第27章预训练语言模型
习题27.1
设计基于双向LSTM的预训练语言模型,假设下游任务是文本分类。
解答:
解答思路:
- 设计基于双向LSTM的预训练模型ELMo,并加载模型权重
- 设计基于ELMo的文本分类模型
- 自编程实现基于ELMo的文本分类
解答步骤:
第1步:设计基于双向LSTM的预训练模型ELMo,并加载模型权重
ELMo是一个双向LSTM模型,它首先使用大规模文本语料库进行预训练,当用于下游任务时,其输出表示通常作为上下文相关的词向量。(论文参考链接:https://arxiv.org/abs/1802.05365)
ELMo有多个不同模型大小的变体,这里我们以small版本为例,详见:https://allenai.org/allennlp/software/elmo.
import wget
import os
from allennlp.modules.elmo import Elmoelmo_options_file = './data/elmo_2x1024_128_2048cnn_1xhighway_options.json'
elmo_weight_file = './data/elmo_2x1024_128_2048cnn_1xhighway_weights.hdf5'
url = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x1024_128_2048cnn_1xhighway/elmo_2x1024_128_2048cnn_1xhighway_options.json"
if(not os.path.exists(elmo_options_file)):
wget.download(url, elmo_options_file)
url = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x1024_128_2048cnn_1xhighway/elmo_2x1024_128_2048cnn_1xhighway_weights.hdf5"
if(not os.path.exists(elmo_weight_file)):
wget.download(url, elmo_weight_file)# 加载模型
elmo = Elmo(elmo_options_file, elmo_weight_file, 1)elmoElmo(
(_elmo_lstm): _ElmoBiLm(
(_token_embedder): _ElmoCharacterEncoder(
(char_conv_0): Conv1d(16, 32, kernel_size=(1,), stride=(1,))
(char_conv_1): Conv1d(16, 32, kernel_size=(2,), stride=(1,))
(char_conv_2): Conv1d(16, 64, kernel_size=(3,), stride=(1,))
(char_conv_3): Conv1d(16, 128, kernel_size=(4,), stride=(1,))
(char_conv_4): Conv1d(16, 256, kernel_size=(5,), stride=(1,))
(char_conv_5): Conv1d(16, 512, kernel_size=(6,), stride=(1,))
(char_conv_6): Conv1d(16, 1024, kernel_size=(7,), stride=(1,))
(_highways): Highway(
(_layers): ModuleList(
(0): Linear(in_features=2048, out_features=4096, bias=True)
)
)
(_projection): Linear(in_features=2048, out_features=128, bias=True)
)
(_elmo_lstm): ElmoLstm(
(forward_layer_0): LstmCellWithProjection(
(input_linearity): Linear(in_features=128, out_features=4096, bias=False)
(state_linearity): Linear(in_features=128, out_features=4096, bias=True)
(state_projection): Linear(in_features=1024, out_features=128, bias=False)
)
(backward_layer_0): LstmCellWithProjection(
(input_linearity): Linear(in_features=128, out_features=4096, bias=False)
(state_linearity): Linear(in_features=128, out_features=4096, bias=True)
(state_projection): Linear(in_features=1024, out_features=128, bias=False)
)
(forward_layer_1): LstmCellWithProjection(
(input_linearity): Linear(in_features=128, out_features=4096, bias=False)
(state_linearity): Linear(in_features=128, out_features=4096, bias=True)
(state_projection): Linear(in_features=1024, out_features=128, bias=False)
)
(backward_layer_1): LstmCellWithProjection(
(input_linearity): Linear(in_features=128, out_features=4096, bias=False)
(state_linearity): Linear(in_features=128, out_features=4096, bias=True)
(state_projection): Linear(in_features=1024, out_features=128, bias=False)
)
)
)
(_dropout): Dropout(p=0.5, inplace=False)
(scalar_mix_0): ScalarMix(
(scalar_parameters): ParameterList(
(0): Parameter containing: [torch.FloatTensor of size 1]
(1): Parameter containing: [torch.FloatTensor of size 1]
(2): Parameter containing: [torch.FloatTensor of size 1]
)
)
)
从模型结构可以看到,ELMo主要由一个token编码器、一个双向双层LSTM和输出层构成。其中token编码器为输入的token计算输入向量表示,然后双向双层LSTM计算隐层(状态),最后,输出层将输入向量表示以及两层LSTM的隐层(状态)进行混合,得到最后的输出表示。
第2步:设计基于ELMo的文本分类模型
文本分类模型主要由预训练模型ELMo、基于双向LSTM的编码器、全连接层分类器三部分组成。
假设输入单词序列是
首先,将单词序列
结合习题25.4,基于双向LSTM的编码器如下所示:
前向的LSTM的隐层(状态):
后向的LSTM的隐层(状态):
其中,
这里,将两者的拼接表示为:
其中,;表示两个向量的拼接。
然后,将所有token的表示进行Mean-Pooling,得到输入单词序列
最后,将这一表示喂入分类器,获得每个类别的概率:
在训练时,通常将预训练模型ELMo的参数进行固定,然后使用交叉熵作为损失函数,优化基于双向LSTM的编码器和全连接层分类器。
第3步:自编程实现双向LSTM的预训练语言模型
import time
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
from torchtext.datasets import AG_NEWS
from allennlp.modules.elmo import batch_to_idslabel_pipeline = lambda x : int(x) - 1device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def collate_batch(batch):
label_list, text_list = [], []
for (_label, _text) in batch:
label_list.append(label_pipeline(_label))
text_list.append(_text.split())
label_list = torch.tensor(label_list, dtype=torch.int64)
return label_list.to(device), text_list# 加载AG_NEWS数据集
train_iter, test_iter = AG_NEWS(root='./data')
train_dataset = to_map_style_dataset(train_iter)
test_dataset = to_map_style_dataset(test_iter)
num_train = int(len(train_dataset) * 0.95)
split_train_, split_valid_ = \
random_split(train_dataset, [num_train, len(train_dataset) - num_train])
BATCH_SIZE = 128
train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,
shuffle=False, collate_fn=collate_batch)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE,
shuffle=False, collate_fn=collate_batch)class TextClassifier(nn.Module):
def __init__(self, embedding_dim, hidden_dim, num_classes):
super().__init__()
# 使用预训练的ELMO
self.elmo = elmo
# 使用双向LSTM
self.lstm = nn.LSTM(embedding_dim, hidden_dim, bidirectional=True, batch_first=True)
# 使用线性函数进行文本分类任务
self.fc = nn.Linear(hidden_dim * 2, num_classes)
self.dropout = nn.Dropout(0.5)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.uniform_(-initrange, initrange)
def forward(self, sentence_lists):
character_ids = batch_to_ids(sentence_lists)
character_ids = character_ids.to(device)
embeddings = self.elmo(character_ids)
embedded = embeddings['elmo_representations'][0]
x, _ = self.lstm(embedded)
x = x.mean(1)
x = self.dropout(x)
x = self.fc(x)
return xEMBED_DIM = 256
HIDDEN_DIM = 64
NUM_CLASSES = 4
LEARNING_RATE = 1e-2
# 由于单个epochs运行时间达到5分钟,
# 有条件的小伙伴可以设置更多的epoch,达到更好的训练效果
NUM_EPOCHS = 1model = TextClassifier(EMBED_DIM, HIDDEN_DIM, NUM_CLASSES).to(device)def train(dataloader):
model.train()
for idx, (label, text) in enumerate(dataloader):
optimizer.zero_grad()
predicted_label = model(text)
loss = criterion(predicted_label, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()def evaluate(dataloader):
model.eval()
total_acc, total_count = 0, 0
with torch.no_grad():
for idx, (label, text) in enumerate(dataloader):
predicted_label = model(text)
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
return total_acc/total_count# 使用交叉熵损失函数
criterion = nn.CrossEntropyLoss().to(device)
# 设置优化器
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)for epoch in range(1, NUM_EPOCHS + 1):
epoch_start_time = time.time()
train(train_dataloader)
accu_val = evaluate(valid_dataloader)
print('-' * 59)
print('| end of epoch {:3d} | time: {:5.2f}s | '
'valid accuracy {:8.1f}% '.format(epoch,
time.time() - epoch_start_time,
accu_val * 100))
print('-' * 59)-----------------------------------------------------------
| end of epoch 1 | time: 321.49s | valid accuracy 90.4%
-----------------------------------------------------------
ag_news_label = {1: "World", 2: "Sports", 3: "Business", 4: "Sci/Tec"}def predict(text):
with torch.no_grad():
output = model([text])
return output.argmax(1).item() + 1ex_text_str = """
Our younger Fox Cubs (Y2-Y4) also had a great second experience
of swimming competition in February when they travelled over to
NIS at the end of February to compete in the SSL Development
Series R2 event. For students aged 9 and under these SSL
Development Series events are a great introduction to
competitive swimming, focussed on fun and participation whilst
also building basic skills and confidence as students build up
to joining the full SSL team in Year 5 and beyond.
"""
print("This is a %s news" %ag_news_label[predict(ex_text_str)])This is a Business news
习题27.2
假设GPT微调的下游任务是两个文本的匹配,写出学习的目标函数。
解答:
解答思路:
- 给出GPT模型的描述
- 给出文本匹配任务的描述
- 写出GPT微调的下游任务是两个文本匹配时的学习的目标函数
解答步骤:
第1步:给出GPT模型的描述
根据书中第27章的本章概要的GPT模型的描述:
GPT模型的输入是单词序列,可以是一个句子或一段文章。首先经过输入层,产生初始的单词表示向量的序列。之后经过
个Transformer解码层,得到单词表示向量的序列,GPT模型的输出是在单词序列各个位置上的条件概率。
GPT预训练时,通过极大似然估计学习模型的参数。GPT微调时,通过优化下游任务的目标函数,进一步调节模型的参数。
第2步:给出文本匹配任务的描述
根据书中第27.2.2节的文本匹配任务的描述:
如果下游任务是文本匹配,如判断两句话是否形成一问一答。输入单词序列是
,输出是类别 ,仍然计算条件概率 。类别有两类,表示匹配或不匹配。这时单词序列 是两个单词序列合成的序列,如一个问句和一个答句合并而成。以特殊字符<cls>开始,中间以特殊字符<sep>间隔,最后以特殊字符<sep>结束。
第3步:写出GPT微调的下游任务是两个文本匹配时的学习的目标函数
假设分别有两个文本,矩阵
经过输入层,产生初始的单词表示向量的序列,分别表示为
将两个句子分别作为前句或后句,构造两个完整的文本:
- 文本1:<Start>,
<Delim>, , <Extract> - 文本2:<Start>,
<Delim>, , <Extract>
分别进行GPT预训练模型:
将得到单词表示向量的序列进行融合,使用线性层得到GPT模型的输出:
在预训练阶段,目标函数是
微调时,下游任务是文本匹配,输入的单词序列是两个文本合的序列
可得到微调的目标函数为
习题27.3
设计一个2层卷积神经网络编码器和2层卷积神经网络解码器组成的自动编码器(使用第28章介绍的转置卷积)。
解答:
解答思路:
- 给出自动编码器的原理
- 给出转置卷积的定义
- 自编程实现2层卷积自动编码器
解答步骤:
第1步:自动编码器的原理
根据书中第27.2.2节的自动编码器的描述:
自动编码器(auto encoder)是用于数据表示的无监督学习的一种神经网络。自动编码器由编码器网络和解码器网络组成。 最基本的情况下,编码器和解码器分别都是一层神经网络
其中,
是权重矩阵, 是偏置向量, 是激活函数。
学习时,目标函数是
第2步: 转置卷积的定义
根据书中第28.2.1节的转置卷积的定义:
转置卷积(transposed convolution)也称为微步卷积(fractionally strided convolution)或反卷积(deconvolution),在图像生成网络、图像自动编码器等模型中广泛使用。卷积可以用于图像数据尺寸的缩小,而转置卷积可以用于图像数据尺寸的放大,又分别称为下采样或上采样。
根据书中第28章的本章概要的转置卷积的运算:
对于任意一个卷积运算,存在对应的线性变换的矩阵
。针对转置矩阵 ,引入新的卷积运算,称为转置卷积。原始卷积和转置卷积是相互对应、互为反向的运算。原始卷积的卷积核是 时,转置卷积的卷积核是 。卷积核和转置卷积核之间有 成立。
第3步:自编程实现2层卷积自动编码器
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import tqdm
from matplotlib import pyplot as plt
from torch import optim
from torch.utils.data import DataLoader
from torchvision.datasets import mnist
from torchviz import make_dotclass AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# 2层卷积神经网络编码器
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, 2, 1),
nn.ReLU(),
nn.Conv2d(16, 32, 3, 2, 1),
nn.ReLU()
)
# 2层卷积神经网络解码器
self.decoder = nn.Sequential(
# 使用转置卷积
nn.ConvTranspose2d(32, 16, 3, 2, 1, output_padding=1),
nn.ReLU(),
nn.ConvTranspose2d(16, 1, 3, 2, 1, output_padding=1),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 使用MNIST数据集
train_set = mnist.MNIST('./data', transform=transforms.ToTensor(), train=True, download=True)
test_set = mnist.MNIST('./data', transform=transforms.ToTensor(), train=False, download=True)
train_dataloader = DataLoader(train_set, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_set, batch_size=8, shuffle=False)model = AutoEncoder().to(device)
# 设置损失函数
criterion = nn.MSELoss()
# 设置优化器
optimizer = optim.Adam(model.parameters(), lr=1e-2)# 显示模型结构
modelAutoEncoder(
(encoder): Sequential(
(0): Conv2d(1, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): ReLU()
(2): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(3): ReLU()
)
(decoder): Sequential(
(0): ConvTranspose2d(32, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(1): ReLU()
(2): ConvTranspose2d(16, 1, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(3): Sigmoid()
)
)
# 模型训练
EPOCHES = 10
for epoch in range(EPOCHES):
for img, _ in tqdm.tqdm(train_dataloader, ):
optimizer.zero_grad()
img = img.to(device)
out = model(img)
loss = criterion(out, img)
loss.backward()
optimizer.step()100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:10<00:00, 180.98it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:09<00:00, 188.63it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:09<00:00, 189.27it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:10<00:00, 178.80it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:10<00:00, 185.14it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:09<00:00, 187.51it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:10<00:00, 179.53it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:10<00:00, 186.49it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:09<00:00, 189.39it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1875/1875 [00:09<00:00, 189.29it/s]
# 将生成图片和原始图片进行对比
for i, data in enumerate(test_dataloader):
img, _ = data
img = img.to(device)
model = model.to(device)
img_new = model(img).detach().cpu().numpy()
img = img.cpu().numpy()
plt.figure(figsize=(8, 2))
for j in range(8):
plt.subplot(2, 8, j + 1)
plt.axis('off')
plt.imshow(img_new[j].squeeze())
plt.subplot(2, 8, 8 + j + 1)
plt.axis('off')
plt.imshow(img[j].squeeze())
if i >= 2:
break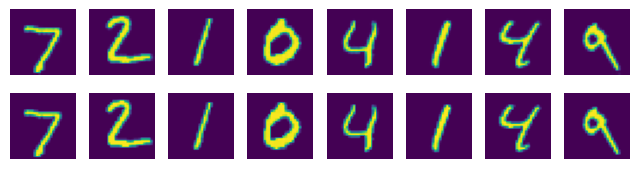

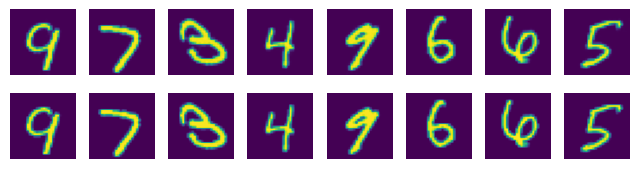
def save_model_structure(model, device):
x = torch.randn(1, 1, 28, 28).requires_grad_(True).to(device)
y = model(x)
vise = make_dot(y, params=dict(list(model.named_parameters()) + [('x', x)]))
vise.format = "png"
vise.directory = "./data"
vise.view("2-Layer-CNN-AutoEncoder-Struction", cleanup=True)# 保存模型架构图
save_model_structure(model, device)习题27.4
证明当编码器和解码器都是线性函数时,主成分分析可以作为自动编码器学习的方法。
解答:
解答思路:
- 给出主成分分析的定义
- 给出自动编码器学习过程
- 证明当编码器和解码器都是线性函数时,主成分分析可以作为自动编码器学习的方法
解答步骤:
第1步:主成分分析的定义
根据书中第16章的主成分分析的基本思想:
主成分分析中,首先对给定数据进行规范化,使得数据每一变量的平均值为0,方差为1,之后对数据进行正交变换,原来由线性相关变量表示的数据通过正交变换变成由若干个线性无关的新变量表示的数据。新变量是可能的正交变换中变量的方差的和(信息保存)最大的,方差表示在新变量上信息的大小。将新变量依次称为第一主成分、第二主成分等。这就是主成分分析的基本思想。
根据书中第16.2.3节的算法16.1主成分分析算法:
算法16.1(主成分分析算法)
输入:样本矩阵 ,其每一行元素的均值为零;
输出:样本主成分矩阵 。
参数:主成分个数
(1)构造新的矩阵
每一列的均值为零。
(2)对矩阵进行截断奇异值分解,得到 有
个奇异值、奇异向量。矩阵 的前 列构成 个样本主成分。
(3)求样本主成分矩阵
第2步:自动编码器学习过程
根据书中第27章的本章概要的自动编码器的描述:
自动编码器是用于数据表示的无监督学习的一种神经网络。自动编码器由编码器网络和解码器网络组成。学习时编码器将输入向量转换为中间表示向量,解码器再将中间表示向量转换为输出向量。编码器和解码器可以是
学习的目标是尽量使输出向量和输入向量保持一致,或者说重建输入向量。认为学到的中间表示向量就是数据的表示。
学习的算法一般是梯度下降。自动编码器学习实际进行的是对数据的压缩。
第3步:证明当编码器和解码器都是线性函数时,主成分分析可以作为自动编码器学习的方法
假设给定样本矩阵
这样,样本主成分矩阵
根据自动编码器中的编码阶段,编码器对数据进行压缩,当编码器是线性函数时,可用主成分矩阵
其中
在解码阶段,解码器通过解压可以得到原始数据的近似,当解码器是线性函数时,可用单位特征向量
其中
综上所述,当损失函数是平方损失函数时,自动编码器学习的目标函数是
由于单位特征向量
习题27.5
解释为什么BERT预训练中的掩码语言模型化是基于去噪自动编码器原理的。
解答:
解答思路:
- 给出BERT预训练中的掩码语言模型化描述
- 给出去噪自动编码器的原理
- 解释BERT预训练中的掩码语言模型化是基于去噪自动编码器原理的原因
解答步骤:
第1步:BERT预训练中的掩码语言模型化的描述
根据书中第27.2.2节的关于BERT预训练中的掩码语言模型化的描述:
BERT模型的预训练由两部分组成,掩码语言模型化和下句预测。掩码语言模型化的目标是复原输入单词序列中被掩码的单词。可以看作是去噪自动编码器学习,对被掩码的单词独立地进行复原。掩码单词序列表示为
。
掩码语言模型化在每一个掩码位置计算条件概率:假设第
个位置是掩码位置, 是在第 层第 个位置的表示, 是预测的单词, 是单词的权重矩阵。
第2步:去噪自动编码器的原理
根据书中第27章的本章概要的去噪自动编码器的描述:
去噪自动编码器是自动编码器的一种扩展,去噪自动编码器不仅可以用于数据表示学习,而且可以用户数据去噪。学习时首先根据对输入向量进行的随机变化,得到有噪声的输入向量。编码器将有噪声的输入向量转换为中间表示向量,解码器再将中间表示向量转换为输出向量。编码器、解码器、目标函数分别是
学习的目标是尽量使输出向量和原始输入向量保持一致,或者说重建原始输入向量。因为学习的目标是排除噪声的干扰重建数据,去噪自动编码器能更有效地学到数据的主要特征。
第3步:解释BERT预训练中的掩码语言模型化是基于去噪自动编码器原理的原因
BERT在预训练阶段,输入序列中的一些单词被随机遮掩,掩盖单词的过程相当于向输入序列中添加了一些噪声,得到有噪声的输入向量,模型需要预测并复原这些单词。这个过程类似于去噪自动编码器的学习过程,其中模型需要从缺失的或噪声的数据中重构原始数据。因此,掩码语言模型化提供了一些“噪音”,让模型学会从不完整的输入中推断出缺失的信息,从而提高模型的泛化能力。这也就说明了BERT预训练中的掩码语言模型化是基于去噪自动编码器原理的。
习题27.6
比较BERT与Transformer编码器在模型上的异同。
解答:
解答思路:
- 给出BERT的模型描述
- 给出Transformer编码器的模型描述
- 比较BERT与Transformer编码器在模型上的异同
解答步骤:
第1步:BERT模型的描述
根据书中第27.2.2节的关于BERT的描述:
BERT是双向Transformer编码器表示(Bidirectional Encoder Representations from Transformers)的缩写。BERT的模型基于Transformer的编码器,是双向语言模型。BERT的预训练主要是掩码语言模型化,使用大规模语料基于自去噪自动编码器原理进行模型的参数估计,学习的目标是复原给定的掩码单词序列中被掩码的每一个单词。学习和预测都是非自回归过程(Non-autoregressive process)。 每一个单词序列是一个句子或一段文章。首先经过输入层,产生初始的单词表示向量的序列,记作矩阵
: 其中,矩阵
表示单词的词嵌入的序列 ;矩阵 表示单词的位置嵌入的序列 ;矩阵 是区别前后单词的标记序列 ,含有 个向量 和 个向量 。 是 矩阵,设词嵌入、位置嵌入、标记向量的维度是 。
根据书中第27章的本章概要的BERT模型的描述:
BERT模型的输入是两个合并的单词序列。首先经过输入层,产生初始的单词表示向量的序列。之后经过
个Transformer编码层,得到单词的表示向量的序列。BERT模型的输出是在单词序列的各个位置上的条件概率。
BERT模型的预训练由掩码语言模型化和下句预测组成。掩码语言模型化的目标是复原输入单词序列中被掩码的单词。下句预测的目标是判断输入单词序列是否来自同一篇文章。预训练以掩码语言模型化为主,其损失函数是BERT微调时,通过优化下游任务的目标函数,进一步调节模型的参数。
第2步:Transformer编码器的模型描述
根据书中第26.3.1节关于Transformer编码器的描述:
Transformer(转换器)由编码器和解码器组成。编码器有1个输入层、6个编码层(一般是
层)。解码器有1个输入层、6个解码层、1个输出层。编码器的输入层与第1个编码层连接,第1个编码层再与第2个编码层连接,依次连接,直到第6个编码层。解码器的输入层与第1个解码层连接,第1个解码层再与第2个解码层连接,依次连接,直到第6个解码层。第6个解码层再与输出层连接。第6个编码层与各个解码层之间也有连接。
编码器的6个编码层将输入单词序列进行转换,得到中间表示序列。
编码器的6个编码层有相同的结构,每一个编码层由自注意力子层和前馈网络子层两部分组成。
在编码器的输入层,输入序列的各个位置有单词的词嵌入(word embedding)和位置嵌入(position embedding),其中位置嵌入表示在序列中的位置。在每一个位置以词嵌入和位置嵌入的和作为该位置的输入向量。单词的词嵌入通常通过对单词的独热向量进行一个线性变化得到,即用一个矩阵乘以独热向量,矩阵称为词嵌入矩阵。
根据书中第26.3.1节关于Transformer编码器计算公式:
在编码器的输入层通过线性变换获得单词的词嵌入。
其中,
是单词的独热向量, 是单词的词嵌入, 是嵌入矩阵。嵌入矩阵在学习中自动获得。
编码器的输入层的每一个位置的输入向量是
其中,
编码器的每一层的每一个位置的前馈网络是
其中,
编码器的每一层的每一个位置的层归一化函数是
其中,
是均值, 是方差, 和 是参数, 是常量。
编码器的输入层的计算可以写作编码器的第
个编码器的多头自注意力子层和前馈网络子层计算可以写作 其中,
是第 个编码层的所有位置的输出, 是所有位置的输入, 是中间结果; 和 的计算针对矩阵的每一列, 的计算针对矩阵整体进行。
第3步:比较BERT与Transformer编码器在模型上的异同
相同点:
- 两者都是基于多头注意力机制的架构设计,使用了自注意力机制来处理输入序列。
- 两者都使用了残差连接和层归一化。
- 两者都可以使用预训练技术提高模型的泛化能力。
不同点:
- BERT模型在Transformer模型的基础上添加了掩码语言模型和下句预测任务。
- BERT模型在训练的时候会在其后添加线性层和softmax层,用于预测掩码语言模型和下句预测任务;Transformer编码器则是直接和Transformer解码器连接,用于预测序列的下一个单词。
- BERT模型中输入序列的嵌入由词嵌入、位置嵌入、区别前后单词的标记序列的和组成;Transformer编码器模型的输入序列的嵌入由词嵌入、位置嵌入的和组成。
- BERT模型使用了双向语言模型,能够同时处理输入序列的左右两个方向;Transformer编码器通常只处理从左到右的输入序列。
- BERT模型的位置嵌入通过学习得到;Transformer的位置嵌入由公式计算得到。
参考文献
【1】Matthew E. Peters and Mark Neumann and Mohit Iyyer and Matt Gardner and Christopher Clark and Kenton Lee and Luke Zettlemoyer. 2018. Deep contextualized word representations. arXiv, abs/1802.05365
【2】ELMo:https://allenai.org/allennlp/software/elmo