
争论一二:语言是鸦片,以及 Bitter Lesson
两种智能基底的分叉
站在 2024 年回望,AI 领域出现了一条清晰的分叉。
语言派认为,智能的核心是符号推理和语言理解。LLM 是通向 AGI(Artificial General Intelligence,通用人工智能,指在所有认知任务上达到或超越人类水平的 AI 系统,与只能完成特定任务的"窄 AI"相对)的正确路径,Scaling Law(缩放定律,指模型性能随参数量、数据量、计算量的增加而可预测地提升的经验规律,Kaplan et al. 2020 首次系统研究)就是答案。GPT-4、Claude、Gemini 的成功不断印证这条路的有效性。整个硅谷,从 OpenAI 到 Google,从 Anthropic 到 Meta 的大部分资源,都在这条路上加速。
世界模型派认为,智能的核心是对物理世界的预测和因果理解。语言是高度压缩的人类知识产物,是交流工具,不是思考工具。真正的智能体必须能够在物理世界中行动、预测、规划,而这正是 LLM 的盲区。谢赛宁(Saining Xie,纽约大学计算机视觉研究者,AMI Labs 联合创始人兼 CSO,曾在 Meta AI Research 主导 ResNeXt、ConvNeXt 等工作,现专注于从物理世界感知出发的具身智能研究)、Yann LeCun、以及来自机器人和强化学习社区的研究者,正在这条路上逆流而上。
这场争论的核心张力,可以用一句话点出:
语言模型预测下一个 token。世界模型预测下一个状态。
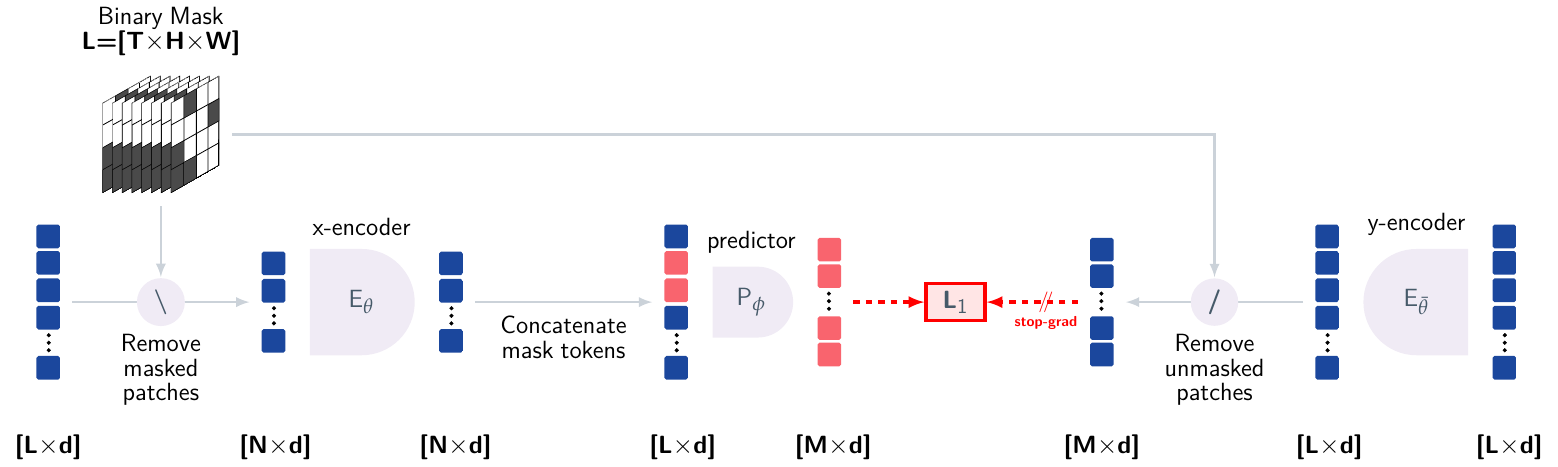
听起来只换了一个词。但这背后是两种完全不同的智能观,关于什么是"理解",关于 AI 的终点在哪里。
争论一:语言是工具,还是"鸦片"?
谢赛宁的核心论点
谢赛宁有一段话,是这场争论里最有张力的表达之一:
"语言其实是一个'毒药',或者说是一剂'鸦片',你加多了语言总是会觉得更幸福的,它有用,但它是一个捷径。如果你一直吸鸦片就废了;如果你一直拄着拐杖,你就没办法训练大腿的肌肉。"
这个类比的逻辑需要展开来理解。
语言是人类几千年文明演化的产物,是高度压缩的抽象知识结构。当你说"杯子掉在地上碎了",你已经丢掉了所有的物理过程:重力加速度、碰撞时的应力分布、碎片飞溅的轨迹、材料的脆性系数。这些物理信息,一个字都没有。
对于一个需要在物理世界中行动的智能体来说,这些丢失的信息恰恰是最关键的。工业机械臂需要知道力矩,手术机器人需要知道组织形变,自动驾驶需要知道路面摩擦系数,这些东西,语言一概表达不了。
谢赛宁把 AI 系统的学习空间分成两层:
- X 空间:物理世界本身,连续的、高维的、带噪声的传感器信号
- Y 空间:监督信息,人类打的标签、写的文字、标注的类别
他的核心指控是:LLM 永远停留在 Y 空间。它学的是人类如何描述世界,而不是世界本身。这不是方法论的问题,而是数据模态的根本局限。
他还有一个更直接的说法:语言会污染视觉。视觉系统处理的是连续、高维、充满噪声的物理信号,而语言是离散的、符号化的。当你强迫一个视觉模型用语言来表达它的"理解",你已经把它的表征空间压进了一个不合适的容器里。
📖 表征学习(representation learning):让模型从原始数据中自动学习出一套内部表达,而不是手工设计特征。世界模型的核心目标之一,就是学到一个能够支持预测和规划的物理世界表征,这个表征应该存在于 X 空间,而非 Y 空间。
反驳:语言派的最强论证
语言派不会沉默地接受这个批评。他们有几个强有力的反驳。
第一,GPT-4 能做物理推理,这不是"描述",这是"理解"。 你让 GPT-4 解释为什么一根棍子浸入水中看起来弯了,它能给出折射率的解释。你让它预测一个物体的受力,它能用牛顿定律推导。如果这不叫理解物理,什么叫理解物理?
第二,人类也是用语言思考的。 "杯子掉地上碎了"这句话之所以有意义,是因为说话的人背后有物理直觉,而这种直觉正是通过无数次经验建立的。语言和物理理解不是对立的,它们是共生的。人类用语言传递知识,用语言推理,用语言规划。如果语言对人类不是"废",凭什么对 AI 就是"废"?
第三,Scaling Law 在物理理解上也持续有效。 在 BIG-Bench Physical Intuition(Beyond the Imitation Game Benchmark 中的物理直觉子集,一套评估语言模型对日常物理场景推理能力的基准,包含物体运动、重力、碰撞等场景的问答题)等物理推理基准上,更大的模型表现更好。趋势没有停止的迹象。如果语言是"拐杖",为什么越用越强?
留给你(争论一)
你认为 LLM 真的"理解"物理世界,还是只是在做高级的模式匹配?这两者之间有没有本质区别,或者说,这个区别本身是否重要?
如果一个系统在所有物理推理测试上都表现得跟真正"理解"无异,我们还有理由坚持说它"只是在匹配模式"吗?
争论二:Bitter Lesson 到底说了什么?
Sutton 的原版论证
2019 年,Richard Sutton 发表了一篇短文《The Bitter Lesson》。全文不长,但引发了 AI 领域最持久的争论之一。
核心论点:
人类自以为聪明的领域知识,经常被"更简单、更通用、依赖大规模计算的算法"超越。
他列举了历史证据。国际象棋:深蓝用了大量国际象棋专家知识。AlphaZero 扔掉了所有这些,只靠自对弈和神经网络,反而打败了深蓝的后代。围棋:人类花了几十年研究棋形、手筋、定式,AlphaGo 用监督学习加强化学习,一举超越所有人类。语音识别:语言学家花了几十年研究音素、共振峰、声学模型,最终被端到端的神经网络取代。图像分类:手工设计的特征(SIFT、HOG)被 AlexNet 的端到端学习干掉。
Sutton 的结论:这是个"苦涩的教训"。研究者一遍又一遍地犯同样的错误,把人类知识硬编码进系统,然后被"更简单、更通用"的方法超越。正确的方向是:减少人类干预,让计算和学习做事。
谢赛宁的反论
这里是最有意思的地方。谢赛宁并不反对 Bitter Lesson,他反对的是用 Bitter Lesson 来为 LLM 背书:
"LLM 完全不够 Bitter Lesson,某种程度上,LLM 是反 Bitter Lesson 的。"
逻辑是这样的:Bitter Lesson 说的是减少人类手工设计的特征和规则,多用搜索和学习。但语言本身就是人类极其聪明的产物。
当你用 Common Crawl(一个持续抓取互联网网页的公开数据集,包含数十亿个网页的文本内容,是训练 GPT、LLaMA 等大型语言模型的主要原始数据来源之一)训练一个 LLM,你在喂给它的不是"原始世界数据",而是人类几千年智慧的语言化压缩:哲学、科学、历史、文学、法律、对话。这是一种极度隐蔽的 inductive bias(归纳偏置)。
📖 归纳偏置(inductive bias):机器学习模型在训练数据之外做泛化时,必须依赖某些"预设假设"来缩小假设空间,这些预设就是归纳偏置。例如,CNN 的归纳偏置是"局部特征比全局特征更重要,且特征可平移"。LLM 用语言数据训练,其归纳偏置是"世界可以用人类语言充分描述",谢赛宁的批评正是指向这个假设。
你不是在"让模型自己发现规律",你是在说:"聪明人类总结出来的规律都在这里,你吸收吧。"
这和 AlphaZero 扔掉国际象棋专家知识正好相反。AlphaZero 是真的在"自己发现"围棋规律,从 X 空间出发。LLM 是在"吸收"人类已经发现的所有规律,从 Y 空间出发。
延伸推论:语言模型的 Scaling Law 里可能有"水分",它不需要真正理解世界就能回答问题,就像一个考试高手,可能只是记忆力很强,而不是真的懂。世界模型的 Scaling Law 会不一样,它面对的是物理信号,没有人类替你预先消化,你必须真正"理解"。
📖 分布外(OOD,Out-of-Distribution):模型在训练时只见过某种数据分布,当测试时遇到训练分布之外的情况,模型的预测可靠性会急剧下降。这是衡量模型真正"理解"还是"记忆"的核心测试,也是世界模型派认为 LLM Scaling 存在水分的重要依据。
反驳:为什么"吸收人类知识"不等于反 Bitter Lesson
Bitter Lesson 反对的是手工设计特征和规则,不是反对使用人类积累的数据。语言数据不是"规则",而是"例子",学习人类语言里的知识,和学习棋谱库里的棋局,在方法论上没有本质区别。AlphaZero 难道没有用到人类发明的围棋规则作为环境?那也算"人类知识"。
从这个角度看,LLM 恰恰是 Bitter Lesson 精神的最彻底实践:扔掉手工特征,把所有东西变成端到端学习。只不过这次的"端"是语言,而不是像素。
留给你(争论二)
Bitter Lesson 的精神是"相信计算和学习,不相信人工规则"。LLM 是遵循了还是违背了这个精神?
更尖锐的版本:如果有一天,一个世界模型被另一个"更简单、更通用"的方法超越,就像深蓝被 AlphaZero 超越,你会说那是世界模型的 Bitter Lesson 时刻吗?或者说,Bitter Lesson 本身,会不会也有自己的 Bitter Lesson?