第28章 生成对抗网络
习题28.1
GAN的生成网络的学习可以定义为以下的最小化问题:
比较与式(28.2)的不同,并考虑其作用。
解答:
解答思路:
- 给出式(28.2)定义的生成网络学习的最小化目标函数
- 比较题中公式和式(28.2)定义的生成网络学习的最小化目标函数函数
- 分析题中的最小化问题的目标函数的作用
解答步骤:
第1步:给出式(28.2)定义的生成网络学习的最小化目标函数
根据书中第28.1.1节的公式(28.2):
假设已给训练数据
遵循分布 ,其中 是样本。生成网络用 表示,其中 是输入向量(种子), 是输出向量(生成数据), 是网络参数。判别网络是一个二类分类器,用 表示,其中 是输入向量, 和 是输出概率,分别白哦是输入 来自训练数据和生成数据的概率, 是网络参数。种子 遵循分布 ,生成网络生成的数据分布表示为 ,由 和 决定。
如果判别网络参数固定,可以通过最小化以下目标函数学习生成网络参数θ。
第2步:比较题中公式和式(28.2)定义的生成网络学习的最小化目标函数
题中GAN的生成网络的学习可以定义为以下的最小化问题:
与式(28.2)比较,式中多减去了一项:
第3步:分析题中的最小化问题的目标函数的作用
令
题中最小化问题的目标函数的作用:
- 加速目标函数优化过程的收敛速度:对于
,其求导结果为 ,可以有效防止 取值时导致的梯度减小而难以训练的情况。 - 防止出现在学习的初始情况,由于生成网络较弱,判别网络很容易区分生成数据和判别数据,导致生成网络的学习难以进行下去的情况。
习题28.2
两个人进行零和博弈,参与人
针对这个博弈求
解答:
解答思路:
- 给出零和博弈的概念
- 结合零和博弈的概念,给出题中的求解方法
- 自编程对该博弈进行求解
- 验证这时
和 的关系
解答步骤:
第1步:零和博弈的概念
根据维基百科中的零和博弈
(参考资料:https://zh.wikipedia.org/wiki/零和博弈 )
零和博弈,又称零和游戏或零和赛局(Zero-sum game)与非零和博弈相对,是博弈论的一个概念,属非合作博弈。零和博弈表示所有博弈方的利益之和为零或一个常数,即一方有所得,其他方必有所失。在零和博弈中,博弈各方是不合作的。
第2步:结合零和博弈的概念,给出题中的求解方法
结合第1步给出的零和博弈概念,该博弈的收益矩阵为:
考虑最小最大化原则,即如果参与人
而对应计算过程,则是先按行计算每一行最小值,然后在每一行的最小值中选择最大值,得到
考虑最大最小化原则,即如果参与人
而对应计算过程,则是先按列计算每一行最大值,然后在每一行的最大值中选择最小值,得到
第3步:自编程对该博弈进行求解
import numpy as npdef minmax_function(A):
"""
从收益矩阵中计算minmax的算法
:param A: 收益矩阵
:return: 计算得到的minmax结果
"""
index_max = []
for i in range(len(A)):
# 计算每一行的最大值
index_max.append(A[i,:].max())
# 计算每一行的最大值中的最小值
minmax = min(index_max)
return minmaxdef maxmin_function(A):
"""
从收益矩阵中计算maxmin的算法
:param A: 收益矩阵
:return: 计算得到的maxmin结果
"""
column_min = []
for i in range(len(A)):
# 计算每一列的最小值
column_min.append(A[:,i].min())
# 计算每一列的最小值中的最大值
maxmin = max(column_min)
return maxmin# 创建收益矩阵
A = np.array([[-1,2],[4,1]])
# 计算maxmin
maxmin = maxmin_function(A)
# 计算minmax
minmax = minmax_function(A)
# 输出结果
print("maxmin =", maxmin)
print("minmax =", minmax)maxmin = 1
minmax = 2
第4步:验证这时
由上步可得:
这时
习题28.3
计算以下两个概率分布的Jessen-Shannon散度,设
| 0.1 | 0.7 | 0.1 | 0.1 | 0 |
|---|---|---|---|---|
| 0.2 | 0 | 0 | 0.8 | 0 |
解答:
解答思路:
- 给出Jessen-Shannon散度的定义
- 写出题中数据的Jessen-Shannon散度数值计算过程
- 使用自编程实现并验证计算结果
解答步骤:
第1步:Jessen-Shannon散度的定义
根据维基百科的Jessen-Shannon散度
(参考Wiki:https://en.wikipedia.org/wiki/Jensen–Shannon_divergence )
给出两个概率分布
和 ,其Jessen-Shannon散度为:
其中
根据书中附录E的KL散度的定义:
KL散度是描述两个概率分布
和 相似度的一种度量,记作 。对离散随机变量,KL散度定义为 对连续随机变量,KL散度定义为
第2步:写出题中数据的Jessen-Shannon散度数值计算过程
由于题中数据是离散值,采用对离散随机变量的KL散度公式进行计算,得到:
则对应KL散度为:
计算JS散度,得到:
第3步:使用自编程实现并计算结果
通过调用scipy.stats的entropy函数,根据题目中的两个概率分布进行计算,得到两个分布的Jessen-Shannon散度。
from scipy.stats import entropy
import numpy as np# 加载数据
P = [0.1, 0.7, 0.1, 0.1, 0]
Q = [0.2, 0, 0, 0.8, 0]
# 计算z=(x+y)/2
M =[(P[i] + Q[i]) / 2 for i in range(min(len(P),len(Q)))]
# 计算P和M之间的KL散度,Q和M之间的KL散度
DL_P_M = entropy(P, M)
DL_Q_M = entropy(Q, M)
# 计算JS散度
result = (DL_P_M + DL_Q_M) / 2
# 输出结果
print("Jessen-Shannon Distance = {:f}".format(result))Jessen-Shannon Distance = 0.440696
可得到两个概率分布的Jessen-Shannon散度为0.440696。
习题28.4
证明两个概率分布
解答:
解答思路:
- 给出两个概率分布
和 之间的Jessen-Shannon散度 - 证明当且仅当
和 相同时,Jessen-Shannon散度取最小值0 - 证明Jessen-Shannon散度取最大值
(设对数是自然对数) - 结合上述证明,得到
关系式
解答步骤:
第1步:两个概率分布 𝑃 和 𝑄 之间的Jessen-Shannon散度
根据维基百科的Jessen-Shannon散度
(参考Wiki:https://en.wikipedia.org/wiki/Jensen–Shannon_divergence )
给出两个概率分布
和 ,其Jessen-Shannon散度为: 其中
, 表示为KL散度。
第2步:证明当且仅当
首先,将两个概率分布
根据书中附录E的KL散度的性质:
KL散度具有性质:$ D(P | Q) \geqslant 0$。当且仅当
时, 。
将上述KL散度的性质带入两个概率分布P和Q的Jessen-Shannon散度展开式可知:当且仅当
根据
综上所述,可证得当前仅当
第3步:证明Jessen-Shannon散度取最大值
可知两个概率分布
- 假设
和 是连续型随机变量的概率分布
将连续随机变量的KL散度公式带入展开,并且将
可知:
可得:
所以:
当且仅当概率分布
- 假设
和 是离散型随机变量的概率分布
将离散随机变量的KL散度公式带入展开,并且将
可知:
可得:
所以:
当且仅当概率分布
故,可得:
第4步:结合上述证明,得到
根据第2步和第3步,两个概率分布
习题28.5
考虑一维卷积运算,其输入是5维的向量
解答:
解答思路:
- 写出该卷积运算的矩阵表示
- 写出对应的转置卷积
- 证明原始卷积核
和转置卷积核 满足
解答步骤:
第1步:写出该卷积运算的矩阵表示
假设输入的5维向量
根据书中第28.2.1节的卷积运算的矩阵表示,可构建矩阵
根据书中第28.2.1节关于矩阵
考虑基于矩阵
的线性变换,其输入是输入矩阵展开的向量,输出是输出矩阵展开的向量。这个线性变换对应神经网络前一层道后一层的信号传递(正向传播),而以上卷积运算表示在这个线性变换中。
可得卷积运算的矩阵表示:
第2步:写出对应的转置卷积
根据书中第28.2.1节的转置卷积的描述,可构建矩阵
根据书中第28.2.1节关于矩阵
考虑基于转置矩阵
的线性变换。这个线性变换对应神经网络后一层到前一层的信号传递(反向传播)。
可得对应的转置卷积为
这个转置卷积是核矩阵为
第3步:证明原始卷积核
因为原始卷积核
习题28.6
写出图28.8中转置卷积的大小和原始卷积的大小之间的关系,转置卷积有输入矩阵尺寸
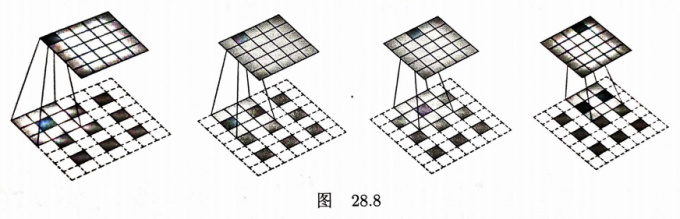
解答:
解答思路:
- 给出转置卷积的大小计算
- 写出图中转置卷积的大小
- 写出图中原始卷积的大小
- 写出图中转置卷积的大小和原始卷积的大小之间的关系
解答步骤:
第1步:给出转置卷积的大小计算
根据书中第28.2.1节的转置卷积的大小计算:
首先,计算原始卷积的大小。这里考虑简单的情况。假设输入矩阵是方阵,卷积核矩阵也是方阵。设
是输入矩阵的尺寸, 是卷积核的尺寸, 是填充的尺寸, 是步幅。输出矩阵的尺寸 满足 这里考虑可以整除的情况,式(28.13)可以改为对应的形式:
接着,计算转置卷积的大小。设
是输入矩阵的尺寸, 是卷积核的尺寸, 是填充的尺寸, 是步幅。输出矩阵的尺寸 满足 这里也考虑可以整除的情况。转置卷积的输出矩阵尺寸
与原始卷积的输入矩阵尺寸 相同。因此,可以推算,当 $S = 1, P = 0 $时,转置卷积的大小和原始卷积的大小之间有以下关系:
第2步:写出图中转置卷积的大小
根据图中的信息,转置卷积的输入矩阵(插入0向量后)尺寸为5,卷积核尺寸为3,步幅为1,填充尺寸为1, 输出矩阵尺寸为5,即
第3步:写出图中原始卷积的大小
根据图中的信息,原始卷积输入矩阵尺寸为5,卷积核尺寸为3,步幅为1,填充尺寸为0,输出矩阵尺寸为3,即
第4步:写出图中转置卷积的大小和原始卷积的大小之间的关系
当
参考文献
【1】零和博弈(来源于Wiki百科):https://zh.wikipedia.org/wiki/零和博弈
【2】Jessen-Shannon散度(来源于Wiki百科):https://en.wikipedia.org/wiki/Jensen–Shannon_divergence