
扩散世界模型与时程漂移
扩散世界模型(Diamond)
Diamond(2024)是第一个将扩散过程与强化学习训练循环直接结合的世界模型,在 Atari 100k 基准上以平均 HNS 1.46 超越了之前所有世界模型方法。扩散模型以历史帧和动作为条件,逐步去噪生成下一帧,每一步去噪都是一次完整的 U-Net 前向传播。这带来了出色的生成保真度,代价是生成速度慢和物体持久性维护困难。
FVD(序列动态质量)
同 STORM 一节所述,FVD 是扩散世界模型序列质量的首选报告指标。Diamond 论文中报告的 FVD 已经低于 Atari 真实游戏帧,说明生成质量在统计意义上接近真实。
物理一致性
这是扩散世界模型的特有挑战:高保真的逐帧生成不代表物理关系在序列中保持一致。具体表现:一个物体从桌面掉落,每帧单独看都很逼真,但物体落地后可能在下一帧又"弹回"桌面,违反了重力和持久性约束。
评估方法:在评估序列上运行一个物体追踪器(如 SAM2,Segment Anything Model 2,Meta 2024 年发布的视频分割追踪模型,可在视频中实时追踪任意指定物体的掩码;或 DINO 特征匹配,一种基于自监督 Transformer 预训练的视觉特征提取器,同一物体在不同帧中的 DINO 特征向量相似度高,可用于跨帧对应关系匹配),追踪关键物体在连续帧间的位置轨迹,标记出违反连续性的跳变帧(帧间位移超过合理阈值)。物理一致性得分是无违规帧占总帧数的比例,越高越好。
动作条件保真度
扩散世界模型以动作为条件生成下一帧,但"条件"的注入方式决定了生成帧与动作的对齐程度。若动作信号只在 U-Net 的少数层注入,模型可能忽略动作条件,生成"视觉上合理但与动作无关"的帧。
评估方法:取同一初始帧,分别用两个相反动作(如"左移"和"右移")条件生成 5 步展开,检验两条轨迹的分歧是否与动作预期一致。保真度指标为动作方向分歧率:在 k 步内,生成轨迹的运动方向与动作方向一致的比例。低于 0.7 说明动作信号被模型弱化。
深度违规率(Depth Violation Rate)
这是 Diamond 评估体系中最具体的自动化诊断指标。物理一致性违规在视觉上最显著的表现是三维关系颠倒:本应在前景的物体出现在背景物体后面,或两个物体的遮挡关系在连续帧间发生反转。
计算流程:
- 用 DepthAnything(一种单目深度估计模型,仅用单张 RGB 图像即可估计场景中每个像素的相对深度,无需双目摄像头或激光雷达)对每帧估计单目深度图
- 用物理一致性评估中的 DINO 特征对关键物体在相邻帧间做特征匹配,追踪同一物体
- 检查同一物体在相邻帧的深度值是否发生突变(变化超过总深度范围的 20%)
- 深度违规率 = 违规帧对数 / 总相邻帧对数
诊断规则:深度违规率超过 10%,需在 U-Net 的每一个分辨率层都注入动作信息(而非只在 bottleneck 注入),同时考虑在损失函数中加入深度一致性约束(相邻帧的深度图 L1 差异惩罚)。
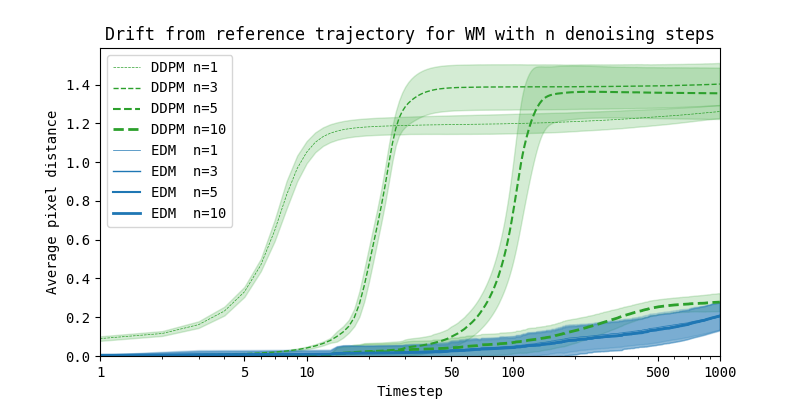
时程漂移:所有世界模型的共同失效模式
所有架构在足够长的展开步数下,都会出现潜在状态或生成内容与真实世界分布的系统性偏离,这是时程漂移(Horizon Drift)。漂移的具体形式因架构而异:
| 架构 | 漂移表现 |
|---|---|
| RNN/RSSM | 潜在向量 z_t 偏离真实观测的对应区域,PSNR 下降 |
| Transformer(STORM) | 自回归误差累积,token 预测残差逐步放大 |
| 扩散(Diamond) | 物体身份、位置、遮挡关系在长序列中悄悄改变 |
| TD-MPC | 潜在空间一致性损失上升,规划效率下降 |
检测:漂移曲线
标准检测流程:从一批真实起始状态出发,让模型自回归展开 N 步(不注入任何真实帧校正),在每一步计算预测状态与真实状态的距离指标(PSNR、FVD 片段、或余弦相似度),画出距离随步数的曲线。
理想曲线:前 5-10 步近似线性上升,随后趋于平台。
危险信号:前 5 步内指标骤降超过原始值 30%,说明模型的单步预测误差过大,展开能力基本失效;或者前 20 步内单调递减不见收敛,说明误差持续累积,模型无法在展开中维持合理的状态分布。
缓解策略
1. 短时域训练(Short Horizon Training)
把训练时的展开步数限制在模型能可靠预测的范围内,而非强行用长序列训练。对大多数架构,4-8 步是比较稳健的训练窗口。长序列训练在梯度上更嘈杂,反而可能让单步精度变差。这不是妥协,而是认识到"会预测 1 步"比"勉强预测 20 步"对规划更有用。
2. 目标网络(Target Network)
在计算时序差分(TD)目标时,使用一个参数更新更慢的副本网络(target network)而非主网络。这截断了误差沿时间方向的反向传播,减少了单步预测误差的跨步积累。TD-MPC 和 Dreamer V3 都采用了这个技巧。
3. 真实数据补充(Real Data Interleaving)
在想象展开的 minibatch 中,周期性地插入真实轨迹,让模型的梯度不会完全由模型自身的预测结果驱动。比例建议:每 4 步想象展开插入 1 步真实数据(25% 真实数据比例)。这对防止 RSSM 的 KL 崩塌也有附带效果。
4. 展开步数自适应(Horizon Annealing)
训练初期用短展开(如 1-2 步),随着模型单步精度提升,逐步增加展开步数(如每 10k 步增加 1 步,上限 8 步)。这避免了训练初期用劣质预测来监督模型自身,减少了自举误差。
延伸阅读
- Alonso et al. (2024): Diamond:扩散世界模型,NeurIPS 2024,Atari 100k 平均 HNS 1.46
- Zhang et al. (2023): STORM:Transformer 动力学世界模型,FVD 评估基线
- Carreira & Zisserman (2017): I3D:FVD 使用的视频特征提取骨干网络