第25章循环神经网络
习题25.1
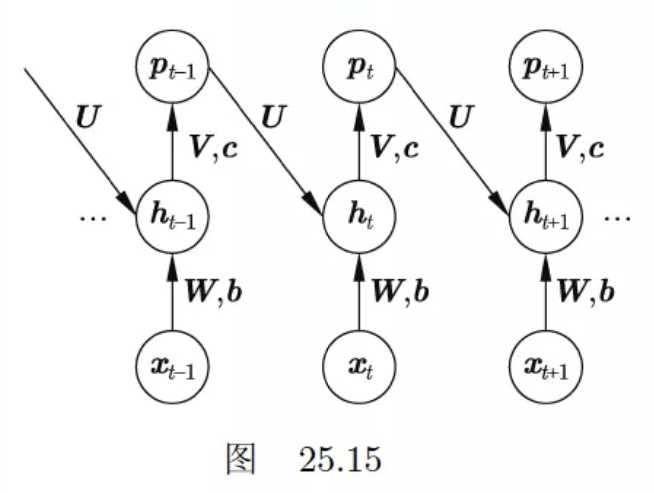
Jordan提出的循环神经网络如图25.15所示。试写出这种神经网络的公式,并与Elman提出的简单循环神经网络做比较。
解答:
解答思路:
- 给出简单循环神经网络(S-RNN)的定义
- 给出Jordan提出的循环神经网络的公式
- 比较Jordan RNN和S-RNN
解答步骤:
第1步:简单循环神经网络(S-RNN)的定义
根据书中第25.1.1节的定义25.1的简单循环神经网络(即Elman提出的简单循环神经网络)的定义:
定义25.1(简单循环神经网络) 称以下的神经网络为简单循环神经网络。神经网络以序列数据
为输入,每一项是一个实数向量。在每一个位置上重复使用同一个神经网络结构。在第 个位置上( ),神经网络的隐层或中间层以 和 为输入,以 为输出,其间有以下关系成立: 其中,
表示第 个位置上的输入,是一个实数向量 ; 表示第 个位置的状态,也是一个实数向量 ; 表示第 个位置的状态 ,也是一个实数向量; 是权重矩阵; 是偏置向量。神经网络的输出层以 为输入, 为输出,有以下关系成立: 其中,
表示第 个位置上的输出,是一个概率向量 ,满足 ; 是权重矩阵; 是偏置向量。神经网络输出序列数据 ,每一项是一个概率向量。
以上公式还可以写作其中,
是隐层的净输入向量, 是输出层的净输入向量。隐层的激活函数通常是双曲正切函数,也可以是其他激活函数;输出层的激活函数通常是软最大化函数。
第2步:给出Jordan提出的循环神经网络的公式
根据图25.15的循环神经网络架构,可得循环神经网络的公式如下:
第3步:比较Jordan RNN和S-RNN
相同点:
- 两者都是描述动态系统的非线性模型
- 两者都满足循环神经网络的基本特点,包括可以处理任意长度的序列数据、属于自回归模型、具有强大的表示能力
- 两者都不能进行并行化处理
不同点:
- Jordan RNN采用softmax处理隐含层后的输出层作为下一层隐含层的输入,而 S-RNN 采用的是softmax处理前的隐含层作为下一层隐含层的输入
- 由于Jordan RNN采用的是经softmax处理后的隐含层,所以其分布较原本的隐含层改变了,尤其是类别间的差距被非线性放大或缩小(负值厌恶),这种对正负向的偏好在信息量表达上是不利的,这里直接建模相邻时间节点的隐含层可以建立更直接的相邻隐含层分布之间的关系,拥有更高的拓展性和普适性,所以后续的循环神经网络多以 S-RNN 作为基础机构。
习题25.2
写出循环神经网络的层归一化的公式。
解答:
解答思路:
- 给出层归一化的基本概念
- 写出循环神经网络的层归一化的公式
解答步骤:
第1步:层归一化的基本概念
根据书中第23.2.5节的层归一化的描述:
层归一化(layer normalization)是另一种防止内部协变量偏移的方法。其基本想法与批量归一化相同,但是是在每一层的神经元上进行归一化,而不是在每一个批量的样本上进行归一化。优点是实现简单,也没有批量大小的超参数需要调节。
层归一化在每一层的神经元的净输入上进行。假设当前层的神经元的净输入是,其中 是第 个神经元的净输入, 是神经元个数。训练和预测时,首先计算这一层的神经元的净输入的均值与方差(无偏估计)。 然后对每一个神经元的净输入进行归一化,得到数值:
其中,
是一个很小的正数。之后再进行仿射变换,得到数值: 其中,
和 是参数。最后将归一化加仿射变换的结果作为这一层神经元的实际净输入。在每一层都做相同的处理。神经网络的每一层都有两个参数 和 。
第2步:写出循环神经网络的层归一化的公式
对于第
记作
在循环神经网络中,假设在
其中
习题25.3
比较前馈神经网络的反向传播算法与循环神经网络的反向传播算法的异同。
解答:
解答思路:
- 给出前馈神经网络的反向传播算法
- 给出循环神经网络的反向传播算法
- 比较两者的异同
解答步骤:
第1步:前馈神经网络的反向传播算法
根据书中第23.2.3节的算法23.3的前馈神经网络的反向传播算法:
算法23.3 (前馈神经网络的反向传播算法)
输入:神经网络,参数向量 ,一个样本
输出:更新的参数向量
超参数:学习率
1.正向传播,得到各层输出For
,do { }
2.反向传播,得到各层误差
,同时计算各层的梯度,更新各层的参数。
计算输出层的误差For
,do {
计算第层的梯度 根据梯度下降公式更新第
层的参数 If (
) {
将第层的误差传到第 层 }
} 3.返回更新的参数向量
第2步:循环神经网络的反向传播算法
根据书中第25.1.2节的算法25.1的循环神经网络的反向传播算法:
算法25.1(随时间的反向传播算法)
输入:循环神经网络,参数 ,样本 和 。
输出:更新的参数
超参数:学习率1.正向传播,得到各个位置的输出
For,do {
将信号从前向后传播,计算隐层的输出和输出层的输出 } 2.反向传播,得到各个位置的梯度
For,do {
计算输出层的梯度将梯度从后向前传播,计算隐层的梯度
If () { } else {
}
}
3.进行参数更新
计算梯度根据梯度下降公式更新参数
4.返回更新的参数
第3步:比较两者的异同
相同点:
- 两者的反向传播学习的过程步骤相同,都是正向传播、反向传播、参数更新、返回更新的参数
- 两者在反向传播过程中都会因矩阵连乘,导致梯度消失和梯度爆炸
不同点:
- 在循环神经网络的反向传播中,矩阵的连乘接近矩阵的连续自乘,导致其梯度消失与爆炸的风险更严重;
- 循环神经网络的反向传播算法需要在时间上展开,计算量更大;
- 循环神经网络的反向传播算法中,每一个位置的参数共享,传播梯度为所有位置求和。而前馈网络神经网络的反向传播算法中没有参数共享;
- 循环神经网络的反向传播算法中,隐层的梯度来自输出层的梯度和下一个位置的隐层梯度两个方向。而前馈网络神经网络的反向传播算法中,隐层梯度只来自于输出层的梯度。
习题25.4
写出LSTM模型的反向传播算法公式。
解答:
解答思路:
- 给出LSTM的基本概念
- 写出LSTM的反向传播算法公式推导
- 写出LSTM的反向传播算法
解答步骤:
第1步:LSTM的基本概念
根据书中第25.2.1节的定义25.2的长短期记忆网络(LSTM):
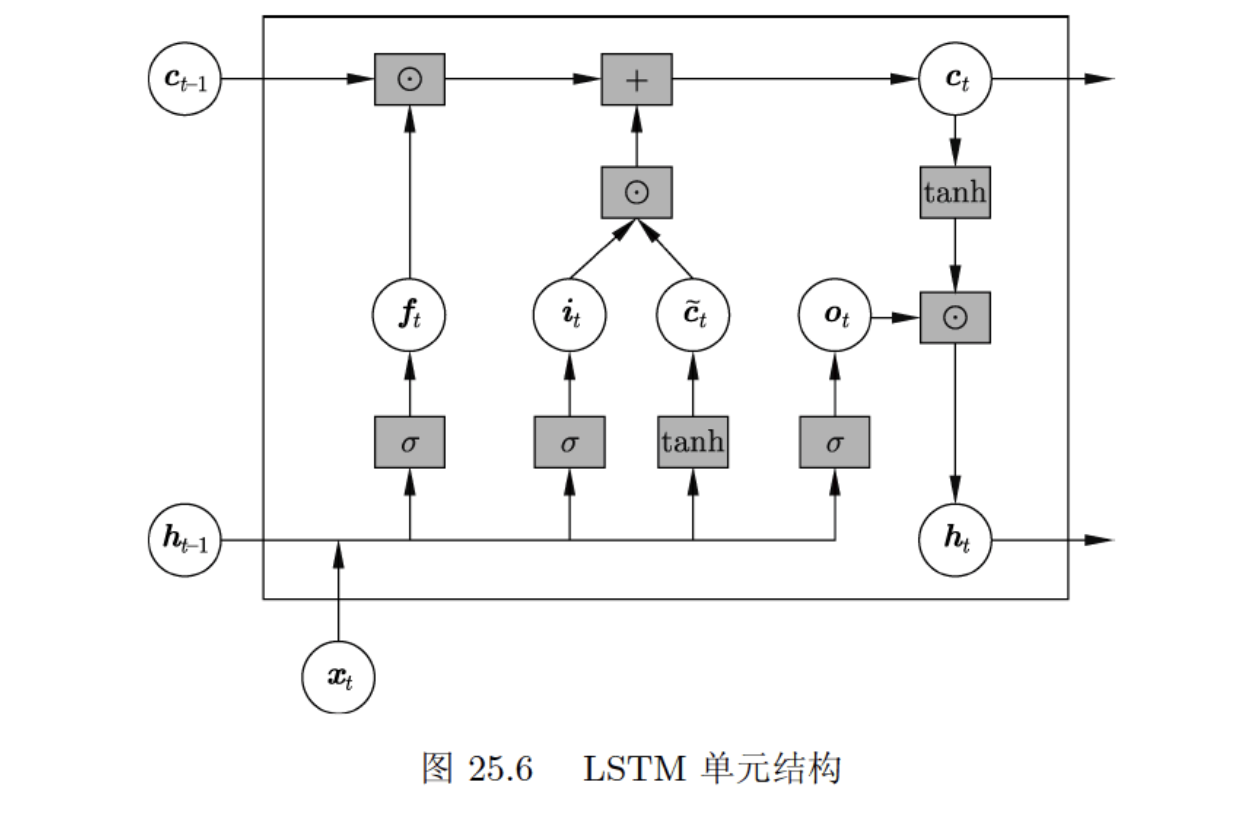
定义25.2(长短期记忆网络) 以下的循环神经网络称为长短期记忆网络。在循环网络的每一个位置上有状态和记忆元,以及输入门、遗忘门、输出门,构成一个单元。第
个位置上 的单元是以当前位置的输入 、之前位置的记忆元 、之前位置的状态 为输入,以当前位置的状态 和当前位置的记忆元 为输出的函数,由以下方式计算。 这里
是输入门, 是遗忘门, 是输出门, 是中间结果。状态 、记忆元 、输入门 、遗忘门 、输出门 都是向量,其维度相同。
第2步:写出LSTM的反向传播算法公式推导
由上述LSTM算法公式,现为了区分
这里
现考虑,已知
假设某一隐层的输出
根据上述计算过程,可计算各个计算公式的中间输出结果的梯度:
可求得各个参数的梯度,注意参数是在每个位置共享的,需要对所有位置求和。
第3步:写出LSTM的反向传播算法
输入:LSTM网络
输出:更新的参数
超参数:
- 正向传播,得到各个位置的输出
For
将信号从前向后传播,计算隐层的输出
}
- 反向传播,得到各个位置的梯度
For
计算输出层的梯度$\displaystyle \frac{\partial{L}}{\partial{z_t}} $
将梯度从后向前传播,计算隐层的梯度
If
其中
} else {
其中
}
- 进行参数更新
计算梯度
根据梯度下降公式更新参数
- 返回更新的参数
习题25.5
推导LSTM模型中记忆元的展开式(25.26)。
解答:
解答思路:
- 给出LSTM模型的记忆元表达式
- 使用递归法推导记忆元的展开式
解答步骤:
第1步:LSTM模型的记忆元表达式
根据书中第25.2.1节的LSTM的模型特点:
当输入门和遗忘门满足
时,当前位置的记忆元 只依赖于当前位置的输入 和之前位置的状态 ,LSTM是S-RNN的近似。当输入门和遗忘门满足 时,当前位置的记忆元 只依赖于之前位置的记忆元 ,LSTM将之前位置的记忆元复制到当前位置。
当前位置的记忆元可以展开成以下形式: 其中,
表示计算得到的第 个位置的权重。
第2步:使用递归法推导记忆元的展开式
根据递推形式,在第
在第
将式(2)带入式(1)中,可得:
逐步递归,可得:
当在第1个位置时,
所以
令第
则
习题25.6
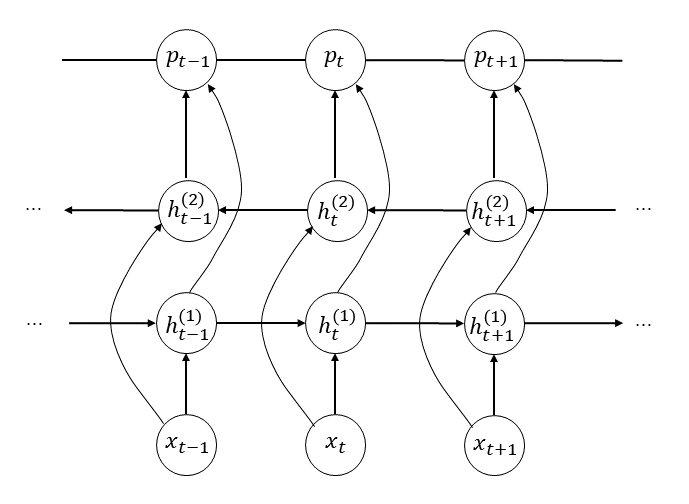
写出双向LSTM-CRF的模型公式。图25.16是双向LSTM-CRF的架构图。
解答:
解答思路:
- 给出双向循环神经网络的模型公式
- 给出LSTM模型公式
- 给出CRF模型公式
- 根据双向LSTM-CRF架构图,写出模型公式
解答步骤:
第1步:双向循环神经网络的模型公式
根据书中第25.2.4节的双向循环神经网络:
前向的循环神经网络的隐层(状态)是:
后向的循环神经网络的隐层(状态)是:
两者的拼接是
其中,;表示两个向量的拼接。
第2步:LSTM模型公式
根据书中第25.2.1节的长短期记忆网络(LSTM)的模型公式:
这里
是输入门, 是遗忘门, 是输出门, 是中间结果。状态 、记忆元 、输入门 、遗忘门 、输出门 都是向量,其维度相同。
第3步:CRF模型公式
根据书中第11.2.3节的条件随机场(CRF)的简化形式:
条件随机场可以写成向量
与 的内积的形式: 其中,$$ Z_w(x) = \sum_y \exp (w \cdot F(y, x)) \tag{11.20} $$
第4步:根据双向LSTM-CRF架构图,写出模型公式
双向LSTM-CRF的基本架构是在双向LSTM的输出层引入CRF,是序列标注的有代表性的方法。
前向的LSTM的隐层(状态)是
后向的LSTM的隐层(状态)是
其中,
两者的拼接是
其中,;表示两个向量的拼接。
将
其中,
其中,