2.2.1. I2I召回¶
在推荐系统中,I2I(Item-to-Item)召回是一个核心任务:给定一个物品,如何快速找出与之相似的其他物品?这个看似简单的问题,实际上蕴含着深刻的洞察——“相似性”并非仅仅由物品的内在属性决定,而是与用户的行为所共同定义的。如果两个商品经常被同一批用户购买,两部电影被同一群观众喜欢,那么它们之间就可能存在某种关联。
这种思想的灵感来源于自然语言处理领域的一个重要发现。在语言学中,有一个著名的分布假说 (Firth, 1957) :“You shall know a word by the company it keeps”(观其伴,知其义)。一个词的含义可以通过它经常与哪些词一起出现来推断。Word2Vec正是基于这一思想,通过分析大量文本中词语的共现关系,学习出了能够捕捉语义相似性的词向量。本节将首先介绍Word2Vec的核心思想,为后续的I2I召回模型奠定理论基础。
接下来,我们将看到所有I2I召回方法的本质都是在回答同一个问题:如何更好地定义和利用“序列”来学习物品之间的相似性。从最直接的用户行为序列,到融合属性信息的增强序列,再到面向业务目标的会话序列,每一种方法都是对“序列”概念的不同诠释和深化。
2.2.1.1. Word2Vec:序列建模的理论基础¶
Word2Vec (Mikolov et al., 2013) 的成功建立在一个简单而深刻的假设之上:在相似语境中出现的词语往往具有相似的含义。通过分析海量文本中词语的共现模式,我们可以为每个词学习一个稠密的向量表示,使得语义相近的词在向量空间中距离更近。
Word2Vec主要包含两种模型架构:Skip-Gram和CBOW(Continuous Bag of Words)。Skip-Gram模型通过给定的中心词来预测其周围的上下文词,而CBOW模型则相反,通过上下文词来预测中心词。在推荐系统中,Skip-Gram模型由于其更好的性能表现而被更广泛地采用。
2.2.1.1.1. Skip-Gram模型详解¶

图2.2.1 Word2Vec Skip-Gram模型示意图¶
在Skip-Gram模型中,给定文本序列中位置\(t\)的中心词\(w_t\),模型的目标是最大化其上下文窗口内所有词语的出现概率。具体而言,对于窗口大小为\(m\)的情况,模型要预测\(w_{t-m}, w_{t-m+1}, \ldots, w_{t-1}, w_{t+1}, \ldots, w_{t+m}\)这些上下文词的概率。
中心词\(w_t\)预测上下文词\(w_{t+j}\)的条件概率定义为:
其中\(v_{w_i}\)表示词\(w_i\)的向量表示,\(V\)是词汇表。这个softmax公式确保了所有词的概率之和为1,而分子中的内积\(v_{w_{t+j}}^T v_{w_t}\)衡量了中心词与上下文词的相似度。
2.2.1.1.2. 负采样优化¶
直接计算上述softmax的分母需要遍历整个词汇表,在实际应用中计算代价过高。为了解决这个问题,Word2Vec采用了负采样(Negative Sampling)技术。这种方法将原本的多分类问题转化为多个二分类问题:
其中\(\sigma(x) = \frac{1}{1 + e^{-x}}\)是sigmoid函数,\(k\)是负样本数量,\(P_n(w)\)是负采样分布。负采样的直观解释是:对于真实的词对,我们希望增加它们的相似度;对于随机采样的负样本词对,我们希望降低它们的相似度。
这种优化策略不仅大幅提升了训练效率,还为后续推荐系统中的模型训练提供了重要的技术范式。当我们将这一思想迁移到推荐领域时,“词语”变成了“物品”,“句子”变成了“用户行为序列”,但核心的序列建模思想保持不变。
2.2.1.2. Item2Vec:最直接的迁移¶
Word2Vec在自然语言处理领域的成功,自然引发了一个问题:能否将这种基于序列的学习方法直接应用到推荐系统中?Item2Vec给出了肯定的答案。
2.2.1.2.1. 从词语到物品的映射¶
Item2Vec (Barkan and Koenigstein, 2016) 的核心洞察在于发现了用户行为数据与文本数据的结构相似性。在文本中,一个句子由多个词语组成,词语之间的共现关系反映了语义相似性。类似地,在推荐系统中,每个用户的交互历史可以看作一个“句子”,其中包含的物品就是“词语”。如果两个物品经常被同一个用户交互,那么它们之间就存在相似性。
这种映射关系可以表示为:
词语 → 物品
句子 → 用户交互序列
词语共现 → 物品共同被用户交互
2.2.1.2.2. 模型实现¶
Item2Vec直接采用Word2Vec的Skip-Gram架构,但在序列构建上有所简化。给定数据集\(\mathcal{S} = \{s_1, s_2, \ldots, s_n\}\),其中每个\(s_i\)包含用户\(i\)交互过的所有物品,Item2Vec将每个用户的交互历史视为一个集合而非序列,忽略了交互的时间顺序。
优化目标函数与Word2Vec保持一致:
其中\(l_i\)表示物品,\(m\)是上下文窗口大小,\(P(l_{i+j} | l_{i})\)采用与Word2Vec相同的softmax形式计算。
核心代码
Item2Vec的实现可以直接调用gensim库 (Řehůřek and Sojka, 2010) 的Word2Vec模型。核心在于将用户交互序列作为训练语料:
def fit(self, train_hist_movie_id_list):
# train_hist_movie_id_list: 用户交互序列列表
# 每个元素是一个用户的物品ID序列
self.model = Word2Vec(
train_hist_movie_id_list,
vector_size=self.model_config["EmbDim"], # 嵌入维度
window=self.model_config["Window"], # 上下文窗口大小
min_count=self.model_config["MinCount"], # 最小出现次数
workers=self.model_config["Workers"], # 并行线程数
)
这里的train_hist_movie_id_list就是前面提到的数据集\(\mathcal{S}\),其中每个用户的交互历史被视为一个“句子”,物品ID对应“词语”。训练完成后,每个物品都得到一个稠密的向量表示。
训练和评估
from funrec import run_experiment
run_experiment('item2vec')
+---------------+--------------+-----------+----------+----------------+---------------+
| hit_rate@10 | hit_rate@5 | ndcg@10 | ndcg@5 | precision@10 | precision@5 |
+===============+==============+===========+==========+================+===============+
| 0.0066 | 0.0033 | 0.0025 | 0.0014 | 0.0007 | 0.0007 |
+---------------+--------------+-----------+----------+----------------+---------------+
2.2.1.3. EGES:用属性信息增强序列¶
Item2Vec虽然验证了序列建模在推荐系统中的可行性,但其简单的设计也带来了明显的局限性。首先,将用户交互历史简单视为无序集合,忽略了时序信息可能丢失重要的用户行为模式。其次,对于新上架的物品由于缺乏用户交互历史,Item2Vec无法生成有意义的向量表示。
EGES(Enhanced Graph Embedding with Side Information):cite:wang2018billion 正是为了解决这些核心挑战而提出的。该方法通过两个关键创新来改进传统的序列建模:一是基于会话构建更精细的商品关系图来更好地反映用户行为模式,二是融合商品的辅助信息来解决冷启动问题。
2.2.1.3.1. 构建商品关系图¶
EGES的第一个创新是将物品序列的概念从简单的用户交互扩展为更精细的会话级序列。考虑到用户行为的复杂性和计算效率,研究者设置了一小时的时间窗口,只选择窗口内的用户行为构建商品关系图。
具体构建过程如图所示:当两个商品在同一会话(时间窗口内)的用户行为序列中连续出现时,在它们之间建立一条有向边,边的权重等于这种商品转移模式在所有用户行为历史中出现的频率。相比于传统方法将整个用户历史视为一个序列,这种基于会话的图构建方法能够更准确地捕捉用户在特定时间段内的连续兴趣转移模式。
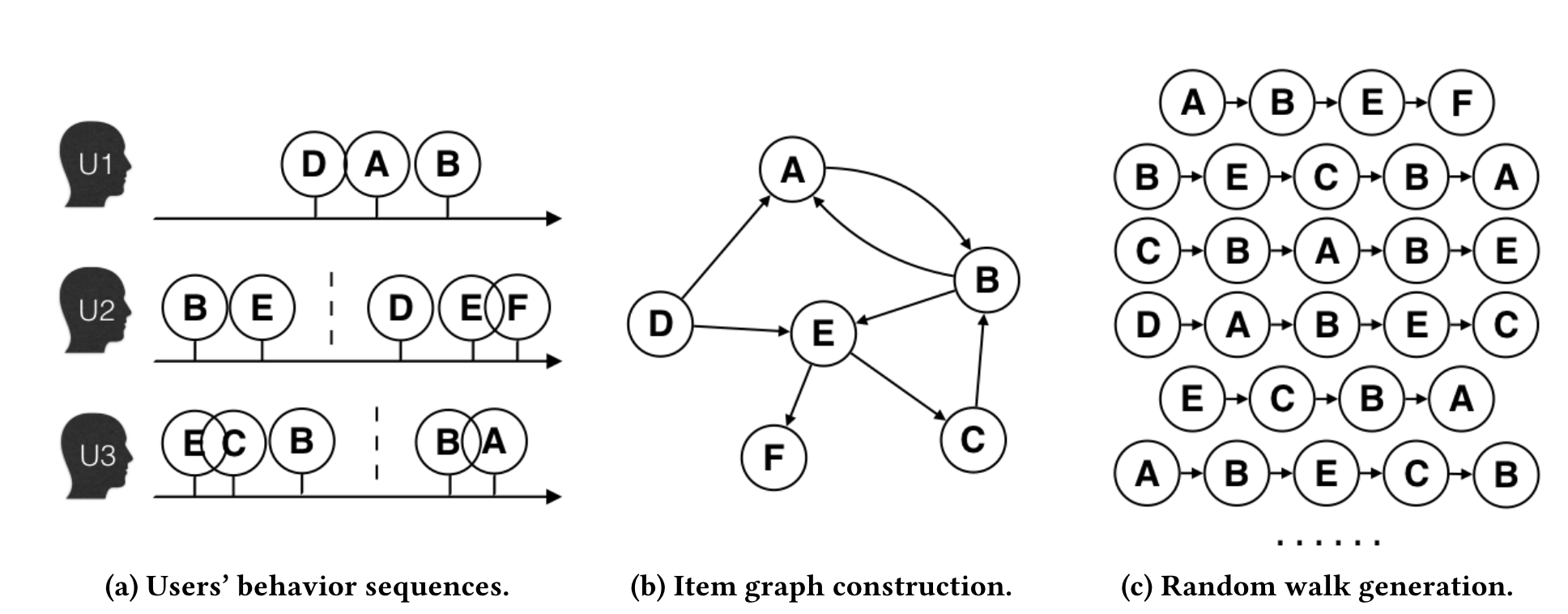
图2.2.2 商品图构建过程¶
在构建好的商品图上,EGES采用带权随机游走策略生成训练序列。从一个节点出发,转移概率由边权重决定:
其中\(M_{ij}\)表示节点\(v_i\)到节点\(v_j\)的边权重,\(N_+(v_i)\)表示节点\(v_i\)的邻居集合。通过这种随机游走过程,可以生成大量的商品序列用于后续的Embedding学习。
2.2.1.3.2. 融合辅助信息解决稀疏性问题¶
基于上述商品图和随机游走策略,我们可以采用类似Word2Vec的方法学习商品的向量表示。然而,这种纯粹基于行为序列的方法面临一个关键挑战:对于用户交互稀少的商品,由于缺乏足够的共现信息,很难学习到高质量的Embedding表示。
为了解决这种稀疏性问题,EGES方法的第二个创新是引入商品的辅助信息(如类别、品牌、价格区间等)来增强商品的向量表示。
GES的核心思想是将商品本身的Embedding与其各种属性的Embedding进行平均聚合:
其中\(W_v^s\)表示商品\(v\)的第\(s\)种属性的向量表示,\(W_v^0\)表示商品ID的向量表示。这种方法虽然有效缓解了稀疏性问题,但存在一个明显的局限:它假设所有类型的辅助信息对商品表示的贡献是相等的,这显然不符合实际情况。
EGES的核心创新在于认识到不同类型的辅助信息应该有不同的重要性。对于手机,品牌可能比价格更重要;对于日用品,价格可能比品牌更关键。
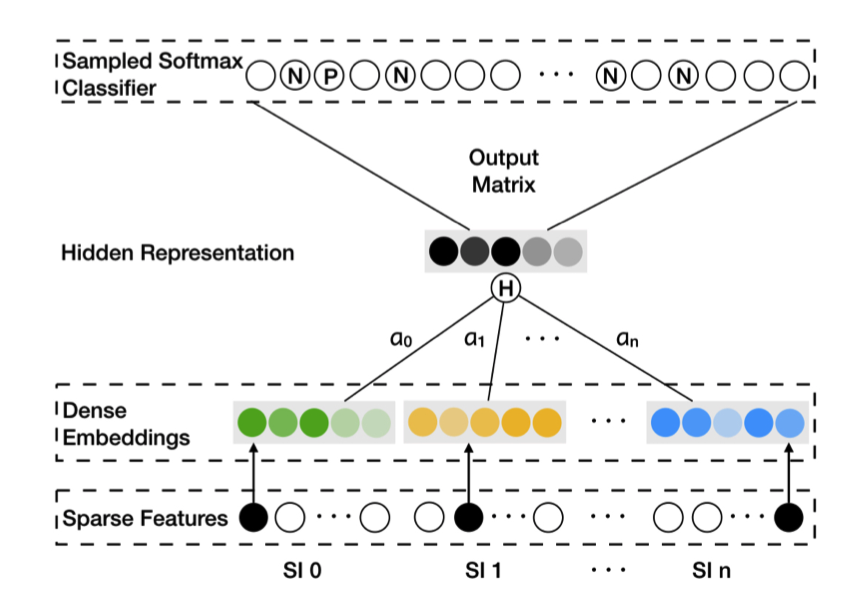
图2.2.3 EGES模型架构¶
对于具有\(n\)种辅助信息的商品\(v\),EGES为其维护\(n+1\)个向量表示:一个商品ID的向量表示,以及\(n\)个属性的向量表示。商品的最终向量表示通过加权聚合得到:
其中\(a_v^j\)是可学习的权重参数。这种设计的精妙之处在于,不同类型的辅助信息对不同商品的重要性是不同的——对于手机,品牌可能比价格更重要;对于日用品,价格可能比品牌更关键。
核心代码
EGES的核心在于商品特定注意力层(ItemSpecificAttentionLayer),它为每个商品学习一组特征权重:
def call(self, inputs, item_indices):
"""
参数:
inputs: 特征嵌入 [batch_size, n+1, emb_dim]
item_indices: 商品索引 [batch_size]
"""
# 获取每个商品对应的权重参数 a_v^j
batch_attention_weights = tf.gather(self.attention_weights, item_indices)
# 计算 e^(a_v^j)
exp_attention = tf.exp(batch_attention_weights) # [batch_size, n+1]
# 归一化权重: e^(a_v^j) / sum(e^(a_v^j))
attention_sum = tf.reduce_sum(exp_attention, axis=1, keepdims=True)
normalized_attention = exp_attention / attention_sum
# 应用权重到特征嵌入
normalized_attention = tf.expand_dims(normalized_attention, axis=-1)
weighted_embedding = inputs * normalized_attention # [batch_size, n+1, emb_dim]
# 求和得到最终的商品表示 H_v
output = tf.reduce_sum(weighted_embedding, axis=1) # [batch_size, emb_dim]
return output, normalized_attention
这里的attention_weights是一个形状为\(|V| \times (n+1)\)的参数矩阵,其中\(|V|\)是商品总数,\(n+1\)是特征数量(商品ID
+
\(n\)种辅助信息)。对于每个商品,模型会学习到一组特定的权重,自动发现哪些特征对该商品更重要。这种商品特定的注意力机制是EGES相比简单平均聚合的关键优势。
冷启动商品的处理:对于新上架且没有任何用户交互历史的商品,EGES提供了有效的冷启动解决方案。由于这类商品缺乏行为数据,无法通过随机游走生成训练序列,因此既不存在基于ID的向量表示,也没有经过训练的注意力权重参数\(a_v^j\)。
在这种情况下,系统采用简单而有效的mean pooling策略:直接对该商品的所有辅助信息向量(类别、品牌、价格区间等)进行平均聚合来构建商品表示。虽然这种方法无法体现不同属性的差异化重要性,但能够有效利用商品的内容特征,从而支持基于向量相似度的商品召回(I2I召回)。
2.2.1.3.3. 训练优化¶
EGES采用与Word2Vec类似的负采样策略,但损失函数经过了优化:
其中\(y\)是标签(1表示正样本,0表示负样本),\(H_v\)是商品\(v\)的向量表示,\(Z_u\)是上下文节点\(u\)的向量表示。
通过这种方式,即使是刚上架、没有任何用户交互的新商品,也能通过其属性信息获得有意义的向量表示,从而被纳入推荐候选集。
EGES在淘宝的实际部署效果显著:在包含十亿级训练样本的大规模数据集上,相比传统方法在推荐准确率上有了显著的提升,同时有效解决了新商品的冷启动问题。
训练和评估
run_experiment('eges')
+---------------+--------------+-----------+----------+----------------+---------------+
| hit_rate@10 | hit_rate@5 | ndcg@10 | ndcg@5 | precision@10 | precision@5 |
+===============+==============+===========+==========+================+===============+
| 0.0136 | 0.0061 | 0.0064 | 0.0041 | 0.0014 | 0.0012 |
+---------------+--------------+-----------+----------+----------------+---------------+
2.2.1.4. Airbnb:将业务目标融入序列¶
Airbnb作为全球最大的短租平台,面临着与传统电商不同的挑战。房源不是标准化商品,用户的预订行为远比点击浏览稀疏,而且地理位置成为了一个关键因素。更重要的是,Airbnb需要的不仅仅是相似性,而是能够真正促进最终预订转化的推荐。
2.2.1.4.1. 面向业务的序列构建¶
Airbnb重新定义了“序列”的概念 (Grbovic and Cheng, 2018),采用基于会话的序列构建策略。具体而言:
会话切分机制:系统不再简单地将用户交互过的所有房源串联,而是基于用户的点击会话(Click Sessions)构建序列。当用户连续点击间隔超过30分钟时,系统会自动开始一个新的会话。这种时间窗口的设计能够更准确地捕捉用户在特定搜索场景下的连贯意图。
行为权重差异化:Airbnb引入了重要的业务洞察——用户行为的信号强度存在显著差异。最终的预订行为相比于简单的点击浏览,包含了更强烈的用户偏好信号,因此在模型训练中应当给予更高的权重。
2.2.1.4.2. 全局上下文机制¶
为了强化模型对最终转化行为的学习,Airbnb设计了全局上下文机制。在传统的Skip-Gram模型中,只有在滑动窗口内的物品才被视为上下文,但这种局部窗口无法充分利用最终预订这一强烈的正向信号。因此,Airbnb让用户最终预订的房源(booked listing)与序列中的每一个浏览房源都形成正样本对进行训练,无论它们在序列中的距离有多远。
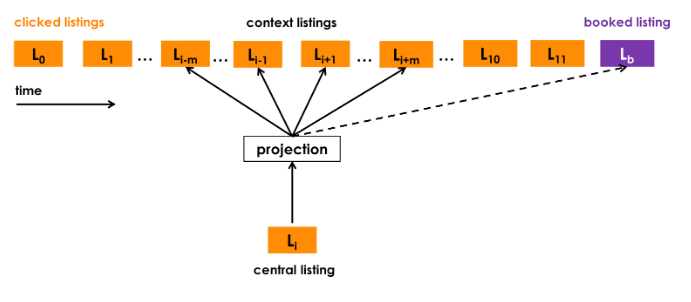
图2.2.4 Airbnb预订房源全局上下文¶
针对有预订行为的会话(booked sessions),Airbnb修改了优化目标函数,增加了全局上下文项:
在这个公式中,前两项是标准的Skip-Gram目标函数:第一项最大化正样本对\((l,c)\)的相似度,其中\(l\)是目标房源,\(c\)是滑动窗口内的上下文房源;第二项最小化负样本对的相似度。关键的创新在于第三项\(\log \frac{1}{1 + e^{-v_{l_b}^T v_l}}\),这里\(l_b\)表示用户在该会话中最终预订的房源。
通过这种全局上下文机制,预订房源为序列中的每个房源都提供了额外的学习信号,使得模型能够更有效地捕捉“什么样的房源组合最终会导致预订”这一关键转化模式。
2.2.1.4.3. 市场感知的负采样¶
Airbnb的另一个创新是改进了负采样策略。传统方法从整个物品库中随机选择负样本,但Airbnb观察到用户通常只会在同一个市场(城市或地区)内进行预订。如果负样本来自不同的地理位置,模型就容易学到地理位置这种“简单特征”,而忽略了房源本身的特点。
因此,Airbnb增加了“同市场负采样”策略,一部分负样本从与正样本相同的地理市场中选择:
其中\(l_m^-\)表示来自相同市场的负样本。这迫使模型学习同一地区内房源的细微差别,提升了推荐的精细度。