llm-algo-leetcode | 大模型算法与系统教程
Notebook-first tutorial for LLM algorithms and systems.
面向大模型算法与系统的 Notebook-first 教程。
WARNING
🧪 Beta公测版本提示:教程主体代码与算子已基本构建完成,正在持续优化文档细节与补充注释。欢迎大家提交 Issue 反馈问题或贡献 PR!
A practical tutorial with theory, walkthroughs, test cases, and solutions.
中文版 (Chinese) | English Version
中文版
📄 许可声明
本仓库所有 .ipynb 文件中的文字内容(Markdown 单元格、公式、图示说明)采用 CC BY 4.0 协议;代码内容(Code 单元格、可执行实现)采用 Apache-2.0 协议。使用、转载、改编时,请按单元格类型分别遵守对应协议。文字协议见 LICENSE,代码协议见 LICENSE-CODE。
🎯 项目简介
这是一个面向大模型入门到进阶的算法实战教程,以 LLM 为主线,帮助读者通过可运行、可验证、可回顾的 Notebook,从“会看”走到“会写、会调、会优化”。
✨ 项目特点
- 主线清晰:从基础能力到 Triton / CUDA 系统优化,形成完整学习链。
- 工程导向:以 Notebook 实战为载体,强调动手实现与性能意识。
- 覆盖广泛:从 PyTorch、Transformer 到推理优化、显存管理与底层实现都有对应内容。
👥 适合对象
- 求职面试者:巩固 LLM 算法工程师、AI 架构师、算子开发工程师的高频考点。
- AI 研发人员:从代码底层理解显存优化、分布式通信与 Triton/CUDA 算子。
📌 学习前提
- 具备 Python 和深度学习基础,熟悉 PyTorch。
- 高阶内容需要一定 C++/CUDA 基础。
🌐 教程总览
这套教程分为纵深主线、横切专题和共学沉淀三层:Part 0 和 Part 1 是共同前置,Part 2 -> Part 5 是主线实战层,topic_discussion 承载 profiling、AI compiler 等跨 Part 主题,team_study 则单独作为动态共学沉淀层,当前主要对应 Part 2。整体关系可以理解为前置打底 -> PyTorch 主线 -> Triton -> CUDA,横切专题和组队学习分别服务于性能分析、编译视野和共学沉淀。
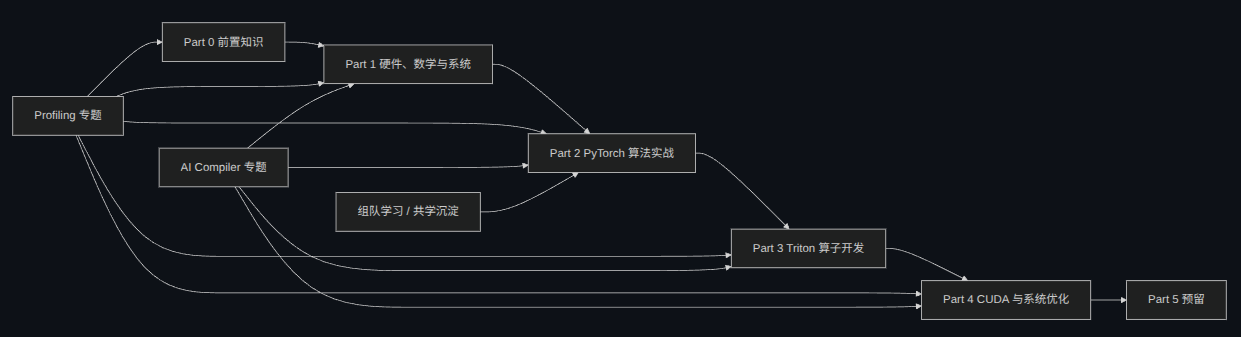
flowchart LR
P0["Part 0 前置知识"] --> P1["Part 1 硬件、数学与系统"]
P1 --> P2["Part 2 PyTorch 算法实战"]
P2 --> P3["Part 3 Triton 算子开发"]
P3 --> P4["Part 4 CUDA 与系统优化"]
P4 --> P5["Part 5 预留"]
Profiling["Profiling 专题"] --> P0
Profiling --> P1
Profiling --> P2
Profiling --> P3
Profiling --> P4
Compiler["AI Compiler 专题"] --> P1
Compiler --> P2
Compiler --> P3
Compiler --> P4
Study["组队学习 / 共学沉淀"] --> P2
📚 资产总览
这套教程不要求从 00 开始按顺序硬读。00 主要是前置补齐区,如果你已有基础,可以直接从最相关的部分开始;下面这张表会直接告诉你:每一部分学什么、包含哪些组、适合谁、当前进度如何。
🧭 专题总览
| 专题 | 覆盖范围 | 内容定位 | 适合对象 | 状态 |
|---|---|---|---|---|
Profiling 专题 | 所有part | 性能意识、profiling 方法、瓶颈定位经验。 | 想系统补性能意识与排障方法的学习者。 | 🛠 建设中 |
AI Compiler 专题 | 所有part | 图优化、编译链路、自动优化策略。 | 想补齐编译视野与自动优化思路的学习者。 | 🛠 建设中 |
🤝 共学沉淀
| 模块 | 覆盖范围 | 内容定位 | 适合对象 | 状态 |
|---|---|---|---|---|
组队学习专题 | 不固定 | part2_l1_202606 / part2_l1_202607 / part2_l2_202607 | 想通过共学沉淀知识、题目与复盘记录的学习者。 | 🛠 建设中 |
🆕 更新时间线
- 2026-07-10:[最新更新点]收紧了中文版首页的教材总览与状态列,校正了
Part 0/Part 1的组名、节数和0E标题,并同步了相关导航与最近更新说明。 - 2026-06-26:[最新更新点]收紧了中文版首页的教材总览、状态列和 mermaid 关系图,明确了
Part 0-1的前置关系、Part 2-5的主线关系,以及横向专题和组队学习的定位。 - 2026-06-15:推进第零部分 / 第一部分的分组与导读收口,统一部分级导航,并完成网页底部评论区接入 GitHub Discussions,同时持续扩展第一部分的正文、桥接页与 Notebook 结构。
- 2026-06-13:修复 dead link,并为未完成页面补充占位页,避免学习入口出现 404。
- 2026-04-21:更新 Colab 徽章链接,统一指向官方
datawhalechina仓库。 - 2026-04-20:上线站点首页与部分导学;新增第零部分前置知识与第一部分练习内容,完善在线阅读入口与学习路径。
- 2026-04-18 ~ 2026-04-19:集中重构第二部分 / 第三部分内容,优化 Notebook、答案区与算子实现说明。
- 2026-04-02:完成教程核心 Notebook、文档与测试脚本的初始搭建。
路径兼容说明:第三部分已从
03_CUDA_and_Triton_Kernels更名为03_Triton_Kernels,CUDA / 系统优化内容拆分到第四部分。旧网页路径会保留迁移入口,建议新链接统一使用03_Triton_Kernels。
🚀 快速开始
如果你想开始学习,不需要从 00 按顺序起步;在线站点的导学和目录是入口,不是硬性起点。Part 0 适合补基础,Part 1 / 2 / 3 / 4 可以按你的目标直接切入。需要运行 Notebook 时,Part 0 / 1 / 2 可以优先走 CPU-first,Part 3 / 4 需要 GPU 环境。环境与平台差异见 使用指南。
学习路径
- 在左侧侧边栏选择你当前最关心的部分
- 点击 📖 完整导学 了解该部分的阅读顺序
- 直接从对应 group 进入,不必先补完全部前置
- 如果后面遇到知识缺口,再回到 Part 0 / Part 1 补基础
- 环境和平台差异见 使用指南
方式 1:在线阅读
访问在线站点:
https://datawhalechina.github.io/llm-algo-leetcode/
适合:
- 先看目录再决定从哪一部分切入
- 先读部分导学,按目标跳转到对应 group
- Part 0 / 1 / 2 可以直接用 Colab CPU 跑练习
- Part 3 / 4 需要 Colab GPU runtime
方式 2:本地学习
git clone https://github.com/datawhalechina/llm-algo-leetcode.git
cd llm-algo-leetcode
conda env create -f environment.yml
conda activate llm_algo
jupyter lab适合:
- 想在本地完整跑 Part 0 / 1 / 2 的 Notebook
- 想自己控制 Python / PyTorch / CUDA 版本
- 想做更稳定的离线调试
- Part 3 / 4 需要本地 NVIDIA GPU
方式 3:CNB 统一环境
如果你希望和仓库当前推荐环境保持一致,可以使用 CNB 统一环境入口。
适合:
- 团队协作
- 统一实验镜像
- 需要减少本地环境差异
- Part 0 / 1 / 2 可以用 CNB CPU
- Part 3 / 4 需要 CNB GPU 会话
CNB 的具体使用方式和适用范围见 使用指南。
📖 更多资源
👨💻 贡献者名单
| 姓名 | 职责 | 简介 |
|---|---|---|
| lynn_jingjing | 项目发起人 | 一个算法工程师 |
(欢迎在此留下您的名字!)
📄 开源协议
本仓库中的教程文字采用 CC BY 4.0 协议;代码采用 Apache-2.0 协议。.ipynb 文件为混合内容,使用时请按单元格类型分别遵守对应协议。
English Version
📄 License Notice
All .ipynb files in this repository are mixed-content notebooks: Markdown cells (tutorial text, formulas, and figure captions) are licensed under CC BY 4.0, while Code cells (executable implementations) are licensed under Apache-2.0. Please comply with the corresponding license by cell type when using, redistributing, or adapting this repository. See LICENSE for text and LICENSE-CODE for code.
🎯 Project Introduction
This is a practical LLM algorithm tutorial from beginner to advanced, built around runnable, verifiable notebooks that help you move from "reading" to "writing, debugging, and optimizing".
✨ Features
- Clear Main Line: A complete learning chain from prerequisites to Triton / CUDA system optimization.
- Engineering-Oriented: Notebook-based practice with hands-on implementation and performance awareness.
- Broad Coverage: Covers PyTorch, Transformers, inference optimization, VRAM management, and low-level implementation.
👥 Suitable For
- Job Seekers: Reinforce common interview topics for LLM algorithm engineers, AI architects, and kernel developers.
- AI Practitioners: Understand VRAM optimization, distributed communication, and Triton/CUDA operators from the code level.
📌 Prerequisites
- Basic Python and deep learning knowledge, plus PyTorch familiarity.
- Advanced parts require some C++/CUDA background.
🌐 Tutorial Overview
This tutorial is organized into a vertical main line and two cross-cutting tracks: the main line connects Part 0 -> Part 4 (with Part 5 reserved), topic_discussion covers profiling and AI compiler, and team_study is maintained as a separate collaborative-learning lane. The overview is summarized in the asset and topic tables below.
flowchart LR
P0["Part 0 Prerequisites"] --> P1["Part 1 Hardware, Math, and Systems"]
P1 --> P2["Part 2 PyTorch Algorithm Practice"]
P2 --> P3["Part 3 Triton Kernel Development"]
P3 --> P4["Part 4 CUDA and System Optimization"]
P4 --> P5["Part 5 Reserved"]
Profiling["Profiling Topic"] --> P0
Profiling --> P1
Profiling --> P2
Profiling --> P3
Profiling --> P4
Compiler["AI Compiler Topic"] --> P1
Compiler --> P2
Compiler --> P3
Compiler --> P4
Study["Team Study / Shared Learning"] --> P2
📚 Current Asset Overview
You do not need to start from 00 in strict order. 00 is the prerequisite lane; if you already have the background, jump directly to the part that matches your goal. The table below summarizes each part, its groups, its audience, and its status.
🧭 Topic Overview
| Topic | Coverage | Content Positioning | Suitable For | Status |
|---|---|---|---|---|
| Topic Discussion Axis | All parts | Cross-Part topic discussion and case stitching. | Learners who want to consolidate methods and cases across parts. | 🛠 In progress |
| Profiling Topic | All parts | Performance awareness, profiling methods, bottleneck localization. | Learners who want systematic performance diagnosis and debugging methods. | 🛠 In progress |
| AI Compiler Topic | All parts | Graph optimization, compiler pipelines, automated optimization strategies. | Learners who want compiler vision and automated optimization ideas. | 🛠 In progress |
🤝 Collaborative Study
| Module | Coverage | Content Positioning | Suitable For | Status |
|---|---|---|---|---|
| Team Study Topic | Not fixed | part2_l1_202606 / part2_l1_202607 / part2_l2_202607 | Learners who want to accumulate knowledge and review records through collaborative study. | 🛠 In progress |
🆕 Update Timeline
- 2026-07-10: [Latest update] tightened the English homepage asset overview and status columns, aligned the part/group counts with the current source structure, and refreshed the topic and team-study status tables.
- 2026-06-26: [Latest update] improved the Chinese homepage overview and clarified the learning path across Parts 3 and 4, making the entry points and study order more intuitive.
- 2026-06-15: Finalized the Part 0 / 1 grouping and guide cleanup, unified the part-level navigation, connected the page comments to GitHub Discussions, and continued expanding Part 1 content, bridge pages, and notebook structure.
- 2026-06-13: Fixed dead links and added placeholder pages for unfinished content to prevent 404s in learning entry points.
- 2026-04-21: Updated Colab badges to point to the official
datawhalechinarepository. - 2026-04-20: Launched the site homepage and part guides; added Part 0 prerequisites and Part 1 practice content to unify the learning path.
- 2026-04-18 ~ 2026-04-19: Refactored Part 2 / 3 content, polishing notebooks, answer sections, and operator implementation notes.
- 2026-04-02: Completed the initial tutorial notebooks, docs, and test scripts.
Path compatibility note: Part 3 has been renamed from
03_CUDA_and_Triton_Kernelsto03_Triton_Kernels, and CUDA / system optimization content has moved to Part 4. Old web paths keep migration pages, but new links should use03_Triton_Kernels.
🚀 Quick Start
You do not need to start from Part 0 in order; Part 0 is the prerequisite lane, and you can jump directly to the part that matches your goal.
Option 1: Read Online
Visit the online platform:
https://datawhalechina.github.io/llm-algo-leetcode/
Suitable for:
- Skimming the table of contents first and then jumping to the part you need
- Reading the part guides first
- Part 0 / 1 / 2 can run on Colab CPU
- Part 3 / 4 need a Colab GPU runtime
Option 2: Local Development
git clone https://github.com/datawhalechina/llm-algo-leetcode.git
cd llm-algo-leetcode
conda env create -f environment.yml
conda activate llm_algo
jupyter labSuitable for:
- Running Part 0 / 1 / 2 locally on CPU
- Controlling your own Python / PyTorch / CUDA versions
- More stable offline debugging
- Part 3 / 4 require a local NVIDIA GPU
For environment details and platform differences, see the Chinese guide section or docs/guide.md.
Option 3: CNB Unified Delivery
If you want the same runtime style used by the repository, use the CNB unified environment.
Suitable for:
- Team collaboration
- Consistent experiment images
- Lower local environment drift
- Part 0 / 1 / 2 can use CNB CPU
- Part 3 / 4 need a CNB GPU session
See docs/guide.md for the exact environment rules and scope.
📖 More Resources
- docs/guide.md - environment and learning modes
- docs/contributing.md - how to contribute to development and testing
- docs/maintenance.md - maintenance rules for parts, links, tests, and releases
- Automated Test Script Index - entry points for automated verification scripts
👨💻 Contributors
| Name | Role | Description |
|---|---|---|
| lynn_jingjing | Project initiator | An algorithm engineer |
(Feel free to add your name here! )
📄 License
Tutorial text in this repository is licensed under CC BY 4.0, and code is licensed under Apache-2.0. .ipynb files are mixed-content notebooks, so please follow the corresponding license by cell type.