第23章前馈神经网络
习题23.1
构造前馈神经网络实现逻辑表达式XNOR,使用S型函数为激活函数。
解答:
解答思路:
- 给出同或函数(XNOR)的输入和输出
- 用神经网络实现的门表示XNOR
- 设计神经网络实现XNOR
- 自编程实现二层前馈神经网络表示XNOR
解答步骤:
第1步: 给出同或函数(XNOR)的输入和输出
对于同或函数(XNOR),全部的输入与对应的输出如下:
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
第2步: 用神经网络实现的门表示XNOR
XNOR(同或门)和XOR(异或门)由于都是线性不可分的,不能由一层神经网络实现,但它们可由一层神经网络实现的门组合实现。
一层神经网络可实现的门包括AND(与门,用
同或函数可表示:
第3步: 设计神经网络实现XNOR
根据书中第23.1.1节的S型函数的定义:
S型函数(sigmoid function)又称为逻辑斯谛函数(logistic function),是定义式如下的非线性函数:
其中,
可知:
可设计如下二层前馈神经网络表示XNOR:
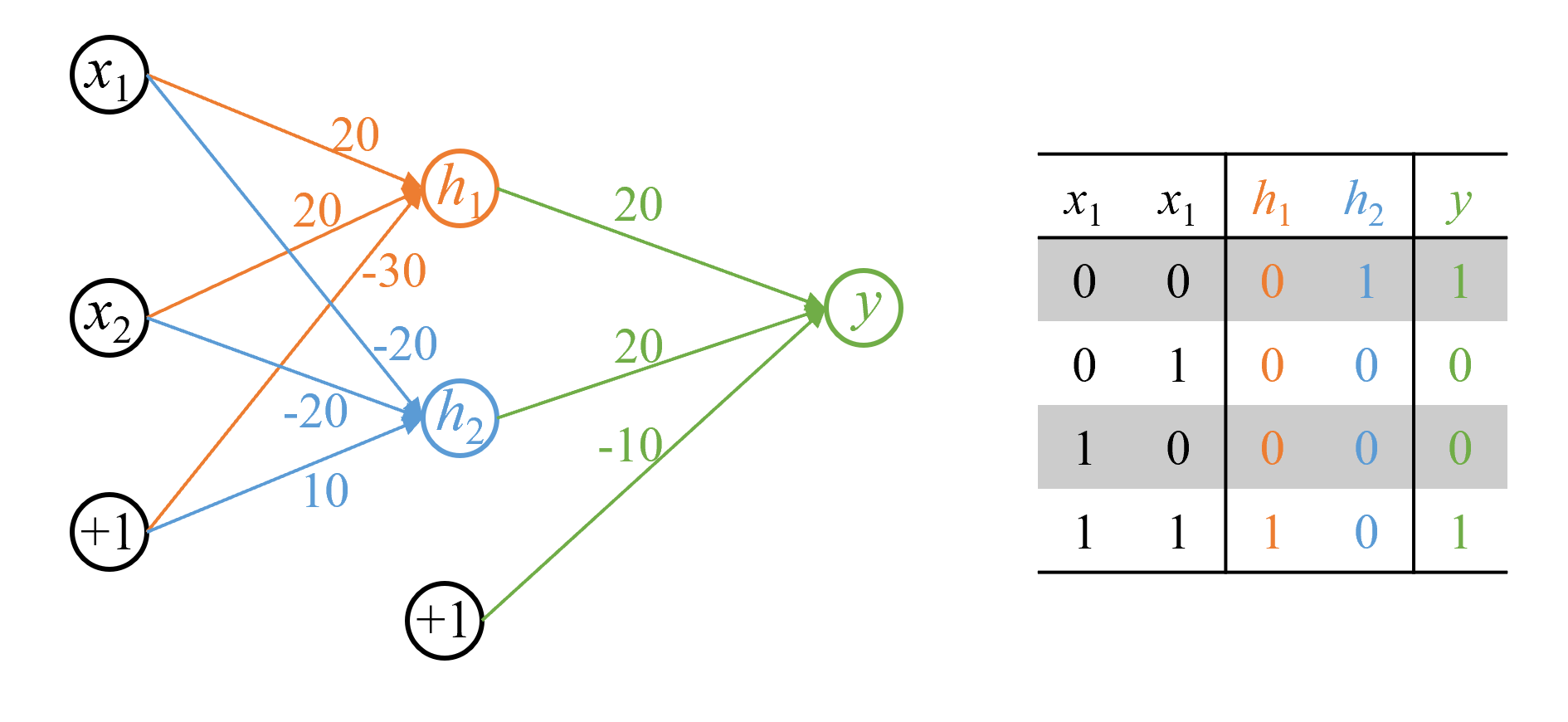
根据书中第23.1.1节的二层前馈神经网络的矩阵表示:
二层前馈神经网络也可以用矩阵来表示,简称矩阵表示:
其中,
第4步: 自编程实现二层前馈神经网络表示XNOR
import numpy as np
# 定义网络的权重W和偏置b
W1 = np.array([[20, -20], [20, -20]])
b1 = np.array([[-30], [10]])
W2 = np.array([[20], [20]])
b2 = np.array([[-10]])
def sigmoid(x):
s = 1 / (1 + np.exp(-x))
return s
def dnn_xnor(X):
Z1 = W1.T.dot(X) + b1
H = sigmoid(Z1)
Z2 = W2.T.dot(H) + b2
Y = sigmoid(Z2)
return YX = np.array([[0, 0, 1, 1],
[0, 1, 0, 1]])
with np.printoptions(suppress=True):
result = dnn_xnor(X)
print(result)[[0.99995456 0.00004548 0.00004548 0.99995456]]
习题23.2
写出多标签分类学习中的损失函数以及损失函数对输出变量的导数。
解答:
解答思路:
- 给出前馈神经网络学习在多标签分类时的模型
- 写出多标签分类学习中的损失函数
- 求损失函数对输出变量的导数
解答步骤:
第1步: 前馈神经网络学习在多标签分类时的模型
根据书中第23.1.1节的前馈神经网络学习在多标签分类时的模型:
用于多标签分类(multi-label classification)。神经网络的输出层有
个神经元,每个神经元的输出是一个概率值。神经网络表示为 ,其中 ,满足条件
表示输入 分别属于1个类别的概率。预测时给定输入 ,计算其属于各个类别的概率。将输入分到概率大于0.5的所有类别,这时输入可以被分到多个类别(赋予多个标签)。
第2步: 写出多标签分类学习中的损失函数
多标签分类时,输出层有
其中,
第3步: 求损失函数对输出变量的导数
输出层的输出变量是经过S型激活函数变换后的值,即
即:
习题23.3
实现前馈神经网络的反向传播算法,使用MNIST数据构建手写数字识别网络。
解答:
解答思路:
- 给出MNIST手写数字识别网络
- 给出前馈神经网络的反向传播算法
- 自编程实现使用MNIST数据集构建手写数字识别网络
解答步骤:
第1步: MNIST手写数据识别网络
根据书中第23章例23.4给出MNIST手写数字识别网络:
MNIST是一个机器学习标准数据集。每一个样本由一个像素为28
28 的手写数字灰度图像以及的0~9之间的标签组成,像素取值为0~255。
可以构建图23.14所示的前馈神经网络对MNIST的手写数字进行识别,是一个多标签分类模型。输入层是一个维向量,取自一个图像,每一维对应一个像素。第一层和第二层是隐层,各自有100个神经元和50个神经元,其激活函数都是S型函数。第三层是输出层,有10个神经元,其激活函数也是S型函数。给定一个图像,神经网络可以计算出其属于0~9类的概率,将图像赋予概率最大的标签。
第2步:前馈神经网络的反向传播算法
根据书中第23.2.3节的算法23.3的前馈神经网络的反向传播算法:
算法23.3 (前馈神经网络的反向传播算法)
输入:神经网络,参数向量 ,一个样本
输出:更新的参数向量
超参数:学习率
- 正向传播,得到各层输出
For
,do { } 2. 反向传播,得到各层误差
,同时计算各层的梯度,更新各层的参数。
计算输出层的误差For
,do {
计算第层的梯度 根据梯度下降公式更新第
层的参数 If (
) {
将第层的误差传到第 层 }
} 3. 返回更新的参数向量
第3步:自编程实现使用MNIST数据集构建手写数字识别网络
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
from tqdm import tqdm
np.random.seed(2023)class NeuralNetwork:
def __init__(self, layers, alpha=0.1):
# 网络层的神经元个数,其中第一层和第二层是隐层
self.layers = layers
# 学习率
self.alpha = alpha
# 权重
self.weights = []
# 偏置
self.biases = []
# 初始化权重和偏置
for i in range(1, len(layers)):
self.weights.append(np.random.randn(layers[i-1], layers[i]))
self.biases.append(np.random.randn(layers[i]))
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
return x * (1 - x)
def feedforward(self, inputs):
'''
(1)正向传播
'''
self.activations = [inputs]
self.weighted_inputs = []
for i in range(len(self.weights)):
weighted_input = np.dot(self.activations[-1], self.weights[i]) + self.biases[i]
self.weighted_inputs.append(weighted_input)
# 得到各层的输出h
activation = self.sigmoid(weighted_input)
self.activations.append(activation)
return self.activations[-1]
def backpropagate(self, expected):
'''
(2)反向传播
'''
# 计算各层的误差
errors = [expected - self.activations[-1]]
# 计算各层的梯度
deltas = [errors[-1] * self.sigmoid_derivative(self.activations[-1])]
for i in range(len(self.weights)-1, 0, -1):
error = deltas[-1].dot(self.weights[i].T)
errors.append(error)
delta = errors[-1] * self.sigmoid_derivative(self.activations[i])
deltas.append(delta)
deltas.reverse()
for i in range(len(self.weights)):
# 更新参数
self.weights[i] += self.alpha * np.array([self.activations[i]]).T.dot(np.array([deltas[i]]))
self.biases[i] += self.alpha * np.sum(deltas[i], axis=0)
def train(self, inputs, expected_outputs, epochs):
for i in tqdm(range(epochs)):
for j in range(len(inputs)):
self.feedforward(inputs[j])
self.backpropagate(expected_outputs[j])# 加载MNIST手写数字数据集
mnist = fetch_openml('mnist_784', parser='auto')
X = mnist.data.astype('float32') / 255.0
y = mnist.target.astype('int')# 划分训练集和测试集
lb = LabelBinarizer()
y = lb.fit_transform(y)
X = np.array(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练神经网络,其中第一层和第二层各有100个神经元和50个神经元
nn = NeuralNetwork([784, 100, 50, 10], alpha=0.1)
nn.train(X_train, y_train, epochs=10)100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [02:21<00:00, 14.20s/it]
# 使用测试集对模型进行评估
correct = 0
for i in range(len(X_test)):
output = nn.feedforward(X_test[i])
prediction = np.argmax(output)
actual = np.argmax(y_test[i])
if prediction == actual:
correct += 1
accuracy = correct / len(X_test) * 100
print("Accuracy: {:.2f} %".format(accuracy))Accuracy: 93.94 %
习题23.4
写出S型函数的正向传播和反向传播的计算图。
解答:
解答思路:
- 写出S型函数的正向传播计算图
- 写出S型函数的反向传播计算图
解答步骤:
第1步: 写出S型函数的正向传播计算图
根据书中第23.2.4节给出了S型函数的计算图例:
起点
, 是输入变量,终点 是输出变量,中间结点 是中间变量。变量 由S型函数 决定,变量 由损失函数 决定。
根据书中第23.2.4节给出的计算图的正向传播:
在计算图上进行的正向传播就是计算复合函数
的过程。从起点 开始,顺着有向边,在结点 依次进行计算,先后得到函数 ;其中先对 计算 得到 ,然后对 和 计算 得到 。
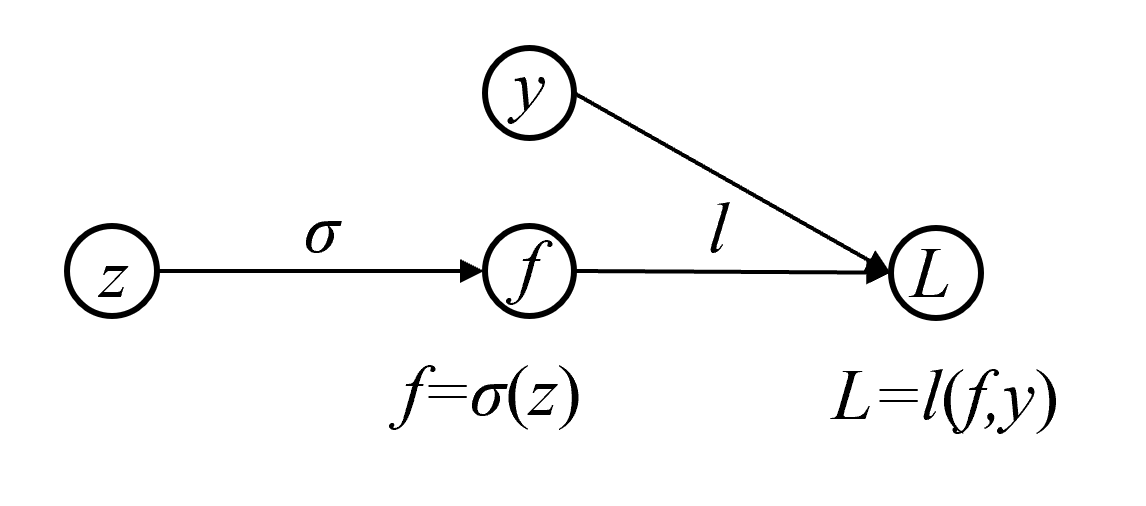
第2步: 写出S型函数的反向传播计算图
根据书中第23.2.4节给出的计算图的方向传播:
反向传播就是计算复合函数
对变量的梯度的过程。从终止起点 出发,逆着有向边,在结点 依次进行,向后得到梯度 ;其中先根据定义计算 ,再利用链式规则计算 : 梯度
在结点 的反向传播变为梯度的 倍,传到输入结点 。
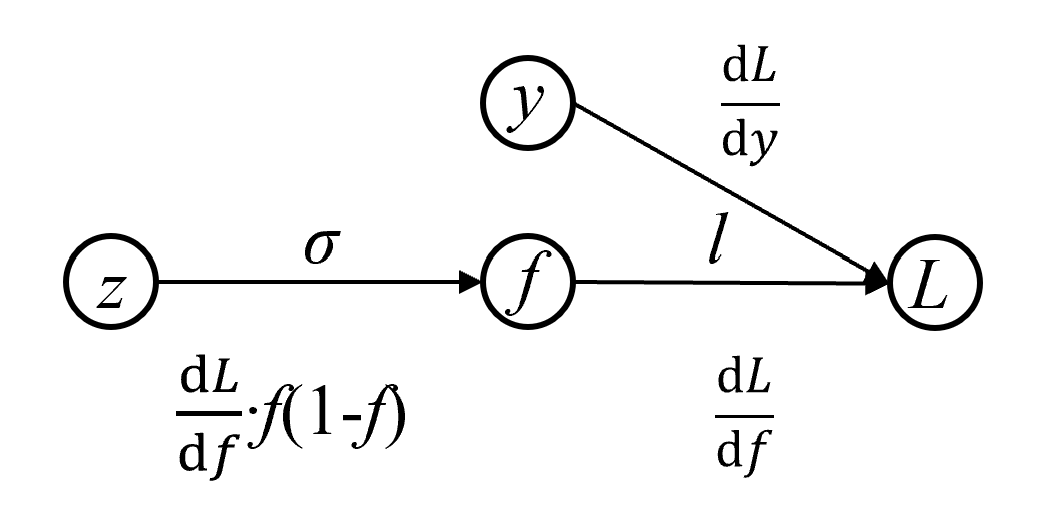
习题23.5
图23.31是3类分类的正向传播计算图,试写出它的反向传播计算图。这里使用软最大化函数和交叉熵损失。
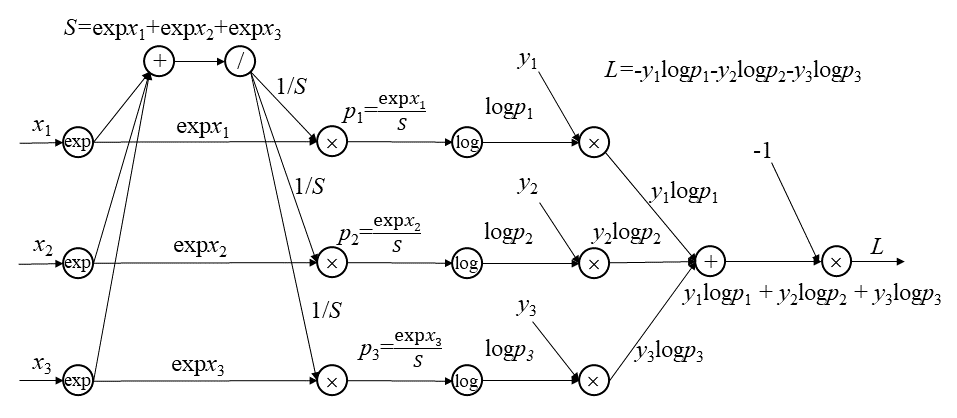
解答:
解答思路:
- 根据正向传播计算图,根据链式法则,逐步求导给出各层的梯度
- 绘制反向传播的计算图
解答步骤:
第1步:根据正向传播计算图,根据链式法则,逐步求导给出各层的梯度
见下图中各层的梯度计算结果。
第2步:绘制反向传播的计算图
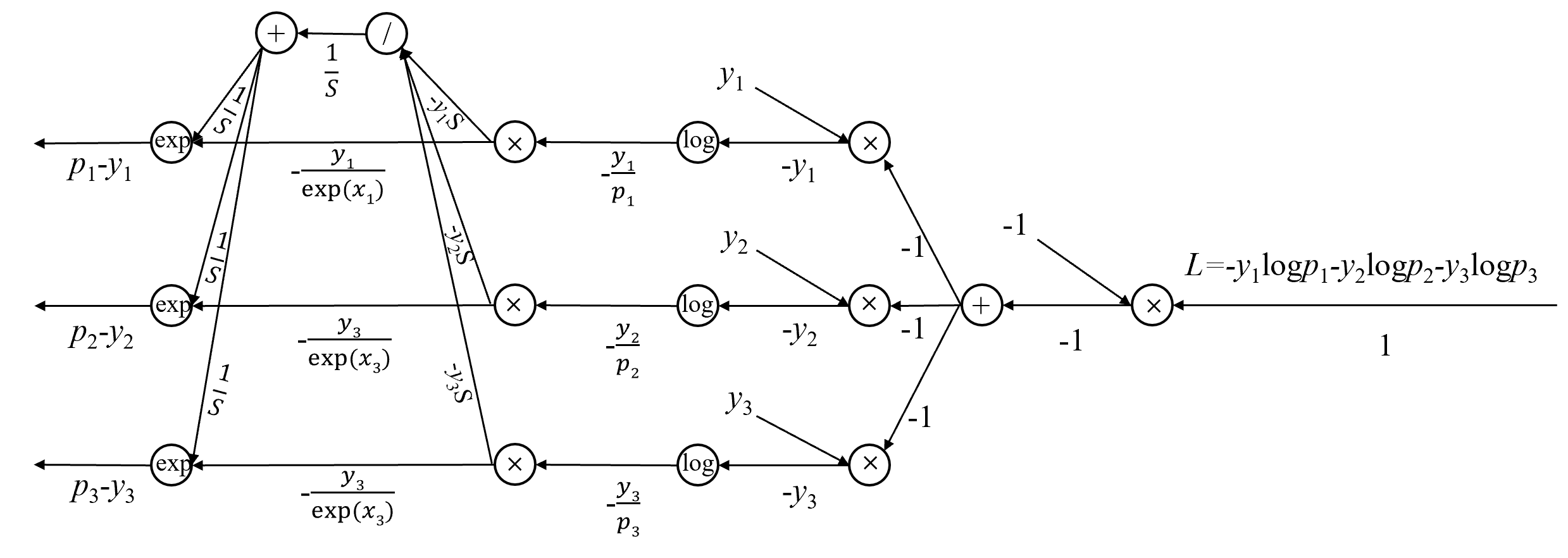
习题23.6
写出批量归一化的反向传播算法。
解答:
解答思路:
- 给出批量归一化算法
- 求批量归一化层的梯度
- 写出全连接层的梯度
- 写出批量归一化的反向传播算法
解答步骤:
第1步:批量归一化算法
根据书中第23.2.5节的算法23.4的批量归一化算法:
算法23.4(批量归一化)
输入:神经网络结构,训练集,测试样本。
输出:对测试样本的预测值。
超参数:批量容量的大小。
{
初始化参数,其中
For each (批量) {
For $t = 1, 2, \cdots, s - 1 $ {
针对批量计算第 层净输入的均值 和方差
进行第层的批量归一化,得到批量净输入 }
}
构建训练神经网络
使用随机梯度下降法训练,估计所有参数
For{
针对所有批量计算层净输入的期待的均值 和方差
针对测试样本,进行第层的批量归一化,得到净输入 }
构建推理神经网络
输出对测试样本的预测值
}
第2步:求批量归一化层的梯度
根据书中第404页图23.25(批量归一化层的正向计算图),求每一步的反向梯度。
假设损失函数为
根据书中第403页的公式23.61:
可将
根据书中第403页的公式23.59, 23.60:
可分别求
第3步:结合批量归一化层的梯度,写出全连接层的梯度
第
参数
参数
其中,
第4步:写出批量归一化的反向传播算法
输入:神经网络结构
,训练集
输出:参数向量
超参数:学习率,批量容量的大小 算法步骤:
- 初始化参数
,其中 - 计算输出层误差
- For each(批量
) {
For, do {
计算第层的梯度
更新第层的参数 If (
) {
将第层的参数误差传递到第 层 }
}
}
4. 返回更新的参数向量
习题23.7
验证逆暂退法和暂退法的等价性。
解答:
解答思路:
- 写出暂退法(dropout)计算公式
- 写出逆暂退法(inverted dropout)计算公式
- 证明两者等价
解答步骤:
第1步: 写出暂退法(dropout)计算公式
根据书中第23.3.3节的暂退法的描述:
假设某一隐层的输出向量是
,误差向量是 ,该层神经元保留与退出的结果用随机向量 表示,其中 是维度为 的 向量,1表示对应的神经元保留,0表示对应的神经元退出。那么,在反向传播算法的每一步,经过保留与退出随机判断后,该层的向量表示变为 这里
表示逐元素积,使用 进行正向传播和使用 进行反向传播。注意暂退法中每一步的 是随机决定的,各步之间并不相同。
预测时,对隐层的输出向量进行调整:其中,
是这层的保留概率。
由上述可知,暂退法训练时的计算公式:
预测时的计算公式:
第2步: 写出逆暂退法(inverted dropout)计算公式
根据书中第23.3.3节的逆暂退法的描述:
为了方便暂退法的实现,常常采用以下等价的逆暂退法。训练时,将隐层的输出变量放大
倍: 预测时,隐层的输出权重保持不变。
由上述可知,逆暂退法训练时计算公式:
预测时,隐层的输出权重保持不变,可得:
第3步: 证明两者等价
假设不考虑神经元的保留或丢弃时,隐层的输出为
其中
假设某一隐层,使用暂退法训练得到的隐层输出向量为
根据暂退法训练时的计算公式,暂退法训练时的输出期望为
其中
由于同一任务的神经网络训练的期望相同,即
即:
根据暂退法预测时计算公式,预测时的隐层输出
根据逆暂退法训练时的计算公式,逆暂退法训练时的输出期望为:
由于同一任务的神经网络训练的期望相同,即
根据逆暂退法预测时计算公式,预测时的隐层输出
由于暂退法和逆暂退法预测时的隐层输出相同,所以暂退法与逆暂退法是等价的。