Chapter 3: From Symbols to Vectors — The First Liberation of Representation Space
Subtract "man" from "king," add "woman," and you get "queen." Is this reasoning or arithmetic?
I. That Sentence
In 2013, Tomas Mikolov wrote down an equation in a paper — an equation that would later be cited more frequently than perhaps any NLP paper of that era:
What it means: if you take the word vector for "king," subtract the word vector for "man," and add the word vector for "woman," the nearest neighbor word vector is "queen."
This was not a carefully crafted example — this emerged from the experimental results. The algorithm learned this relationship; nobody told it that "king is to man as queen is to woman."
At this moment, the AI research community collectively gasped.
Why? Because it looked like the machine was doing analogical reasoning. Not rule-based reasoning, not logical deduction, but something closer to human intuition: grasping the essence of a relationship and then transferring it to a new object.
And then the question arose: is it really reasoning?
This chapter is about exactly this — what vector representations are, why they are more powerful than symbols, and where that power comes from, and where it stops.
II. The Problem with Symbols, Revisited
In the previous chapter, we saw the core dilemma of symbolic AI: knowledge must be explicitly written out, and the world's knowledge can never be fully written.
But there is another problem I didn't emphasize, which is that the semantics of symbols are external.
In an expert system, the string "is mammal" is, to the machine, just a token — an atom that cannot be further decomposed. It doesn't know the relationship between "mammal" and "animal," doesn't know how close "mammal" is to "reptile," doesn't know that "cat" is more of a typical mammal than "whale."
All these relationships need to be explicitly written into rules.
IF is mammal
THEN is animal [R_base_1]
IF is mammal
AND is not cetacean
THEN usually has legs [R_mammal_legs]
Every relationship must correspond to a rule. And relationships are infinite; rules can never be fully written.
The root of this problem is: symbolic systems use discrete tokens to represent concepts, but the relationships between concepts are continuous, graded, and nested. The distance between "cat" and "dog" cannot be captured by discrete If-Then rules — you can only say "cat is a mammal, dog is a mammal," but you cannot say "cat is closer to dog than to snake."
Vector representations solved this problem. Not completely, but they solved the core part.
III. The Distributional Hypothesis: Meaning Hides in Neighbors
The idea of vector representations can be traced back to something linguist J.R. Firth said in 1957:
"You shall know a word by the company it keeps."
This intuition is called the Distributional Hypothesis: the meaning of a word is determined by its contextual distribution within a corpus.
Words that appear in similar contexts have similar meanings. "Cat" and "dog" both frequently appear in contexts like "I have a ___ as a pet," "feed it," "it barked/meowed" — so they are semantic neighbors.
This intuition can be mechanized. You build a matrix where rows are words, columns are context words (or documents), and each cell records the co-occurrence count (or its transform). Then, each row is a vector representation of that word. Words with similar meanings have corresponding vectors that are close to each other in high-dimensional space.
This is the original version of vector representations, called Distributional Semantic Models (DSM), which have existed since the 1990s. It works, but has two problems: the dimensionality is too high (potentially hundreds of thousands of dimensions), and the vectors are very sparse (most cells are zero).
Distributional Semantic Models (DSM): Word meaning hides in the co-occurrence matrix
Distributional Semantic Models are a class of methods that represent word meaning as vectors. The core idea is: build a large "word × context" table, record which words each word frequently co-occurs with, and then treat each row of this table as the vector for that word.
- High-dimensional: if the corpus has 100,000 different words, the matrix has 100,000 columns, and each word's vector is 100,000-dimensional — very long
- Sparse: most word pairs rarely or never co-occur, so most of the matrix is zeros, making storage extremely wasteful
Word2Vec (Mikolov 2013) solved this problem: instead of directly building the matrix, it trains a neural network to implicitly compress this co-occurrence information into 100-300-dimensional dense vectors.
Mikolov's 2013 paper did something more radical.
IV. Word2Vec: Compressing Semantics Through Prediction
Word2Vec does not build a co-occurrence matrix. It trains a neural network with the task: given a word, predict its context words (Skip-gram), or given context words, predict the center word (CBOW).
Skip-gram and CBOW: The two training modes of Word2Vec
Word2Vec has two variants, differing in the direction of the prediction task:
- Skip-gram: input the center word, predict the surrounding words. For example, in the sentence "I like to eat apples," input "eat," predict "like" and "apples." Better for small datasets, handles low-frequency words better.
- CBOW (Continuous Bag of Words): input the surrounding words, predict the center word. Input "like" and "apples," predict "eat." Faster training, better for large datasets.
Both approaches are just means; the real goal is to learn the word vector representations (embeddings). After training is complete, the prediction head is discarded, and only the word embedding matrix is kept.
This sounds mundane. But the byproduct is the point.
When you train this network, you map each word to a low-dimensional vector (typically 100 to 300 dimensions). For the prediction task to be done well, these vectors must encode something essential about the words — because only by understanding the relationships between words can you accurately predict which words will co-occur.
After the network training is complete, you throw away the prediction head and keep only the word embedding matrix. These are your word vectors.
There is something profound here worth pausing to think about:
You didn't teach the network the relationship between "king" and "queen." You didn't tell it any semantic rules. You just let it predict text sequences. Then, after it learned to predict, you discovered that relationships like "king - man + woman ≈ queen" spontaneously emerged.
Why does this happen? Because in natural language, the places where "king" appears are also where "queen" appears in some parallel way — just in the corresponding feminine contexts. For the network to predict accurately, it must encode this parallel relationship into the vectors. "Royalty" is one contextual axis; "gender" is another contextual axis. These two axes correspond to two directions in the vector space. Subtracting the vector for "man" and adding the vector for "woman" is performing a shift along the gender axis.
Semantics emerged from distribution.
V. Shallow Logic in Geometry
Let us look more closely at this analogy equation.
King - Man + Woman ≈ Queen Paris - France + Japan ≈ Tokyo Walk - Walked + Swam ≈ Swim (past tense relationships are also encoded)
Every analogy corresponds to a translation in the vector space. The difference between "man->king" and "woman->queen" is a fixed vector direction, representing "movement along the gender dimension."
This is a very clean geometric structure. Semantic relationships become directions.
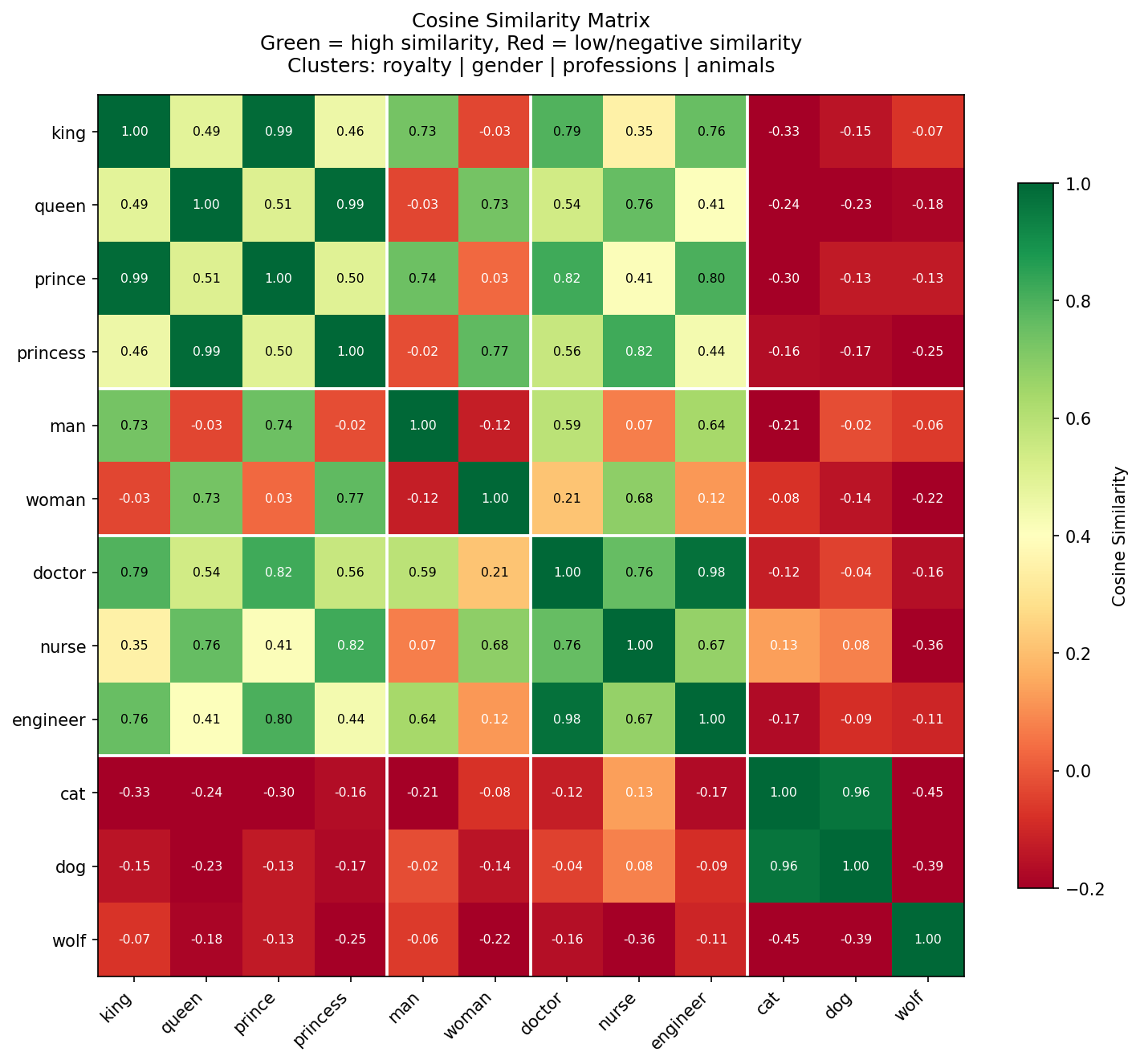
Figure 4: Pairwise cosine similarity matrix for 12 words. Green = high similarity, red = low/negative similarity. White lines demarcate the boundaries of four semantic clusters (royalty, gender, profession, animal). Observe: intra-cluster similarity is significantly higher than cross-cluster; the animal cluster has almost no overlap with the other three clusters. This is exactly the visual proof that "semantically similar words are neighbors in the vector space."
VI. The Bias of Vectors: Corpus as Worldview
What Word2Vec learns is not the truth of language, but the statistical regularities of the corpus. And the corpus is a product of human writing — it carries human biases, historical biases, cultural biases.
This is not a marginal problem; it is the core cost of the Distributional Hypothesis.
The Experiment of Bolukbasi et al. (2016)
They found that in Word2Vec trained on Google News:
"Man is to doctor as woman is to nurse" — this analogy holds in the vector space because it holds statistically in the training corpus.
A more direct test:
Not "female programmer," but "homemaker."
This is not a bug in the algorithm; this is the algorithm correctly learning the statistical regularities in the corpus. The bug is: we mistook statistical regularities for semantic truth.
Where does the bias come from?
The Distributional Hypothesis says: a word's meaning hides in its neighbors. But if the neighbors' distribution itself is biased —
- In news reports, the neighbor words of "CEO" are more often "his decision" rather than "her decision"
- In historical texts, "scientist" co-occurs more often with male names
- In novels, the gender distribution of emotion words is uneven
Word2Vec faithfully learns these regularities. It is a mirror, reflecting the corpus, not the world.
This reveals a fundamental limitation of the Distributional Hypothesis:
What vector space learns are descriptive statistical regularities, but reasoning requires normative truth values. "In the corpus, X and Y frequently co-occur" does not equal "X and Y have a causal relationship in the world," nor does it equal "this co-occurrence is correct."
You can apply debiasing to word vectors (Bolukbasi's paper proposed a linear projection method), but this is treating the symptom rather than the cause. The fundamental problem is: starting from statistical correlation, you cannot reach semantic truth.
This limitation still exists in the era of Transformers and large language models. Larger corpora, larger biases, broader coverage — but the underlying logic of the Distributional Hypothesis hasn't changed.
VII. The Illusion of Analogy
Let me return to that equation:
Is this really reasoning?
Let's take it apart and think.
For this equation to hold, it means that in the word vector space, the vector difference between "king" and "man" is approximately equal to the vector difference between "queen" and "woman."
What is this? It is a statement about the consistency of vector offset directions. It is geometric regularity, not logical reasoning.
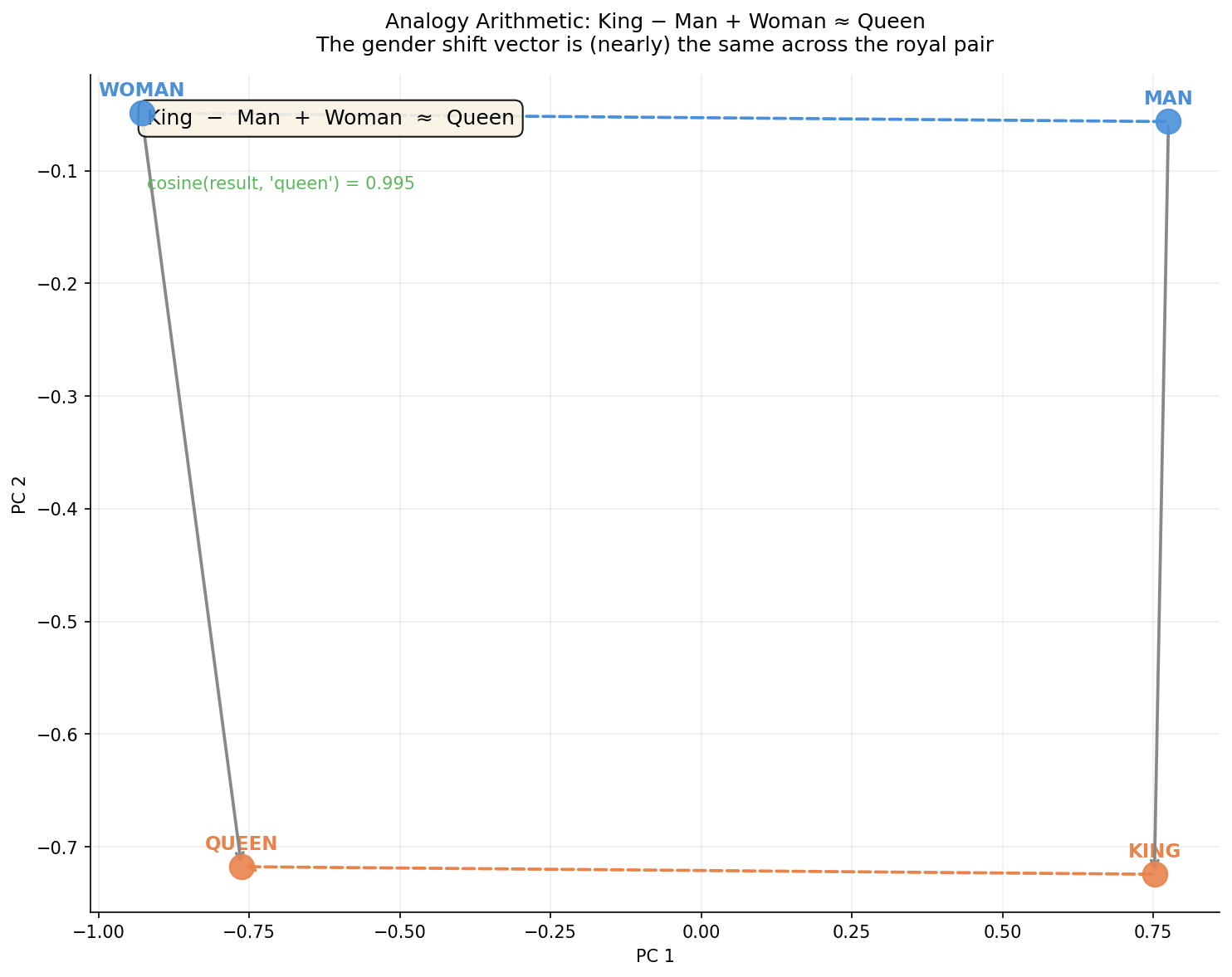
Figure 2: Geometric visualization of vector analogy. Four words form an approximate parallelogram in PCA 2D space — man->king and woman->queen are two approximately parallel sides, and man->woman and king->queen are another pair of approximately parallel sides. This is what "the gender shift vector remains consistent across royalty word pairs" means. The cosine similarity of King − Man + Woman to Queen approaches 0.995.
In logic, reasoning requires rules + facts -> conclusion. "All kings are men" plus "Elizabeth is a queen" leads to "Elizabeth is not a king" — this is reasoning, because there is transitivity, variable binding, quantifiers.
Vector arithmetic has none of these. It is merely saying: the relative positions of these words in the semantic space exhibit some kind of parallel structure.
More importantly, this equation does not hold in many cases.
Fournier et al. (2020) systematically analyzed the limitations of analogy tests and found: the so-called "analogy equations" heavily depend on a convenient evaluation trick — excluding the input words themselves from the answers, when the nearest neighbor is often one of the input words. After changing the evaluation method, the statistical results of much "analogy ability" dropped significantly -> [Fournier et al., 2020, arXiv:2010.03446].
There is an even more direct example. Try this analogy:
Doctor - Man + Woman ≈ ?
On certain training corpora, what you get is not "female doctor," but "nurse."
Because in those corpora, "doctor" co-occurs more frequently with male contexts, and "nurse" co-occurs more frequently with female contexts. What the model learned is not the neutral meaning of the profession "doctor," but its statistical bias in the specific corpus.
Vector representations do not capture truth. They capture the statistical distribution of the corpus. If the corpus has bias, the vectors have bias. This is not a bug; it is how it works.
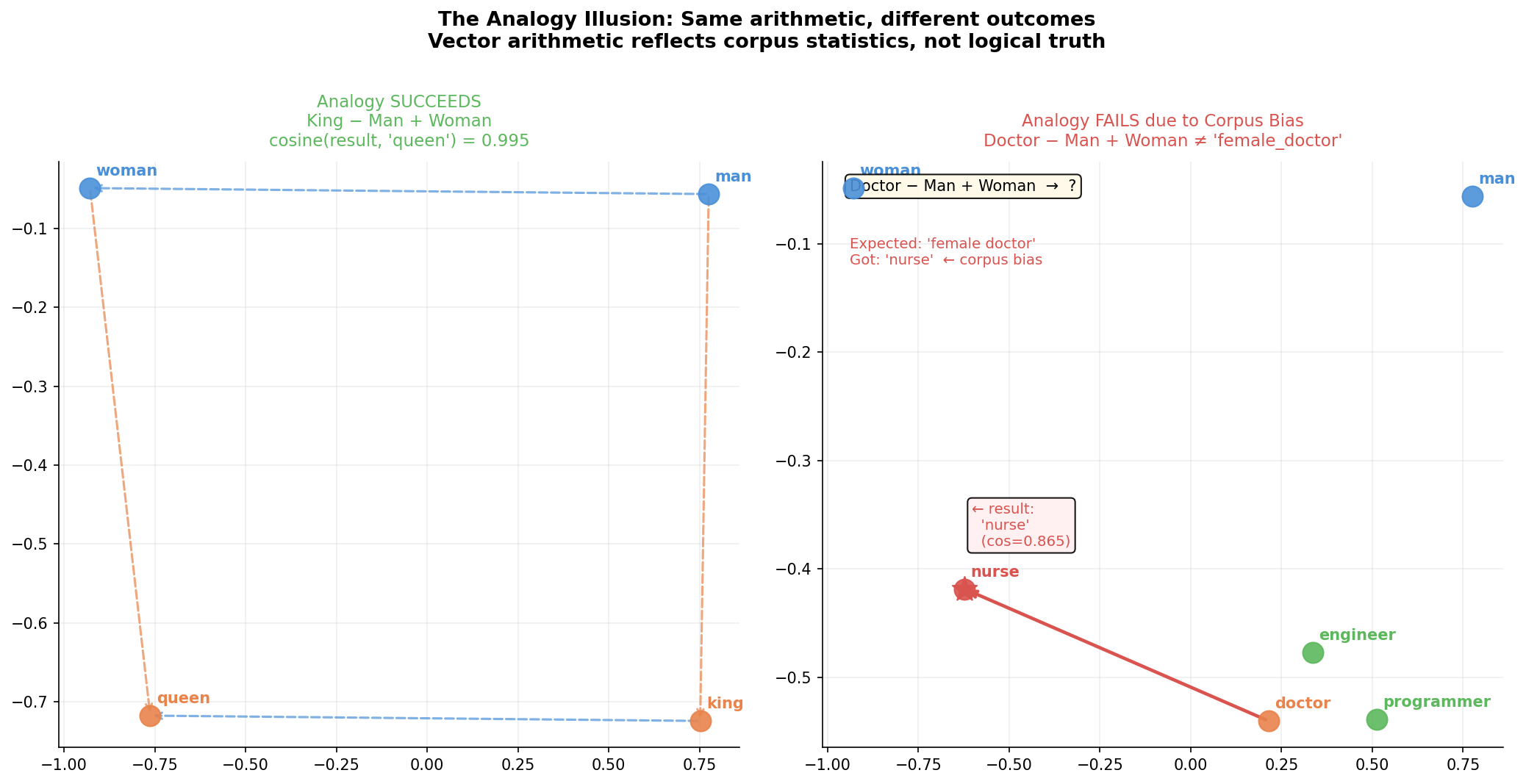
Figure 3: Left panel, the royalty analogy succeeds — the result vector of King − Man + Woman is highly close to Queen (cosine ≈ 0.995), with a clear parallelogram structure. Right panel, the profession analogy fails — Doctor − Man + Woman does not point to "female doctor" but to Nurse (cosine ≈ 0.865). This is because in the training corpus, Doctor is biased toward male contexts, and Nurse toward female contexts. Same arithmetic, different bias outcomes.
VIII. The Upper Bound of the Distributional Hypothesis
Let us think more deeply about where the boundary of the Distributional Hypothesis lies.
The Distributional Hypothesis says: meaning is determined by contextual distribution. This is correct in many cases. But it implies: if two words have exactly the same contextual distribution in text, the model will consider them to have the same meaning.
"I like cats" and "I like dogs" — these two sentences are structurally completely symmetric, so "cat" and "dog" are highly similar in distribution. Indeed, they are semantically close; the model is right.
But:
"The Earth revolves around the Sun" and "The Sun revolves around the Earth"
For these two sentences, if you only look at word distribution, "Earth" and "Sun" will appear in very similar contexts — they frequently appear in sentences about astronomy, gravity, and revolution. But of these two sentences, one is true and one is false.
Distributional semantic models have no concept of truth value. They don't know which propositions are true and which are false. What they know is which words appear in which contexts — this is a statistical regularity, not a causal model of the world.
This is why vector representations, despite performing well on many tasks, have not solved the reasoning problem. What they solved is the representation problem: using a richer, more continuous way to represent concepts, so that similar concepts are geometrically close. But "close" does not equal "logically related," and "statistical co-occurrence" does not equal "causal correlation."
Wittgenstein said something that resonates here: the meaning of language is its use. The Distributional Hypothesis captures part of this intuition — a word's meaning is indeed embodied in its use. But use is statistical, and is understanding also statistical? This is an unresolved question.
IX. From Word Vectors to Sentences: The Accumulation of Cost
Word2Vec produces static word vectors — each word corresponds to a fixed vector, regardless of what context it appears in.
The word "bank," in "I went to the bank to withdraw money" and "wildflowers grew on the river bank," has the same static word vector. This is one of its fundamental limitations.
ELMo (2018) and later BERT (2018) introduced contextualized word vectors — the same word has different vector representations in different contexts. This is a major advance. But it brings another cost: you no longer have a concise, offline-lookup word vector; you need to run the entire network every time.
ELMo and BERT: What are contextualized word vectors?
Static word vectors (like Word2Vec): each word has only one vector, regardless of where it appears. "Apple" whether referring to the fruit or the company, the vector is the same.
Contextualized word vectors (ELMo, BERT): the same word has different vectors in different sentences, because the entire sentence is fed into the network, and the word's representation is influenced by context.
- ELMo (2018, Allen AI): uses bidirectional LSTM to generate context-sensitive word vectors, used as features for downstream tasks
- BERT (2018, Google): uses Transformer Encoder for bidirectional language model pre-training, fine-tuned to downstream tasks
Cost: you can no longer look up a table; every inference requires running the full network, significantly increasing computation. This is the eternal trade-off between precision and efficiency.
A more fundamental problem is: the meaning of a sentence is not equal to the simple combination of word vectors.
"Cat bites dog" and "Dog bites cat" — if you average the word vectors, you get almost the same sentence vector — because the same three words are used. But these two sentences describe completely opposite events.
Word meanings can be encoded by vectors, but sentence meaning depends on structure — who is the subject, who is the object, the argument relations of the verb. Pure vector operations do not capture structure.
This problem drove the invention of the Transformer — using attention mechanisms to dynamically process relationships between words, rather than simply stacking them. But that is the story of Chapter 9.
X. A Small Pause
Let me sort things out.
From symbols to vectors — this is a genuine paradigm shift. It solved a core problem of symbolic AI: the representation of semantics. Concepts are no longer meaningless atoms; they have positions, distances, and directions in the vector space. Similar concepts are close to each other; relationships are encoded as directional offsets.
This brought real capabilities: semantic retrieval, analogical reasoning (of a certain form), semantic clustering, the foundation of transfer learning.
But it did not solve the reasoning problem, for three reasons:
First, it captures statistical regularities, not causal structure. If the corpus has bias, the vectors have bias. If the corpus has correlations, the vectors have correlations. But correlation is not causation; distribution is not truth.
Second, it lacks compositionality. Simple linear combinations of word vectors cannot capture the structural semantics of sentences. "Cat bites dog" and "Dog bites cat" are identical to a bag-of-words model — this is a fundamental defect.
Third, analogy equations look like reasoning, but are not reasoning. They are geometric parallel structures, not logical transitive derivations. When they fail (such as analogies with social biases), they silently give wrong answers, without any warning.
Vector representation is one of the prerequisites for reasoning, but it is not reasoning itself.
XI. And One Deeper Problem
The deep presupposition of the Distributional Hypothesis is: language can carry meaning, and meaning can be extracted from patterns of language use.
This is a presupposition that can be questioned.
John Searle's Chinese Room thought experiment (1980) is the most famous attack in this direction. Imagine: a person who does not understand Chinese at all is locked in a room, holding a thick rule book that tells him what Chinese character symbols to output given what Chinese character symbols he sees. From the outside, he appears to understand Chinese, able to answer Chinese questions — but he completely does not know the meaning of those symbols; he is merely mechanically executing rules.
Professor Pallas's Cat's Comment
This thought experiment is like a mirror, reflecting the awkward truth of symbolic manipulation: you can perfectly imitate understanding while understanding nothing at all. What word vector models do is, in a certain sense, very much like this Chinese Room — they extract extremely fine-grained statistical patterns from vast amounts of text, and these patterns produce correct behavior on many tasks. But do they "understand" the meaning of those words? This question has no simple answer, because we first need to define what "understanding" means.
But there is a more practical test: distribution shift. If you put the model outside its training distribution, let it handle combinations never seen in the training corpus, what will its behavior be? If its performance collapses, you have reason to suspect that it merely memorized the distribution, rather than truly understanding language.
This is the core question of Chapter 5. For now, keep this suspense in mind.
Vectors capture similarity, but not causality. In the next chapter, we will enter the geometry of high-dimensional spaces — the manifold hypothesis reveals why data is not randomly distributed.
Unresolved
Is the analogy equation
vec(King) - vec(Man) + vec(Woman) ≈ vec(Queen)evidence of reasoning, or a statistical coincidence? It holds for some analogies and fails for others — what does this inconsistency tell us?Where is the boundary of the Distributional Hypothesis? Are there meanings that cannot be learned from text distribution? Color? Pain? Bodily sensation?
Word vectors capture social biases — is this their defect, or their function? Do debiased word vectors also lose some real structure of the world?
If you train word2vec on purely random noise text, what would you get? What does this thought experiment illustrate?
Hands-On: Using Vector Arithmetic to Puncture the Illusion of Analogy
This chapter said an important thing: analogy equations look like reasoning, but they are only geometric parallel structures. You need to personally verify this distinction — not just understand it intellectually, but feel the moment it collapses.
You need access to a pre-trained word vector model. The simplest option: use Python's gensim library to load the word2vec model released by Google, or use fasttext pre-trained vectors.
Step 1: Verify That Famous Equation
Start with the most classic analogy:
Implement using the logic given in Section V of this chapter:
import numpy as np
# Assume model is an already-loaded gensim KeyedVectors object
# Example loading method:
# from gensim.models import KeyedVectors
# model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
def analogy_query(model, positive_word, minus_word, plus_word, topn=5):
"""
Perform vector analogy query: vec(positive_word) - vec(minus_word) + vec(plus_word)
model: gensim KeyedVectors object
Returns: list of nearest neighbor words and their cosine similarity scores
"""
# Compute the target vector: vec("king") - vec("man") + vec("woman")
target_vector = (model[positive_word]
- model[minus_word]
+ model[plus_word])
# Find words in the vocabulary with highest cosine similarity to the target vector
# gensim's similar_by_vector automatically excludes input words (controlled via negative parameter)
results = model.similar_by_vector(
target_vector,
topn=topn + 3 # take a few extra, to manually filter out input words
)
# Exclude positive_word, minus_word, plus_word themselves
exclude = {positive_word.lower(), minus_word.lower(), plus_word.lower()}
filtered = [(word, score) for word, score in results
if word.lower() not in exclude][:topn]
return filtered
# ── Run the classic analogy: king - man + woman ≈ ? ───────────────────────
results = analogy_query(model, "king", "man", "woman")
print("Analogy query: king - man + woman ≈ ?")
print("─" * 35)
for rank, (word, score) in enumerate(results, 1):
print(f" Rank {rank}: {word:15s} cosine similarity = {score:.4f}")You should get "queen," with cosine similarity close to 0.7 to 0.9.
Your first question: Does this result surprise you? Record your intuition: does this look "like reasoning" or "like arithmetic"? Before you answer, don't read ahead.
Step 2: Systematically Verify, Then Find Counterexamples
From the following four categories of analogy, pick 3 pairs from each and test sequentially:
Category 1: Gender analogies - man -> woman analogy applied to: king, doctor, professor, nurse, engineer…
Category 2: Capital relations - France -> Paris, analogy applied to: China, Japan, Germany, United States…
Category 3: Tense transformations - go -> went analogy applied to: run, swim, eat, think…
Category 4: Antonyms - good -> bad analogy applied to: big, hot, fast, happy…
For each test case, record: - What the expected answer is - What the actual top 5 nearest neighbors are - What the cosine similarity is
Your second question: Which category of analogy has the highest success rate? Which is the lowest? Can you speculate why — is it a problem with the training corpus, or is this kind of relationship fundamentally unsuitable for encoding via linear offsets?
Step 3: Personally Reproduce the Occupational Bias Experiment
Test the failure case described in Section VII of this chapter:
Doctor - Man + Woman ≈ ?
Then extend the test: - Engineer - Man + Woman ≈ ? - Nurse - Woman + Man ≈ ? - CEO - Man + Woman ≈ ? - Janitor - Woman + Man ≈ ?
Record each result.
Your third question: For word pairs where the output results show clear bias, what is your explanation? Are these biases bugs in the word vector system, or faithful reflections of the true statistical structure of the training corpus? If the latter, what does "debiasing" mean?
Step 4: Find the Geometric Conditions for Analogy Equations
Do a more precise test: when do analogy equations hold precisely, and when do they fail severely?
Construct the following experiment:
For a set of analogy pairs you choose, compute two quantities:
import numpy as np
def cosine_similarity(v1, v2):
"""Compute the cosine similarity between two vectors."""
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
def analogy_precision(model, analogies):
"""
Batch-measure analogy precision.
analogies: list, each item is (A, B, C, D), representing the analogical relationship A:B :: C:D.
Returns: detailed measurement results for each analogy.
"""
results = []
for (A, B, C, D) in analogies:
# Compute the predicted vector: vec(B) - vec(A) + vec(C)
predicted_vector = model[B] - model[A] + model[C]
# Get the entire vocabulary sorted by similarity (exclude input words)
exclude = {A.lower(), B.lower(), C.lower()}
neighbors = model.similar_by_vector(predicted_vector, topn=len(model.key_to_index))
# Filter out input words, obtaining a ranked word list
filtered_neighbors = [(word, score) for word, score in neighbors
if word.lower() not in exclude]
# Actual nearest neighbor rank: the position of D after sorting the vocabulary by similarity
rank_of_D = None
for idx, (word, score) in enumerate(filtered_neighbors, 1):
if word.lower() == D.lower():
rank_of_D = idx
break
# Compute offset vector consistency: cosine similarity between vec(B) - vec(A) and vec(D) - vec(C)
# This directly measures whether the "relationship direction" between the two word pairs is consistent
offset_AB = model[B] - model[A]
offset_CD = model[D] - model[C]
offset_consistency = cosine_similarity(offset_AB, offset_CD)
results.append({
"analogy": f"{A}:{B} :: {C}:{D}",
"top1_hit": rank_of_D == 1, # whether D appears in the top 1 (exact hit)
"top5_hit": rank_of_D is not None and rank_of_D <= 5, # whether D appears in the top 5
"rank_of_D": rank_of_D,
"offset_consistency": offset_consistency, # offset vector consistency (geometric-level measurement)
})
return results
# ── Example test ────────────────────────────────────────────────────
test_analogies = [
("man", "king", "woman", "queen"), # gender × royalty
("france", "paris", "japan", "tokyo"), # country × capital
("go", "went", "run", "ran"), # verb tense
("good", "bad", "big", "small"), # antonyms
("man", "doctor", "woman", "nurse"), # occupational bias case
]
precision_results = analogy_precision(model, test_analogies)
print(f"{'Analogy':30s} {'Exact Hit':^8s} {'Top5 Hit':^8s} {'Rank':^6s} {'Offset Consistency':^10s}")
print("─" * 70)
for r in precision_results:
print(f"{r['analogy']:30s} "
f"{'✓' if r['top1_hit'] else '✗':^8s} "
f"{'✓' if r['top5_hit'] else '✗':^8s} "
f"{str(r['rank_of_D']):^6s} "
f"{r['offset_consistency']:^10.4f}")Your fourth question (the core question): When an analogy fails, is the "offset vector consistency" score high or low? That is, does the geometric structure (same offset direction) hold, but the nearest neighbor retrieval fails? If so, is the failure in the geometry, or in the retrieval method? Which argument of Section VII does this illustrate?
Step 5: Construct an Example Where Cosine Similarity Lies
Cosine similarity measures direction, not magnitude. Find two words whose cosine similarity is high, but your intuition tells you their semantic gap is large — or conversely, cosine similarity is low, but you think they should be semantically close.
def find_counterintuitive_similarities(model, word, topn=20, low_threshold=0.3):
"""
For a given word W:
1. Find the topn words with highest cosine similarity, look for "counterintuitive" words
2. Find words with cosine similarity below low_threshold, check for semantically related but geometrically distant words
model: gensim KeyedVectors object
"""
print(f"=== Cosine similarity analysis for word '{word}' ===\n")
# Find topn words with highest cosine similarity
top_neighbors = model.most_similar(word, topn=topn)
print(f"Top {topn} words by cosine similarity (look for words that feel counterintuitive):")
for w, score in top_neighbors:
print(f" {w:20s} similarity = {score:.4f}")
print()
# Among words with lower cosine similarity, check for semantically related but geometrically distant words
# Method: directly compute similarity for a set of candidate words
candidate_words = ["science", "art", "mathematics", "philosophy",
"literature", "music", "history", "biology"]
print(f"Cosine similarity of candidate words (similarity below {low_threshold} but you think they are semantically related?):")
for candidate in candidate_words:
if candidate in model:
sim = model.similarity(word, candidate)
flag = " ← semantically related but distant?" if sim < low_threshold else ""
print(f" {candidate:20s} similarity = {sim:.4f}{flag}")
# ── Example run ────────────────────────────────────────────────────
find_counterintuitive_similarities(model, word="physics", topn=20, low_threshold=0.3)Your fifth question: What type of semantic relationships does cosine similarity fail to capture? How does this connect to Section VIII's "Upper Bound of the Distributional Hypothesis"?
Verification Criteria
After completing this exercise, you should have the following three things:
A table: all the analogies you tested, successes/failures, and your explanations
A bias case: a personally reproduced result that made you uncomfortable, and your position on that result
A counterintuitive cosine similarity case: a real crack between vector geometry and linguistic intuition
The third item is the most important. This crack is the distance between vector representation and true reasoning.
Further Reading
Mikolov et al. (2013). Efficient Estimation of Word Representations in Vector Space — the original word2vec paper, CBOW and Skip-gram architectures,
-> [arXiv:1301.3781]Mikolov et al. (2013). Distributed Representations of Words and Phrases and their Compositionality — negative sampling, phrase vectors and compositionality,
-> [arXiv:1310.4546]Fournier, Dupoux & Dunbar (2020). Analogies minus analogy test — a critical analysis of analogy testing, demonstrating flaws in standard evaluation,
-> [arXiv:2010.03446]Firth, J.R. (1957). A synopsis of linguistic theory 1930-55 — the philosophical starting point of the Distributional Hypothesis, "You shall know a word by the company it keeps"
Searle, J. (1980). Minds, Brains, and Programs — the Chinese Room thought experiment, a philosophical attack on whether symbolic manipulation can produce understanding
Bolukbasi et al. (2016). Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings — the classic empirical study of the word vector bias problem