思想基石
第一块基石:Craik 的微型模型(1943)
英国心理学家 Kenneth Craik 在二战期间写下了一本薄薄的书《The Nature of Explanation》[1]。他提出了一个超前于时代的想法:
"如果有机体在颅骨内携带了一个外部现实的'小尺度模型',它就能在应对紧急情况之前预先试验各种可能性。"
Craik 认为,大脑不是被动接收刺激、被动输出反应的黑盒,而是主动维护一个内部模拟器。这个模拟器可以"快进"未来、"回放"过去,让生物在真实代价发生之前就筛选出最佳行动。
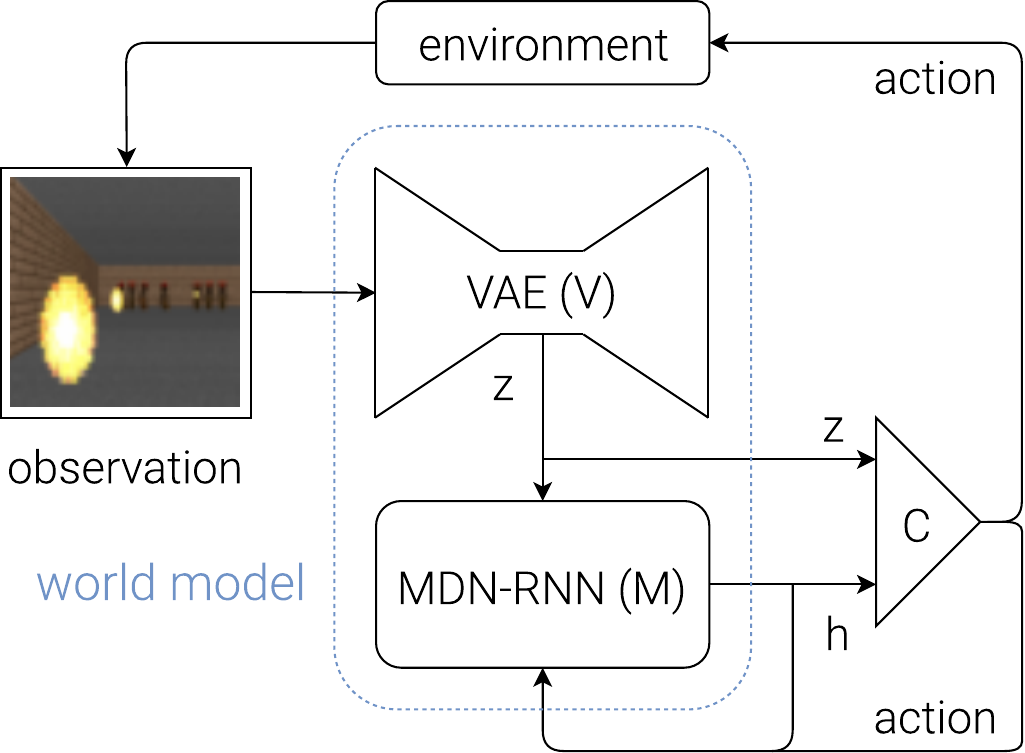
感知输入内部模型,内部模型生成预测并引导决策,预测误差反过来修正模型。
遗憾的是,Craik 在 1945 年的一次自行车事故中去世,年仅 31 岁。他的思想沉寂了数十年,直到认知科学和神经科学的兴起,才重新被人们发现。
大脑的预言机制:预测编码(1990s)
1990 年代,神经科学家开始用**预测编码**(Predictive Coding)来解释大脑的工作方式。
核心思路出人意料地简单:
大脑不是在"看"世界,而是在预测世界,然后只处理"预测错了的部分"。
视觉皮层并不是老老实实地把每一个像素从眼睛传到大脑,那太耗能了。相反,大脑高层持续向低层"下发预测",低层只需要把预测与实际感官信号的误差往上传。
如果你走进一个熟悉的房间,大脑几乎不需要处理任何信息,因为一切都在预期之内。但如果椅子换了个位置,那个"错位"的信号会立刻被放大、引起注意。
这个机制解释了为什么我们对变化如此敏感,对熟悉的背景又如此健忘,预测准确的部分被压缩掉了,只有误差才值得关注。
控制理论的洞见:内模原理(1960s)
几乎同一时期,控制工程领域也独立发现了类似的思想。1960 年代,内模原理(Internal Model Principle)被正式提出:
要实现对某个系统的完美控制,控制器内部必须包含该系统的一个模型。
这听起来像是工程术语,但直觉极其清晰:自动驾驶汽车要在弯道上保持车道,它的控制算法必须"知道"车辆在弯道上的动力学行为,不是靠反应,而是靠预判。
这条原理在机器人、航天器、经济模型中无处不在,也成为后来强化学习中"基于模型的方法"的理论根基。想控制某件事,先得理解它,内模原理把这句常识变成了数学上的必要条件。
一个容易混淆的问题:广义 vs 狭义世界模型
在真正进入历史叙事之前,有一个概念边界必须先说清楚,因为后面的每一个例子都会涉及它:"世界模型"这个词,在不同语境下指的不是同一件事。
广义世界模型:只要能预测,就能叫
广义地说,任何能预测"接下来会发生什么"的模型,都可以被称为世界模型。
- 语言模型预测下一个 token(语言模型处理文本的基本单元,可以是一个词、一个字或一个子词片段),属于广义世界模型
- 视频生成模型预测下一帧,属于广义世界模型
- 天气预报模型预测明天气温,属于广义世界模型
按照这个定义,Veo、Genie、Cosmos 都可以放进"世界模型"这把大伞下。它们确实在某种意义上学到了世界的统计规律:光影如何变化,物体如何运动,场景如何演进。
狭义世界模型:必须是 action-conditioned
但在机器人学和强化学习(Reinforcement Learning, RL)的语境里,"世界模型"有更严格的含义:它必须以动作为条件。
不只是"下一帧长什么样",而是"我做了这个动作之后,世界会怎么变"。用公式表达:
📖 下标约定:公式中的下标
t表示时间步(time step),是一个离散的计数器:t=0是第一步,t=1是第二步,以此类推。读作"时刻 t 的观测"(observation), 读作"时刻 t 的动作"(action), 读作"下一时刻的观测"。这套下标记法贯穿整个课程:凡是带 t下标的变量,都指该时间步的值;带t+1的,指下一步的值。
这里 a_t 是智能体在时刻 t 执行的动作。这一个条件的存在,让世界模型从"旁观者"变成了"参与者",它不仅能告诉你世界会怎样,还能告诉你你的选择会带来什么后果。
广义世界模型是个预言家,告诉你"未来会发生什么";狭义世界模型是个顾问,告诉你"如果你这么做,未来会发生什么"。机器人需要顾问,不只是预言家。
三个实用分类问题
面对一个具体的模型,可以用三个问题快速判断它属于哪种世界模型:
| 分类维度 | 选项 | 代表系统 |
|---|---|---|
| 预测什么? | 像素 / 原始帧 | 视频扩散模型 |
| latent 向量(网络内部低维压缩表示) | Dreamer(一种在潜在空间训练策略的强化学习系统,详见 L02–L03)、RSSM(Dreamer 的动力学核心,详见 L02) | |
| 结构化状态(不含像素,只保留决策所需信息) | MuZero、TD-MPC | |
| 动作本身(从视频自动推断的 latent action) | Genie | |
| 是否接受动作? | 不接受 → 被动视频预测 | Veo |
| 接受给定动作 → 可控仿真 | Dreamer、世界模型机器人 | |
| 自己学动作 → latent action | Genie | |
| 服务什么目的? | 生成内容(视频、图像) | Veo |
| 评估策略 / 反事实仿真 | 自动驾驶测试 | |
| 在梦境中训练 policy | Dreamer、Ha&Schmidhuber | |
| 理解物理、迁移知识 | JEPA、基础世界模型 |
这门课程聚焦的是狭义世界模型,action-conditioned、可以用于规划和 policy 学习的动力学模型。