生成式推荐¶
在前面的召回章节中,我们探讨了以SASRec为代表的生成式召回方法,它们将推荐问题重新定义为序列预测任务,通过自回归的方式预测用户下一个可能交互的物品。这种范式的成功验证了一个重要观点:推荐系统可以从传统的“判别式打分”转向“自回归生成”,借鉴自然语言处理领域的成功经验,将用户行为序列视为一种特殊的“语言”来理解和生成。
生成式推荐的核心在于三个关键要素的重新设计:输入如何组织(从简单的物品ID序列到复杂的事件流)、输出生成什么(从原子ID到语义化表示)、以及目标与架构如何取舍(在表达能力与计算效率间寻求平衡)。围绕这三个维度,生成式推荐沿着三条清晰的演进路径不断发展:一是生成式召回,延续SASRec的思路但在输入和输出上进行深度创新;二是生成式排序,将生成范式引入传统的排序阶段;三是端到端统一生成,试图用单一模型完成从召回到排序的全流程。
生成式召回的深化演进¶
生成式召回在SASRec奠定的基础上,主要沿着两个方向进行深化探索。HSTU模型 (Zhai et al., 2024) 代表了对“输入”理解的深化,它不再满足于简单的物品ID序列,而是将用户的所有异构信息——属性、行为类型、时间戳等——统一编码为一个复杂的“事件流”。这种设计的核心思想是学习条件分布\(p(\Phi_{i+1}|u_i)\),其中\(u_i\)是用户在当前时刻的综合表示,\(\Phi_{i+1}\)是下一个候选物品。
HSTU的技术创新主要体现在两个方面。首先是特征统一化处理:对于类别特征,按时间戳将所有信息拉平成统一序列,如[(特征:年龄,值:30), (行为:登录), (行为:浏览,物品:A)];对于数值特征,则采用隐式建模让模型自动推断。其次是点向聚合机制:摒弃传统Transformer中的softmax归一化,采用点向聚合\(A(X)V(X) = \phi_2(Q(X)K(X)^T + \text{rab}^{p,t})V(X)\)来保持用户偏好的强度信息。这种设计的动机在于,推荐场景中用户兴趣的“强度”是关键信号,而softmax归一化会将所有历史行为的注意力权重强制归一化,从而扭曲真实的偏好强度。值得注意的是,HSTU通过切换预测目标和训练头,也可以从召回任务转换为排序任务,体现了生成式架构的灵活性。
TIGER模型 (Rajput et al., 2023) 则代表了对“输出”定义的根本性重塑。它认为预测一个无语义的原子ID效率低下且存在泛化问题,转而提出生成结构化的“语义ID”来代表物品。TIGER的工作流程分为两个阶段:首先利用残差量化变分自编码器(RQ-VAE)为每个物品生成语义ID。具体而言,对于物品的内容特征向量\(\boldsymbol{x}\),编码器将其映射为潜在表示\(\boldsymbol{z} := \mathcal{E}(\boldsymbol{x})\),然后通过\(m\)层量化过程,在每层\(d\)中寻找最接近当前残差\(\boldsymbol{r}_d\)的码字:\(c_d = \arg\min_{k} \|\boldsymbol{r}_d - \boldsymbol{e}_k\|^2\),并更新残差\(\boldsymbol{r}_{d+1} := \boldsymbol{r}_d - \boldsymbol{e}_{c_d}\),最终得到语义ID元组\((c_0, c_1, ..., c_{m-1})\)。
在第二阶段,TIGER将推荐任务转化为标准的序列到序列生成问题。用户历史交互序列被转换为对应的语义ID序列,然后训练Encoder-Decoder Transformer模型自回归地生成下一个物品的语义ID。这种设计的优势在于:语义共享使得内容相似的物品拥有相似的语义ID,从而实现知识共享;冷启动优势允许为新物品生成语义ID并进行推荐;结构化表示通过多层码字高效表示大规模物品库。然而,这种方法也面临生成无效ID和推理代价较高的挑战,需要在表达能力和计算效率间进行权衡。
生成式排序的架构创新¶
生成式排序将自回归生成的思想引入传统排序阶段,主要通过两种不同的技术路径实现。GenRank模型 (Huang et al., 2025) 采用“动作导向”的设计思路,将排序问题重新定义为预测用户对给定候选物品的动作概率\(p(a_{i+1} | \text{历史}, \Phi_{i+1})\)。这种设计的核心洞察是:相比于预测下一个物品ID,预测用户的行为动作(如点击、喜欢)在计算上更加高效,因为动作空间远小于物品空间。
GenRank的架构创新主要体现在动作导向的序列组织上。不同于HSTU将物品和动作交替排列导致序列长度翻倍,GenRank将物品视为已知的位置上下文,专注于预测每个位置上的动作。输入序列的最终表示是五种嵌入的和:物品嵌入、动作嵌入(候选物品使用特殊的[MASK]嵌入)、位置嵌入、请求索引嵌入和时间嵌入。同时,GenRank采用ALiBi(线性偏置注意力)替代可学习的相对注意力偏置,这是一种无参数的静态惩罚机制,能够有效降低计算开销。实验表明,这种设计实现了约75%的注意力计算成本降低和94.8%的训练速度提升。
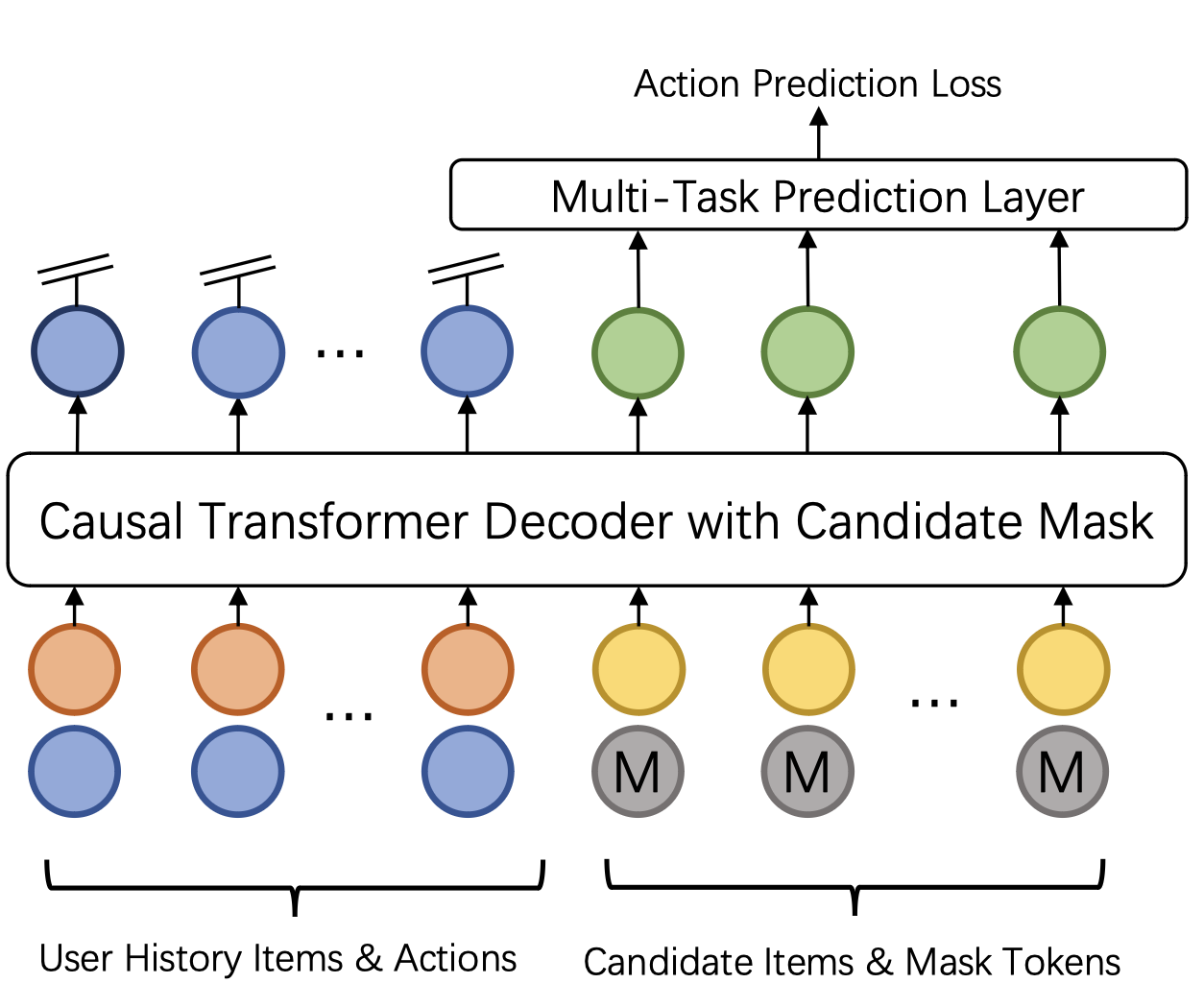
GenRank 动作为导向的序列¶
MTGR模型 (Han et al., 2025)
则提供了另一种技术路径,它试图在保留传统深度学习推荐模型(DLRM)丰富特征的同时,获得生成式架构的可扩展性优势。MTGR的核心创新是用户样本聚合:将用户的所有\(K\)个候选物品聚合为单个样本[用户特征, [候选1特征, ..., 候选K特征]],使得用户相关特征只需计算一次并在所有候选间共享。
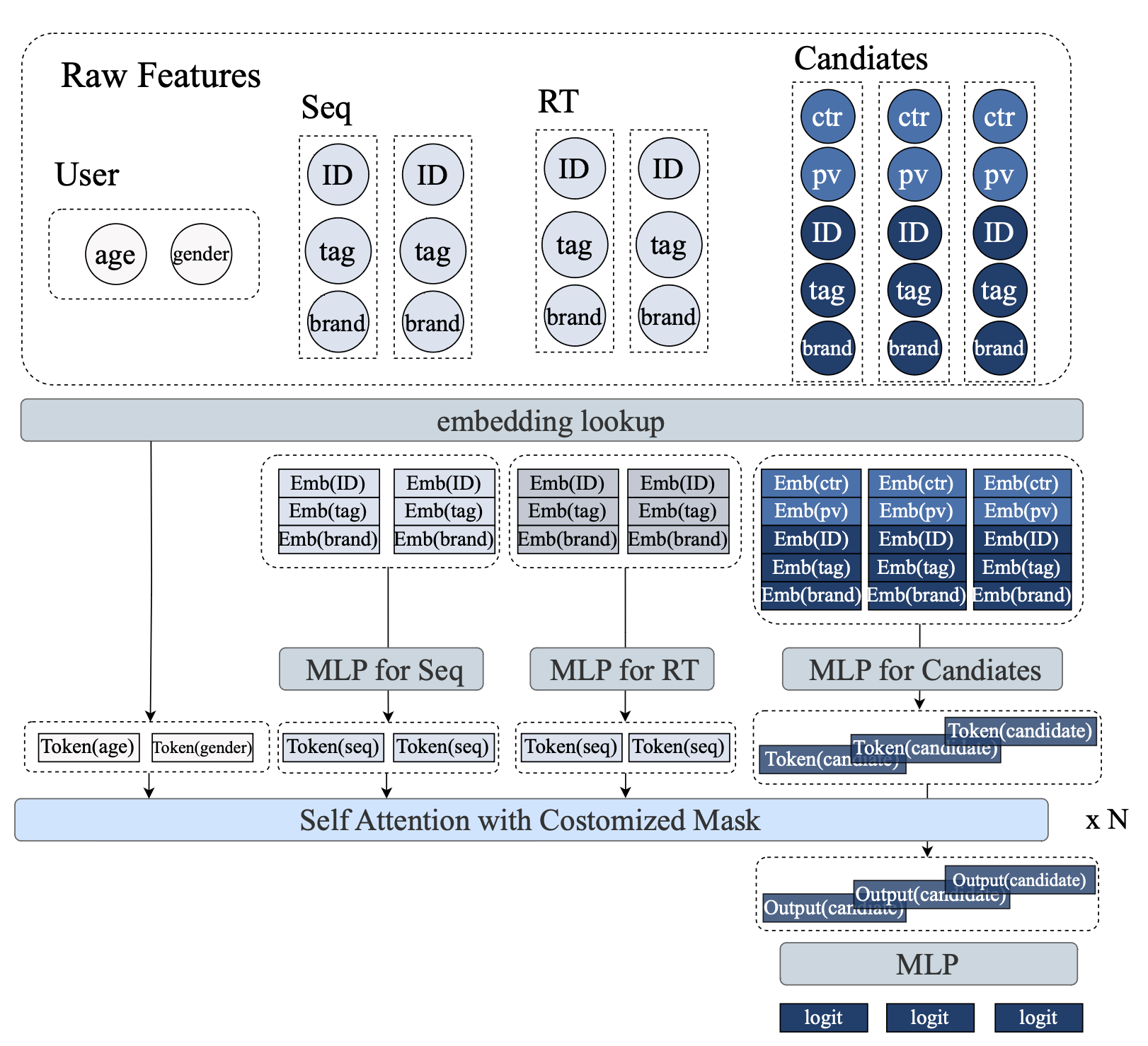
MTGR 用户样本聚合¶
为了有效处理这种异构序列,MTGR引入了两个关键技术组件。组层归一化(GLN)针对不同语义空间的token(如用户画像、物品特征)分别进行归一化,而非传统层归一化的统一处理。动态掩码策略精确控制信息流:静态用户特征对所有token可见;动态用户特征遵循因果关系;候选token之间相互不可见,防止信息泄露。需要强调的是,尽管MTGR被称为“生成式”模型,但它本质上是一个排序模型,其“生成式”特征主要体现在架构风格上——采用Transformer处理token序列,而最终目标仍是判别式的打分排序。
端到端统一生成¶
OneRec模型 (Deng et al., 2025) 代表了生成式推荐的最高形态——端到端统一生成,它试图用单一模型完成从召回到排序的全流程。OneRec的核心创新是会话级生成:不再预测单一的下一个物品,而是直接生成一组有序的推荐列表(通常5-10个物品),这个列表被定义为一个“会话”。
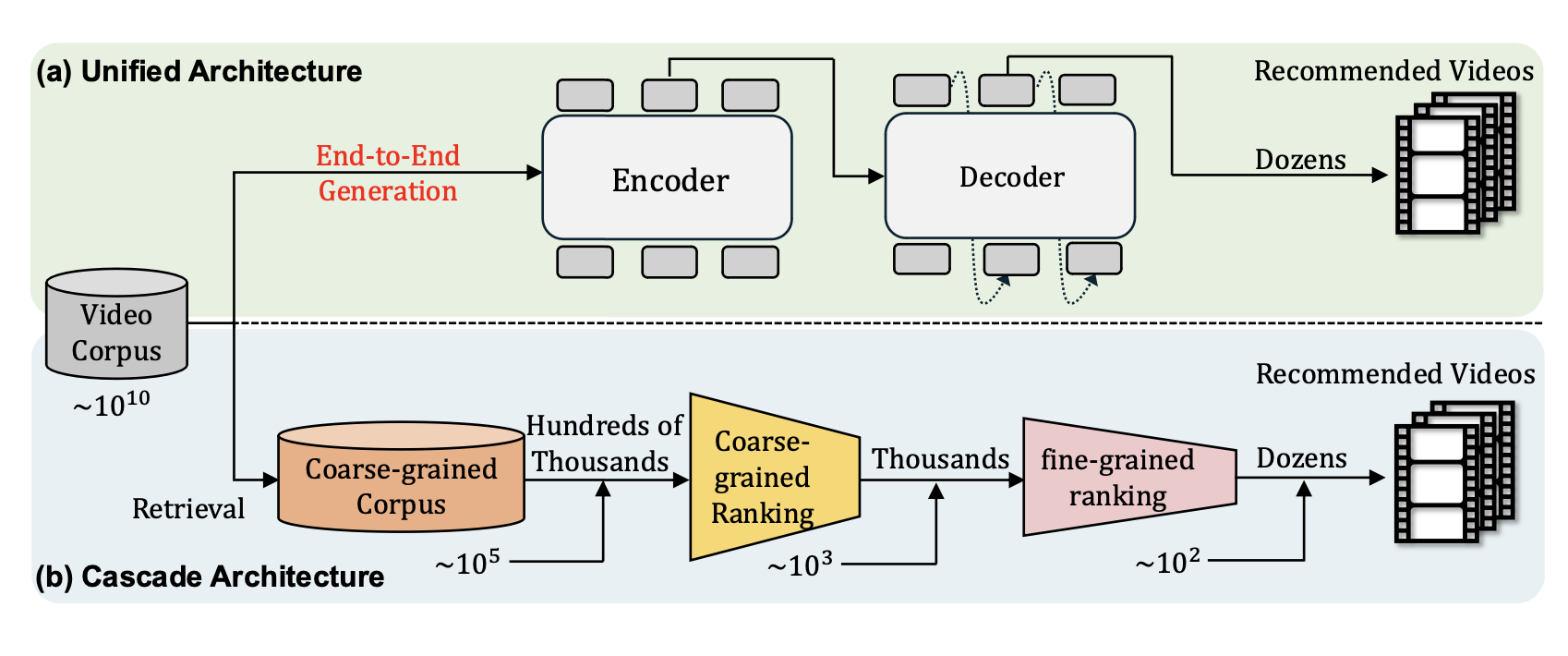
OneRec 端到端统一生成¶
OneRec采用标准的Encoder-Decoder架构,但在三个方面进行了重要扩展。首先是语义化物品表示:使用多级向量量化技术将每个物品转换为语义token序列,使模型能够理解物品的内容和含义而非仅仅是ID。其次是稀疏专家混合(MoE):在解码器的前馈网络中引入MoE层,通过激活少数专家子网络来显著增加模型容量而不成比例增加计算成本。最后是迭代偏好对齐(IPA):这是OneRec最具创新性的组件,它解决了推荐场景中难以获得显式偏好对比数据的问题。
IPA的工作机制如下:首先训练一个奖励模型来预测会话质量(如观看时长、点赞数等);然后使用当前OneRec模型为训练样本生成多个候选会话(通常128个);奖励模型对所有候选进行评分,选择最高分的作为“选择”响应\(S_w\),最低分的作为“拒绝”响应\(S_l\);最后使用直接偏好优化(DPO) (Rafailov et al., 2023) 损失函数更新模型。
OneRec在线上推荐场景的部署取得了1.68%的用户总观看时长提升,证明了端到端统一生成的实用价值。然而,这种方法也带来了训练流程的复杂性:需要依次训练量化模型、基础生成模型、奖励模型,然后进行迭代的IPA-DPO循环,对工程实现提出了较高要求。