8.5 torchaudio简介
Contents
8.5 torchaudio简介#
本节我们来介绍PyTorch官方用于语音处理的工具包torchaduio。语音的处理也是深度学习的一大应用场景,包括说话人识别(Speaker Identification),说话人分离(Speaker Diarization),音素识别(Phoneme Recognition),语音识别(Automatic Speech Recognition),语音分离(Speech Separation),文本转语音(TTS)等任务。
CV有torchvision,NLP有torchtext,人们希望语音领域中也能有一个工具包。而语音的处理工具包就是torchaudio。由于语音任务本身的特性,导致其与NLP和CV在数据处理、模型构建、模型验证有许多不同,因此语音的工具包torchaudio和torchvision等CV相关工具包也有一些功能上的差异。
通过本章的学习,你将收获:
语音数据的I/O
语音数据的预处理
语音领域的数据集
语音领域的模型
8.4.1 torchaduio的主要组成部分#
torchaduio主要包括以下几个部分:
torchaudio.io:有关音频的I/O
torchaudio.backend:提供了音频处理的后端,包括:sox,soundfile等
torchaudio.functional:包含了常用的语音数据处理方法,如:spectrogram,create_fb_matrix等
torchaudio.transforms:包含了常用的语音数据预处理方法,如:MFCC,MelScale,AmplitudeToDB等
torchaudio.datasets:包含了常用的语音数据集,如:VCTK,LibriSpeech,yesno等
torchaudio.models:包含了常用的语音模型,如:Wav2Letter,DeepSpeech等
torchaudio.models.decoder:包含了常用的语音解码器,如:GreedyDecoder,BeamSearchDecoder等
torchaudio.pipelines:包含了常用的语音处理流水线,如:SpeechRecognitionPipeline,SpeakerRecognitionPipeline等
torchaudio.sox_effects:包含了常用的语音处理方法,如:apply_effects_tensor,apply_effects_file等
torchaudio.compliance.kaldi:包含了与Kaldi工具兼容的方法,如:load_kaldi_fst,load_kaldi_ark等
torchaudio.kalid_io:包含了与Kaldi工具兼容的方法,如:read_vec_flt_scp,read_vec_int_scp等
torchaudio.utils:包含了常用的语音工具方法,如:get_audio_backend,set_audio_backend等
8.4.2 torchaduio的安装#
一般在安装torch的同时,也会安装torchaudio。假如我们的环境中没有torchaudio,我们可以使用pip或者conda去安装它。只需要执行以下命令即可:
pip install torchaudio # conda install torchaudio
在安装的时候,我们一定要根据自己的PyTorch版本和Python版本选择对应的torchaudio的版本,具体我们可以查看torchaudio Compatibility Matrix
8.4.3 datasets的构建#
torchaudio中对于一些公共数据集,我们可以主要通过torchaudio.datasets来实现。对于私有数据集,我们也可以通过继承torch.utils.data.Dataset来构建自己的数据集。数据集的读取和处理,我们可以通过torch.utils.data.DataLoader来实现。
import torchaudio
import torch
# 公共数据集的构建
yesno_data = torchaudio.datasets.YESNO('.', download=True)
data_loader = torch.utils.data.DataLoader(
yesno_data,
batch_size=1,
shuffle=True,
num_workers=4)
torchaudio提供了许多常用的语音数据集,包括CMUARCTIC,CMUDict,COMMONVOICE,DR_VCTK,FluentSpeechCommands,GTZAN,IEMOCAP,LIBRISPEECH,LIBRITTS,LJSPEECH,LibriLightLimited,LibriMix,MUSDB_HQ,QUESST14,SPEECHCOMMANDS,Snips,TEDLIUM,VCTK_092,VoxCeleb1Identification,VoxCeleb1Verification,YESNO等。具体的我们可以通过以下命令来查看:
import torchaudio
dir(torchaudio.datasets)
'CMUARCTIC','CMUDict','COMMONVOICE','DR_VCTK','FluentSpeechCommands',
'GTZAN','IEMOCAP','LIBRISPEECH','LIBRITTS','LJSPEECH','LibriLightLimited',
'LibriMix','MUSDB_HQ','QUESST14','SPEECHCOMMANDS','Snips','TEDLIUM',
'VCTK_092','VoxCeleb1Identification','VoxCeleb1Verification','YESNO']
8.4.4 model和pipeline的构建#
torchaudio.models包含了常见语音任务的模型的定义,包括:Wav2Letter,DeepSpeech,HuBERTPretrainModel等。torchaudio.pipelines则是将预训练模型和其对应的任务组合在一起,构成了一个完整的语音处理流水线。torchaudio.pipeline相较于torchvision这种视觉库而言,是torchaudio的精华部分。我们在此也不进行过多的阐述,对于进一步的学习,我们可以参考官方给出的Pipeline Tutorials和torchaudio.pipelines docs。
8.4.5 transforms和functional的使用#
torchaudio.transform模块包含常见的音频处理和特征提取。torchaudio.functional则包括了一些常见的音频操作的函数。关于torchaudio.transform,官方提供了一个流程图供我们参考学习:
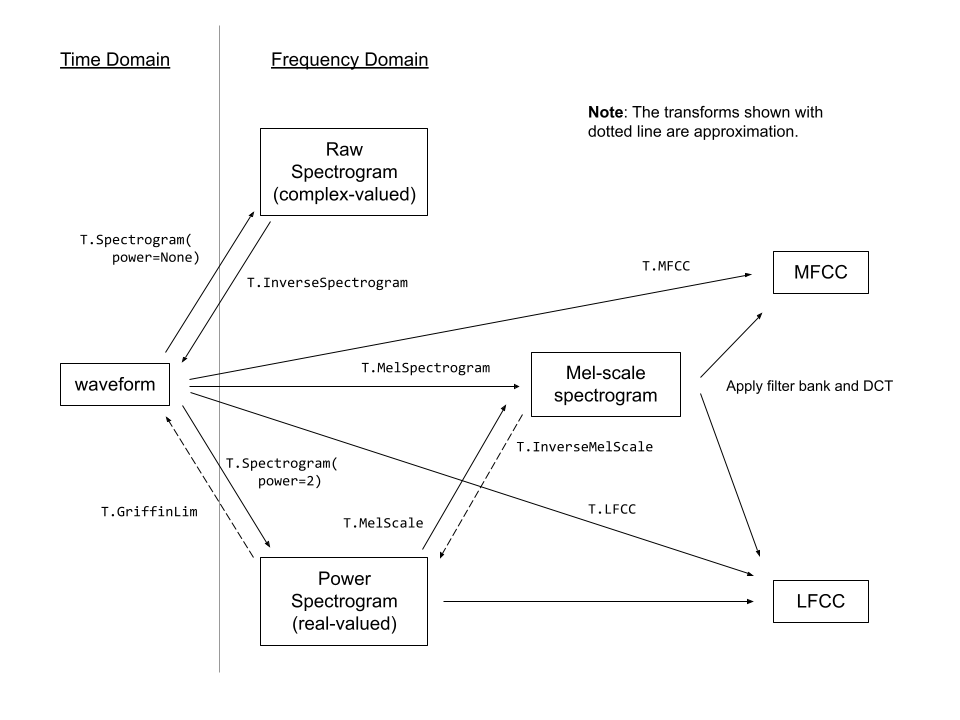 torchaudio.transforms继承于torch.nn.Module,但是不同于torchvision.transforms,torchaudio没有compose方法将多个transform组合起来。因此torchaudio构建transform pipeline的常见方法是自定义模块类或使用torch.nn.Sequential将他们在一起。然后将其移动到目标设备和数据类型。我们可以参考官方所给出的例子:
torchaudio.transforms继承于torch.nn.Module,但是不同于torchvision.transforms,torchaudio没有compose方法将多个transform组合起来。因此torchaudio构建transform pipeline的常见方法是自定义模块类或使用torch.nn.Sequential将他们在一起。然后将其移动到目标设备和数据类型。我们可以参考官方所给出的例子:
# Define custom feature extraction pipeline.
#
# 1. Resample audio
# 2. Convert to power spectrogram
# 3. Apply augmentations
# 4. Convert to mel-scale
#
class MyPipeline(torch.nn.Module):
def __init__(
self,
input_freq=16000,
resample_freq=8000,
n_fft=1024,
n_mel=256,
stretch_factor=0.8,
):
super().__init__()
self.resample = Resample(orig_freq=input_freq, new_freq=resample_freq)
self.spec = Spectrogram(n_fft=n_fft, power=2)
self.spec_aug = torch.nn.Sequential(
TimeStretch(stretch_factor, fixed_rate=True),
FrequencyMasking(freq_mask_param=80),
TimeMasking(time_mask_param=80),
)
self.mel_scale = MelScale(
n_mels=n_mel, sample_rate=resample_freq, n_stft=n_fft // 2 + 1)
def forward(self, waveform: torch.Tensor) -> torch.Tensor:
# Resample the input
resampled = self.resample(waveform)
# Convert to power spectrogram
spec = self.spec(resampled)
# Apply SpecAugment
spec = self.spec_aug(spec)
# Convert to mel-scale
mel = self.mel_scale(spec)
return mel
torchaudio.transform的使用,我们可以参考torchaudio.transforms进一步了解。
torchaudio.functional支持了许多语音的处理方法,关于torchaudio.functional的使用,我们可以参考torchaudio.functional进一步了解。
8.4.6 compliance和kaldi_io的使用#
Kaldi是一个用于语音识别研究的工具箱,由CMU开发,开源免费。它包含了构建语音识别系统所需的全部组件,是语音识别领域最流行和影响力最大的开源工具之一。torchaudio中提供了一些与Kaldi工具兼容的方法,这些方法分别属于torchaduio.compliance.kaldi,torchaduio.kaldi_io。
torchaduio.compliance.kaldi#
在torchaudio.compliance.kaldi中,torchaudio提供了以下三种方法:
torchaudio.compliance.kaldi.spectrogram:从语音信号中提取Spectrogram特征
torchaudio.compliance.kaldi.fbank:从语音信号中提取FBank特征
torchaduio.compliance.kaldi.mfcc:从语音信号中提取MFCC特征
torchaduio.kaldi_io#
torchaudio.kaldi_io是一个torchaudio的子模块,用于读取和写入Kaldi的数据集格式。当我们要使用torchaudio.kaldi_io时,我们需要先确保kalid_io已经安装。
具体来说,主要接口包括:
torchaudio.kaldi_io.read_vec_int_ark:从Kaldi的scp文件中读取float类型的数据
torchaudio.kaldi_io.read_vec_flt_scp
torchaudio.kaldi_io.read_vec_flt_ark
torchaudio.kaldi_io.read_mat_scp
torchaudio.kaldi_io.read_mat_ark
具体的使用方法,我们可以参考torchaudio.kaldi_io进一步了解。
总结#
本节我们主要介绍了torchaudio的基本使用方法和常用的模块,如果想要进一步学习,可以参考torchaudio官方文档。