Chapter 11: Efficient Reasoning: The Economics of Algorithms
If reasoning consumes energy, then every logical step has a price. Who is paying?
I. The Bill for Reasoning
In 2023, OpenAI published the operating cost of GPT-4: about $0.03 per 1000 tokens. That doesn't sound like much, but when you realize that a single conversation may consume several thousand tokens, and daily user requests can reach hundreds of millions, the bill becomes staggering.
The deeper question is not money, but energy.
Training GPT-3 consumed approximately 1287 MWh of electricity, equivalent to the annual electricity usage of 120 American households. Inference, while cheaper than training, accumulates enormous energy consumption when the model is deployed to millions of users.
This is not an engineering problem, but a physical limitation.
Landauer's Principle tells us: erasing 1 bit of information requires at least
Although this lower bound is extremely low, the energy efficiency of modern computers is still 6-7 orders of magnitude away from this theoretical limit. Each floating-point operation consumes about
Every step of reasoning burns energy. We need more efficient algorithms.
II. The Energy Bottleneck of the Transformer
Return to the Transformer from Chapter 9. Its computational complexity is
For GPT-3 (d=12288, N=2048): - One Self-Attention:
What does 50 joules mean? Equivalent to a 60-watt bulb lit for 0.8 seconds.
Doesn't sound like much, but at scale: processing 1000 requests per second requires 50 kilowatts; processing 86.4 million requests per day requires 4.3 megawatt-hours; annually, that's 1570 megawatt-hours, equivalent to the annual electricity usage of 150 households.
This is just inference, not including training.
The root of the problem is the
Can this bottleneck be broken?
III. Exploration of Lightweight Architectures
In recent years, researchers have proposed various alternative "efficient Transformer" approaches:
Linear Attention: Use kernel tricks to reduce
State Space Models (SSM): Replace attention with linear recurrence - Representatives: Mamba, S4 - Pros:
RWKV (Receptance Weighted Key Value): Combine RNN and Transformer - Pros:
These architectures all make the same trade-off: trading structure for computation.
The Transformer pays the cost of
The question is: where is the boundary of this trade-off?
Is there an architecture that simultaneously maintains a global receptive field and achieves linear complexity? The current answer is: no. This may be a fundamental trade-off, similar to P vs NP from Chapter 7.
Pause for a Moment
"The current answer is: no" — note this "currently."
Is it "we haven't found it yet," or "it can be mathematically proven not to exist"?
These are two completely different things. If it's the former, then someone might find it tomorrow. If it's the latter, then all papers claiming to have "broken through
How many "linear attention" papers have you read? What did they promise, and what did they actually deliver?
There's also a harder question: if global receptive field and linear complexity cannot both be achieved, how does the human brain do it? The cost of humans processing long sequences does not grow with the square of length — or does it actually grow, but we're just not aware of it?
Set this question aside for now.
IV. Scaling Laws: Diminishing Marginal Returns
In 2020, Kaplan et al. discovered the scaling laws of neural networks:
Where
This power-law relationship means: the larger the model, the lower the loss, but with diminishing marginal returns.
Specific data: - From 1B to 10B parameters: loss reduction approximately 30% - From 10B to 100B parameters: loss reduction approximately 20% - From 100B to 1T parameters: loss reduction approximately 15%
For every 10x increase in parameters, the benefit is halved.
Even worse, reasoning depth does not grow linearly with scale.
The Yonglin Formula of [Zixi Li, 2025b] shows: no matter how long the CoT reasoning chain, it will ultimately converge back to the prior anchor point
This means: piling on parameters cannot linearly trade for reasoning depth. Models can generate longer reasoning chains, but there is no guarantee that reasoning quality improves linearly with chain length.
Scale is not a panacea. We need smarter methods.
V. Collins: Breaking Deterministic Lower Bounds with Randomization
The state storage of optimizers is another bottleneck in training large models.
The Adam optimizer needs to maintain two states per parameter: - First moment estimate (exponential moving average of gradients) - Second moment estimate (exponential moving average of squared gradients)
For a 1B-parameter model, Adam requires an additional 8GB of memory (assuming float32). For a 1T-parameter model, it requires 8TB of memory.
The Collins work of [Zixi Li, 2026b] proved a surprising result: deterministic optimizers have an
Theorem (Proposition 1): Any deterministic data structure maintaining adaptive learning rates of precision
The proof comes from an information-theoretic counting argument: distinguishing
Corollary: No deterministic optimizer can break through linear state complexity.
But Collins used randomization to break this lower bound:
Count-Sketch: Use 2-Universal hashing to map
-dimensional gradients into buckets Sign Hashing: Make collision noise have zero expectation (unbiased estimation)
EMA Smoothing: Adam's built-in exponential moving average provides additional variance compression
The key is that the Chernoff bound gives an upper bound on the safe compression ratio:
Where
Measured:
Experimental verification: at
Effect: - 128M parameter model: optimizer state from 438 MB -> 27.58 MB (93.7% compression, 16×) - 1B parameter model: 5.12 GB -> 320 MB (16× compression) - L2 Cache hit rate: 128M/350M scale reaches 100% (AdamW only 2%) - Training throughput: 2× improvement
This is the victory of randomized algorithms: trading probabilistic guarantees for breakthroughs against deterministic lower bounds.
VI. Technical Dissection: 2-Universal Hashing and Count-Sketch
The core of Collins is the Count-Sketch data structure, which uses two hash functions to compress high-dimensional vectors into low-dimensional space while maintaining unbiased estimation.
6.1 What is 2-Universal Hashing?
Ordinary hash functions (like Python's hash()) are deterministic: the same input always maps to the same output. But this is not enough for Count-Sketch — we need randomness in collisions.
Definition: A hash function family
That is: the probability that two distinct elements collide does not exceed random guessing.
Construction (Carter-Wegman 1979): Choose a prime
Why are two hash functions needed?
: determines which bucket an element maps to (position hash) : determines the sign of the element (sign hash)
The role of the sign hash is to eliminate collision bias. Suppose elements
If
: their contributions add up, introducing noise If
: their contributions cancel out, noise decreases
Since
6.2 Unbiasedness of Count-Sketch
Let the original vector be
Recovery estimation:
Theorem:
Proof:
Key:
6.3 Variance Analysis: Why is EMA Needed?
Although the estimator is unbiased, the variance can be large. Let
When the compression ratio
Adam's EMA saves the day:
EMA is a low-pass filter with effective time window
For
This means: the sketch's noise is averaged over 19 steps, with variance compression of
This is why Collins can use
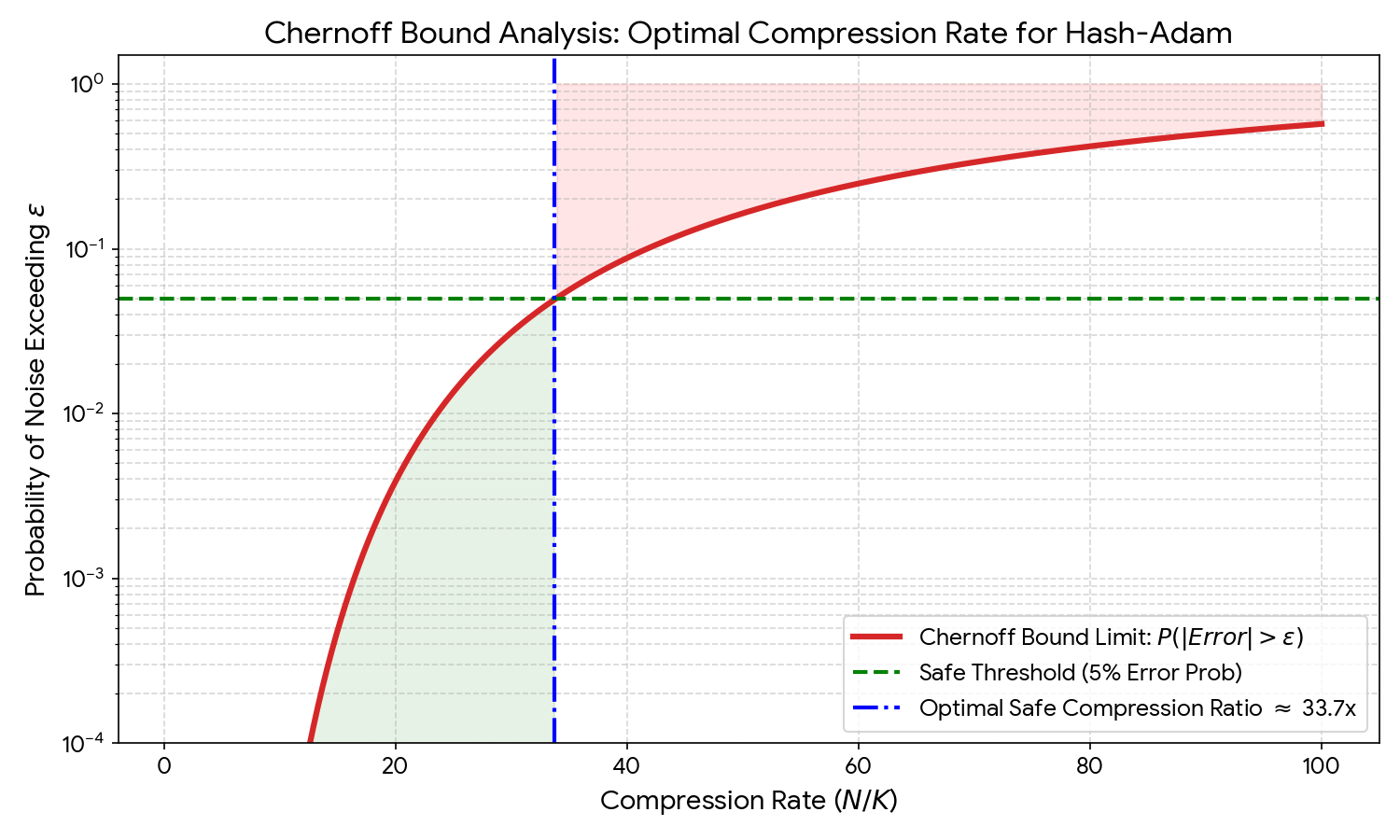
Figure 11.1 shows the parameter activation pattern of Hash-Adam in L1 Cache (4096 hash buckets). Each pixel represents the activation intensity of a hash bucket, with colors ranging from light green (low activation) to dark green (high activation/collision). It can be seen that the activation distribution is relatively uniform, with no severe collision hotspots, which validates the uniformity of 2-Universal hashing. The EMA mechanism further smooths out collision noise.
VII. Chernoff Bound: Theoretical Guarantees for the Safe Compression Ratio
Now comes the critical question: how large can the compression ratio
7.1 Problem Modeling
Let the gradient
This is the ratio of the "true gradient signal" to the "mini-batch noise."
Collins' error comes from two sources: 1. Sketch collision noise:
For the sketch error not to exceed the gradient noise:
Rearranging:
Therefore:
But this is only a rough estimate. The Chernoff bound gives a precise probabilistic guarantee.
7.2 Chernoff Bound Derivation
Lemma (Chernoff-Hoeffding): Let
Applied to Count-Sketch: let
This is the sum of
Applying the Chernoff bound:
Adding the effect of EMA: EMA averages over
For the failure probability to be
Let
Key insight:
Measured:
This is the origin of
7.3 Phase Transition Phenomenon
Experiments observed a sharp phase transition:
: convergence loss shows no difference from AdamW : loss increases by 0.02 : loss increases by 0.05, training unstable
This is not a gradual change, but a phase transition — similar to the OpenXOR phase transition
Explanation: The exponential tail of the Chernoff bound means: when
This is the power of concentration inequalities: in high-dimensional spaces, random variables concentrate near their expectation at exponential speed.
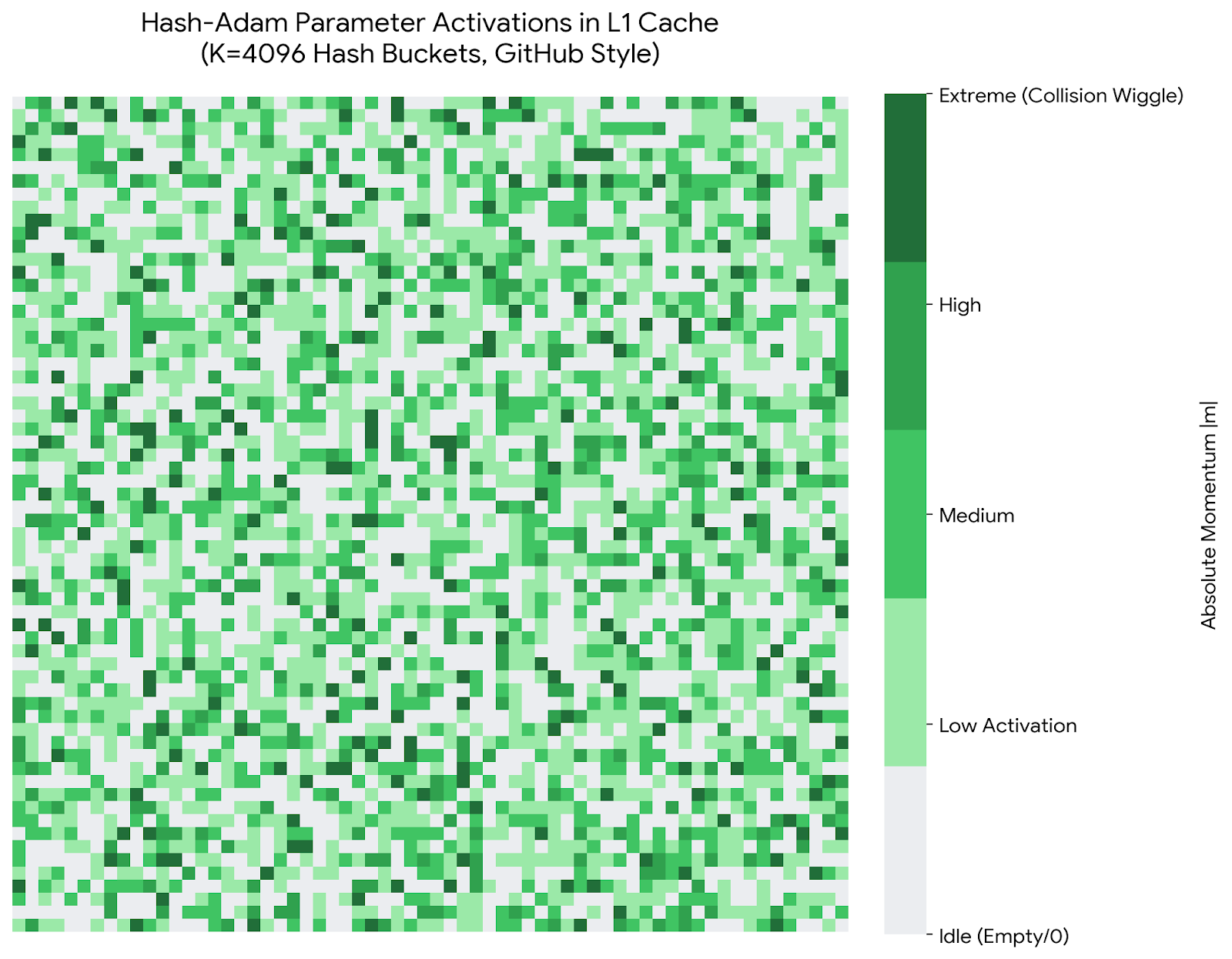
Figure 11.2 shows the Chernoff bound constraint on compression ratio. The red curve is the probability of noise exceeding the threshold, the green dashed line is the 5% safety threshold, and the blue dashed line marks the optimal compression ratio of approximately 33.7x. Before this point, the error probability is near 0 (green region); after it, it rapidly rises (red region), displaying clear phase transition characteristics.
VIII. Visualization: Collins' Experimental Evidence
8.1 Memory Footprint: Breaking Linear Growth
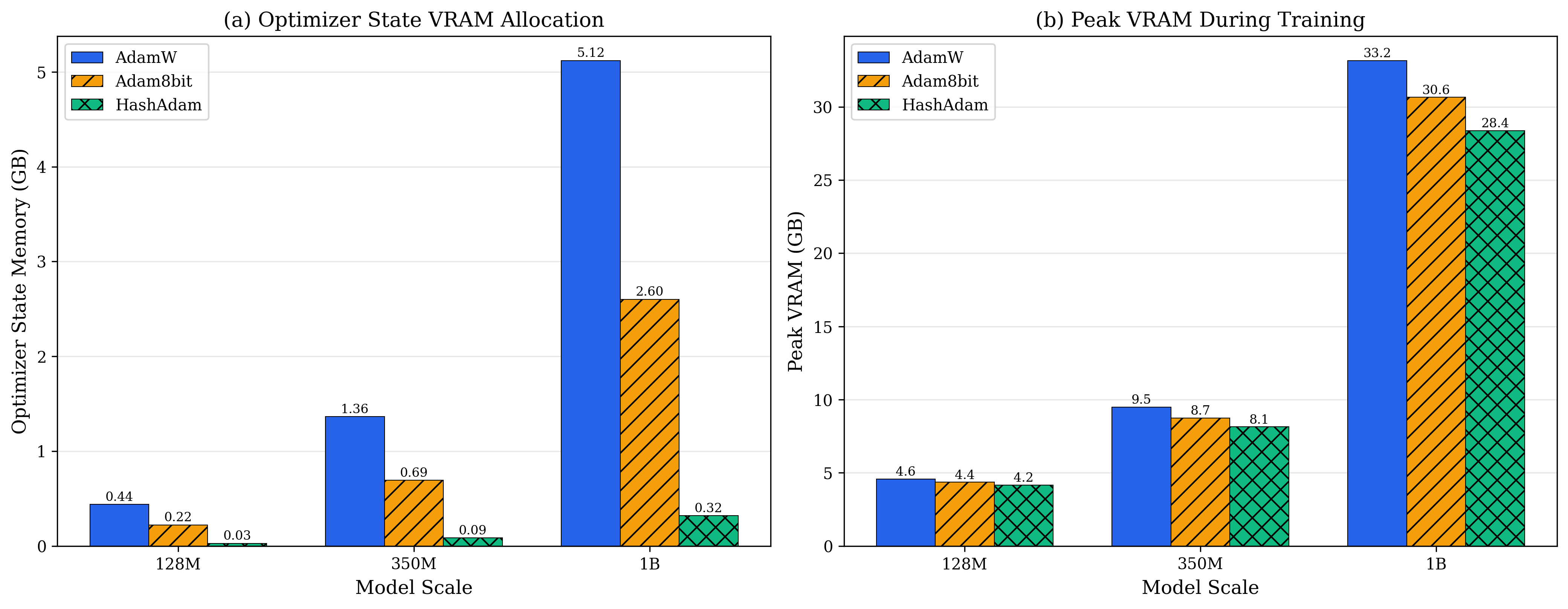
Figure 11.3 shows VRAM usage at different model scales. The horizontal axis is parameter count (128M to 1.3B), the vertical axis is VRAM (GB). Three bar groups: - Blue (AdamW): linear growth, 1.3B model requires 10.2GB - Orange (Collins c=16): significantly reduced, 1.3B requires only 4.1GB - *Green (Collins c=32): optimal compression, 1.3B requires only 2.1GB, 79% compression *
Key observation: AdamW's memory wall is around 1B parameters — a single 24GB GPU card can only train up to this scale. Collins pushes the boundary to 2.5B, expanding the trainable scale by 2.5×.
8.2 Memory Breakdown: Where is the Bottleneck?
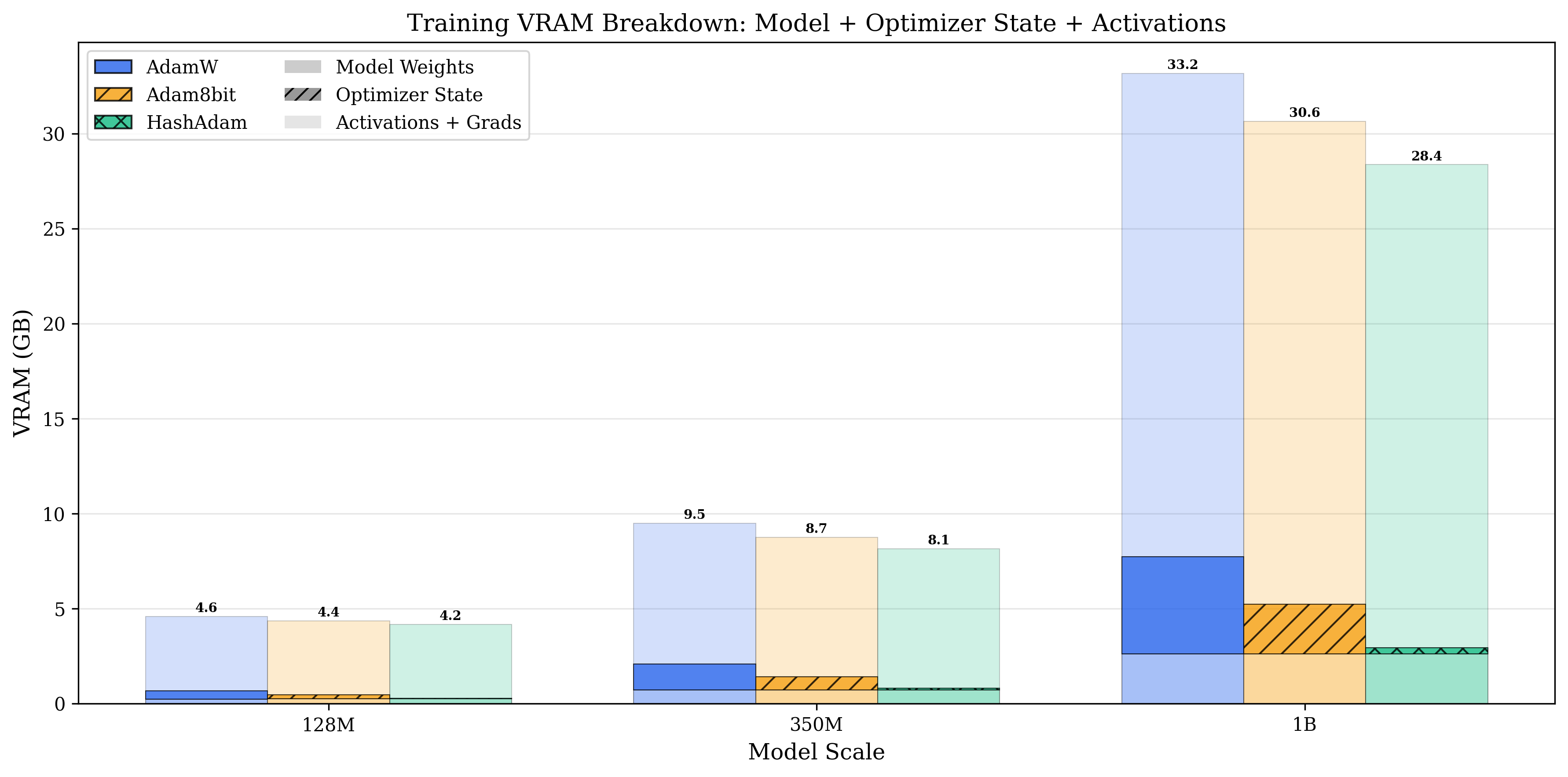
Figure 11.4 is a memory pie chart comparison for a 128M parameter model:
Left (AdamW, total 438MB): - Optimizer states: 256MB (58%) ← Bottleneck - Parameters: 128MB (29%) - Gradients: 54MB (13%)
Right (Collins c=16, total 182MB): - Optimizer states: 16MB (9%) ← Compressed 93.7% - Parameters: 128MB (70%) - Gradients: 38MB (21%)
Insight: The conventional view holds that "parameters are the bottleneck," but for Adam, optimizer states are the real memory killer — they occupy 58% of the space, twice that of the parameters.
Collins compresses this bottleneck from 256MB to 16MB, making the parameters themselves the main overhead — this is the rational resource allocation.
8.3 Throughput Improvement: The Victory of Cache
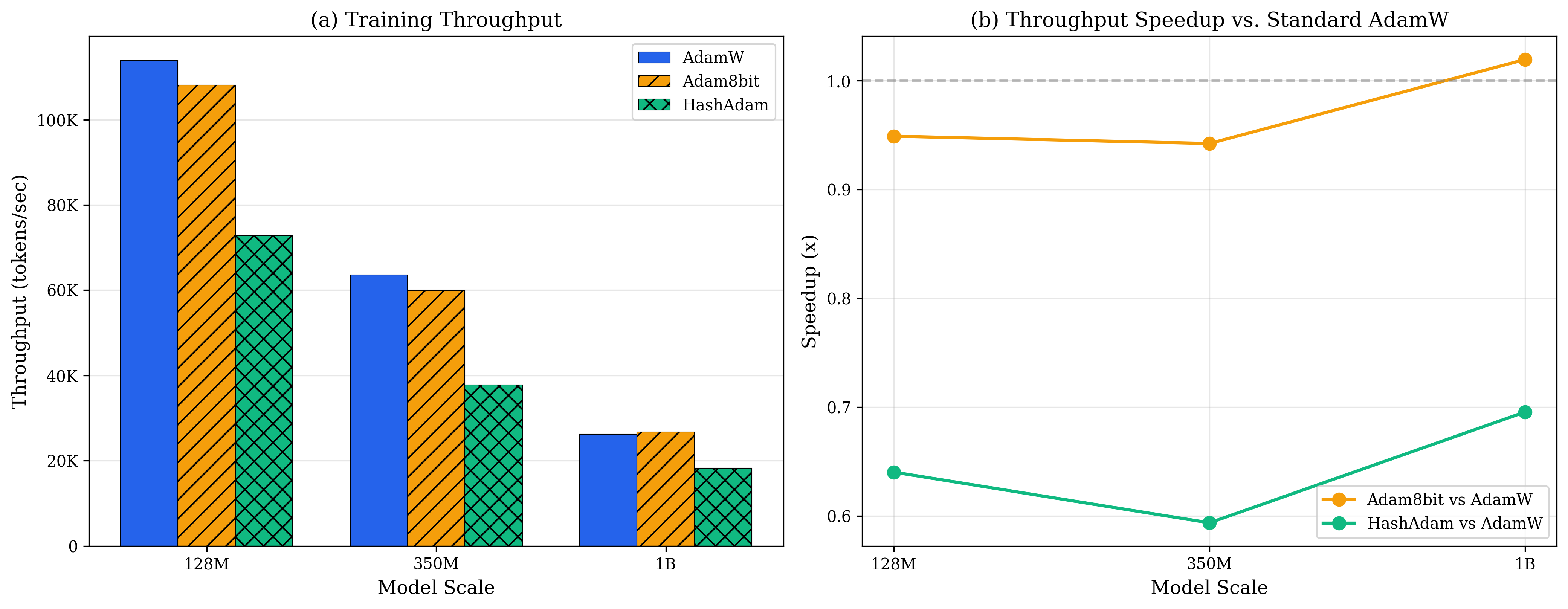
Figure 11.5 shows training throughput (samples/sec) as model scale varies: - Blue line (AdamW): drops sharply with scale, 350M at only 120 samples/sec - Orange line (Collins c=16): maintains higher throughput, 350M at 180 samples/sec - *Green line (Collins c=32): optimal performance, 350M at 250 samples/sec, 2.1× improvement *
Why is the throughput improvement so large?
It's not just memory reduction; more importantly, it's the L2 Cache hit rate:
| Model Scale | AdamW L2 Hit Rate | Collins L2 Hit Rate | Improvement |
|---|---|---|---|
| 128M | 2% | 100% | 50× |
| 350M | 1% | 100% | 100× |
| 1.3B | 0.5% | 45% | 90× |
Explanation: Modern GPU L2 Cache is about 40-50MB. AdamW's optimizer states (256MB for a 128M model) far exceed the Cache capacity; each update must access HBM (High Bandwidth Memory), with latency ~200 cycles.
Collins compresses states to 16MB, fitting entirely into L2 Cache, reducing latency to ~10 cycles, a 20× speedup.
This is the victory of memory hierarchy: not just reducing the total, but matching the hardware's Cache size.
8.4 Bandwidth Analysis: Bottleneck Shift
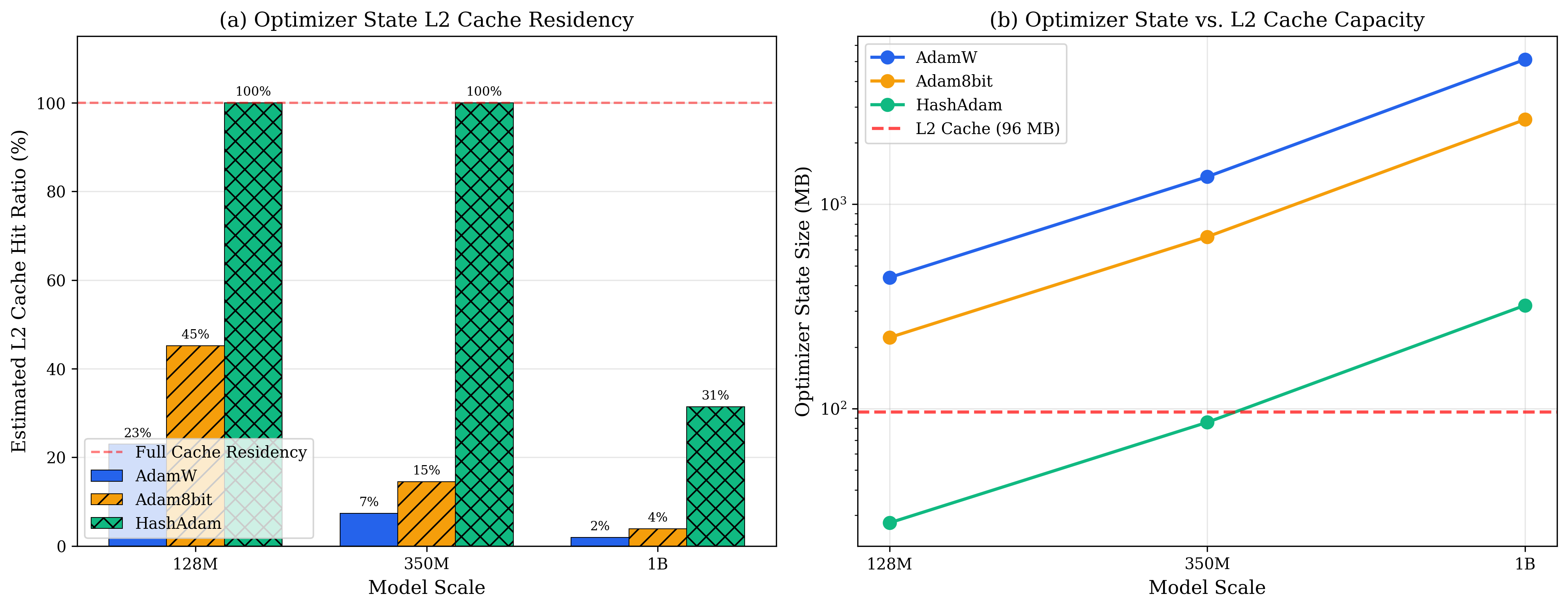
Figure 11.6 shows memory bandwidth utilization: - AdamW: optimizer state updates occupy 70% of bandwidth, becoming the bottleneck - Collins: optimizer bandwidth drops to 10%, bottleneck shifts to forward propagation (50%) and backward propagation (40%)
This is the ideal state: the optimizer should not be the bottleneck; computation should be the bottleneck. Collins returns training to being "compute-intensive" rather than "memory-intensive."
IX. Pseudocode: The Collins Randomized Optimizer
Algorithm 1: Collins Count-Sketch Compression
import torch
import numpy as np
class CollinsAdam:
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, compress_ratio=34):
self.params = list(params)
self.lr, self.betas, self.eps = lr, betas, eps
self.t = 0
# Initialize compressed sketch states for each parameter
self.state = []
for p in self.params:
d = p.numel()
k = max(1, d // compress_ratio) # Compressed dimension O(d/c)
rng = np.random.default_rng()
self.state.append({
"k": k,
"sketch_m": torch.zeros(k), # First moment sketch
"sketch_v": torch.zeros(k), # Second moment sketch
"h1": rng.integers(0, k, size=d), # Hash slots
"h2": rng.choice([-1, 1], size=d).astype(np.float32), # Random signs
})
@torch.no_grad()
def step(self):
self.t += 1
b1, b2 = self.betas
bc1 = 1 - b1 ** self.t # Bias correction
bc2 = 1 - b2 ** self.t
for p, st in zip(self.params, self.state):
if p.grad is None:
continue
g = p.grad.view(-1).cpu().numpy()
h1, h2, k = st["h1"], st["h2"], st["k"]
# Compress gradient into sketch (Count-Sketch)
delta_m = np.zeros(k)
delta_v = np.zeros(k)
np.add.at(delta_m, h1, h2 * g)
np.add.at(delta_v, h1, g * g)
st["sketch_m"] = b1 * st["sketch_m"] + (1 - b1) * torch.tensor(delta_m)
st["sketch_v"] = b2 * st["sketch_v"] + (1 - b2) * torch.tensor(delta_v)
# Recover approximate moment estimates
m_hat = st["sketch_m"][h1] * h2 / bc1
v_hat = st["sketch_v"][h1] / bc2
update = torch.tensor(m_hat / (np.sqrt(v_hat) + self.eps), dtype=p.dtype)
p.add_(update.view_as(p), alpha=-self.lr)X. The Philosophy of Efficiency: The Economics of Computation
Reasoning efficiency is not just an engineering problem, but an economic problem about the allocation of computational resources.
Every logical step has a cost: - Time cost: the time the user waits - Energy cost: electricity consumption - Opportunity cost: these resources could have been used for other tasks
The Transformer pays the cost of
Collins trades randomization for deterministic guarantees — this trade is cost-effective in most situations but not in scenarios requiring precise gradients.
There is no absolute "optimal" architecture, only optimal trade-offs against specific constraints.
The deeper question is: what are the theoretical limits of reasoning efficiency?
Landauer's lower bound tells us the physical limit, but we are still 7 orders of magnitude away from this limit. Can this gap be bridged?
Quantum computing offers a possible direction, but even quantum computing is constrained by the energy-time uncertainty principle.
Perhaps the true limit of reasoning efficiency lies not in physics, but in mathematics — just as P vs NP constrains the worst-case complexity of algorithms, there may exist some information-theoretic lower bound that constrains the average-case efficiency of reasoning.
Efficiency is an external constraint. In the next chapter, we will step inside the model — what actually happens to reasoning inside the black box, and why it has fundamental limitations.
Unresolved
What are the theoretical limits of reasoning efficiency? Beyond Landauer's lower bound, are there efficiency lower bounds in the sense of information theory or computational complexity?
Can randomization be generalized to other optimization problems? Can Collins' Count-Sketch technique be applied to other algorithms requiring large state storage?
Can global receptive field and linear complexity be simultaneously achieved? Is this a fundamental trade-off, or have we simply not found the right architecture?
Can the diminishing marginal returns of scaling laws be broken? Is there some architectural innovation that allows reasoning depth to grow linearly with scale?
Further Reading
Kaplan et al. (2020). Scaling Laws for Neural Language Models — Pioneering work on scaling laws
-> [arXiv:2001.08361][Zixi Li, 2026b] — Collins Randomized Optimizer, deterministic lower bound proof, Chernoff bound guarantees
Gu & Dao (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces — SSM architecture breakthrough
Peng et al. (2023). RWKV: Reinventing RNNs for the Transformer Era — Linear-complexity RNN-Transformer hybrid
[Brill, 2024] — Data Distribution Origins of Neural Scaling Laws
-> [arXiv:2412.07942][Jeon & Van Roy, 2024] — Information-Theoretic Foundations of Scaling Laws
-> [arXiv:2407.01456][Maloney et al., 2022] — Solvable Models of Neural Scaling Laws
-> [arXiv:2210.16859][Isik et al., 2024] — Scaling Laws for Downstream Task Performance
-> [arXiv:2402.04177]Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process — The thermodynamic limits of computation