冷启动问题¶
内容冷启动¶
在推荐系统的发展历程中,内容冷启动一直是一个核心挑战。新上线的物品由于缺乏用户交互历史,传统的协同过滤方法难以为其提供有效推荐。而基于内容的方法虽然能够处理新物品,但推荐质量往往不如协同过滤。
针对这一挑战,研究者们提出了多种创新解决方案。本节将重点介绍两种具有代表性的方法:CB2CF(Content-Based to Collaborative Filtering)和MetaEmbedding。CB2CF通过学习内容特征到协同过滤表示的映射关系,让新物品能够直接获得协同过滤质量的推荐效果;MetaEmbedding则通过元学习的思想,利用物品的辅助属性信息为新物品生成更好的初始embedding表示。这两种方法从不同角度解决了内容冷启动问题,为推荐系统的实际应用提供了有效的技术支撑。
CB2CF¶
协同过滤依赖用户-物品交互数据学习用户偏好和物品特征,能够发现复杂的隐式关联模式,但面对新物品时束手无策。基于内容的方法利用物品的属性信息进行推荐,可以处理新物品,但往往只能捕捉 到表面的相似性。
CB2CF(Content-Based to Collaborative Filtering)的核心思想是学习从物品内容特征到协同过滤表示的映射关系。对于那些既有内容描述又有丰富用户交互的物品,我们可以同时获得它们的内容特征向量和协同过滤嵌入向量。通过深度神经网络学习这两种表示之间的映射函数,新物品就能够基于其内容特征直接获得高质量的协同过滤表示。
CB2CF模型架构¶
CB2CF采用多视图深度学习架构,主要包含以下组件:
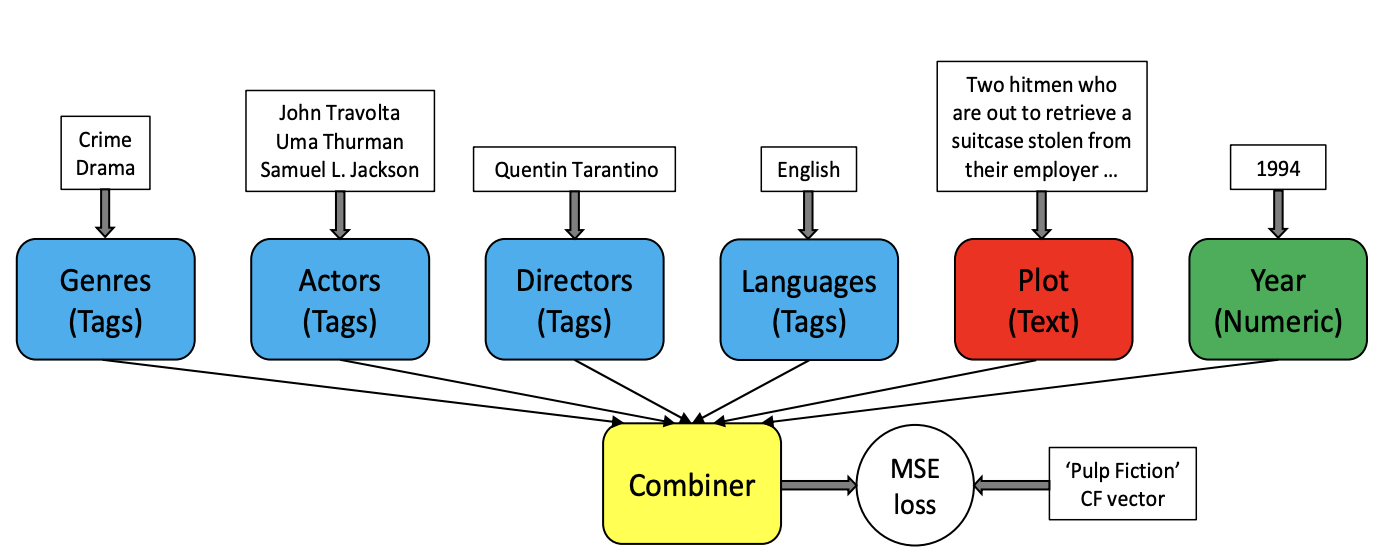
CB2CF架构¶
从架构图可以看出,CB2CF模型主要由以下三个核心模块构成。
内容编码器(Content Encoder):负责将物品的多模态内容特征(如文本描述、图像、类别等)编码为统一的内容表示向量。对于不同类型的内容特征,模型采用相应的编码器进行处理,例如使用卷积神经网络处理图像特征,使用循环神经网络或Transformer处理文本特征。
映射网络(Mapping Network):这是CB2CF的核心组件,由多层全连接神经网络构成,负责学习从内容特征空间到协同过滤嵌入空间的非线性映射关系。映射网络通过深度学习的方式捕捉内容特征与用户偏好之间的复杂关联。
约束优化模块(Constraint Optimization):通过余弦相似度约束确保映射后的表示与真实的协同过滤嵌入在语义上保持一致。这个模块是训练过程中的关键,它保证了模型学习到的映射关系的有效性。
协同过滤向量生成¶
在CB2CF中,协同过滤向量可以通过多种方法生成。对于有交互历史的物品,模型可以通过不同的协同过滤算法学习得到物品的嵌入向量。常见的协同过滤向量生成方法如下。
矩阵分解方法:给定用户-物品交互矩阵\(R \in \mathbb{R}^{m \times n}\),其中\(m\)为用户数量,\(n\)为物品数量,通过分解\(R \approx UV^T\)来学习用户嵌入矩阵\(U \in \mathbb{R}^{m \times d}\)和物品嵌入矩阵\(V \in \mathbb{R}^{n \times d}\),其中\(d\)为嵌入维度。物品\(i\)的协同过滤向量即为\(V\)的第\(i\)行\(v_i\)。
双塔召回模型:通过构建用户塔和物品塔的深度神经网络架构,分别将用户特征和物品特征编码为低维向量表示。物品塔输出的向量即为物品的协同过滤嵌入,这种方法能够更好地处理稀疏特征和复杂的非线性关系。
其他深度学习方法:如神经协同过滤(NCF)、自编码器等方法也能生成高质量的物品嵌入向量,这些方法通过深度神经网络学习用户-物品交互的复杂模式。
CB2CF通过学习映射函数\(f: \mathcal{C} \rightarrow \mathcal{V}\),将新物品的内容特征\(c_i\)映射到协同过滤空间,得到\(\hat{v}_i = f(c_i)\)。这样新物品就能获得与已有物品在语义上一致的协同过滤表示。
MetaEmbedding¶
CB2CF通过学习内容特征到协同过滤表示的映射,有效解决了新物品的冷启动问题。然而,在实际应用中,我们还面临着另一个挑战:如何为新物品生成更好的初始embedding表示?传统做法通常采用随机初始化新物品的embedding,但这种简单粗暴的方式往往导致新物品在初期表现不佳,需要大量交互数据才能收敛到有效状态。
MetaEmbedding正是针对这一问题提出的解决方案。与CB2CF专注于学习内容到协同过滤的映射不同,MetaEmbedding关注的是如何利用物品的辅助属性信息,通过元学习的思想为新物品生成更好的初始embedding。
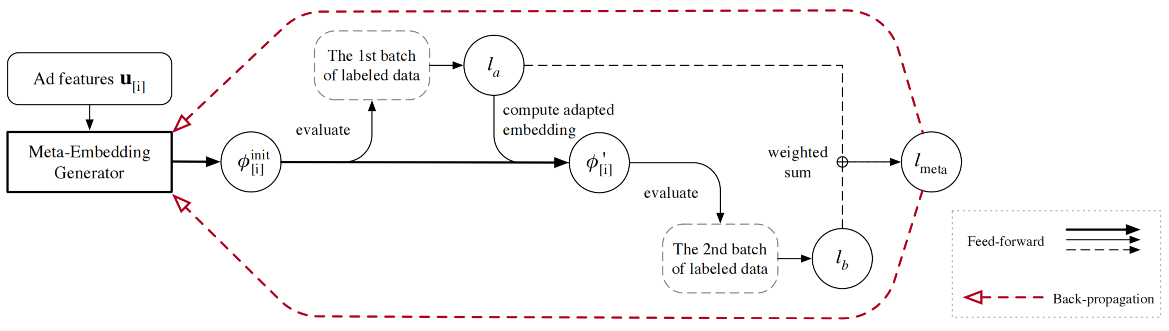
MetaEmbedding两阶段训练¶
MetaEmbedding采用基于SGD的元学习训练算法,其核心思想是通过模拟物品从冷启动到预热的完整过程来优化embedding生成器。该算法为每个物品ID学习一个能够快速适应的初始embedding,从而解决新物品的冷启动问题。
算法的输入包括预训练的基础模型\(f_\theta\)、所有现有物品ID的集合\(\mathcal{I}\)、元损失的权重系数\(\alpha\),以及梯度更新的步长参数\(a\)和\(b\)。训练过程首先随机初始化Meta-Embedding生成器的参数\(w\),然后在主循环中重复执行以下操作直到收敛。
在每次迭代中,算法从物品集合\(\mathcal{I}\)中随机采样\(n\)个物品ID,记为\(\{i_1, i_2, \ldots, i_n\}\)。对于每个采样的物品\(i\),算法执行双阶段训练过程。
初始Embedding生成阶段。算法使用Meta-Embedding生成器为物品\(i\)生成初始embedding:
其中\(\boldsymbol{u}_{[i]}\)表示物品\(i\)的特征向量,\(h_w\)是参数为\(w\)的生成器函数。随后,算法为物品\(i\)采样两个mini-batch:第一批标注数据\(\mathcal{D}_{[i]}^a\)和第二批标注数据\(\mathcal{D}_{[i]}^b\),每批均包含\(K\)个样本。
梯度适应与评估阶段。算法首先在第一批数据\(\mathcal{D}_{[i]}^a\)上评估初始embedding的损失\(l_a(\phi_{[i]}^{\text{init}})\),然后计算适应后的embedding:
这一步骤模拟了物品在获得少量交互数据后的快速适应过程。接着,算法在第二批数据\(\mathcal{D}_{[i]}^b\)上评估适应后embedding的损失\(l_b(\phi_{[i]}')\)。
算法的关键创新在于其元损失函数的设计。对于每个物品\(i\),算法计算综合的元损失:
该损失函数巧妙地平衡了初始embedding的直接质量和经过适应后的性能。权重系数\(\alpha\)控制着两个目标的相对重要性:既要保证生成的初始embedding在冷启动时表现良好,又要确保其具备快速适应的能力。
最后,算法使用所有采样物品的元损失来更新生成器参数:
这种双阶段机制的深层含义在于优化embedding的“可学习性”而非embedding本身。通过在大量现有物品上重复“初始化→适应→评估”的过程,Meta-Embedding生成器学会了如何为新物品提供一个既有良好初始性能,又具备强适应潜力的embedding起点。当面对真正的新物品时,生成器能够基于其内容特征直接输出一个“聪明”的初始embedding,该embedding经过少量真实交互数据的训练后能够快速收敛到高质量的表示,从而显著改善冷启动性能。
用户冷启动¶
除了内容冷启动之外,推荐系统还面临着另一个重要挑战——用户冷启动。与内容冷启动关注新物品的推荐不同,用户冷启动问题聚焦于如何为新用户提供高质量的个性化推荐。当新用户刚加入推荐系统时,由于缺乏历史交互数据,传统的协同过滤方法难以准确捕捉其偏好特征,往往只能提供基于流行度的通用推荐,导致用户体验不佳。
下面将重点介绍两种用户冷启动解决方案:MeLU(Meta-Learned User preference estimator)和POSO。MeLU是基于元学习的方法,通过MAML (Model-Agnostic Meta-Learning)框架学习用户偏好估计器,能够基于少量交互快速捕捉新用户的个性化偏好;POSO则采用分人群的架构设计思路,通过引入多个用户群体专用的子模块和个性化门控机制来解决用户冷启动问题。这两种方法分别从元学习和模型架构优化的角度展示了解决推荐系统冷启动问题的不同思路。
MELU¶
正如我们在MetaEmbedding中看到的,元学习为解决冷启动问题提供了一种全新的思路——通过学习如何快速适应新任务来应对数据稀缺的挑战。这一思想同样适用于用户冷启动场景:我们可以将每个新用户的偏好学习视为一个独立的学习任务,通过元学习框架训练一个能够快速适应新用户偏好的模型。
MeLU的核心思想是将每个用户的偏好学习视为一个独立的学习任务,通过元学习框架训练一个能够快速适应新用户偏好的推荐模型。与传统方法不同,MeLU不仅关注如何基于少量交互数据进行推荐,还创新性地提出了证据候选选择策略,用于确定最能区分用户偏好的物品集合。
具体而言,MeLU将推荐问题建模为一个评分预测任务。给定用户\(u\)和物品\(i\),模型需要预测用户对物品的评分\(r_{ui}\)。模型的核心是一个用户偏好估计器,由用户嵌入、物品嵌入以及多层决策网络组成。与传统方法为每个用户学习固定嵌入不同,MeLU学习的是一个能够快速生成个性化用户表示的元模型。
双阶段元学习机制¶
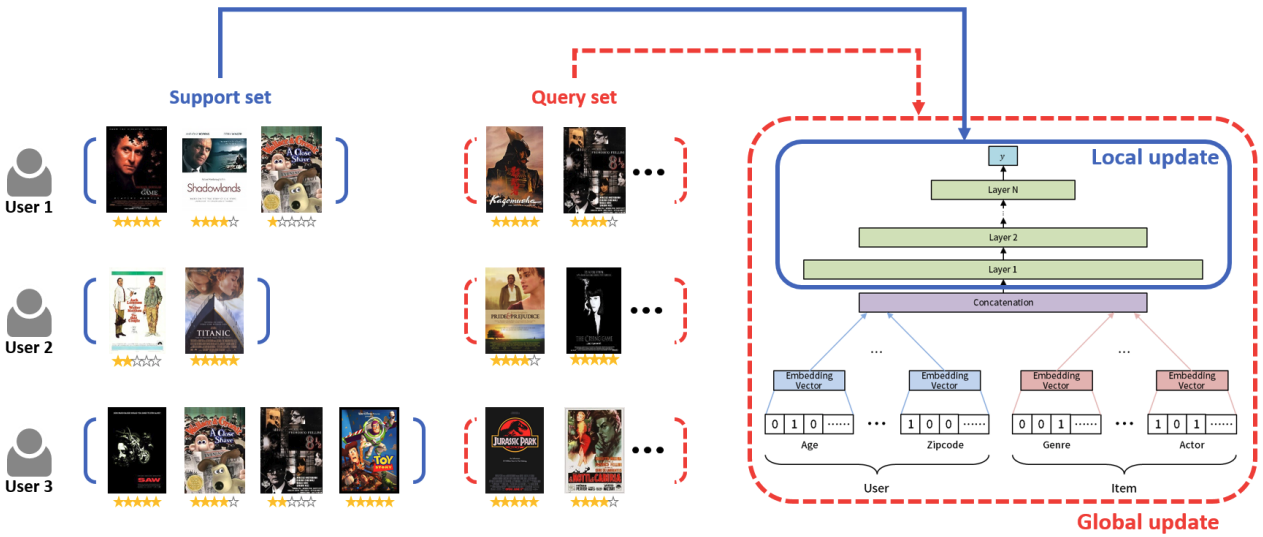
MeLU双阶段训练¶
MeLU的训练过程严格遵循MAML(Model-Agnostic Meta-Learning)框架。MAML的核心思想是“学会如何学习”——它不是让模型在某个特定任务上表现最优,而是让模型学习到一个好的初始化状态,使其能够用少量样本快速适应新任务。这正是解决用户冷启动的理想思路:为每个新用户提供一个良好的起点,然后基于他们的少量交互快速个性化。针对推荐系统的特点,MeLU的算法采用双层参数结构:
\(\theta_1\)控制用户和物品的embedding参数
\(\theta_2\)负责模型的核心决策网络参数。
整个训练过程可以形式化为以下步骤。
算法初始化:随机初始化两组参数\(\theta_1\)和\(\theta_2\),设定内循环学习率\(\alpha\)和外循环学习率\(\beta\)。
批次用户采样:在每个训练迭代中,从用户分布\(p(\mathcal{B})\)中采样一个用户批次\(B\),确保训练过程能够覆盖不同类型的用户偏好模式。
内循环适应阶段:对于批次中的每个用户\(i\),算法执行以下本地适应过程。
将用户特定参数初始化为全局参数:\(\theta_2^i = \theta_2\)
基于用户的交互历史计算梯度:\(\nabla_{\theta_2^i} \mathcal{L}_i'(f_{\theta_1, \theta_2^i})\)
执行本地参数更新:\(\theta_2^i \leftarrow \theta_2^i - \alpha \nabla_{\theta_2^i} \mathcal{L}_i'(f_{\theta_1, \theta_2^i})\)
外循环元更新阶段:使用所有用户的适应后参数,同时更新两组全局参数:
与标准MAML不同,MeLU的关键创新在于参数分离设计。\(\theta_1\)负责学习用户和物品的通用embedding表示,这些表示在所有用户间共享;而\(\theta_2\)专门负责快速适应个体用户的决策偏好。这种设计使得模型既能保持良好的表示学习能力,又能在面对新用户时实现快速的个性化适应。
POSO¶
与MeLU从元学习角度解决用户冷启动不同,POSO(Personalized COld Start MOdules)从模型架构设计的角度提出了一种全新的解决思路。POSO的核心洞察在于:用户冷启动问题的根本原因并非仅仅是数据稀缺,更重要的是新用户与老用户行为分布的巨大差异,以及现有模型在处理这种不平衡分布时的“个性化淹没”(Submergence Problem)现象。所谓个性化淹没,是指当新用户数量远少于老用户时,即使模型有“是否新用户”这样的特征,训练过程也会被占多数的老用户数据主导,导致模型学会忽略这个严重不平衡的特征。结果就是新用户的个性化信号被老用户的主导模式淹没,无法得到真正个性化的推荐。
新老用户的行为差异如下图 poso_feature
所示:新用户通常表现出更高的点赞率(因为新鲜感)、更高的完播率(产品机制倾向于推送更短的视频)、但更低的观看时长和视频播放量(尚未形成使用粘性)。这种分布差异使得单一模型难以同时服务好两类用户群体。
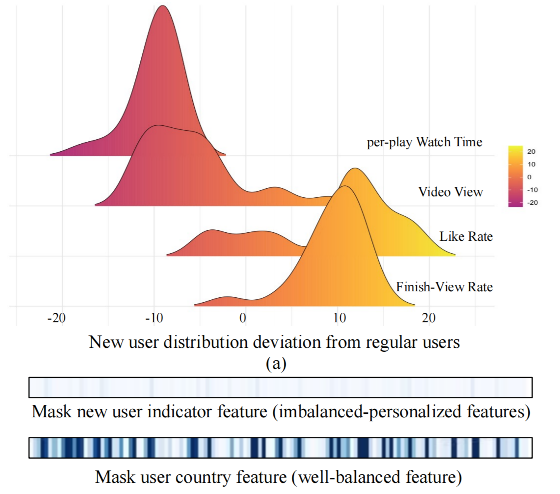
POSO新老用户行为差异¶
POSO的设计具有很强的通用性,可以灵活地集成到推荐系统的各种神经网络模块中。下面详细介绍POSO在三种典型模块中的具体应用方式,分别为MLP、MAH及MMoE。
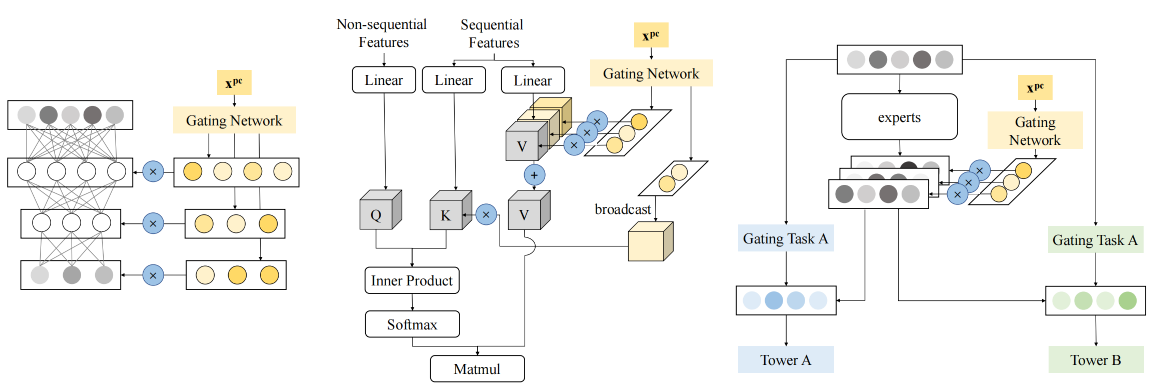
POSO模型结构¶
POSO-MLP¶
在传统的多层感知机(MLP)中,所有用户共享相同的权重参数。POSO-MLP通过引入多个并行的MLP子网络来解决这一问题,具体结构如下。
子模块设计:假设原始MLP层的变换为\(y = \sigma(Wx + b)\),POSO-MLP引入\(K\)个并行的MLP子模块,每个子模块\(i\)具有独立的权重矩阵\(W_i\)和偏置向量\(b_i\):
门控机制:个性化门控网络接收用户的个性化编码\(x^{pc}\)(如is_new_user、用户活跃度等特征),输出各子模块的权重:
最终输出:POSO-MLP的输出为所有子模块的加权组合:
这种设计使得新用户可以主要依赖专门为其优化的子模块,而老用户则使用另一组专门的子模块,有效避免了特征淹没问题。
POSO-MHA¶
多头注意力机制(Multi-Head Attention, MHA)在序列建模中发挥着重要作用。POSO-MHA通过为不同用户群体提供专门的注意力头来实现个性化,具体设计如下。
多组注意力头:传统MHA包含\(H\)个注意力头,POSO-MHA扩展为\(K\)组注意力头,每组包含\(H\)个头。第\(i\)组的第\(h\)个注意力头定义为:
其中\(W_i^Q\)、\(W_i^K\)、\(W_i^V\)是第\(i\)组专用的查询、键、值变换矩阵。
组内聚合:每组内的多个注意力头通过拼接进行聚合:
个性化门控:门控网络根据用户特征决定各组注意力的权重:
这种设计让新用户和老用户能够关注到不同的序列模式,新用户的注意力机制可能更关注内容的新颖性和多样性,而老用户则更关注与历史偏好的匹配度。
POSO-MMoE¶
多任务学习中的专家混合模型(Multi-gate Mixture-of-Experts, MMoE)本身就具有专家分工的思想,POSO-MMoE在此基础上进一步引入用户群体的个性化,具体结构如下。
分层专家结构:POSO-MMoE采用以下两层专家结构。
底层专家:\(E\)个共享专家\(\{e_1, e_2, \ldots, e_E\}\),负责学习通用的特征表示
顶层专家组:\(K\)个专家组,每组包含\(M\)个专门化专家,第\(i\)组的第\(j\)个专家记为\(s_{i,j}\)
双重门控机制
任务门控:每个任务\(t\)有独立的门控网络,决定底层专家的权重:
()¶\[\alpha_t = \text{softmax}(W_t^{task} \cdot x + b_t^{task})\]个性化门控:根据用户特征决定专家组的权重:
()¶\[\beta = \text{softmax}(W^{pc} \cdot x^{pc} + b^{pc})\]
最终输出:任务\(t\)的输出为:
这种设计实现了任务级别和用户群体级别的双重个性化,既保证了多任务学习的效果,又解决了不同用户群体的差异化需求。