Chapter 2: The Dawn of Symbols — The First Modeling of Causality
If you could write the world as If-Then, you would own the world. The problem is, you can never finish writing.
I. A Bet
In 1965, Herbert Simon said something that would be quoted for nearly sixty years:
"Within twenty years, machines will be capable of doing any work a human can do."
Simon was a Nobel laureate in economics, one of the founders of cognitive science, an extraordinarily intelligent person. He was not talking nonsense. He had arguments. He saw the most exhilarating thing of his era: a machine, for the first time, beginning to reason like a human.
Not compute. Reason.
The Logic Theorist, written by Newell and Simon in 1956, used a set of axioms and inference rules to automatically prove 36 of the 38 theorems in Chapter 2 of Russell's Principia Mathematica. One of those proofs was more elegant than Russell's own version. At the time, Simon wrote to a friend: "We have invented a thinking machine."
Counting from that moment, for roughly thirty years, the dominant paradigm of artificial intelligence was built on a bet so concise it was almost beautiful:
If you could represent the world's knowledge as symbols, and reasoning rules as logic, then machines could reason.
This chapter's story is about how that bet was placed, where it won, and why it ultimately lost.
II. The Aesthetics of If-Then
Let me first explain what the core of this paradigm is.
A rule-based reasoning system has a very simple structure. You have two parts:
Knowledge Base: A set of If-Then rules describing the regularities of the world. Inference Engine: Given a problem, follows the chain of rules to derive an answer.
Take a classic example — the MYCIN system developed at Stanford University in 1972. MYCIN was designed to diagnose bacterial blood infections. Its knowledge base contained about 600 rules, looking like this:
IF the organism's gram stain = positive
AND the organism's morphology = coccus
AND the organism's growth pattern = clusters
THEN the organism's identity = Staphylococcus aureus (confidence 0.7)
The inference engine takes a specific case, substitutes the known observational facts into the rules, pushes forward step by step, and ultimately gives a diagnosis and recommended medication.
MYCIN's performance was astonishing. In 1979, Stanford conducted a blind test — they gave 10 real cases to MYCIN and 5 medical experts for diagnosis, then asked 8 infectious disease authorities to evaluate the quality of all answers without telling them which was the machine's. The result: MYCIN's performance ranked in the top tier among all participants, surpassing several of the human doctors.
This was 1979.
You can understand why Simon's generation was so optimistic. If you could write an expert's domain knowledge as rules, the machine could become an expert in that domain. And it would not get tired, would not make careless mistakes, would not suffer impaired judgment after working the night shift.
This idea has a kind of pure aesthetics. The world is complex, but behind the complexity are regularities. Regularities can be explicitly expressed. Once expressed, the machine can operate on them.
The problem is that the act of "writing as rules" itself is far harder than it looks.
III. The Knowledge Bottleneck
Expert systems had a problem that gave everyone headaches. They gave it a name: the Knowledge Acquisition Bottleneck.
Knowledge Acquisition Bottleneck: Why is expert knowledge so hard to encode as rules?
The term "knowledge acquisition bottleneck" means: transforming the knowledge in a human expert's mind into rules that a computer can process is itself extraordinarily difficult.
There are two layers of reasons:
- Experts cannot clearly articulate what they are doing: many experiential judgments have been automated to the subconscious level, and the expert themselves cannot explicitly describe them (see "Tacit Knowledge" below).
- Knowledge is context-dependent: the same piece of information means different things in different contexts, but rule systems cannot gracefully handle such dependencies.
This was the most central practical difficulty of the entire expert systems era, and it ultimately led to the decline of this technical approach.
In other words: the task of writing an expert's knowledge into rules is itself an almost impossible mission.
You go to a surgeon with thirty years of experience and ask: "How do you determine whether a patient needs surgery?" He will give you standard answers: look at imaging results, look at blood markers, look at symptom duration. But you write all of these into rules and find that the system performs terribly. Because what he didn't tell you is the intuition accumulated over thirty years: the way the patient frowned while saying something, that indescribable "feeling" when two indicators appear simultaneously, the special pattern of a certain type of patient in a certain season.
These things are real knowledge, the things that make him a top-tier surgeon. But he cannot articulate them. Not because he doesn't want to, but because that knowledge has sedimented into the bottom layer of his cognitive system, and he himself cannot access their explicit form.
Cognitive science calls this kind of knowledge tacit knowledge — you know how to ride a bicycle, but you cannot explain to someone who cannot ride exactly what precise mechanical adjustments you make while cycling.
Tacit Knowledge: The part of knowledge that cannot be spoken
The concept of tacit knowledge comes from philosopher Michael Polanyi, who proposed in 1958 that: "We know more than we can tell."
Typical examples:
- Riding a bicycle — you can do it, but can you precisely describe every adjustment you make at every frame?
- Face recognition — you recognize an old friend at a glance, but can you say which pixel features triggered that recognition?
- Expert judgment — an old Chinese medicine doctor "tells by complexion," an experienced surgeon "senses something is off"
The existence of tacit knowledge explains why expert systems were destined to encounter the problem of "knowledge can never be fully written": the most valuable part of expert experience is precisely the part that the expert themselves cannot explicitly describe.
So knowledge engineers (builders of knowledge bases) had a very hard time. They spent enormous amounts of time interviewing experts, obtained some rules, put them into the system, tested, discovered edge cases not covered, went back to ask again, modified, tested again. This process was slow, expensive, and had no endpoint.
You wrote 1000 rules and discovered you needed another 1000. You wrote 10000 and discovered new cases triggering situations none of the previous 1000 had anticipated.
The world is not closed. Rules can never be fully written.
IV. Logic Gates Are the Simplest Form of Causality
Before continuing the story of expert systems' failure, I want to insert a footnote from physics here.
When we talk about "rule-based reasoning," what we are actually talking about is a very specific physical process.
A logic gate — an AND gate, an OR gate, a NOT gate — what is its function? What it does is: given inputs, produce deterministic outputs. This is the simplest, purest physical implementation of causal relationships.
An AND gate: if A=1 and B=1, then output=1. Otherwise, output=0. This is an If-Then rule, etched onto a silicon chip, executed by the flow of electrons.
All expert systems, all logical reasoning, at their lowest level are such physical implementations. Causal relationships are materialized as circuits: some state causes another state, no exceptions, no probabilities, no ambiguity.
There is something profound here worth pausing to think about.
The computer is not "thinking." What it is doing is: executing a sequence of deterministic causal transformations. Each step, the input determines the output, with no uncertainty whatsoever. The intuition of McCarthy, Minsky, and their generation was: if we can decompose the thinking process into sufficiently many deterministic steps, then the machine can reproduce thinking.
This intuition is correct to some extent. Mathematical proofs can be decomposed into sequences of symbolic operations, and each symbolic operation is deterministic. MYCIN's reasoning process is deterministic — given the same facts, it always gives the same answer. Chess move search is deterministic. A large class of "precisely defined problems" can be handled in this way.
But "thinking" is not merely the set of precisely defined problems.
V. The Closed World Assumption
Here we need to formally introduce a concept, because it is the root of all problems in this chapter.
It is called the Closed World Assumption (CWA).
Closed World Assumption: What you don't know, the system treats as non-existent
The Closed World Assumption (CWA) is the default working mode of rule-based systems: any fact not explicitly recorded in the knowledge base is treated as "not true" or "non-existent."
Compare the two worldviews:
- Closed world: what's not written in = does not exist (the logic of database-style queries)
- Open world: what's not written in = I don't know (closer to reality)
This assumption is reasonable in closed, bounded domains (like a flight database). But in the open real world, it is very dangerous: the system will mistake "I haven't seen this situation" for "this situation does not exist," and then confidently give a wrong answer.
Today's large language models have a similar problem — the boundaries of training data are, in a sense, a new form of "closed world." This problem runs throughout this book.
In a rule-based system, you can only use knowledge you have already put in. Anything you have not explicitly stated, the system treats as "non-existent" or "not true."
For example. You build a database containing all the flight information you know. Someone queries "are there direct flights from Beijing to Mars." Under the closed world assumption, because there is no such record in the database, the system's answer is: no. This answer is correct.
But: someone queries "are there any flights from Beijing to Shanghai this afternoon." It's not in the database, and the system answers: no. But perhaps the database is simply incomplete — perhaps the flight exists, you just didn't enter it.
In these two situations, the system gives exactly the same mode of answering, but one is a correct inference and the other is an erroneous inference. The closed world assumption cannot distinguish between "explicitly non-existent" and "unknown whether exists."
In expert systems, this problem is even more severe. Your rule base covers 70% of the doctor's knowledge. What about the remaining 30% of situations? The system won't say "I don't know" — it will follow the existing rules and derive an answer it "can" derive, an answer that may be completely wrong, and the system will be fully confident in this answer.
This is a very dangerous failure mode.
It won't be confused; it will only crash, and crash with confidence.
VI. The Descendants of MYCIN
Let us continue the story.
After MYCIN, the expert systems approach was extended to almost every conceivable domain. Oil exploration (PROSPECTOR, 1978, one case discovered a molybdenum deposit worth approximately one hundred million dollars). Loan approval (numerous banking systems). Production scheduling (Digital Equipment Corporation's XCON, saving the company tens of millions of dollars annually).
The 1980s — this was a very hot industry. There were specialized companies selling expert system development tools, a specialized engineer position called "knowledge engineer," and universities offering specialized courses. The Japanese government launched an ambitious "Fifth Generation Computer Project" in 1982, aiming to build a supercomputer based on logical reasoning, expecting a breakthrough in artificial intelligence within ten years. The U.S. government was frightened and specifically established DARPA's Strategic Computing Initiative in response.
Doesn't this sound familiar? Every few decades, this kind of story happens again.
And then, slowly, the cracks appeared.
Maintenance cost. In a large expert system, the interactions between rules became extremely complex. You modify one rule and discover it breaks the reasoning chains of three other rules. Expert systems began to become brittle — brittle not in edge cases, but in the core area where they should have been most powerful, collapsing due to internal contradictions.
Scalability. Expanding from 600 rules to 6000 rules, the system's behavior became unpredictable. Knowledge engineers could not simultaneously track all rule interactions in their heads, let alone understand their combined global behavior.
Adaptability. MYCIN was written in 1972. Medicine advances. New pathogens, new detection methods, new drugs. Every update required knowledge engineers to re-enter the system, find the affected rules, manually modify them — while being careful not to break anything else. This was not a self-learning system; it was a static snapshot requiring constant human maintenance.
By the late 1980s, Japan's Fifth Generation Computer Project began to run into trouble. The limitations of expert systems became increasingly clear. In 1987, the expert system hardware market collapsed, and the AI industry entered its second "winter."
VII. A Simple Expert System
To prevent this from being merely abstract history, let me show you what an actual miniature expert system looks like.
This is a small system for diagnosing "what animal is this," originally given by Winston and Horn in their 1981 textbook — a classic case in expert systems education:
The facts you input: ["has hair", "eats meat", "tawny color", "has dark spots", "has claws", "eyes forward"]
Reasoning process:
Triggered R1: ['has hair'] -> is mammal
Triggered R5: ['is mammal', 'eats meat'] -> is carnivore
Triggered R6: ['is mammal', 'has claws', 'eyes forward'] -> is carnivore [already known]
Triggered R8: ['is carnivore', 'tawny color', 'has dark spots'] -> is cheetah
Final conclusion: is cheetah
This logic is clear, traceable, and explainable. For every step of reasoning, you can say which rule it came from. This is precisely a major advantage of expert systems — transparency.
But now, you ask: this animal simultaneously has dark spots and black stripes.
The system does not know how to handle this situation. R8 and R9 are both partially satisfied, but the two rules have different conclusions — is it a cheetah or a tiger? The system's handling depends on the implementation: sometimes it reports the first matching conclusion, sometimes it gets stuck in conflict, sometimes it produces two contradictory conclusions.
It won't be confused, it won't say "I don't know," it will give you an answer.
And that answer may be completely meaningless.
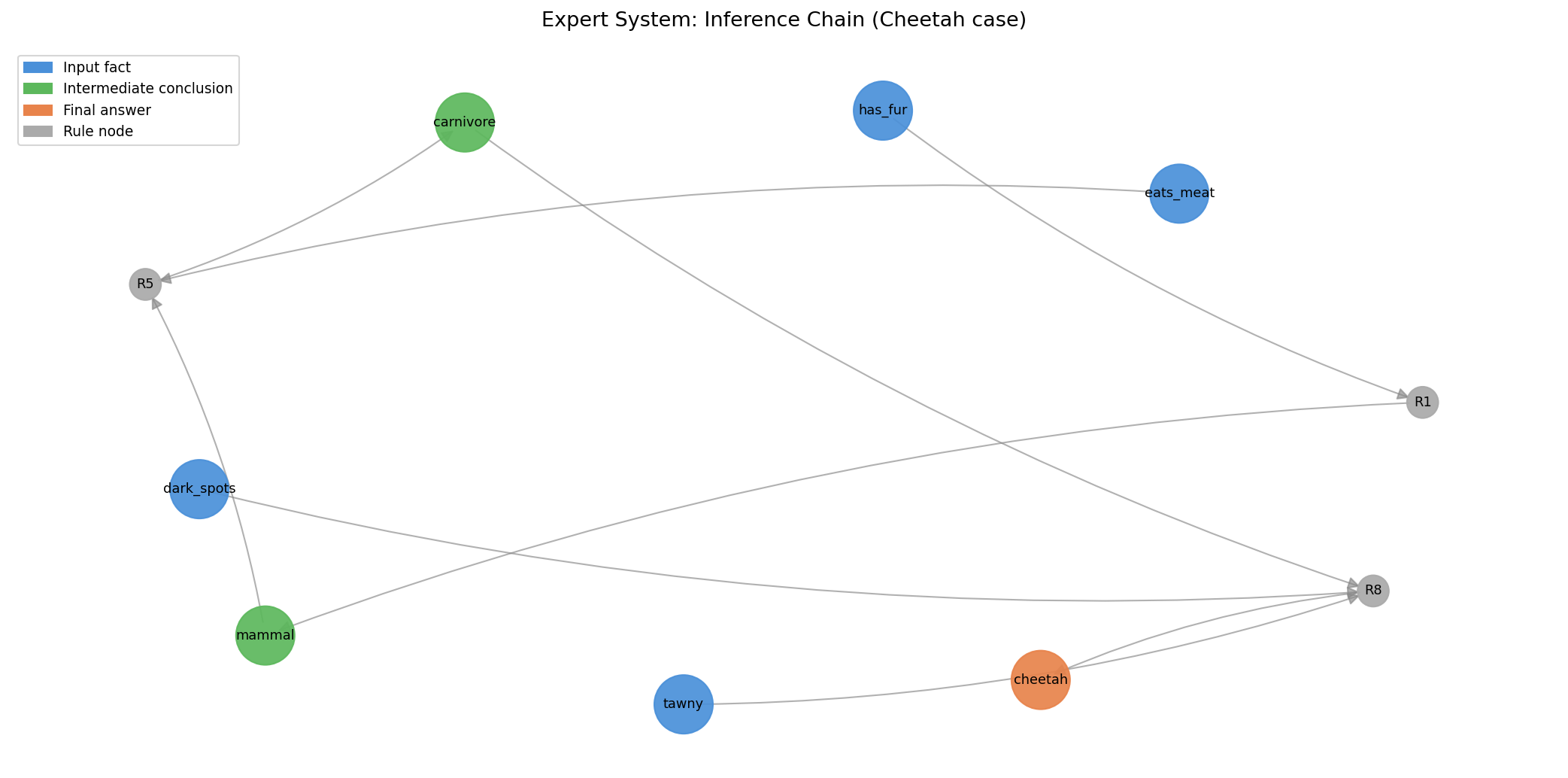
Figure 1: The DAG structure of MYCIN-style forward chaining reasoning. Each node is a fact or conclusion, each edge is a triggered rule. The reasoning path is clear and traceable — this is the greatest advantage of expert systems, and also their ceiling.
VIII. Why It Failed — The Real Reason
Now I want to say something deeper than "knowledge can never be fully written."
The core assumption of expert systems is: reasoning can be decomposed into independent, enumerable rules, and the interactions between rules are finite and predictable.
This assumption holds in very constrained domains. MYCIN dealt with the diagnosis of bacterial infections — a domain with clear boundaries, standard protocols, and finite variables. Here, the knowledge base is close to complete, and reasoning is close to closed.
But in the open, real world, this assumption is fundamentally wrong.
Human reasoning is not a rule system. When you walk into an unfamiliar room, you are not accessing a rule base about "rooms" and matching them one by one. What your brain is doing is mapping this new scene into an internal, highly compressed world model — a model you have spent decades building, continuously updated through countless experiences. This model is continuous, is generative; it can interpolate, can extrapolate, can produce reasonable guesses when encountering new situations, even if this situation has never appeared in the samples it has "seen."
Rule systems do not have this capability. Rule systems are discrete, are enumerative; they can only reason within the regions they explicitly cover. When they encounter the boundary of the rule base, they won't guess; they will crash.
There is a deeper philosophical question here. In 1971, philosopher Hubert Dreyfus raised it in his What Computers Can't Do: human intelligence, to a large extent, depends on our intuition about "what is important" — and this intuition is situated, formed through the experiences we accumulate as embodied beings living in the world. You cannot extract this situated knowledge into context-free rules, because it never existed in the form of rules to begin with.
Dreyfus was mocked by the AI community at the time. Later it was proven he was largely right.
Figure 2: The boundary between the region covered by the knowledge base (known) and what lies beyond coverage (unknown). Expert systems reason precisely within the known region; at the boundary, they won't say "I don't know," but will follow the nearest known rule to give a wrong, confident answer. The Closed World Assumption conflates "not in the base" with "does not exist."
IX. Yet What It Left Behind
I don't want the ending of this chapter to sound too much like a failure story. Because that is not the full picture.
Expert systems, in what they were good at, were genuinely effective. Those problems where the number of rules is limited, the domain boundaries are clear, and the knowledge can be fully enumerated — the real tens of millions of dollars XCON saved for DEC, that was real. In loan approval systems, if the rules are well-written, bias can be explicitly audited and corrected — this is far more transparent than the implicit biases in black-box systems. Medical decision support systems still use some form of rule engines to this day, on formatted, rule-explicit subtasks.
More importantly, the expert systems era left behind some truly important legacies:
Clear problem decomposition. Decomposing a complex problem into independently manageable subproblems — this is a truly valuable capability. Modern software engineering still does this.
Reasoning interpretability. You can trace every step of the system's reasoning — in today's AI systems, this is ironically a scarce commodity. The problem of interpretability has become a hot topic again in the deep learning era, and expert systems did this the best.
Knowledge representation theory. The theory of Knowledge Representation built around expert systems later developed into Ontology, Description Logic, and the Semantic Web — these things still run in many industrial systems to this day.
Ontology, Description Logic, Semantic Web: How are these three terms related?
These three terms are different layers of "how knowledge can be structurally represented in computers":
- Ontology: in computer science, it refers to "using a formal language to define the conceptual system and relationships between concepts in a domain." For example, the medical ontology SNOMED defines hierarchical relationships between "disease," "symptom," and "medication."
- Description Logic: the set of logical languages used to build ontologies, more precise than natural language, more computable than full first-order logic. OWL (Web Ontology Language) is based on description logic.
- Semantic Web: the vision proposed by Tim Berners-Lee — making data on web pages not just readable by humans, but also "understandable" by machines (i.e., machines can understand the semantic relationships of data). RDF and OWL are its core technologies.
These three form a chain from concept to technology: Ontology is the goal, Description Logic is the tool, and the Semantic Web is the application scenario.
And, the most important legacy:
A clear counterexample about the boundaries of reasoning. Expert systems thoroughly and empirically demonstrated that: if reasoning depends on a complete explicit knowledge base, then how far reasoning can go depends entirely on how complete your knowledge base is written. The world is open, the knowledge base is closed. The tension between the two is the fundamental limitation of any rule-based system.
The opposite of this lesson is the direction AI research turned to in the following decades: do not try to explicitly write out all rules, but let machines learn these regularities from data, including the tacit knowledge that humans themselves cannot articulate.
This was not an easy transition, nor a completely successful one. But that is the story of the next chapter.

Figure 3: The complete rule network of the animal identification expert system. The left layer contains raw observational facts (input), the middle layer contains intermediate reasoning conclusions (mammal, bird, carnivore…), the right layer contains final classifications. The connections between nodes are rule dependencies. This diagram is also a demonstration of the paradigm's limit: when the number of rules grows from 10 to 10000, no one can track this diagram in their head.
X. A Small Pause
Let me sort out this chapter here.
The era of symbolic AI and expert systems gave us a very clean lesson: explicitly representing the world's knowledge as rules is, in principle, an impossible task. Not because we didn't work hard enough, but because the structure of knowledge itself is not in the form of rules — it is situated, tacit, continuous, generative.
Logic gates are the simplest physical implementation of causality. Rule systems are the most direct modeling of causal reasoning. Where they excel, they work very well. But the world is far broader than this.
The Closed World Assumption is the death point of this paradigm: within the scope of what you know, it is strong; at the boundary of what you know, it collapses gracefully; and you never know where that boundary is, because you don't know what you don't know.
This is a pattern worth remembering. Not just about expert systems, but about any reasoning system. Every reasoning system has its closed-world boundary — it explicitly or implicitly assumes that certain things do not exist, or that certain situations will not occur. When reality touches this boundary, reasoning fails in some way.
The mode of failure differs; the lesson is the same: reasoning requires a world model, and the boundary of the world model is the boundary of reasoning.
In Chapter 3, we will begin to talk about vectors, about continuous representation spaces, about the revolution of representation learning. Moving from discrete symbols to continuous vectors is a fundamental leap. But the new problems brought by this leap are not necessarily fewer than the old problems it solved.
Symbols failed, but they left behind a question: What is meaning? In the next chapter, we will see how vectors give "meaning" a geometric coordinate.
The Scaled Evolution of Symbols: From Expert Systems to Knowledge Graphs
Before closing this chapter, let us see how the legacy of symbolism persists in modern AI — in the form of knowledge graphs.
Knowledge Graphs: The Scaled Implementation of Symbolism
Knowledge graphs are essentially the scaled, structured version of expert system knowledge bases:
- Entities replace the "concepts" in expert systems
- Relations replace the "conditions" in If-Then rules
- Triples (head entity-relation-tail entity) constitute the basic unit of knowledge
But knowledge graphs face challenges similar to expert systems:
- Construction cost: requires extensive manual annotation or complex extraction algorithms
- Coverage problem: can never completely cover all knowledge
- Dynamic updates: the world changes, knowledge graphs need continuous updating
- Knowledge representation: how to represent fuzzy, probabilistic, context-dependent knowledge?
The Dialogue Between Knowledge Graphs and Large Models
A frontier direction in current AI research is the combination of symbols (knowledge graphs) and statistics (large models). This is not a simple replacement relationship, but a complementary relationship:
| Dimension | Knowledge Graph | Large Model |
|---|---|---|
| Knowledge Representation | Explicit, structured, discrete | Implicit, distributed, continuous |
| Interpretability | High: clear triple structure | Low: black-box vector operations |
| Reasoning Mode | Symbolic logic reasoning | Statistical pattern matching |
| Knowledge Acquisition | Manual construction/extraction | Implicit learning from text |
| Dynamicity | High update cost | Can adapt via fine-tuning |
Combination Strategies: RAG and Knowledge Injection
Current main combination approaches:
- Retrieval-Augmented Generation (RAG): using knowledge graphs as external memory to provide factual grounding for large models
- Knowledge Injection: converting knowledge graph triples into training data and injecting them into large models
- Symbol-Guided Generation: using knowledge graph structures to constrain large model outputs
- Hybrid Reasoning: symbolic reasoning handles deterministic knowledge, statistical reasoning handles uncertainty
Deep Questions: Fundamental Differences Between Symbols and Statistics
This combination faces fundamental challenges:
- Representation gap: discrete symbols vs. continuous vectors
- Reasoning gap: logical deduction vs. probabilistic inference
- Knowledge gap: explicit declaration vs. implicit entailment
- Update gap: local updates vs. global retraining
Key question: Knowledge graphs are "slow but accurate," large models are "fast but fuzzy." How can they be made to work together rather than simply patched together?
Discussion Question: A Modern Revival of Symbolism?
Does the combination of knowledge graphs and large models signify some kind of revival of symbolism? Or is it merely borrowing the form of symbols within a statistical framework?
A deeper question: if large models can "learn" knowledge from text, why do we still need explicit knowledge graphs? Possible answer: interpretability, verifiability, updatability — these are indispensable in critical applications (medicine, law, finance).
Unresolved
Do modern large language models, in some implicit way, reintroduce the Closed World Assumption? Is the distribution of training data a new form of "knowledge base boundary"?
The interpretability of expert systems is a genuine advantage. But are interpretability and correctness the same thing? Being able to articulate the reasoning process does not mean the reasoning process is correct.
A core point of Dreyfus's critique: situated knowledge cannot be made explicit. Do large language models somehow capture situated knowledge? Or are they merely performing very high-dimensional pattern matching?
The combination of symbols and statistics: knowledge graphs provide structured knowledge, large models provide generalization ability. Is this combination a "1+1>2" synergy, or an "oil and water" patchwork? What fundamental problems need to be solved for true fusion?
Dual representation of knowledge: the same fact, in a knowledge graph it is a discrete triple, in a large model it is a continuous vector distribution. How can these two representations mutually verify and complement each other? When they conflict, which should be trusted?
Hands-On: Build Your Own Expert System, Then Make It Collapse
The lesson of this chapter is: rules can never be fully written, boundaries cannot be found, failure comes silently. Just reading without doing, these things remain abstract aphorisms. You need to build it with your own hands, then watch with your own eyes as it collapses at the boundary.
Step 1: Choose a Domain You Truly Understand
Don't choose medicine, don't choose law. Choose a domain you actually have experience with — one where you can say "this is what should be done in this situation."
A few suggestions: - Determining the flavor style of a dish (Sichuan / Cantonese / Japanese…) - Diagnosing common computer faults (network issues / hardware issues / software issues…) - Judging whether an article is worth reading in depth (field / source / keywords…) - Assessing the difficulty level of a programming problem (easy / medium / hard)
Once chosen, write down on paper: what are the final conclusions of this domain? (Categories, no more than 10.)
Step 2: Write Your Rule Base
Using the format shown in Section VII of this chapter, write at least 15 If-Then rules.
# Rule data structure: each rule is a dictionary
# 'conditions': list of premise conditions (all conditions in the list must be met to trigger)
# 'conclusion': rule conclusion (a string)
# 'name': rule name, for tracking the reasoning trace
# Example: a rule base for "determining cuisine type"
rules = [
# ── Intermediate layer rules: identifying ingredient characteristics ──────
{"name": "R1", "conditions": ["has houttuynia"], "conclusion": "uses Sichuan specialty ingredients"},
{"name": "R2", "conditions": ["has chili", "has Sichuan pepper"], "conclusion": "mala style"},
{"name": "R3", "conditions": ["has sashimi"], "conclusion": "uses Japanese ingredients"},
{"name": "R4", "conditions": ["has miso"], "conclusion": "uses Japanese ingredients"},
{"name": "R5", "conditions": ["has douchi", "has steamed fish soy sauce"], "conclusion": "Cantonese seasoning"},
{"name": "R6", "conditions": ["has ginger and scallion"], "conclusion": "Cantonese base flavor"},
# ── Intermediate layer rules: identifying cooking methods ──────────────
{"name": "R7", "conditions": ["high-heat stir-fry"], "conclusion": "high-heat quick-fry style"},
{"name": "R8", "conditions": ["steamed"], "conclusion": "light cooking style"},
{"name": "R9", "conditions": ["charcoal grilled"], "conclusion": "barbecue style"},
# ── Terminal layer rules: arriving at cuisine conclusions ──────────────
{"name": "R10", "conditions": ["uses Sichuan specialty ingredients", "mala style"], "conclusion": "is Sichuan cuisine"},
{"name": "R11", "conditions": ["uses Japanese ingredients"], "conclusion": "is Japanese cuisine"},
{"name": "R12", "conditions": ["Cantonese seasoning", "light cooking style"], "conclusion": "is Cantonese cuisine"},
{"name": "R13", "conditions": ["Cantonese base flavor", "Cantonese seasoning"], "conclusion": "is Cantonese cuisine"},
{"name": "R14", "conditions": ["barbecue style", "uses Sichuan specialty ingredients"], "conclusion": "is Sichuan-style barbecue"},
{"name": "R15", "conditions": ["high-heat quick-fry style", "Cantonese seasoning"], "conclusion": "is Cantonese stir-fry"},
]When writing, pay attention to two things:
a. Write intermediate layer rules, not just rules that go directly to conclusions.
Bad writing:
IF has houttuynia AND has chili THEN is Sichuan cuisine
Good writing:
IF has houttuynia THEN uses Sichuan specialty ingredients
IF has chili AND has Sichuan pepper THEN mala style
IF uses Sichuan specialty ingredients AND mala style THEN is Sichuan cuisine
The intermediate layer makes the reasoning chain interpretable and also exposes problems more clearly.
b. Try to reason backwards from conclusions, not just forwards from conditions.
Ask yourself: "To conclude 'is Sichuan cuisine,' what are the minimum prerequisites needed? Are these prerequisites sufficient? Are there any exceptions?"
Step 3: Implement the Forward Chaining Engine
This chapter has already given you the complete pseudocode logic:
def forward_chain(rules, initial_facts):
"""
Forward chaining inference engine.
rules: list of rules, each rule has three fields: 'conditions', 'conclusion', 'name'.
initial_facts: set of initial observed facts (set).
Returns: (final facts set, reasoning trace list)
"""
# Known facts set = input observation set
known_facts = set(initial_facts)
reasoning_trace = [] # record which rules were triggered (reasoning trace)
# Repeat inference until no new facts are added
while True:
new_fact_added = False # mark whether any new fact was added this round
for rule in rules:
# Check whether all premises of the rule are in the known facts set
conditions_met = all(cond in known_facts for cond in rule["conditions"])
if conditions_met and rule["conclusion"] not in known_facts:
# Add the rule's conclusion to the known facts set
known_facts.add(rule["conclusion"])
# Record which rule was triggered (this is your reasoning trace)
reasoning_trace.append(
f"Triggered {rule['name']}: {rule['conditions']} -> {rule['conclusion']}"
)
new_fact_added = True
# If no new fact was added this round, stop
if not new_fact_added:
break
# Output: known facts set + reasoning trace
return known_facts, reasoning_trace
# ── Example run ────────────────────────────────────────────────────
# Initial observations: input dish characteristics
initial_observations = {"has houttuynia", "has chili", "has Sichuan pepper", "high-heat stir-fry"}
final_facts, trace = forward_chain(rules, initial_observations)
print("=== Reasoning Trace ===")
for step in trace:
print(" ", step)
print("\n=== Final Conclusions ===")
conclusions = [f for f in final_facts if f.startswith("is")]
for c in conclusions:
print(" ", c)No graphical interface needed, no database needed, no configuration files. The simplest implementation: store rules in a list, store known facts in a set, use a loop for inference.
Step 4: Construct Three Test Cases — Let One Pass, Two Fail
Case A: Normal case. A typical case your rule base can fully cover. Input observations, get the correct conclusion, reasoning trace complete. This is proof that "the system works."
Case B: Boundary case. Construct an ambiguous case sitting between two categories — simultaneously satisfying the premises of two different conclusions. Observe the system's behavior: does it report two conclusions? Choose the first match? Or silently give a wrong answer?
Your first question: In Case B, is your system's behavior an "acceptable failure" or a "dangerous silent failure"? What's the difference between these two?
Case C: Out-of-distribution case. Construct a case your rule base completely failed to anticipate — for example, a fusion dish with both Sichuan and Japanese ingredients; or a computer whose fault symptoms cross all known categories.
Observe: what will the system output? Will it say "I don't know"? Or will it follow some nearest rule chain and give an answer that seems reasonable but is actually wrong?
Your second question: For Case C's input, which rules were triggered? What situations were these rules originally designed for? What specific defect of the Closed World Assumption does the system's misuse of rules illustrate?
Step 5: Do the Math
How many rules did you write? How much of this domain do these rules cover?
Estimate: how much knowledge in this domain do you think you still haven't written in? Of the knowledge not written in, is it because you don't know it, or because you "know it but can't articulate it"?
Your third question (and the hardest one): If you had to convert all your knowledge in this domain into rules, how many would you need? Is this number finite?
Verification Criteria
After completing this exercise, you should be able to answer:
Where the boundary of your rule base lies — not the boundary you guess, but the boundary you personally hit
Whether the system's mode of failure at the boundary matches the "confident error" described in this chapter
Why knowledge engineers say this is "an almost impossible mission"
You don't need to theoretically articulate the third one. You just need, in your own tiny domain, to feel once why.
Further Reading
Shortliffe, E. H. (1976). MYCIN: Computer-Based Medical Consultations — The foundational case study of expert systems
Dreyfus, H. L. (1972). What Computers Can't Do — A philosophical critique of the symbolic AI paradigm, mocked at the time, later proven profound
Reiter, R. (1978). "On Closed World Databases." Logic and Data Bases — The formal definition of the Closed World Assumption; the original source for understanding the core concept of this chapter
Minsky, M. (1975). "A Framework for Representing Knowledge." The Psychology of Computer Vision — Frame systems, another path attempting to solve the knowledge representation problem
Winston, P. H. & Horn, B. K. P. (1981). LISP — Contains the classic animal identification expert system case, the original inspiration for this chapter's script
[Bader et al., 2004, arXiv:cs/0408069] — Neuro-symbolic integration: the unified challenge of connectionism and first-order logic knowledge representation, the modern echo of expert-systems-era problems