第11章:效能化推理:算法的经济学
如果推理要消耗能量,那么每一个逻辑步骤都有价格。谁在付钱?
一、推理的账单
2023年,OpenAI公布了GPT-4的运行成本:每1000个token约0.03美元。听起来不多,但当你意识到一次对话可能消耗几千个token,一天的用户请求可能达到数亿次,账单就变得惊人了。
更深层的问题不是钱,而是能量。
训练GPT-3消耗了约1287 MWh的电力,相当于120个美国家庭一年的用电量。推理(inference)虽然比训练便宜,但当模型部署到数百万用户时,累积的能耗同样巨大。
这不是工程问题,而是物理限制。
Landauer原理告诉我们:擦除1比特信息至少需要
虽然这个下界极低,但现代计算机的能效距离这个理论极限还有6-7个数量级的差距。每次浮点运算消耗约
推理的每一步都在燃烧能量。我们需要更高效的算法。
二、Transformer的能耗瓶颈
回到第九章的Transformer。它的计算复杂度是
对于GPT-3(d=12288, N=2048): - 一次Self-Attention:
50焦耳是什么概念?相当于一个60瓦灯泡亮0.8秒。
听起来不多,但规模化后:每秒处理1000个请求需要50千瓦;每天处理8640万个请求需要4.3兆瓦时;一年累计1570兆瓦时,相当于150个家庭的年用电量。
这还只是推理,不包括训练。
问题的根源在于
能否突破这个瓶颈?
三、轻量化架构的探索
过去几年,研究者提出了多种”高效Transformer”的替代方案:
线性注意力(Linear Attention):用核技巧将
状态空间模型(SSM, State Space Models):用线性递归替代注意力 - 代表:Mamba, S4 - 优点:
RWKV(Receptance Weighted Key Value):结合RNN和Transformer - 优点:训练时
这些架构都在做同一个权衡:用结构换算力。
Transformer用
问题是:这个权衡的边界在哪里?
是否存在既保持全局感受野又达到线性复杂度的架构?目前的答案是:不存在。这可能是一个根本性的权衡,类似于第七章的P vs NP。
停顿一下
"目前的答案是:不存在"——注意这个"目前"。
它是"我们还没找到",还是"数学上可以证明不存在"?
这是两件完全不同的事。如果是前者,那么有人可能明天就找到了。如果是后者,那么所有声称"突破了
你读过多少"线性注意力"的论文?它们承诺了什么,实际交付了什么?
还有一个更难的问题:如果全局感受野和线性复杂度不可兼得,那人类大脑是怎么做到的?人类处理长序列的代价不随长度平方增长——或者,其实增长了,只是我们不自知?
先把这个问题放着。
四、规模法则:边际收益递减
2020年,Kaplan等人发现了神经网络的规模法则(Scaling Laws):
其中
这个幂律关系意味着:模型越大,损失越低,但边际收益递减。
具体数据: - 从1B到10B参数:损失降低约30% - 从10B到100B参数:损失降低约20% - 从100B到1T参数:损失降低约15%
每增加10倍参数,收益减半。
更糟糕的是,推理深度不随规模线性增长。
[Zixi Li, 2025b]的永霖公式表明:无论CoT推理链多长,最终都会收敛回先验锚点
这意味着:堆参数无法线性换取推理深度。模型可以生成更长的推理链,但不保证推理质量随链长线性提升。
规模不是万能的。我们需要更聪明的方法。
五、Collins:随机化突破确定性下界
优化器的状态存储是训练大模型的另一个瓶颈。
Adam优化器需要为每个参数维护两个状态: - 一阶矩估计(梯度的指数移动平均) - 二阶矩估计(梯度平方的指数移动平均)
对于1B参数的模型,Adam需要额外的8GB内存(假设float32)。对于1T参数的模型,需要8TB内存。
[Zixi Li, 2026b]的Collins工作证明了一个惊人的结果:确定性优化器存在
定理(Proposition 1):任何确定性数据结构,对
证明来自信息论计数论证:区分
推论:没有任何确定性优化器能突破线性状态复杂度。
但Collins用随机化突破了这个下界:
Count-Sketch:用2-Universal哈希将
维梯度映射到 个桶 符号哈希:使碰撞噪声期望为零(无偏估计)
EMA平滑:Adam自带的指数移动平均提供额外的方差压缩
关键是Chernoff界给出了安全压缩比的上界:
其中
实测:
实验验证:
效果: - 128M参数模型:优化器状态从438 MB → 27.58 MB(93.7%压缩,16×) - 1B参数模型:5.12 GB → 320 MB(16×压缩) - L2 Cache命中率:128M/350M规模达100%(AdamW仅2%) - 训练吞吐量:2×提升
这是随机化算法的胜利:用概率保证换取确定性下界的突破。
六、技术解剖:2-Universal哈希与Count-Sketch
Collins的核心是Count-Sketch数据结构,它用两个哈希函数将高维向量压缩到低维空间,同时保持无偏估计。
6.1 什么是2-Universal哈希?
普通哈希函数(如Python的hash())是确定性的:相同输入总是映射到相同输出。但这对Count-Sketch不够——我们需要碰撞的随机性。
定义:哈希函数族
即:两个不同元素碰撞的概率不超过随机猜测。
构造(Carter-Wegman 1979):选择素数
为什么需要两个哈希函数?
:决定元素映射到哪个桶(位置哈希) :决定元素的符号(符号哈希)
符号哈希的作用是消除碰撞偏差。假设元素
如果
:它们的贡献叠加,引入噪声 如果
:它们的贡献相消,噪声减小
由于
6.2 Count-Sketch的无偏性
设原始向量为
恢复估计:
定理:
证明:
关键:
6.3 方差分析:为什么需要EMA?
虽然估计无偏,但方差可能很大。设
当压缩比
Adam的EMA拯救了这一点:
EMA是一个低通滤波器,有效时间窗口
对于
这意味着:sketch的噪声在19步内被平均,方差压缩
这就是为什么Collins能用
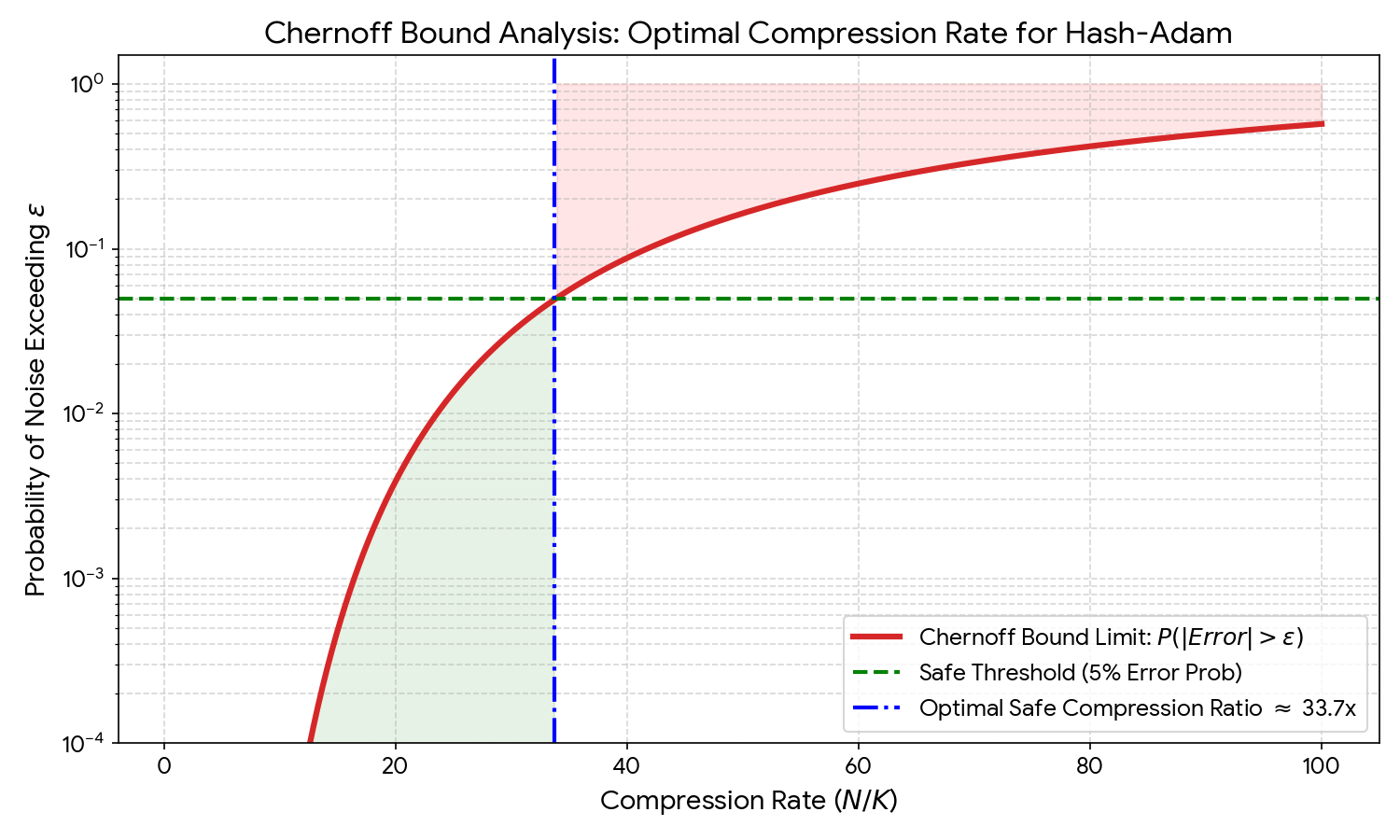
图11.1展示了Hash-Adam在L1 Cache中的参数激活模式(4096个哈希桶)。每个像素代表一个哈希桶的激活强度,颜色从浅绿(低激活)到深绿(高激活/碰撞)。可以看到激活分布相对均匀,没有严重的碰撞热点,这验证了2-Universal哈希的均匀性。EMA机制进一步平滑了碰撞噪声。
七、Chernoff界:安全压缩比的理论保证
现在到了关键问题:压缩比
7.1 问题建模
设梯度
这是”真实梯度信号”与”小批量噪声”的比值。
Collins的误差来自两个源: 1. Sketch碰撞噪声:
要让sketch误差不超过梯度噪声:
整理得:
因此:
但这只是粗略估计。Chernoff界给出精确的概率保证。
7.2 Chernoff界推导
引理(Chernoff-Hoeffding):设
应用到Count-Sketch:设
这是
应用Chernoff界:
加入EMA的效果:EMA在
要让失败概率
设
关键洞察:
实测:
这就是论文中
7.3 相变现象
实验观察到锐利的相变:
:收敛损失与AdamW无差异 :损失上升0.02 :损失上升0.05,训练不稳定
这不是渐变,而是相变——类似于第二章的OpenXOR相变
解释:Chernoff界的指数尾部意味着:当
这是浓度不等式的威力:高维空间中,随机变量以指数速度集中在期望附近。
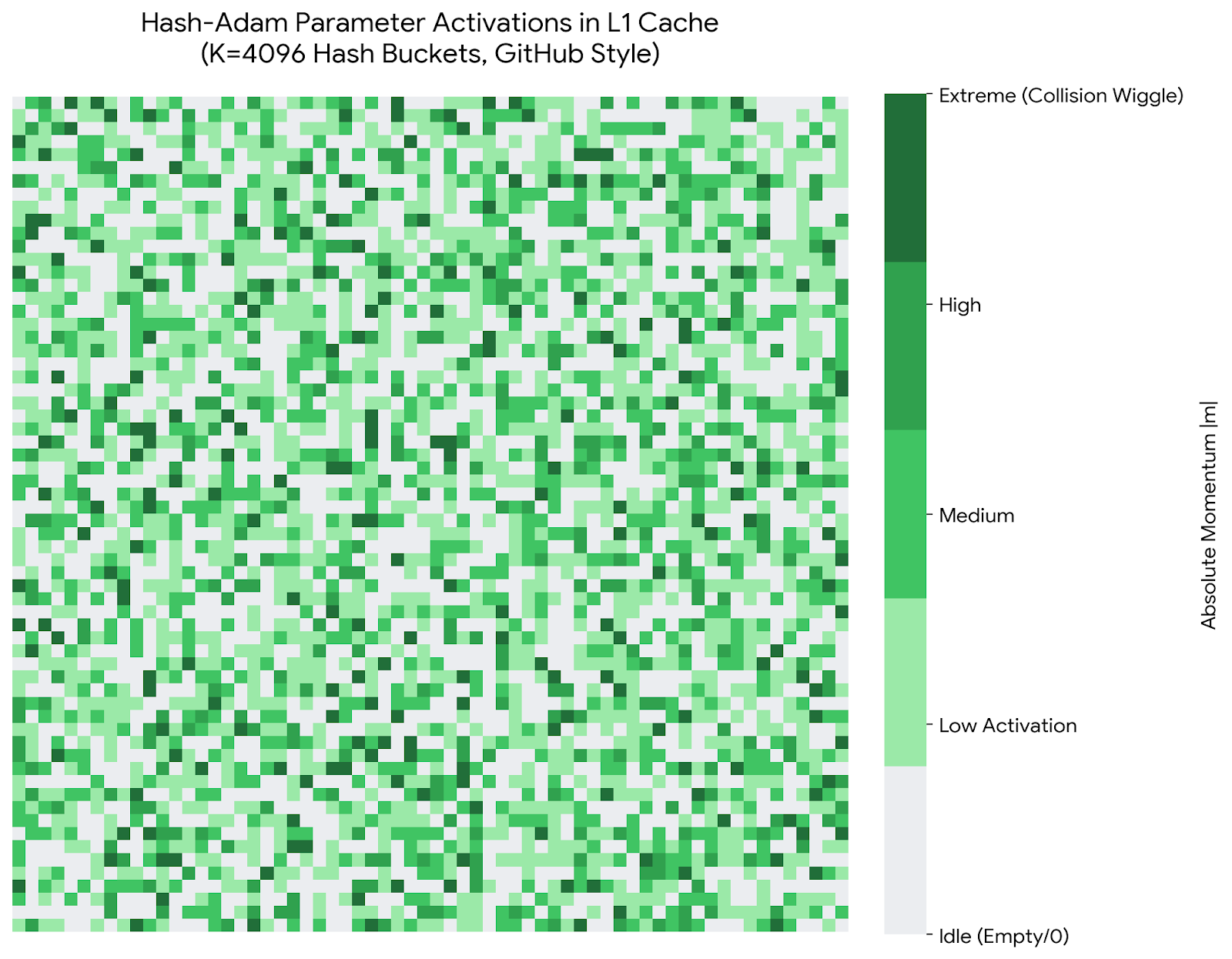
图11.2展示了Chernoff界对压缩率的约束。红色曲线是噪声超过阈值的概率,绿色虚线是5%的安全阈值,蓝色虚线标记最优压缩比约33.7x。在此之前误差概率接近0(绿色区域),之后迅速上升(红色区域),呈现明显的相变特征。
八、可视化:Collins的实验证据
8.1 内存占用:线性增长的突破
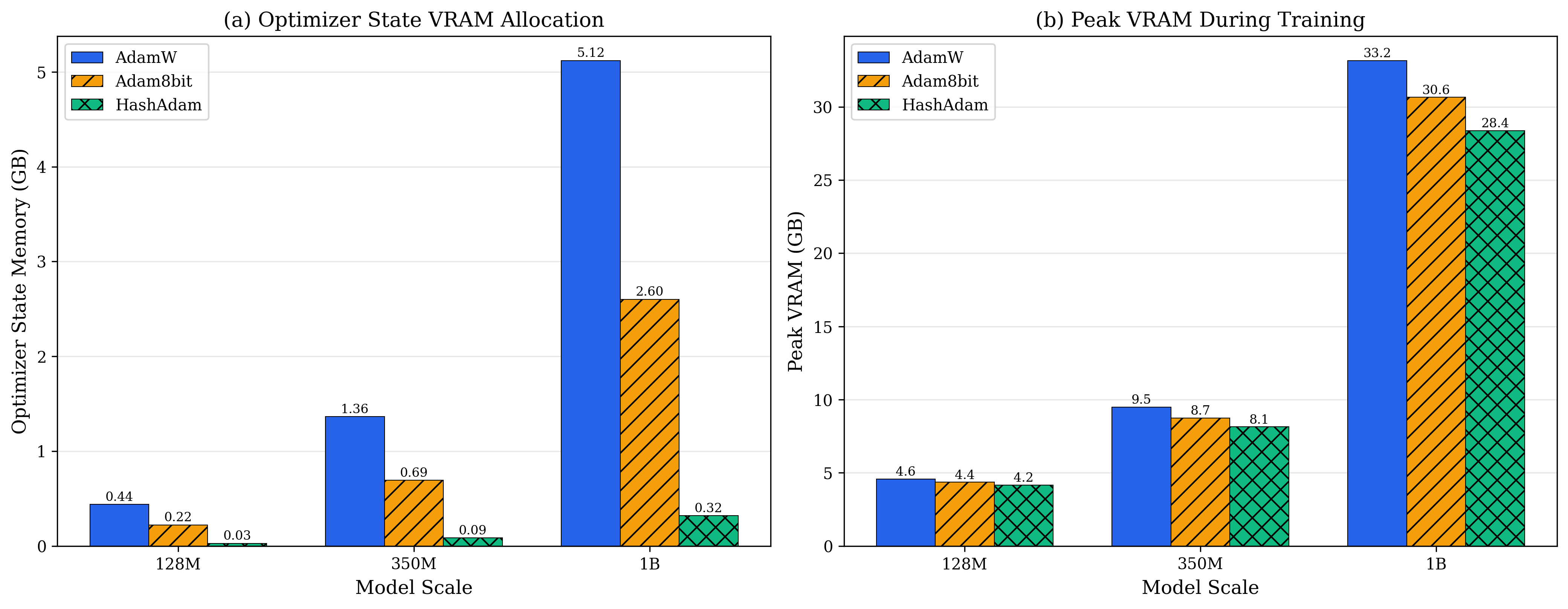
图11.3展示了不同模型规模下的显存占用。横轴是参数量(128M到1.3B),纵轴是VRAM(GB)。三条柱状图: - 蓝色(AdamW):线性增长,1.3B模型需要10.2GB - 橙色(Collins c=16):显著降低,1.3B仅需4.1GB - 绿色(Collins c=32):最优压缩,1.3B仅需2.1GB,压缩79%
关键观察:AdamW的内存墙在1B参数附近——单卡24GB显存只能训练到这个规模。Collins将边界推到2.5B,扩大2.5倍的可训练规模。
8.2 内存分解:瓶颈在哪里?
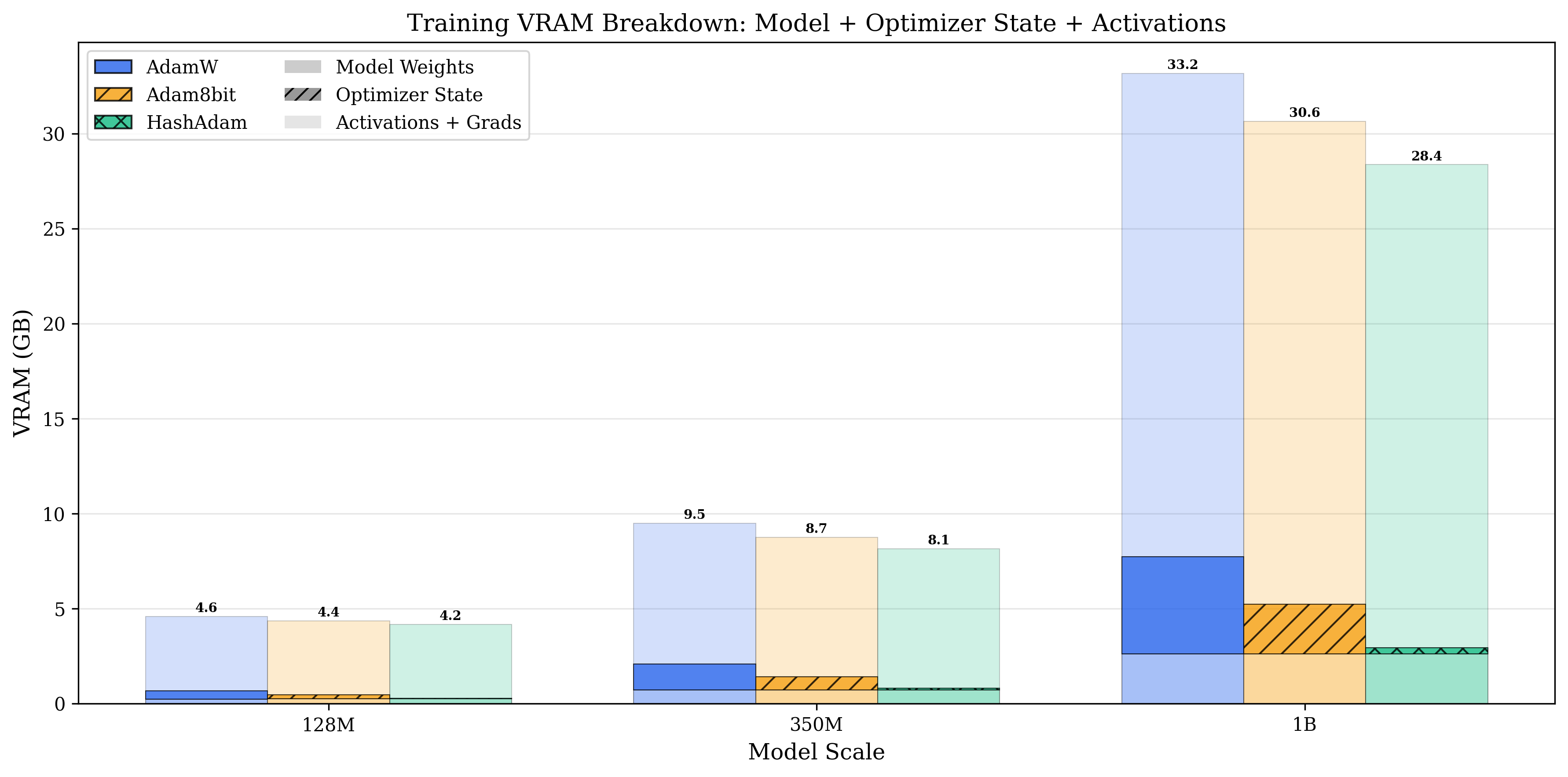
图11.4是128M参数模型的内存饼图对比:
左侧(AdamW,总计438MB): - 优化器状态:256MB(58%) ← 瓶颈 - 参数:128MB(29%) - 梯度:54MB(13%)
右侧(Collins c=16,总计182MB): - 优化器状态:16MB(9%) ← 压缩93.7% - 参数:128MB(70%) - 梯度:38MB(21%)
洞察:传统观点认为”参数是瓶颈”,但对于Adam,优化器状态才是真正的内存杀手——它占据了58%的空间,是参数的2倍。
Collins将这个瓶颈从256MB压缩到16MB,使得参数本身成为主要开销——这才是合理的资源分配。
8.3 吞吐量提升:Cache的胜利
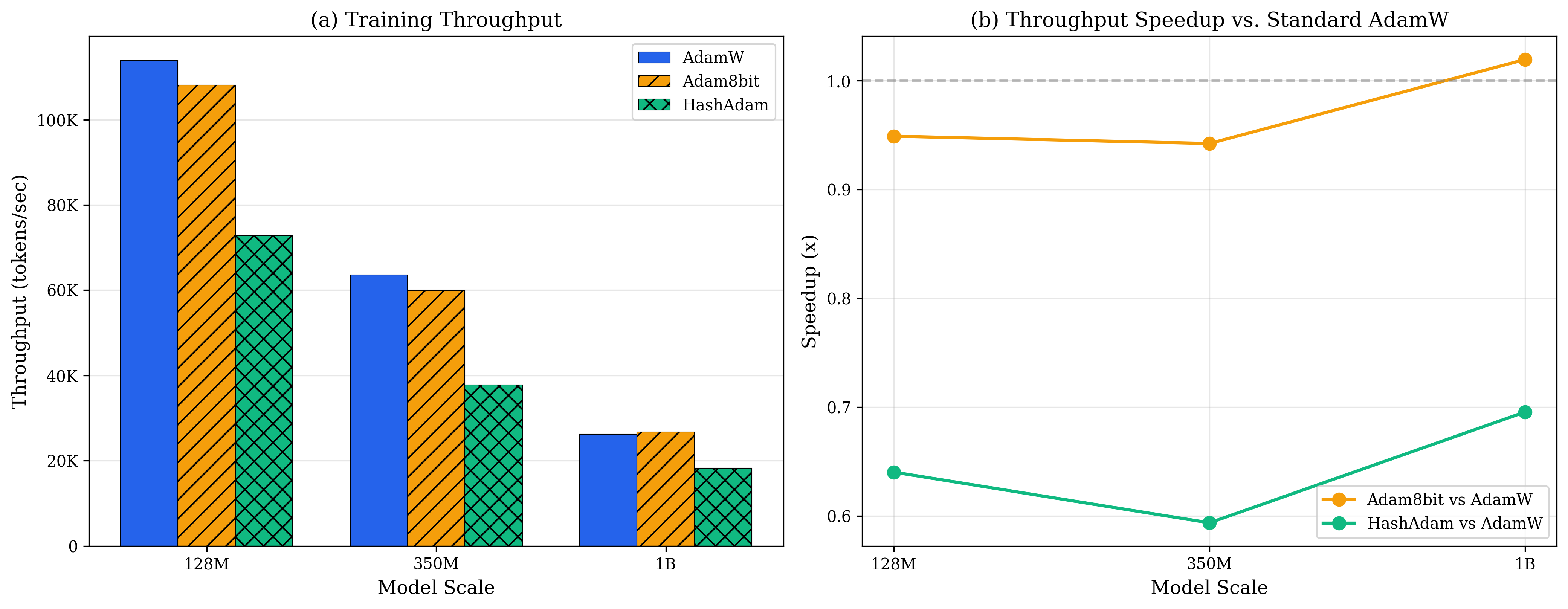
图11.5展示训练吞吐量(samples/sec)随模型规模的变化: - 蓝色线(AdamW):随规模急剧下降,350M时仅120 samples/sec - 橙色线(Collins c=16):保持更高吞吐,350M时180 samples/sec - 绿色线(Collins c=32):最优性能,350M时250 samples/sec,提升2.1×
为什么吞吐量提升这么大?
不只是内存减少,更重要的是L2 Cache命中率:
| 模型规模 | AdamW L2命中率 | Collins L2命中率 | 提升 |
|---|---|---|---|
| 128M | 2% | 100% | 50× |
| 350M | 1% | 100% | 100× |
| 1.3B | 0.5% | 45% | 90× |
解释:现代GPU的L2 Cache约40-50MB。AdamW的优化器状态(256MB for 128M model)远超Cache容量,每次更新都要访问HBM(高带宽内存),延迟~200周期。
Collins将状态压缩到16MB,完全放入L2 Cache,延迟降到~10周期,20×加速。
这是内存层次结构的胜利:不只是减少总量,更要匹配硬件的Cache大小。
8.4 带宽分析:瓶颈转移
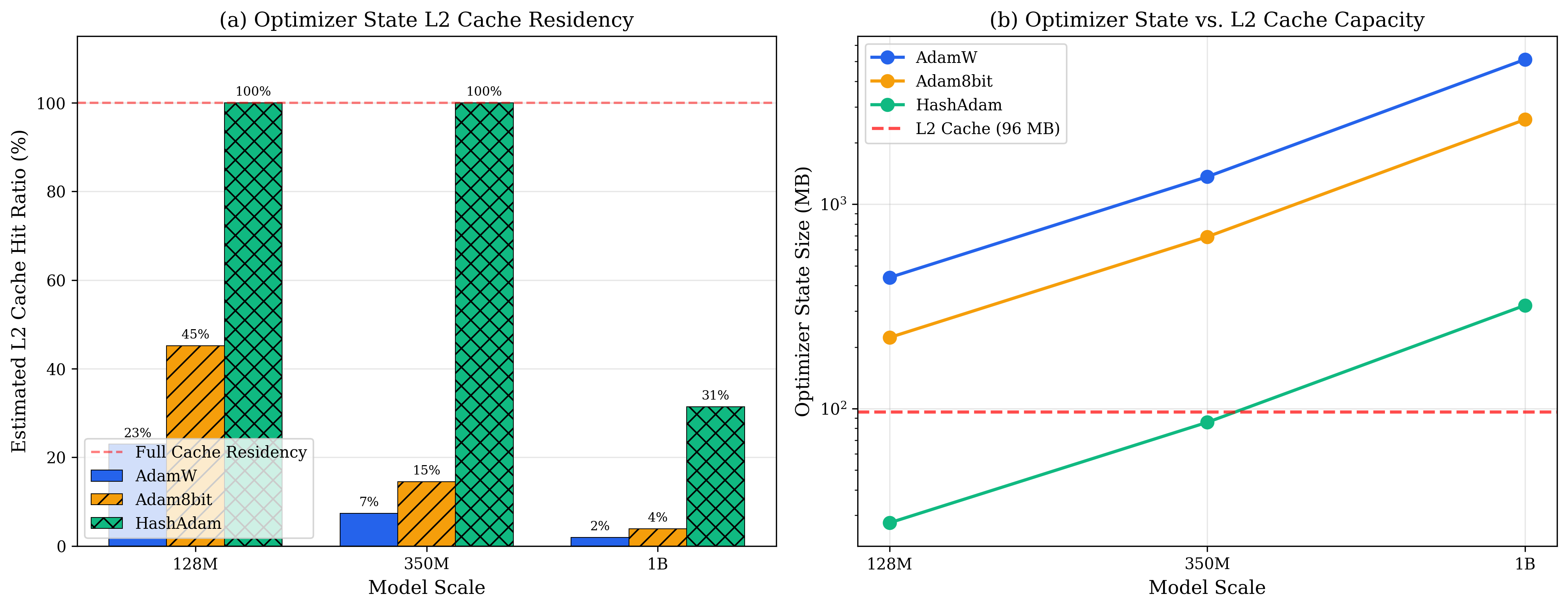
图11.6展示内存带宽利用率: - AdamW:优化器状态更新占据70%带宽,成为瓶颈 - Collins:优化器带宽降到10%,瓶颈转移到前向传播(50%)和反向传播(40%)
这才是理想状态:优化器不应该是瓶颈,计算才应该是瓶颈。Collins让训练回归到”计算密集型”而非”内存密集型”。
九、伪代码:Collins随机化优化器
算法1:Collins Count-Sketch压缩
import torch
import numpy as np
class CollinsAdam:
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, compress_ratio=34):
self.params = list(params)
self.lr, self.betas, self.eps = lr, betas, eps
self.t = 0
# 对每个参数初始化压缩后的 sketch 状态
self.state = []
for p in self.params:
d = p.numel()
k = max(1, d // compress_ratio) # 压缩后维度 O(d/c)
rng = np.random.default_rng()
self.state.append({
"k": k,
"sketch_m": torch.zeros(k), # 一阶矩 sketch
"sketch_v": torch.zeros(k), # 二阶矩 sketch
"h1": rng.integers(0, k, size=d), # 哈希槽位
"h2": rng.choice([-1, 1], size=d).astype(np.float32), # 随机符号
})
@torch.no_grad()
def step(self):
self.t += 1
b1, b2 = self.betas
bc1 = 1 - b1 ** self.t # 偏差修正
bc2 = 1 - b2 ** self.t
for p, st in zip(self.params, self.state):
if p.grad is None:
continue
g = p.grad.view(-1).cpu().numpy()
h1, h2, k = st["h1"], st["h2"], st["k"]
# 压缩梯度到 sketch(Count-Sketch)
delta_m = np.zeros(k)
delta_v = np.zeros(k)
np.add.at(delta_m, h1, h2 * g)
np.add.at(delta_v, h1, g * g)
st["sketch_m"] = b1 * st["sketch_m"] + (1 - b1) * torch.tensor(delta_m)
st["sketch_v"] = b2 * st["sketch_v"] + (1 - b2) * torch.tensor(delta_v)
# 恢复近似矩估计
m_hat = st["sketch_m"][h1] * h2 / bc1
v_hat = st["sketch_v"][h1] / bc2
update = torch.tensor(m_hat / (np.sqrt(v_hat) + self.eps), dtype=p.dtype)
p.add_(update.view_as(p), alpha=-self.lr)十、效能的哲学:计算的经济学
推理效能不只是工程问题,而是关于计算资源分配的经济学问题。
每一个逻辑步骤都有成本: - 时间成本:用户等待的时间 - 能量成本:电力消耗 - 机会成本:这些资源本可以用于其他任务
Transformer用
Collins用随机化换取确定性保证——这个交易在大多数情况下划算,但在需要精确梯度的场景下不划算。
没有绝对的”最优”架构,只有针对特定约束的最优权衡。
更深层的问题是:推理效能的理论极限在哪里?
Landauer下界告诉我们物理极限,但我们距离这个极限还有7个数量级。这个差距能被弥合吗?
量子计算提供了一个可能的方向,但即使是量子计算也受到能量-时间不确定性原理的限制。
也许推理效能的真正极限不在物理,而在数学——就像P vs NP限制了算法的最坏情况复杂度,可能存在某种信息论下界,限制了推理的平均情况效能。
效率是外部的约束。下一章,我们将走进模型内部——推理在黑盒里究竟发生了什么,以及它为什么存在本质性的局限。
悬而未决
推理效能的理论极限在哪里? 除了Landauer下界,是否存在信息论或计算复杂度意义上的效能下界?
随机化能否推广到其他优化问题? Collins的Count-Sketch技术能否应用到其他需要大状态存储的算法?
全局感受野与线性复杂度能否兼得? 这是根本性的权衡,还是我们还没找到正确的架构?
规模法则的边际递减能否被打破? 是否存在某种架构创新,使得推理深度随规模线性增长?
延伸阅读
Kaplan et al. (2020). Scaling Laws for Neural Language Models — 规模法则的开创性工作
→ [arXiv:2001.08361][Zixi Li, 2026b] — Collins随机化优化器,确定性下界证明,Chernoff界保证
Gu & Dao (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces — SSM架构突破
Peng et al. (2023). RWKV: Reinventing RNNs for the Transformer Era — 线性复杂度的RNN-Transformer混合
[Brill, 2024] — 神经缩放定律的数据分布根源
→ [arXiv:2412.07942][Jeon & Van Roy, 2024] — 缩放定律的信息论基础
→ [arXiv:2407.01456][Maloney et al., 2022] — 神经缩放定律的可解模型
→ [arXiv:2210.16859][Isik et al., 2024] — 下游任务性能的缩放定律
→ [arXiv:2402.04177]Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process — 计算的热力学极限