4.2. 基于个性化的重排¶
上一节我们探讨了基于贪心策略的重排序方法。这些方法通过显式定义多样性、相关性或覆盖度的优化目标,在初始排序列表上进行局部调整。它们计算效率高且可解释性强,但在处理复杂的物品间相互影响和深度个性化方面存在局限:目标函数往往需要手工设计,难以捕捉高阶、非线性的交互模式;同时,将用户个性化信息深度融入列表级优化也颇具挑战。
接下来将介绍两个经典的个性化重排模型:PRM(Personalized Re-Ranking Model)和PRS(Permutation Retrieve System)。
4.2.1. Transformer个性化重排模型¶
PRM (Personalized Re-Ranking Model) (Pei et al., 2019) 的提出,标志着重排序技术从基于规则/启发式向数据驱动、端到端学习的重要转变。其核心思想是:利用强大的序列建模能力(Transformer)自动学习列表中物品间复杂的相互影响,并将细粒度的用户个性化信息深度融入整个重排序过程,通过最大化列表级效用目标(如点击率)进行全局优化。 PRM不再依赖预设的多样性公式,而是让模型直接从数据中学习最优的物品组合方式,同时精准反映用户的独特偏好。下图展示了PRM的整体架构:
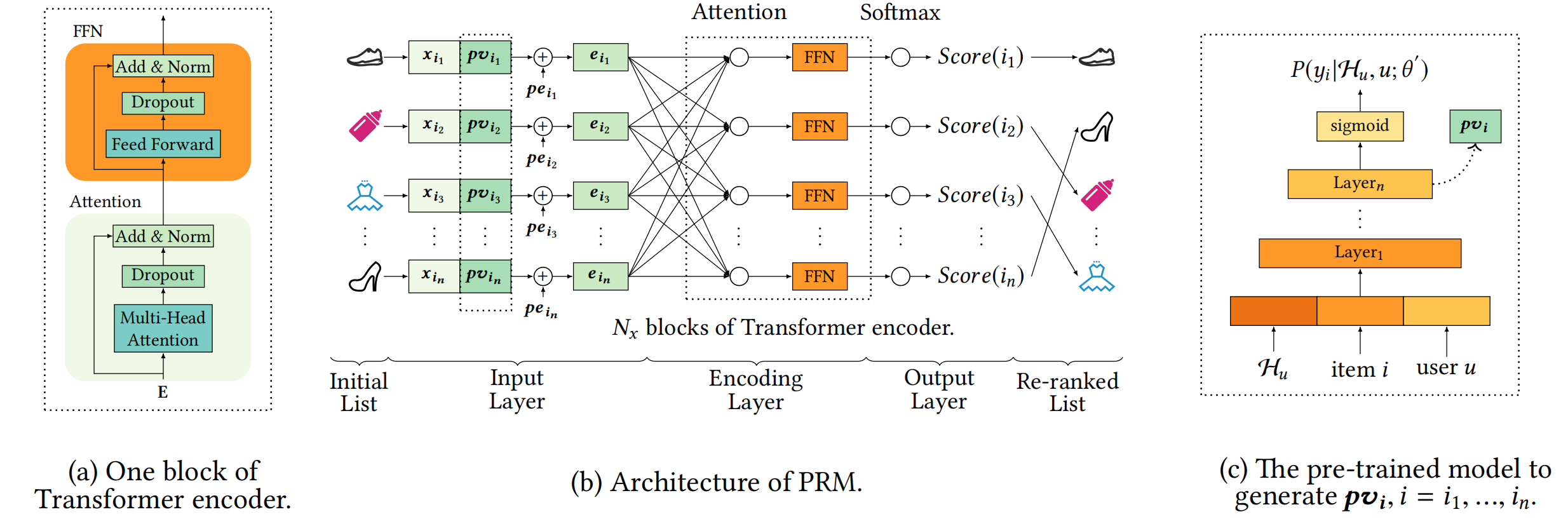
图4.2.1 PRM模型架构¶
输入层
输入层的核心任务是为初始列表 \(S = [i_1, i_2, ..., i_n]\) 中的每个物品 \(i_j\) 准备一个信息丰富且适合后续处理的初始表示。这个表示需要包含以下两个至关重要的方面。
物品自身特征 (\(X\)): 例如物品ID嵌入、类别、标签、统计特征等基础信息。
用户对该物品的个性化偏好 (\(PV\)): 这是PRM实现个性化重排序的关键所在。它编码了用户\(u\)与物品\(i_j\)之间的互动关系和偏好程度。PV 的生成是其核心创新点,我们将在后面详细探讨。
PRM采用了一个直观且有效的方法:将物品的原始特征向量 \(x_j\) 与其对应的个性化向量 \(pv_j\) 拼接(Concatenate)起来,形成一个更全面的基础表示 \([x_j; pv_j]\)。
然而,仅有个性化和物品特征还不够。基础排序模型给出的初始列表 \(S = [i_1, i_2, ..., i_n]\) 本身包含潜在的序列信息(例如,排名靠前的物品可能相关性更高)。为了利用这一信息,PRM引入了标准的位置嵌入 (Positional Embedding, PE),为列表中的每个位置(第1位、第2位…第n位)赋予一个可学习的向量表示。最终,每个物品进入编码层之前的输入表示\(E\)是其融合特征与位置信息的叠加:
这个组合结果通常会经过一个简单的前馈网络(线性变换)进行维度调整,以适应后续Transformer编码器的输入要求。
编码层
输入层提供了带有个性化信息和位置信息的物品序列。编码层的核心目标是利用 Transformer 架构的序列建模能力,使列表中的所有物品能够相互关联,从而捕捉它们之间复杂的、高阶的相互影响。这对于重排序至关重要,因为:
用户是否点击列表中的第 j 个物品,很可能受到第 k 个(甚至更远)物品的显著影响(例如,它们是替代品、互补品,或者提供了多样性)。
这种影响往往是长距离的,不受物品在列表中初始物理位置的限制。
Transformer的核心机制是自注意力机制 (Self-Attention)。它使得序列中每个物品可以关注序列中的所有其他物品(包括它自己)。其工作原理是计算每个物品的查询向量(Query)与其他物品的键向量(Key)的相似度,得到一个注意力权重。这个权重决定了在更新当前物品表示时,应该聚合(Value) 多少来自其他物品的信息。公式 \(Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d}}) V\) 描述了这个加权聚合过程。
为了更全面、更鲁棒地捕捉列表中物品间复杂的相互影响,PRM采用了多头注意力机制,这些多头注意力模块被组织在标准的 Transformer 编码器块(Block) 中,每个块包含一个多头自注意力层和一个前馈神经网络层。PRM通过堆叠多层编码器,使模型能够在初始交互表示的基础上,逐层提炼更复杂、更高阶的物品间依赖关系。最终,编码层输出每个物品的高级表示\(F^{N_x}\),它融合了物品自身特征、用户个性化偏好以及在整个列表上下文中的交互信息。
输出层
PRM采用了一个轻量级但有效的输出结构:对每个物品的高级表示 \(F^{N_x}\) 应用一个线性变换(\(W^f \cdot F^{N_x} + b^f\)),将其映射为一个标量分数(或称 logit)。这个分数初步反映了该物品在重排序后的列表中的相对价值。将列表中所有物品的标量分数输入一个 Softmax 函数。Softmax 在此扮演以下两个关键角色。
归一化: 将所有分数转换为一个概率分布 \(P(y_i | X, PV; \hat{\theta})\),其中 \(y_i\) 表示物品 \(i\) 在最终列表中被认为是最合适(或最可能被点击)的概率。所有物品的概率之和为1。
隐含相对关系建模: Softmax 函数的特性使得每个物品的最终概率不仅取决于它自身的分数,也取决于它与列表中所有其他物品分数的相对比较。这天然地符合重排序需要评估物品间相对重要性的需求
个性化向量 (PV) 的生成
回顾整个流程,个性化向量 \(PV\) 是PRM区别于普通重排序模型、实现真正“个性化”的关键所在。那么,\(PV\) 从何而来?PRM采用了一个巧妙且实用的策略:利用预训练的点击率预估模型来生成PV。
预训练模型的作用: 这个模型在海量的用户历史行为数据(用户ID、物品ID、上下文特征、历史点击/转化日志)上进行训练。它的核心任务是学习预测:给定用户 \(u\) 及其行为历史 \(H_u\),用户点击某个候选物品 \(i\) 的概率 \(P(y_i | H_u, u; \theta')\)。
提取个性化向量: PRM 并不直接使用预训练模型预测的点击概率本身。相反,它提取该模型在输出最终点击概率(通常经过Sigmoid激活)之前的那个隐藏层的激活值。这个隐藏层的向量,蕴含了预训练模型学习到的、关于“用户 \(u\) 对物品 \(i\) 偏好程度”的丰富、抽象的信息,将其作为物品 \(i\) 相对于用户 \(u\) 的个性化向量 \(pv_i\)。
输入PRM: 对于初始列表 \(S = [i_1, i_2, ..., i_n]\) 中的每个物品 \(i_j\),都通过上述预训练模型计算出其对应的 \(pv_j\),然后作为关键输入送入PRM的输入层。
PRM核心代码如下:
# 模型输入层
input_layer_dict = build_input_layer(feature_columns)
# 用户侧Embedding:将用户相关特征的embedding拼接为一个向量,形状为 [B, D]
user_part_embedding = concat_group_embedding(group_embedding_feature_dict, 'user_part') # BxD
# 将用户向量扩展到序列维度,使每个时间步(或位置)都携带同一用户上下文
# tf.expand_dims(x, axis=1):在第1维增加一个长度为1的维度 -> [B, 1, D]
# tf.tile(..., [1, max_seq_len, 1]):沿序列维复制 max_seq_len 次 -> [B, max_len, D]
user_part_embedding = tf.keras.layers.Lambda(
lambda x: tf.tile(tf.expand_dims(x, axis=1), [1, max_seq_len, 1])
)(user_part_embedding) # [B, max_len, D]
# 物品侧Embedding:拼接序列中的物品特征,形成每个位置的物品表示,形状为 [B, max_len, K]
item_part_embedding = concat_group_embedding(
group_embedding_feature_dict, 'item_part', axis=-1, flatten=False
) # Bxmax_seq_lenxK
# 用户对item的个性化Embedding,Item Embedding,形状均为 [B, max_len, D]
pv_embeddings = input_layer_dict['pv_emb'] # Bxmax_seq_lenxD
item_embeddings = input_layer_dict['item_emb'] # Bxmax_seq_lenxD
# 页面级序列表示:将用户上下文、物品侧特征、用户对item的个性化Embedding、Item Embedding拼接
page_embedding = concat_func(
[user_part_embedding, item_part_embedding, pv_embeddings, item_embeddings],
axis=-1
) # [B, max_len, dim]
# 位置编码:为每个时间步(位置)加入位置信息,帮助 Transformer 捕捉顺序关系
position_embedding = PositionEncodingLayer(
dims=feature_columns[0].emb_dim,
max_len=max_seq_len,
trainable=pos_emb_trainable,
initializer='glorot_uniform'
)(page_embedding)
# 将内容编码与位置编码相加,形成 Transformer 的最终输入
enc_inputs = add_func([page_embedding, position_embedding])
# Transformer 编码层堆叠:
for _ in range(transformer_blocks):
enc_inputs = TransformerEncoder(
intermediate_dim,
nums_head,
dropout_rate,
activation="relu",
normalize_first=True,
is_residual=True
)(enc_inputs)
# 打分头:对序列中所有位置都映射成一个概率
enc_output = tf.keras.layers.Dense(intermediate_dim, activation='tanh')(enc_inputs)
enc_output = tf.keras.layers.Dense(1)(enc_output)
flat = tf.keras.layers.Flatten()(enc_output)
score_output = tf.keras.layers.Activation(activation='softmax')(flat)
代码实践
from funrec import run_experiment
run_experiment('prm')
+---------+-------------+-----------+-------------+-----------+--------+
| map@5 | new_map@5 | new_p@5 | old_map@5 | old_p@5 | p@5 |
+=========+=============+===========+=============+===========+========+
| 0.2207 | 0.2207 | 0.0926 | 0.2824 | 0.1196 | 0.0926 |
+---------+-------------+-----------+-------------+-----------+--------+
4.2.2. 基于排列组合的重排模型¶
虽然PRM通过Transformer架构实现了端到端的个性化重排序,但它仍然存在一个根本性的局限:缺乏对排列组合影响的深度理解。 想象这样一个场景:用户面对商品列表 [A, B, C] 时毫无购买欲望,但当看到 [B, A, C] 这个排列时却购买了商品A。这种现象被称为 排列变异影响 (Permutation-Variant Influence)。一个可能的解释是:将价格较高的商品B放在前面,会让用户觉得商品A相对便宜,从而激发购买欲望。
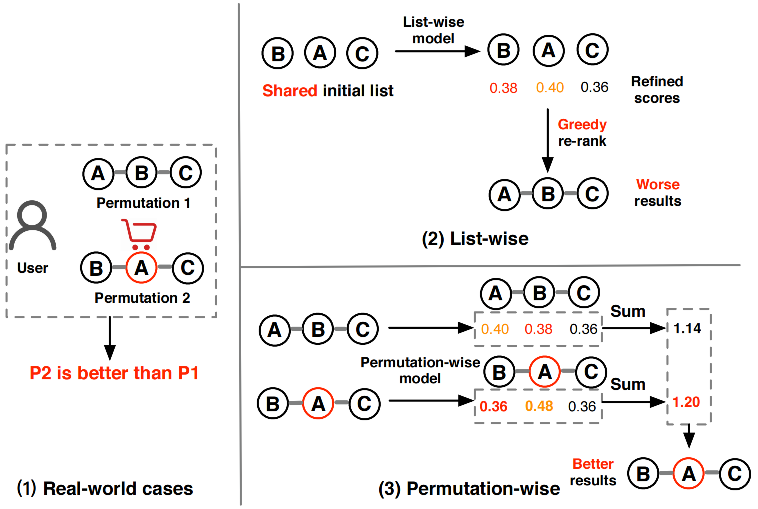
图4.2.2 排列变异影响¶
这个观察引出了一个重要问题:传统的重排序方法(包括PRM)主要关注单个物品的分数优化,却忽略了物品排列顺序本身对用户行为的影响。
PRS (Feng et al., 2021) 的设计思路是:评估所有可能的物品排列组合,并选择其中用户体验最佳的那一个。对于包含n个物品的列表,所有可能的排列数量是n!,这在计算上是不可行的。因此,PRS提出了以下两阶段的解决方案。
PMatch阶段:通过搜索算法快速筛选出少数几个候选排列
PRank阶段:使用神经网络模型评估这些候选排列的质量,选出最优解
这种设计既保证了计算效率,又能够捕捉到排列组合对用户体验的影响。
PRS整体架构
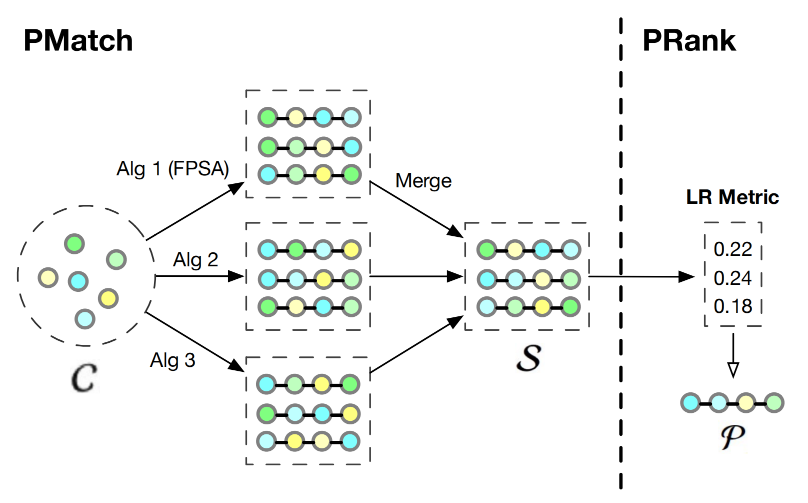
图4.2.3 PRS框架整体架构¶
4.2.2.1. PMatch阶段:候选排列生成¶
PMatch (Permutation-Matching) 阶段的目标是从指数级的排列空间中,高效地识别出候选排列。这个阶段采用了一种名为FPSA (Fast Permutation Searching Algorithm) 的算法,它结合了beam search和两个用户行为预测模型。
离线训练:双模型预测体系
PMatch阶段需要以下两个point-wise预测模型的支持。
CTR模型:预测用户点击某个物品的概率 \(P_{CTR}(i|u)\)
Next模型:预测用户在浏览完当前物品后继续浏览下一个物品的概率 \(P_{Next}(i|u)\)
Next模型的引入反映了用户浏览行为的连续性特点:某个物品不仅要能吸引用户点击,还要能够引导用户继续浏览列表中的后续内容。这两个模型都采用标准的point-wise建模方式:
其中 \(x_u\) 和 \(x_i\) 分别表示用户和物品的特征向量,\(\sigma\) 是sigmoid激活函数。两个模型都使用交叉熵损失进行训练。
在线服务:FPSA算法
FPSA算法的核心创新在于将用户的浏览行为建模为一个序列决策过程。传统的重排序方法往往独立地评估每个物品,而FPSA认识到:物品在序列中的价值不仅取决于自身特征,更取决于它在整个浏览路径中的作用。
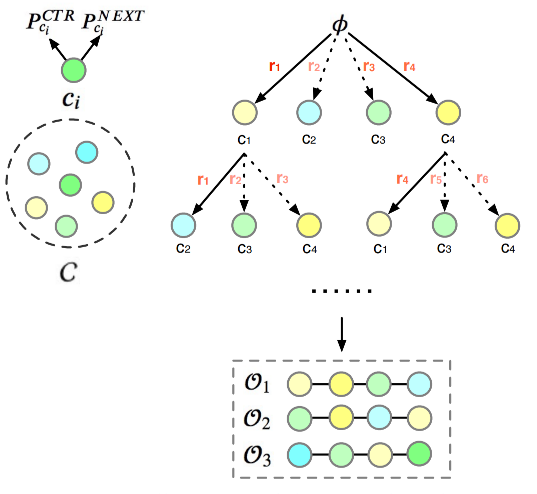
图4.2.4 FPSA结构图¶
上图展示了FPSA算法在整个PRS框架中的位置和核心组件,主要包含以下几个部分。
输入处理:算法接收来自ranking阶段的候选物品集合C,每个物品都有丰富的特征表示
双模型预测体系,包含两类预测模型:
CTR模型:预测每个物品的点击概率 \(P^{CTR}_i\)
Next模型:预测用户浏览完物品i后继续浏览的概率 \(P^{NEXT}_i\)
Beam Search核心:通过树状搜索逐步构建候选排列,每一步都基于奖励函数进行剪枝
奖励计算机制:融合rPV和rIPV两个指标,平衡浏览深度和点击收益
rPV (Page View Reward):衡量排列能够带来的总浏览深度,鼓励选择那些能引导用户深度浏览的物品组合
rIPV (Item Page View Reward):衡量排列中物品被点击的总概率,确保排列具有足够的商业价值
FPSA核心代码如下
def fpsa_algorithm(items, ctr_scores, next_scores, beam_size=5, max_length=10, alpha=0.5, beta=0.5):
"""
Fast Permutation Searching Algorithm (根据Algorithm 1实现)
Args:
items: 候选物品列表 (对应Algorithm 1的Input ranking list C)
ctr_scores: 每个物品的CTR分数字典 (对应P^CTR)
next_scores: 每个物品的Next分数字典 (对应P^NEXT)
beam_size: beam search的大小 (对应Beam size integer k)
max_length: 输出序列的最大长度 (对应Output length n)
alpha, beta: 融合系数 (对应Fusion coefficient float $\alpha, \beta$)
Returns:
候选排列集合 (对应Output: Candidate list set S)
"""
# 候选序列集合 S:每个元素是一个排列(元组),初始为“空序列”占位
S = [()]
# 奖励字典 R:记录每个候选排列的估计奖励,用于排序与截断
R = {}
# 逐步扩展排列长度,从 1 到 max_length(每次在尾部追加一个物品)
for i in range(1, max_length + 1):
# 当前步的候选快照(上一轮的前 k 个),作为本轮的扩展基准
St = S.copy()
# 重置本轮的候选与奖励(只保留当前轮生成的候选)
S = []
R = {}
# 遍历每个已有的部分排列 O,尝试将未出现的物品 ci 追加到末尾
for O in St:
for ci in items:
if ci not in O:
# 生成新排列 Ot:在 O 的基础上追加一个物品 ci
Ot = O + (ci,)
# 计算该排列的估计奖励:融合 CTR(点击倾向)与 NEXT(序列连贯性)两种信号
r = calculate_estimated_reward(Ot, ctr_scores, next_scores, alpha, beta)
# 记录奖励并加入候选集合,稍后按奖励进行 Beam 截断
R[Ot] = r
S.append(Ot)
# Beam Search 截断:按奖励从高到低排序,仅保留前 beam_size 个候选
S = sorted(S, key=lambda x: R[x], reverse=True)[:beam_size]
# 返回最终的候选序列集合(长度不超过 beam_size 的最优排列)
return S
def calculate_estimated_reward(O, ctr_scores, next_scores, alpha, beta):
"""
计算估计奖励 (对应Algorithm 1的第19-28行 Calculate-Estimated-Reward函数)
Args:
O: 当前排列序列
ctr_scores: CTR分数字典
next_scores: Next分数字典
alpha, beta: 融合系数
Returns:
估计奖励值
"""
# 若当前序列为空,则无曝光与点击,奖励为 0
if not O:
return 0.0
# r_pv:最终页面曝光概率(序列完整浏览的概率),初始化为 1
r_pv = 1.0
# r_ipv:期望点击次数(或累计点击指标),初始化为 0
r_ipv = 0.0
# p_expose:当前位置的曝光链概率(上一位置是否继续浏览的概率)
p_expose = 1.0
# 遍历序列中的每个物品 ci,累计曝光与点击指标
for ci in O:
# p_ctr_ci:该位置物品的点击概率;p_next_ci:继续浏览到下一个位置的概率
p_ctr_ci = ctr_scores[ci]
p_next_ci = next_scores[ci]
# 累加期望点击:当前曝光概率 * 当前物品的点击概率
r_ipv = r_ipv + p_expose * p_ctr_ci
# 更新下一位置的曝光链:乘以继续浏览概率
p_expose *= p_next_ci
# 最终页面曝光概率为链式乘积后的结果
r_pv = p_expose
# 线性融合:alpha 权重控制曝光目标(PV),beta 权重控制点击目标(IPV)
r_sum = alpha * r_pv + beta * r_ipv
return r_sum
算法的关键特点:
rPV 表示用户浏览到列表末尾的概率,通过不断乘以“继续浏览下一个”的概率计算得到
rIPV 表示整个排列的预期点击数,通过累加每个位置被曝光且被点击的概率计算得到
曝光概率递减 模拟了用户浏览行为:随着位置后移,物品被看到的概率逐渐降低
4.2.2.2. PRank阶段:排列评估¶
PRank (Permutation-Ranking) 阶段接收PMatch生成的候选排列,使用神经网络模型DPWN (Deep Permutation-Wise Network) 来评估每个排列的质量。
DPWN模型架构
DPWN的设计理念是:排列中每个物品的价值不仅取决于它自身的特征,更取决于它在整个序列上下文中的位置和作用。为了捕捉这种复杂的序列依赖关系,DPWN采用了Bi-LSTM架构:
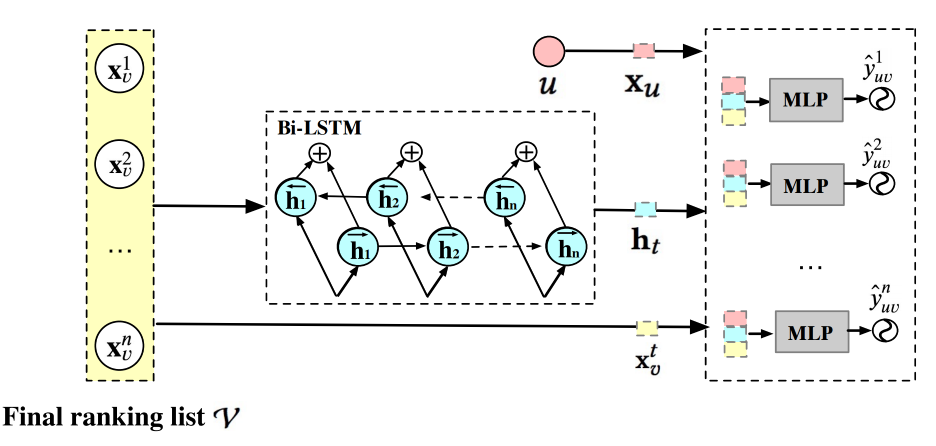
图4.2.5 DPWN模型架构¶
模型结构介绍
序列编码层:对于输入序列中的第t个物品,DPWN使用双向LSTM计算其上下文表示:
其中 \(x_{v_t}\) 是第t个物品的特征向量,\(h_t\) 是融合了前向和后向信息的隐状态。
特征融合层:将序列表示与用户特征和物品特征进行融合:
其中 \(x_u\) 是用户特征向量。
预测层:通过多层感知机预测每个位置的点击概率:
List Reward (LR) 计算
PRank阶段的核心评估指标是List Reward,它被定义为排列中所有物品预测点击概率的总和:
这个简单而有效的指标反映了整个排列的预期收益。在线服务时,PRank会计算每个候选排列的LR值,并选择LR最高的排列作为最终输出。