3.1. 记忆与泛化¶
在构建推荐模型时,我们常常追求两个看似矛盾的目标:记忆(Memorization)与泛化(Generalization)。
记忆能力,指的是模型能够学习并记住那些在历史数据中频繁共同出现的特征组合。例如,模型记住“买了A的用户,通常也会买B”。这种能力可以精准地捕捉显性、高频的关联,为用户提供与他们历史行为高度相关的推荐。
泛化能力,就是模型能学到特征间的深层关系,处理训练时很少见到的特征组合。举个例子,模型发现“物品A和物品C都是同一类的,用户喜欢这类东西”,那就可以给喜欢A的用户推荐C,哪怕用户以前没见过C。这能让推荐更丰富一些。
怎么让一个模型同时做好这两件事呢?这确实不容易。2016年Google提出的Wide & Deep模型给了一个不错的思路。这个模型的想法很直接:既然需要两种能力,那就设计两个部分,然后让它们一起训练,通过 联合训练(Joint Training) 的方式配合工作。
模型的设计思路是把结构分成两块,各自负责不同的事情:
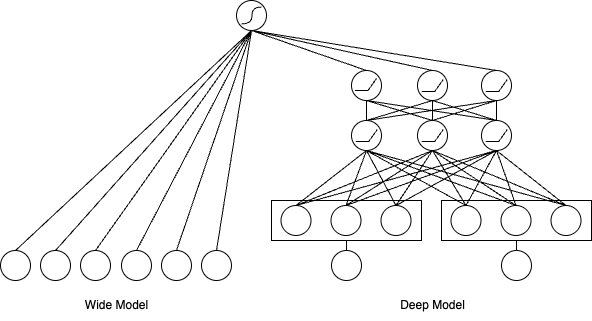
图3.1.1 Wide & Deep 模型结构图¶
记忆的捷径:Wide部分
Wide部分本质上是一个广义线性模型,比如逻辑回归。它的优势在于结构简单、可解释更强,并且能高效地“记忆”那些显而易见的关联规则。其数学表达形式如下:
其中,y是预测值,\(\boldsymbol{w}\) 是模型权重,\(\boldsymbol{x}\)是特征向量,b是偏置项。
Wide部分的关键在于其输入的特征向量\(\boldsymbol{x}\)。它不仅包含原始特征,更重要的是包含了大量人工设计的交叉特征(Cross-product
Features)。交叉特征可以将多个独立的特征组合成一个新的特征,用于捕捉特定的共现模式。例如,在应用商店的推荐场景中,我们可以创建一个交叉特征AND(installed_app=photo_editor, impression_app=filter_pack),它代表用户已经安装了“照片编辑器”应用,并且现在看到了“滤镜包”应用的推荐。
通过这种方式,Wide部分能够直接、快速地学习到“照片编辑器用户对滤镜包应用有更高的安装意愿”这类强关联规则,正是“记忆能力”的直接体现。
核心代码
Wide部分的关键在于处理交叉特征。对于每一对需要交叉的特征,模型会创建一个专门的权重来记住它们的共现模式:
# 遍历所有需要交叉的特征对
for i in range(len(cross_feature_columns)):
for j in range(i + 1, len(cross_feature_columns)):
fc_i = cross_feature_columns[i]
fc_j = cross_feature_columns[j]
# 获取两个特征的输入
feat_i = input_layer_dict[fc_i.name] # [B, 1]
feat_j = input_layer_dict[fc_j.name] # [B, 1]
# 为每个特征对创建独立的权重表
cross_vocab_size = fc_i.vocab_size * fc_j.vocab_size
cross_embedding = Embedding(
input_dim=cross_vocab_size,
output_dim=1, # 标量权重,直接记住这对特征的影响
name=f"cross_{fc_i.name}_{fc_j.name}"
)
# 将特征对组合成单一索引并查找权重
combined_index = feat_i * fc_j.vocab_size + feat_j
cross_weight = cross_embedding(combined_index) # 查表得到这对特征的权重
cross_weights.append(cross_weight)
# 所有交叉特征权重相加
cross_logits = tf.add_n(cross_weights)
这段代码的设计体现了Wide部分的本质:为每个特征组合分配一个独立的权重,通过查表操作直接“记住”历史数据中的共现模式。
学习复杂关系:Deep部分
Deep部分是一个标准的前馈神经网络(DNN),它负责模型的“泛化能力”。与Wide部分依赖人工特征工程不同,Deep部分可以自动学习特征之间的高阶、非线性关系。
它的工作流程如下:首先,对于那些高维稀疏的类别特征(如用户ID、物品ID),通过一个嵌入层(Embedding Layer)将它们映射为低维、稠密的向量。这些嵌入向量能够捕捉到特征的潜在语义信息,是实现泛化的基础。例如,《流浪地球》和《三体》的电影ID在嵌入空间中的距离,可能会比《流浪地球》和《熊出没》更近。
随后,这些嵌入向量与其他数值特征拼接在一起,被送入多层神经网络中进行前向传播:
其中,\(a^{(l)}\)是第\(l\)层的激活值,\(W^{(l)}\)和\(b^{(l)}\)是该层的权重和偏置,\(f\)是激活函数(如ReLU)。通过逐层抽象,DNN能够发掘出数据中隐藏的复杂模式,从而对未曾见过的特征组合也能做出合理的预测。
核心代码
Deep部分的实现分为两个关键步骤:首先将类别特征映射为稠密向量,然后通过多层神经网络学习高阶特征交互:
# 1. 特征嵌入:将稀疏的类别特征转换为稠密向量
group_feature_dict = {}
for group_name, _ in group_embedding_feature_dict.items():
group_feature_dict[group_name] = concat_group_embedding(
group_embedding_feature_dict, group_name, axis=1, flatten=True
) # B x (N * D) - 拼接所有特征的嵌入向量
# 2. 深度神经网络:逐层学习特征的非线性组合
deep_logits = []
for group_name, group_feature in group_feature_dict.items():
# 构建多层神经网络
deep_out = DNNs(
units=dnn_units, # 例如 [64, 32]
activation="relu", # ReLU激活函数
dropout_rate=dnn_dropout_rate
)(group_feature)
# 输出层:将深度特征映射为预测分数
deep_logit = tf.keras.layers.Dense(1, activation=None)(deep_out)
deep_logits.append(deep_logit)
这种设计使得模型能够自动学习特征的语义表示,例如将“物品A”相关的特征映射到向量空间的相近位置,从而实现对未见过的特征组合的泛化预测。
两者结合
Wide & Deep模型通过联合训练,将两部分的输出结合起来进行最终的预测。其预测概率如下:
在这里,\(\sigma\) 是Sigmoid函数,\([\boldsymbol{x}, \phi(\boldsymbol{x})]\)代表Wide部分的输入(包含原始特征和交叉特征),\(a^{(lf)}\)是Deep部分最后一层的输出向量,\(\boldsymbol{w}_{wide}\),\(\boldsymbol{w}_{deep}\)和\(b\)是最终预测层的权重和偏置。模型的梯度在反向传播时会同时更新Wide和Deep两部分的所有参数。
一个值得注意的工程细节是,由于两部分处理的特征类型不同,它们通常会采用不同的优化器。
Wide部分的输入特征非常稀疏,常使用带L1正则化的FTRL (Ferreira and Soares, 2025) 等优化器。L1正则化可以产生稀疏的权重,相当于自动进行特征选择,让模型只“记住”重要的规则。
Deep部分的参数是稠密的,更适合使用像AdaGrad (Duchi et al., 2011) 或Adam (Kingma and Ba, 2014) 这样的优化器。
核心代码
联合训练的核心是将Wide和Deep两部分的输出进行融合:
# Wide部分:线性特征 + 交叉特征
linear_logit = get_linear_logits(input_layer_dict, feature_columns)
cross_logit = get_cross_logits(input_layer_dict, feature_columns)
# Deep部分:多个特征组的深度网络输出
deep_logits = []
for group_name, group_feature in group_feature_dict.items():
deep_out = DNNs(units=dnn_units, activation="relu", dropout_rate=dnn_dropout_rate)(
group_feature
)
deep_logit = tf.keras.layers.Dense(1, activation=None)(deep_out)
deep_logits.append(deep_logit)
# 联合训练:将Wide和Deep的输出相加
wide_deep_logits = add_tensor_func(deep_logits + [linear_logit, cross_logit])
# 最终预测:通过sigmoid函数输出点击概率
output = tf.keras.layers.Dense(1, activation="sigmoid")(wide_deep_logits)
Wide & Deep模型的意义不只是提供了一个新的网络结构,更重要的是给出了一个思路:怎么把记忆能力和泛化能力结合起来。该模型不仅成为了许多推荐业务的基线模型,更为后续精排模型的发展提供了重要的参考。
代码实践
from funrec import run_experiment
run_experiment('wide_deep')
+--------+--------+------------+
| auc | gauc | val_user |
+========+========+============+
| 0.5902 | 0.5724 | 928 |
+--------+--------+------------+