5.1 预处理(强调模态差异)
开场问题
这一节回答的是:原始医学影像为什么不能直接丢进模型,以及不同模态为什么必须走不同的预处理路线。
读者在真正开始做项目时,通常会先遇到三个痛点:
- 同样是 CT,不同医院导出的 spacing、方向、层厚并不一致;
- 同样是 MRI,同一种组织在不同设备上亮度可能差很多;
- 训练能跑通,但模型学到的可能是扫描协议差异,而不是病灶本身。
所以,预处理不是“把图像弄干净”这么简单,而是把原始数据整理成可比较、可学习、可复现的输入。
直觉解释
可以先把预处理理解成两句话:
- 先把数据摆到同一把尺子上。
- 再把和任务无关的波动压下去。
如果不先统一“尺子”,模型看到的差异里会混进很多无关因素:
- 有的是体素大小不同;
- 有的是扫描方向不同;
- 有的是强度范围根本没有可比性;
- 还有的是伪影、偏场或噪声把真正的病灶特征盖住了。
因此,预处理的核心目标不是让图像更“好看”,而是让后面的分割、分类、检测模型更容易学到真正稳定的医学信号。
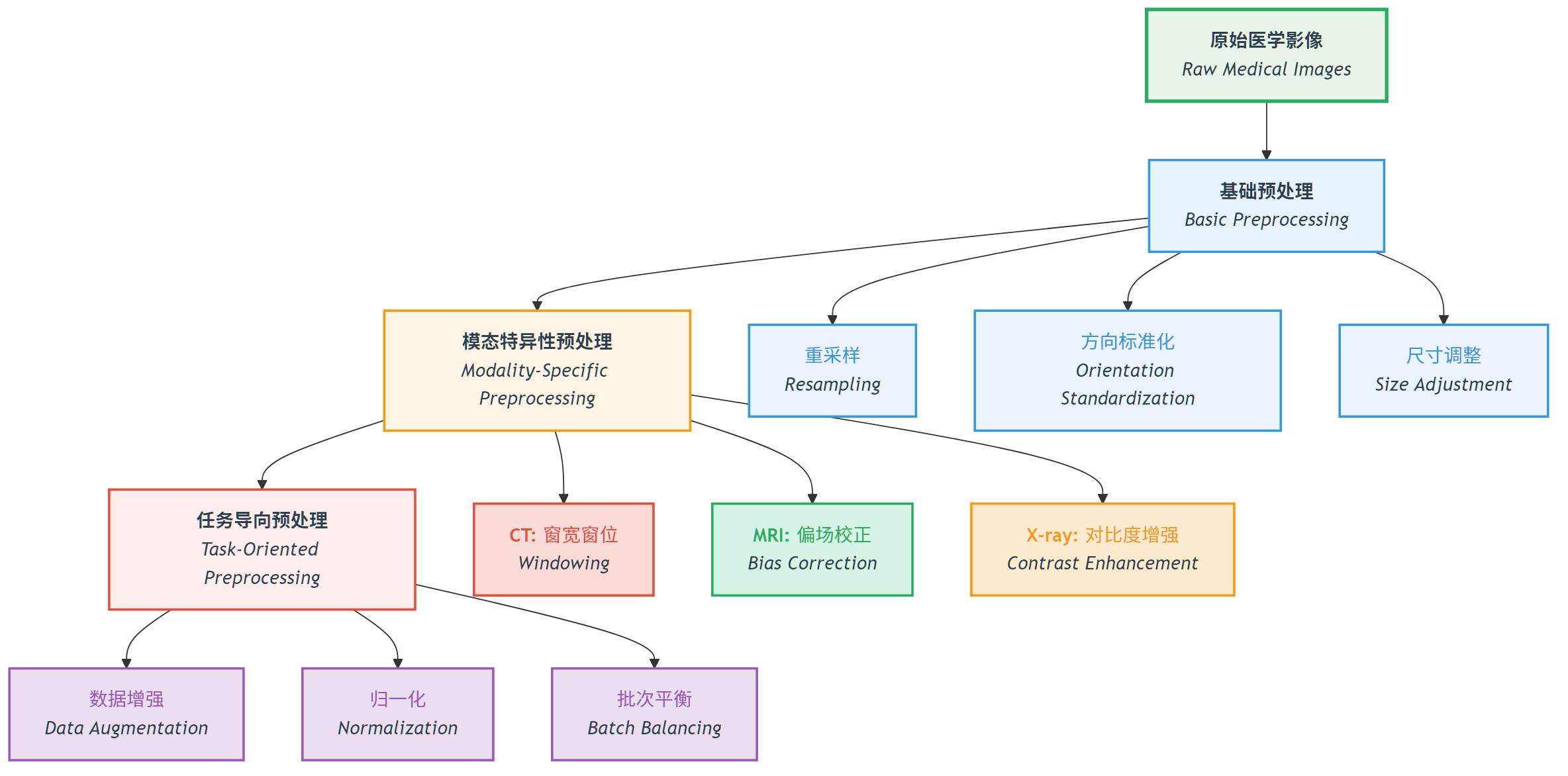 图:预处理通常先统一空间,再做模态特异性的强度处理,最后才连接到具体任务。
图:预处理通常先统一空间,再做模态特异性的强度处理,最后才连接到具体任务。
核心方法
这一节只抓住 4 个最关键的动作。
1. 统一空间
不同扫描的 spacing、方向、尺寸可能完全不同。常见处理包括:
- 重采样到统一体素间距;
- 统一方向;
- 按任务裁剪 ROI 或补零到固定大小。
2. 统一强度
不同模态的强度规则不同,不能用一套方法硬套所有图像:
- CT 更关注 HU 的物理意义,常做截断、窗化、归一化;
- MRI 没有统一绝对强度,常做偏场校正与标准化;
- X 光 常依赖局部对比度与动态范围调整。
3. 去掉明显干扰
噪声、偏场、金属伪影或局部退化会让模型学习方向跑偏。预处理常做的不是“彻底修复”,而是先把最强的干扰因素降下来。
4. 让训练和部署规则一致
很多项目失败,不是模型结构有问题,而是训练时和推理时采用了两套预处理。真正可靠的做法是:
- 把预处理参数写进脚本;
- 保存处理前后的关键元数据;
- 保证训练、验证、部署使用同一套规则。
典型案例
场景 1:CT 肺结节或器官分析
- 痛点:原始 HU 范围太大,空气、软组织、骨和金属混在一起。
- 做法:HU 截断 → 窗化或归一化 → 重采样到统一 spacing。
- 本地源码:
src/ch05/clip_hu_values/main.pysrc/ch05/medical_image_resampling/main.pysrc/ch05/detect_metal_artifacts/main.py
场景 2:MRI 脑影像建模
- 痛点:同一组织在图像不同位置亮度都可能不一样,跨设备差异更明显。
- 做法:偏场校正 → 强度标准化 → 统一尺寸与分辨率。
- 本地源码:
src/ch05/n4itk_bias_correction/main.pysrc/ch05/white_stripe_normalization/main.pysrc/ch05/visualize_bias_field/main.py
场景 3:多中心数据联合训练
- 痛点:模型会把“来自哪家医院”误当成疾病线索。
- 做法:固定空间规则、固定强度规则,并保存处理日志,保证训练与推理一致。
实践提示
正文只保留帮助建立直觉的关键片段;完整实现请查看 src/ch05/。
1. CT:先把极端 HU 裁回任务区间
python
import numpy as np
def clip_hu(image, hu_min=-1000, hu_max=1000):
image = np.asarray(image, dtype=np.float32)
return np.clip(image, hu_min, hu_max)2. 重采样:先算缩放比例
python
import numpy as np
def scale_factors(original_spacing, target_spacing):
original_spacing = np.array(original_spacing, dtype=np.float32)
target_spacing = np.array(target_spacing, dtype=np.float32)
return original_spacing / target_spacing3. MRI:用白质带做标准化
python
import numpy as np
def normalize_with_white_stripe(image, wm_mask):
wm_values = image[wm_mask > 0]
mean = wm_values.mean()
std = wm_values.std() + 1e-6
return (image - mean) / std4. 实操时优先记录这些信息
- 原始与目标 spacing;
- 强度处理区间或标准化参数;
- 是否对 mask 做了同步变换;
- 训练和部署是否共用同一套配置。
延伸实践
- 把“空间统一”和“强度统一”分成两个独立函数,便于训练与推理共用。
- 同时保存处理前后的 spacing 与强度范围,方便回溯实验差异。
- 尝试比较不同 CT 窗口:肺窗、软组织窗、骨窗是否能作为多通道输入。
- 比较 MRI 标准化策略:White Stripe、z-score、百分位归一化对下游分割的影响。
- 阅读并运行本地源码:
src/ch05/clip_hu_values/main.pysrc/ch05/medical_image_resampling/main.pysrc/ch05/n4itk_bias_correction/main.pysrc/ch05/white_stripe_normalization/main.pysrc/ch05/detect_metal_artifacts/main.py
完成这些练习后,再进入分割、分类和增强章节,你会更容易看懂“为什么同一个网络在不同数据上表现差异巨大”。
代码实验 / 实践附录
运行命令、环境依赖、完整输出和可运行 demo 已统一迁移到 5.6 代码实验 / 实践附录 与 src/ch05/README.md。