第6章:因果的边界——观测数据永远不够
你观测了一千次日出。这能证明明天太阳会升起吗?休谟说:不能。
一、归纳的幽灵
1748年,大卫·休谟在《人类理解研究》里提出了一个让人不安的问题:
我们凭什么相信未来会像过去一样?
太阳每天升起,这是事实。我们观测了一千次、一万次日出。但这能证明明天太阳会升起吗?
休谟的答案是:不能。
从逻辑上讲,“过去太阳每天升起”和”明天太阳会升起”之间,没有必然的推导关系。你能想象一个世界,在那里太阳升起了一万次,然后在第一万零一次停止了——这个想象不包含逻辑矛盾。
这就是归纳问题(Problem of Induction):从有限的观测,我们无法逻辑地推导出普遍规律。
休谟的论证在哲学史上引发了巨大的震动,因为它触及了科学方法的根基。科学依赖归纳——从实验数据推导出自然定律。如果归纳在逻辑上不可靠,科学的地位是什么?
三百年后,这个问题以一种更技术化的形式回来了:从观测数据,我们能推导出因果关系吗?
答案依然是:不能。
这一章要讲的,就是这个”不能”的精确含义,以及我们如何在这个限制下依然做出有用的推断。
二、相关性的陷阱
让我从一个经典的例子开始。
在1950年代,流行病学家观测到一个强烈的统计相关性:吸烟者的肺癌发病率显著高于非吸烟者。
这能证明吸烟导致肺癌吗?
烟草公司的律师说:不能。他们提出了一个替代解释:也许存在某个隐藏变量——比如基因型——同时导致了”喜欢吸烟”和”易患肺癌”。在这个解释下,吸烟和肺癌之间没有因果关系,它们只是共同原因的两个结果。
用因果图来表示:
假说1(因果):
吸烟 → 肺癌
假说2(混淆):
基因型 → 吸烟
基因型 → 肺癌
在假说2里,吸烟和肺癌之间的相关性是虚假的(spurious)——它们在统计上相关,但没有直接的因果联系。
关键问题是:仅凭观测数据,你能区分这两个假说吗?
答案是:不能。
如果基因型是不可观测的(在1950年代确实如此),那么这两个假说在所有观测数据上的预测是完全相同的。它们是观测等价(observationally equivalent)的。
这不是数据量的问题。你可以观测一百万个样本,相关性会变得更显著,但你依然无法确定因果方向——因为观测数据只能告诉你变量之间的联合分布
观测和干预,是两个不同的问题。
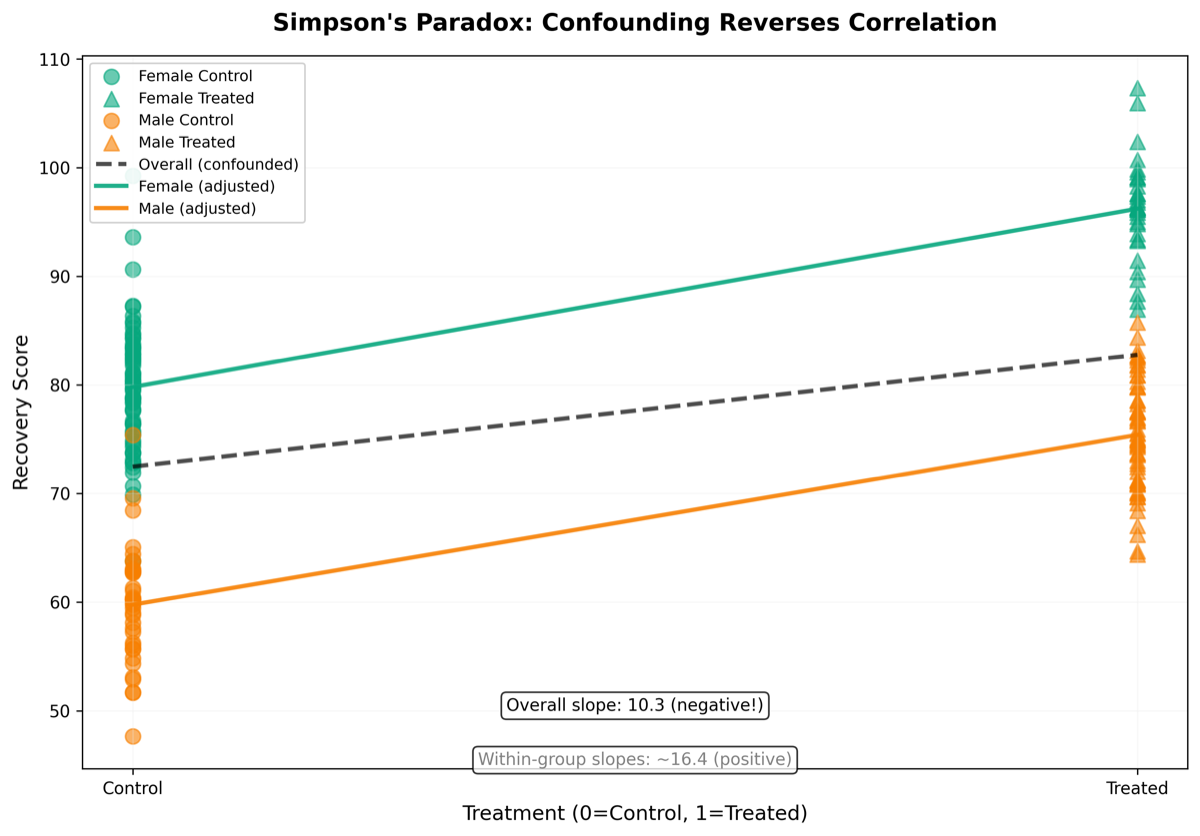
图2:辛普森悖论的几何表现。总体回归线(黑色虚线)斜率为负——治疗组康复率反而更低。但按性别分层后,女性内部(蓝线)和男性内部(红线)的治疗效应均为正。混淆变量(性别)同时影响了治疗概率和基线康复率,扭曲了总体相关性的方向。后门调整消除混淆后,因果效应恢复正确符号。
三、贝叶斯网络:概率的因果外衣
在讲Pearl的因果理论之前,我们需要先理解贝叶斯网络——因为它是结构因果模型的前身,也是它的陷阱。
贝叶斯网络(Bayesian Network)是一个有向无环图(DAG),节点是随机变量,边表示条件依赖关系。
给定一个贝叶斯网络
这个分解有一个漂亮的性质:它把高维联合分布拆成了一系列低维条件分布的乘积,大大减少了需要估计的参数数量。
但这里有一个微妙的地方:贝叶斯网络的边,不一定是因果关系。
贝叶斯网络只是对联合分布的一种分解方式。同一个联合分布,可以对应多个不同的贝叶斯网络——只要它们编码了相同的条件独立性。
举个例子。考虑三个变量:
真实的因果结构是:
B → A ← E
入室盗窃或地震都会触发警报。
但从纯粹的概率角度,以下结构也可以编码相同的条件独立性:
A → B, A → E
警报响了,增加了入室盗窃和地震的概率。
这两个网络在观测数据上是等价的——它们对应相同的联合分布
第一个网络说:干预
第二个网络说:干预
贝叶斯网络是概率模型,不是因果模型。 它的边表示的是条件依赖,不是因果流。
Pearl的贡献,就是在贝叶斯网络的基础上,加入了因果语义——把边解释为因果关系,然后定义在这个解释下,干预和反事实意味着什么。
停顿一下
贝叶斯网络的边不是因果关系——这已经够让人不安的了。
但还有更深的问题:即使你有了Pearl的因果图,你怎么知道这张图是对的?
因果图本身是你画的,是你对世界结构的先验假设。数据可以告诉你哪些变量是条件独立的,但这只能缩小可能的因果图的范围,无法唯一确定一张图。
这意味着:因果推断的所有结论,都建立在一个无法从数据中验证的假设之上——你画的那张图。
如果图画错了,do算子算出来的干预效果也是错的。你得到的是一个内部自洽的错误答案。
那么,我们凭什么相信自己画的因果图?经验?直觉?领域知识?
这些都是答案,但它们都不是从数据里来的。
先把这个问题放着。
四、Pearl的因果阶梯
Judea Pearl在2000年出版的《Causality》一书里,提出了一个三层的因果推理框架,后来被称为因果阶梯(Ladder of Causation)。
第一层:观测(Association)
问题形式:
“看到
这是纯粹的统计问题。给定数据,你可以估计条件概率。机器学习的绝大多数任务都在这一层:给定特征
第二层:干预(Intervention)
问题形式:
“如果我强制设定
这里的
举个例子:
可能很高——因为病情轻的人更可能吃药,而病情轻的人本来就更可能康复。 是药物的真实因果效应——如果我们随机分配谁吃药,吃药组的康复率是多少。
第一个是观测性的,第二个是干预性的。混淆两者,是医学研究中最常见的错误之一。
第三层:反事实(Counterfactual)
问题形式:
“如果过去
这是最难的一层,因为它涉及对未发生的事情的推理。
例子:
观测:这个病人吃了药,康复了。
反事实:如果这个病人没吃药,他会康复吗?
反事实推理需要的不只是数据,还需要一个结构因果模型——关于世界如何运作的机制性假设。
Pearl的核心论点是:这三层不能互相替代。 你不能用第一层的信息回答第二层的问题,也不能用第二层的信息回答第三层的问题。
每一层都需要更强的假设,更多的结构。

图1:Pearl的因果阶梯。第一层(观测)只需要数据,回答”看到X后Y的概率”。第二层(干预)需要因果图,回答”强制设定X后Y的概率”。第三层(反事实)需要完整的SCM参数,回答”如果过去X不同,Y会如何”。每向上一层,都需要更强的结构假设。
五、结构因果模型:世界的机制蓝图
要回答干预和反事实问题,我们需要结构因果模型(Structural Causal Model, SCM)。
一个SCM由三部分组成:
内生变量
:我们关心的变量 外生变量
:外部的、不可观测的随机扰动 结构方程
:每个内生变量由一个函数决定
这里
例子:吸烟与肺癌
变量: -
结构方程:
G = U_G (基因型由外生因素决定)
S = f_S(G, U_S) (吸烟倾向受基因和其他因素影响)
C = f_C(S, G, U_C) (肺癌受吸烟、基因和其他因素影响)
因果图:
G → S → C
G → C
这个模型编码了一个关于世界的假设:基因型
有了SCM,我们可以定义干预:
干预后的模型变成:
G = U_G
S = s (强制设定)
C = f_C(s, G, U_C)
现在
干预后的联合分布
关键点:
六、do-演算:从观测到干预的桥梁
现在我们到了一个核心问题:给定观测数据,我们能计算干预分布吗?
也就是说,能否从
Pearl的do-演算(do-calculus)给出了答案:在某些条件下,可以。
do-演算包含三条规则,它们允许你在因果图
规则1:插入/删除观测
其中
直觉:如果在干预
规则2:行动/观测交换
其中
直觉:如果
规则3:插入/删除行动
其中
直觉:如果
这三条规则看起来很技术化,但它们的威力在于:它们是完备的。
Pearl和同事证明:如果一个因果效应
反过来,如果do-演算无法推导出
七、后门准则与前门准则
do-演算是理论上的完备工具,但在实践中,我们通常用更直接的准则来判断因果效应是否可识别。
后门准则(Backdoor Criterion)
给定因果图
阻断了所有从 到 的后门路径(包含指向 的边的路径) 中没有 的后代
那么因果效应可以通过调整公式计算:
这就是调整(adjustment):通过对混淆变量
回到吸烟与肺癌的例子:
因果图:
G → S → C
G → C
这就是为什么随机对照试验(RCT)有效:随机分配
前门准则(Frontdoor Criterion)
但如果混淆变量不可观测呢?
Pearl发现了一个巧妙的情况:即使混淆变量不可观测,如果存在一个中介变量
完全中介了 对 的效应( 只通过 影响 ) 阻断了所有从 到 的后门路径 所有从
到 的后门路径被空集阻断
那么因果效应可以通过前门公式计算:
这个公式不需要观测混淆变量——它通过中介变量
例子:吸烟、焦油、肺癌
U → S → T → C
U → C
即使我们无法观测
这是一个深刻的结果:在某些结构下,观测数据足以识别因果效应,即使存在不可观测的混淆。
但”某些结构”是关键——不是所有因果图都满足后门或前门准则。
八、观测等价类:因果图的不可区分性
现在我们到了这一章最关键的地方。 即使你有无限的观测数据,你依然无法唯一确定因果图——因为多个不同的因果图可以产生相同的观测分布。
这些图被称为马尔可夫等价类(Markov Equivalence Class)。
定义: 两个DAG
等价的图有相同的骨架(skeleton,忽略边方向的无向图)和相同的v-结构(v-structure,形如
例子:三个变量的等价类
考虑三个变量 X → Y → Z X ← Y → Z X ← Y ← Z
它们都编码了同一个条件独立性:
从观测数据,你无法区分这三个图——因为它们对应相同的联合分布。
但它们的因果含义完全不同:
- 第一个图:
影响 , 影响 - 第二个图: 同时影响 和 - 第三个图: 影响 , 影响
如果你想知道,这三个图会给出不同的答案。
不可识别性的根源
这不是数据量的问题,不是算法的问题,是结构性的不可能。
观测数据只能告诉你条件独立性——哪些变量在给定其他变量时是独立的。但因果关系不只是独立性,它是关于干预下的行为。
两个图可以有相同的观测分布,但在干预下表现完全不同。
这意味着:仅凭观测数据,因果发现(causal discovery)只能恢复到马尔可夫等价类,无法确定唯一的因果图。
要打破等价类,你需要额外的信息:
- 干预数据:如果你能做实验,强制改变某些变量,观察其他变量的反应,你可以确定因果方向 2. 时间顺序:如果你知道
发生在 之前,那么 是不可能的 3. 函数形式假设:如果你假设因果机制是线性的、或者是加性噪声模型,某些等价类可以被打破 4. 先验知识:如果你知道某些边不可能存在(比如”年龄不能被收入影响”),你可以排除某些图
但如果你只有观测数据,没有任何额外假设,因果图是不可识别的。

图3:马尔可夫等价类示例。三个不同的因果图(X→Y→Z、X←Y→Z、X←Y←Z)编码相同的条件独立性 X⊥ZY,因此在观测数据上完全等价。但它们的因果含义不同:第一个图中 do(X) 会影响 Z,第二个图中不会。仅凭观测数据无法区分它们。
九、忠实性假设:一个脆弱的桥梁
因果发现算法(如PC算法、GES算法)通常依赖两个假设:
假设1:因果马尔可夫条件
给定其父节点,每个变量与其非后代独立。
这是贝叶斯网络的标准假设,通常是合理的。
假设2:忠实性(Faithfulness)
观测分布中的所有条件独立性,都由因果图的d-分离蕴含。
换句话说:如果
这个假设看起来无害,但它其实很强。
反例:参数的巧合抵消
考虑以下因果图和结构方程:
X → Y → Z
X → Z
Y = a·X + U_Y
Z = b·Y + c·X + U_Z
如果参数恰好满足
在这种情况下,观测数据会显示
忠实性假设排除了这种巧合——它假设参数是”一般位置”的,不会恰好抵消。
但在真实世界里,这种巧合可能并不罕见。生物系统、经济系统中存在大量的反馈和平衡机制,它们的参数可能恰好使得某些效应相互抵消。
忠实性失败的后果
如果忠实性不成立,因果发现算法会推断出错误的图结构——它会认为某些边不存在,因为对应的变量在数据中看起来独立,但实际上它们有因果关系,只是效应被抵消了。
这是一个深层的脆弱性:因果发现依赖一个关于参数的假设,而这个假设在数据中是无法被检验的——因为你无法区分”真正的独立”和”巧合的抵消”。
十、反事实:最难的一层
Pearl的因果阶梯的第三层——反事实——是最难的,因为它涉及对未发生的事情的推理。
反事实的定义
给定一个SCM和观测到的证据
“如果
计算反事实需要三个步骤:
步骤1:溯因(Abduction)
根据观测到的证据,更新对外生变量
步骤2:行动(Action)
修改SCM,用
步骤3:预测(Prediction)
在修改后的模型和更新后的
例子:药物的个体因果效应
假设我们有以下SCM:
X = U_X (是否服药,由外生因素决定)
Y = a·X + U_Y (康复情况)
观测:某个病人服药了(
反事实问题:如果这个病人没服药(
步骤1:从
步骤2:干预
步骤3:计算反事实结果:
如果
反事实的不可识别性
关键问题:反事实通常是不可识别的。
即使你知道因果图,即使你有无限的观测数据,你依然无法从数据中唯一确定反事实分布——因为反事实依赖于外生变量
在上面的例子里,如果我们不知道
反事实需要的不只是因果图,还需要参数化的结构方程——这比图结构更强的假设。
这就是为什么反事实推理在实践中很难:它需要一个完整的、参数化的世界模型,而这个模型通常是无法从数据中完全学到的。
十一、伪代码:因果推断的核心算法
让我把前面讨论的核心算法形式化。
算法1:后门调整(Backdoor Adjustment)
import itertools
import numpy as np
def backdoor_adjustment(data, x_col, y_col, z_cols, x_val):
"""
后门调整估计因果效应 P(Y | do(X=x_val))。
data: pandas DataFrame,包含观测数据
x_col: 干预变量列名
y_col: 结果变量列名
z_cols: 调整集列名列表(满足后门准则)
x_val: 干预值
返回: P(Y=1 | do(X=x_val)) 的估计
"""
if not z_cols:
raise ValueError("调整集为空,因果效应不可识别(通过后门调整)")
# 枚举 Z 的所有取值组合
z_values = [data[z].unique() for z in z_cols]
result = 0.0
for z_combo in itertools.product(*z_values):
# 条件概率 P(Y | X=x_val, Z=z_combo)
mask_xz = (data[x_col] == x_val)
for z_col, z_val in zip(z_cols, z_combo):
mask_xz &= (data[z_col] == z_val)
if mask_xz.sum() == 0:
continue
p_y_given_xz = data.loc[mask_xz, y_col].mean()
# 边际概率 P(Z=z_combo)
mask_z = np.ones(len(data), dtype=bool)
for z_col, z_val in zip(z_cols, z_combo):
mask_z &= (data[z_col] == z_val)
p_z = mask_z.mean()
result += p_y_given_xz * p_z
return result十二、一个小小的停顿
让我梳理一下这一章做了什么。
休谟的归纳问题,在三百年后以因果推断的形式回来了:从观测数据,我们能推导出因果关系吗?答案是:不能——至少不能唯一确定。
观测数据只能告诉我们变量之间的联合分布
Pearl的因果阶梯把推理分成三层:观测、干预、反事实。每一层都需要更强的假设。机器学习的绝大多数任务停留在第一层,而真正的因果推理需要第二层或第三层。
结构因果模型(SCM)提供了一个框架,用结构方程和因果图来编码世界的机制。有了SCM,我们可以定义干预(删除指向被干预变量的边)和反事实(溯因-行动-预测三步法)。
do-演算给出了从观测分布推导干预分布的完备规则。后门准则和前门准则是实践中更直接的工具——在某些图结构下,观测数据足以识别因果效应。
但核心的限制依然存在:
马尔可夫等价类:多个因果图可以产生相同的观测分布,仅凭观测数据无法区分它们
忠实性假设:因果发现依赖一个关于参数”一般位置”的假设,这个假设在数据中无法被检验
反事实的不可识别性:反事实推理需要参数化的结构方程,而不只是因果图
这引出了第七章的问题:如果观测数据不够,我们需要什么?答案是干预——主动地改变世界,而不只是被动地观察。随机对照试验(RCT)是因果推断的黄金标准,不是因为它更精确,而是因为它打破了观测的牢笼。
因果推断揭示了观测的局限。下一章,我们将转向另一个边界——计算本身的不对称性:为什么找答案比验证答案难得多?
悬而未决
忠实性假设在真实世界中有多常失败?我们有办法检测忠实性失败吗?
如果两个因果图在马尔可夫等价类中,但给出不同的干预预测,我们应该相信哪一个?这是一个科学选择问题,还是一个哲学问题?
反事实推理需要完整的参数化SCM。在什么条件下,我们可以从数据中学到这些参数?什么时候这是不可能的?
大型语言模型能做因果推理吗?它们从文本中学到的是
还是 ?这个问题的答案,决定了LLM的能力边界。 如果你用纯粹的观测数据训练一个因果发现算法,然后在干预数据上测试,它会系统性地失败在哪里?这个失败模式能告诉我们什么?
自己动手:用辛普森悖论看穿观测的谎言
这一章说的核心命题是:观测数据会撒谎,因为它包含混淆。你要亲手构造一个辛普森悖论(Simpson’s Paradox)的例子,看着同一组数据在不同的分层下给出完全相反的结论。
第一步:生成带混淆的数据
构造以下因果结构:
因果图:
G → T → Y
G → Y
其中:
G = 性别(0=女性,1=男性)
T = 是否接受治疗(0=否,1=是)
Y = 康复情况(连续值,越高越好)
真实的因果机制: - 男性更倾向于接受治疗(因为病情更重) - 治疗有正效应(提高康复率) - 但男性的基线康复率更低(因为病情更重)
import numpy as np
import pandas as pd
np.random.seed(42)
N = 1000 # 样本量
# 生成性别(混淆变量):0=女性,1=男性,各50%
G = np.random.binomial(1, 0.5, N)
# 生成治疗决策(受性别影响)
# 男性病情更重,更倾向于接受治疗
p_treatment = np.where(G == 1, 0.7, 0.3) # 男性 70%,女性 30%
T = np.random.binomial(1, p_treatment, N)
# 生成康复结果(受性别和治疗共同影响)
# 女性基线康复分 80,男性基线 60(男性病情更重)
baseline = 80 - 20 * G # 向量化:每个样本的基线分
treatment_effect = 15 * T # 治疗提高 15 分(真实因果效应)
noise = np.random.normal(0, 5, N) # 随机噪声
Y = baseline + treatment_effect + noise
# 整理为 DataFrame,方便后续分析
df = pd.DataFrame({'G': G, 'T': T, 'Y': Y})
print(f"数据生成完成:{N} 个样本")
print(df.describe().round(2))
print(f"\n真实因果效应(治疗参数)= +15 分")你的第一个问题(在生成数据之前回答): 在这个设定下,治疗的真实因果效应是多少?如果我们随机分配治疗(切断 G → T),治疗组比对照组的康复分数高多少?
第二步:计算观测相关性(不调整混淆)
生成数据后,直接计算:
import pandas as pd
# 不考虑性别混淆,直接比较治疗组和对照组
treated_mean = df[df['T'] == 1]['Y'].mean() # 治疗组均值
untreated_mean = df[df['T'] == 0]['Y'].mean() # 对照组均值
observed_effect = treated_mean - untreated_mean # 观测效应(未调整混淆)
print(f"治疗组均值:{treated_mean:.2f}")
print(f"对照组均值:{untreated_mean:.2f}")
print(f"观测效应(未调整): {observed_effect:.2f}")
print(f"真实因果效应:+15.00")你的第二个问题: 观测效应的符号是什么?它是正的(治疗组更好)还是负的(对照组更好)?这和真实因果效应一致吗?
如果不一致,这就是辛普森悖论——总体层面的相关性,和因果效应的方向相反。
第三步:分层分析(调整混淆)
现在按性别分层,分别计算:
import pandas as pd
# ── 女性组(G=0)内部的治疗效应 ──────────────────────────────
female_treated = df[(df['G'] == 0) & (df['T'] == 1)]['Y'].mean()
female_untreated = df[(df['G'] == 0) & (df['T'] == 0)]['Y'].mean()
effect_female = female_treated - female_untreated
# ── 男性组(G=1)内部的治疗效应 ──────────────────────────────
male_treated = df[(df['G'] == 1) & (df['T'] == 1)]['Y'].mean()
male_untreated = df[(df['G'] == 1) & (df['T'] == 0)]['Y'].mean()
effect_male = male_treated - male_untreated
# ── 后门调整:用性别的边际分布对分层效应加权平均 ─────────────
P_G0 = (df['G'] == 0).mean() # 女性样本比例
P_G1 = (df['G'] == 1).mean() # 男性样本比例
adjusted_effect = P_G0 * effect_female + P_G1 * effect_male # 加权平均
print(f"女性内部效应(G=0): {effect_female:.2f}")
print(f"男性内部效应(G=1): {effect_male:.2f}")
print(f"调整后因果效应(后门调整): {adjusted_effect:.2f}")
print(f"真实因果效应:+15.00")
print(f"观测效应(未调整): {observed_effect:.2f}")你的第三个问题(核心问题): 分层后,每个性别内部的治疗效应是什么符号?它和第二步的观测效应符号相同吗?
如果第二步是负的,但分层后两个性别内部都是正的,你刚刚亲手看到了辛普森悖论:总体相关性和分层因果效应方向相反。
第四步:可视化混淆的几何
画一个散点图,横轴是治疗(0或1),纵轴是康复分数:
import numpy as np
import matplotlib.pyplot as plt
from numpy.polynomial.polynomial import polyfit
fig, ax = plt.subplots(figsize=(9, 6))
# 四个子组的散点(加少量抖动避免重叠)
jitter = 0.04
groups = [
(0, 0, 'royalblue', 'o', '女性 对照组(G=0, T=0)'),
(0, 1, 'royalblue', '^', '女性 治疗组(G=0, T=1)'),
(1, 0, 'tomato', 'o', '男性 对照组(G=1, T=0)'),
(1, 1, 'tomato', '^', '男性 治疗组(G=1, T=1)'),
]
for g_val, t_val, color, marker, label in groups:
mask = (df['G'] == g_val) & (df['T'] == t_val)
t_jittered = df.loc[mask, 'T'] + np.random.uniform(-jitter, jitter, mask.sum())
ax.scatter(t_jittered, df.loc[mask, 'Y'],
c=color, marker=marker, alpha=0.5, s=20, label=label)
# 辅助函数:画 OLS 回归线
def plot_regression(x, y, color, linestyle, label):
coeffs = np.polyfit(x, y, 1) # 线性回归,coeffs=[斜率, 截距]
x_line = np.array([x.min(), x.max()])
ax.plot(x_line, np.polyval(coeffs, x_line),
color=color, linestyle=linestyle, linewidth=2, label=label)
return coeffs[0] # 返回斜率
# 1. 总体回归线(忽略性别)—— 黑色虚线
slope_overall = plot_regression(df['T'].values, df['Y'].values,
'black', '--', '总体回归线(忽略性别)')
# 2. 女性内部回归线 —— 蓝色实线
female_mask = df['G'] == 0
slope_female = plot_regression(df.loc[female_mask, 'T'].values,
df.loc[female_mask, 'Y'].values,
'royalblue', '-', '女性内部回归线')
# 3. 男性内部回归线 —— 红色实线
male_mask = df['G'] == 1
slope_male = plot_regression(df.loc[male_mask, 'T'].values,
df.loc[male_mask, 'Y'].values,
'tomato', '-', '男性内部回归线')
ax.set_xlabel('是否接受治疗(0=否,1=是)')
ax.set_ylabel('康复分数 Y')
ax.set_title('辛普森悖论的几何表现\n总体线向下,但分层内部线向上')
ax.set_xticks([0, 1])
ax.set_xticklabels(['对照(T=0)', '治疗(T=1)'])
ax.legend(fontsize=8, loc='upper left')
print(f"总体回归线斜率:{slope_overall:.2f}({'正' if slope_overall > 0 else '负'}——治疗{'有益' if slope_overall > 0 else '有害'}?)")
print(f"女性内部回归线斜率:{slope_female:.2f}")
print(f"男性内部回归线斜率:{slope_male:.2f}")
plt.tight_layout()
plt.show()你的第四个问题: 总体回归线的斜率是什么符号?女性和男性的内部回归线斜率是什么符号?
如果总体线向下(负斜率),但两条内部线都向上(正斜率),这就是辛普森悖论的几何表现:混淆变量改变了相关性的方向。
第五步:反转因果图,看看会发生什么
现在假设你错误地认为因果图是:
错误的因果图:
T → G → Y
(治疗影响性别?显然荒谬,但我们假装不知道)
在这个错误的图下,后门准则会告诉你:不需要调整任何变量,因为没有后门路径。
# 根据错误的因果图 T → G → Y:
# 因果图认为 T 是 G 的原因,所以 G 不是 T 的混淆变量,
# 后门路径 T←G→Y 不存在(因为箭头方向错了),
# 因此直接用观测相关性作为"因果效应"
# 错误图下的"因果效应"= 直接观测效应(不做任何调整)
wrong_causal_effect = observed_effect # 就是第二步算出的未调整值
print(f"错误因果图下的'因果效应': {wrong_causal_effect:.2f}")
print(f"正确调整后因果效应: {adjusted_effect:.2f}")
print(f"真实因果效应(生成设定): +15.00")
print(f"错误推断与真实值偏差: {abs(wrong_causal_effect - 15):.2f} 分")
print()
print("结论:因果图结构假设错误 → 推断完全偏离真实效应")
print("观测数据本身无法告诉你哪个图是对的。")你的第五个问题: 如果你用错误的因果图,你会得出什么结论?这个结论和真实因果效应差多少?
这说明了本章第八节的核心论点:因果图的结构假设是不可避免的。如果图错了,推断就错了,而观测数据无法告诉你图是否正确。
检验标准
完成这个练习,你应该能回答:
辛普森悖论是如何发生的?混淆变量如何让观测相关性和因果效应方向相反?
后门调整(分层分析)如何消除混淆?为什么分层后的效应更接近真实因果效应?
如果因果图的结构假设错了,后门调整会给出什么结果?错误有多大?
如果你只做一件事,做第四步。那个图会让你一眼看穿混淆是如何扭曲相关性的。
自己动手:手写 do 运算——咖啡真的让你更聪明吗?
辛普森悖论那个练习,你看到了为什么观测数据会撒谎。这个练习更进一步:动手计算
场景:你在一家科技公司的数据团队工作。老板看到数据:喝咖啡的员工代码产出更高。他准备推行"强制每人每天三杯咖啡"的政策。你需要告诉他,观测到的相关性,和强制喝咖啡的真实效果,是不是同一回事。
因果图:
工作压力 (S) ──→ 喝咖啡 (C) ──→ 代码产出 (Y)
│ ↑
└──────────────────────────────┘- S(Stress,工作压力):0=低压,1=高压
- C(Coffee,今天喝了咖啡):0=没喝,1=喝了
- Y(代码产出,行数/小时,连续值)
真实机制:高压员工更想喝咖啡(用咖啡撑着),但高压本身降低产出。咖啡本身对产出只有轻微正效应。
第一步:生成数据,感受混淆
import numpy as np
import pandas as pd
np.random.seed(42)
N = 2000
# 工作压力(混淆变量)
S = np.random.binomial(1, 0.5, N) # 50% 高压
# 喝咖啡(受压力驱动)
p_coffee = np.where(S == 1, 0.80, 0.25) # 高压 80% 喝咖啡,低压 25%
C = np.random.binomial(1, p_coffee, N)
# 代码产出(受压力拖累,咖啡略微提升)
Y = (50 # 基线产出
- 20 * S # 高压降低产出 20 行
+ 5 * C # 咖啡提升产出 5 行(真实因果效应)
+ np.random.normal(0, 8, N))
df = pd.DataFrame({'S': S, 'C': C, 'Y': Y})问题 1:咖啡对产出的真实因果效应是多少?(直接从生成过程读出来。)
第二步:计算观测相关性
# 直接比较喝咖啡 vs 不喝咖啡
obs_effect = df[df.C == 1]['Y'].mean() - df[df.C == 0]['Y'].mean()
print(f"观测效应 P(Y|C=1) - P(Y|C=0) = {obs_effect:.2f}")问题 2:观测效应是正的还是负的?它比真实因果效应大还是小?为什么?
(提示:高压员工既更可能喝咖啡,又产出更低——这会把咖啡和低产出绑在一起。)
第三步:手写 do 运算——后门调整公式
现在你要亲手实现
后门准则告诉我们:S 是 C 和 Y 之间的后门路径(
公式是:
翻译成代码:
def do_calculus(df, intervention_value):
"""
计算 P(Y | do(C = intervention_value))
步骤:
1. 按 S 分层,计算每层内 C=intervention_value 时的 Y 均值
2. 用 S 的边际分布加权平均
这就是"切断 C←S 这条箭头"的代码实现。
"""
result = 0.0
for s_val in [0, 1]:
# 第一层:当 S=s 且 C=intervention_value 时,Y 的期望
# (在这个子集里,C 的值是我们"观测到的",不是干预的)
subset = df[(df['S'] == s_val) & (df['C'] == intervention_value)]
E_Y_given_C_S = subset['Y'].mean()
# 第二层:S=s 的边际概率(从原始数据估计)
P_S = (df['S'] == s_val).mean()
result += E_Y_given_C_S * P_S
return result
# 计算干预效应
E_Y_do_C1 = do_calculus(df, intervention_value=1) # do(C=1)
E_Y_do_C0 = do_calculus(df, intervention_value=0) # do(C=0)
causal_effect = E_Y_do_C1 - E_Y_do_C0
print(f"do(C=1) 时 Y 的期望:{E_Y_do_C1:.2f}")
print(f"do(C=0) 时 Y 的期望:{E_Y_do_C0:.2f}")
print(f"因果效应 P(Y|do(C=1)) - P(Y|do(C=0)) = {causal_effect:.2f}")
print(f"真实因果效应(生成时设定)= 5.00")问题 3:do_calculus 函数和"分层后取加权平均"在做同一件事——它和第二步的直接比较,哪个更接近真实因果效应?
第四步:理解"切断箭头"是什么意思
do 运算的本质,是构造一个干预后的数据集:强制把 C 设成某个值,同时不改变 S(因为 S 是 C 的原因,但 C 不是 S 的原因,所以强制喝咖啡不会改变工作压力)。
# 构造干预数据集:do(C=1)——所有人都喝咖啡
df_do_C1 = df.copy()
df_do_C1['C'] = 1 # 强制所有人喝咖啡
# 注意:不修改 S!S 是外部变量,不受 C 影响
# 在干预数据集上,重新计算 Y(用真实的生成公式)
df_do_C1['Y'] = (50
- 20 * df_do_C1['S']
+ 5 * df_do_C1['C'] # C 现在全是 1
+ np.random.normal(0, 8, N))
# 构造干预数据集:do(C=0)——所有人都不喝咖啡
df_do_C0 = df.copy()
df_do_C0['C'] = 0
df_do_C0['Y'] = (50
- 20 * df_do_C0['S']
+ 5 * df_do_C0['C'] # C 现在全是 0
+ np.random.normal(0, 8, N))
effect_intervention = df_do_C1['Y'].mean() - df_do_C0['Y'].mean()
print(f"直接干预实验的效应估计:{effect_intervention:.2f}")问题 4:do_calculus 函数的结果(第三步)和"直接干预实验"的结果(第四步)应该接近。如果接近,说明什么?如果有差距,差距来自哪里?
第五步:告诉老板真相
print("=" * 50)
print(f"观测相关性(错误依据): {obs_effect:.1f} 行/小时")
print(f"do 运算因果效应(正确依据): {causal_effect:.1f} 行/小时")
print(f"真实因果效应(生成设定): 5.0 行/小时")
print()
print("结论:")
print(f"观测数据显示喝咖啡的员工产出{'高' if obs_effect > 0 else '低'} {abs(obs_effect):.1f} 行")
print("但这个差距大部分来自混淆变量(工作压力)")
print(f"强制喝咖啡政策的真实效果只有约 5 行/小时")最终问题:如果老板推行"强制三杯咖啡"政策,他期待的效果是多少?实际会发生什么?
这就是 do 运算的实际价值:在没有随机对照实验的情况下,从观测数据中估计干预效果。
扩展挑战(选做)
如果你想更深入,试试修改因果图,增加一个对撞节点:
S ──→ C ──→ Y
↗
加班 (O)──→ Y
↑
S加班(O)也受工作压力影响,也影响产出。现在后门路径变了——你需要同时调整 S,但不能调整 O(O 是 C 的下游)。试着修改 do_calculus,处理这个更复杂的图。
延伸阅读
Pearl, J. (2009). Causality: Models, Reasoning, and Inference (2nd ed.) — 因果推断的奠基性著作,完整阐述SCM、do-演算、反事实推理框架
Pearl, J. & Mackenzie, D. (2018). The Book of Why: The New Science of Cause and Effect — 因果阶梯的科普版本,讲述因果革命的历史和哲学
Spirtes, P., Glymour, C. & Scheines, R. (2000). Causation, Prediction, and Search — 因果发现算法的经典教材,PC算法、FCI算法的原始来源
Peters, J., Janzing, D. & Schölkopf, B. (2017). Elements of Causal Inference — 从机器学习角度讲因果推断,包含独立因果机制、加性噪声模型
→ [MIT Press]Hume, D. (1748). An Enquiry Concerning Human Understanding — 归纳问题的哲学起点,“过去不能证明未来”
Hernán, M. A. & Robins, J. M. (2020). Causal Inference: What If — 流行病学和医学中的因果推断,强调干预与观测的区别
→ [Free online]Schölkopf, B. et al. (2021). Toward Causal Representation Learning — 因果推断与深度学习的交叉,如何从数据中学习因果结构
→ [arXiv:2102.11107]Bareinboim, E. & Pearl, J. (2016). Causal inference and the data-fusion problem — 如何从多个异质数据源中识别因果效应
→ [PNAS]Zhang, K. & Hyvärinen, A. (2009). On the Identifiability of the Post-Nonlinear Causal Model — 非线性因果模型的可识别性,打破马尔可夫等价类的方法
→ [UAI 2009]Uhler, C., Raskutti, G., Bühlmann, P. & Yu, B. (2013). Geometry of the faithfulness assumption in causal inference — 忠实性假设的几何分析,何时会失败
→ [arXiv:1207.0547]