2.3.2. 生成式召回方法¶
上一小节,我们探讨了如MIND和SDM等序列召回方法,它们的核心目标是分析用户的历史行为,并将其“总结”成一个或多个能够代表用户兴趣的向量。这种方法好比是为用户拍摄一张静态的“兴趣快照”,用以在海量物品中进行检索。
本节将介绍一种截然不同的思路:生成式召回。它不再试图去“总结”用户,而是直接“预测”用户的下一个行为。其核心是直接对序列中物品与物品之间的动态依赖关系进行建模,关注“用户接下来会做什么”而非“用户是怎样的人”。
依循这条思路,我们将探讨三种代表性的生成式召回模型,它们清晰地展示了该领域的一条核心演进脉络。首先是SASRec,它开创性地将自然语言处理领域的Transformer模型直接应用于推荐序列预测,奠定了“预测下一个物品ID”这一基础范式。
在SASRec验证了该范式的巨大潜力之后,后续的探索主要沿着两个方向继续深化:
深化对“输入”的理解:既然模型可以处理序列,我们能否给它提供一个信息更丰富的序列?HSTU模型在这个方向上做了进一步的探索。它不再满足于简单的物品ID,而是将用户的属性、行为类型、时间等所有异构信息都融合成一个复杂的“事件流”作为输入,增强了模型对行为上下文的理解能力。
改进物品表示方式:传统推荐系统中,物品通常用简单的ID来表示,这种方式虽然直观,但缺乏语义信息。TIGER 模型尝试了一种不同的思路:能否用更有意义的方式来表示物品?它提出将物品表示为由多个“码本”组成的“语义ID”,这样的表示方式不仅适用于预测目标,也可以用于输入序列中的历史物品。
本节中,我们将通过 SASRec (基础框架) -> HSTU (丰富输入) -> TIGER (改进表示) 这几个典型模型,来了解生成式召回技术的一些代表性思路。
2.3.2.1. SASRec:基于自注意力的序列推荐¶
在SASRec出现之前,主流的序列模型,如基于马尔可夫链或RNN的方法,存在各自的局限。马尔可夫链 (Rendle et al., 2010) 通常只考虑最近的少数几个行为,视野有限;而RNN (Dobrovolny et al., 2021) 虽然理论上能捕捉长期依赖,但其串行计算的特性导致训练效率低下。SASRec (Kang and McAuley, 2018) 的出发点便是:能否找到一种方法,既能像RNN一样看到完整的历史序列,又能高效地捕捉其中最重要的依赖关系?答案是借用在自然语言处理(NLP)领域大获成功的Transformer模型 (Vaswani et al., 2017) 。
SASRec的核心思想是将用户的行为序列视为一个句子来处理。对于序列中的每个物品,模型会自动学习它与序列中其他所有物品的相关性,然后基于这些相关性来预测下一个用户可能交互的物品。这样既保留了对长期行为的建模能力,又能根据数据特性灵活地调整对不同历史行为的关注度。

图2.3.3 生成式召回模型的基本架构¶
类似于Transformer,SASRec的基本模块如 图2.3.3 左 所示,主要包含自注意力层和前馈网络层两个组件。
自注意力层
对于序列中的每个物品,通过Embedding矩阵 \(\bf{M}\in\mathbb{R}^{|\mathcal{I}|\times d}\) 将其映射为d维向量,其中 \(|\mathcal{I}|\) 是物品总数。输入序列的Embedding矩阵记为 \(\bf{E}\in\mathbb{R}^{n\times d}\),其中 \(\bf{E}_i=\bf{M}_{s_i}\)。
由于自注意力机制本身无法感知位置信息,这里引入了可学习的位置Embedding \(\bf{P}\in\mathbb{R}^{n\times d}\),因此最终的序列输入表示为:
接下来,SASRec使用自注意力机制来捕捉序列中物品之间的依赖关系。具体来说,它采用了缩放点积注意力:
这里 \(\bf{Q}\)、\(\bf{K}\)、\(\bf{V}\) 分别表示查询、键、值矩阵。在自注意力中,这三个矩阵都由输入的Embedding序列通过线性变换得到:
其中 \(\bf{W}^Q\)、\(\bf{W}^K\)、\(\bf{W}^V\) 都是 \(d\times d\) 的可学习权重矩阵,\(\sqrt{d}\) 是缩放因子用于稳定训练。
值得注意的是,这里的自注意力机制需要采用因果掩码,确保在预测第 \(t\) 个位置的下一个物品时,模型只能利用 \(1\) 到 \(t-1\) 的历史信息,而不能‘偷看’未来的行为。
前馈网络层
得到自注意力层的输出后,前馈网络为模型引入了非线性变换能力:
其中 \(\bf{W}^{(1)}\)、\(\bf{W}^{(2)}\) 是权重矩阵,\(\bf{b}^{(1)}\)、\(\bf{b}^{(2)}\) 是偏置向量,\(\bf{F}_i\) 是第\(i\)层前馈网络的输出。
预测与训练
经过多层Transformer模块的加工后,模型会基于最后一个物品(第\(t\)个)的输出表示\(\bf{F}_t\),来预测用户最可能交互的下一个物品\(i\)。这个预测过程,本质上就是在整个物品库中,寻找与该输出表示向量最相似的物品向量。
物品\(i\)的相关性分数为:
这里复用了物品Embedding矩阵 \(\bf{M}\),既减少了参数量又提高了性能。
类似于Decoder Only的Transformer模型,SASRec的训练目标也是预测用户下一个交互的物品。对于时间步t,期望输出 \(o_t\) 定义为:
其中\(\texttt{<pad>}\)表示填充项,\(\mathcal{S}^{u}\)表示用户\(u\)的交互序列。模型训练时,输入为\(s\),期望输出为\(o\),采用二元交叉熵作为损失函数:
其中 \(\sigma\) 是sigmoid函数,\(r_{o_t,t}\) 是正样本分数,\(r_{j,t}\) 是负样本分数。
核心代码
SASRec的核心在于将位置编码与序列嵌入相结合,然后通过多层Transformer模块处理:
# 位置编码与序列嵌入相加
position_embedding = PositionEncodingLayer(
dims=emb_dim,
max_len=max_seq_len,
trainable=True,
initializer='glorot_uniform',
)(sequence_embedding)
sequence_embedding = add_tensor_func([sequence_embedding, position_embedding])
# 多头注意力层,使用因果掩码确保只看到历史信息
for i in range(mha_num):
sequence_embedding_norm = tf.keras.layers.LayerNormalization()(
sequence_embedding
)
sequence_embedding_output = tf.keras.layers.MultiHeadAttention(
num_heads=nums_heads,
key_dim=emb_dim,
dropout=dropout,
name=f"{i}_block",
)(sequence_embedding_norm, sequence_embedding, use_causal_mask=True)
# 残差连接
sequence_embedding = add_tensor_func(
[sequence_embedding, sequence_embedding_output]
)
sequence_embedding = tf.keras.layers.LayerNormalization()(sequence_embedding)
# 前馈网络层
sequence_embedding = DNNs(
units=[emb_dim, emb_dim],
dropout_rate=dropout,
activation='relu',
name=f"{i}_dnn",
)(sequence_embedding)
关键的设计点包括:(1) use_causal_mask=True
确保预测第\(t\)个位置时只能看到前\(t-1\)个位置;(2)
残差连接和层归一化稳定训练;(3)
前馈网络增强非线性表达能力。最后取序列最后一个位置的输出表示用户当前兴趣,用于预测下一个物品。
训练和评估
from funrec import run_experiment
run_experiment('sasrec')
+---------------+--------------+-----------+----------+
| hit_rate@10 | hit_rate@5 | ndcg@10 | ndcg@5 |
+===============+==============+===========+==========+
| 0.0154 | 0.0076 | 0.0066 | 0.0041 |
+---------------+--------------+-----------+----------+
2.3.2.2. HSTU:为复杂的“事件流”输入定制生成式架构¶
SASRec成功地验证了将推荐问题视为序列预测的可行性,但它将视线聚焦于一个相对简化的世界:一个仅由物品ID构成的序列。一个自然而然的问题是:用户的行为序列远比这丰富,能否将用户的属性、行为类型(点击、加购、购买)、上下文时间等所有信息都融入这个序列,让模型拥有一个更全面的“上帝视角”?
HSTU (Zhai et al., 2024) 模型正是对这个问题的一次深入探索。它代表了生成式范式的一个重要演进方向:不再满足于简单的物品ID序列,而是将所有异构特征统一编码为单一的、更复杂的“事件流”(Event Stream)作为模型输入。 HSTU的目标,就是学习这个复杂的“句子”,并预测下一个可能的事件。
这种统一化的架构设计虽然优雅,但在实现过程中面临着诸多技术挑战。HSTU的设计巧妙地解决了特征处理、模型架构和信号传递等关键问题,旨在用单一的模块替换传统推荐模型中特征提取、交互和预测等多个异构组件。
特征处理
HSTU的特征处理分为两个策略。对于类别特征,它将所有信息按时间戳“拉平”成一个统一的序列。想象一个用户的行为流:[用户年龄=30, 登录, 浏览物品A(类别:手机), 浏览物品B(类别:手机壳), 将B加入购物车, 退出]。SASRec可能只看到
[A, B]。而HSTU则试图理解整个事件流:[(特征:年龄,值:30), (行为:登录), (行为:浏览,物品:A), (行为:浏览,物品:B), (行为:加购,物品:B), (行为:退出)]。
对于变化频繁的数值特征(如加权计数器、比率等),HSTU则采用隐式建模策略,让模型通过观察用户在序列中的实际行为模式来自动推断这些数值信息。
因此,HSTU的输入输出可以表示为:
输入(\(x_i\)):\((\Phi_0,a_0), (\Phi_1,a_1), \ldots, (\Phi_{n_c-1},a_{n_c-1})\)
输出(\(y_i\)):\(\Phi_1',\Phi_2',\ldots,\Phi_{n_c-1}',\varnothing\),
其中 \(\Phi_i\) 表示用户在时刻 \(i\) 交互的内容,\(a_i\) 表示用户在时刻 \(i\) 的行为,\(\Phi_i'\) 表示用户在时刻 \(i\) 交互的内容,\(\Phi_i' = \Phi_i\) (如果 \(a_i\) 为正向行为),否则为 \(\varnothing\)。
在推荐系统的召回阶段,模型学习一个条件分布\(p(\Phi_{i+1}|u_i)\),其中 \(u_i\) 是用户在当前时刻的表示向量,\(\Phi_{i+1}\) 是候选物品。召回的目标是从物品库 \(\mathbb{X}_c\) 中选择能够最大化用户满意度的物品,即 \(\text{argmax}_{\Phi \in \mathbb{X}_c} p(\Phi|u_i)\)。HSTU召回与标准的序列生成任务有两个不同的地方:首先用户可能对推荐的物品产生负面反应,因此监督信号不总是下一个物品;其次当序列中包含非交互相关的特征(如人口统计学信息)时,对应的输出标签是未定义的。通过这种方式,HSTU将复杂的推荐问题转化为序列到序列的学习问题,使得模型能够基于用户的历史行为序列预测其未来可能感兴趣的内容。
架构统一:HSTU单元
为了用一个模块就能替换DLRM中的异构组件,HSTU引入了层次序列转换单元(Hierarchical Sequential Transduction Unit,HSTU) 如 图2.3.3 右所示。HSTU由堆叠的相同层组成,每层包含三个关键子模块:
点向投影(Pointwise Projection):使用单一线性变换后分割的方式同时产生注意力计算所需的查询、键、值以及门控权重: \(U(X), V(X), Q(X), K(X) = \text{Split}(\phi_1(f_1(X)))\)
点向聚合(Pointwise Aggregation):采用点向聚合而非传统Softmax来保持推荐系统中用户偏好强度信息: \(A(X)V(X) = \phi_2\left(Q(X)K(X)^T + \text{rab}^{p,t}\right)V(X)\)
点向转换(Pointwise Transformation):使用门控机制实现类似MoE的特征选择能力: \(Y(X) = f_2\left(\text{Norm}\left(A(X)V(X)\right) \odot U(X)\right)\)
其中:\(f_i(X) = W_i X + b_i\)表示线性变换,\(\phi_1\)和\(\phi_2\)使用SiLU激活函数,\(\text{Norm}\)表示Layer Normalization(层归一化),\(\text{rab}^{p,t}\)表示包含位置和时间信息的相对注意力偏置,\(\odot\)表示元素级乘法。
这三个子模块巧妙地统一处理了传统DLRM的三个主要阶段:特征提取通过注意力机制实现目标感知的特征池化;特征交互通过门控机制实现从原始特征到交叉特征的动态结合,注意力部分(\(A(X)V(X)\))捕捉高阶关系,门控部分(\(U(X)\))保留低阶信息;表示转换中门控信号\(U(X)\)充当为每个特征维度定制的“路由器”,实现类似MoE的条件计算效果。
替换Softmax归一化机制
HSTU Pointwise Aggregation 步骤放弃了传统的Softmax归一化,而使用了不一样的聚合方式。传统Transformer使用Softmax注意力虽然在语言任务中表现优异,但在推荐场景下存在信息丢失的问题。在推荐场景中,用户兴趣的“强度”是一个至关重要的信号。传统的Softmax注意力机制会将所有历史行为的注意力权重归一化,使其总和为1。这本质上是在计算一种相对重要性,而非绝对相关性,从而扭曲了真实的偏好强度。例如,假设目标是推荐一部科幻电影。用户A的历史记录中有10部科幻片和1部喜剧片,而用户B只有1部科幻片和1部喜剧片。对于用户A,其对科幻的强烈偏好是一个非常强的信号。然而,Softmax归一化可能会迫使这10部科幻片瓜分注意力权重,从而削弱“大量观看科幻”这一整体信号的强度,使其与用户B的信号差异不再显著。相比之下,HSTU的点向聚合(通过SiLU激活)独立计算每个历史物品的相关性得分,不进行跨项归一化。这使得模型能够保留偏好的原始强度——用户A历史中的科幻片可以共同产生一个非常高的激活总分,这对于准确预估点击率、观看时长等具体数值至关重要,而不仅仅是进行排序。
训练与召回
HSTU的完整工作流程包含训练和召回两个阶段。在训练阶段,模型基于前面描述的输入输出格式进行标准的Transformer训练——通过预测用户行为序列中的下一个正向交互物品来学习用户偏好模式和物品间的依赖关系。在召回阶段,经过多层HSTU编码器处理后,模型将用户的完整行为事件序列转换为能够概括用户历史、捕捉当前兴趣的实时动态表示\(u_i\)。拥有了用户表示向量\(u_i\)后,召回过程就转变为一个标准的向量检索问题——将\(u_i\)与物品语料库中所有物品的Embedding向量进行高效的相似度计算,通过近似最近邻(ANN)搜索从海量物品池中快速检索出与用户当前兴趣最匹配的Top-K个物品,形成召回列表。
总而言之,如果说SASRec是将推荐序列视为一句由’单词’(物品ID)组成的句子,那么HSTU则是将推荐场景中的所有信息(用户属性、行为、物品、上下文)都看作一种更复杂的’语言’,并为此设计了一套全新的’语法规则’(HSTU单元)来理解和生成这种语言。它的核心创新在于丰富了模型的输入,从而实现了对用户行为更深层次的理解。
核心代码
HSTU的核心在于其定制的注意力机制,它通过SiLU激活和门控机制实现了点向聚合,避免了传统Softmax的归一化:
class HstuLayer(tf.keras.layers.Layer):
"""HSTU层实现点向聚合的注意力机制"""
def __init__(self, num_units, num_heads, attention_type='dot_product',
dropout_rate=0, causality=False):
super(HstuLayer, self).__init__()
self.num_units = num_units
self.num_heads = num_heads
self.attention_type = attention_type
self.dropout_rate = dropout_rate
self.causality = causality
def build(self, input_shape):
# 点向投影:同时产生Q、K、V(这里简化为独立投影)
self.query_dense = tf.keras.layers.Dense(
self.num_units, activation=None, use_bias=False, name='query_projection'
)
self.key_dense = tf.keras.layers.Dense(
self.num_units, activation=None, use_bias=False, name='key_projection'
)
self.value_dense = tf.keras.layers.Dense(
self.num_units, activation=None, use_bias=False, name='value_projection'
)
def silu(self, x):
"""SiLU (Swish) 激活函数,用于点向聚合"""
return x * tf.sigmoid(x)
def call(self, inputs, input_interval=None, training=True):
queries = keys = inputs
batch_size = tf.shape(queries)[0]
# 点向投影:线性变换生成Q、K、V
Q = self.query_dense(queries) # (N, T_q, C)
K = self.key_dense(keys) # (N, T_k, C)
V = self.value_dense(keys) # (N, T_k, C)
# 分割多头
Q_ = tf.reshape(Q, [batch_size * self.num_heads, -1,
self.num_units // self.num_heads])
K_ = tf.reshape(K, [batch_size * self.num_heads, -1,
self.num_units // self.num_heads])
V_ = tf.reshape(V, [batch_size * self.num_heads, -1,
self.num_units // self.num_heads])
# 应用SiLU激活(HSTU特色)
Q_, K_, V_ = self.silu(Q_), self.silu(K_), self.silu(V_)
# 点向聚合:计算注意力但不使用Softmax归一化
outputs = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1])) # (h*N, T_q, T_k)
# 因果掩码(用于序列预测)
if self.causality:
diag_vals = tf.ones_like(outputs[0, :, :])
tril = tf.linalg.band_part(diag_vals, -1, 0)
causality_mask = tf.tile(tf.expand_dims(tril, 0),
[tf.shape(outputs)[0], 1, 1])
paddings = tf.ones_like(causality_mask) * (-(2 ** 32) + 1)
outputs = tf.where(tf.equal(causality_mask, 0), paddings, outputs)
# 这里不使用Softmax,而是直接应用激活(保留强度信息)
weights = self.silu(outputs) # 点向聚合的核心:用SiLU代替Softmax
# 加权求和(点向转换)
attention_output = tf.matmul(weights, V_)
# 合并多头
outputs = tf.reshape(attention_output,
[batch_size, -1, self.num_units])
# 残差连接
outputs += queries
return outputs
HSTU的关键设计在于用SiLU激活代替Softmax归一化。传统Softmax会将注意力权重归一化使其和为1,这抹平了不同用户兴趣强度的差异。而HSTU通过
weights = self.silu(outputs)
保持了原始的相关性强度,使得历史行为丰富的用户能够产生更强的激活信号,更准确地反映用户的真实偏好强度。
训练和评估
run_experiment('hstu')
+---------------+--------------+-----------+----------+
| hit_rate@10 | hit_rate@5 | ndcg@10 | ndcg@5 |
+===============+==============+===========+==========+
| 0.0174 | 0.0073 | 0.0075 | 0.0042 |
+---------------+--------------+-----------+----------+
2.3.2.3. TIGER:用语义ID重新定义物品表示¶
HSTU通过丰富输入信息,提升了模型对用户行为上下文的理解能力。然而,生成式召回的演进还有另一条同样重要的路径。这条路径不仅关注输出侧的改进,更是对整个推荐范式的重新思考:传统推荐系统中,无论是输入序列还是预测目标,物品都被表示为孤立的、无语义的原子ID。这种表示方式真的是最佳选择吗?
直接使用原子ID存在两个固有局限: 1. 语义鸿沟:模型难以理解物品间的内在联系。它不知道“耐克篮球鞋A”和“耐克篮球鞋B”在本质上高度相似,这种相似性只能通过海量共现数据间接学习,效率低下。 2. 泛化难题:对于从未在训练集中出现过的新物品(冷启动问题),模型完全无法进行推荐,因为它的词汇表中根本没有这个ID。
TIGER (Transformer Index for GEnerative Recommenders) (Rajput et al., 2023) 模型正是基于这一思考而提出的创新方案。它的核心理念很直观:与其让模型预测毫无语义信息的原子ID,不如让它生成能够描述物品内在语义的结构化’语义ID’。
想象一下,如果我们能让模型理解“耐克篮球鞋A”和“耐克篮球鞋B”在语义上的相似性,那么即使某款新鞋从未在训练数据中出现过,模型也能基于其语义特征进行合理的推荐。这正是TIGER想要解决的核心问题。通过引入语义ID,模型不仅能够在相似物品间共享知识,还能用更紧凑的方式表示庞大的物品库。
TIGER的实现思路分为两步:先根据物品的内容特征为每个物品构建一个语义ID,然后基于这些语义ID组成的序列来训练生成式推荐模型。
语义ID的生成 (RQ-VAE)
语义ID的核心是为每个物品创建一个语义上有意义的码本元组。内容特征相似的物品,其语义ID也应当相似(部分重叠),从而让模型能学习物品间的深层语义关系。
TIGER采用残差量化变分自编码器 (RQ-VAE) (Zeghidour et al., 2021) 来实现这一目标。RQ-VAE是一种多层向量量化器,它通过对残差进行迭代量化来生成语义ID元组(码本)。
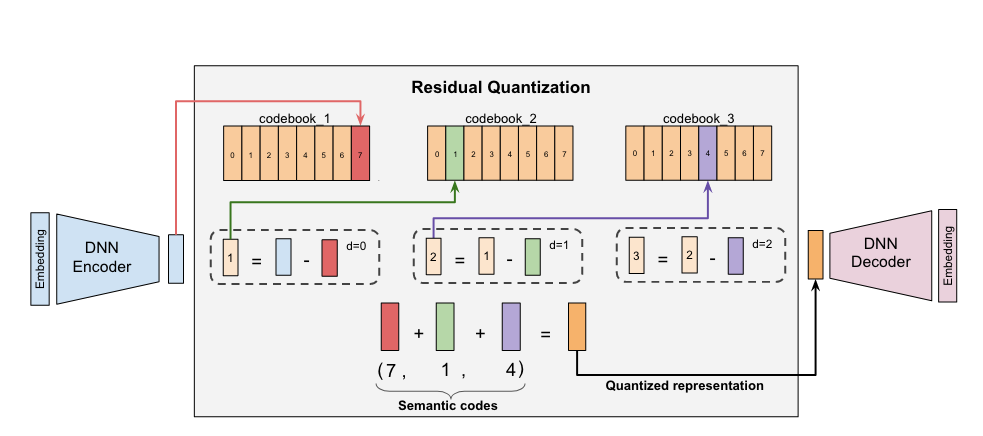
图2.3.4 RQ-VAE量化方法¶
具体过程如下:
一个预训练的内容编码器(如Sentence-T5)先将物品内容特征(如标题、描述)处理成语义Embedding向量 \(\mathbf{x}\)。
RQ-VAE的编码器 \(\mathcal{E}\) 将输入向量 \(\mathbf{x}\) 进一步编码为潜在表示 \(\mathbf{z} := \mathcal{E}(\mathbf{x})\),并将初始残差定义为 \(\mathbf{r}_0 := \mathbf{z}\)。
模型包含 \(m\) 个层级,每个层级 \(d \in \{0, 1, ..., m-1\}\) 都有一个独立的码本 \(\mathcal{C}_d\)。在第 \(d\) 层,通过在码本中寻找与当前残差 \(\mathbf{r}_d\) 最接近的码本索引来完成量化:
(2.3.24)¶\[c_d = \arg\min_{k} \|\mathbf{r}_d - \mathbf{e}_k\|^2 \quad \text{其中 } \mathbf{e}_k \in \mathcal{C}_d\]计算新的残差并送入下一层:
(2.3.25)¶\[\mathbf{r}_{d+1} := \mathbf{r}_d - \mathbf{e}_{c_d}\]重复此过程 \(m\) 次,最终得到一个由 \(m\) 个码本组成的语义ID元组 \((c_0, c_1, ..., c_{m-1})\)。
RQ-VAE通过一个联合损失函数进行端到端训练,该函数包含重构损失(确保解码器能从量化表示中恢复原始信息)和量化损失(用于更新码本),从而联合优化编码器、解码器和所有码本向量。
为确保唯一性,如果多个物品在量化后产生了完全相同的语义ID,TIGER会在ID末尾追加一个额外的索引位来区分它们,例如
(12, 24, 52, 0) 和 (12, 24, 52, 1)。
基于语义ID的生成式检索
拥有了每个物品的语义ID后,推荐任务就转变为一个标准的序列到序列生成问题。
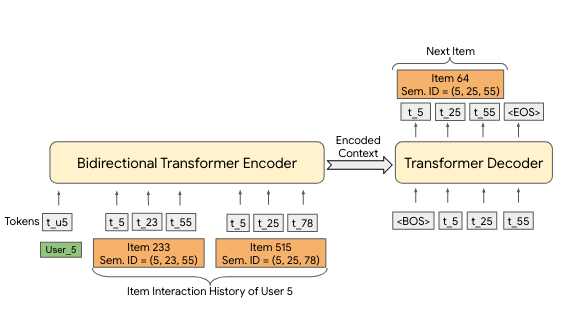
图2.3.5 基于语义ID的生成式检索¶
将用户的历史交互序列 \((\text{item}_1, \text{item}_2, ..., \text{item}_n)\) 转换为其对应的语义ID序列:
(2.3.26)¶\[((c_{1,0}, ..., c_{1,m-1}), (c_{2,0}, ..., c_{2,m-1}), ..., (c_{n,0}, ..., c_{n,m-1}))\]其中 \((c_{i,0}, ..., c_{i,m-1})\) 是 \(\text{item}_i\) 的语义ID
将每个物品的语义ID元组展平,形成一个长序列作为Transformer模型的输入:
(2.3.27)¶\[(c_{1,0}, ..., c_{1,m-1}, c_{2,0}, ..., c_{2,m-1}, ..., c_{n,0}, ..., c_{n,m-1})\]训练一个标准的Encoder-Decoder Transformer模型。Encoder负责理解用户历史序列的上下文,Decoder则自回归地、逐个码本地生成下一个最可能被用户交互的物品语义ID \((c_{n+1,0}, ..., c_{n+1,m-1})\)。
在推理阶段,一旦生成了完整的预测语义ID,就可以通过查找表将其映射回具体的物品,完成推荐。