第24章卷积神经网络
习题24.1
设有输入矩阵
产生输出矩阵
证明数学卷积和机器学习卷积有以下关系:
这里
解答:
解答思路:
- 给出机器学习二维卷积的定义
- 计算
输出矩阵 - 验证
与 相等
解答步骤:
第1步:给出机器学习二维卷积的定义
根据书中第24.1.2节的定义24.1的二维卷积的定义:
定义24.1(二维卷积) 给定一个
输入矩阵 ,一个 核矩阵 ,满足 。让核矩阵在输入矩阵上从左到右再从上到下按顺序滑动,在滑动的每一个位置,核矩阵与输入矩阵的一个子矩阵重叠。求核矩阵与每一个子矩阵的内积,产生一个 输出矩阵 ,称此运算为卷积(convolution)或二维卷积。写作
其中,
。
其中,
。
第2步:计算
令
令
第3步:验证
对于
可令
可得:
因此,
习题24.2
假设有矩阵
其中,
试求数学卷积
解答:
解答思路:
- 给出数学卷积的定义
- 给出二维数学卷积的定义
- 计算数学卷积
- 验证数学卷积满足交换律
解答步骤:
第1步:数学卷积的定义
根据书中第24.1.2节的数学卷积的定义:
在数学中,卷积(convolution)是定义在两个函数上的运算,表示用其中一个函数对另一个函数的形状进行的调整。这里考虑一维卷积。设
和 是两个可积的实值函数,则积分 定义了一个新的函数
,称为 和 的卷积,记作 其中,符号
表示卷积运算。
第2步:二维数学卷积的定义
见习题24.1中二维数学卷积:
其中输入矩阵
第3步:计算数学卷积
根据定义,计算
第4步:验证数学卷积满足交换律
不妨设
令
因此,
习题24.3
验证机器学习卷积(互相关)不满足交换律。
解答:
解答思路:
- 给出机器学习卷积定义
- 计算
- 验证
与 不相等
解答步骤:
第1步:机器学习卷积定义
根据书中第24章的本章概要的机器学习卷积的定义:
给定输入矩阵
,核矩阵 。让核矩阵在输入矩阵上按顺序滑动,(二维)卷积是定义在核矩阵与输入矩阵的子矩阵的内积,产生输出矩阵 。
其中,
第2步:计算
设
其中
令
第3步:验证
综上,
习题24.4
CNN也可以用于一维数据的处理,求图24.22所示的一维卷积。
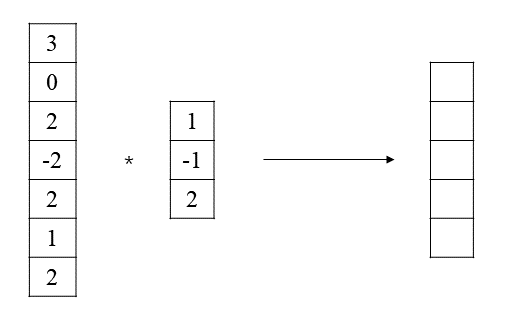
解答:
解答思路:
- 根据二维卷积的定义,写出一维卷积的定义
- 计算一维卷积的输出矩阵
解答步骤:
第1步:根据二维卷积的定义,写出一维卷积的定义
给定一个
其中
其中,
第2步:计算一维卷积的输出矩阵
根据上述公式计算可得:
一维卷积的输出矩阵为
习题24.5
通过例24.2验证卷积运算不具有旋转可变性。假设对图像数据进行90度顺时针和逆时针旋转。
解答:
解答思路:
- 将输入矩阵
顺时针旋转90度,计算卷积核为 时的输出矩阵 - 将输入矩阵
逆时针旋转90度,计算卷积核为 时的输出矩阵 - 验证旋转之后产生的输出矩阵与未旋转产生的输出矩阵不相等
解答步骤:
例24.2给定的输入矩阵
第1步:将输入矩阵
将输入矩阵
根据二维卷积定义,得到输出矩阵
第2步:将输入矩阵
将输入矩阵
根据二维卷积定义,得到输出矩阵:
第3步:验证旋转之后产生的输出矩阵与未旋转产生的输出矩阵不相等
由例24.2可知,
显然,
习题24.6
证明感受野的关系式(24.19)成立。
解答:
解答思路:
- 给出感受野的关系式
- 写出感受野递推形式的计算公式
- 用数学归纳法证明感受野关系式成立
解答步骤:
第1步:感受野的关系式
根据书中第24.1.4节的感受野的关系式:
考虑卷积神经网络全部由卷积层组成的情况,神经元的感受野的大小有以下关系成立。
设输入矩阵和卷积核都呈正方形。
表示第 层的神经元的感受野的大小, 表示第 层的卷积核的大小, 表示第 层卷积的步幅,设 。
第2步:写出感受野递推形式的计算公式
每个卷积层的每个神经元只与上一层的一部分神经元相连,故我们可根据上一层卷积层情况推导出下一层的感受野,感受野递推形式的计算公式如下:
其中,
第3步:用数学归纳法证明感受野关系式成立
当
假设当
成立。
当
结合
习题24.7
设计一个基于CNN的自然语言句子分类模型。假设句子是单词序列,每个单词用一个实数向量表示。
解答:
解答思路:
- 给出自然语言句子分类模型的参考文献和相关的模型架构图
- 使用PyTorch编程实现模型
解答步骤:
第1步:给出自然语言句子分类模型的参考文献和相关的模型架构图
根据Chen,Yahui的Convolutional neural network for sentence classification. MS thesis. University of Waterloo论文,该论文提出了一种基于CNN的自然语言句子分类模型,其模型架构图如下:
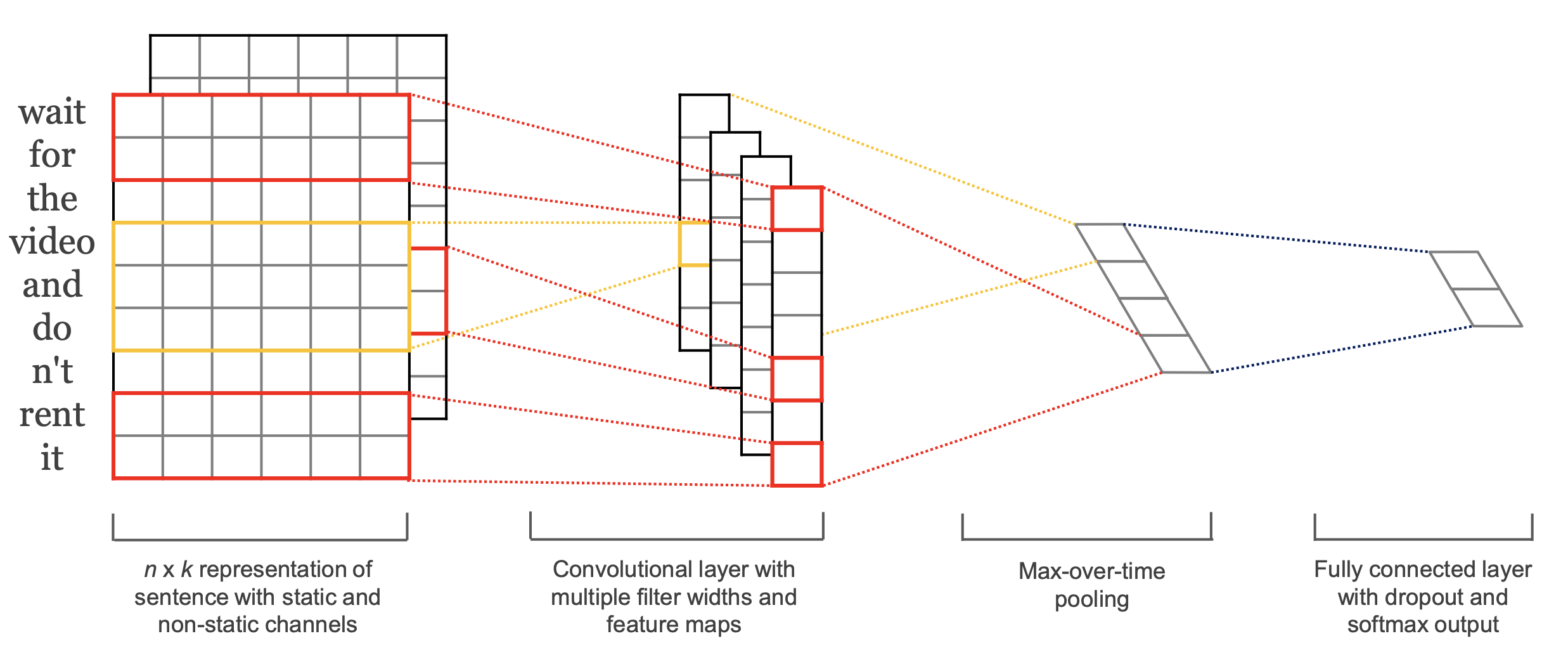
第2步:使用PyTorch编程实现模型
import time
import torch
from torch import nn, optim
from torch.utils.data import random_split, DataLoader
from torchtext.data import get_tokenizer, to_map_style_dataset
from torchtext.datasets import AG_NEWS
from torchtext.vocab import build_vocab_from_iteratordevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载AG_NEWS数据集
train_iter, test_iter = AG_NEWS(root='./data')# 定义tokenizer
tokenizer = get_tokenizer('basic_english')
# 定义数据处理函数
def yield_tokens(data_iter):
for _, text in data_iter:
yield tokenizer(text)
# 构建词汇表
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])# 将数据集映射到MapStyleDataset格式
train_dataset = list(to_map_style_dataset(train_iter))
test_dataset = list(to_map_style_dataset(test_iter))
# 划分验证集
num_train = int(len(train_dataset) * 0.9)
train_dataset, val_dataset = random_split(train_dataset, [num_train, len(train_dataset) - num_train])
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: int(x) - 1
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def collate_batch(batch):
label_list, text_list, offsets = [], [], [0]
for (_label, _text) in batch:
label_list.append(label_pipeline(_label))
processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)
text_list.append(processed_text)
offsets.append(processed_text.size(0))
label_list = torch.tensor(label_list, dtype=torch.int64)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
text_list = torch.cat(text_list)
return label_list.to(device), text_list.to(device), offsets.to(device)
BATCH_SIZE = 64
# 构建数据集的数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(val_dataset, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)class CNN_Text(nn.Module):
def __init__(self, vocab_size, embed_dim, class_num=4, dropout=0.5, kernel_size: list = None):
super(CNN_Text, self).__init__()
if kernel_size is None:
kernel_size = [3, 4, 5]
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)
self.convs = nn.ModuleList(
[nn.Conv1d(in_channels=1, out_channels=256, kernel_size=k) for k in kernel_size])
self.fc = nn.Sequential(
nn.Dropout(p=dropout),
nn.Linear(256 * len(kernel_size), 256),
nn.ReLU(),
nn.Dropout(p=dropout),
nn.Linear(256, class_num)
)
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
embedded = embedded.unsqueeze(0)
embedded = embedded.permute(1, 0, 2)
conv_outputs = []
for conv in self.convs:
conv_outputs.append(nn.functional.relu(conv(embedded)))
pooled_outputs = []
for conv_output in conv_outputs:
pooled = nn.functional.max_pool1d(conv_output, conv_output.shape[-1]).squeeze(-1)
pooled_outputs.append(pooled)
cat = torch.cat(pooled_outputs, dim=-1)
return self.fc(cat)# 设置超参数
vocab_size = len(vocab)
embed_dim = 64
class_num = len(set([label for label, _ in train_iter]))
lr = 1e-3
dropout = 0.5
epochs = 10# 创建模型、优化器和损失函数
model = CNN_Text(vocab_size, embed_dim, class_num, dropout).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()def train(dataloader):
model.train()
for label, text, offsets in dataloader:
optimizer.zero_grad()
predicted_label = model(text, offsets)
loss = criterion(predicted_label, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1)
optimizer.step()def evaluate(dataloader):
model.eval()
total_acc, total_count = 0, 0
with torch.no_grad():
for label, text, offsets in dataloader:
predicted_label = model(text, offsets)
criterion(predicted_label, label)
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
return total_acc / total_countmax_accu = 0
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train(train_dataloader)
accu_val = evaluate(valid_dataloader)
print('-' * 59)
print('| end of epoch {:3d} | time: {:5.2f}s | '
'valid accuracy {:8.1f}% '.format(epoch,
time.time() - epoch_start_time,
accu_val * 100))
print('-' * 59)
if max_accu < accu_val:
best_model = model
max_accu = accu_val-----------------------------------------------------------
| end of epoch 1 | time: 13.36s | valid accuracy 57.3%
-----------------------------------------------------------
-----------------------------------------------------------
| end of epoch 2 | time: 10.13s | valid accuracy 77.8%
-----------------------------------------------------------
-----------------------------------------------------------
| end of epoch 3 | time: 10.27s | valid accuracy 83.3%
-----------------------------------------------------------
-----------------------------------------------------------
| end of epoch 4 | time: 10.70s | valid accuracy 85.4%
-----------------------------------------------------------
-----------------------------------------------------------
| end of epoch 5 | time: 10.66s | valid accuracy 86.1%
-----------------------------------------------------------
-----------------------------------------------------------
| end of epoch 6 | time: 10.63s | valid accuracy 86.5%
-----------------------------------------------------------
-----------------------------------------------------------
| end of epoch 7 | time: 10.72s | valid accuracy 86.6%
-----------------------------------------------------------
-----------------------------------------------------------
| end of epoch 8 | time: 10.75s | valid accuracy 86.6%
-----------------------------------------------------------
-----------------------------------------------------------
| end of epoch 9 | time: 10.65s | valid accuracy 86.8%
-----------------------------------------------------------
-----------------------------------------------------------
| end of epoch 10 | time: 11.39s | valid accuracy 86.5%
-----------------------------------------------------------
# 在测试集上测试模型
test_acc = 0.0
with torch.no_grad():
for label, text, offsets in test_dataloader:
output = best_model(text, offsets)
pred = output.argmax(dim=1)
test_acc += (pred == label).sum().item()
test_acc /= len(test_dataset)
print(f"Test Acc: {test_acc * 100 :.1f}%")Test Acc: 86.9%
ag_news_label = {1: "World",
2: "Sports",
3: "Business",
4: "Sci/Tec"}
def predict(text, text_pipeline):
with torch.no_grad():
text = torch.tensor(text_pipeline(text))
output = best_model(text, torch.tensor([0]))
return output.argmax(1).item() + 1ex_text_str = """
Our younger Fox Cubs (Y2-Y4) also had a great second experience of swimming competition in February when they travelled
over to NIS at the end of February to compete in the SSL Development Series R2 event. For students aged 9 and under
these SSL Development Series events are a great introduction to competitive swimming, focussed on fun and participation
whilst also building basic skills and confidence as students build up to joining the full SSL team in Year 5 and beyond.
"""
best_model = best_model.to("cpu")
print("This is a %s news" % ag_news_label[predict(ex_text_str, text_pipeline)])This is a World news
习题24.8
设有输入矩阵
有卷积
求
解答:
解答思路:
- 给出二维卷积定义
- 计算
和 - 计算
和
解答步骤:
第1步:二维卷积定义
根据书中第24章的本章概要的二维卷积的定义:
给定输入矩阵
,核矩阵 。让核矩阵在输入矩阵上按顺序滑动,(二维)卷积是定义在核矩阵与输入矩阵的子矩阵的内积,产生输出矩阵 。 其中,
。 其中,
。
第2步:计算
- 计算
- 计算
根据二维卷积的定义,可得:
则:
第3步:计算
- 计算
- 计算
首先计算
令
则当
当
综上,
习题24.9
设有输入矩阵
验证
解答:
解答思路:
- 给出机器学习卷积的定义
- 计算
- 计算
- 验证
与 是否相等
解答步骤:
第1步:给出机器学习卷积的定义
根据书中第24章的本章概要的二维卷积的定义:
给定输入矩阵
,核矩阵 。让核矩阵在输入矩阵上按顺序滑动,(二维)卷积是定义在核矩阵与输入矩阵的子矩阵的内积,产生输出矩阵 。
其中,
其中,
第2步:计算
由题意已知:
由机器学习卷积定义,可得:
第3步:计算
由题意已知:
由机器学习卷积定义,可得:
第4步:验证
由上述计算可知:
令
又令
则
因此
综上,
习题24.10
解释残差网络为什么能防止梯度消失和梯度爆炸。
解答:
解答思路:
- 给出残差网络的基本概念
- 描述梯度消失和梯度爆炸的现象
- 解释残差网络能防止梯度消失和梯度爆炸的原因
解答步骤:
第1步:残差网络的基本概念
根据书中第24章的本章概要的残差网络的描述:
残差网络是为了解决深度神经网络训练困难而提出的深度学习方法。假设要学习的真实模型是函数
,也可以写作 残差网络的想法是用一个神经网络
近似残差 ,用 近似真实模型 ,整个过程以递归的方式进行。 残差网络由很多个残差单元串联连接组成。每一个残差单元相当于一般的前馈网络的两层,每一层由线性变换和非线性变换组成,还有一个残差连接。
残差单元的输入是向量,输出是向量 时,整个单元的运算是 残差网络可以展开成多个神经网络模块的集成,有很强的表示和学习能力。
第2步:梯度消失和梯度爆炸的现象
根据书中第23.2.5节的梯度消失与梯度爆炸:
深度神经网络学习中有时会出现梯度消失(vanishing gradient)或者梯度爆炸(exploding gradient)现象。使用反向传播算法时,首先通过正向传播计算神经网络各层的输出,然后通过反向传播神经网络各层的误差以及梯度,接着利用梯度下降公式对神经网络各层的参数进行更新。在这个过程中,各层的梯度,特别是前面层的梯度,有时会接近0(梯度消失)或接近无穷(梯度爆炸)。梯度消失会导致参数更新停止,梯度爆炸会导致参数溢出,都会使学习无法有效地进行。 反向传播中,首先计算误差向量:
之后计算梯度:
造成梯度消失和梯度爆炸的原因有两种:
- 每一层的误差向量实际由矩阵的连乘决定,连乘得到的矩阵的元素可能会接近0,也可能会接近无穷,导致梯度的元素也会接近0或接近无穷,而且越是前面的层,这个问题就越严重。
- 得到每一层的误差向量之前,每个元素乘以激活函数的导数,如果激活函数的导数过小,也容易引起梯度消失,而且越是前面的层,这个问题就越严重。
假设
其中
对于一个损失函数
在反向传播过程中,可以通过链式法则来计算每个神经元的梯度。具体地,对于第
其中
因为梯度是从输出层向输入层反向传播的,则梯度的大小可以表示为:
由于
如果 $\displaystyle \left| \frac{\partial z_j^{(l+1)}}{\partial z_i^{(l)}} \right| > 1 $,那么在反向传播时,梯度会呈现指数级增长,导致梯度爆炸的问题。这种情况通常会导致权重的值变得非常大,从而使模型无法收敛。
相反,如果
第3步:解释残差网络能防止梯度消失和梯度爆炸的原因
在残差网络中,每个残差单元可以表示为
简单地,考虑这个残差单元的导数。计算
残差网络能防止梯度消失和梯度爆炸的原因如下:
由于残差网络中的
不可能一直为-1,因此在残差网络中不容易出现梯度消失的问题。 由于残差网络中的残差映射是通过将输入直接加到输出上实现的,因此它不会影响导数的大小。这意味着如果
接近于 1,那么 ( 表示损失函数)的值也会比较稳定,不会出现梯度消失或梯度爆炸的问题。 由于残差映射中的
只包含了局部信息,而没有涉及到全局信息,因此它通常不会影响梯度的大小。这意味着即使 很小,梯度也可以通过残差映射传递到后面的层中,从而避免了梯度消失的问题。
参考文献
【1】Yoon Kim. 2014. Convolutional Neural Networks for Sentence Classification[J]. cs.CL, abs/1408.5882