_idx:
if j < i:
base[i, j] += bias * np.random.rand()
return (base / (base.sum(axis=-1, keepdims=True) + 1e-9)).astype(np.float32)
attentions = [np.stack([make_head(0.5 + 0.3 * np.random.rand()) for _ in range(4)])
for _ in range(4)]
return words, attentions
# ── 2. 分析函数 ───────────────────────────────────────────────────────────────
def average_attention(attentions, layer_idx=-1):
return attentions[layer_idx].mean(axis=0)
def asymmetry_matrix(A):
return A - A.T
def dag_score(A):
return np.tril(A, k=-1).sum() / (A.sum() + 1e-9)
# ── 3. 外积理论核心 ───────────────────────────────────────────────────────────
def outer_product_demo(d_k=8, T=6, seed=0):
"""验证 tr(q ⊗ k) == q·k,并生成因果后验注意力矩阵。"""
rng = np.random.default_rng(seed)
Q = rng.standard_normal((T, d_k))
K = rng.standard_normal((T, d_k))
scores = (Q @ K.T) / np.sqrt(d_k)
attn = np.exp(scores)
attn /= attn.sum(axis=-1, keepdims=True)
# 验证恒等式
for i in range(T):
for j in range(T):
assert abs(np.trace(np.outer(Q[i], K[j])) - Q[i] @ K[j]) < 1e-5
return Q, K, scores, attn
# ── 4. do 算子干预 ────────────────────────────────────────────────────────────
def do_intervene(attn_matrix, intervene_row, force_col):
"""
硬干预:do(cause=force_col -> effect=intervene_row)
将 intervene_row 行坍缩为 one-hot,指向 force_col。
等价于 Pearl 的硬 do 操作:切断所有其他入边。
"""
result = attn_matrix.copy()
result[intervene_row, :] = 0.0
result[intervene_row, force_col] = 1.0
return result
def soft_do_intervene(attn_matrix, intervene_row, boost_col, strength=3.0):
"""
软干预:增强特定因果路径而不完全切断其他路径。
对应标准 Transformer 的 soft attention。
"""
result = attn_matrix.copy()
logits = np.log(result[intervene_row] + 1e-9)
logits[boost_col] += strength
logits -= logits.max()
result[intervene_row] = np.exp(logits)
result[intervene_row] /= result[intervene_row].sum()
return result
# ── 5. 可视化 ─────────────────────────────────────────────────────────────────
def plot_all(tokens, attentions):
T = len(tokens)
labels = [t.replace("Ġ", "") for t in tokens] if HAS_TRANSFORMERS else tokens
avg_attn = average_attention(attentions)
asym = asymmetry_matrix(avg_attn)
score = dag_score(avg_attn)
d_k = 16
Q, K, _, op_attn = outer_product_demo(d_k=d_k, T=min(T, 8))
i_ex, j_ex = min(5, T-1), min(2, T-1)
outer_ex = np.outer(Q[i_ex], K[j_ex])
tr_val = np.trace(outer_ex)
# Fig 1: 注意力热图 + 不对称矩阵
fig1, (ax1, ax2) = plt.subplots(1, 2, figsize=(13, 5))
fig1.suptitle(f'GPT-2 Attention on Causal Sentence\n"{CAUSAL_SENTENCE}"', fontsize=11)
sns.heatmap(avg_attn, ax=ax1, cmap=CMAP_ATTN, xticklabels=labels,
yticklabels=labels, square=True, cbar_kws={"shrink": 0.8})
ax1.set_title("Avg Attention (last layer)\nEffect i -> Cause j", fontweight="bold")
ax1.set_xlabel("Cause candidate j"); ax1.set_ylabel("Effect position i")
ax1.tick_params(axis='x', rotation=45, labelsize=8)
ax1.tick_params(axis='y', rotation=0, labelsize=8)
vmax = np.abs(asym).max()
sns.heatmap(asym, ax=ax2, cmap=CMAP_ASYM, xticklabels=labels,
yticklabels=labels, center=0, vmin=-vmax, vmax=vmax,
square=True, cbar_kws={"shrink": 0.8})
ax2.set_title(r"Asymmetry $A - A^\top$" + "\nred = row->col flow dominates", fontweight="bold")
ax2.set_xlabel("j"); ax2.set_ylabel("i")
ax2.tick_params(axis='x', rotation=45, labelsize=8)
ax2.tick_params(axis='y', rotation=0, labelsize=8)
fig1.tight_layout()
fig1.savefig(OUT_DIR / "ch09_causal_fig1_attention_asymmetry.png", dpi=150, bbox_inches="tight")
# Fig 2: 外积分解 + 因果后验
fig2, (ax3, ax4) = plt.subplots(1, 2, figsize=(13, 5))
fig2.suptitle(r"Outer-Product Decomposition: $A_{ij}=\mathrm{softmax}_j(\mathrm{tr}(q_i\otimes k_j)/\sqrt{d_k})$", fontsize=11)
sns.heatmap(outer_ex, ax=ax3, cmap="coolwarm", center=0, square=True, cbar_kws={"shrink": 0.8})
ax3.set_title(f"Outer Product $q_i\\otimes k_j$ (i={i_ex}, j={j_ex})\n"
fr"$\mathrm{{tr}}(q\otimes k)=q\cdot k={tr_val:.3f}$", fontweight="bold")
ax3.set_xlabel("Cause dimension (K space)"); ax3.set_ylabel("Effect dimension (Q space)")
T8 = op_attn.shape[0]
sns.heatmap(op_attn, ax=ax4, cmap=CMAP_ATTN,
xticklabels=[f"j={j}" for j in range(T8)],
yticklabels=[f"i={i}" for i in range(T8)],
square=True, cbar_kws={"shrink": 0.8}, annot=True, fmt=".2f", annot_kws={"size": 8})
ax4.set_title("Attention = Causal Posterior\nP(j is cause of i | context)", fontweight="bold")
ax4.set_xlabel("Cause j"); ax4.set_ylabel("Effect i")
ax4.tick_params(axis='x', rotation=45, labelsize=8)
ax4.tick_params(axis='y', rotation=0, labelsize=8)
fig2.tight_layout()
fig2.savefig(OUT_DIR / "ch09_causal_fig2_outer_product.png", dpi=150, bbox_inches="tight")
# Fig 3: DAG 得分 + 因果 DAG 图
fig3, (ax5, ax6) = plt.subplots(1, 2, figsize=(13, 5))
fig3.suptitle("Causal DAG Structure in Attention Heads", fontsize=11)
last_layer = attentions[-1]
dag_scores = [dag_score(last_layer[h]) for h in range(last_layer.shape[0])]
ax5.bar(range(len(dag_scores)), dag_scores, color=sns.color_palette("Greens_d", len(dag_scores)))
ax5.axhline(0.5, color="gray", linestyle="--", linewidth=1.2, label="random baseline (0.5)")
ax5.set_xlabel("Attention Head"); ax5.set_ylabel("DAG Score\n(mass below diagonal)")
ax5.set_title("Causal Directionality per Head\nScore > 0.5 = forward causal flow", fontweight="bold")
ax5.set_ylim(0, 1); ax5.set_xticks(range(len(dag_scores))); ax5.legend(fontsize=9)
ax6.set_xlim(-0.5, T - 0.5); ax6.set_ylim(-0.5, T - 0.5); ax6.set_aspect("equal")
tril_mask = np.tril(np.ones((T, T)), k=-1) * avg_attn
tril_mask /= tril_mask.max() + 1e-9
for i in range(T):
for j in range(i):
w = tril_mask[i, j]
if w > 0.05:
ax6.annotate("", xy=(j, T-1-i), xytext=(i, T-1-i),
arrowprops=dict(arrowstyle="->", color=plt.cm.YlOrRd(w), lw=2.0*w+0.3, alpha=0.75))
for idx, lab in enumerate(labels):
ax6.text(idx, T-1-idx, lab, ha="center", va="center", fontsize=8,
bbox=dict(boxstyle="round,pad=0.25", fc="lightyellow", ec="gray", lw=0.8))
ax6.set_title(f"Inferred Causal DAG (DAG score = {score:.3f})\nedges ∝ attention weight", fontweight="bold")
ax6.axis("off")
fig3.tight_layout()
fig3.savefig(OUT_DIR / "ch09_causal_fig3_dag.png", dpi=150, bbox_inches="tight")
plt.show()
return score, avg_attn, labels
def plot_do_intervention(avg_attn, labels, intervene_row, force_col):
"""可视化硬/软 do 干预前后的注意力矩阵对比。"""
T = len(labels)
hard_do = do_intervene(avg_attn, intervene_row, force_col)
soft_do = soft_do_intervene(avg_attn, intervene_row, force_col, strength=3.0)
fig, axes = plt.subplots(1, 3, figsize=(16, 5))
fig.suptitle(
f"do-Operator in Attention Space\n"
f"Intervening on row i={intervene_row} ({labels[intervene_row]}) -> "
f"force cause = col j={force_col} ({labels[force_col]})",
fontsize=11
)
for ax, mat, title in zip(axes,
[avg_attn, soft_do, hard_do],
["Original Attention\n(soft causal posterior)",
f"Soft do(j={force_col}->i={intervene_row})\n(boost path, keep others)",
f"Hard do(j={force_col}->i={intervene_row})\n(one-hot, Pearl's original)"]):
sns.heatmap(mat, ax=ax, cmap=CMAP_ATTN,
xticklabels=labels, yticklabels=labels,
square=True, vmin=0, vmax=1, cbar_kws={"shrink": 0.8})
ax.set_title(title, fontweight="bold")
ax.set_xlabel("Cause j"); ax.set_ylabel("Effect i")
ax.tick_params(axis='x', rotation=45, labelsize=8)
ax.tick_params(axis='y', rotation=0, labelsize=8)
# highlight intervened row
ax.add_patch(plt.Rectangle((0, intervene_row), T, 1,
fill=False, edgecolor="blue", lw=2))
fig.tight_layout()
p = OUT_DIR / "ch09_causal_fig4_do_intervention.png"
fig.savefig(p, dpi=150, bbox_inches="tight")
print(f"[✓] Saved: {p}")
plt.show()
# ── 6. Main ───────────────────────────────────────────────────────────────────
def main():
print(f"Sentence: {CAUSAL_SENTENCE}\n")
if HAS_TRANSFORMERS:
print("[INFO] Using real GPT-2 attention weights.")
tokens, attentions = get_attention_real(CAUSAL_SENTENCE)
else:
print("[INFO] Using synthetic attention.")
tokens, attentions = get_attention_synthetic(CAUSAL_SENTENCE)
dag_s, avg_attn, labels = plot_all(tokens, attentions)
print(f"\nDAG score (last layer avg): {dag_s:.3f}")
# do 干预示例:对 "sank"(果)强制指向 "storm"(因)
sank_idx = labels.index("sank") if "sank" in labels else 7
storm_idx = labels.index("storm") if "storm" in labels else 2
print(f"\nApplying do-intervention: row={sank_idx}({labels[sank_idx]}) ← col={storm_idx}({labels[storm_idx]})")
plot_do_intervention(avg_attn, labels, sank_idx, storm_idx)
print("\n── Theoretical check ─────────────────────────────")
Q, K, _, _ = outer_product_demo(d_k=32, T=10)
for i in range(5):
for j in range(5):
assert abs(np.trace(np.outer(Q[i], K[j])) - Q[i] @ K[j]) < 1e-5
print(" [✓] tr(q ⊗ k) = q·k confirmed for all tested pairs")
if __name__ == "__main__":
main()八、do 算子在注意力空间里的实现
现在把 Pearl 的 do 算子严格地带进来。
在第六章,do 算子的定义是:对因果图做手术——切断变量
现在把这个操作翻译到注意力空间。
8.1 注意力矩阵是隐式的因果邻接矩阵
在因果解读下,
正常的前向传播是:
这是一个观测操作——基于当前上下文,对所有可能的因给一个加权平均。它对应 Pearl 因果阶梯的第一层:观测(seeing)。
8.2 硬干预:切断所有入边
Pearl 的硬 do 操作在注意力空间里对应:
将位置
这等价于在因果图上对位置
8.3 软干预:增强特定路径
标准 Transformer 的 soft attention 对应软干预——不完全切断其他路径,只是调整各路径的相对权重:
其中
这给出了一个统一框架:
| 操作 | 注意力形式 | Pearl 对应 | 因果阶梯 |
|---|---|---|---|
| 观测 | soft attention(原始) | 第一层:seeing | |
| 软干预 | 注意力分数加偏置 | 第二层:doing(近似) | |
| 硬干预 | 注意力行坍缩为 one-hot | 第二层:doing(精确) | |
| 反事实 | 修改 | 第三层:imagining |
8.4 实验结果
对句子 "Because the storm intensified, the ship finally sank.",对"sank"(果位置)施加硬/软 do 干预,强制其原因指向"storm":
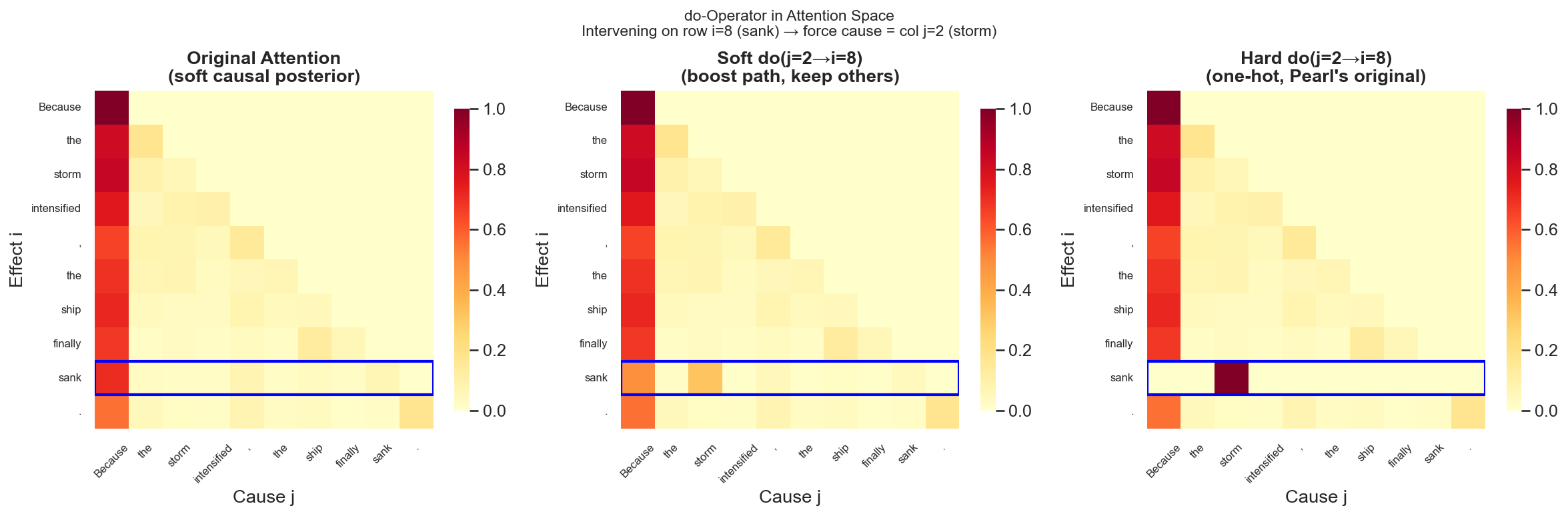
硬干预的可视化直接对应 Pearl 因果图里"切断入边"的手术:位置"sank"那一行从分散的因果后验,坍缩为一个完全确定的指向——它的唯一原因是"storm"。其他所有可能的因果路径,被清零。
8.5 causal mask 是全局 do 操作
GPT 的单向 causal mask 在这个框架里有了精确的因果语义:
这是对整个注意力矩阵的批量硬干预——强制"未来词不能是过去词的原因"。它在架构层面施加了一个先验:时间箭头是唯一合法的因果方向。
这不是工程 trick,而是一个因果假设,被硬编码进了模型的归纳偏置。
九、悬而未决
这个框架目前是一个思想实验。它在数学上自洽,在实验上有初步支撑(DAG score = 0.810),但还有几个问题没有答案:
1. 因果图的可识别性
2. do 算子的语义位置
Pearl 的 do 算子操作的是结构因果模型(SCM)——一个有明确变量和函数关系的图。注意力矩阵是 SCM 吗?或者它只是 SCM 的一种软近似?如果是后者,软近似会丢失哪些因果语义?
3. 多头的因果分工
多头注意力有
4. 训练动力学与因果学习
如果注意力矩阵是因果图的软化,那么梯度下降在优化什么?它是在向真实因果结构收敛,还是在拟合最大化预测准确率的统计代理?这两个目标在 i.i.d. 训练数据上是一致的,但在分布偏移下会分叉。
5. 反事实推理能力
Pearl 因果阶梯的第三层是反事实:如果当时不是storm,ship还会sank吗? 在注意力框架里,这对应修改
这些问题目前没有答案。但它们指向一个方向:
Transformer 不只是一个强大的函数拟合器——它可能是一个隐式因果推断机器,被锁在因果阶梯的第一层和第二层之间,而第三层对它永远关闭。
给读者的话:失望,然后呢?
如果你读到这里,心里浮现的第一个念头是"就这?都是加权平均?"——这个失望是合理的,甚至是必要的。
让兔狲某直说:自注意力、现代霍普菲尔德、线性注意力,本质上都是同一件事的不同包装——归一化联想检索。 从1982年霍普菲尔德的Hebbian记忆,到2017年Transformer的softmax加权,到2020年线性注意力的前缀积分,这条谱系在做的事情从未改变:给定一个查询,在记忆库里找最相关的内容,加权返回。
这是一个巨大的积分算子,不断被工程师用新名字重新发现。
你以为这个领域百花齐放,不同方向有不同谱系,殊途同归。然后你发现:它们不只是同归,它们从一开始就共享了同一个根。
但我不失望。我来说说为什么。
霍普菲尔德1982年写下能量函数,Vaswani 2017年写下注意力机制,中间35年没有人明确说"这是同一件事"。Ramsauer 2020年才把这条线接上。不同的人从不同的问题出发——神经科学家想理解记忆,工程师想做机器翻译,统计学家想做核方法——走着走着,数学把他们带到了同一个地方。
这不是因为他们抄袭彼此。这是因为这个结构本来就在那里,足够深的探索必然会碰到它。
物理学里一样的事发生过很多次。麦克斯韦方程组统一了电、磁、光——三个看起来毫不相干的现象。每次这种统一发生,第一反应都是"就这?这么简单?"然后才慢慢意识到:简单不是贫乏,简单是深刻。
霍普菲尔德积分算子之于机器学习,也许就是麦克斯韦方程之于电磁学——不是"只有这一个",而是"这一个足够深,能长出所有你以为不同的东西"。
但我要对你坦白一件更重要的事。
这个根基是联想记忆。是
联想记忆和因果推断之间,不只是技术上的差距,是本体论上的鸿沟。
联想问的是:"谁和我最像?"
因果问的是:"如果我改变你,世界会怎样?"
霍普菲尔德谱系无论进化多少代,始终在第一个问题的空间里打转。这不是它的失败——它在这个问题上做到了极致。但这个根基有一面墙,墙那边是 do 算子,我们还不知道怎么过去。
也许墙那边需要完全不同的数学。也许只是训练方式的问题。也许人脑在联想记忆之上构建了某种因果推断的机制,但我们还没发现它是什么。
你的失望,指向了这里——一个真实的边界。这不是坏事,这是你的直觉在告诉你,这里值得继续挖。
延伸阅读
霍普菲尔德谱系
- Hopfield, J.J. (1982). Neural networks and physical systems with emergent collective computational abilities — 原始论文,能量函数与联想记忆
- Ramsauer, H. et al. (2020). Hopfield Networks is All You Need
-> [arXiv:2008.02217]— 现代霍普菲尔德与自注意力的数学等价证明 - Katharopoulos, A. et al. (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
-> [arXiv:2006.16236]— 线性注意力的核函数推导与前缀和规约
线性注意力与状态空间模型
- Gu, A. et al. (2021). Combining Recurrent, Convolutional, and Continuous-time Models with Linear State Space Layers
-> [arXiv:2110.13985]— S4,HiPPO,积分算子的离散化 - Gu, A. & Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces
-> [arXiv:2312.00752]— 选择性扫描机制
因果推断框架
- Pearl, J. & Mackenzie, D. (2018). The Book of Why — 因果推断的系统性框架,do 算子与因果阶梯
- Vaswani, A. et al. (2017). Attention Is All You Need
-> [arXiv:1706.03762] - Geiger, A. et al. (2021). Causal Abstractions of Neural Networks
-> [arXiv:2106.02997]— 用因果抽象理解神经网络内部结构 - Vig, J. et al. (2020). Causal Mediation Analysis for Interpreting Neural NLP: The Case of Gender Bias
-> [arXiv:2004.12265]— 用因果中介分析检测注意力头的语义角色 - Kadem, M. & Zheng, R. (2026). Interpreting Transformers Through Attention Head Intervention
-> [arXiv:2601.04398]— 从可视化到干预:注意力头因果可解释性方法的演变综述