
世界模型解决了什么,以及为什么是现在
世界模型解决了什么问题?
1. 样本复杂度
📖 背景知识:强化学习(Reinforcement Learning, RL) 强化学习是一种让智能体(Agent)通过与环境交互来学习的框架。智能体在每个时间步选择一个动作(action),环境返回一个新的观测(observation)和一个奖励信号(reward),数值越高表示结果越好。智能体的目标是学会一套策略(policy):在每种状态下应该执行哪个动作,以最大化长期累计奖励。
无模型 RL(model-free RL):智能体直接从与环境的反复试错中学习策略,不建立对"世界如何运作"的任何内部模型。优点是简单,但缺点是需要极其大量的真实交互("样本")才能学会。
基于模型的 RL(model-based RL):先学习一个世界模型(预测动作的后果),再用这个模型在"想象"中模拟大量轨迹,减少与真实环境的交互次数。
无模型的强化学习需要数百万次真实交互才能学会一个简单任务。世界模型让 Agent 可以在内部模拟中"虚拟经历"数以万计的轨迹(rollout,一条从初始状态出发、按策略执行动作的完整序列),把真实环境交互降低几个数量级。
2. 规划能力 有了世界模型,Agent 可以在行动之前先在头脑里把几条路都走一遍,选预期回报最高的那条,而不是到真实环境里盲目撞墙。
3. 安全性 在机器人、自动驾驶、工业控制这些场景里,试错的代价可能是灾难性的。世界模型让"在沙箱里把策略压垮再修好"成为可能,而不是拿真实系统当实验台。
中间的沉寂:世界模型为什么冷了
2018 到 2020 年的初期热潮过后,世界模型方向逐渐降温。Dreamer、RSSM、PlaNet 带来了真实的学术关注,但持续研究中暴露出一批顽固的问题:预测质量随时间迅速退化,长时域轨迹崩坏,误差逐步累积,生成的视频帧在短短几步后就糊成一片。这些不只是工程缺陷,它们指向一个更根本的能力空缺。
与此同时,更大的浪潮正在别处涌起。Scaling Law 的成功让许多研究者相信:数据够大、模型够大,端到端直接解决问题就行了。VLM 和 VLA 的能力爆炸性增长。世界模型反而像是一个被时代甩在身后的旧想法。
事后来看,问题从来不是想法本身有误。问题是让它运转所需的生成能力当时根本不存在。世界模型需要稳定地逐步生成连贯的未来,不能漂移,不能崩坏。早期的视频预测架构做不到这一点,几帧之后输出就模糊成噪声。
改变这个局面的,是扩散模型和视频基础模型。AI 系统第一次具备了连续生成时间上连贯的世界状态的能力。这才是世界模型复活的根本原因:不是新的理论突破,而是一种新获得的生成能力,让旧想法突然变得可行。
这个逻辑的推论值得单独说出来:扩散模型最重要的意义,可能根本不是生成图像。它可能是让 AI 第一次真正具备了对世界如何演化进行建模的能力。现实世界本身就是一个连续演化的过程,视频不过是对这个过程在时间上的采样。
为什么世界模型现在重新变热?
世界模型不是新概念。Ha & Schmidhuber 的论文[2] 发表于 2018 年,更早的基于模型的强化学习(MBRL)在 2000 年代就一直在学习环境动力学。Dreamer 也已经迭代到了第三版。那么,为什么 2024–2026 年间,这个领域突然又成了每个 AI 会议的主角?
答案不是某一篇论文,而是三条技术线在同一时间窗口内交汇,形成了一股共振。
第一条线:视频生成模型突然变强
Veo(Google DeepMind)、Genie(Google DeepMind)、Cosmos(NVIDIA),这一批视频生成模型在 2024 年集中涌现,展示了大规模视频预训练的惊人能力。
它们让研究者开始认真思考一个问题:这些模型在生成逼真视频的过程中,是不是顺带学到了某种空间结构感、物体持久性和粗粒度物理规律?如果是,那它们是不是可以作为机器人或 agent 的底层世界模型来使用?
这个问题至今没有确定的答案,但正是它把视频生成领域和机器人控制领域拉到了同一张讨论桌前。
第二条线:具身智能遇到数据瓶颈
视觉语言动作模型(VLA,Vision-Language-Action model,以视觉观测和语言指令为输入、直接输出机器人动作的端到端模型,如 RT-2、OpenVLA)已经展示了通用机器人技能的可能性,但它们有一个致命的依赖:大量 teleoperation 示范数据。
📖 Teleoperation(遥操作):操作员通过手柄、数据手套或外骨骼实时控制机器人,机器人同步记录观测和对应的关节动作。所得数据格式规整、标注完整,但采集代价极高,需要专业硬件、熟练操作员和大量时间,每小时数据的采集成本可能高达数千美元。
收集一条机器人操作数据,需要专业的硬件设备、熟练的操作员、真实的物理场景。相比之下,互联网上有数十亿条人类操作视频,但这些视频没有动作标注,没有关节角度,没有力矩信号。
世界模型提供了一条绕路的思路:如果 WM 能从无动作标注的视频里学到"人是怎么与物体交互的",再用 latent action(从视频帧差异中自动提取的隐式动作编码,不对应具体的关节角度,而是捕捉"相邻帧之间发生了什么类型的变化",详见 L03 Genie 一节)把这种理解转化成可控的动力学模型,机器人就能从互联网视频里"间接学习",不需要每个动作都有人亲手标注。
这不是已经解决的问题,但它的诱惑足够大,几乎所有顶级机器人团队都在这条路上押注。
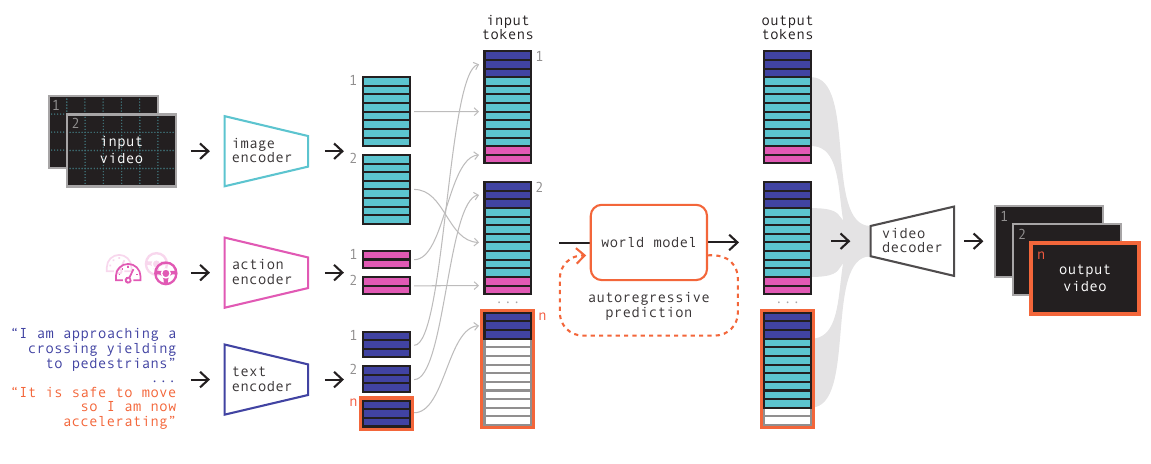
第三条线:自动驾驶已经证明"反事实仿真"有巨大价值
自动驾驶是世界模型最早落地的工业场景之一,而且它已经给出了清晰的商业验证。
真实道路上的 corner case(边缘情况,指在正常训练数据中极少出现但系统必须处理正确的罕见场景)极其稀少:暴雪中的行人突然冲出,大货车在十字路口侧翻,轮椅用户违规穿行……这些场景每隔数百万公里才可能遇到一次,但它们恰恰是自动驾驶最容易出错的地方。
世界模型的解决方案是:
Wayve(英国自动驾驶公司)的 GAIA-1、Tesla 的世界模型仿真、Waabi(加拿大自动驾驶初创公司)的反事实训练,这些工业级部署已经证明,WM 驱动的数据增强可以把安全关键测试的覆盖率提高几个数量级,而成本只是真实道路测试的千分之一。
三线交汇
把三条线放在一起看,今天世界模型热潮的本质就清晰了:
这不是单篇论文带来的热点,而是三个独立赛道——大规模视频生成、机器人学习、自动驾驶仿真——在 2024–2026 年间同时发现世界模型是各自问题的关键拼图。视频生成模型提供了可复用的物理先验,具身智能暴露了动作标注的数据瓶颈,自动驾驶验证了在仿真里做反事实测试的商业价值。三股力量汇聚,把这个领域推向了中心舞台。
上一次世界模型热(2018–2020)是学术界主导的,研究者在游戏环境里证明了可行性,但落地场景还很遥远。这一次(2024+)工业界和学术界同时入场,因为它已经触碰到了真实的成本瓶颈和安全需求。两次热潮的温度完全不同。
下一讲
知道了"为什么需要世界模型",下一个问题是"怎么建"。L02 从两个最基础的工程问题出发:如何把高维像素压缩成可操作的潜在向量(VAE 编码器),以及如何在这个低维空间里预测未来状态(GRU → MDN-RNN → RSSM)。这两件事做好了,就有了 Dreamer 的核心骨架。