第18章 概率潜在语义分析
习题18.1
证明生成模型与共现模型是等价的。
解答:
解答思路:
- 生成模型的定义
- 共现模型的定义
- 证明生成模型与共现模型是等价的
解答步骤:
第1步:生成模型
根据书中第18.1.2节的生成模型的定义:
假设有单词集合
,其中 是单词个数;文本(指标)集合 ,其中 是文本个数;话题集合 ,其中 是预先设定的话题个数。随机变量 取值于单词集合;随机变量 取值于文本集合,随机变量 取值于话题集合。概率分布 、条件概率分布 、条件概率分布 皆属于多项分布,其中 表示生成文本 的概率, 表示文本 生成话题 的概率, 表示话题 生成单词 的概率。 每个单词-文本对
的生成概率由以下公式决定: 即生成模型的定义。
生成模型假设在话题给定条件下,单词 与文本 条件独立,即
第2步:共现模型
根据书中第18.1.3节的共现模型的定义:
每个单词-文本对
的概率由以下公式决定: 即共现模型的定义。
共现模型假设在话题给定条件下,单词 与文本 是条件独立的,即
第3步:证明生成模型与共现模型是等价的
结合公式(1)和公式(2),可得:
可知生成模型与共现模型的概率公式是等价的,故证得生成模型与共现模型是等价的。
习题18.2
推导共现模型的EM算法。
解答:
解答思路:
- EM算法的一般步骤
- 推导共现模型的
函数 - 推导共现模型的E步
- 推导共现模型的M步
- 写出共现模型的EM算法
解答步骤:
第1步:EM算法
根据书中第18.2节的EM算法介绍:
EM算法是一种迭代算法,每次迭代包括交替的两步:E步,求期望;M步,求极大。E步是计算
函数,即完全数据的对数似然函数对不完全数据的条件分布的期望。M步是对 函数极大化,更新模型参数。详细介绍见第9章。
第2步:推导共现模型的
设单词集合为
根据书中第18.1.3节的共现模型定义:
文本-单词共现数据
的生成概率为所有单词-文本对 的生成概率的乘积: 每个单词-文本对
的概率由以下公式决定: 即共现模型的定义。
对公式(1)使用极大似然估计,结合公式(2),对数似然函数是
由于Jessen不等式,得:
可以得到
第3步:推导共现模型的E步
根据贝叶斯公式计算
第4步:推导共现模型的M步
通过约束最优化求解
使用拉格朗日法,引入拉格朗日乘子
将拉格朗日函数
解方程组得M步的参数估计公式:
第5步:共现模型的EM算法
输入:设单词集合为
输出:
(1)设置参数
(2)迭代执行以下E步、M步,直到收敛为止。
E步:
M步:
习题18.3
对以下文本数据集进行概率潜在语义分析。 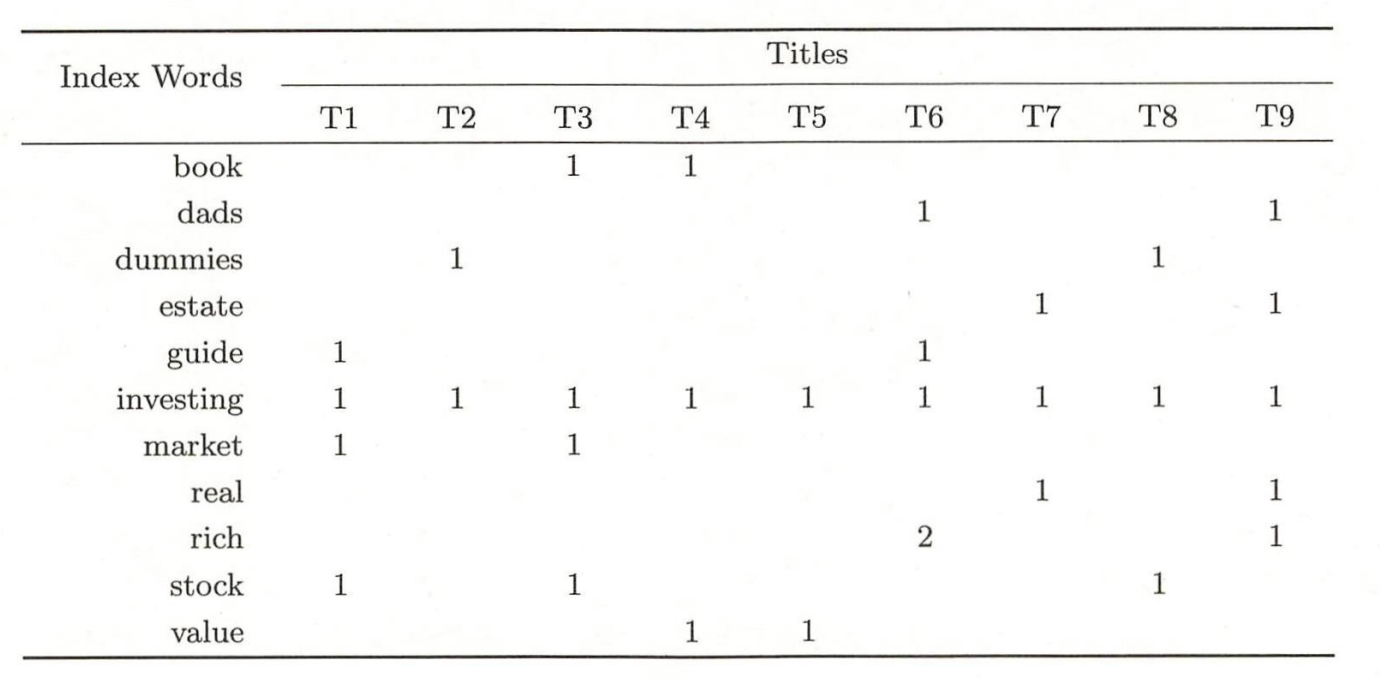
解答:
解答思路:
- 给出概率潜在语义模型参数估计的EM算法
- 自编程实现概率潜在语义模型参数估计的EM算法
- 对文本数据集进行概率潜在语义分析
解答步骤:
第1步:概率潜在语义模型参数估计的EM算法
根据书中第18章的算法18.1的概率潜在语义模型参数估计的EM算法:
算法18.1(概率潜在语义模型参数估计的EM算法)
输入:设单词集合为,文本集合为 ,话题集合为 ,共现数据 ;
输出:和 。
(1)设置参数和 的初始值。
(2)迭代执行以下E步、M步,直到收敛为止。
E步:M步:
第2步:自编程实现概率潜在语义模型参数估计的EM算法
import numpy as np
class EMPlsa:
def __init__(self, max_iter=100, random_state=2022):
"""
基于生成模型的EM算法的概率潜在语义模型
:param max_iter: 最大迭代次数
:param random_state: 随机种子
"""
self.max_iter = max_iter
self.random_state = random_state
def fit(self, X, K):
"""
:param X: 单词-文本矩阵
:param K: 话题个数
:return: P(w_i|z_k) 和 P(z_k|d_j)
"""
# M, N分别为单词个数和文本个数
M, N = X.shape
# 计算n(d_j)
n_d = [np.sum(X[:, j]) for j in range(N)]
# (1)设置参数P(w_i|z_k)和P(z_k|d_j)的初始值
np.random.seed(self.random_state)
p_wz = np.random.random((M, K))
p_zd = np.random.random((K, N))
# (2)迭代执行E步和M步,直至收敛为止
for _ in range(self.max_iter):
# E步
P = np.zeros((M, N, K))
for i in range(M):
for j in range(N):
for k in range(K):
P[i][j][k] = p_wz[i][k] * p_zd[k][j]
P[i][j] /= np.sum(P[i][j])
# M步
for k in range(K):
for i in range(M):
p_wz[i][k] = np.sum([X[i][j] * P[i][j][k] for j in range(N)])
p_wz[:, k] /= np.sum(p_wz[:, k])
for k in range(K):
for j in range(N):
p_zd[k][j] = np.sum([X[i][j] * P[i][j][k] for i in range(M)]) / n_d[j]
return p_wz, p_zd第3步:对文本数据集进行概率潜在语义分析
# 输入文本-单词矩阵,共有9个文本,11个单词
X = np.array([[0, 0, 1, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 1],
[0, 1, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 1],
[0, 0, 0, 0, 0, 2, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 1, 1, 0, 0, 0, 0]])
# 设置精度为3
np.set_printoptions(precision=3, suppress=True)
# 假设话题的个数是3个
k = 3
em_plsa = EMPlsa(max_iter=100)
p_wz, p_zd = em_plsa.fit(X, 3)
print("参数P(w_i|z_k):")
print(p_wz)
print("参数P(z_k|d_j):")
print(p_zd)参数P(w_i|z_k):
[[0. 0.162 0. ]
[0. 0. 0.2 ]
[0.116 0.081 0. ]
[0.115 0. 0.1 ]
[0. 0.081 0.1 ]
[0.423 0.271 0.2 ]
[0. 0.162 0. ]
[0.115 0. 0.1 ]
[0. 0. 0.3 ]
[0. 0.243 0. ]
[0.231 0. 0. ]]
参数P(z_k|d_j):
[[0. 1. 0. 0.553 1. 0. 1. 0. 0. ]
[1. 0. 1. 0.447 0. 0. 0. 1. 0. ]
[0. 0. 0. 0. 0. 1. 0. 0. 1. ]]