2.5.1. 聚类统计的全量兴趣召回¶
在推荐系统的研究中,有一种被称为“搜索式兴趣模型” (Pi et al., 2020) 的方法已经证明了一个重要观点:与其将所有历史行为压缩到固定容量的向量中,不如在推理时根据目标物品动态地从历史行为中“搜索”相关信息。这种方法的核心思想是先用轻量级的方式从用户的超长行为序列中筛选出与当前目标相关的子序列,再对这个子序列进行精细建模。通过这种两阶段的搜索机制,模型能够有效处理长达数万条的行为序列。
然而,这类搜索式方法的计算复杂度对于需要处理数十亿候选物品的召回阶段来说仍然过高。Trinity (Yan et al., 2024) 的核心贡献在于将“搜索式”的兴趣建模思想成功地迁移到了召回阶段,通过引入一套基于聚类的统计框架来实现这一目标。
2.5.1.1. 兴趣遗忘问题¶
在理解Trinity的设计之前,我们需要先认识其试图解决的核心问题。在线学习框架下的召回模型倾向于拟合最近的训练样本,这意味着当某个兴趣主题的训练样本变得稀疏时,模型对该主题的记忆会逐渐衰退。Trinity将这种现象称为“兴趣遗忘”(Interest Amnesia)问题。
更具体地说,用户的多元兴趣、长尾兴趣和长期兴趣这三者之间存在相互依存的关系。长期行为记录能够揭示用户的多元兴趣全貌,因为短期行为往往被热门话题主导;而真正需要关注的多元兴趣实际上是那些尚未被充分推送的长尾主题,因为热门内容已经被现有召回器很好地覆盖;同时,判断用户是否真正对某个长尾主题感兴趣,也需要回溯长期行为来确认。
2.5.1.2. 聚类系统的构建¶
Trinity的基础是一套层次化的物品聚类系统。如 图2.5.1 所示,训练阶段采用向量量化(Vector Quantization) (van den Oord et al., 2018) 结构来学习物品的聚类归属。对于每个物品,系统首先从用户的长期行为序列中提取与该物品相关的历史交互,得到物品embedding \(\boldsymbol{x}\) 和用户embedding \(\boldsymbol{b}\)。同时,系统维护两级可学习的聚类中心:粗粒度的主聚类 \(\{\boldsymbol{e}^1_j\}_{j=1}^J\) 和细粒度的次级聚类 \(\{\boldsymbol{e}^2_k\}_{k=1}^K\),其中 \(J=128\),\(K=1024\)。
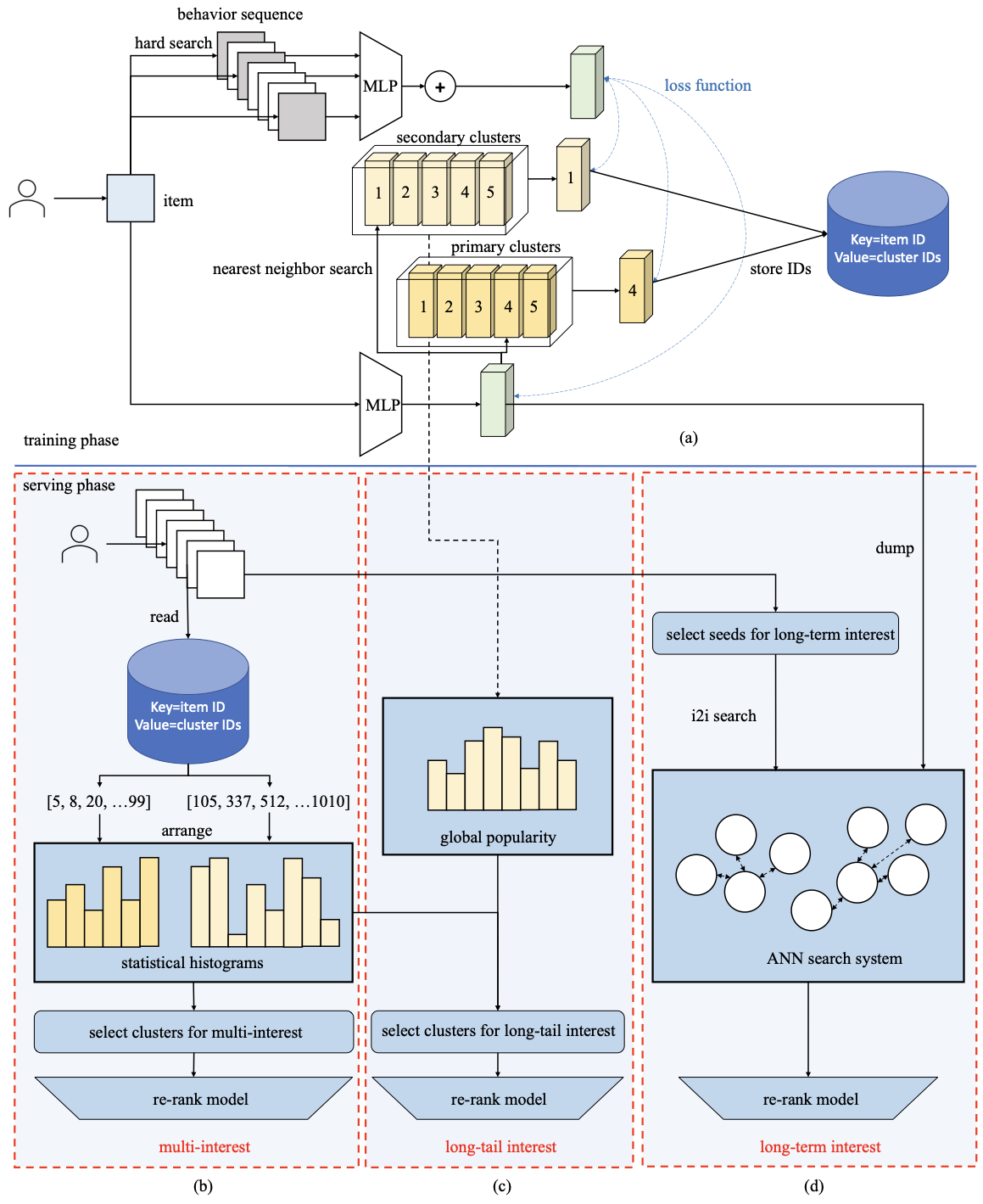
图2.5.1 Trinity框架整体结构。训练阶段(a)通过VQ-VAE构建层次化聚类系统;服务阶段基于用户行为的统计直方图实现多元兴趣召回(b)、长尾兴趣召回(c)和长期兴趣召回(d)。¶
每个物品通过最近邻搜索被分配到对应的聚类:
训练损失函数同时优化用户-物品匹配和用户-聚类匹配:
其中 \(\sigma(\cdot)\) 是sigmoid函数,\(y=1\) 表示用户完成观看、产生互动(点赞/分享/关注/评论)或观看时长超过10秒。聚类中心的更新采用指数移动平均机制(Exponential Moving Average, EMA) (van den Oord et al., 2018) :不直接通过梯度更新聚类中心,而是用其所属物品embedding的加权平均来更新,这样聚类中心能够平滑地适应物品分布的变化。
这套聚类系统的关键特性在于其时间无偏性。由于训练过程中同时使用了用户的长期行为序列,近期物品和早期物品被同等对待,不会出现传统在线学习中对近期样本的过度偏向。
2.5.1.3. 基于直方图的兴趣召回¶
有了物品到聚类的映射关系,Trinity就可以将任意长度的用户行为序列转换为固定维度的统计直方图。对于用户的长期行为序列(长度可达2500),系统从键值存储中读取每个物品的聚类ID,然后统计每个聚类的行为计数,形成主聚类直方图 \(\boldsymbol{h}^1 = [h^1_1, h^1_2, \ldots, h^1_J]\) 和次级聚类直方图 \(\boldsymbol{h}^2 = [h^2_1, h^2_2, \ldots, h^2_K]\)。
将直方图按计数降序排列后,用户的兴趣分布一目了然。例如,若排序后的直方图为 \([50, 20, 20, 4, 2, 0, 0, 0]\),对应的聚类索引为 \([10, 33, 100, 91, 62, 21, 5, 83]\),则聚类10是用户的主要兴趣,聚类33和100构成需要关注的多元兴趣,聚类91和62是探索性兴趣,其余聚类可以忽略。
基于这种直方图表示,Trinity设计了三个互补的召回器。第一个是多元兴趣召回器(Trinity-M),其核心策略是选择那些计数显著但可能被主流召回器忽略的聚类。为了保证主题多样性,系统限制每个主聚类下最多选择一个次级聚类,起到分散化的作用。这种设计确保了召回结果不会被头部兴趣主导,从而唤醒那些被“遗忘”的兴趣主题。
第二个是长尾兴趣召回器(Trinity-LT),它需要首先识别哪些聚类属于全局长尾主题。Trinity采用流式频率估计方法来追踪每个聚类的出现间隔:
其中 \(A[\mathcal{H}(c_k)]\) 记录聚类 \(c_k\) 的上次出现时间戳,\(B[\mathcal{H}(c_k)]\) 是出现间隔的移动平均。出现间隔大的聚类代表长尾主题。当用户在这些长尾聚类上有显著的行为计数时,说明该用户是这类小众内容的真正受众,系统会增强对这些内容的推送。
第三个是长期兴趣召回器(Trinity-L),它利用训练得到的物品embedding构建物品到物品(Item-to-Item)的检索系统。系统首先通过一个轻量级的双塔模型从用户的长期行为中选择种子物品,然后基于Trinity embedding的相似度检索与种子物品相关的其他物品。由于Trinity embedding本身就编码了长期行为信息,因此能够有效召回与用户历史偏好相关的内容。
2.5.1.4. 与多向量方法的对比¶
Trinity与MIND等多向量方法在目标上有相似之处,都试图捕捉用户的多元兴趣,但实现路径截然不同。多向量方法(如MIND的多个用户表示头)通过在线学习框架训练多个用户embedding,每个embedding负责捕捉一类兴趣。然而这种方法存在几个问题:首先,不同的头可能重复检索相同的热门内容,导致计算效率随头数增加而下降;其次,每个头的语义含义不够明确,难以进行针对性的策略调整;最后,模型无法灵活地扩展到长尾兴趣或长期兴趣建模。
相比之下,Trinity将物品排他性地分配到聚类中,增加关注的兴趣主题只会带来线性的额外开销。同时,每个聚类具有明确的语义含义(如教育、旅游、科技等),便于理解和调控。更重要的是,基于统计直方图的方法天然不会“遗忘”任何兴趣主题,因为只要用户历史中存在相关行为,对应聚类的计数就不会为零。