第26章序列到序列模型
习题26.1
设计由4层LSTM组成的序列到序列的基本模型,写出其公式。
解答:
解答思路:
- 给出序列到序列的基本模型
- 设计基于4层LSTM的编码器和解码器,绘制模型架构图
- 结合模型架构图,写出模型公式
- 自编程实现模型
解答步骤:
第1步:序列到序列的基本模型
根据书中第26章的本章概要的序列到序列的基本模型:
对于序列到序列基本模型,编码器和解码器是循环神经网络,通常是LSTM和GRU。
编码器的状态是
解码器的状态是
解码器的输出是
编码器的最终状态
是解码器的初始状态 。
第2步:设计基于4层LSTM的编码器和解码器,绘制模型架构图
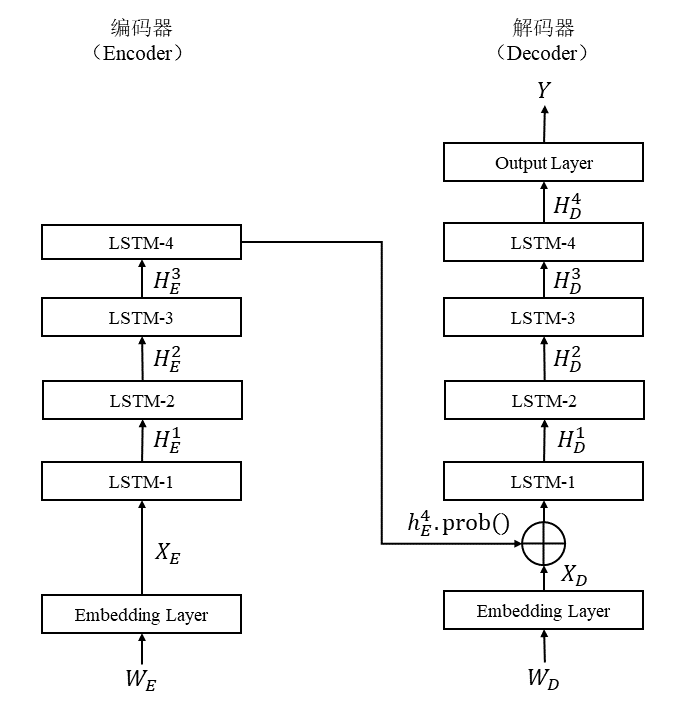
第3步:结合模型架构图,写出模型公式
对于编码器部分,输入为
取最后一层的输出
第4步:自编程实现模型
import torch
from torch import nn
import numpy as npclass S2SEncoder(nn.Module):
r"""Info: 由LSTM组成的序列到序列编码器。
Args:
inp_size: 嵌入层的输入维度。
embed_size: 嵌入层的输出维度。
num_hids: LSTM 隐层向量维度。
num_layers: LSTM 层数,本题目设置为4。
"""
def __init__(self, inp_size, embed_size, num_hids,
num_layers, dropout=0, **kwargs):
super(S2SEncoder, self).__init__(**kwargs)
self.embed = nn.Embedding(inp_size, embed_size)
self.rnn = nn.LSTM(embed_size, num_hids, num_layers,
dropout=dropout)
def forward(self, inputs):
# inputs.shape(): (seq_length, embed_size)
inputs = self.embed(inputs)
# output.shape(): (seq_length, num_hids)
# states.shape(): (num_layers, num_hids)
output, state = self.rnn(inputs)
return output, stateclass S2SDecoder(nn.Module):
r"""Info: 由LSTM组成的序列到序列解码器。
Args:
inp_size: 嵌入层的输入维度。
embed_size: 嵌入层的输出维度。
num_hids: LSTM 隐层向量维度。
num_layers: LSTM 层数,本题目设置为4。
"""
def __init__(self, inp_size, embed_size, num_hids,
num_layers, dropout=0, **kwargs):
super(S2SDecoder, self).__init__(**kwargs)
self.num_layers = num_layers
self.embed = nn.Embedding(inp_size, embed_size)
# 解码器 LSTM 的输入,由目标序列的嵌入向量和编码器的隐层向量拼接而成。
self.rnn = nn.LSTM(embed_size + num_hids, num_hids, num_layers,
dropout=dropout)
self.linear = nn.Linear(num_hids, inp_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1][-1]
def forward(self, inputs, state):
# inputs.shape(): (seq_length, embed_size)
inputs = self.embed(inputs)
# 广播编码器最后输出的隐藏状态,使其具有与 inputs 相同的长度
# context.shape(): (seq_length, hid_size)
context = state[-1].repeat(inputs.shape[0], 1)
inputs = torch.cat((inputs, context), 1)
# output.shape(): (seq_length, num_hids)
output, _ = self.rnn(inputs)
output = self.linear(output)
return outputclass EncoderDecoder(nn.Module):
r"""Info: 基于 LSTM 的序列到序列模型。
Args:
encoder: 编码器。
decoder: 解码器。
"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_inp, dec_inp):
enc_out = self.encoder(enc_inp)
dec_state = self.decoder.init_state(enc_out)
return self.decoder(dec_inp, dec_state)# 搭建一个4层LSTM构成的序列到序列模型,进行前向计算
inp_size, embed_size, num_hids, num_layers = 4, 8, 16, 4
encoder = S2SEncoder(inp_size, embed_size, num_hids, num_layers)
decoder = S2SDecoder(inp_size, embed_size, num_hids, num_layers)
model = EncoderDecoder(encoder, decoder)enc_inp_seq = "I love you !"
dec_inp_seq = "我 爱 你 !"
enc_inp, dec_inp = [], []
# 自己构造的的词典
voc_1 = {"I": 1,
"love": 2,
"you": 3,
"!": 0}
voc_2 = {"我": 1,
"爱": 2,
"你": 3,
"!": 0}
for word in enc_inp_seq.split():
enc_inp.append(voc_1[word])
enc_inp = torch.tensor(enc_inp)
for word in dec_inp_seq.split():
dec_inp.append(voc_2[word])
dec_inp = torch.tensor(dec_inp)
output = model(enc_inp, dec_inp)
# output (dec_seq_len, dec_voc_size)
print(output)tensor([[-0.1821, 0.2403, -0.0596, 0.1208],
[-0.1576, 0.2332, -0.0129, 0.1142],
[-0.1435, 0.2280, 0.0110, 0.1143],
[-0.1357, 0.2243, 0.0222, 0.1161]], grad_fn=<AddmmBackward0>)
习题26.2
比较基本模型和RNN Search的异同。
解答:
解答思路:
- 给出基本模型
- 给出RNN Search模型
- 比较基本模型和RNN Search的异同
解答步骤:
第1步:基本模型
根据书中第26章的本章概要的序列到序列的基本模型:
对于序列到序列基本模型,编码器和解码器是循环神经网络,通常是LSTM和GRU。
编码器的状态是解码器的状态是
解码器的输出是
编码器的最终状态
是解码器的初始状态 。
第2步:RNN Search模型
根据书中第26章的本章概要的RNN Search模型:
RNN Search模型用双向LSTM实现编码,用单向LSTM实现解码,用注意力实现编码器到解码器的信息传递。在输出单词序列的每一个位置,通过注意力搜索到输入单词序列中的相关内容,以影响下一个位置的单词生成。
编码器的状态是解码器的状态是
解码器的输出是
通过注意力计算上下文向量
。注意力的查询是前一个位置的状态 ,键和值是编码器的各个位置上的中间表示 。
第3步:比较基本模型和RNN Search的异同
相同点:
- 两者都由编码器和解码器组成,编码器和解码器都是循环神经网络
- 两者都能解决序列到序列的学习任务,属于序列到序列模型
不同点:
- 编码器:RNN Search的编码器使用双向LSTM,将各个位置对正向和反向状态进行拼接,得到中间表示;基本模型仅使用单向RNN。
- 解码器:RNN Search使用单向LSTM,在解码器的每一个位置,通过加法注意力计算上下文向量,在解码的过程中,将编码器得到的状态序列或中间表示序列通过注意力有选择地传递到解码器,决定解码器的状态序列,以及输出的单词序列。基本模型使用单向RNN,编码器将其最终状态作为整个输入单词序列的表示传递给解码器。
习题26.3
写出多头自注意力的对损失函数的求导公式。
解答:
解答思路:
- 给出多头注意力的计算公式
- 给出多头自注意力的计算公式
- 写出多头自注意力的对损失函数的求导公式
解答步骤:
第1步:多头注意力的计算公式
根据书中第26.3.1的多头注意力的描述:
多头是指多个并行的注意力。在多头注意力中,先通过线性变换将表示向量从所在的空间分别投影到多个不同的子空间,每个子空间对应一个头,接着在各个子空间分别进行注意力计算,之后将各个子空间的注意力计算结果进行拼接,最后再对拼接结果进行线性变换,得到的表示向量的维度与原来的表示向量的维度相同。
设是查询矩阵, 是键矩阵, 是值矩阵。多头注意力multi_attend的计算是 其中,
是头的个数, 是第 个头的注意力计算结果,concate是矩阵向量的拼接, 是线性变换矩阵。 分别是第 个头的查询矩阵、键矩阵、值矩阵的线性变换矩阵,attend是注意力函数。
第2步:多头自注意力的计算公式
根据书中第26.3.1的多头自注意力的描述:
当注意力中的查询、键、值向量
相同,或者说自己时,称为自注意力。多头自注意力是有多个头的自注意力。
在解码器中,多头自注意力计算对之后的位置进行掩码处理,让这些位置不参与计算。具体导入矩阵,自注意力计算变成以下的掩码自注意力计算: 也就是说,自注意力在每一个位置以该位置的表示向量作为查询向量,该位置和之前位置的所有表示向量作为键向量和值向量。掩码注意力保证了解码的过程是自回归的,学习时可以使用强制教学的方法,即训练在各个位置上并行进行。
第3步:写出多头自注意力的对损失函数的求导公式
假设有某个
其中
根据softmax函数
根据链式求导法则,损失函数
习题26.4
设计一个基于CNN的序列到序列模型。
解答:
解答思路:
- 给出基于CNN的序列到序列模型
- 根据模型架构图,分析编码器和解码器的构成
- 自编程实现基于CNN的序列到序列模型
解答步骤:
第1步:基于CNN的序列到序列模型
根据论文《Convolutional Sequence to Sequence Learning》中的基于CNN的序列到序列模型的架构图
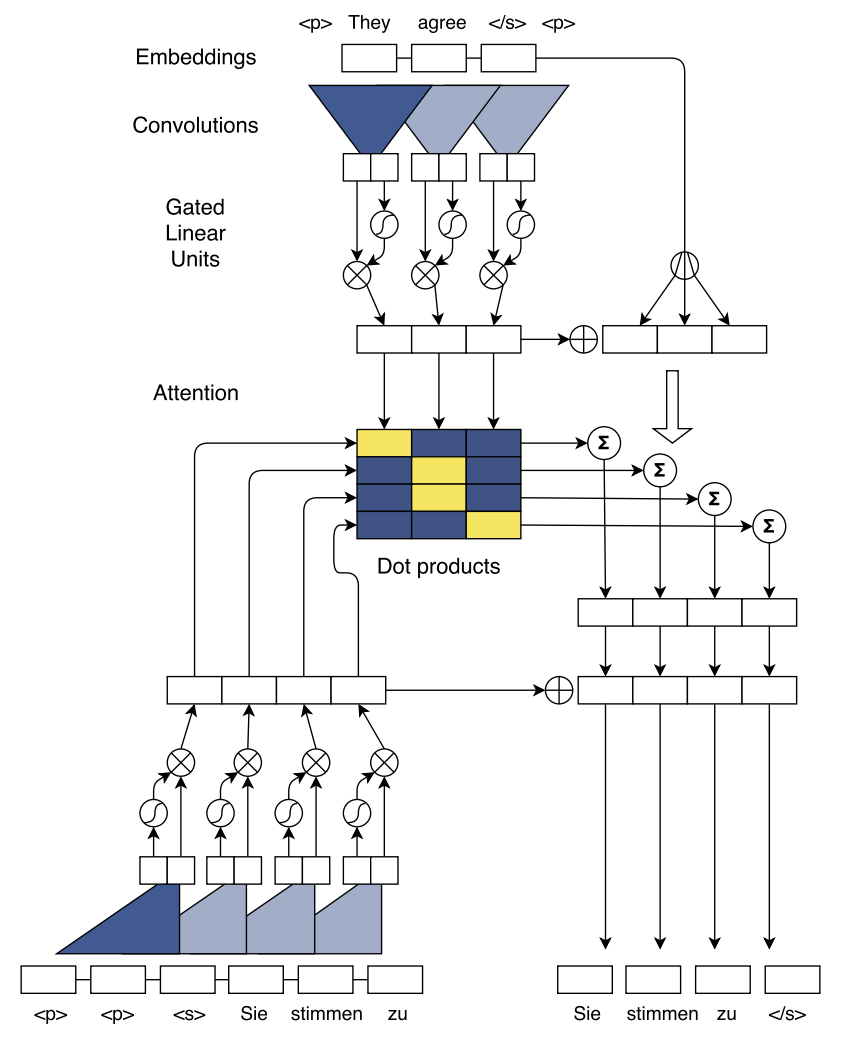
第2步:根据模型架构图,分析编码器和解码器的构成
以机器翻译为任务为例,对模型网络进行分析:
- 在最上面的编码器部分,首先对输入文本进行 Embedding 计算,通过层叠的卷积抽取输入源文本序列的特征,卷积之后经过激活函数作为编码器的输出
- 在左下的解码器部分,用层叠卷积抽取输出目标序列的特征,经过GLU激活函数作为解码器的输出
- 在中间的注意力层,将编码器和解码器的输出进行点乘,作为输入的源语言序列中每个词权重
- 最后在残差连接部分,把注意力计算的权重与输入序列相乘,加入到解码器的输出中得到输出序列
第3步:自编程实现基于CNN的序列到序列模型
import torch
import torch.nn as nn
import torch.nn.functional as Fclass CNNEncoder(nn.Module):
r"""Info: 序列到序列 CNN 编码器。
Args:
inp_dim: 嵌入层的输入维度。
emb_dim: 嵌入层的输出维度。
hid_dim: CNN 隐层向量维度。
num_layers: CNN 层数。
kerner_size: 卷积核大小。
"""
def __init__(self, inp_dim, emb_dim, hid_dim,
num_layers, kernel_size):
super().__init__()
self.embed = nn.Embedding(inp_dim, emb_dim)
self.emb2hid = nn.Linear(emb_dim, int(hid_dim/2))
self.hid2emb = nn.Linear(int(hid_dim/2), emb_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels = emb_dim,
out_channels = hid_dim,
kernel_size = kernel_size,
padding = (kernel_size - 1) // 2)
for _ in range(num_layers)])
def forward(self, inputs):
# inputs.shape(): (src_len, inp_dim)
# conv_inp.shape(): (src_len, emb_dim)
conv_inp = self.embed(inputs).permute(1, 0)
for _, conv in enumerate(self.convs):
# 进行卷积运算
# conv_out.shape(): (src_len, hid_dim)
conv_out = conv(conv_inp)
# 经过激活函数
conved = F.glu(conv_out, dim=0)
# 残差连接运算
conved = self.hid2emb(conved.permute(1, 0)).permute(1, 0)
conved = conved + conv_inp
conv_inp = conved
# 卷积输出与词嵌入 element-wise 点加进行注意力运算
# combined.shape(): (src_len, emb_dim)
combined = conved + conv_inp
return conved, combinedclass CNNDecoder(nn.Module):
r"""Info: 序列到序列 CNN 解码器。
Args:
out_dim: 嵌入层的输入维度。
emb_dim: 嵌入层的输出维度。
hid_dim: CNN 隐层向量维度。
num_layers: CNN 层数。
kernel_size: 卷积核大小。
"""
def __init__(self, out_dim, emb_dim, hid_dim,
num_layers, kernel_size, trg_pad_idx):
super().__init__()
self.kernel_size = kernel_size
self.trg_pad_idx = trg_pad_idx
self.embed = nn.Embedding(out_dim, emb_dim)
self.emb2hid = nn.Linear(emb_dim, int(hid_dim/2))
self.hid2emb = nn.Linear(int(hid_dim/2), emb_dim)
self.attn_hid2emb = nn.Linear(int(hid_dim/2), emb_dim)
self.attn_emb2hid = nn.Linear(emb_dim, int(hid_dim/2))
self.fc_out = nn.Linear(emb_dim, out_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels = emb_dim,
out_channels = hid_dim,
kernel_size = kernel_size)
for _ in range(num_layers)])
def calculate_attention(self, embed, conved, encoder_conved, encoder_combined):
# embed.shape(): (trg_len, emb_dim)
# conved.shape(): (hid_dim, trg_len)
# encoder_conved.shape(), encoder_combined.shape(): (src_len, emb_dim)
# 进行注意力层第一次线性运算调整维度
conved_emb = self.attn_hid2emb(conved.permute(1, 0)).permute(1, 0)
# conved_emb.shape(): (trg_len, emb_dim])
combined = conved_emb + embed
# print(combined.size(), encoder_conved.size())
energy = torch.matmul(combined.permute(1, 0), encoder_conved)
# attention.shape(): (trg_len, emb_dim])
attention = F.softmax(energy, dim=1)
attended_encoding = torch.matmul(attention, encoder_combined.permute(1, 0))
# attended_encoding.shape(): (trg_len, emd_dim)
# 进行注意力层第二次线性运算调整维度
attended_encoding = self.attn_emb2hid(attended_encoding)
# attended_encoding.shape(): (trg_len, hid_dim)
# 残差计算
attended_combined = conved + attended_encoding.permute(1, 0)
return attention, attended_combined
def forward(self, targets, encoder_conved, encoder_combined):
# targets.shape(): (trg_len, out_dim)
# encoder_conved.shape(): (src_len, emb_dim)
# encoder_combined.shape(): (src_len, emb_dim)
conv_inp = self.embed(targets).permute(1, 0)
src_len = conv_inp.shape[0]
hid_dim = conv_inp.shape[1]
for _, conv in enumerate(self.convs):
#need to pad so decoder can't "cheat"
padding = torch.zeros(src_len,
self.kernel_size - 1).fill_(self.trg_pad_idx)
padded_conv_input = torch.cat((padding, conv_inp), dim=-1)
#padded_conv_input = [batch size, hid dim, trg len + kernel size - 1]
# 经过卷积运算
conved = conv(padded_conv_input)
# 经过激活函数
conved = F.glu(conved, dim=0)
# 注意力分数计算
attention, conved = self.calculate_attention(conv_inp, conved,
encoder_conved,
encoder_combined)
# 残差连接计算
conved = self.hid2emb(conved.permute(1, 0)).permute(1, 0)
conved = conved + conv_inp
conv_inp = conved
output = self.fc_out(conved.permute(1, 0))
return output, attentionclass EncoderDecoder(nn.Module):
r"""Info: 序列到序列 CNN 模型。
"""
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_inp, dec_inp):
# 编码器,将源句子编码为向量输入解码器进行解码。
encoder_conved, encoder_combined = self.encoder(enc_inp)
# 解码器,根据编码器隐藏状态和解码器输入预测下一个单词的概率
# 注意力层,源句子和目标句子之间进行注意力运算从而对齐
output, attention = self.decoder(dec_inp, encoder_conved, encoder_combined)
return output, attention# 构建一个基于CNN的序列到序列模型
inp_dim, out_dim, emb_dim, hid_dim, num_layers, kernel_size = 4, 4, 8, 16, 1, 3
encoder = CNNEncoder(inp_dim, emb_dim, hid_dim, num_layers, kernel_size)
decoder = CNNDecoder(out_dim, emb_dim, hid_dim, num_layers, kernel_size, trg_pad_idx=0)
model = EncoderDecoder(encoder, decoder)enc_inp_seq = "I love you !"
dec_inp_seq = "我 爱 你 !"
enc_inp, dec_inp = [], []
# 自己构造的的词典
voc_1 = {"I": 1,
"love": 2,
"you": 3,
"!": 0}
voc_2 = {"我": 1,
"爱": 2,
"你": 3,
"!": 0}
for word in enc_inp_seq.split():
enc_inp.append(voc_1[word])
enc_inp = torch.tensor(enc_inp)
for word in dec_inp_seq.split():
dec_inp.append(voc_2[word])
dec_inp = torch.tensor(dec_inp)
output, _ = model(enc_inp, dec_inp)
# output (dec_seq_len, dec_voc_size)
print(output.size())torch.Size([4, 4])
习题26.5
写出6层编码器和6层解码器组成的Transformer的所有参数。
解答:
解答思路:
- 给出Transformer模型的描述
- 分析Transformer模型结构
- 写出6层编码器和6层解码器组成的Transformer的所有参数
解答步骤:
第1步:Transformer模型的描述
根据书中第26章的本章概要的Transformer模型的描述:
Transformer是完全基于注意力机制的序列到序列学习模型。使用注意力实现编码、解码及编码器和解码器之间的信息传递。
Transformer拥有非常简单的结构。编码器的输入是输入单词序列,编码器的输入层是编码器的第
个编码层由多头自注意力子层和前馈网络子层组成: 解码器的输入是已生成的输出单词序列,解码器的输入层是
解码器的第
个解码层由多头自注意力子层、多头注意力子层、前馈网络子层组成: 解码器的输出层计算下一个位置单词出现的条件概率。
第2步:分析Transformer模型结构
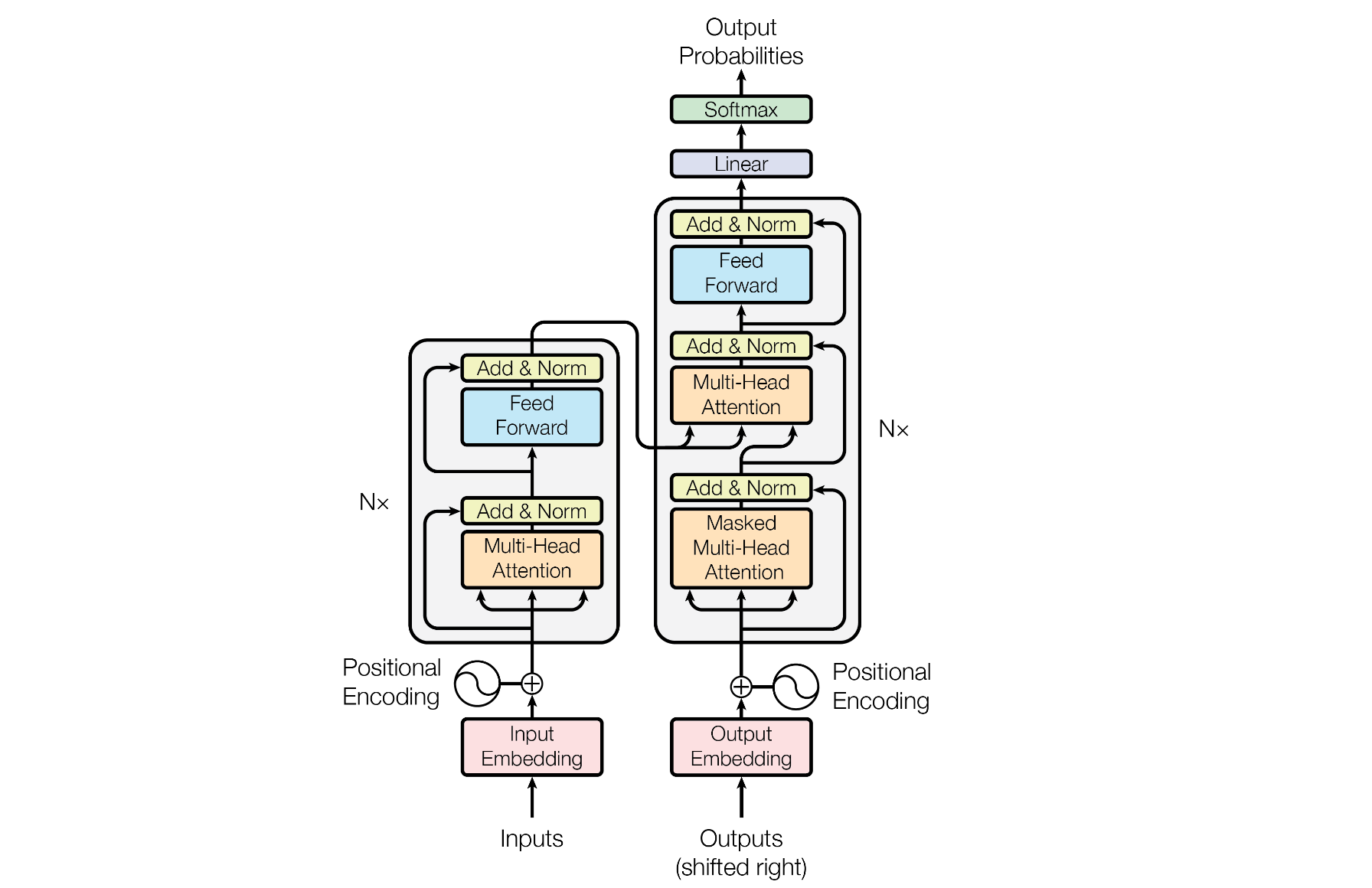
上图来自论文《Attention Is All You Need》中的Transformer模型架构图,根据该图,逐一分析各个模块包含的参数:
- 输入Embedding层
Embedding层分为连接编码器的输入 Embedding 层和连接解码器的输出 Embedding 层,包含各自的 Word Embedding 参数,假设输入 Embedding 和输出 Embedding 的参数规模大小相同,经过独热(one-hot)编码之后,某时刻输入至编码器和解码器对应 Embedding 的向量分别为
其中
- 编码器和解码器
结构上,Transformer 编码器和解码器的唯一区别在于解码器的注意力层会存在一个 Attention Mask 的掩码矩阵,但在参数结构规模上是完全一样的,因此只需要分析编码器的参数,同理也就知道解码器上的参数了,用参数下标
首先,将编码器对应 Embedding 的输出记作
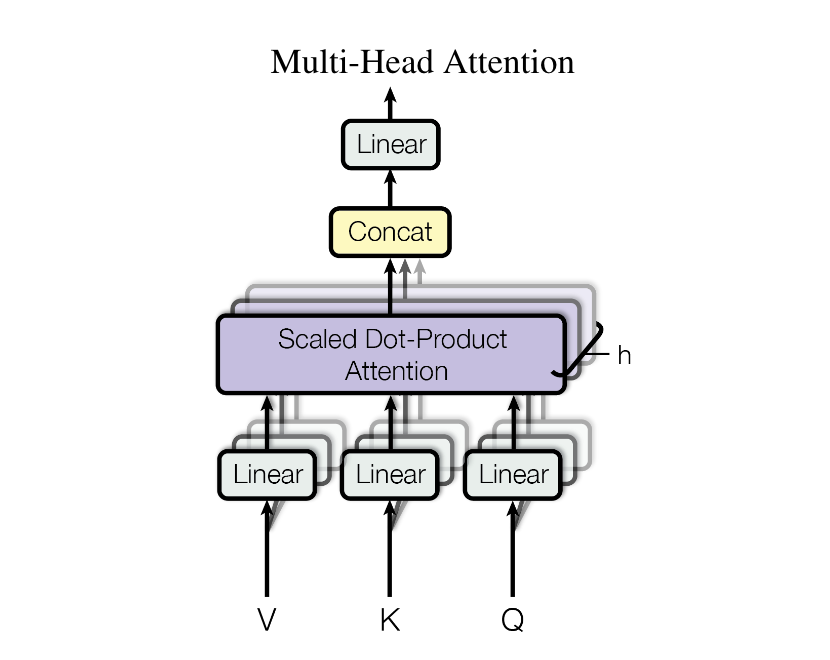
由于多头注意力中的每个头的计算原理都一样,这里只分析单头注意力,第
这里需要更新的参数有三组权重
再进行自注意力运算,这里不涉及到可更新参数,可直接跳过,得到自注意力层的输出
又有一组需要更新的权重和偏差
再经过残差运算和层归一化,涉及到少量层归一化的参数;把归一化后的输出记作
然后输入至前馈神经网络层,经过两次线性运算和残差连接以及层归一化,可得
这里需要更新的参数有两层前馈神经网络的权重和偏差
- 输出层
对于6层编码器解码器的Transformer,输出层的输入为最后一层解码器的输出
便可得到最终输出结果。
需要更新参数有输出层的权重和偏差$\boldsymbol{W}{\tilde Y} \in \mathbb{R}^{ M \times N{\tilde Y}}, \boldsymbol{b}{\tilde Y} \in \mathbb{R}^{N{\tilde Y}}
第3步:写出6层编码器和6层解码器组成的Transformer的所有参数
6层编码器和6层解码器组成的Transformer的所有参数包含以下三部分:
Embedding 层,分别为编码器和解码器对应的 Word Embedding 参数
编码器的参数,对于第
层编码器,注意力层有 ,前馈网络层有 ,其中 ,每一层都有一些层归一化的隐藏参数 同理,解码器的参数,对于第
层解码器,注意力层有 ,前馈网络层有 ,其中 ,每一层都有一些层归一化的隐藏参数 输出层,包含一组参数 $\boldsymbol{W}{\tilde Y} ,\boldsymbol{b}{\tilde Y} $
参考文献
【1】Jonas Gehring and Michael Auli and David Grangier and Denis Yarats and Yann N. Dauphin. 2017. Convolutional Sequence to Sequence Learning[J]. arXiv, abs/1705.03122
【2】Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin. 2017. Attention Is All You Need[J]. arXiv, abs/1706.03762