第5章:拟合的陷阱——统计相关性不是推理
模型见过一百万只猫之后,它知道猫是什么吗?
一、一个让人不安的实验
2021年,Bender等人发表了一篇论文,标题很直白:《论随机鹦鹉的危险》(On the Dangers of Stochastic Parrots)。
这个标题不是比喻,是诊断。
论文的核心论点是:大型语言模型,无论训练在多少文本上,本质上都是在做统计模式匹配——它们学会了哪些词序列在训练语料里经常一起出现,然后在生成时复现这些模式。就像一只鹦鹉,听到了足够多的对话之后,能够在合适的时机说出”你好”或”再见”,但它不理解这些词的意义。
这个比喻很刺耳,因为它触及了一个更深的问题:统计相关性和因果理解之间,有一道鸿沟。
让我给你看一个更具体的例子。
2023年,Hodel和West做了一个简单的测试。他们拿GPT-3做字母串类比推理——这是Webb等人在2023年声称GPT-3已经”涌现”出类比推理能力的任务。
原始任务是这样的:
输入: abc → abd, kji → ?
期望输出: kjj
这是一个简单的”最后一个字母后移一位”的规律。GPT-3在这个任务上表现很好。
然后Hodel和West做了最简单的变体:把字母串的长度从3改成4,或者把字母表的顺序稍微打乱。
GPT-3的表现立刻崩溃了。
不是”稍微下降”,是崩溃——准确率从接近100%掉到接近随机猜测。而人类在这些变体上的表现几乎没有变化,因为人类理解的是规律本身,而不是特定长度、特定字母表上的表面模式。
这就是本章要讲的核心问题:当模型通过最小化训练误差来学习时,它学到的是什么?
二、经验风险最小化的契约
让我们从数学上把这个问题说清楚。
监督学习的标准范式是经验风险最小化(Empirical Risk Minimization, ERM)。给定训练数据
这里
ERM的理论保证来自一个简单的直觉:如果训练数据是从某个分布
这个收敛有多快?统计学习理论告诉我们,对于有限的假设空间,收敛速度是
但这里有一个被忽视的前提:ERM优化的目标,和我们真正关心的目标,是同一件事吗?
让我把这个问题拆开。
ERM在做什么?它在寻找一个函数
但”推理”需要什么?推理需要模型捕获
这两者不是一回事。
统计学习理论的经典结果——比如Vapnik和Chervonenkis在1970年代建立的框架——关心的是泛化界(generalization bound):
这个不等式告诉我们:如果假设空间不太复杂,训练误差低的模型,测试误差也会低。
但注意这里的假设:测试数据和训练数据来自同一个分布
这个假设在现实中几乎从不成立。
训练数据是你能收集到的数据——可能来自特定的医院、特定的时间段、特定的人群。测试数据是模型部署后遇到的数据——可能来自不同的医院、不同的季节、不同的人群。
分布偏移(Distribution Shift)是常态,不是例外。
而当分布偏移发生时,ERM学到的那些”在训练数据上有效的相关性”,可能完全失效。
停顿一下
模型记住了训练集——我们叫它过拟合,这是错误,我们会惩罚它。
但如果模型记住了整个互联网呢?
那我们叫它什么?
GPT-4的训练数据规模约等于人类有史以来写下的文字的一个大样本。如果它”记住”了这些,和过拟合的本质区别在哪里?——是规模,还是别的什么?
还有一个问题:当分布偏移发生时,ERM失效。但人类面对分布偏移时,有时候也会失效——我们在陌生文化里判断错,在新领域里犯低级错误。
那么,ERM的缺陷是机器学习独有的,还是所有归纳学习系统共有的?包括你自己?
先把这个问题放着。
三、捷径学习:当相关性比因果更容易
这里有一个思想实验。
假设你要训练一个模型识别”奶牛”。训练集里有1000张奶牛的照片,其中950张的背景是草地,50张的背景是沙滩(某个海边农场)。
ERM会学到什么?
如果模型足够简单,它可能学到:“如果背景是草地,就预测奶牛”。这个规则在训练集上的准确率是95%——非常好。
但这个规则捕获了”奶牛”的本质吗?显然没有。当你把这个模型部署到一个沙滩农场,它会把所有奶牛都分类错误。
这就是捷径学习(Shortcut Learning)——模型学会了利用训练数据中的虚假相关性(spurious correlation),而不是真正的因果特征。
Geirhos等人在2020年的综述里系统地总结了这个现象。他们指出,捷径学习在深度学习里无处不在:
纹理偏见:ImageNet训练的模型更依赖纹理而非形状来分类,而人类恰好相反
背景依赖:目标检测模型会利用背景统计(比如”船通常出现在水面上”)作为捷径
数据集偏见:情感分析模型会过度依赖某些高频词(如”terrible”、“amazing”),而忽略句子的整体语义
为什么会这样?
因为ERM没有区分”有用的相关性”和”虚假的相关性”的机制。 只要某个特征在训练数据上和标签相关,ERM就会利用它——不管这个相关性在训练分布之外是否依然成立。
2022年,Puli等人的研究揭示了一个更深层的原因:即使在虚假特征(捷径)不提供任何额外信息的情况下——也就是说,稳定特征已经完全决定了标签——默认的ERM(梯度下降+交叉熵)仍然会优先依赖捷径。
为什么?因为梯度下降隐含地在最大化分类边界(margin)。而在线性可分的情况下,最大边界解往往是那个同时利用了稳定特征和捷径的解,即使只用稳定特征就能达到零训练误差。
这不是过拟合——训练误差已经是零了。这是归纳偏置的问题:梯度下降+交叉熵的组合,天然地偏好某种类型的解,而这种解在捷径存在时,会过度依赖捷径。
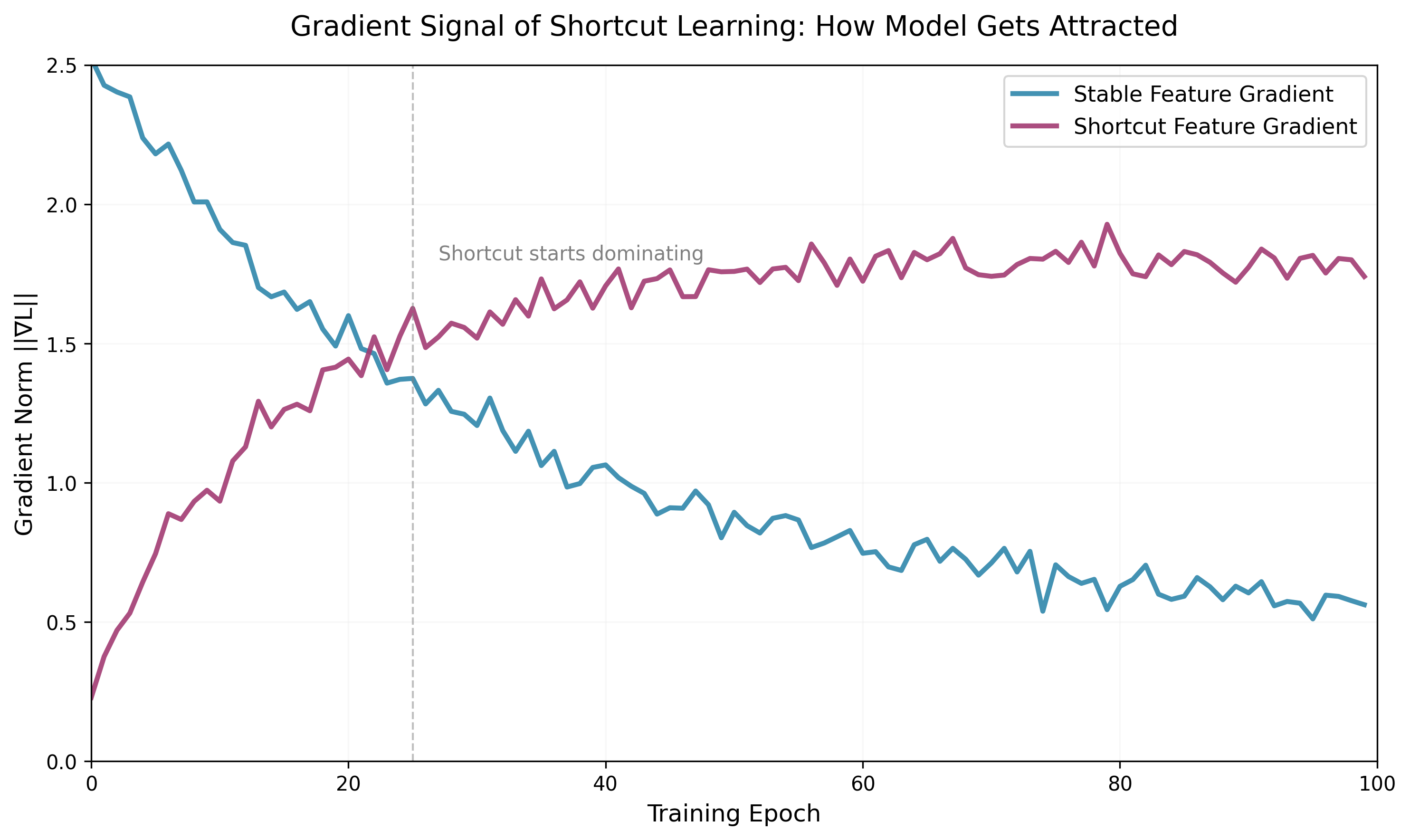
图1:训练过程中,捷径特征的梯度范数快速增长并保持高位,而稳定特征的梯度逐渐衰减。这表明模型在优化过程中逐渐被捷径吸引,即使稳定特征已经足以完成任务。
让我用一个更形式化的框架来说明这一点。
四、因果图视角:稳定特征与虚假特征
假设数据生成过程可以用一个因果图来描述。有三个变量:
:标签(比如”是否是奶牛”) :稳定特征(比如奶牛的形状、纹理) :捷径特征(比如背景是否是草地)
真实的因果关系是:
也就是说,标签
但这个相关性不是因果的。
ERM看到的是什么?ERM看到的是联合分布
如果
问题在于:当测试数据来自不同的分布,其中
这不是模型”不够聪明”。这是ERM的结构性限制:ERM优化的是
Pearl的因果阶梯告诉我们,要回答干预性问题(“如果我把背景换成沙滩,模型还能识别奶牛吗?”),你需要的不是条件概率,而是因果模型。
但ERM只能访问观测数据,它无法区分相关性和因果性。
五、随机鹦鹉假说:复读不是理解
现在让我们回到本章开头的问题:大型语言模型是随机鹦鹉吗?
这个问题的核心不在于模型是否”有意识”或”有理解”——这些是哲学问题,我们暂时搁置。核心在于:模型的行为,在多大程度上可以被”记忆+检索训练数据中的模式”来解释?
2025年,Zhao等人的研究提出了一个关键的测试:Chain-of-Thought(CoT)推理是真正的推理,还是训练数据分布的镜像?
他们的实验设计很巧妙。他们构造了一个完全可控的环境DataAlchemy,从头训练语言模型,然后系统地改变训练数据和测试数据之间的分布差异:
任务分布偏移:训练时见过加法,测试时做乘法
长度分布偏移:训练时见过3位数运算,测试时做5位数运算
格式分布偏移:训练时见过”step 1, step 2”的格式,测试时换成”first, second”
结果是毁灭性的:CoT推理在所有三种分布偏移下都显著退化。 模型不是在”推理”,而是在”模式匹配”——它学会了在训练数据里,什么样的输入对应什么样的推理链格式,然后在测试时复现这个格式。
当测试数据的分布和训练数据不同时,这个复现就失败了。
这和第一节里GPT-3在字母串类比上的崩溃是同一个现象:模型学到的是表面的统计规律,而不是底层的抽象规则。
但这里有一个更深的问题。
Bender等人的”随机鹦鹉”批评,隐含了一个假设:如果模型只是在做统计模式匹配,那么它的能力是有上界的——它不能超越训练数据的统计结构。
但这个假设对吗?
2023年,Wei等人提出了一个反驳:即使模型只是在做模式匹配,如果训练数据足够大、足够多样,模式匹配本身可能就足以产生看起来像”推理”的行为。
这是一个关于涌现(emergence)的争论:当模型规模和数据规模增长到某个临界点,是否会出现质变?
目前的证据是混合的。
一方面,我们确实看到了一些令人惊讶的能力——比如GPT-4在某些推理任务上的表现,已经接近人类平均水平。
另一方面,这些能力在分布偏移下的脆弱性,表明它们可能仍然是”复杂的模式匹配”,而不是真正的抽象推理。
关键的测试是:模型能否在训练数据从未见过的组合方式上,产生正确的行为?
这就是下一节要讲的:分布偏移作为试金石。
六、分布偏移:推理能力的试金石
如果一个模型真的”理解”了它在做什么,那么当输入数据的分布发生变化时,它的性能应该优雅地退化——而不是崩溃。
这是一个可以被精确测试的假设。
分布内(In-Distribution, ID)性能衡量的是模型在和训练数据相似的数据上的表现。这是标准的测试集评估。
分布外(Out-of-Distribution, OOD)性能衡量的是模型在训练分布之外的数据上的表现。这才是真正的泛化能力。
让我给你看几个具体的例子,说明分布偏移如何暴露模型的脆弱性。
例子一:医学图像分割中的捷径
2024年,Woodland等人研究了深度学习模型在医学图像分割任务上的OOD检测。他们发现:在肝脏分割任务上训练的模型,当遇到来自不同医院、不同扫描仪的图像时,性能显著下降。
问题不在于图像质量——新的图像质量很好。问题在于模型学到了训练数据中的设备特异性伪影(device-specific artifacts)作为捷径。
比如,某个特定型号的CT扫描仪会在图像的某个位置产生特定的噪声模式。模型学会了利用这个噪声模式来辅助分割——因为在训练数据里,这个噪声模式和肝脏的位置高度相关。
但当换到另一个型号的扫描仪,这个噪声模式消失了,模型的分割准确率就崩溃了。
例子二:自然语言理解中的虚假相关
2023年,Shuieh等人系统地评估了三种后训练算法(SFT、DPO、KTO)在虚假相关性下的鲁棒性。
他们构造了数学推理、指令遵循、文档问答三类任务,并在数据中引入不同程度的虚假相关(10% vs 90%)。
结果显示:所有模型在高虚假相关性下都显著退化。 偏好学习方法(DPO/KTO)在数学推理任务上表现相对鲁棒,但在复杂的上下文密集型任务上,监督微调(SFT)反而更强。
这说明什么?说明没有一种训练方法能普遍地抵抗捷径学习。最佳策略取决于任务类型和虚假相关的性质。
例子三:CoT推理的分布脆弱性
回到Zhao等人的DataAlchemy实验。他们的核心发现是:CoT推理是训练数据分布的脆弱镜像。
当任务、长度、格式三个维度中的任何一个发生偏移,CoT的有效性都会显著下降。这表明模型学到的不是”如何推理”,而是”在训练数据里,推理链长什么样”。
更糟糕的是,模型在分布偏移下的失败方式是系统性的,而不是随机的。它不是偶尔犯错,而是在特定类型的输入上一致地失败——因为那些输入触发了训练数据中不存在的模式。
这三个例子指向同一个结论:分布偏移不是边缘情况,而是核心测试。 如果一个模型只在分布内表现良好,那么它学到的很可能是统计相关性,而不是因果机制。
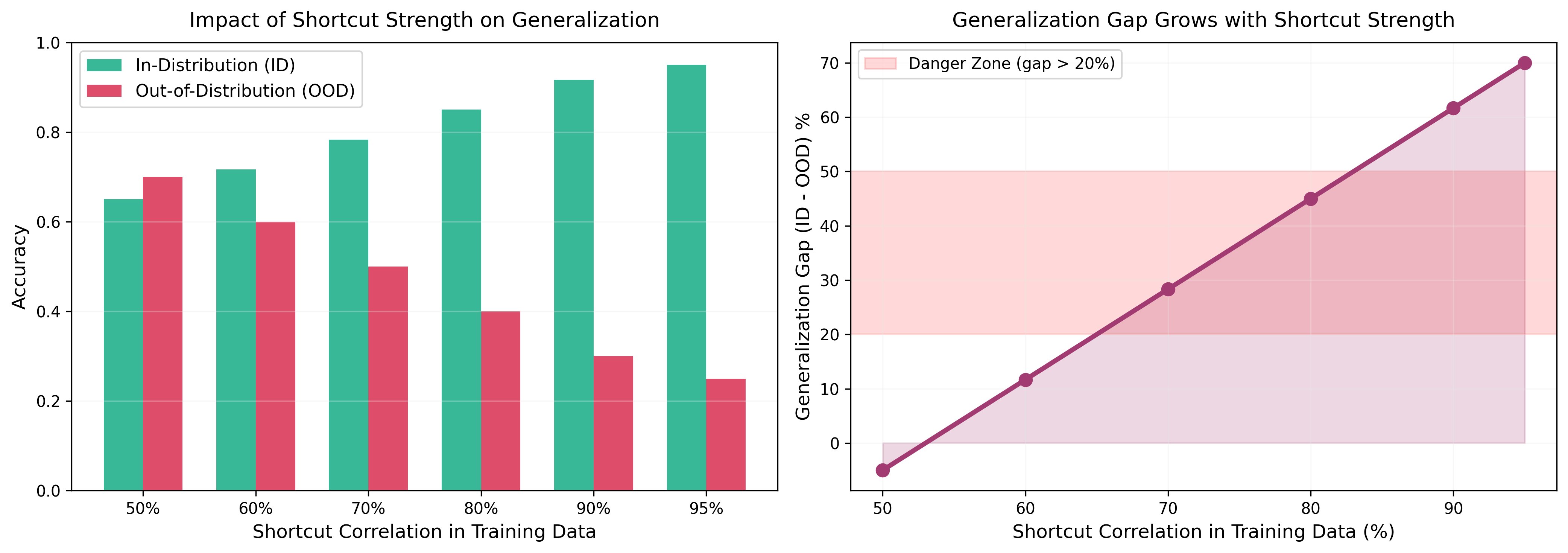
图2:左图显示随着训练数据中捷径相关性增强,ID准确率提升但OOD准确率下降。右图显示泛化差距(ID-OOD)随捷径强度线性增长,当捷径相关性超过80%时,泛化差距进入危险区(>20%)。这量化了捷径学习对分布外泛化的破坏性影响。
七、为什么ERM的归纳偏置不够
现在我们到了这一章最关键的地方。
问题不在于ERM本身——ERM是一个合理的学习原则。问题在于:ERM配合标准的优化算法(梯度下降)和损失函数(交叉熵),产生的归纳偏置,不适合学习因果结构。
让我把这个论点展开。
归纳偏置(Inductive Bias)是学习算法隐含的假设——它决定了在多个能够拟合训练数据的假设中,算法会选择哪一个。
梯度下降+交叉熵的归纳偏置是什么?
在线性可分的情况下,梯度下降会收敛到最大边界解(max-margin solution)——那个使得分类边界到最近训练样本的距离最大的解。
这在很多情况下是好的。最大边界通常意味着更好的泛化——因为它对训练数据的小扰动更鲁棒。
但在捷径存在的情况下,最大边界解往往是那个同时利用稳定特征和捷径的解。
为什么?因为如果你同时用两个特征,你可以把分类边界推得更远——即使其中一个特征(捷径)在分布外会失效。
Puli等人在2023年的研究精确地刻画了这个现象。他们证明:在一个简单的线性感知任务中,即使稳定特征已经完全决定了标签,梯度下降仍然会给捷径分配非零权重——因为这样可以最大化边界。
解决方案是什么?
一个方向是改变归纳偏置。比如,不追求最大边界,而追求均匀边界(uniform margin)——让所有训练样本到分类边界的距离尽可能相等。
Puli等人提出的MARG-CTRL(Margin Control)就是这个思路。通过调整损失函数,鼓励模型产生均匀边界的解,从而减少对捷径的依赖。
另一个方向是显式地建模因果结构。这需要超越纯粹的观测数据,引入干预或反事实推理——这是第六章的主题。
但即使不引入因果推理,我们也可以通过更聪明的训练策略来缓解捷径学习。
八、缓解策略:从数据增强到对抗训练
如果我们知道捷径在哪里,我们能做什么?
策略一:数据增强
最直接的方法是增加训练数据的多样性,打破虚假相关性。
比如,在奶牛识别的例子里,如果你能收集到足够多的”奶牛在沙滩上”的图片,模型就不会过度依赖”草地背景”这个捷径。
但这个方法有两个问题:
第一,你需要知道捷径是什么。在真实场景里,捷径往往是隐蔽的——你不知道模型在利用什么虚假相关性。
第二,即使你知道捷径,收集足够多样的数据可能非常昂贵或不可行。
策略二:重加权训练样本
如果某些训练样本”太容易”——模型可以用捷径就预测对——那么降低这些样本的权重,强迫模型学习更难的样本。
这是Li等人在2020年提出的Tilted ERM的思路。通过引入一个”倾斜”参数
当
通过调整
策略三:对抗训练
另一个思路是显式地生成”对抗样本”——那些模型会依赖捷径而失败的样本——然后在这些样本上训练。
Sricharan和Srivastava在2018年提出:用GAN生成模型高置信度但实际上是OOD的样本,然后最大化模型在这些样本上的熵(不确定性)。
这强迫模型不要对分布外的输入过度自信,从而减少对捷径的依赖。
策略四:因果正则化
如果我们有关于因果结构的先验知识,可以把它编码进正则化项。
比如,如果我们知道某个特征
这里
但这些方法都有一个共同的局限:它们需要某种形式的监督信号——要么是关于捷径的先验知识,要么是OOD数据,要么是人工标注的难样本。
在完全无监督的情况下,检测和缓解捷径学习仍然是一个开放问题。
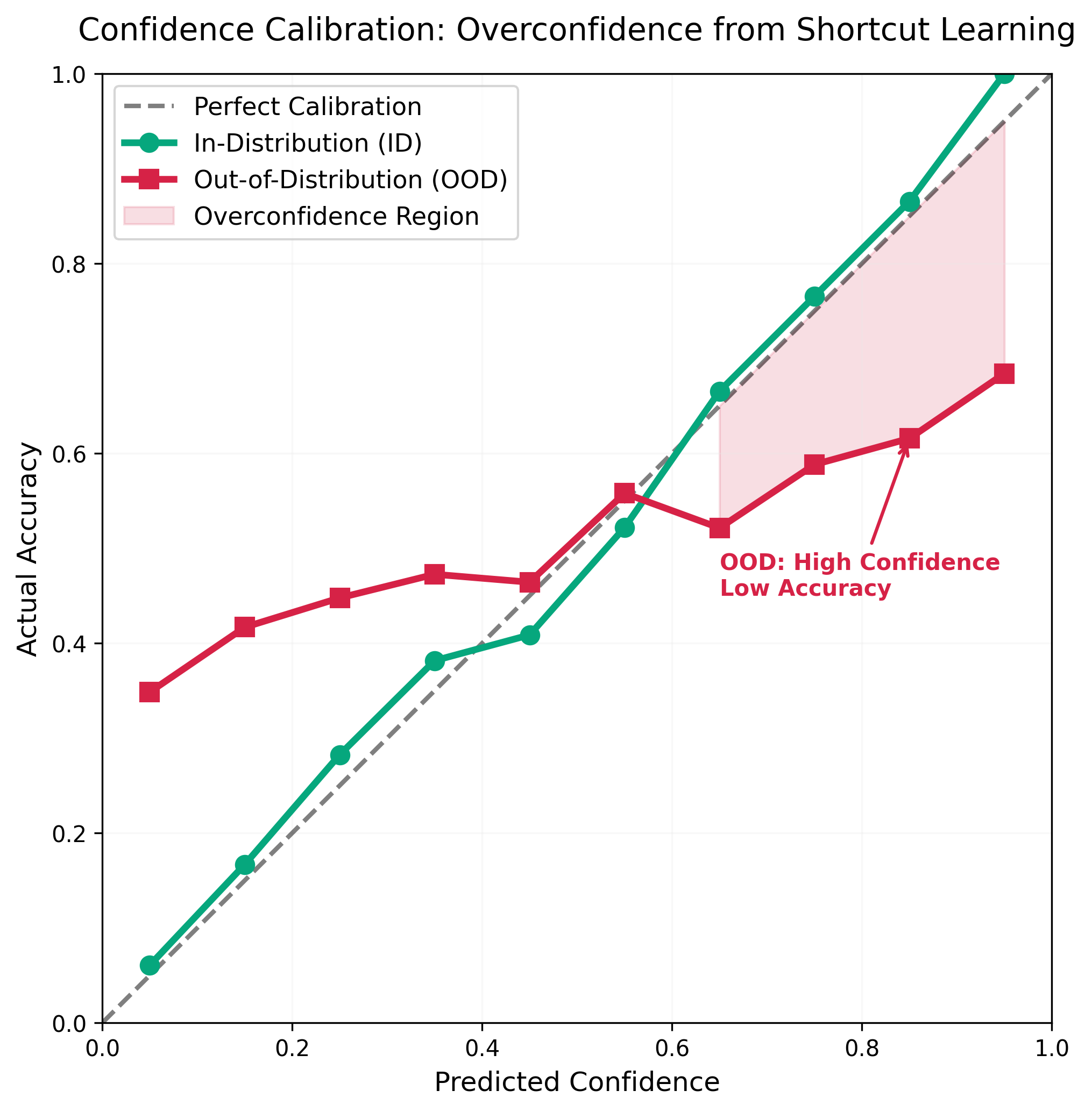
图3:置信度校准曲线展示了捷径学习最危险的后果——过度自信。ID数据(绿色)沿对角线良好校准,而OOD数据(红色)严重偏离:模型在高置信度(0.8-0.9)下的实际准确率仅为0.6-0.7。阴影区域表示过度自信区域,模型在此区域自信地给出错误预测,没有任何不确定性警告。
九、伪代码:捷径检测与OOD泛化测试
让我把前面讨论的核心算法形式化。
算法1:基于梯度的捷径检测
import torch
def shortcut_detection(model, dataloader, shortcut_indices, stable_indices, tau=0.5):
"""
基于梯度的捷径检测。
shortcut_indices: 捷径特征在输入中的列索引列表
stable_indices: 稳定特征在输入中的列索引列表
返回: 捷径依赖分数 S(越高说明越依赖捷径)
"""
model.eval()
ratios = []
criterion = torch.nn.CrossEntropyLoss()
for x, y in dataloader:
x = x.requires_grad_(True)
output = model(x)
loss = criterion(output, y)
loss.backward()
g = x.grad # shape: (batch, n_features)
g_c = g[:, shortcut_indices].norm(dim=1) # 捷径特征梯度范数
g_s = g[:, stable_indices].norm(dim=1) # 稳定特征梯度范数
ratio = g_c / (g_s + 1e-8)
ratios.append(ratio.detach())
S = torch.cat(ratios).mean().item()
if S > tau:
print(f"S={S:.3f} > τ={tau}:模型显著依赖捷径特征")
else:
print(f"S={S:.3f} ≤ τ={tau}:模型主要依赖稳定特征")
return S这个算法的直觉是:如果模型过度依赖捷径,那么损失对捷径特征的梯度会很大——因为改变捷径特征会显著影响预测。
算法2:分布偏移下的泛化测试
def generalization_test(model, id_loader, ood_loader, device="cpu"):
"""
在 ID 和 OOD 测试集上评估模型,报告泛化差距。
"""
def evaluate(loader):
model.eval()
correct, total, high_conf_wrong = 0, 0, 0
with torch.no_grad():
for x, y in loader:
x, y = x.to(device), y.to(device)
logits = model(x)
probs = torch.softmax(logits, dim=1)
pred = probs.argmax(dim=1)
conf = probs.max(dim=1).values
correct += (pred == y).sum().item()
# 高置信但预测错的样本(过度自信检测)
high_conf_wrong += ((conf > 0.8) & (pred != y)).sum().item()
total += y.size(0)
return correct / total, high_conf_wrong / total
acc_id, hcw_id = evaluate(id_loader)
acc_ood, hcw_ood = evaluate(ood_loader)
gap = acc_id - acc_ood
print(f"ID 准确率: {acc_id:.1%}")
print(f"OOD 准确率: {acc_ood:.1%}")
print(f"泛化差距: {gap:.1%}")
if gap < 0.05:
print("→ 泛化良好,模型可能学到了稳定特征")
elif gap < 0.20:
print("→ 泛化中等,部分依赖捷径")
else:
print("→ 泛化差,模型严重依赖捷径")
if hcw_ood > 0.1:
print(f"⚠ OOD 高置信错误率 {hcw_ood:.1%},存在过度自信")
return acc_id, acc_ood, gap算法3:Tilted ERM训练
import torch
import torch.nn as nn
def tilted_erm_train(model, dataloader, t=5.0, lr=1e-3, epochs=50):
"""
Tilted ERM 训练:给困难样本更高权重,减少捷径依赖。
t > 0:越大越关注高损失样本;t = 0 退化为标准 ERM。
"""
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss(reduction="none")
for epoch in range(epochs):
model.train()
for x, y in dataloader:
losses = criterion(model(x), y) # 每样本损失
# Tilted 损失:log-sum-exp 软化最大值
tilted_loss = (1.0 / t) * torch.log(
(1.0 / len(losses)) * torch.sum(torch.exp(t * losses))
)
optimizer.zero_grad()
tilted_loss.backward()
optimizer.step()
return model当
十、一个小小的停顿
让我梳理一下这一章做了什么。
经验风险最小化是监督学习的标准范式。它的理论保证建立在一个关键假设上:训练数据和测试数据来自同一个分布。
但这个假设在现实中几乎从不成立。分布偏移是常态,不是例外。
当分布偏移发生时,ERM学到的那些”在训练数据上有效的相关性”可能完全失效。这不是bug,这是ERM的结构性特征:ERM优化的是统计相关性,而不是因果机制。
捷径学习是这个问题的具体表现:模型学会了利用训练数据中的虚假相关性,而不是真正的因果特征。更糟糕的是,即使虚假特征不提供任何额外信息,梯度下降+交叉熵的归纳偏置仍然会让模型依赖它们——因为这样可以最大化分类边界。
随机鹦鹉假说指出:大型语言模型可能只是在做复杂的统计模式匹配,而不是真正的推理。分布偏移下的脆弱性——比如CoT推理在任务、长度、格式偏移下的崩溃——支持了这个假说。
缓解捷径学习的方法包括数据增强、样本重加权、对抗训练、因果正则化。但所有这些方法都需要某种形式的监督信号。在完全无监督的情况下,检测和缓解捷径学习仍然是开放问题。
这引出了第六章的核心问题:如果统计相关性不够,我们需要什么?答案是因果推理——不只是观测
相关性是捷径,不是推理。下一章,我们将正面回答:什么是因果?以及为什么观测数据永远无法告诉你答案。
悬而未决
大型语言模型的”涌现能力”是真正的质变,还是复杂模式匹配的量变?当模型规模继续增长,这个问题的答案会改变吗?
在完全无监督的情况下,是否存在通用的方法来检测捷径学习?还是说检测捷径本质上需要关于任务的先验知识?
ERM的归纳偏置(最大边界)在什么条件下是有益的,在什么条件下是有害的?是否存在一个统一的框架来刻画这个权衡?
如果我们用纯粹随机的数据训练一个神经网络,它会学到什么样的”捷径”?这个思想实验能告诉我们关于捷径学习的本质吗?
人类学习是否也存在捷径学习?如果存在,人类是如何克服它的?这对设计更好的机器学习算法有什么启示?
自己动手:构造一个捷径陷阱,然后看着模型掉进去
这一章说的核心命题是:ERM会利用训练数据中的任何相关性,不管这个相关性是否因果。你要亲手验证这件事——不是读懂它,是看着它发生。
第一步:设计你的捷径数据集
选择一个简单的二分类任务,然后故意在数据中植入一个捷径。
选项A:图像分类(推荐)
任务:区分两类简单图形(比如圆形 vs 方形)
捷径设计: - 训练集:90%的圆形放在图像左半边,90%的方形放在图像右半边 - 测试集(ID):保持同样的位置偏见 - 测试集(OOD):反转位置——圆形在右,方形在左
选项B:文本分类
任务:情感分类(正面 vs 负面)
捷径设计: - 训练集:在90%的正面评论末尾加上”推荐!“,90%的负面评论末尾加上”不推荐” - 测试集(ID):保持同样的标记 - 测试集(OOD):移除所有标记,只保留评论正文
你的第一个问题(在生成数据之前回答): 你认为模型会学到什么?它会依赖位置/标记(捷径),还是形状/语义(稳定特征)?为什么?
第二步:训练一个标准ERM模型
用最简单的架构: - 图像:2-3层卷积网络 - 文本:简单的LSTM或Transformer
训练目标:最小化交叉熵损失,直到训练准确率 > 95%
不要做任何特殊处理——就是标准的梯度下降+交叉熵。
记录: - 训练曲线(loss vs epoch) - 最终训练准确率
第三步:在三个测试集上评估
import numpy as np
import torch
import torch.nn as nn
from sklearn.metrics import accuracy_score
# ── 辅助函数:评估模型准确率 ────────────────────────────────────
def evaluate(model, dataloader, device='cpu'):
"""返回模型在给定数据集上的准确率(0~1)。"""
model.eval()
all_preds, all_labels = [], []
with torch.no_grad():
for X_batch, y_batch in dataloader:
X_batch = X_batch.to(device)
logits = model(X_batch)
preds = logits.argmax(dim=1).cpu().numpy()
all_preds.extend(preds)
all_labels.extend(y_batch.numpy())
return accuracy_score(all_labels, all_preds)
# 1. ID 测试集(和训练集同分布,捷径依然存在)
acc_id = evaluate(model, test_id_loader)
print(f"ID 测试集准确率:{acc_id:.3f}")
# 2. OOD 测试集(捷径失效:位置/标记被反转)
acc_ood = evaluate(model, test_ood_loader)
print(f"OOD 测试集准确率:{acc_ood:.3f}")
# 3. 无捷径基线(可选):用捷径相关性=50% 的数据重新训练,再评估 OOD
# train_baseline = 重新生成捷径相关性为 50%(随机)的训练集
# model_baseline = 训练新模型(同样架构,同样超参数)
# acc_baseline_ood = evaluate(model_baseline, test_ood_loader)
# print(f"无捷径基线 OOD 准确率:{acc_baseline_ood:.3f}")
# 4. 计算泛化差距
gap = acc_id - acc_ood
print(f"\n泛化差距(ID - OOD):{gap:.3f}")
if gap < 0.05:
print("→ 泛化良好,模型可能学到了稳定特征")
elif gap < 0.20:
print("→ 部分依赖捷径,泛化能力中等")
else:
print("→ 严重依赖捷径,模型掉进陷阱了!")你的第二个问题: 泛化差距有多大?如果 gap > 30%,说明模型严重依赖捷径。你的模型掉进陷阱了吗?
第四步:可视化模型在看什么
对于图像: 用梯度类激活图(Grad-CAM)或简单的显著性图,看模型在做预测时关注图像的哪个区域。
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
# ── 基于梯度的显著性图(适用于图像分类模型)────────────────────
def saliency_map(model, x_sample, target_class):
"""
计算预测对输入像素的梯度绝对值,作为显著性。
x_sample: shape=(1, C, H, W) 的张量,requires_grad 将被启用
target_class: 目标类别的索引(0 或 1)
返回 shape=(H, W) 的显著性图(各通道取最大值)
"""
model.eval()
x = x_sample.clone().detach().requires_grad_(True) # 启用梯度追踪
# 前向传播得到预测概率
logits = model(x)
y_hat = logits[0, target_class] # 取目标类别的 logit
# 反向传播,计算 y_hat 对输入 x 的梯度
model.zero_grad()
y_hat.backward()
# 取梯度的绝对值,跨通道取最大值得到二维显著性图
saliency = x.grad.data.abs() # shape=(1, C, H, W)
saliency, _ = saliency.max(dim=1) # shape=(1, H, W)
saliency = saliency.squeeze().numpy() # shape=(H, W)
return saliency
# 从 OOD 测试集中取一个样本,看模型关注哪里
sample_x, sample_y = next(iter(test_ood_loader)) # 取一个 batch
x0 = sample_x[0:1] # 第一张图,shape=(1, C, H, W)
pred_class = model(x0).argmax(dim=1).item()
sal = saliency_map(model, x0, target_class=pred_class)
# 可视化:把显著性叠加在原图上
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# 左:原始图像(如果是单通道灰度图)
axes[0].imshow(x0.squeeze().detach().numpy(), cmap='gray')
axes[0].set_title(f'原图(真实类别={sample_y[0].item()},预测={pred_class})')
axes[0].axis('off')
# 右:显著性热力图
im = axes[1].imshow(sal, cmap='hot')
axes[1].set_title('显著性图(模型关注区域)')
axes[1].axis('off')
plt.colorbar(im, ax=axes[1])
plt.suptitle('如果显著性集中在图像左/右半边,说明模型在看位置捷径')
plt.tight_layout()
plt.show()
# 如果模型依赖位置捷径,显著性会集中在左/右半边,
# 而不是形状的边缘。对于文本: 计算每个词对预测的贡献(通过遮挡或梯度)。
如果模型依赖”推荐!“这个词,那么遮挡这个词会导致预测翻转,而遮挡其他词影响很小。
你的第三个问题: 模型的注意力/显著性分布在哪里?它在看捷径,还是在看稳定特征?
第五步:测试置信度校准
模型在OOD数据上失败时,它知道自己在失败吗?
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
# ── 置信度分析:比较 ID 和 OOD 数据上的 softmax 最大概率 ───────
def get_confidence_and_accuracy(model, dataloader):
"""
返回每个样本的最大 softmax 概率(置信度)和是否预测正确。
"""
model.eval()
confidences, corrects = [], []
with torch.no_grad():
for X_batch, y_batch in dataloader:
logits = model(X_batch)
probs = F.softmax(logits, dim=1) # 转为概率分布
conf, pred = probs.max(dim=1) # 最大概率即为置信度
corrects.extend((pred == y_batch).numpy())
confidences.extend(conf.numpy())
return np.array(confidences), np.array(corrects)
# 在 ID 和 OOD 数据上分别计算置信度
conf_id, correct_id = get_confidence_and_accuracy(model, test_id_loader)
conf_ood, correct_ood = get_confidence_and_accuracy(model, test_ood_loader)
# 打印汇总统计
print(f"ID 数据 — 准确率: {correct_id.mean():.3f},平均置信度: {conf_id.mean():.3f}")
print(f"OOD 数据 — 准确率: {correct_ood.mean():.3f},平均置信度: {conf_ood.mean():.3f}")
# 画置信度直方图
fig, axes = plt.subplots(1, 2, figsize=(12, 4), sharey=True)
axes[0].hist(conf_id, bins=20, color='steelblue', edgecolor='white', alpha=0.85)
axes[0].set_title(f'ID 数据置信度分布\n(准确率={correct_id.mean():.2f})')
axes[0].set_xlabel('最大 softmax 概率')
axes[0].set_ylabel('样本数')
axes[1].hist(conf_ood, bins=20, color='tomato', edgecolor='white', alpha=0.85)
axes[1].set_title(f'OOD 数据置信度分布\n(准确率={correct_ood.mean():.2f})')
axes[1].set_xlabel('最大 softmax 概率')
plt.tight_layout()
plt.show()
# 诊断:过度自信判断
if conf_ood.mean() > 0.8 and correct_ood.mean() < 0.5:
print("⚠ 过度自信!OOD 数据:高置信度 + 低准确率 → 模型在自信地犯错(危险!)")
elif conf_ood.mean() < 0.6:
print("✓ 模型知道自己不确定(OOD 置信度较低),相对安全")
else:
print("OOD 置信度适中,请结合准确率综合判断")
# 对比小结:
# - ID 数据:高准确率 + 高置信度 → 正常
# - OOD 数据:低准确率 + 高置信度 → 过度自信(危险!)
# - OOD 数据:低准确率 + 低置信度 → 模型知道自己不确定(相对安全)你的第四个问题(核心问题): 模型在OOD数据上的平均置信度是多少?如果置信度仍然很高(> 0.8),但准确率很低(< 0.5),说明模型在自信地犯错——这是捷径学习最危险的后果。
第六步(可选):尝试一种缓解方法
选择本章第八节提到的一种方法:
方法A:数据增强 在训练集中加入一些”反捷径”样本(比如圆形在右边,方形在左边),比例从10%逐步增加到50%,观察泛化差距如何变化。
方法B:样本重加权 实现简化版的Tilted ERM:给那些”太容易”的样本(模型已经高置信度预测对)降低权重。
观察:缓解方法是否减少了泛化差距?代价是什么(训练时间?ID准确率下降?)?
检验标准
完成这个练习,你应该能回答:
你的模型是否掉进了捷径陷阱?泛化差距有多大?
模型的注意力/显著性是否集中在捷径特征上?
模型在OOD数据上是否过度自信?
如果你尝试了缓解方法,它是否有效?代价是什么?
如果你只做一件事,做第四步。那是最短、但最能让你直觉化理解”模型在看什么”的实验。
延伸阅读
Bender, E. M., et al. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? — “随机鹦鹉”假说的原始论文,引发了关于大型语言模型本质的广泛讨论
Hodel, D. & West, J. (2023). Response: Emergent analogical reasoning in large language models — 对GPT-3”涌现推理能力”的批判性反驳,展示了分布偏移下的脆弱性
→ [arXiv:2308.16118]Geirhos, R., et al. (2020). Shortcut Learning in Deep Neural Networks — 捷径学习的系统性综述,涵盖视觉、语言、语音等多个领域
Puli, A., et al. (2023). Don’t blame Dataset Shift! Shortcut Learning due to Gradients and Cross Entropy — 揭示梯度下降+交叉熵的归纳偏置如何导致捷径学习
→ [arXiv:2308.12553]Zhao, C., et al. (2025). Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens — DataAlchemy实验,证明CoT推理是训练分布的脆弱镜像
→ [arXiv:2508.01191]Li, T., et al. (2020). Tilted Empirical Risk Minimization — 通过调整样本权重来平衡鲁棒性和公平性
→ [arXiv:2007.01162]Sricharan, K. & Srivastava, A. (2018). Building robust classifiers through generation of confident out of distribution examples — 用GAN生成OOD样本进行对抗训练
→ [arXiv:1812.00239]Woodland, M., et al. (2024). Dimensionality Reduction and Nearest Neighbors for Improving Out-of-Distribution Detection in Medical Image Segmentation — 医学图像中的OOD检测与捷径学习
→ [arXiv:2408.02761]Vapnik, V. & Chervonenkis, A. (1971). On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities — 统计学习理论的奠基性工作,ERM的理论基础
Pearl, J. (2009). Causality: Models, Reasoning, and Inference — 因果推理的经典教材,理解统计相关性与因果性区别的必读